diff --git a/docs/database/Redis/Redis.md b/docs/database/Redis/Redis.md
index a17c7f042dd411520b06a84c7fda40d0f587dace..ed3e5885e958831af0c96bec822d32edba351fa3 100644
--- a/docs/database/Redis/Redis.md
+++ b/docs/database/Redis/Redis.md
@@ -34,7 +34,7 @@
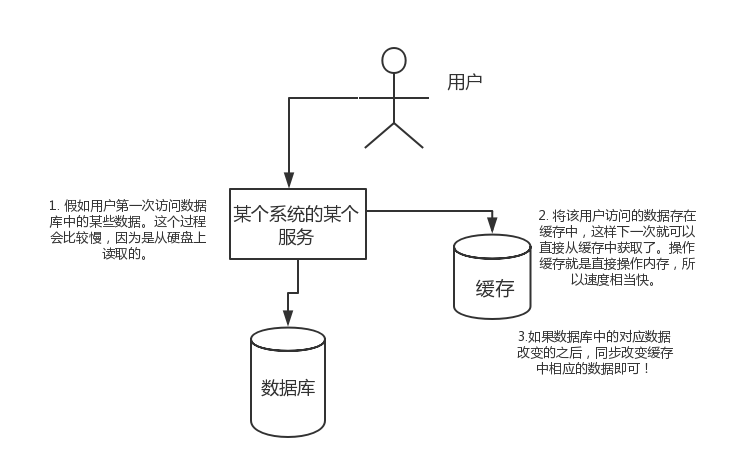
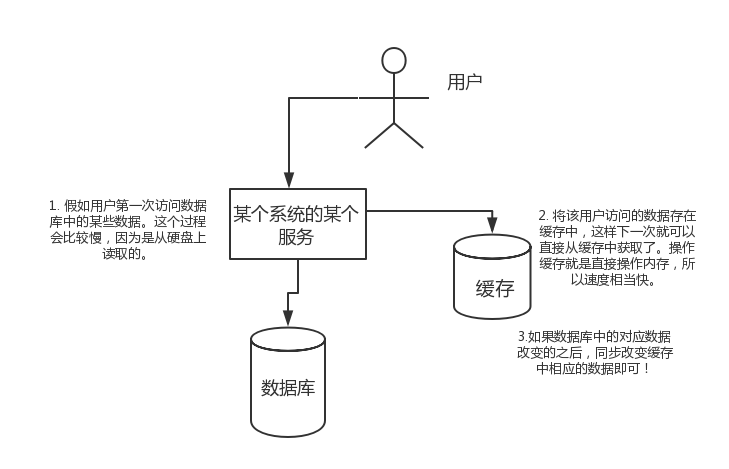
假如用户第一次访问数据库中的某些数据。这个过程会比较慢,因为是从硬盘上读取的。将该用户访问的数据存在缓存中,这样下一次再访问这些数据的时候就可以直接从缓存中获取了。操作缓存就是直接操作内存,所以速度相当快。如果数据库中的对应数据改变的之后,同步改变缓存中相应的数据即可!
