中文 | English
![]()
💜 Qwen Chat | 🤗 Hugging Face | 🤖 ModelScope | 📑 Blog | 📚 Cookbooks | 📑 Paper
🖥️ Demo | 💬 WeChat (微信) | 🫨 Discord | 📑 API
 ## 新闻
* 2025.04.11: 我们正式发布了支持音频输出的vllm版本!请从源码或者我们的镜像中来体验。
* 2025.04.02: ⭐️⭐️⭐️ Qwen2.5-Omni 达到 Hugging Face Trending 榜的 top-1!
* 2025.03.29: ⭐️⭐️⭐️ Qwen2.5-Omni 达到 Hugging Face Trending 榜的 top-2!
* 2025.03.26: 与Qwen2.5-Omni的实时交互体验已经在 [Qwen Chat](https://chat.qwen.ai/) 上线,欢迎体验!
* 2025.03.26: 我们发布了 [Qwen2.5-Omni](https://huggingface.co/collections/Qwen/qwen25-omni-67de1e5f0f9464dc6314b36e). 对于更多的信息请访问我们的[博客](https://qwenlm.github.io/zh/blog/qwen2.5-omni/)!
## 目录
- [概览](#概览)
- [简介](#简介)
- [主要特点](#主要特点)
- [模型结构](#模型结构)
- [性能指标](#性能指标)
- [快速开始](#快速开始)
- [Transformers 使用方法](#--transformers-使用方法)
- [ModelScope 使用方法](#-modelscope-使用方法)
- [使用提示](#使用提示)
- [更多使用用例的 Cookbooks](#更多使用用例的-cookbooks)
- [API 推理](#api-推理)
- [自定义模型设定](#自定义模型设定)
- [和 Qwen2.5-Omni 对话](#和-qwen25-omni-对话)
- [在线演示](#在线演示)
- [启动本地网页演示](#启动本地网页演示)
- [实时交互](#实时交互)
- [使用vLLM部署](#使用vLLM部署)
- [Docker](#-docker)
## 概览
### 简介
Qwen 2.5-Omni是一个端到端的多模态大语言模型,旨在感知包括文本、图像、音频和视频在内的多种模态,同时以流式的方式生成文本和自然语音响应。
## 新闻
* 2025.04.11: 我们正式发布了支持音频输出的vllm版本!请从源码或者我们的镜像中来体验。
* 2025.04.02: ⭐️⭐️⭐️ Qwen2.5-Omni 达到 Hugging Face Trending 榜的 top-1!
* 2025.03.29: ⭐️⭐️⭐️ Qwen2.5-Omni 达到 Hugging Face Trending 榜的 top-2!
* 2025.03.26: 与Qwen2.5-Omni的实时交互体验已经在 [Qwen Chat](https://chat.qwen.ai/) 上线,欢迎体验!
* 2025.03.26: 我们发布了 [Qwen2.5-Omni](https://huggingface.co/collections/Qwen/qwen25-omni-67de1e5f0f9464dc6314b36e). 对于更多的信息请访问我们的[博客](https://qwenlm.github.io/zh/blog/qwen2.5-omni/)!
## 目录
- [概览](#概览)
- [简介](#简介)
- [主要特点](#主要特点)
- [模型结构](#模型结构)
- [性能指标](#性能指标)
- [快速开始](#快速开始)
- [Transformers 使用方法](#--transformers-使用方法)
- [ModelScope 使用方法](#-modelscope-使用方法)
- [使用提示](#使用提示)
- [更多使用用例的 Cookbooks](#更多使用用例的-cookbooks)
- [API 推理](#api-推理)
- [自定义模型设定](#自定义模型设定)
- [和 Qwen2.5-Omni 对话](#和-qwen25-omni-对话)
- [在线演示](#在线演示)
- [启动本地网页演示](#启动本地网页演示)
- [实时交互](#实时交互)
- [使用vLLM部署](#使用vLLM部署)
- [Docker](#-docker)
## 概览
### 简介
Qwen 2.5-Omni是一个端到端的多模态大语言模型,旨在感知包括文本、图像、音频和视频在内的多种模态,同时以流式的方式生成文本和自然语音响应。
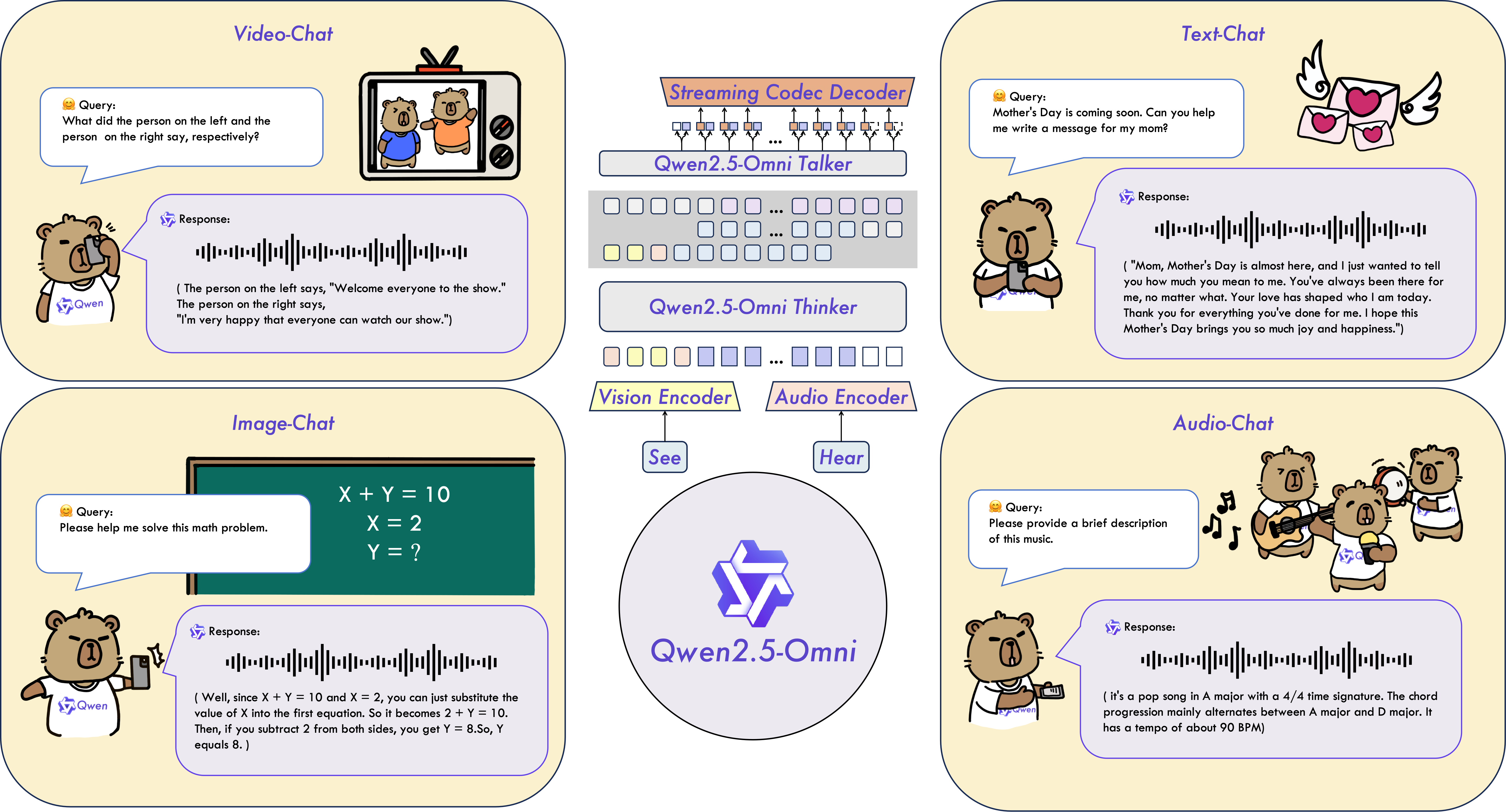
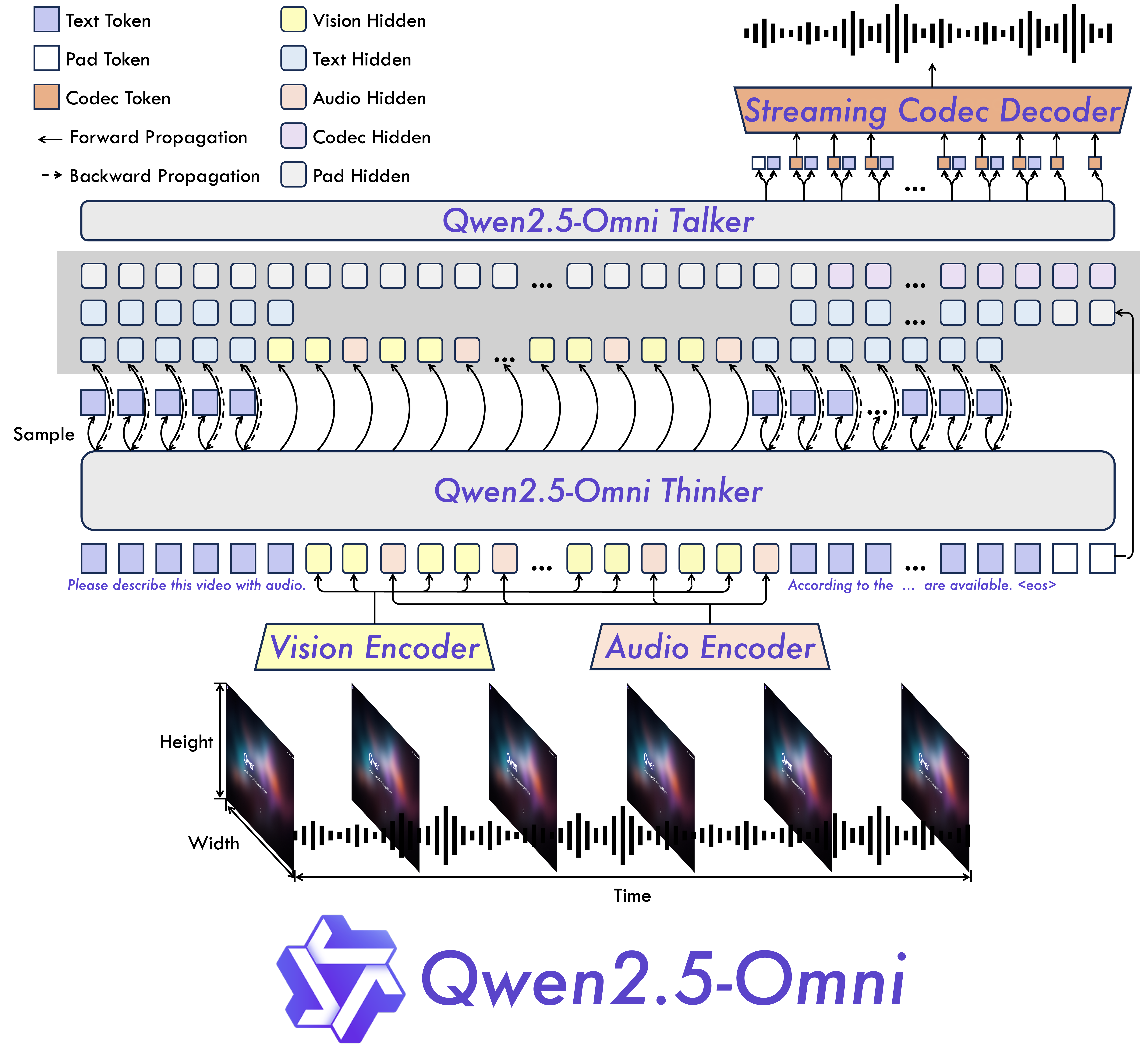
### 主要特点 * **全能创新架构**:我们提出了一种全新的Thinker-Talker架构,这是一种端到端的多模态模型,旨在支持文本/图像/音频/视频的跨模态理解,同时以流式方式生成文本和自然语音响应。我们提出了一种新的位置编码技术,称为TMRoPE(Time-aligned Multimodal RoPE),通过时间轴对齐实现视频与音频输入的精准同步。 * **实时音视频交互**:架构旨在支持完全实时交互,支持分块输入和即时输出。 * **自然流畅的语音生成**:在语音生成的自然性和稳定性方面超越了许多现有的流式和非流式替代方案。 * **全模态性能优势**:在同等规模的单模态模型进行基准测试时,表现出卓越的性能。Qwen2.5-Omni在音频能力上优于类似大小的Qwen2-Audio,并与Qwen2.5-VL-7B保持同等水平。 * **卓越的端到端语音指令跟随能力**:Qwen2.5-Omni在端到端语音指令跟随方面表现出与文本输入处理相媲美的效果,在MMLU通用知识理解和GSM8K数学推理等基准测试中表现优异。 ### 模型结构
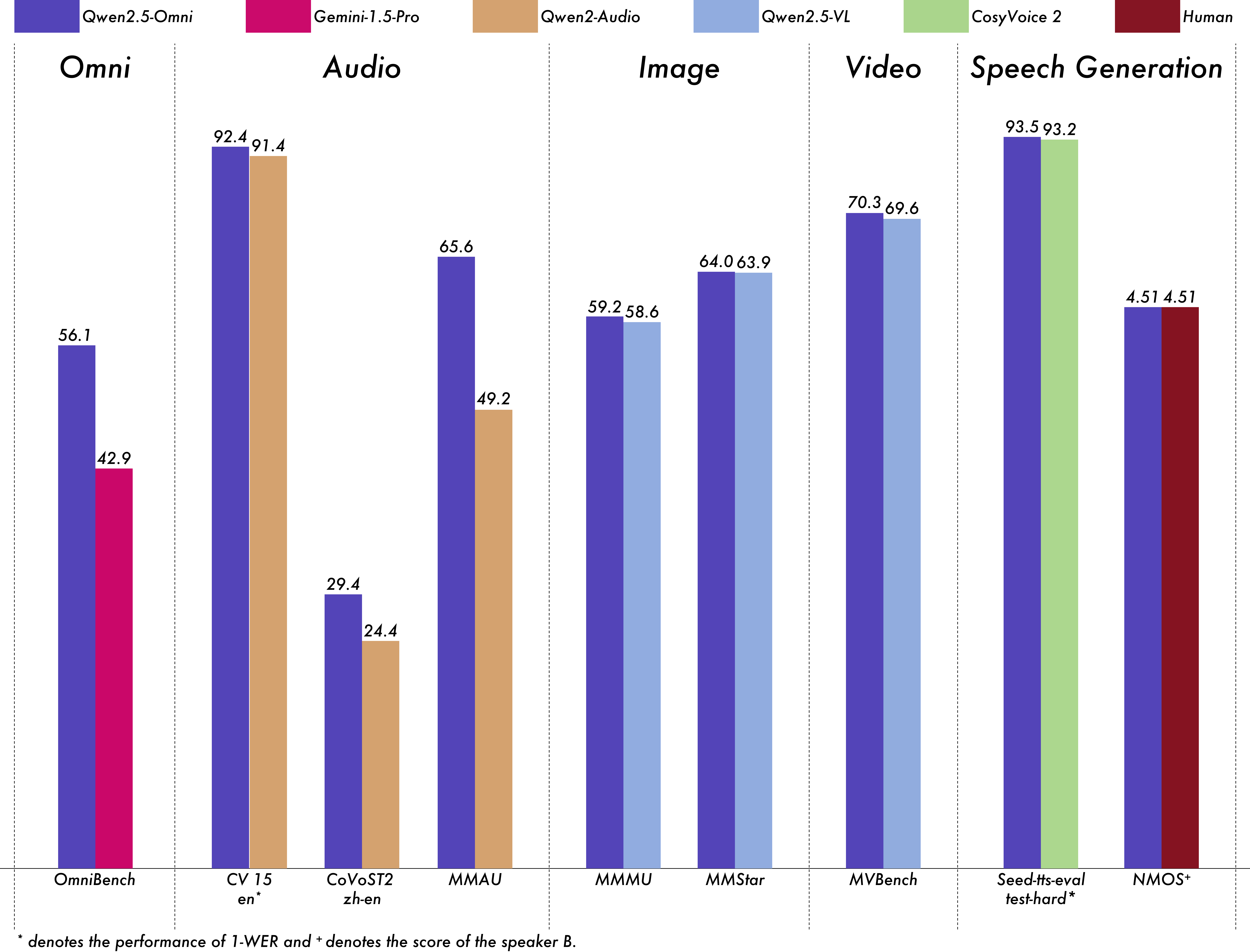
### 性能指标 Qwen2.5-Omni在包括图像,音频,音视频等各种模态下的表现都优于类似大小的单模态模型以及封闭源模型,例如Qwen2.5-VL-7B、Qwen2-Audio和Gemini-1.5-pro。在多模态任务OmniBench,Qwen2.5-Omni达到了SOTA的表现。此外,在单模态任务中,Qwen2.5-Omni在多个领域中表现优异,包括语音识别(Common Voice)、翻译(CoVoST2)、音频理解(MMAU)、图像推理(MMMU、MMStar)、视频理解(MVBench)以及语音生成(Seed-tts-eval和主观自然听感)。
Multimodality -> Text
Datasets
Model
Performance
OmniBench
