diff --git a/sig/T-One/README.en.md b/sig/T-One/README.en.md
index ebb6b43d2bd7592a53635a2209f4d8123939ba11..1131c472e4860dbce634c4b769945a22ae47e618 100644
--- a/sig/T-One/README.en.md
+++ b/sig/T-One/README.en.md
@@ -15,6 +15,8 @@ T-One:https://tone.openanolis.cn/
Testfarm:https://testfarm.openanolis.cn/
+Testlib:https://testlib.openanolis.cn/
+
## Members
| Member | Role |
| ------------ | ------------ |
@@ -46,7 +48,8 @@ Source code repositories:
- https://gitee.com/anolis/tone-deploy
- https://gitee.com/anolis/tone-cli
- https://gitee.com/anolis/tone-storage
-
+- https://gitee.com/anolis/testlib
+- https://gitee.com/anolis/python-tone-agent
## Meetings
@@ -54,4 +57,4 @@ Source code repositories:
欢迎使用钉钉扫码入群
-
\ No newline at end of file
+
diff --git a/sig/T-One/README.md b/sig/T-One/README.md
index 6162714a56e3247b46e0cbf66d6d8b06265badc5..b03448a127ac7cfda80c6b583b2065f091447a09 100644
--- a/sig/T-One/README.md
+++ b/sig/T-One/README.md
@@ -48,6 +48,7 @@ Source code repositories:
- https://gitee.com/anolis/tone-cli
- https://gitee.com/anolis/tone-storage
- https://gitee.com/anolis/testlib
+- https://gitee.com/anolis/python-tone-agent
## 小组例会
双周会,采用线上会议形式
diff --git "a/sig/T-One/content/SIG\344\276\213\344\274\232/SIG\344\276\213\344\274\232(2023-01-05).md" "b/sig/T-One/content/SIG\344\276\213\344\274\232/SIG\344\276\213\344\274\232(2023-01-05).md"
new file mode 100644
index 0000000000000000000000000000000000000000..992a9a0484f32b20ebbdfd6649112de7e761e8f9
--- /dev/null
+++ "b/sig/T-One/content/SIG\344\276\213\344\274\232/SIG\344\276\213\344\274\232(2023-01-05).md"
@@ -0,0 +1,17 @@
+# 会议主题
+测试平台T-One、测试管理系统TestLib进展
+# 会议时间
+2023.01.05 10:30-11:00
+# 参会人
+
+- 参会方:来自电子五所(赛宝实验室)和阿里云的社区爱好者
+- 参会人:yongchao、juexiao、VosAmoWho、zhizhisheng
+# 会议记要
+**T-One**
+
+- **T-One一键部署功能**:初步模型预计在下周发布。后续五所同学帮忙进行功能验证。
+- **T-One dashboard**:初始化的时候,dashboard显示空白
+- **ToneAgent**:python版本的ToneAgent发布前的测试。当前稳定版在ceprei分支
+
+**TestLib**
+- **TestLib采购指标功能完善**。已完成。
diff --git a/sig/TC/content/report/2022/2022.12.md b/sig/TC/content/report/2022/2022.12.md
new file mode 100644
index 0000000000000000000000000000000000000000..91eac217ff6fa499d76e84d41d0c820788d01d84
--- /dev/null
+++ b/sig/TC/content/report/2022/2022.12.md
@@ -0,0 +1,14 @@
+
+# 龙蜥社区技术委员会治理升级
+
+龙蜥社区技术委员会(TC)双周会在2022年12月9日顺利召开。近一年龙蜥社区又取得了很大进步,社区的发展步入快车道,为适应社区快速发展的需要,本次会议对社区技术委员会治理机制进行了升级。
+
+1、龙蜥社区技术委员会治理章程升级
+经技术委员、理事单位、社区合作伙伴伙伴积极提议,技术委员会多伦讨论和修改,通过了《龙蜥社区技术委员会章程》修订。本次修订兼顾社区治理效率、开放平等协作、生态发展繁荣等要素,升级了技术委员增补、退出、变更路径,并引入KOL、观察员角色,融合了龙蜥社区治理实践经验。感谢各位委员为社区发展做出大量积极贡献。
+
+2、技术委员会会议轮值机制常规化
+经过前期TC会议轮值试运营实践,社区总结了一套TC会议轮值机制,涵盖会前、会中、会后等环节。会议决策,TC会议轮值从试运营升级为常规运营。开源开放治理是龙蜥社区的基本运营理念之一,TC会议运营升级将进一步发挥各理事单位、合作伙伴的创造性,进一步提升社区开放治理水平。
+
+技术委员会将继续努力,推动龙蜥社区更高水平建设和发展。感谢各位技术委员、理事单位、合作伙伴为社区高水平治理建设做出持续不懈努力。
+
+
diff --git a/sig/high-perf-network-sig/README.md b/sig/high-perf-network-sig/README.md
index 6543dd6cf3c288a81f74ee985e7cac687456d507..a1dcc027142a66d8a94296c2722fa65838e89254 100644
--- a/sig/high-perf-network-sig/README.md
+++ b/sig/high-perf-network-sig/README.md
@@ -41,5 +41,5 @@ netdev@lists.openanolis.cn
搜索:34077273
或者扫描二维码:
-
+
diff --git a/sig/high-perf-network-sig/asserts/dingtalk.jpg b/sig/high-perf-network-sig/assets/dingtalk.jpg
similarity index 100%
rename from sig/high-perf-network-sig/asserts/dingtalk.jpg
rename to sig/high-perf-network-sig/assets/dingtalk.jpg
diff --git "a/sig/high-perf-network-sig/content/projects/SMC/1_\346\246\202\350\277\260.md" "b/sig/high-perf-network-sig/content/projects/SMC/1_\346\246\202\350\277\260.md"
new file mode 100644
index 0000000000000000000000000000000000000000..9df334d5c61cdfabb44896232f0f21fc603b5133
--- /dev/null
+++ "b/sig/high-perf-network-sig/content/projects/SMC/1_\346\246\202\350\277\260.md"
@@ -0,0 +1,7 @@
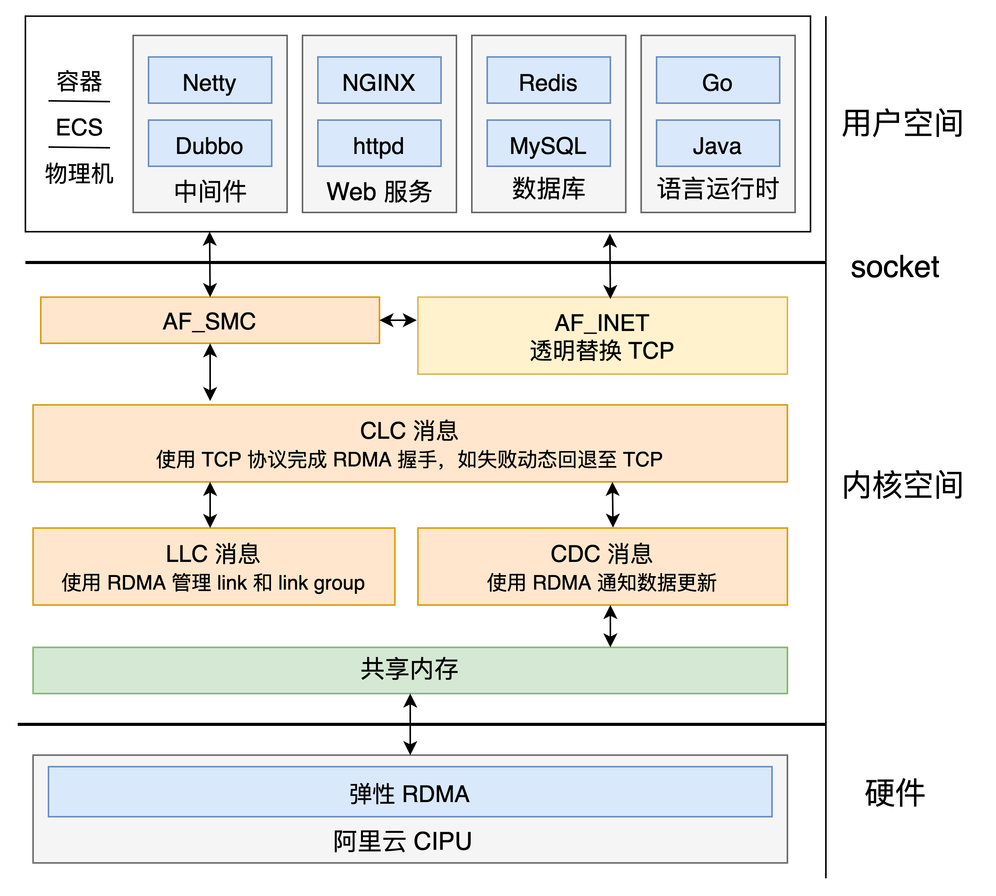
+共享内存通信(Shared Memory Communication,SMC)是一种兼容 socket 层,利用共享内存操作实现高性能通信的内核网络协议栈。当共享内存通信基于远程内存直接访问(Remote Direct Memory Access,RDMA)技术实现时,称为 SMC over RDMA(SMC-R)。
+
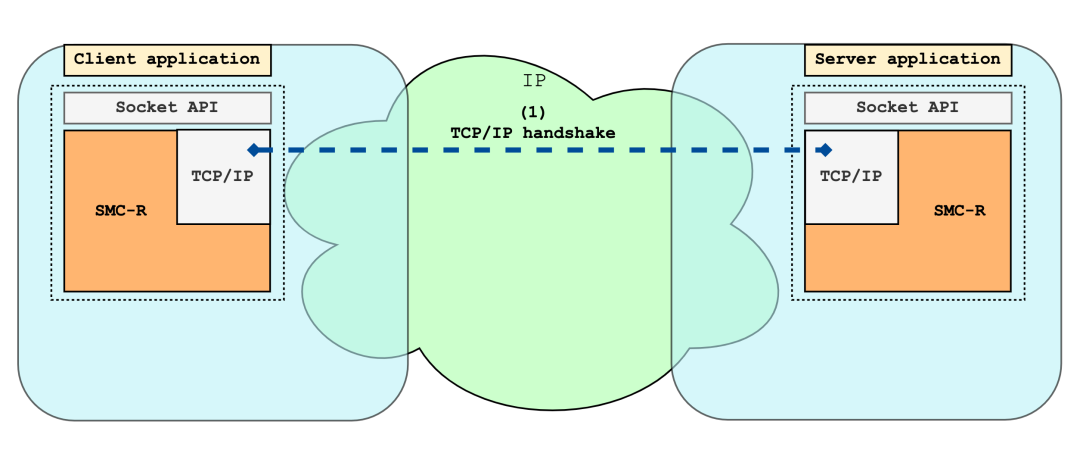
+SMC-R 兼容 socket 接口的特点使 TCP 应用程序无需任何改造即可运行在 SMC 协议栈上;底层使用的 RDMA 网络使 SMC 拥有相较于 TCP 更好的网络性能。SMC 协议栈通过 TCP 连接自主发现对侧 SMC 能力,协商成功后使用 SMC 协议栈承载应用数据流量;协商失败则安全回退至 TCP/IP 协议栈,保证数据正常传输。
+
+阿里云 Alibaba Cloud Linux 3 操作系统基于阿里云弹性 RDMA(elastic RDMA, eRDMA)技术首次将 SMC-R 带入云上场景,实现云上 TCP 协议栈的透明无损替换,为数据库、RPC、批量数据传输等场景提供相比 TCP 更好的网络性能。相较于上游 Linux SMC-R 实现,Alibaba Cloud Linux 3 中的 SMC-R 更适配阿里云 eRDMA 技术、拥有更好的性能、可靠的稳定性、丰富成熟的透明替换方案和及时的更新维护。
+
+