-
+
**高并发:**
@@ -42,7 +42,7 @@
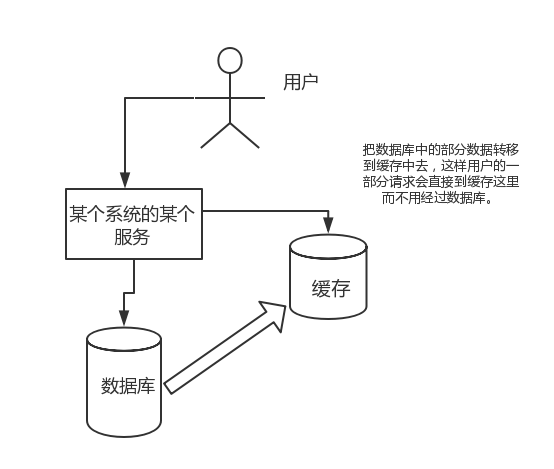
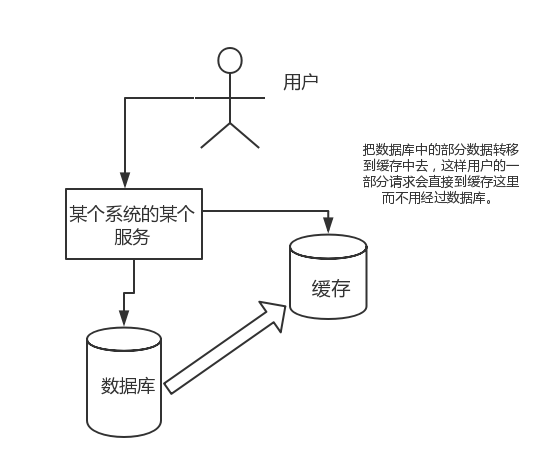
直接操作缓存能够承受的请求是远远大于直接访问数据库的,所以我们可以考虑把数据库中的部分数据转移到缓存中去,这样用户的一部分请求会直接到缓存这里而不用经过数据库。
-
+
### 为什么要用 redis 而不用 map/guava 做缓存?
@@ -58,7 +58,7 @@
> 参考地址:https://www.javazhiyin.com/22943.html
-redis 内部使用文件事件处理器 `file event handler`,这个文件事件处理器是单线程的,所以 redis 才叫做单线程的模型。它采用 IO 多路复用机制同时监听多个 socket,根据 socket 上的事件来选择对应的事件处理器进行处理。
+redis 内部使用文件事件处理器 `file event handler`,这个文件事件处理器是单线程的,所以redis才叫做单线程的模型。它采用 IO 多路复用机制同时监听多个 socket,根据 socket 上的事件来选择对应的事件处理器进行处理。
文件事件处理器的结构包含 4 个部分:
@@ -82,7 +82,7 @@ redis 内部使用文件事件处理器 `file event handler`,这个文件事
> 来自网络上的一张图,这里分享给大家!
-
+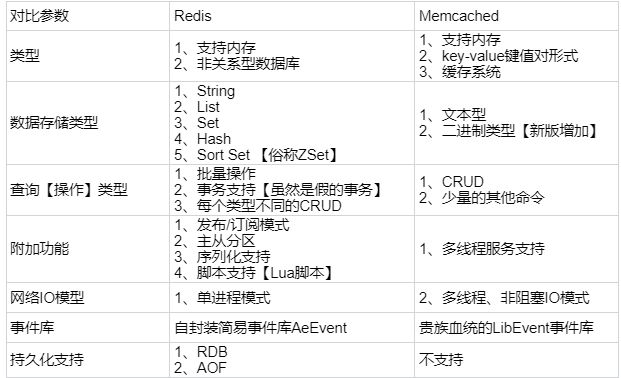
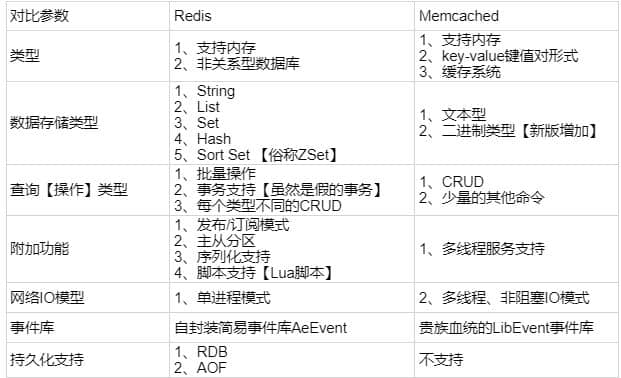