Speech | Sound Event | Music | AvgGemini-1.5-Pro
42.67%|42.26%|46.23%|42.91%
MIO-Instruct
36.96%|33.58%|11.32%|33.80%
AnyGPT (7B)
17.77%|20.75%|13.21%|18.04%
video-SALMONN
34.11%|31.70%|56.60%|35.64%
UnifiedIO2-xlarge
39.56%|36.98%|29.25%|38.00%
UnifiedIO2-xxlarge
34.24%|36.98%|24.53%|33.98%
MiniCPM-o
-|-|-|40.50%
Baichuan-Omni-1.5
-|-|-|42.90%
Qwen2.5-Omni-7B
55.25%|60.00%|52.83%|56.13%
Audio -> Text
Datasets
Model
Performance
ASR
Librispeech
dev-clean | dev other | test-clean | test-otherSALMONN
-|-|2.1|4.9
SpeechVerse
-|-|2.1|4.4
Whisper-large-v3
-|-|1.8|3.6
Llama-3-8B
-|-|-|3.4
Llama-3-70B
-|-|-|3.1
Seed-ASR-Multilingual
-|-|1.6|2.8
MiniCPM-o
-|-|1.7|-
MinMo
-|-|1.7|3.9
Qwen-Audio
1.8|4.0|2.0|4.2
Qwen2-Audio
1.3|3.4|1.6|3.6
Qwen2.5-Omni-7B
1.6|3.5|1.8|3.4
Common Voice 15
en | zh | yue | frWhisper-large-v3
9.3|12.8|10.9|10.8
MinMo
7.9|6.3|6.4|8.5
Qwen2-Audio
8.6|6.9|5.9|9.6
Qwen2.5-Omni-7B
7.6|5.2|7.3|7.5
Fleurs
zh | enWhisper-large-v3
7.7|4.1
Seed-ASR-Multilingual
-|3.4
Megrez-3B-Omni
10.8|-
MiniCPM-o
4.4|-
MinMo
3.0|3.8
Qwen2-Audio
7.5|-
Qwen2.5-Omni-7B
3.0|4.1
Wenetspeech
test-net | test-meetingSeed-ASR-Chinese
4.7|5.7
Megrez-3B-Omni
-|16.4
MiniCPM-o
6.9|-
MinMo
6.8|7.4
Qwen2.5-Omni-7B
5.9|7.7
Voxpopuli-V1.0-en
Llama-3-8B
6.2
Llama-3-70B
5.7
Qwen2.5-Omni-7B
5.8
S2TT
CoVoST2
en-de | de-en | en-zh | zh-enSALMONN
18.6|-|33.1|-
SpeechLLaMA
-|27.1|-|12.3
BLSP
14.1|-|-|-
MiniCPM-o
-|-|48.2|27.2
MinMo
-|39.9|46.7|26.0
Qwen-Audio
25.1|33.9|41.5|15.7
Qwen2-Audio
29.9|35.2|45.2|24.4
Qwen2.5-Omni-7B
30.2|37.7|41.4|29.4
SER
Meld
WavLM-large
0.542
MiniCPM-o
0.524
Qwen-Audio
0.557
Qwen2-Audio
0.553
Qwen2.5-Omni-7B
0.570
VSC
VocalSound
CLAP
0.495
Pengi
0.604
Qwen-Audio
0.929
Qwen2-Audio
0.939
Qwen2.5-Omni-7B
0.939
Music
GiantSteps Tempo
Llark-7B
0.86
Qwen2.5-Omni-7B
0.88
MusicCaps
LP-MusicCaps
0.291|0.149|0.089|0.061|0.129|0.130
Qwen2.5-Omni-7B
0.328|0.162|0.090|0.055|0.127|0.225
Audio Reasoning
MMAU
Sound | Music | Speech | AvgGemini-Pro-V1.5
56.75|49.40|58.55|54.90
Qwen2-Audio
54.95|50.98|42.04|49.20
Qwen2.5-Omni-7B
67.87|69.16|59.76|65.60
Voice Chatting
VoiceBench
AlpacaEval | CommonEval | SD-QA | MMSUUltravox-v0.4.1-LLaMA-3.1-8B
4.55|3.90|53.35|47.17
MERaLiON
4.50|3.77|55.06|34.95
Megrez-3B-Omni
3.50|2.95|25.95|27.03
Lyra-Base
3.85|3.50|38.25|49.74
MiniCPM-o
4.42|4.15|50.72|54.78
Baichuan-Omni-1.5
4.50|4.05|43.40|57.25
Qwen2-Audio
3.74|3.43|35.71|35.72
Qwen2.5-Omni-7B
4.49|3.93|55.71|61.32
VoiceBench
OpenBookQA | IFEval | AdvBench | AvgUltravox-v0.4.1-LLaMA-3.1-8B
65.27|66.88|98.46|71.45
MERaLiON
27.23|62.93|94.81|62.91
Megrez-3B-Omni
28.35|25.71|87.69|46.25
Lyra-Base
72.75|36.28|59.62|57.66
MiniCPM-o
78.02|49.25|97.69|71.69
Baichuan-Omni-1.5
74.51|54.54|97.31|71.14
Qwen2-Audio
49.45|26.33|96.73|55.35
Qwen2.5-Omni-7B
81.10|52.87|99.42|74.12
Image -> Text
| Dataset | Qwen2.5-Omni-7B | Other Best | Qwen2.5-VL-7B | GPT-4o-mini |
|--------------------------------|--------------|------------|---------------|-------------|
| MMMUval | 59.2 | 53.9 | 58.6 | **60.0** |