diff --git "a/sig/high-perf-network-sig/content/projects/SMC/2_\345\216\237\347\220\206\350\247\243\350\257\273-\346\212\200\346\234\257\346\217\255\347\247\230:\351\230\277\351\207\214\344\272\221\345\217\221\345\270\203\347\254\254\345\233\233\344\273\243\347\245\236\351\276\231.md" "b/sig/high-perf-network-sig/content/projects/SMC/2_\345\216\237\347\220\206\350\247\243\350\257\273-\346\212\200\346\234\257\346\217\255\347\247\230:\351\230\277\351\207\214\344\272\221\345\217\221\345\270\203\347\254\254\345\233\233\344\273\243\347\245\236\351\276\231.md"
new file mode 100644
index 0000000000000000000000000000000000000000..66d5f2092627324adaa2debcfd8e3fe3ca0518a1
--- /dev/null
+++ "b/sig/high-perf-network-sig/content/projects/SMC/2_\345\216\237\347\220\206\350\247\243\350\257\273-\346\212\200\346\234\257\346\217\255\347\247\230:\351\230\277\351\207\214\344\272\221\345\217\221\345\270\203\347\254\254\345\233\233\344\273\243\347\245\236\351\276\231.md"
@@ -0,0 +1,55 @@
+> 原文链接:[技术揭秘:阿里云发布第四代神龙 ,SMC-R 让网络性能提升 20%](https://mp.weixin.qq.com/s?__biz=MzUxNjE3MTcwMg==&mid=2247486197&idx=1&sn=e1b86ef6627dd13847b88e2ca367f890&chksm=f9aa382cceddb13a24c553451351aee1e0c026b0044403e0f6442e010df5e7303b07c4ce9912&scene=21#wechat_redirect)
+
+> 注:一年一度的云栖大会近日在杭州如约举行。今年的云栖大会上阿里云发布了第四代神龙架构,其中弹性 RDMA 加速能力尤其值得关注。基于弹性 RDMA,阿里云操作系统 Alibaba Cloud Linux 3 和龙蜥社区操作系统 Anolis OS 在网络方面基于社区 SMC-R 优化形成兼容 socket 的 RDMA 产品方案,旨在帮助云上应用无修改的享受 RDMA 带来的性能提升。本文将为您阐述 SMC-R 的产生背景、原理架构以及部分性能数据。
+
+近些年,随着云计算的飞速发展,特别是阿里云神龙、AWS Nitro 等硬件虚拟化方案的出现,云上的虚拟化网络性能有了质的飞跃。相比于云网络的欣欣向荣,CPU 的性能提升却似“挤牙膏”一般有些力不从心。因此,将部分原本由 CPU 承担的工作卸载到后端硬件的解决思路成为了云计算领域研究的一个“热点”。远程内存直接访问 (Remote Direct Memory Access, RDMA) 这项追求极致性能,曾经主要应用在高性能计算、高频交易等特定场景中的技术也因此进入了云厂商的数据中心。
+
+# 从 TCP 到 RDMA
+
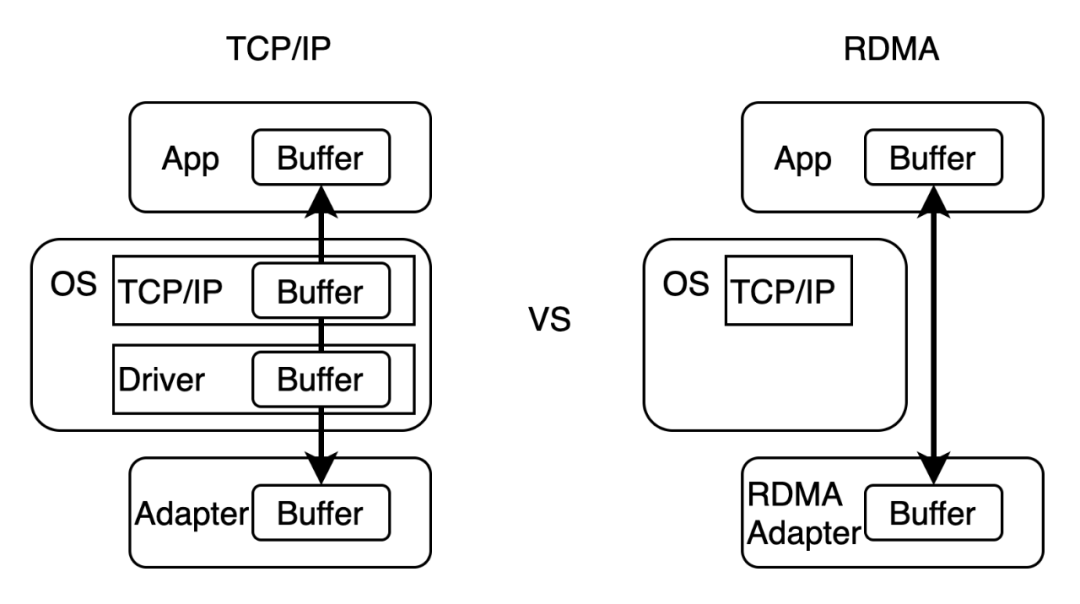
+RDMA 作为一种旁路内核的远程内存直接访问技术,被广泛应用于数据密集型和计算密集型场景中,是高性能计算、机器学习、数据中心、海量存储等领域的重要解决方案。RDMA 在阿里巴巴已大规模稳定运行多年,支撑了阿里云 ESSD、PolarDB 等核心业务,并在双十一等重大场景得到充分验证。
+RDMA 具有零拷贝、协议栈卸载的特点。RDMA 将协议栈的实现下沉至 RDMA 网卡 (RNIC),绕过内核直接访问远程内存中的数据。由于不经过系统内核协议栈,RDMA 与传统 TCP/IP 实现相比不仅节省了协议处理和数据拷贝所需的 CPU 资源,同时也提高了网络吞吐量、降低了网络通信时延。
+
+
+
+在过去,RDMA 只能在一些数据中心网络中通过网卡和交换机紧密配合使用,部署复杂度高。但如今,阿里云弹性 RDMA 将复杂的 RDMA 技术带到云上,使普通的 ECS 用户也能使用高性能的 RDMA 传输,无需关心底层复杂的网卡、交换机等物理网络环境配置,使其成为一种亲民、普惠的技术。
+
+# 从 verbs 到 socket
+
+不过,虽然 RDMA 性能优异,但是由于 RDMA 使用的 IB verbs 接口和常用的 POSIX socket 接口存在巨大的差异,普通应用要使用 RDMA 将面临着大量的业务改造,高效的将 RDMA 应用于现有业务存在较高的技术门槛。
+所以,历史上存在一些将 RDMA 的 IB verbs 语义封装成 socket 接口的尝试,典型如 rsocket、libvma。其中,libvma 通过 LD_PRELOAD 拦截 socket 接口,转而使用用户态 verbs 完成数据传输。但这些方案存在一些缺陷:由于转换发生在用户态,一方面缺少内核统一资源管理,另一方面在兼容性上也存在一些问题。
+从资源管理和兼容的角度上看,在内核中实现 socket 接口相比于用户态来说有着天然的优势。在 Alibaba Cloud Linux 3 和 Anolis OS 中,我们提供并优化了基于 RDMA 的共享内存通信 (**Shared Memory Communications over RDMA, SMC-R**) 技术,这是一次基于内核 RDMA 实现 TCP 应用兼容的尝试。
+原生的 SMC-R 支持标准 RoCE 网络,我们对其进行了扩展,首次实现对 iWARP 的支持,可以完美的支持阿里云自研的弹性 RDMA,从而实现云上应用**零修改**的享受 RDMA 带来的性能红利。
+
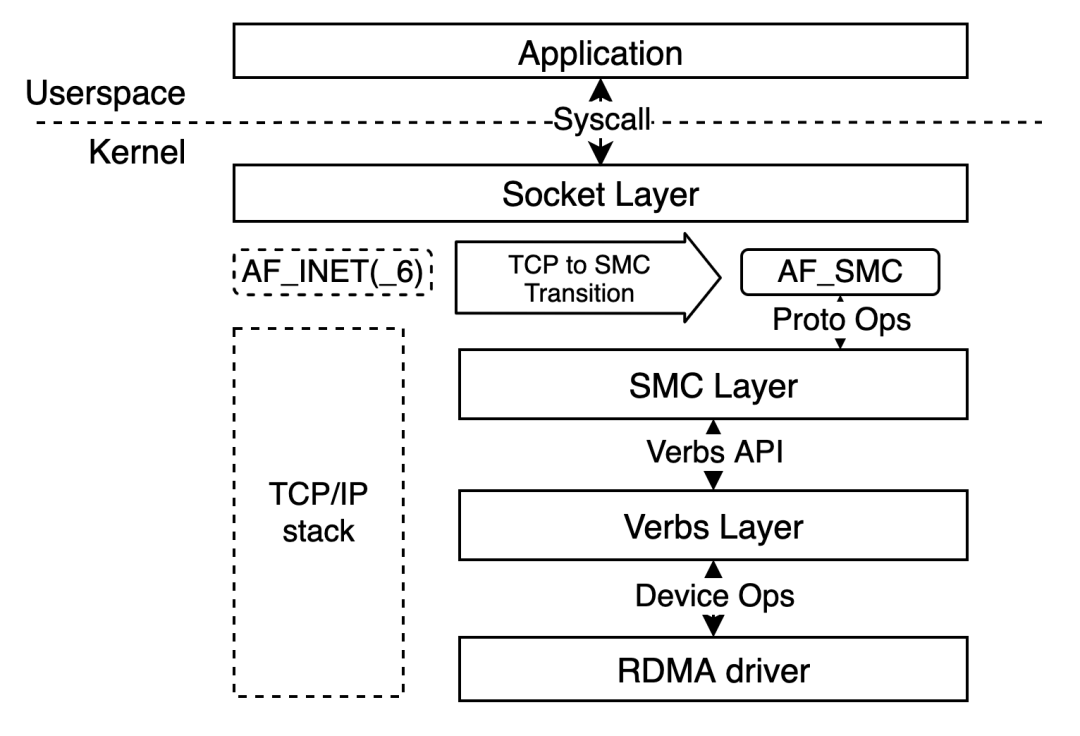
+# 兼备 socket 和 RDMA 的内核实现:SMC-R
+
+用一句话来描述,SMC-R 是一套与 TCP/IP 平行的**向上兼容 TCP socket 接口,底层使用 RDMA RC 进行数据传输的协议族。**
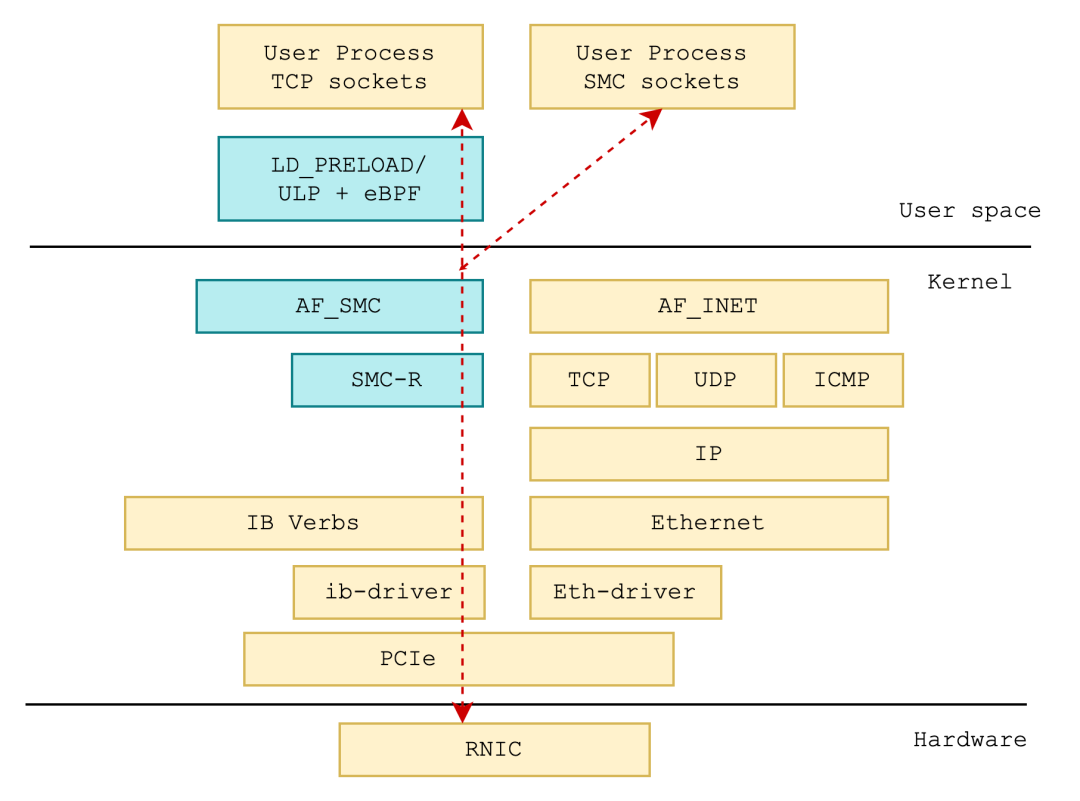
+SMC-R 工作于内核空间,处于 socket 层和内核 RDMA 的 IB verbs 层之间。SMC-R 像是一个能力卓越的翻译兼管家,它接收用户传达的 socket 指令,转而使用 RDMA 的 IB verbs 接口管理 RDMA 资源,完成底层基于 RDMA 的数据传输。所以,用户只需将原有 socket 接口使用的协议族从 AF_INET(6) 修改为 AF_SMC 即可完成从 TCP 协议栈到 SMC-R 协议栈的转变。
+但这还不够,我们希望在零修改的前提下完成协议替换。为此,Alibaba Cloud Linux 3 和 Anolis OS 在 socket 层增加协议族替换相关的 sysctl 和白名单,提供了 net namespace 和单个应用维度下的 TCP 至 SMC-R 协议栈透明替换能力,使应用**不需要任何修改**即可让数据在 RDMA 链路这条高速公路上飞驰起来。
+
+
+
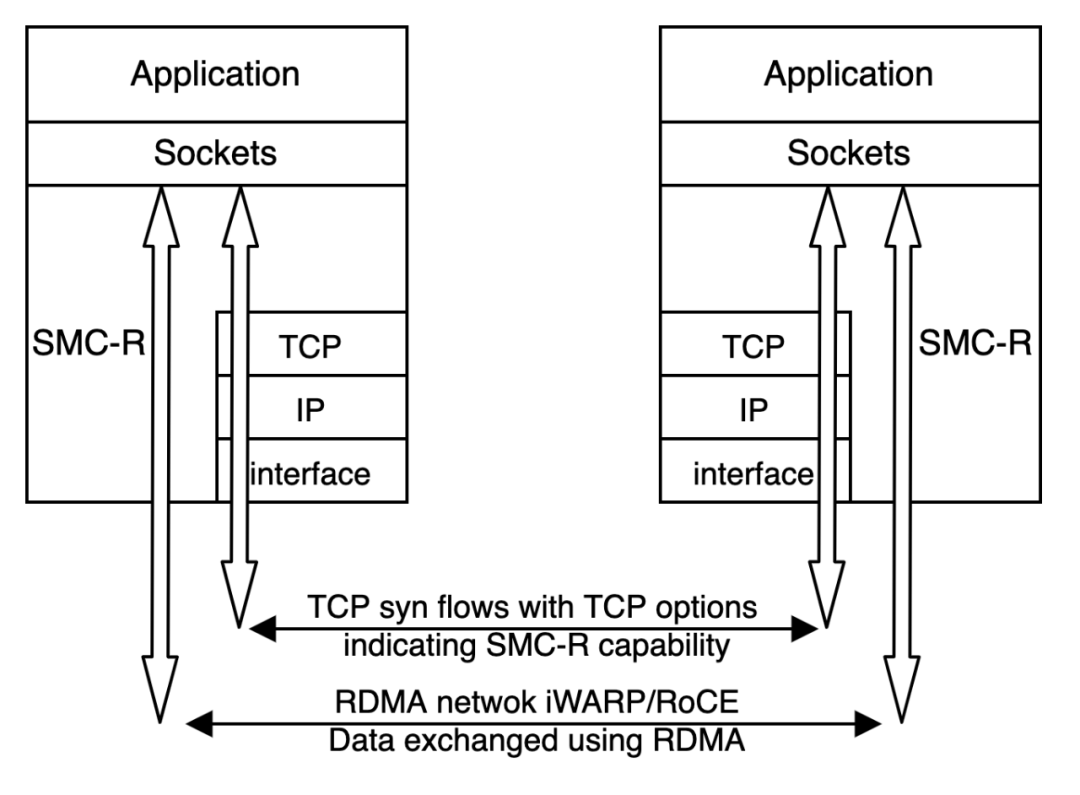
+然而,仅本地一厢情愿的使用 SMC-R 可不行,远端节点同样得具备 SMC-R 能力才能让高速公路有始有终。因此,SMC-R 具备**自动协商和安全回退 TCP** 的能力。
+SMC-R 建立 RDMA 链路时,首先会与通信对端建立 TCP 连接,双方在握手过程中通过特殊的 TCP 选项表明自身支持 SMC-R。协商成功后,SMC-R 将为用户态应用申请必要的 RDMA 资源,将接收数据缓冲区注册为可被远程节点直接访问的远程内存缓冲区 (Remote Memory Buffer, RMB),并将对应的访问密钥以及缓冲区起始地址封装成远程访问令牌 (RToken) 告知远程节点,作为其访问 RMB 的重要验证信息。
+特殊情况下,若在协商过程中发现收发两端其一不具备 RDMA 传输条件时,将触发安全回退机制。SMC-R 会使用协商过程中建立的 TCP 连接完成后续的数据传输,保证网络的可靠稳定。
+
+
+
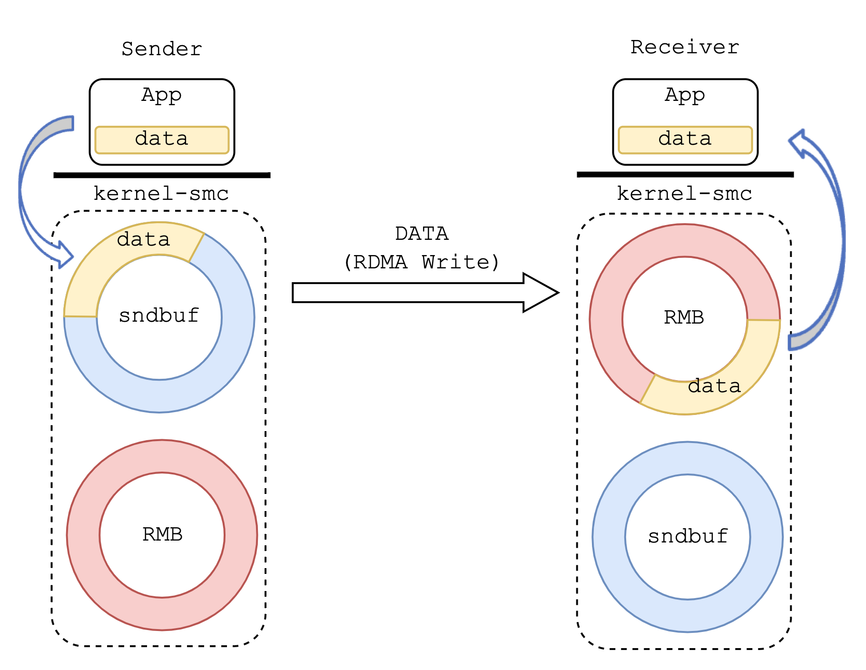
+数据传输的高速公路建立起来后,交通规则也要安排妥当。顾名思义,SMC-R 是一种通过 RDMA 实现共享内存的通信方式,**其将环形 RMB 作为共享内存**,配合数据游标实现高效的数据传输。
+SMC-R 使用 RDMA WRITE 单边操作的方式将网络应用传递至内核的数据直接、高效地写入远程节点环形 RMB 中。同时使用 RDMA SEND/RECV 双边操作的方式交互连接数据管理 (Connection Data Control, CDC) 消息,用于更新、同步 RMB 中的数据游标 (Cursor)。针对一侧 RMB,读者更新消费者游标 (Consumer Cursor),标识即将读取的下一字节地址。为避免数据丢失,写者不会将数据写入超过消费者游标的 RMB 空间中。相似的,写者更新生产者游标 (Producer Cursor),标识即将写入的下一字节地址。为确保数据的正确性,读者不会读取超过生产者游标的 RMB 空间中的内容。就这样,两个数据游标在环形 RMB 上你追我赶,贯穿网络数据传输的始终,确保传输的安全与可靠。
+
+
+
+最后,数据在高速公路上飞驰难免会遇到差错,为了保证一切都在掌控之中,Alibaba Cloud Linux 3 和 Anolis OS 为 SMC-R 提供了一系列监控诊断接口和工具,包括控制透明替换的 sysctl、查询 SMC-R socket 状态的 proc 文件、获取 SMC-R 各维度信息的 smc-tools 工具集等,以保障网络的可监控性和易运维性。
+通过上述架构概述和理论分析,SMC-R 展现了其兼容 socket 接口,透明替换 TCP,使用 RDMA 完成底层数据传输的能力。基于这些,我们终于可以总结出 SMC-R 的核心优势:
+
+### 高性能
+
+- 更轻薄的协议栈;
+- 使用 RDMA 进行通信,网络时延更低、CPU 占用更少、吞吐量更高;
+- 高效可靠的远程环形缓冲区直接访问。
+
+### 透明替换
+- 兼容 socket 接口的 RDMA 可靠流式传输;