### redis 常见数据结构以及使用场景分析
@@ -271,7 +271,7 @@ Redis 通过 MULTI、EXEC、WATCH 等命令来实现事务(transaction)功能。
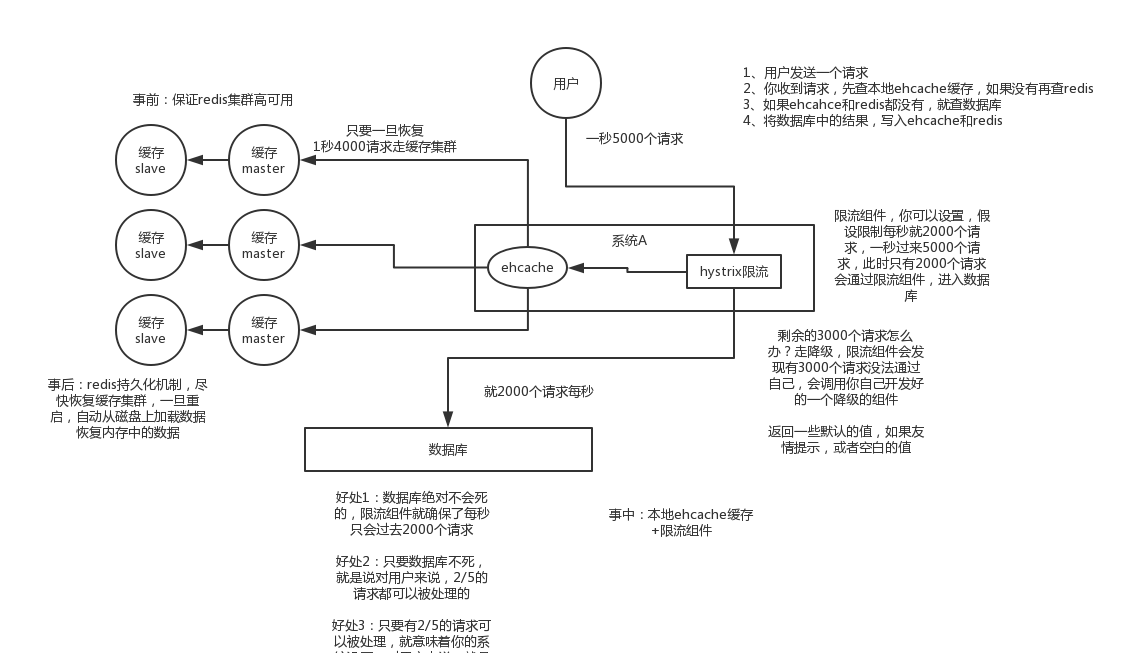
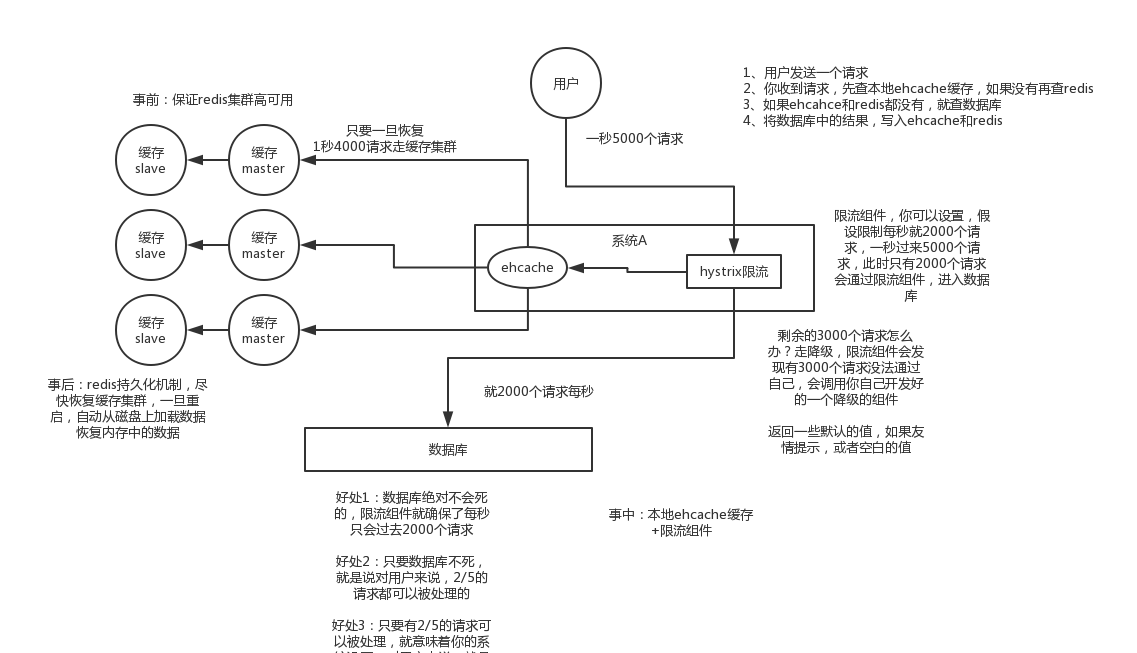
- 事中:本地ehcache缓存 + hystrix限流&降级,避免MySQL崩掉
- 事后:利用 redis 持久化机制保存的数据尽快恢复缓存
-
+
#### **缓存穿透**
@@ -281,11 +281,10 @@ Redis 通过 MULTI、EXEC、WATCH 等命令来实现事务(transaction)功能。
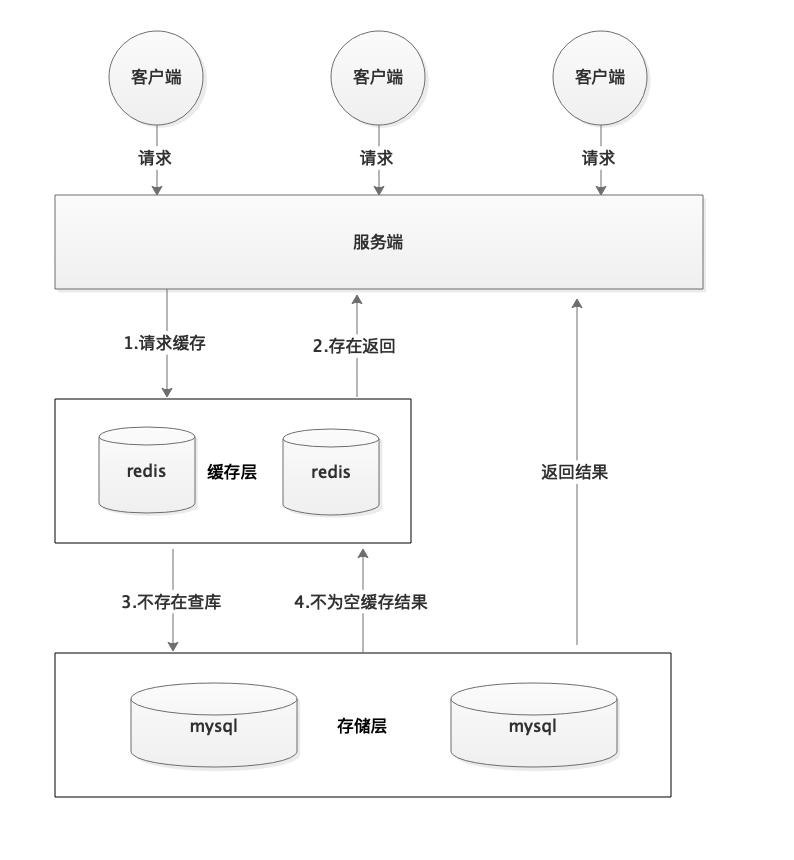
**正常缓存处理流程:**
- +
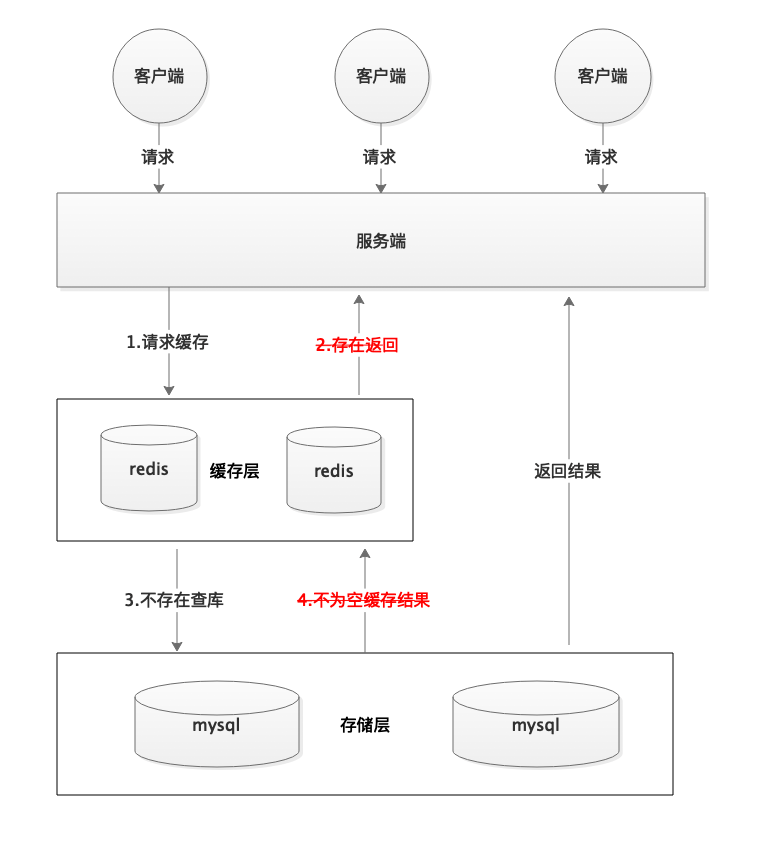
+ **缓存穿透情况处理流程:**
-
-
**缓存穿透情况处理流程:**
-
- +
一般MySQL 默认的最大连接数在 150 左右,这个可以通过 `show variables like '%max_connections%'; `命令来查看。最大连接数一个还只是一个指标,cpu,内存,磁盘,网络等无力条件都是其运行指标,这些指标都会限制其并发能力!所以,一般 3000 个并发请求就能打死大部分数据库了。
@@ -322,7 +321,7 @@ public Object getObjectInclNullById(Integer id) {
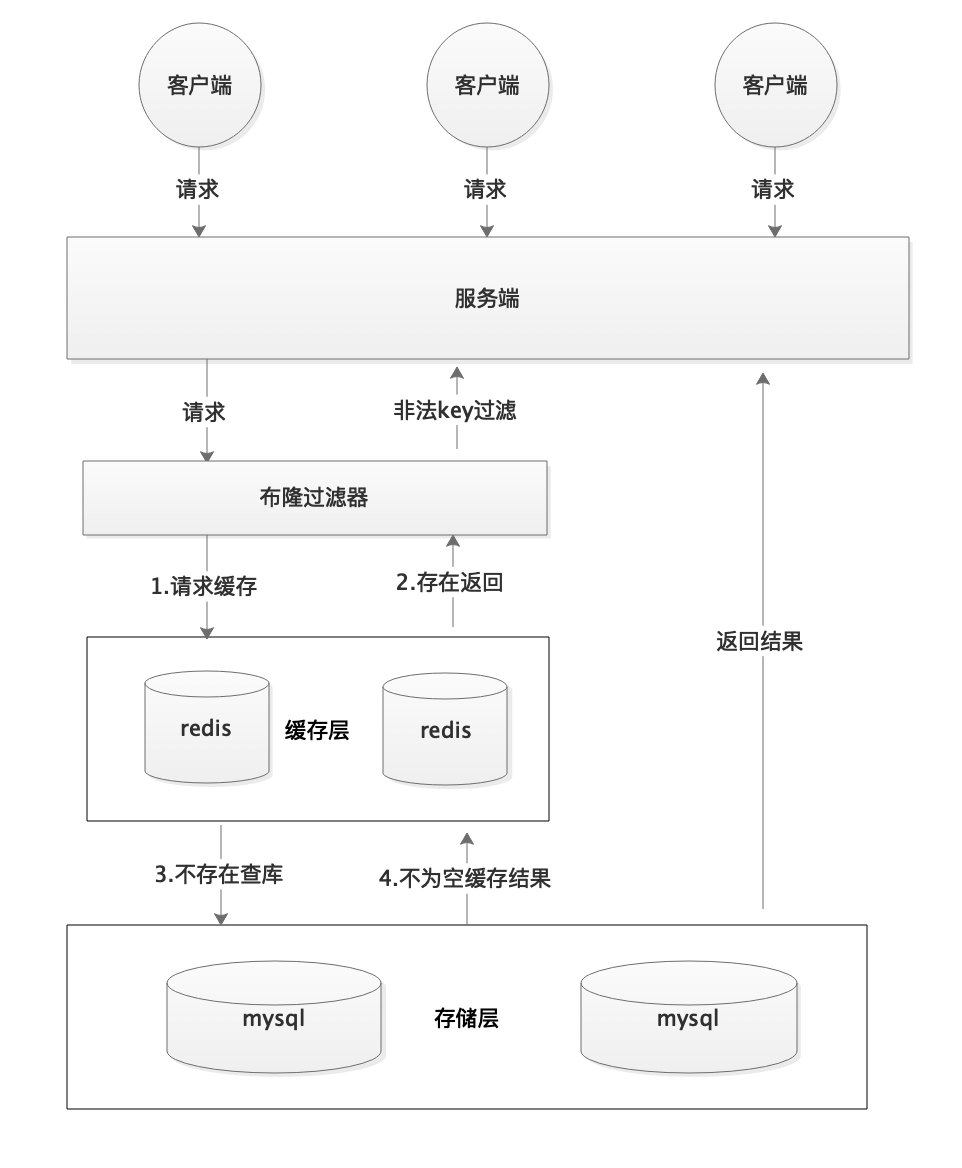