| MMMU-Prooverall | 36.6 | - | **38.3** | 37.6 |
| MathVistatestmini | 67.9 | **71.9** | 68.2 | 52.5 |
| MathVisionfull | 25.0 | 23.1 | **25.1** | - |
| MMBench-V1.1-ENtest | 81.8 | 80.5 | **82.6** | 76.0 |
| MMVetturbo | 66.8 | **67.5** | 67.1 | 66.9 |
| MMStar | **64.0** | **64.0** | 63.9 | 54.8 |
| MMEsum | 2340 | **2372** | 2347 | 2003 |
| MuirBench | 59.2 | - | **59.2** | - |
| CRPErelation | **76.5** | - | 76.4 | - |
| RealWorldQAavg | 70.3 | **71.9** | 68.5 | - |
| MME-RealWorlden | **61.6** | - | 57.4 | - |
| MM-MT-Bench | 6.0 | - | **6.3** | - |
| AI2D | 83.2 | **85.8** | 83.9 | - |
| TextVQAval | 84.4 | 83.2 | **84.9** | - |
| DocVQAtest | 95.2 | 93.5 | **95.7** | - |
| ChartQAtest Avg | 85.3 | 84.9 | **87.3** | - |
| OCRBench_V2en | **57.8** | - | 56.3 | - |
| Dataset | Qwen2.5-Omni-7B | Qwen2.5-VL-7B | Grounding DINO | Gemini 1.5 Pro |
|--------------------------|--------------|---------------|----------------|----------------|
| Refcocoval | 90.5 | 90.0 | **90.6** | 73.2 |
| RefcocotextA | **93.5** | 92.5 | 93.2 | 72.9 |
| RefcocotextB | 86.6 | 85.4 | **88.2** | 74.6 |
| Refcoco+val | 85.4 | 84.2 | **88.2** | 62.5 |
| Refcoco+textA | **91.0** | 89.1 | 89.0 | 63.9 |
| Refcoco+textB | **79.3** | 76.9 | 75.9 | 65.0 |
| Refcocog+val | **87.4** | 87.2 | 86.1 | 75.2 |
| Refcocog+test | **87.9** | 87.2 | 87.0 | 76.2 |
| ODinW | 42.4 | 37.3 | **55.0** | 36.7 |
| PointGrounding | 66.5 | **67.3** | - | - |
Video(without audio) -> Text
| Dataset | Qwen2.5-Omni-7B | Other Best | Qwen2.5-VL-7B | GPT-4o-mini |
|-----------------------------|--------------|------------|---------------|-------------|
| Video-MMEw/o sub | 64.3 | 63.9 | **65.1** | 64.8 |
| Video-MMEw sub | **72.4** | 67.9 | 71.6 | - |
| MVBench | **70.3** | 67.2 | 69.6 | - |
| EgoSchematest | **68.6** | 63.2 | 65.0 | - |
Zero-shot Speech Generation
Datasets
Model
Performance
Content Consistency
SEED
test-zh | test-en | test-hard Seed-TTS_ICL
1.11 | 2.24 | 7.58
Seed-TTS_RL
1.00 | 1.94 | 6.42
MaskGCT
2.27 | 2.62 | 10.27
E2_TTS
1.97 | 2.19 | -
F5-TTS
1.56 | 1.83 | 8.67
CosyVoice 2
1.45 | 2.57 | 6.83
CosyVoice 2-S
1.45 | 2.38 | 8.08
Qwen2.5-Omni-7B_ICL
1.70 | 2.72 | 7.97
Qwen2.5-Omni-7B_RL
1.42 | 2.32 | 6.54
Speaker Similarity
SEED
test-zh | test-en | test-hard Seed-TTS_ICL
0.796 | 0.762 | 0.776
Seed-TTS_RL
0.801 | 0.766 | 0.782
MaskGCT
0.774 | 0.714 | 0.748
E2_TTS
0.730 | 0.710 | -
F5-TTS
0.741 | 0.647 | 0.713
CosyVoice 2
0.748 | 0.652 | 0.724
CosyVoice 2-S
0.753 | 0.654 | 0.732
Qwen2.5-Omni-7B_ICL
0.752 | 0.632 | 0.747
Qwen2.5-Omni-7B_RL
0.754 | 0.641 | 0.752
## 快速开始
接下来,我们将提供如何在🤖 ModelScope和🤗 Transformers上使用 Qwen2.5-Omni. Qwen2.5-Omni的代码在Hugging Face transformers的最新版本中,我们建议您从源代码构建:
```
pip uninstall transformers
pip install git+https://github.com/huggingface/transformers
pip install accelerate
```
否则您可能会遇到以下错误:
```
KeyError: 'qwen2_5_omni'
```
或者您也可以使用我们的[官方 docker 镜像](#-docker)来免去从源码构建。
我们提供了一个额外的小工具,它使您可以更方便地像使用API一样处理各种音频和视觉模态的输入,处理您输入中包括base64、URL以及交错的音频、图像和视频的情况。您可以使用以下命令安装此工具包,并确保您的系统安装了`ffmpeg`:
```bash
# 非常建议使用`[decord]`特性来获取更快的视频读取速度
pip install qwen-omni-utils[decord] -U
```
如果您未使用Linux操作系统,您可能无法从PyPI安装`decord`。 在这种情况下,您可以使用`pip install qwen-omni-utils -U`,它将回退到使用torchvision进行视频处理。 但是,您仍然可以[从源代码安装decord](https://github.com/dmlc/decord?tab=readme-ov-file#install-from-source),以在加载视频时使用decord。
此外,我们还准备了一些 [cookbooks](https://github.com/QwenLM/Qwen2.5-Omni/tree/main/cookbooks) 来进行能力展示, 包括音频理解、语音对话、屏幕录制交互、视频信息提取、多模态对话等等,敬请访问。
### 🤗 Transformers 使用方法
在这里我们通过一个简单的代码片段来向您展示如何通过`transformers` and `qwen_omni_utils`来使用我们的模型:
```python
import soundfile as sf
from transformers import Qwen2_5OmniForConditionalGeneration, Qwen2_5OmniProcessor
from qwen_omni_utils import process_mm_info
# default: Load the model on the available device(s)
model = Qwen2_5OmniForConditionalGeneration.from_pretrained("Qwen/Qwen2.5-Omni-7B", torch_dtype="auto", device_map="auto")
# 我们建议启用 flash_attention_2 以获取更快的推理速度以及更低的显存占用.
# model = Qwen2_5OmniForConditionalGeneration.from_pretrained(
# "Qwen/Qwen2.5-Omni-7B",
# torch_dtype="auto",
# device_map="auto",
# attn_implementation="flash_attention_2",
# )
processor = Qwen2_5OmniProcessor.from_pretrained("Qwen/Qwen2.5-Omni-7B")
conversation = [
{
"role": "system",
"content": [
{"type": "text", "text": "You are Qwen, a virtual human developed by the Qwen Team, Alibaba Group, capable of perceiving auditory and visual inputs, as well as generating text and speech."}
],
},
{
"role": "user",
"content": [
{"type": "video", "video": "https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen2.5-Omni/draw.mp4"},
],
},
]
# set use audio in video
USE_AUDIO_IN_VIDEO = True
# Preparation for inference
text = processor.apply_chat_template(conversation, add_generation_prompt=True, tokenize=False)
audios, images, videos = process_mm_info(conversation, use_audio_in_video=USE_AUDIO_IN_VIDEO)
inputs = processor(text=text, audio=audios, images=images, videos=videos, return_tensors="pt", padding=True, use_audio_in_video=USE_AUDIO_IN_VIDEO)
inputs = inputs.to(model.device).to(model.dtype)
# Inference: Generation of the output text and audio
text_ids, audio = model.generate(**inputs, use_audio_in_video=USE_AUDIO_IN_VIDEO)
text = processor.batch_decode(text_ids, skip_special_tokens=True, clean_up_tokenization_spaces=False)
print(text)
sf.write(
"output.wav",
audio.reshape(-1).detach().cpu().numpy(),
samplerate=24000,
)
```
Text -> Text
| Dataset | Qwen2.5-Omni-7B | Qwen2.5-7B | Qwen2-7B | Llama3.1-8B | Gemma2-9B |
|-----------------------------------|-----------|------------|----------|-------------|-----------|
| MMLU-Pro | 47.0 | **56.3** | 44.1 | 48.3 | 52.1 |
| MMLU-redux | 71.0 | **75.4** | 67.3 | 67.2 | 72.8 |
| LiveBench0831 | 29.6 | **35.9** | 29.2 | 26.7 | 30.6 |
| GPQA | 30.8 | **36.4** | 34.3 | 32.8 | 32.8 |
| MATH | 71.5 | **75.5** | 52.9 | 51.9 | 44.3 |
| GSM8K | 88.7 | **91.6** | 85.7 | 84.5 | 76.7 |
| HumanEval | 78.7 | **84.8** | 79.9 | 72.6 | 68.9 |
| MBPP | 73.2 | **79.2** | 67.2 | 69.6 | 74.9 |
| MultiPL-E | 65.8 | **70.4** | 59.1 | 50.7 | 53.4 |