+- 自动协议协商和安全回退 TCP 能力;
+- net namespace 和应用维度的协议栈无损透明替换;
+- 底层兼容弹性 RDMA iWARP 和标准 RoCE 网络。
diff --git "a/sig/high-perf-network-sig/content/projects/SMC/2_\345\216\237\347\220\206\350\247\243\350\257\273-\347\263\273\345\210\227\350\247\243\350\257\273_SMC-R_\344\270\200.md" "b/sig/high-perf-network-sig/content/projects/SMC/2_\345\216\237\347\220\206\350\247\243\350\257\273-\347\263\273\345\210\227\350\247\243\350\257\273_SMC-R_\344\270\200.md"
new file mode 100644
index 0000000000000000000000000000000000000000..50ea7d54074efff6191dc9cc688e1a81f180ee74
--- /dev/null
+++ "b/sig/high-perf-network-sig/content/projects/SMC/2_\345\216\237\347\220\206\350\247\243\350\257\273-\347\263\273\345\210\227\350\247\243\350\257\273_SMC-R_\344\270\200.md"
@@ -0,0 +1,252 @@
+> 原文链接:[系列解读SMC-R:透明无感提升云上 TCP 应用网络性能(一)| 龙蜥技术](https://mp.weixin.qq.com/s?search_click_id=2359972879487335624-1672728145437-6094177369&__biz=Mzg4MTMyMTUwMQ==&mid=2247493698&idx=1&sn=1f03ea3a9025ae0a461a7346cd75b3bd&chksm=cf651b30f812922698c49f95cedf18f4f83ed16d399800cda80e5d1188d64e8bd15b408f13ba&scene=0&subscene=10000&clicktime=1672728145&enterid=1672728145&sessionid=0&ascene=65&fasttmpl_type=0&fasttmpl_fullversion=6485008-zh_CN-zip&fasttmpl_flag=0&realreporttime=1672728145471#rd)
+
+# 引言
+
+Shared Memory Communication over RDMA (SMC-R) 是一种基于 RDMA 技术、兼容 socket 接口的内核网络协议,由 IBM 提出并在 2017 年贡献至 Linux 内核。SMC-R 能够帮助 TCP 网络应用程序透明使用 RDMA,获得高带宽、低时延的网络通信服务。
+
+由于 RDMA 技术在数据中心领域的广泛使用,龙蜥社区高性能网络 SIG 认为 SMC-R 将成为下一代数据中心内核协议栈的重要方向之一。为此,我们对其进行了大量的优化,并积极将这些优化回馈到上游 Linux 社区。目前,**龙蜥社区高性能网络 SIG 是除 IBM 以外最大的 SMC-R 代码贡献团体**。由于 SMC-R 相关中文资料极少,我们希望通过一系列文章,让更多的国内读者了解并接触 SMC-R,也欢迎有兴趣的读者加入龙蜥社区高性能网络 SIG 一起沟通交流。
+
+本篇作为系列文章的第一篇,将从宏观的角度带领读者初探 SMC-R。
+
+# 从 RDMA 谈起
+
+Shared Memory Communication over RDMA 的名称包含了 SMC-R 网络协议的一大特点——基于 RDMA。因此,在介绍 SMC-R 前我们先来看看这个高性能网络领域中的绝对主力:Remote Direct Memory Access (RDMA) 技术。
+
+### 1.1 为什么需要 RDMA ?
+
+随着数据中心、分布式系统、高性能计算领域的快速发展,网络设备性能进步显著,主流物理网络带宽已达到了 25-100 Gb/s,网络时延也进入了十微秒的时代。
+然而,**网络设备性能提升的同时一个问题也逐渐显露:网络性能与 CPU 算力逐渐失配**。传统网络中,负责网络报文封装、解析和用户态/内核态间数据搬运的 CPU 在高速增长的网络带宽面前逐渐显得力不从心,面临越来越大的压力。
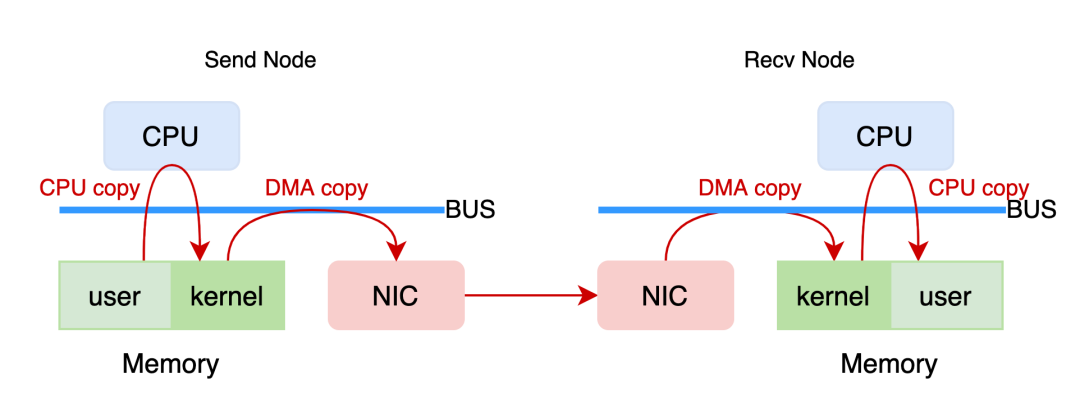
+以 TCP/IP 网络的一次数据发送与接收过程为例。发送节点 CPU 首先将数据从用户态内存拷贝至内核态内存,在内核态协议栈中完成数据包封装;再由 DMA 控制器将封装好的数据包搬运到 NIC 上发送到对端。接收端 NIC 获得数据包后通过 DMA 控制器搬运到内核态内存中,由内核协议栈解析,层层剥离帧首或包头后再由 CPU 将有效负载 (payload) 拷贝到用户态内存中,完成一次数据传输。
+
+
+
+在这一过程中,CPU 需要负责:
+- 用户态与内核态间的数据拷贝。
+- 网络报文的封装、解析工作。
+
+这些工作“重复低级”,占用了大量 CPU 资源 (如 100 Gb/s 的网卡跑到满带宽需要打满多个 CPU 核资源),使得 CPU 在数据密集型场景下无法将算力用到更有益的地方。
+所以,解决网络性能与 CPU 算力失配问题成为了高性能网络发展的关键。考虑到摩尔定律逐渐失效,CPU 性能短时间内发展缓慢,将网络数据处理工作从 CPU 卸载到硬件设备的思路就成为了主流解决方案。这使得以往专用于特定高性能领域的 RDMA 在通用场景下得到愈来愈多的应用。
+
+
+### 1.2 RDMA 的优势
+
+RDMA (Remote Direct Memory Access) 是一种远程内存直接访问技术,自提出以来经过 20 余年的发展已经成为了高性能网络的重要组成。那么 RDMA 是如何完成一次数据传输的呢?
+
+
+
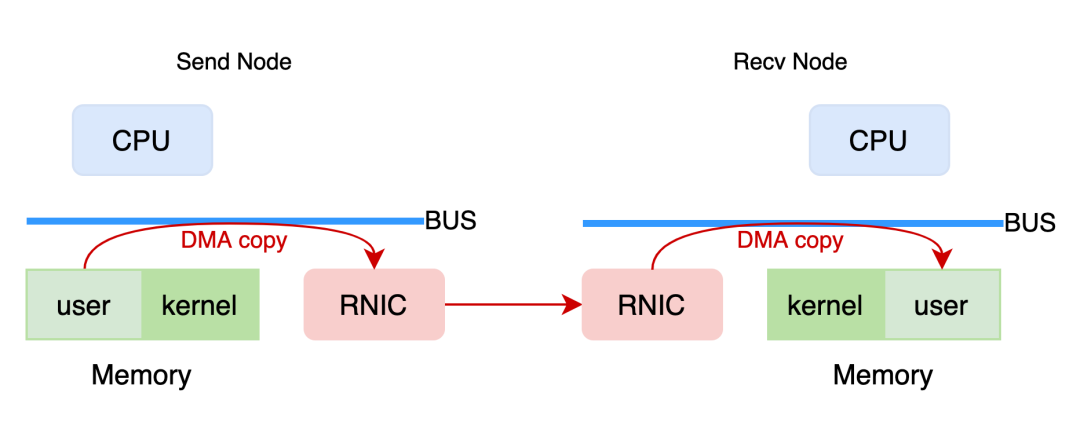
+RDMA 网络 (用户态模式) 中,具备 RDMA 能力的网卡 RNIC 直接从发送端用户态内存中取得数据,在网卡中完成数据封装后传输到接收端,再由接收端 RNIC 将数据解析剥离,将有效负载 (payload) 直接放入用户态内存中完成数据传输。
+这一过程中 CPU 除了必要的控制面功能外,几乎不用参与数据传输。数据就像是通过 RNIC 直接写入到远程节点的内存中一样。因此,与传统网络相比,RDMA 将 CPU 从网络传输中解放了出来,使得网络传输就像是远程内存直接访问一样方便快捷。
+
+
+
+对比传统网络协议,RDMA 网络协议具有以下三个特点:
+
+- 旁路软件协议栈
+
+RDMA 网络依赖 RNIC 在网卡内部完成数据包封装与解析,旁路了网络传输相关的软件协议栈。对于用户态应用程序,RDMA 网络的数据路径旁路了整个内核;对于内核应用程序,则旁路了内核中的部分协议栈。由于旁路了软件协议栈,将数据处理工作卸载到了硬件设备,因而 RDMA 能够有效降低网络时延。
+
+- CPU 卸载
+
+RDMA 网络中,CPU 仅负责控制面工作。数据路径上,有效负载由 RNIC 的 DMA 模块在应用缓冲区和网卡缓冲区中拷贝 (应用缓冲区提前注册,授权网卡访问的前提下),不再需要 CPU 参与数据搬运,因此可以降低网络传输中的 CPU 占用率。
+
+- 内存直接访问
+
+RDMA 网络中,RNIC 一旦获得远程内存的访问权限,即可直接向远程内存中写入或从远程内存中读出数据,不需要远程节点参与,非常适合大块数据传输。
+
+# 回到 SMC-R
+
+通过上述介绍,相信读者对 RDMA 主要特点以及性能优势有了初步的了解。不过,虽然 RDMA 技术能够带来可喜的网络性能提升,但是想使用 RDMA 透明提升现有 TCP 应用的网络性能仍有困难,这是因为 RDMA 网络的使用依赖一系列新的语义接口,包括 ibverbs 接口与 rdmacm 接口 (后统称 verbs 接口)。
+
+相较于传统 POSIX socket 接口,verbs 接口数量多,且更接近硬件语义。对于已有的基于 POSIX socket 接口实现的 TCP 网络应用,想要享受 RDMA 带来的性能红利就不得不对应用程序进行大量改造,成本巨大。
+因此,我们希望能够在使用 RDMA 网络的同时沿用 socket 接口,使现有 socket 应用程序透明的享受 RDMA 服务。针对这一需求,业界提出了以下两个方案:
+
+- 其一,是基于 libvma 的用户态方案
+libvma 的原理是通过 LD_PRELOAD 来将应用所有 socket 调用引入自定义实现,在自定义实现中调用 verbs 接口,完成数据收发。但是,由于实现在用户态,libvma 一方面缺少内核统一资源管理,另一方面对 socket 接口的兼容性较差。
+
+- 其二,是基于 SMC-R 的内核态方案
+作为内核态协议栈,SMC-R 对 TCP 应用的兼容性相较于用户态方案会好很多,这种 100% 兼容意味着极低的推广和复用成本。此外,实现在内核态使得 SMC-R 协议栈中的 RDMA 资源能够被用户态不同进程共享,提高资源利用率的同时降低频繁资源申请与释放的开销。不过,完全兼容 socket 接口就意味着需要牺牲极致的 RDMA 性能 (因为用户态 RDMA 程序可以做到数据路径旁路内核与零拷贝,而 SMC-R 为了兼容 socket 接口,无法实现零拷贝),但这也换来兼容与易用,以及对比 TCP 协议栈的透明性能提升。未来,我们还计划拓展接口,以牺牲小部分兼容性的代价将零拷贝特性应用于 SMC-R,使它的性能得到进一步改善。
+
+### 2.1 透明替换 TCP
+
+> SMC-R is an open sockets over RDMA protocol that provides transparent exploitation of RDMA (for TCP based applications) while preserving key functions and qualities of service from the TCP/IP ecosystem that enterprise level servers/network depend on!