**2)布隆过滤器:**布隆过滤器是一个非常神奇的数据结构,通过它我们可以非常方便地判断一个给定数据是否存在与海量数据中。我们需要的就是判断 key 是否合法,有没有感觉布隆过滤器就是我们想要找的那个“人”。具体是这样做的:把所有可能存在的请求的值都存放在布隆过滤器中,当用户请求过来,我会先判断用户发来的请求的值是否存在于布隆过滤器中。不存在的话,直接返回请求参数错误信息给客户端,存在的话才会走下面的流程。总结一下就是下面这张图(这张图片不是我画的,为了省事直接在网上找的):
-
+
一般MySQL 默认的最大连接数在 150 左右,这个可以通过 `show variables like '%max_connections%'; `命令来查看。最大连接数一个还只是一个指标,cpu,内存,磁盘,网络等无力条件都是其运行指标,这些指标都会限制其并发能力!所以,一般 3000 个并发请求就能打死大部分数据库了。
@@ -322,7 +321,7 @@ public Object getObjectInclNullById(Integer id) {
**2)布隆过滤器:**布隆过滤器是一个非常神奇的数据结构,通过它我们可以非常方便地判断一个给定数据是否存在与海量数据中。我们需要的就是判断 key 是否合法,有没有感觉布隆过滤器就是我们想要找的那个“人”。具体是这样做的:把所有可能存在的请求的值都存放在布隆过滤器中,当用户请求过来,我会先判断用户发来的请求的值是否存在于布隆过滤器中。不存在的话,直接返回请求参数错误信息给客户端,存在的话才会走下面的流程。总结一下就是下面这张图(这张图片不是我画的,为了省事直接在网上找的):
- +
更多关于布隆过滤器的内容可以看我的这篇原创:[《不了解布隆过滤器?一文给你整的明明白白!》](https://github.com/Snailclimb/JavaGuide/blob/master/docs/dataStructures-algorithms/data-structure/bloom-filter.md) ,强烈推荐,个人感觉网上应该找不到总结的这么明明白白的文章了。