| LiveCodeBench2305-2409 | 24.6 | **28.7** | 23.9 | 8.3 | 18.9 |
最小GPU内存需求
| 精度 | 15(s) 视频 | 30(s) 视频 | 60(s) 视频 |
|-----------| ------------- | --------- | -------------- |
| FP32 | 93.56 GB | 不推荐 | 不推荐 |
| BF16 | 31.11 GB | 41.85 GB | 60.19 GB |
注意: 上述的表格所展示的只是使用`transformers`进行推理的理论最小值,并且`BF16`的结果是在`attn_implementation="flash_attention_2"`的情况下测试得到的,但是在实际中,内存使用通常比这个值要高至少1.2倍。 有关更多信息,请参阅[这里](https://huggingface.co/docs/accelerate/main/en/usage_guides/model_size_estimator)。
视频URL超链接使用方法
视频URL超链接的兼容性取决于第三方库的版本。具体的细节在下表中所示,如果您不希望使用默认值,可以通过设置`FORCE_QWENVL_VIDEO_READER=torchvision`或`FORCE_QWENVL_VIDEO_READER=decord`来实现。
| 后端类型 | HTTP | HTTPS |
|-------------|------|-------|
| torchvision >= 0.19.0 | ✅ | ✅ |
| torchvision < 0.19.0 | ❌ | ❌ |
| decord | ✅ | ❌ |
### 🤖 ModelScope 使用方法
我们强烈建议中国用户使用ModelScope来获取模型,`snapshot_download`可以解决下载过程中的各种网络问题,详情请参考[ModelScope](https://modelscope.cn/organization/qwen)。
### 使用提示
#### 音频输出的提示词
如果用户需要音频输出,那么系统提示必须设置为"You are Qwen, a virtual human developed by the Qwen Team, Alibaba Group, capable of perceiving auditory and visual inputs, as well as generating text and speech.",否则音频输出可能不会按照预期工作。
```
{
"role": "system",
"content": [
{"type": "text", "text": "You are Qwen, a virtual human developed by the Qwen Team, Alibaba Group, capable of perceiving auditory and visual inputs, as well as generating text and speech."}
]
}
```
#### 使用视频中的音频
在多模态交互过程中,用户提供的视频通常伴随着音频(如对视频内容的提问,或者视频中某些事件的声音),这些信息对模型的交互体验很关键。因此,我们提供了以下选项让用户决定是否使用视频中的音频。
```python
# 第一处,在数据预处理中
audios, images, videos = process_mm_info(conversations, use_audio_in_video=True)
```
```python
# 第二处,在模型处理中
inputs = processor(text=text, audio=audios, images=images, videos=videos, return_tensors="pt",
padding=True, use_audio_in_video=True)
```
```python
# 第三处,在模型推理中
text_ids, audio = model.generate(**inputs, use_audio_in_video=True)
```
值得注意的是,在多轮对话过程中,`use_audio_in_video`参数在这几个地方必须设置为相同的值,否则可能会出现非预期的结果。
#### 是否使用音频输出
模型支持文本和音频输出,如果用户不需要音频输出,可以在模型加载完毕后调用`model.disable_talker()`,此选项将节省约`2GB`的GPU内存,但`generate`函数的`return_audio`选项将只能设置为`False`。
```python
model = Qwen2_5OmniForConditionalGeneration.from_pretrained(
"Qwen/Qwen2.5-Omni-7B",
torch_dtype="auto",
device_map="auto"
)
model.disable_talker()
```
为了获得灵活的体验,我们建议在调用`generate`函数时根据需要决定是否返回音频。当`return_audio`设置为`False`时,模型将仅返回文本输出以更快地获取文本响应。
``python
model = Qwen2_5OmniForConditionalGeneration.from_pretrained(
"Qwen/Qwen2.5-Omni-7B",
torch_dtype="auto",
device_map="auto"
)
...
text_ids = model.generate(**inputs, return_audio=False)
```
#### 修改输出语音的音色类型
Qwen2.5-Omni 支持修改输出语音的音色类型,`"Qwen/Qwen2.5-Omni-7B"`目前支持两种如下两种音色类型:
| 音色类型 | 性别 | 描述 |
|------------|--------|-------------|
| Chelsie | 女 | 甜美,温婉,明亮,轻柔|
| Ethan | 男 | 阳光,活力,轻快,亲和|
用户可以使用`generate`函数的`speaker`参数来指定音色类型。默认情况下,如果没有指定`speaker`,则默认音色类型为`Chelsie`。
```python
text_ids, audio = model.generate(**inputs, speaker="Chelsie")
```
```python
text_ids, audio = model.generate(**inputs, speaker="Ethan")
```
#### 使用Flash-Attention 2加速生成
首先,请确保已安装最新版本的Flash Attention 2:
```bash