+
+SMC-R 作为一套与 TCP/IP 协议平行,向上兼容 socket 接口,底层使用 RDMA 完成共享内存通信的内核协议栈,其设计意图是为 TCP 应用提供透明的 RDMA 服务,同时保留了 TCP/IP 生态系统中的关键功能。
+为此,SMC-R 在内核中定义了新的网络协议族 AF_SMC,其 proto_ops 与 TCP 行为完全一致。
+
+```
+/* must look like tcp */
+static const struct proto_ops smc_sock_ops = {
+ .family = PF_SMC,
+ .owner = THIS_MODULE,
+ .release = smc_release,
+ .bind = smc_bind,
+ .connect = smc_connect,
+ .socketpair = sock_no_socketpair,
+ .accept = smc_accept,
+ .getname = smc_getname,
+ .poll = smc_poll,
+ .ioctl = smc_ioctl,
+ .listen = smc_listen,
+ .shutdown = smc_shutdown,
+ .setsockopt = smc_setsockopt,
+ .getsockopt = smc_getsockopt,
+ .sendmsg = smc_sendmsg,
+ .recvmsg = smc_recvmsg,
+ .mmap = sock_no_mmap,
+ .sendpage = smc_sendpage,
+ .splice_read = smc_splice_read,
+};
+```
+
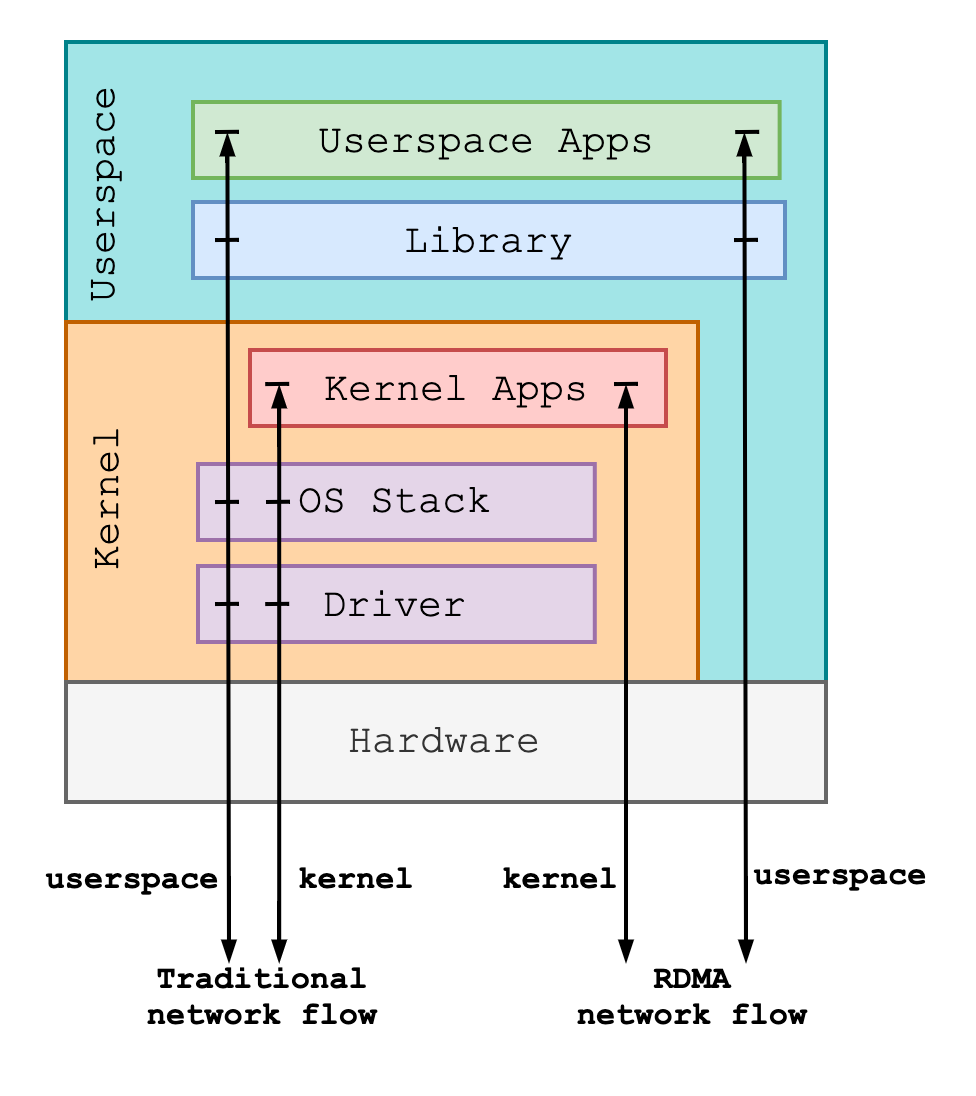
+由于 SMC-R 协议支持与 TCP 行为一致的 socket 接口,使用 SMC-R 协议非常简单。总体来说有两个方法:
+
+
+
+- 其一,使用 SMC-R 协议族 AF_SMC 开发
+通过创建 AF_SMC 类型的 socket,应用程序的流量将进入到 SMC-R 协议栈;
+- 其二,透明替换协议栈
+将应用程序创建的 TCP 类型 socket 透明替换为 SMC 类型 socket。**透明替换可以通过以下两种方式实现**:
+
+- 使用 LD_PRELOAD 实现协议栈透明替换。在运行 TCP 应用程序时预加载一个动态库。在动态库中实现自定义 socket() 函数,将 TCP 应用程序创建的 AF_INET 类型 socket 转换为 AF_SMC 类型的 socket,再调用标准 socket 创建流程,从而将 TCP 应用流量引入 SMC-R 协议栈。
+ ```
+int socket(int domain, int type, int protocol)
+{
+ int rc;
+
+ if (!dl_handle)
+ initialize();
+
+ /* check if socket is eligible for AF_SMC */
+ if ((domain == AF_INET || domain == AF_INET6) &&
+ // see kernel code, include/linux/net.h, SOCK_TYPE_MASK
+ (type & 0xf) == SOCK_STREAM &&
+ (protocol == IPPROTO_IP || protocol == IPPROTO_TCP)) {
+ dbg_msg(stderr, "libsmc-preload: map sock to AF_SMC\n");
+ if (domain == AF_INET)
+ protocol = SMCPROTO_SMC;
+ else /* AF_INET6 */
+ protocol = SMCPROTO_SMC6;
+
+ domain = AF_SMC;
+ }
+
+ rc = (*orig_socket)(domain, type, protocol);
+
+ return rc;
+}
+```
+开源用户态工具集 [smc-tools](https://github.com/ibm-s390-linux/smc-tools) 中的 smc_run 指令即实现上述功能。
+- 通过 ULP + eBPF 实现协议栈透明替换。SMC-R 支持 TCP ULP 是龙蜥社区高性能网络 SIG 贡献到上游 Linux 社区的新特性。用户可以通过 setsockopt() 指定新创建的 TCP 类型 socket 转换为 SMC 类型 socket。同时,为避免应用程序改造,用户可以通过 eBPF 在合适的 hook 点 (如 BPF_CGROUP_INET_SOCK_CREATE、BPF_CGROUP_INET4_BIND、BPF_CGROUP_INET6_BIND 等) 注入 setsockopt(),实现透明替换。这种方式更适合在容器场景下可以依据自定义规则,批量的完成协议转换。
+ ```
+static int smc_ulp_init(struct sock *sk)
+{
+ struct socket *tcp = sk->sk_socket;
+ struct net *net = sock_net(sk);
+ struct socket *smcsock;
+ int protocol, ret;
+
+ /* only TCP can be replaced */
+ if (tcp->type != SOCK_STREAM || sk->sk_protocol != IPPROTO_TCP ||
+ (sk->sk_family != AF_INET && sk->sk_family != AF_INET6))
+ return -ESOCKTNOSUPPORT;
+ /* don't handle wq now */
+ if (tcp->state != SS_UNCONNECTED || !tcp->file || tcp->wq.fasync_list)
+ return -ENOTCONN;
+
+ if (sk->sk_family == AF_INET)
+ protocol = SMCPROTO_SMC;
+ else
+ protocol = SMCPROTO_SMC6;
+
+ smcsock = sock_alloc();
+ if (!smcsock)
+ return -ENFILE;
+
+ <...>
+}
+```
+```
+ SEC("cgroup/connect4")
+int replace_to_smc(struct bpf_sock_addr *addr)
+{
+ int pid = bpf_get_current_pid_tgid() >> 32;
+ long ret;
+
+ /* use-defined rules/filters, such as pid, tcp src/dst address, etc...*/
+ if (pid != DESIRED_PID)
+ return 0;
+
+ <...>
+
+ ret = bpf_setsockopt(addr, SOL_TCP, TCP_ULP, "smc", sizeof("smc"));
+ if (ret) {
+ bpf_printk("replace TCP with SMC error: %ld\n", ret);
+ return 0;
+ }
+ return 0;
+}
+```
+综合上述介绍,TCP 应用程序**透明**使用 RDMA 服务可以体现在以下两个方面:
+- TCP 协议栈透明替换为 SMC-R 协议栈
+- 利用 SMC-R 协议栈透明使用 RDMA 技术
+
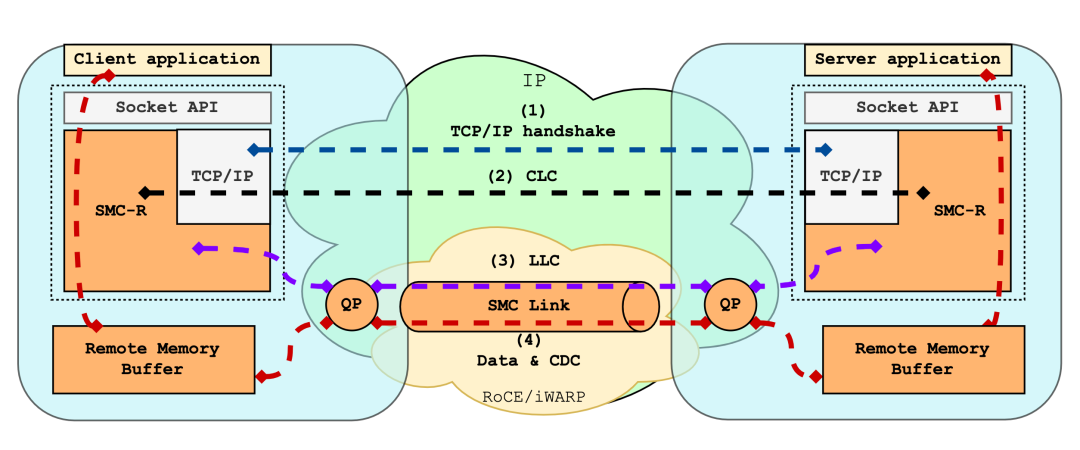
+### 2.2 SMC-R 架构
+
+
+
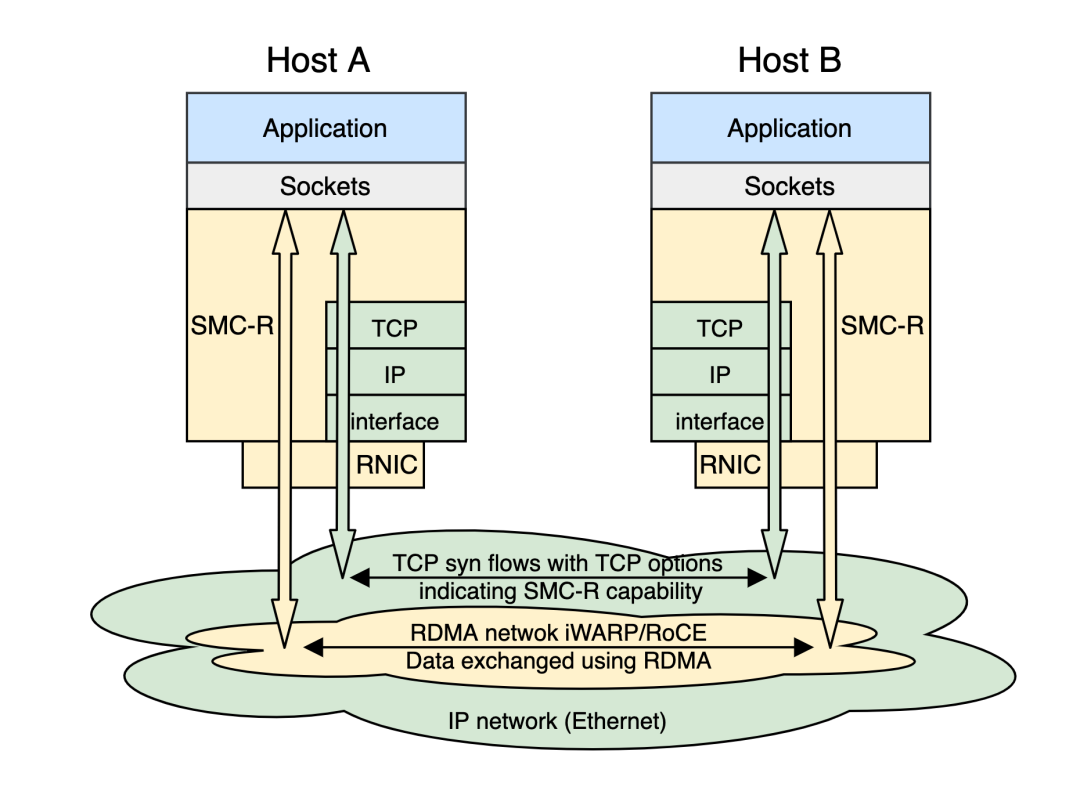
+SMC-R 协议栈在系统内部处于 socket 层以下,RDMA 内核 verbs 层以上。是一个具备 ***"hybrid"*** 特点的内核网络协议栈。这里的 ***"hybrid"*** 主要体现在 SMC-R 协议栈中混合了 RDMA 流与 TCP 流:
+
+#### 数据流量基于 RDMA 网络传输
+
+SMC-R 使用 RDMA 网络来传递用户态应用程序的数据,使应用程序透明的享受到 RDMA 带来的性能红利,即上图中黄色部分所示。
+发送端应用程序的数据流量通过 socket 接口从应用缓冲区来到内核内存空间;接着通过 RDMA 网络直接写入远程节点的一个内核态 ringbuf (remote memory buffer, RMB) 中;最后由远程节点 SMC-R 协议栈将数据从 RMB 拷贝到接收端应用缓冲区中。
+
+
+显然,SMC-R 名称中的共享内存通信指的就是基于远程节点 RMB 进行通信。与传统的本地共享内存通信相比,SMC-R 将通信两端拓展为了两个分离的节点,利用 RDMA 实现了基于“远程”共享内存的通信。
+
+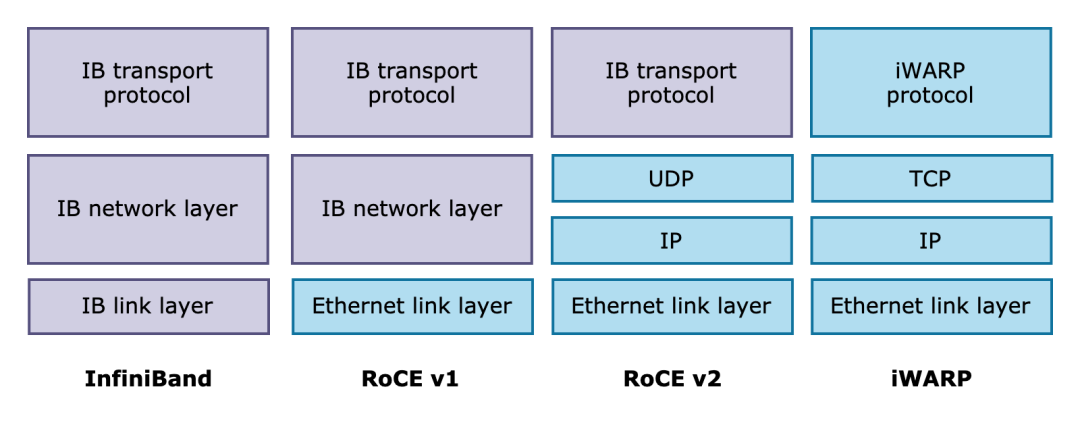
+
+目前,RDMA 网络的主流实现有三种:InfiniBand、RoCE 和 iWARP。其中,RoCE 作为在高性能与高成本中权衡的方案,在使用 RDMA 的同时兼容以太网协议,既保证了不错的网络性能,同时也降低了网络组建成本,因此倍受企业青睐,Linux 上游社区版本的 SMC-R 也因此使用 RoCE v1 和 v2 作为其 RDMA 实现。
+而 iWARP 则是基于 TCP 实现了 RDMA,突破了其余两者对无损网络的刚性需求。iWARP 具备更好的可拓展性,非常适用于云上场景。阿里云弹性 RDMA (eRDMA) 基于 iWARP 将 RDMA 技术带到云上。**阿里云操作系统 Alibaba Cloud Linux 3 与龙蜥社区开源操作系统 Anolis 8 中的 SMC-R 也进一步支持了 eRDMA (iWARP),使云上用户透明无感的使用 RDMA 网络。**