@@ -367,4 +366,4 @@ public Object getObjectInclNullById(Integer id) {
**Java工程师必备学习资源:** 一些Java工程师常用学习资源公众号后台回复关键字 **“1”** 即可免费无套路获取。
-
+
diff --git "a/docs/java/Java\347\226\221\351\232\276\347\202\271.md" "b/docs/java/Java\347\226\221\351\232\276\347\202\271.md"
index 1a10e9586ef98f05001784c6a35fcc59d301767f..bd5b00ddef4668d4213f2bc084bb590188cacf3b 100644
--- "a/docs/java/Java\347\226\221\351\232\276\347\202\271.md"
+++ "b/docs/java/Java\347\226\221\351\232\276\347\202\271.md"
@@ -132,7 +132,7 @@ System.out.println(n);// 1.255
注意:我们在使用BigDecimal时,为了防止精度丢失,推荐使用它的 **BigDecimal(String)** 构造方法来创建对象。《阿里巴巴Java开发手册》对这部分内容也有提到如下图所示。
-
+
### 1.3.5. 总结
@@ -367,7 +367,9 @@ s=list.toArray(new String[0]);//没有指定类型的话会报错
`java.util`包下面的所有的集合类都是fail-fast的,而`java.util.concurrent`包下面的所有的类都是fail-safe的。
-
+
+PR: CopyOnWriteArrayList 可以在foreach循环里进行元素的remove,实测确认。这个应该是跟CopyOnWriteArrayList自身的特点有关。因为CopyOnWriteArrayList对数据修改时是先生成一份快照,然后在快照上修改,再把快照上的值覆盖回去。
+CopyOnWriteArrayList反而是不能使用迭代器进行remove/add,直接抛UnsupportedOperationException的错。
+
更多关于布隆过滤器的内容可以看我的这篇原创:[《不了解布隆过滤器?一文给你整的明明白白!》](https://github.com/Snailclimb/JavaGuide/blob/master/docs/dataStructures-algorithms/data-structure/bloom-filter.md) ,强烈推荐,个人感觉网上应该找不到总结的这么明明白白的文章了。
@@ -367,4 +366,4 @@ public Object getObjectInclNullById(Integer id) {
**Java工程师必备学习资源:** 一些Java工程师常用学习资源公众号后台回复关键字 **“1”** 即可免费无套路获取。
-
+
diff --git "a/docs/java/Java\347\226\221\351\232\276\347\202\271.md" "b/docs/java/Java\347\226\221\351\232\276\347\202\271.md"