pip install -U flash-attn --no-build-isolation
```
当然,您还需要确保您的硬件兼容Flash Attention 2,可以从[官方文档](https://github.com/Dao-AILab/flash-attention)来获取更多信息。FlashAttention-2仅可在模型加载到`torch.float16`或`torch.bfloat16`时使用。
为了加载并运行使用FlashAttention-2的模型,在加载模型时添加`attn_implementation="flash_attention_2"`:
```python
from transformers import Qwen2_5OmniForConditionalGeneration
model = Qwen2_5OmniForConditionalGeneration.from_pretrained(
"Qwen/Qwen2.5-Omni-7B",
device_map="auto",
torch_dtype=torch.bfloat16,
attn_implementation="flash_attention_2",
)
```
### 更多使用用例的 Cookbooks
| Cookbook | 描述 | 打开 |
| -------- | ----------- | ---- |
| [通用语音理解](https://github.com/QwenLM/Qwen2.5-Omni/blob/main/cookbooks/universal_audio_understanding.ipynb) | 语音识别,语音到文本翻译,音频分析。 | [](https://github.com/QwenLM/Qwen2.5-Omni/blob/main/cookbooks/universal_audio_understanding.ipynb) |
| [语音对话](https://github.com/QwenLM/Qwen2.5-Omni/blob/main/cookbooks/voice_chatting.ipynb) | 和 Qwen2.5-Omin 通过语音输入和输出对话。 | [](https://github.com/QwenLM/Qwen2.5-Omni/blob/main/cookbooks/voice_chatting.ipynb) |
| [屏幕录制交互](https://github.com/QwenLM/Qwen2.5-Omni/blob/main/cookbooks/screen_recording_interaction.ipynb) | 从正在实时录制的屏幕中通过提问的方式获取想了解的信息和内容。 | [](https://github.com/QwenLM/Qwen2.5-Omni/blob/main/cookbooks/screen_recording_interaction.ipynb) |
| [视频信息提取](https://github.com/QwenLM/Qwen2.5-Omni/blob/main/cookbooks/video_information_extracting.ipynb) | 从视频流中获取信息。 | [](https://github.com/QwenLM/Qwen2.5-Omni/blob/main/cookbooks/video_information_extracting.ipynb) |
| [关于音乐的全模态对话](https://github.com/QwenLM/Qwen2.5-Omni/blob/main/cookbooks/omni_chatting_for_music.ipynb) | 和 Qwen2.5-Omni 通过音视频流的交互方式聊聊关于音乐的话题。 | [](https://github.com/QwenLM/Qwen2.5-Omni/blob/main/cookbooks/omni_chatting_for_music.ipynb) |
| [关于数学的全模态对话](https://github.com/QwenLM/Qwen2.5-Omni/blob/main/cookbooks/omni_chatting_for_math.ipynb) | 和 Qwen2.5-Omni 通过音视频流的交互方式聊聊关于数学的话题。 | [](https://github.com/QwenLM/Qwen2.5-Omni/blob/main/cookbooks/omni_chatting_for_math.ipynb) |
| [多轮全模态对话](https://github.com/QwenLM/Qwen2.5-Omni/blob/main/cookbooks/multi_round_omni_chatting.ipynb) | 与 Qwen2.5-Omni 进行了多轮全模态的音视频对话,提供最全面的能力演示。 | [](https://github.com/QwenLM/Qwen2.5-Omni/blob/main/cookbooks/multi_round_omni_chatting.ipynb) |
### API 推理
为了近一步探索 Qwen2.5-Omni,我们鼓励您使用我们的最新 API 服务来获取更快更高效的体验。
#### 安装
```bash
pip install openai
```
#### 示例
您可以按照如下的示例使用 OpenAI API 服务与 Qwen2.5-Omni 进行交互,对于更多的使用方法,请参考阿里云的[教程](https://help.aliyun.com/zh/model-studio/user-guide/qwen-omni)。
```python
import base64
import numpy as np
import soundfile as sf
from openai import OpenAI
client = OpenAI(
api_key="your_api_key",
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
)
messages = [
{
"role": "system",
"content": "You are Qwen, a virtual human developed by the Qwen Team, Alibaba Group, capable of perceiving auditory and visual inputs, as well as generating text and speech.",
},
{
"role": "user",
"content": [
{"type": "video_url", "video_url": "https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen2.5-Omni/draw.mp4"},