+
+#### 依赖 TCP 流建立连接
+
+除 RDMA 流外,SMC-R 还会为每个 SMC-R 连接配备一条 TCP 连接,两者具有相同的生命周期。TCP 流在 SMC-R 协议栈中主要担负以下职责:
+
+- 动态发现对端 SMC-R
+
+在 SMC-R 连接建立前,通信两端并不知道对端是否同样支持 SMC-R。因此,两端会首先建立一条 TCP 连接。在 TCP 连接三次握手的过程中通过发送携带特殊的 TCP 选项的 SYN 包表示支持 SMC-R,同时检验对端发送的 SYN 包中的 TCP 选项。
+
+
+- 回退
+
+若在上述过程中,通信两端其一无法支持 SMC-R 协议,或是在 SMC-R 连接建立过程中无法继续,则 SMC-R 协议栈将回退至 TCP 协议栈。回退过程中,SMC-R 协议栈将应用程序持有的文件描述符对应的 socket 替换为 TCP 连接的 socket。应用程序的流量将通过这条 TCP 连接承载,以保证数据传输不会中断。
+
+- 帮助建立 SMC-R 连接
+
+若通信两端均支持 SMC-R 协议,则将通过 TCP 连接交换 SMC-R 连接建立消息 (建连过程类似 SSL 握手)。此外,还需要使用此 TCP 连接交换两侧的 RDMA 资源信息,帮助建立用于数据传输的 RDMA 链路。
+
+
+通过上述介绍,相信读者对 SMC-R 总体架构有了初步的了解。SMC-R 作为一个 ***"hybrid"*** 解决方案,充分利用了 TCP 流的通用性和 RDMA 流的高性能。后面的文章中我们将对 SMC-R 中的一次完整通信过程进行分析,届时读者将进一步体会到 ***"hybrid"*** 这一特点。
+
+本篇作为 SMC-R 系列文章的首篇,希望能够起到一个引子的作用。回顾本篇,我们主要回答了这几个问题:
+
+- 为什么要基于 RDMA ?
+
+因为 RDMA 能够带来网络性能提升 (吞吐/时延/CPU占用率);
+
+- 为什么 RDMA 能够带来性能提升?
+
+因为旁路了大量软件协议栈,将 CPU 从网络传输过程中解放出来,使数据传输就像直接写入远程内存一样简单;
+
+- 为什么需要 SMC-R ?
+
+因为 RDMA 应用基于 verbs 接口实现,已有的 TCP socket 应用若想使用 RDMA 技术改造成本高;
+
+- SMC-R 有什么优势?
+
+SMC-R 完全兼容 socket 接口,模拟 TCP socket 接口行为。使 TCP 用户态应用程序能够透明使用 RDMA 服务,不做任何改造就可以享受 RDMA 带来的性能优势。
+
+- SMC-R 的架构特点?
+
+SMC-R 架构具有 ***"hybrid"*** 的特点,融合了 RDMA 流与 TCP 流。SMC-R 协议使用 RDMA 网络传输应用数据,使用 TCP 流确认对端 SMC-R 能力、帮助建立 RDMA 链路。
diff --git "a/sig/high-perf-network-sig/content/projects/SMC/2_\345\216\237\347\220\206\350\247\243\350\257\273-\347\263\273\345\210\227\350\247\243\350\257\273_SMC-R_\344\272\214.md" "b/sig/high-perf-network-sig/content/projects/SMC/2_\345\216\237\347\220\206\350\247\243\350\257\273-\347\263\273\345\210\227\350\247\243\350\257\273_SMC-R_\344\272\214.md"
new file mode 100644
index 0000000000000000000000000000000000000000..e347517b5031915482c23f12eca691972576749e
--- /dev/null
+++ "b/sig/high-perf-network-sig/content/projects/SMC/2_\345\216\237\347\220\206\350\247\243\350\257\273-\347\263\273\345\210\227\350\247\243\350\257\273_SMC-R_\344\272\214.md"
@@ -0,0 +1,186 @@
+> 原文链接:[系列解读 SMC-R (二):融合 TCP 与 RDMA 的 SMC-R 通信 | 龙蜥技术](https://mp.weixin.qq.com/s?search_click_id=2084229434777311559-1672728623690-5538769394&__biz=Mzg4MTMyMTUwMQ==&mid=2247494585&idx=1&sn=2d025e849833cdd3ecbe0b1754a32aef&chksm=cf6518cbf81291dd2653a014e00308e49ee257deee6545f6e82602c39963c74613c168b5e8a7&scene=0&subscene=10000&clicktime=1672728623&enterid=1672728623&sessionid=0&ascene=65&fasttmpl_type=0&fasttmpl_fullversion=6485008-zh_CN-zip&fasttmpl_flag=0&realreporttime=1672728623725&devicetype=android-29&version=28001759&nettype=WIFI&abtest_cookie=AAACAA%3D%3D&lang=zh_CN&exportkey=n_ChQIAhIQktJ6bQmIv3NiRYGRAbRosxLcAQIE97dBBAEAAAAAAMNdK7DEVIYAAAAOpnltbLcz9gKNyK89dVj0CrfxwLkASXQVVw99WBLScNOeEGq4CybsSRtMLlLXX5vSrnZi7CPSV6dwcBi%2Fq%2BETLKeRG7c4bSF%2FEPNBR80y3r3h0TSAUcw8wr1WX0WjCcS57xULJ2CFvkd%2BbavO%2FKPwMRWsSCyMneKPAd%2FPasjhI9D1fF0eVb9KKBxeuEFRIo%2FOBOydEAcuysGgtlerrjHqbwwno5Vd5qUne3Whv5%2BhgS%2FvR0DUXK212jj%2BpBm8aZDMEFnXv1M%3D&pass_ticket=LXS2YRVcmamkGMyhelL4ieilHzCrCcudro4S8I%2BudsxWwnZ7B5Mb8U1F8Q9vu59k3OVbQ8p4nfoHVEdr1Xcixw%3D%3D&wx_h)
+
+# 引言
+
+通过上一篇文章 [《系列解读 SMC-R (一):透明无感提升云上 TCP 应用网络性能》](https://openanolis.cn/sig/high-perf-network/doc/734387760257141914?)我们了解到,RDMA 相对于 TCP 具有旁路软件协议栈、卸载网络工作到硬件的特点,能有效增加网络带宽、降低网络时延与 CPU 负载。而内核网络协议 SMC-R 在利用 RDMA 技术的同时、又进一步完美兼容了 socket 接口,能够透明无感的为 TCP 应用带来网络性能提升。因此,龙蜥社区高性能网络 SIG 认为 SMC-R 将成为下一代数据中心内核协议的重要组成,对其进行了大量优化,并积极将这些优化回馈到上游 Linux 社区。
+
+本篇文章作为 SMC-R 系列的第二篇,将聚焦一次完整的 SMC-R 通信流程。通过具体的建连、传输、销毁过程,使读者进一步体会到 SMC-R 是一个融合了通用 TCP 与高性能 RDMA 的 ***"hybrid"*** 解决方案。
+
+# 通信流程
+
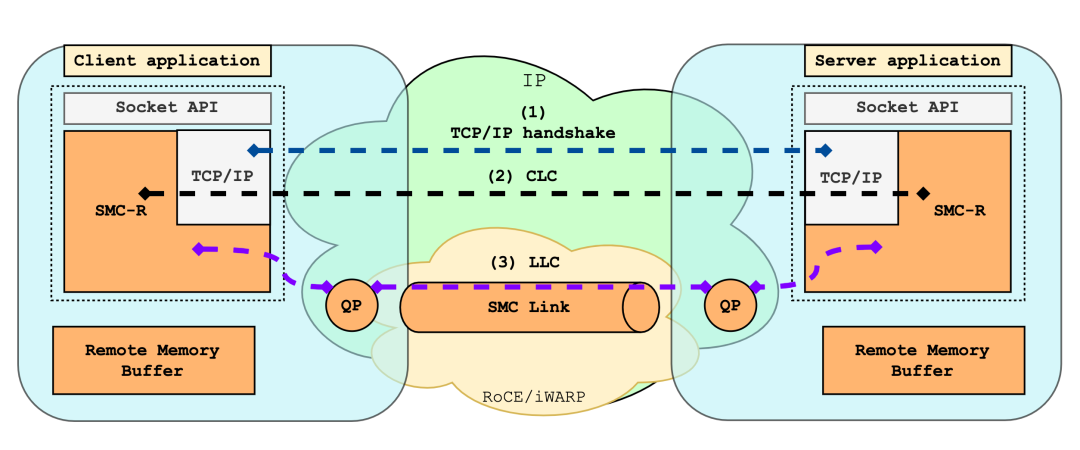
+如前篇所述,使用 SMC-R 协议有两种方法。其一,是在应用程序中显式创建 AF_SMC 族的 socket;其二,是利用 LD_PRELOAD 或 ULP + eBPF 的方式透明的将应用程序中的 AF_INET 族 socket 替换为 AF_SMC 族 socket。我们默认使用 SMC-R 通信的节点已经加载了 SMC 内核模块,并通过上述方式将应用程序运行在 SMC-R 协议上。接下来,**我们以 first contact (通信两端建立首个连接) 场景为例,介绍 SMC-R 通信流程。**
+
+
+### 2.1 确认对端能力
+
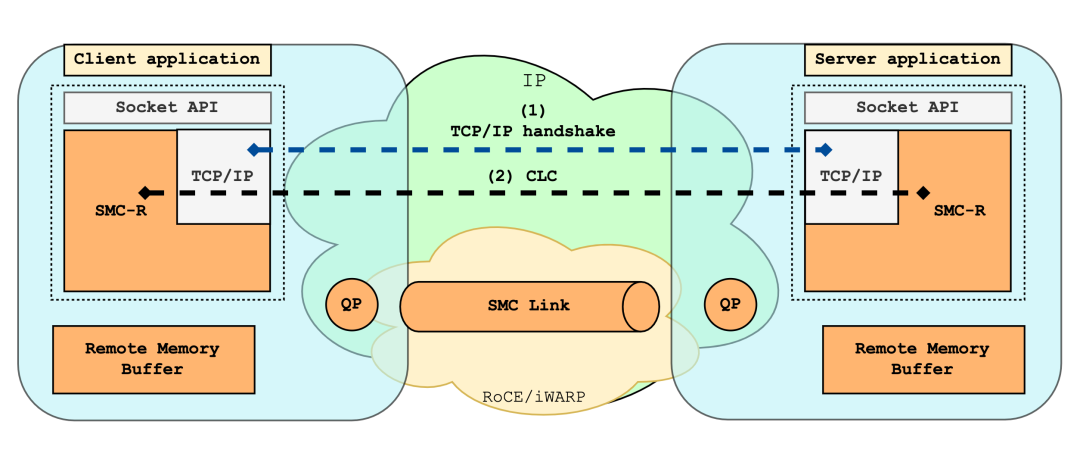
+使用 SMC-R 通信时,我们首先需要确认对端是否同样支持 SMC-R 协议。因此,SMC-R 协议栈为应用程序创建 SMC 类型 socket (smc socket) 的同时,还会在内核创建并维护一个与之关联的 TCP 类型 socket (clcsock),并基于 clcsock 与对端建立起 TCP 连接。
+
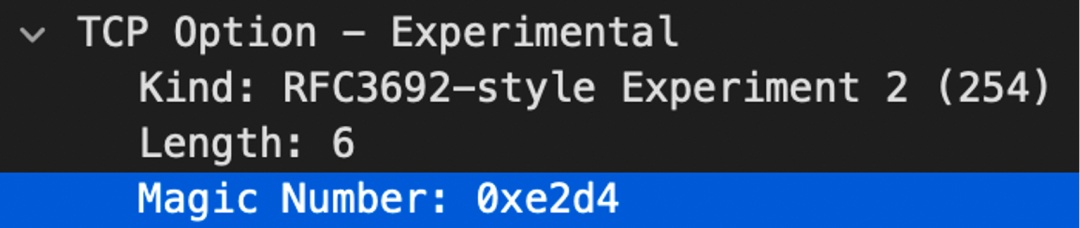
+
+
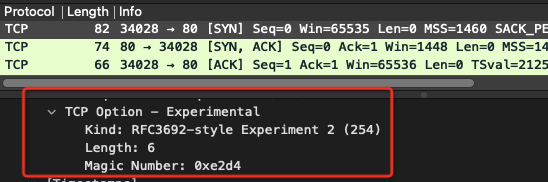
+在 TCP 连接三次握手中,使用 SMC-R 协议的一端发送的 SYN/ACK 中携带了特殊的 TCP 选项 (Kind = 254,Magic Number = 0xe2d4),用于表明自身支持 SMC-R。通过检查对端发送的 SYN/ACK,通信节点得知其 SMC-R 能力,进而决定是否继续使用 SMC-R 通信。
+
+
+
+
+
+### 2.2 协议回退
+
+若在上述 TCP 握手过程中,通信两端其一表示无法支持 SMC-R,则进入协议回退 (fallback) 流程。
+