index 1a10e9586ef98f05001784c6a35fcc59d301767f..bd5b00ddef4668d4213f2bc084bb590188cacf3b 100644
--- "a/docs/java/Java\347\226\221\351\232\276\347\202\271.md"
+++ "b/docs/java/Java\347\226\221\351\232\276\347\202\271.md"
@@ -132,7 +132,7 @@ System.out.println(n);// 1.255
注意:我们在使用BigDecimal时,为了防止精度丢失,推荐使用它的 **BigDecimal(String)** 构造方法来创建对象。《阿里巴巴Java开发手册》对这部分内容也有提到如下图所示。
-
+
### 1.3.5. 总结
@@ -367,7 +367,9 @@ s=list.toArray(new String[0]);//没有指定类型的话会报错
`java.util`包下面的所有的集合类都是fail-fast的,而`java.util.concurrent`包下面的所有的类都是fail-safe的。
-
+
+PR: CopyOnWriteArrayList 可以在foreach循环里进行元素的remove,实测确认。这个应该是跟CopyOnWriteArrayList自身的特点有关。因为CopyOnWriteArrayList对数据修改时是先生成一份快照,然后在快照上修改,再把快照上的值覆盖回去。
+CopyOnWriteArrayList反而是不能使用迭代器进行remove/add,直接抛UnsupportedOperationException的错。