],
},
]
# Qwen-Omni only supports stream mode
completion = client.chat.completions.create(
model="qwen-omni-turbo",
messages=messages,
modalities=["text", "audio"],
audio={
"voice": "Cherry", # Cherry, Ethan, Serena, Chelsie is available
"format": "wav"
},
stream=True,
stream_options={"include_usage": True}
)
text = []
audio_string = ""
for chunk in completion:
if chunk.choices:
if hasattr(chunk.choices[0].delta, "audio"):
try:
audio_string += chunk.choices[0].delta.audio["data"]
except Exception as e:
text.append(chunk.choices[0].delta.audio["transcript"])
else:
print(chunk.usage)
print("".join(text))
wav_bytes = base64.b64decode(audio_string)
wav_array = np.frombuffer(wav_bytes, dtype=np.int16)
sf.write("output.wav", wav_array, samplerate=24000)
```
### 自定义模型设定
由于Qwen2.5-Omni在使用[音频输出](#音频输出的提示词)时(包括本地部署和API推理)并不支持prompt的设定,因此我们建议如果您需要对模型的输出进行一定的控制或者对模型的人设等进行修改,可以尝试在对话模板中加入如下类似的设定:
```python
conversation = [
{
"role": "user",
"content": [
{"type": "text", "text": "You are a shopping guide, now responsible for introducing various products."},
],
},
{
"role": "assistant",
"content": [
{"type": "text", "text": "Sure, I got it."},
],
},
{
"role": "user",
"content": [
{"type": "text", "text": "Who are you?"},
],
},
]
```
## 和 Qwen2.5-Omni 对话
### 在线演示
无需部署,您可以直接访问我们的 [Hugginface Spaces](https://huggingface.co/spaces/Qwen/Qwen2.5-Omni-7B-Demo) 和 [Modelscope 创空间](https://modelscope.cn/studios/Qwen/Qwen2.5-Omni-Demo) 来直接体验在线网页演示。
### 启动本地网页演示
在本节中,我们提供了如何构建一个基于网页的 UI(用户界面)演示的指南,此 UI 演示允许用户通过浏览器与预定义的模型或应用程序进行交互,请按照以下步骤开始使用或您可以直接从我们的[官方 Docker 镜像](#-docker)中启动网页演示。
#### 安装
在您开始之前,请确保已安装所需的依赖项,您可以通过运行以下命令来安装它们:
```bash
pip install -r requirements_web_demo.txt
```
#### 基于 FlashAttention-2 启动演示
一旦您已安装所需的依赖项,您可以使用以下命令启动网页演示。此命令将启动一个 Web 服务,并提供您用于在 Web 浏览器中访问 UI 的链接。
**建议**: 为了获得更好的性能和效率,尤其是处理大量图像和视频的场景下,我们强烈建议使用 [FlashAttention-2](https://github.com/Dao-AILab/flash-attention)。FlashAttention-2 提供了显存使用和速度的显著改进,因此对于处理大型模型和数据处理的场景,它非常合适。
为了启用 FlashAttention-2,使用如下命令启动演示:
```bash
python web_demo.py --flash-attn2
```
这将会加载模型并启用 FlashAttention-2。
**默认使用方法**: 如果您更希望在不使用 FlashAttention-2 的情况下运行演示,也即不指定`--flash-attn2`参数,此时演示将会使用默认的注意力机制实现方法来加噪和运行模型,您可以使用以下命令:
```bash
python web_demo.py
```
在运行这个命令之后, 您将会在终端中看到类似的输出:
```
Running on local: http://127.0.0.1:7860/
```
复制该链接,并将其粘贴到浏览器中,即可访问网页演示,在网页中您可以输入文本、上传音频、图像和视频,以及切换输出音色类型等功能。
### 实时交互
实时交互体验目前已经上线,请您访问[Qwen Chat](https://chat.qwen.ai/),并在聊天框中选择语音/视频通话,即可体验与Qwen2.5-Omni的实时交互。
## 使用vLLM部署
我们建议使用vLLM进行Qwen2.5-Omni的快速部署和推理,您需要从我们提供的[源码](https://github.com/fyabc/vllm/tree/qwen2_omni_public)构建vLLM以获取对Qwen2.5-Omni支持,或者使用我们的[官方 docker 镜像](#-docker)。您也可以查看[vLLM官方文档](https://docs.vllm.ai/en/latest/serving/multimodal_inputs.html)以获取在线服务和离线推理的更多信息。
### 安装
```bash
git clone -b qwen2_omni_public https://github.com/fyabc/vllm.git
cd vllm
git checkout 729feed3ec2beefe63fda30a345ef363d08062f8
pip install setuptools_scm torchdiffeq resampy x_transformers qwen-omni-utils accelerate
pip install -r requirements/cuda.txt
pip install .