+协议回退时,应用程序所持有的 fd 对应的 smc socket 将被替换为 clcsock。从此,应用程序将使用 TCP 协议通信,从而确保数据传输不会因为协议兼容问题而中断。
+
+需要注意的是,协议回退仅发生在通信协商过程中,如前文提到的 TCP 握手阶段,或是下文提到的 SMC-R 建连阶段。为便于跟踪诊断,SMC-R 协议详细分类了潜在的回退可能,用户可以通过用户态工具 smc-tools 观测到协议回退事件及原因。
+
+
+
+### 2.3 建立 SMC-R 连接
+
+若在 TCP 握手中,两端均表示支持 SMC-R,则进入 SMC-R 建连流程。SMC-R 连接的建立依赖 TCP 连接传递控制消息,这种控制消息被称为 Connection Layer Control (CLC) 消息。
+
+
+
+CLC 消息的主要职责是同步通信两端的 RDMA 资源以及共享内存等信息。使用 CLC 消息建立 SMC-R 连接的过程与 SSL 握手类似,主要包含 Proposal、Accept、Decline、Confirm 等语义。在建连过程中,若遇到不可恢复的异常 (如 RDMA 资源失效) 导致后续 SMC-R 通信无法继续,也将触发前文所述的协议回退流程。
+
+First contact 场景下,由于通信两端首次接触,两者间尚不存在使用 RDMA 通信的条件。所以,在建立首个 SMC-R 连接时,还将创建 SMC-R 通信所需的 RDMA 资源,建立 RDMA 链路,申请 RDMA 内存。
+
+
+
+#### 2.3.1 创建 RDMA 资源
+
+SMC-R 建连初期,两端根据应用程序传递的 IP 地址在本地寻找可用 (如相同 Pnet ID) 的 RDMA 设备,并基于找到的设备创建必要的 RDMA 资源,包括 Queue Pair (QP),Completion Queue (CQ),Memory Region (MR),Protect Domain (PD) 等等。
+
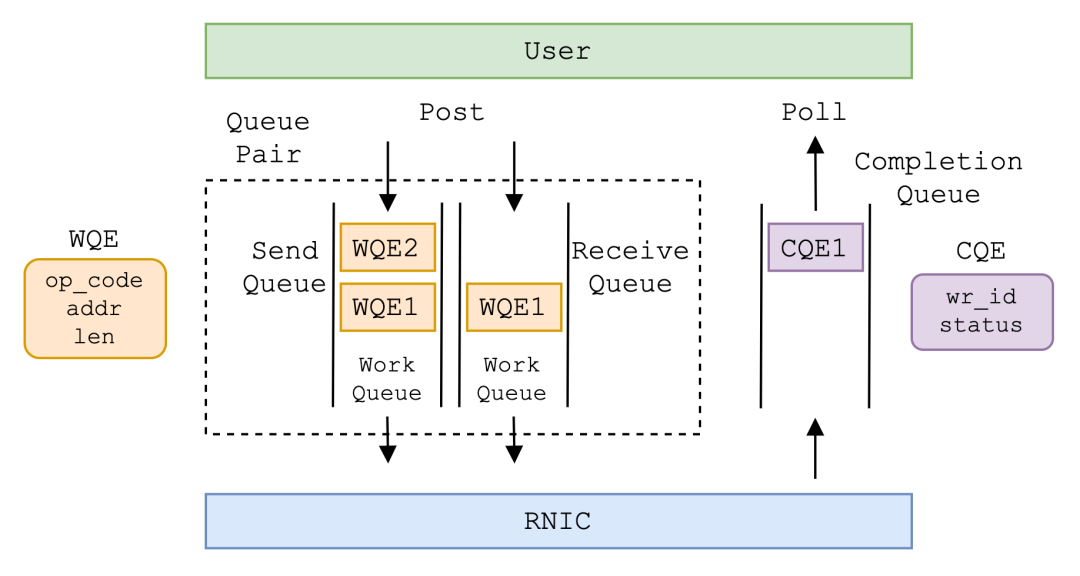
+其中,QP 与 CQ 是 RDMA 通信的基础,提供了一套 RDMA 使用者 (如 SMC 内核协议栈) 与 RDMA 设备 (RNIC) 之间的异步通信机制。
+
+QP 本质是存放工作任务 (Work Request, WR) 的工作队列 (Work Queue, WQ)。负责发送任务的 WQ 称为 Send Queue (SQ),负责接收任务的 WQ 称为 Receive Queue (RQ),两者总是成对出现,称为 QP。用户将希望 RNIC 完成的任务打包为工作队列元素 (Work Queue Element, WQE),post 到 QP 中。RNIC 从 QP 中取出 WQE,完成 WQE 中定义的工作。
+
+CQ 本质是存放工作完成信息 (Work Completion, WC) 的队列。RNIC 完成 WR 后,将完成信息打包为完成队列元素 (Completion Queue Element, CQE) 放入 CQ 中。用户从 CQ 中 poll 出 CQE,获悉 RNIC 已经完成某个 WR。
+
+
+
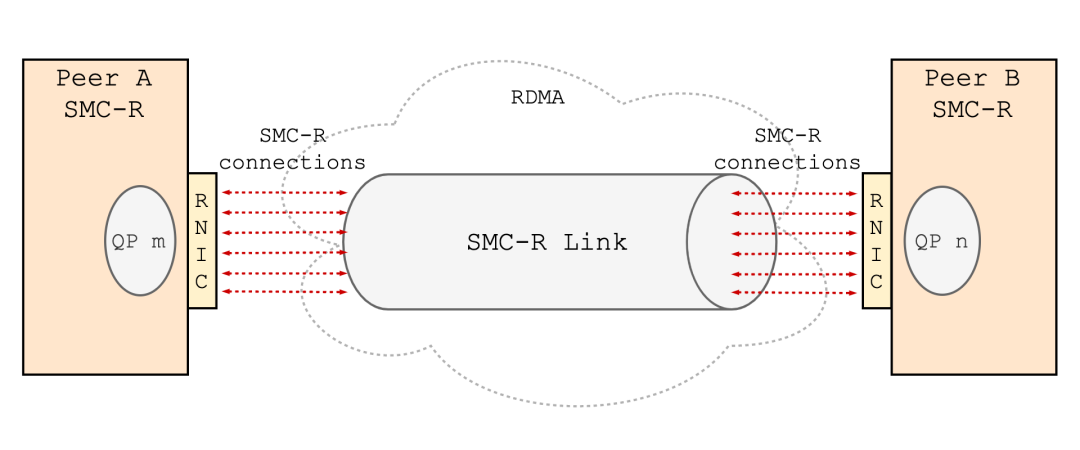
+#### 2.3.2 建立 RDMA 链路
+
+通信两端将已创建的 RDMA 资源通过 CLC 消息同步到对端,进而在两端之间建立起基于 RC (Reliable Connection) QP 的 RDMA 链路。SMC-R 中将这种点对点逻辑上的 RDMA 链路称为 SMC-R Link。一条 SMC-R Link 承载着多条 SMC-R 连接的数据流量。
+
+
+
+若通信节点之间存在不止一对可用的 RNIC,则会建立不止一条 Link。这些 Link 在逻辑上组成一个小组,称为 SMC-R Link Group。
+
+
+
+在 Linux 实现中,每个 Link Group 具备 1-3 条 Link,最多承载 255 条 SMC-R 连接。这些连接被均衡的关联到 Link Group 的某一 Link 上。应用程序通过 SMC-R 连接发送的数据将由关联的 Link (也即 RDMA 链路) 传输。
+
+同一个 Link Group 中,所有的 Link 互相“平等”。这个“平等”体现在同一 Link Group 中的 Link 具备访问 Group 中所有 SMC-R 连接收发缓冲区 (下文提到的 sndbuf 与 RMB) 的权限,具备承载任意 SMC-R 连接数据流的能力。因此,当某一 Link 失效时 (如 RNIC down),关联此 Link 的所有连接可以迁移到同 Link Group 的另一条 Link 上。这使得 SMC-R 通信稳定可靠,具备一定的容灾能力。
+
+SMC-R 中,Link (Group) 在 first contact 时创建,在最后一条 SMC-R 连接断开一段时间 (Linux 实现中为 10 mins) 后销毁,具备比连接更长的生命周期。First contact 之后创建的 SMC-R 连接都将尝试复用已有的 Link (Group)。这样的设计充分利用了已有的 RDMA 资源,避免了频繁创建与销毁带来的额外开销。
+
+#### 2.3.3 申请 RDMA 内存
+
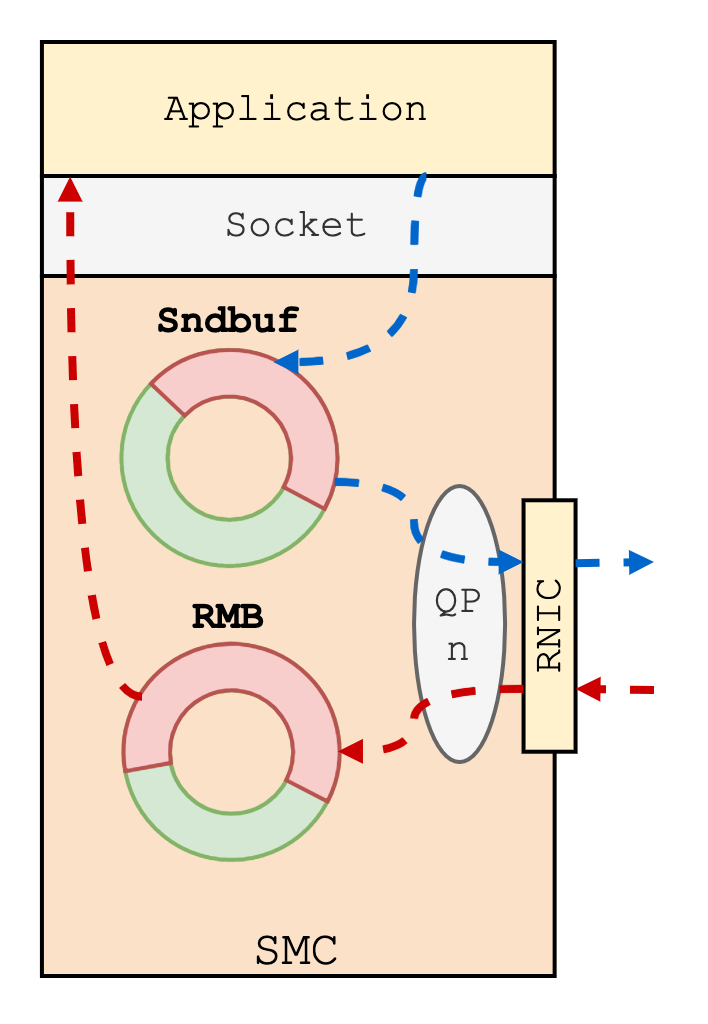
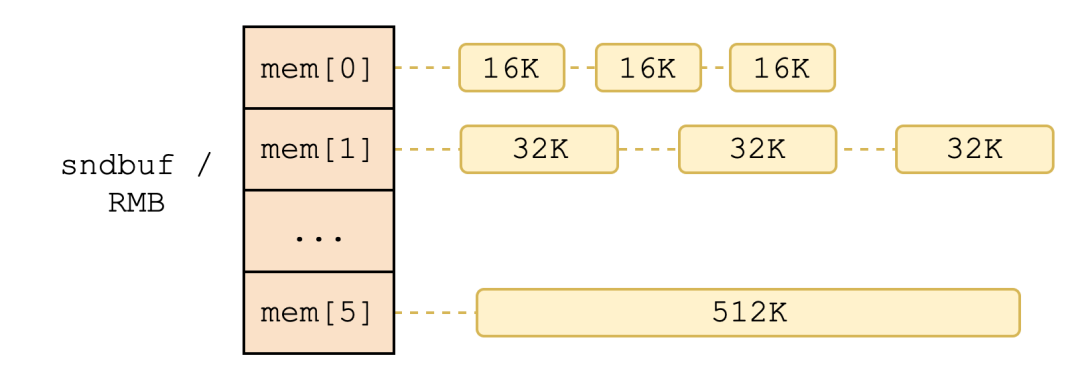
+SMC-R 协议栈为每条 SMC-R 连接分配了独属的收发缓冲区:sndbuf (发送缓冲区) 与 RMB (接收缓冲区,Remote Memory Buffer)。这是两片地址连续,长度在 16 KB ~ 512 KB 间的内核态 ring buffer。
+
+
+
+其中,sndbuf 用于存放连接待发送的数据,被注册为 DMA 内存。本地 RNIC 设备可以直接访问 sndbuf,从中取走有效负载 (payload)。而 RMB 用于存放远程节点 RNIC 写入的数据,即连接待接收的数据。由于需要被远程节点访问,因此 RMB 被注册为 RDMA 内存。
+
+注册 RDMA 内存的过程称为 Memory Registration,主要完成以下操作:
+
+- 生成地址翻译表
+
+RDMA 使用者 (如本地/远程 SMC-R 协议栈) 通常使用虚拟地址 (VA) 描述内存,而 RNIC 则通过物理地址 (PA) 寻址。RNIC 从 WQE 或数据包中取得数据 VA 后通过查表得到 PA,进而访问正确内存空间。因此 Memory Registration 首要任务就是形成目标内存的地址翻译表。
+
+- Pin 住内存
+
+现代 OS 会置换暂不使用的内存数据,这将导致地址翻译表中的映射关系失效。因此,Memory Registration 会将目标内存 pin 住,锁定 VA-to-PA 映射关系。
+
+- 限制内存访问权限
+
+为避免内存非法访问,Memory Registration 会为目标内存生成两把内存密钥:Local Key (l_key) 和 Remote Key (r_key)。内存密钥实质是一串序列,本地或远端凭借 l_key 或 r_key 访问 RDMA 内存,确保内存访问合法。
+
+SMC-R 中,远程节点访问本地 RMB 所需的 addr 与 r_key 被封装为远程访问令牌 (Remote Token, rtoken),通过 CLC 消息传递到远端,使其具备远程访问本地 RMB 的权限。
+
+SMC-R 连接销毁后,对应的 sndbuf 与 RMB 将被回收到 Link Group 维护的内存池中,供后续新连接复用,以此减小 RDMA 内存创建/销毁对建连性能的影响。
+
+
+
+### 2.4 验证 SMC-R Link
+
+由于 first contact 场景下新建立的 SMC-R Link 尚未经过验证,所以在正式使用 Link 传输应用数据前,通信两端会基于 Link 发送 Link Layer Control (LLC) 消息,用于检验 Link 是否可用。
+
+
+
+LLC 消息通常为请求-回复模式,用于传输 Link 层面的控制信息,如添加/删除/确认 Link,确认/删除 r_key 等。
+
+
+
+| 类型 | 说明 |
+|--------------|-----------------------------------------|
+| ADD_LINK | 向 Link Group 中添加新的 Link。 |
+| CONFIRM_LINK | 确认新创建的 Link 是否能够正常工作。 |
+| DELETE_LINK | 删除一个特定的 Link 或整个 Link Group。 |
+| CONFIRM_RKEY | 新增 RMB 时通知 Link 对端。 |
+| DELETE_RKEY | 删除一个或多个 RMB 时通知 Link 对端。 |
+| TEST_LINK | 确认 Link 是否健康、活跃。 |
+
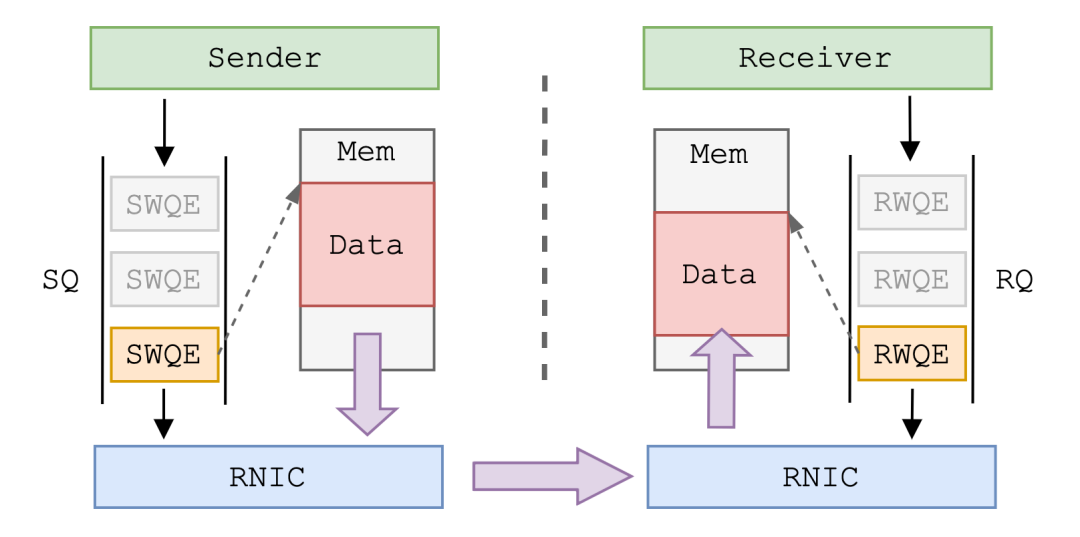
+LLC 消息的传输基于 RDMA 的 SEND 操作完成,与之相对的是后文提到的 RDMA WRITE 操作。
+
+
+
+SEND 操作又被称为“双边操作”,这是因为 SEND 操作要通信两端都参与进来。一次 SEND 的传输过程为:
+
+- 接收端 RDMA 使用者 (SMC-R 内核协议栈) 向本地 RQ 中 Post RWQE,RWQE 中记录了待接收数据的长度以及预留内存地址;
+
+- 发送端 RDMA 使用者 (SMC-R 内核协议栈) 向本地 SQ 中 Post SWQE,SWQE 中记录了待发送数据长度和内存地址。发送端 RNIC 根据 SWQE 记录的信息取出相应长度的数据发送到对端;
+
+- 接收端 RNIC 接收到数据后,取出 RQ 中的第一个 RWQE,依照其中记录的内存地址和长度存放数据;
+
+通过在 Link 上收发 CONFIRM_LINK 类型的 LLC 消息,通信两端确认了新创建的 Link 具备 RDMA 通信的能力,可以用于传输 SMC-R 连接数据。
+
+### 2.5 基于共享内存通信
+