pip install git+https://github.com/huggingface/transformers
```
### 本地离线推理
您可以使用vLLM进行Qwen2.5-Omni的本地推理,我们在vLLM[源码](https://github.com/fyabc/vllm/tree/qwen2_omni_public)中提供了[示例](https://github.com/fyabc/vllm/blob/qwen2_omni_public/examples/offline_inference/qwen2_5_omni/end2end.py),该示例可以端到端的生成音频。
```bash
# git clone -b qwen2_omni_public https://github.com/fyabc/vllm.git
# cd vllm
# git checkout 729feed3ec2beefe63fda30a345ef363d08062f8
# cd examples/offline_inference/qwen2_5_omni/
# only text output for single GPU
python end2end.py --model Qwen/Qwen2.5-Omni-7B --prompt audio-in-video-v2 --enforce-eager --thinker-only
# only text output for multi GPUs (example in 4 GPUs)
python end2end.py --model Qwen/Qwen2.5-Omni-7B --prompt audio-in-video-v2 --enforce-eager --thinker-only --thinker-devices [0,1,2,3] --thinker-gpu-memory-utilization 0.9
# audio output for single GPU
python end2end.py --model Qwen/Qwen2.5-Omni-7B --prompt audio-in-video-v2 --enforce-eager --do-wave --voice-type Chelsie --warmup-voice-type Chelsie --output-dir output_wav
# audio output for multi GPUs (example in 4 GPUs)
python end2end.py --model Qwen/Qwen2.5-Omni-7B --prompt audio-in-video-v2 --enforce-eager --do-wave --voice-type Chelsie --warmup-voice-type Chelsie --thinker-devices [0,1] --talker-devices [2] --code2wav-devices [3] --thinker-gpu-memory-utilization 0.9 --talker-gpu-memory-utilization 0.9 --output-dir output_wav
```
除了上述的示例之外,您可以通过以下命令通过vLLM来启动API服务,目前vLLM serve仅支持文本输出。
```bash
# for single GPU
VLLM_USE_V1=0 vllm serve /path/to/Qwen2.5-Omni-7B/ --port 8000 --host 127.0.0.1 --dtype bfloat16
# for multi GPUs (example in 4 GPUs)
VLLM_USE_V1=0 vllm serve /path/to/Qwen2.5-Omni-7B/ --port 8000 --host 127.0.0.1 --dtype bfloat16 -tp 4
```
然后您可以通过如下代码使用这个API(示例里是使用curl命令):
```bash
curl http://localhost:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"messages": [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": [
{"type": "image_url", "image_url": {"url": "https://modelscope.oss-cn-beijing.aliyuncs.com/resource/qwen.png"}},
{"type": "audio_url", "audio_url": {"url": "https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen2.5-Omni/cough.wav"}},
{"type": "text", "text": "What is the text in the illustrate ans what it the sound in the audio?"}
]}
]
}'
```
## 🐳 Docker
为了简化部署过程,我们提供了预构建环境:[qwenllm/qwen-omni](https://hub.docker.com/r/qwenllm/qwen-omni),您只需要安装驱动并下载模型文件即可启动演示。
```bash
docker run --gpus all --ipc=host --network=host --rm --name qwen2.5-omni -it qwenllm/qwen-omni:2.5-cu121 bash
```
并且您也可以直接通过如下命令启动网页演示:
```bash
bash docker/docker_web_demo.sh --checkpoint /path/to/Qwen2.5-Omni-7B
```
如需启用FlashAttention-2,请使用如下命令:
```bash
bash docker/docker_web_demo.sh --checkpoint /path/to/Qwen2.5-Omni-7B --flash-attn2
```
## 引用
如果您在您的研究中感到 Qwen2.5-Omni 为您提供了帮助,期待您能给一个 Star :star: 和引用 :pencil: :)
```BibTeX
@article{Qwen2.5-Omni,
title={Qwen2.5-Omni Technical Report},
author={Jin Xu, Zhifang Guo, Jinzheng He, Hangrui Hu, Ting He, Shuai Bai, Keqin Chen, Jialin Wang, Yang Fan, Kai Dang, Bin Zhang, Xiong Wang, Yunfei Chu, Junyang Lin},
journal={arXiv preprint arXiv:2503.20215},
year={2025}
}
```
批处理
当`return_audio=False`设置时,模型支持混合输入的批处理,其中可以包含各种类型的样本,如文本、图像、音频和视频,以下是一个代码片段的示例。
```python
# Sample messages for batch inference
# Conversation with video only
conversation1 = [
{
"role": "system",
"content": [
{"type": "text", "text": "You are Qwen, a virtual human developed by the Qwen Team, Alibaba Group, capable of perceiving auditory and visual inputs, as well as generating text and speech."}
],
},
{
"role": "user",
"content": [
{"type": "video", "video": "/path/to/video.mp4"},
]
}
]
# Conversation with audio only
conversation2 = [
{
"role": "system",
"content": [
{"type": "text", "text": "You are Qwen, a virtual human developed by the Qwen Team, Alibaba Group, capable of perceiving auditory and visual inputs, as well as generating text and speech."}
],
},
{
"role": "user",
"content": [
{"type": "audio", "audio": "/path/to/audio.wav"},
]
}
]
# Conversation with pure text
conversation3 = [
{
"role": "system",
"content": [
{"type": "text", "text": "You are Qwen, a virtual human developed by the Qwen Team, Alibaba Group, capable of perceiving auditory and visual inputs, as well as generating text and speech."}
],
},
{
"role": "user",
"content": "who are you?"
}
]
# Conversation with mixed media
conversation4 = [
{
"role": "system",
"content": [
{"type": "text", "text": "You are Qwen, a virtual human developed by the Qwen Team, Alibaba Group, capable of perceiving auditory and visual inputs, as well as generating text and speech."}
],
},
{
"role": "user",
"content": [
{"type": "image", "image": "/path/to/image.jpg"},
{"type": "video", "video": "/path/to/video.mp4"},
{"type": "audio", "audio": "/path/to/audio.wav"},
{"type": "text", "text": "What are the elements can you see and hear in these medias?"},
],
}
]
# Combine messages for batch processing
conversations = [conversation1, conversation2, conversation3, conversation4]
# set use audio in video
USE_AUDIO_IN_VIDEO = True
# Preparation for batch inference
text = processor.apply_chat_template(conversations, add_generation_prompt=True, tokenize=False)
audios, images, videos = process_mm_info(conversations, use_audio_in_video=USE_AUDIO_IN_VIDEO)
inputs = processor(text=text, audio=audios, images=images, videos=videos, return_tensors="pt", padding=True, use_audio_in_video=USE_AUDIO_IN_VIDEO)
inputs = inputs.to(model.device).to(model.dtype)
# Batch Inference
text_ids = model.generate(**inputs, use_audio_in_video=USE_AUDIO_IN_VIDEO, return_audio=False)
text = processor.batch_decode(text_ids, skip_special_tokens=True, clean_up_tokenization_spaces=False)
print(text)
```
{kind=link}