+通过上述重重步骤,first contact 场景下 SMC-R 建连工作终于结束。接下来,应用程序将通过已建立好的 SMC-R 连接传输数据。
+
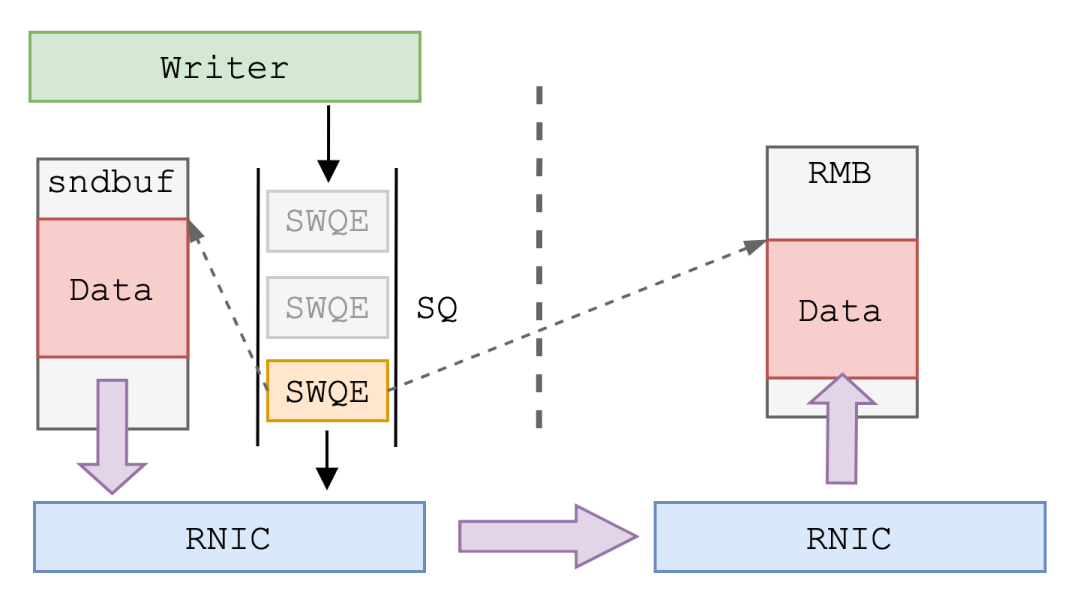
+
+
+应用程序下发到 SMC-R 连接中的数据由关联的 Link 通过 RDMA WRITE 操作写入远程节点 RMB 中。
+
+
+
+与上文提到的 SEND 操作不同,RDMA WRITE 又被称为“单边操作”。这是因为数据传输只有 RDMA WRITE 发起的一方参与,而接收数据一方的 RDMA 使用者完全不参与数据传输,也不知晓数据的到来。一次 RDMA WRITE 操作过程如下:
+
+- 前期准备阶段,接收端 RDMA 使用者 (SMC-R 内核协议栈) 将接收缓冲区注册为 RDMA 内存,将远程访问密钥 rkey 告知发送端,使其拥有直接访问接收端内存的权限,这个过程我们在前文介绍过。
+
+- 发送端 RDMA 使用者 (SMC-R 内核协议栈) 向 SQ 中 post SWQE。与 SEND 不同的是,RDMA WRITE 的 SWQE 中不仅包含数据在本地的内存地址和长度,还包含数据即将存放在接收端的内存地址,以及访问接收端内存所需的 r_key。发送端 RNIC 根据 SWQE 中记录的信息将数据传输到接收端。
+
+- 接收端 RNIC 核实数据包中的 r_key,将数据存放到指定内存地址中。此时的接收端 RDMA 使用者并不知道数据已经被写入内存。
+
+由于 RDMA WRITE 操作不需要接收端 RDMA 使用者参与,因此非常适合大量数据的直接写入。不过,由于接收端并不知晓数据到来,发送端写入数据后需要通过 SEND 操作发送控制消息通知接收端。在 SMC-R 中,这种控制消息称为 Connection Data Control (CDC) 消息。CDC 消息中包含 RMB 相关控制信息用以同步数据读写。
+
+| 内容 | 含义 |
+|----------------------------|-----------------------------------|
+| Sequence number | CDC 消息序列号 |
+| Alert token | 发送此消息的 SMC-R 连接 ID |
+| Producer cursor | RMB 数据生产游标 (写者更新) |
+| Producer cursor wrap seqno | RMB 数据生产 wrap 次数 (写者更新) |
+| Consumer cursor wrap seqno | RMB 数据消费wrap 次数 (读者更新) |
+| Consumer cursor | RMB 数据消费 游标 (读者更新) |
+
+在系列文章的第一篇中我们提到,SMC-R 名称中的“共享内存”指的是接收端的 RMB。结合上述的 RDMA WRITE 操作与 CDC 消息,SMC-R 的共享内存通信流程可以总结为:
+
+
+
+ - 发送端的数据通过 socket 接口,由应用缓冲区拷贝至内核 sndbuf 中 (图中未画出 sndbuf)
+ - 协议栈通过 RDMA WRITE 单边操作将数据写入接收端 RMB 中
+ - 发送端通过 SEND 双边操作发送 CDC 消息告知接收端有新的数据到来
+ - 接收端从 RMB 中拷贝数据至应用缓冲区
+ - 接收端通过 SEND 双边操作发送 CDC 消息告知发送端 RMB 中部分数据已被使用
+
+### 2.6 连接关闭与资源销毁
+
+结束数据传输后,主动关闭方发起 SMC-R 连接关闭流程。与 TCP 相似,SMC-R 连接也存在半关闭/全关闭状态。断开的 SMC-R 连接与 Link (Group) 解绑,相关的 sndbuf 与 RMB 也将被回收到内存池中,等待复用。同时,与 SMC-R 连接关联的 TCP 连接也进入关闭流程,最终释放。
+
+若 Link (Group) 中不再存在活跃的 SMC-R 连接,则等待一段时间后 (Linux 实现中为 10 mins) 进入Link (Group) 销毁流程。销毁 Link (Group) 将释放与之相关的所有 RDMA 资源,包括 QP、CQ、PD、MR、以及所有的 sndbuf 与 RMB。Link (Group) 销毁后,再次创建 SMC-R 连接则需要重新经历 first contact 流程。
+
+# 总结
+
+本篇作为 SMC-R 系列文章的第二篇,以 first contact 场景为例,介绍了完整的 SMC-R 通信流程。包括:通过 TCP 握手确认对端 SMC-R 能力;使用 TCP 连接传递 CLC 消息,交换 RDMA 资源、创建 RDMA 链路、建立 SMC-R 连接;通过 RDMA SEND 操作发送 LLC 消息验证 Link 可用;基于 Link 使用 RDMA WRITE 传输应用程序数据,并利用 CDC 消息同步 RMB 中数据变化;关闭 SMC-R、TCP 连接,销毁 RDMA 资源等一系列过程。
+
+上述过程充分体现了 SMC-R 的 **"hybrid"** 特点。SMC-R 既利用了 TCP 的通用性 ,如通过 TCP 连接确认对端能力,建立 SMC-R 连接与 RDMA 链路;又利用了 RDMA 的高性能 ,如通过 Link 传输应用程序数据流量。正因为如此,SMC-R 能够在兼容现有 TCP/IP 生态系统关键功能的同时为 TCP 应用提供透明无感的网络性能提升。
diff --git "a/sig/high-perf-network-sig/content/projects/SMC/3_\346\200\247\350\203\275\345\261\225\347\244\272-redis\345\222\214nginx\346\200\247\350\203\275\345\261\225\347\244\272.md" "b/sig/high-perf-network-sig/content/projects/SMC/3_\346\200\247\350\203\275\345\261\225\347\244\272-redis\345\222\214nginx\346\200\247\350\203\275\345\261\225\347\244\272.md"
new file mode 100644
index 0000000000000000000000000000000000000000..3c8c07c1acb27d002281a222f2bde02e5e7bdd2d
--- /dev/null
+++ "b/sig/high-perf-network-sig/content/projects/SMC/3_\346\200\247\350\203\275\345\261\225\347\244\272-redis\345\222\214nginx\346\200\247\350\203\275\345\261\225\347\244\272.md"
@@ -0,0 +1,140 @@
+作为在 RDMA/eRDMA 场景下对 TCP 应用透明无损替换的技术,SMC 同样也继承了 RDMA 技术的天然优势,在内存数据库、RPC、数据中心内部等场景相比 TCP 能提供更好的网络性能,包括但不限于更低的访问时延,更高的吞吐上限以及更低的 CPU 开销等。考虑到 SMC 兼容 socket 接口的特性,能够快速运行 SMC 的应用很多,因此有极其丰富的相对应的计算性能的测试工具。在本项基础性能测试中,我们选择了两台都是16vCPU 32G内存,基于ecs.c7re.4xlarge规格的添加了ERDMA网卡的阿里云ECS实例。
+
+## 软件版本
+
+- ERDMA 驱动版本:kernel driver version: 0.2.29
+- Kernel:5.10.134
+- wrk 版本:wrk [epoll]
+- nginx 版本:nginx version: nginx/1.20.1
+- redis 版本: redis-server v6.0.5
+- maven 版本:Apache Maven 3.4.5 (Red Hat 3.4.5-5.1)
+
+## 机器规格
+
+
+
+为了能够对 SMC 技术进行深入的了解,本次评测将常见应用的基础性能工具进行评测,包括
+
+1. 经典 microbenchmark
+2. 标准业务应用
+3. 数据库等基础设施
+
+本次测试包括时延测试,吞吐测试和CPU开销测试三个部分。看看 SMC 技术是如何在透明替换中保持ERDMA技术的性能收益。
+
+## Redis 应用性能
+
+作为高性能的内存数据库的代表,与复杂的传统数据库不同,包括主从同步在内的Redis的处理性能很大程度上会受到网络性能的制约,这里这里我们
+使用 经典的 Redis测试工具 redis-benchmark 来测试验证SMC-R的性能。测试脚本如下:
+
+```
+#server script
+redis-server --save '' --appendonly no --protected-mode no --daemonize yes
+```
+
+```
+#client script
+redis-benchmark -h ${serverAddress} -q -n $requests -c $connections -d $size -t GET,SET --thread ${threads}
+```
+
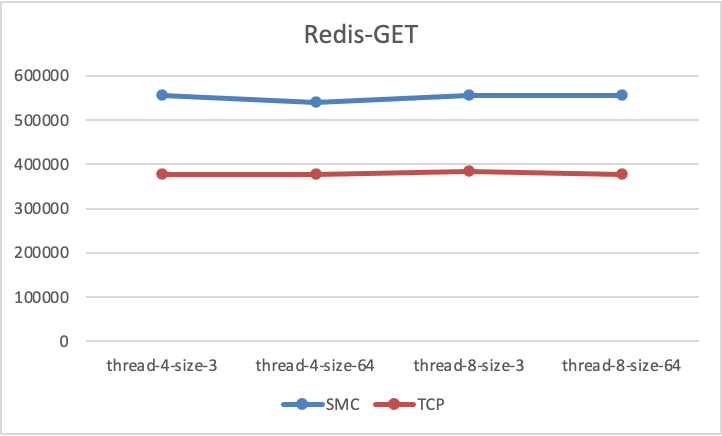
+### 吞吐收益
+
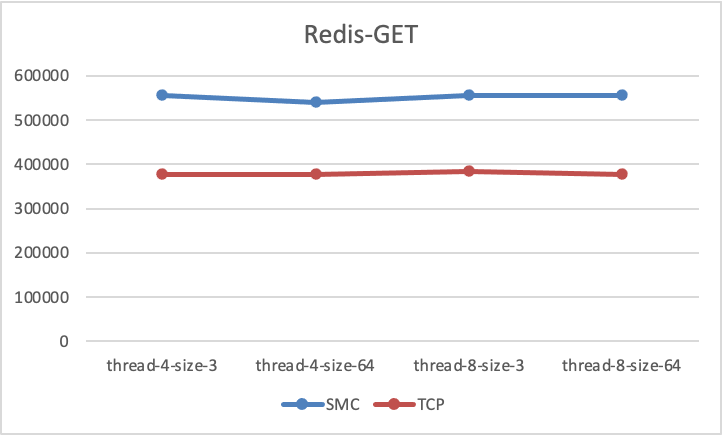
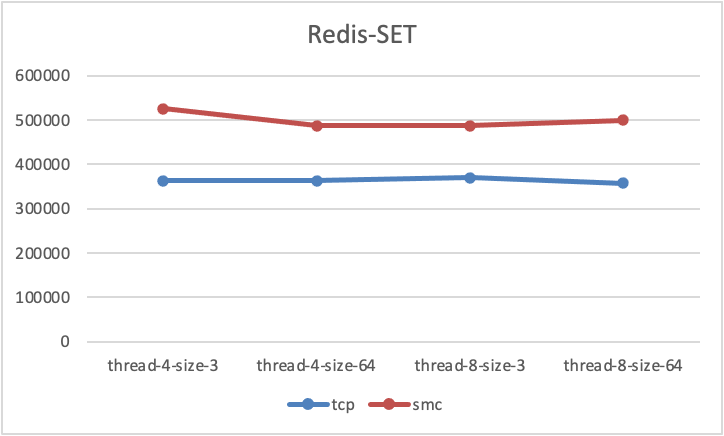
+在针对Redis的性能测试,这里我们使用了 redis-benmark下的 GET/SET 测试模型,对redis数据性能进行了多次测试,稳定的测试结果如下:
+
+
+
+
+
+从测试结果可以看出,无论是GET测试还是SET测试,SMC-R相对于TCP都带来了至少40%+的性能测试数据提升.
+但如果CPU开销也额外花费了40%,数据就没有显著意义了,因此CPU开销也是及其重要的数据,接下来我们将在同样的测试条件下对SMC-R和TCP的CPU开销数据进行对比。
+
+### CPU 开销
+
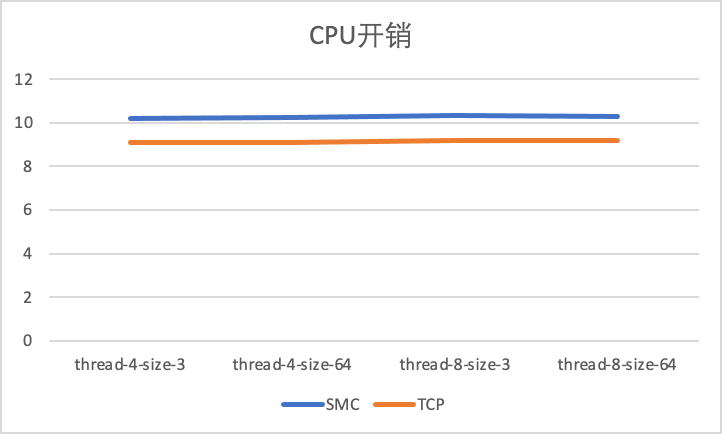
+
+
+从测试结果可以看出,SMC-R相对于TCP花费了额外的11%左右的CPU开销,这主要是因为显著的提升了吞吐导致用户态处理CPU增多导致的(吞吐提升了40%+)。
+另一方面,因为ERDMA提供的协议栈卸载和内核bypass能力,它允许应用程序直接通过目标主机内的内存空间进行数据传输,具有ERDMA能力的以太网卡负责将保证他们之间连接的可靠性。
+因此能够做到在大幅提高吞吐收益的同时,可以做到低CPU开销。
+
+## Nginx 应用性能
+
+nginx作为一个高性能的HTTP和反向代理服务器,在国内外被广泛应用,对于HTTP服务器来说,最重要的莫过于其响应请求的延时和处理请求的能力。
+这里我们将基于 经典的wrk/nginx测试模型 来快速验证 SMC 的性能。测试脚本如下:
+
+```
+#nginx server config
+
+user nginx;
+worker_processes auto;
+error_log /var/log/nginx/error.log;
+worker_rlimit_nofile 10240;
+pid /run/nginx.pid;
+
+# Load dynamic modules. See /usr/share/doc/nginx/README.dynamic.
+include /usr/share/nginx/modules/*.conf;
+
+events {
+ worker_connections 10240;
+}
+
+http {
+ log_format main '$remote_addr - $remote_user [$time_local] "$request" '
+ '$status $body_bytes_sent "$http_referer" '
+ '"$http_user_agent" "$http_x_forwarded_for"';
+
+ access_log off;
+
+ sendfile off;
+ tcp_nopush on;
+ tcp_nodelay on;
+ keepalive_timeout 300s;
+ keepalive_requests 1000000;
+ types_hash_max_size 4096;
+
+ include /etc/nginx/mime.types;
+ default_type application/octet-stream;
+
+ # Load modular configuration files from the /etc/nginx/conf.d directory.
+ # See http://nginx.org/en/docs/ngx_core_module.html#include
+ # for more information.
+ include /etc/nginx/conf.d/*.conf;
+
+ open_file_cache max=10240000 inactive=60s;
+ open_file_cache_valid 80s;
+ open_file_cache_min_uses 1;
+
+ server {
+ listen 80 backlog=1024;
+ server_name _;
+ root /usr/share/nginx/html;
+ }
+}
+```
+
+```
+#client script
+wrk http://${server}/${path} -t${thread} -c{connection} -d30
+```
+
+对于大多数RPC应用,响应时延的重要性毋庸置疑,这直接影响到了用户能够感受到的真实时间。因此在Nginx测试中,我们重点额外引入了时延维度,接下来我们将通过一组数据来观察,SMC-R能否相对于TCP减少数据延迟,我们拭目以待。特别的,这里测试全部打满了CPU,因此CPU开销情况没有单独列出。
+
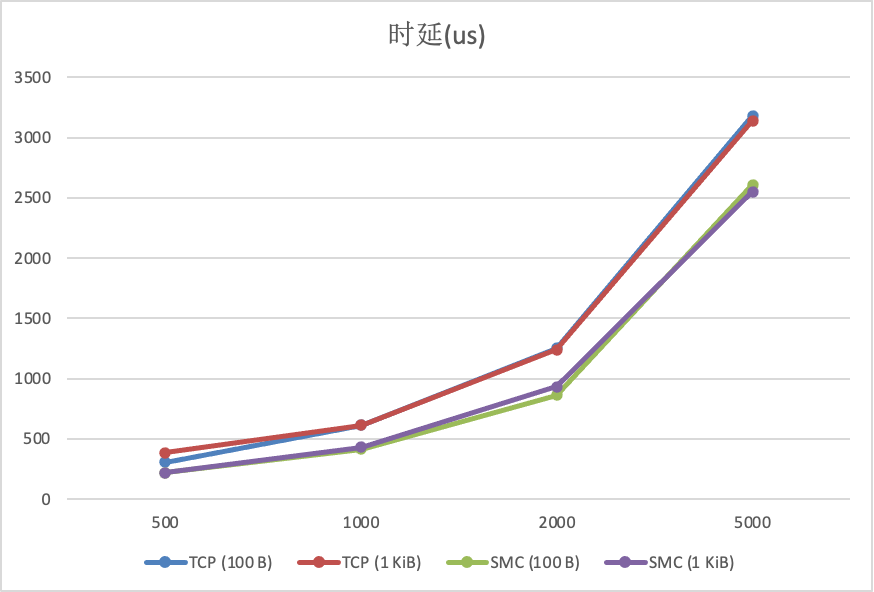
+### 时延收益
+
+这里展示了在不同文件大小,不同线程数以及不同连接数下的时延数据情况:
+
+
+
+我们可以看到,SMC-R在优化请求的时延上也有显著收益,在不同请求数据大小下,相对于TCP减少了20%到40%左右的时延,受益于ERDMA快速的协议栈处理和更短的数据路径,显著的时延收益也不足为奇了。
+因此,即使您的RPC应用不太关心吞吐的收益,SMC-R也可以帮助你在优化请求的时延上大做文章,在不需要任何代码改动的情况下,便可以使用SMC-R来获得收益。
+
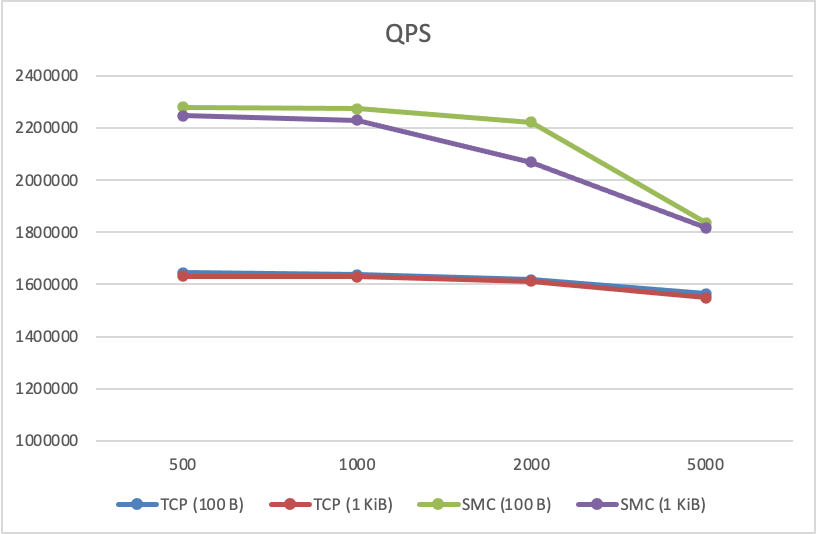
+### 吞吐收益
+
+
+
+同样的,在Nginx测试中,测试的吞吐数据也同样有显著提升。如上图所示,在不同测试参数下,相对于TCP,SMC-R可以带来21%到37.6%的吞吐提升。
+
+## 结论
+
+受益于 SMC 在内核中无损透明替换的语义,SMC 兼容 socket 接口的特点使 TCP 应用程序无需任何改造即可运行在 SMC 协议栈上;底层使用的 eRDMA 网络使 SMC 拥有相较于 TCP 更好的网络性能。SMC 协议栈通过 TCP 连接自主发现对侧 SMC 能力,协商成功后使用 SMC 协议栈承载应用数据流量;协商失败则安全回退至 TCP/IP 协议栈,保证数据正常传输。阿里云 Alibaba Cloud Linux 3 操作系统基于阿里云弹性 RDMA(elastic RDMA, eRDMA)技术首次将 SMC-R 带入云上场景,实现云上 TCP 协议栈的透明无损替换,为数据库、RPC、批量数据传输等场景提供相比 TCP 更好的网络性能。相较于上游 Linux SMC-R 实现,Alibaba Cloud Linux 3 中的 SMC-R 更适配阿里云 eRDMA 技术、拥有更好的性能、可靠的稳定性、丰富成熟的透明替换方案和及时的更新维护;在这些场景中,我们可以观测到
+
+- 平均20%的延迟收益;
+- 最大40+的每CPU吞吐收益,在合适的场景中甚至可以达到50%+。
diff --git "a/sig/high-perf-network-sig/content/projects/SMC/4_\344\275\277\347\224\250\350\257\264\346\230\216-\344\275\277\347\224\250\346\214\207\345\215\227.md" "b/sig/high-perf-network-sig/content/projects/SMC/4_\344\275\277\347\224\250\350\257\264\346\230\216-\344\275\277\347\224\250\346\214\207\345\215\227.md"
new file mode 100644
index 0000000000000000000000000000000000000000..b40a89a07feb8832b33b4dab9ebc5eefcba2e4ca
--- /dev/null
+++ "b/sig/high-perf-network-sig/content/projects/SMC/4_\344\275\277\347\224\250\350\257\264\346\230\216-\344\275\277\347\224\250\346\214\207\345\215\227.md"
@@ -0,0 +1,351 @@
+Alibaba Cloud Linux 3 提供的共享内存通信(Shared Memory Communication,SMC)是一种兼容 socket 层,使用硬件卸载的共享内存技术实现的高性能内核网络协议栈。SMC 支持基于 RDMA 卸载的内存共享技术 SMC over RDMA,简称 SMC-R。
+
+SMC-R 由 IBM 于 2017 年开源至 Linux 4.11 并持续维护至今,其协议标准可参考 RFC 7609。阿里云 Alibaba Cloud Linux 3 操作系统基于阿里云弹性 RDMA(elastic RDMA,eRDMA)技术首次将 SMC-R 带上云上场景,实现对 TCP 应用透明无损的替换,提供高性能、普惠的硬件卸载网络。
+
+本文将介绍 SMC-R 及其使用方法。
+
+# 一、背景介绍
+
+SMC 基于共享内存的数据交互模型依赖 RDMA 提供的内存操作原语。
+
+RDMA 技术将网络协议栈下沉至 RDMA 网卡 (RNIC) 实现,使网络节点能够绕过内核直接访问远程内存。与传统 TCP 网络相比,RDMA 网络减少了数据在内存间拷贝的次数,降低了网络传输过程中消耗的 CPU 资源,进而提高了网络吞吐、降低了网络时延。
+
+
+
+因此,RDMA 被广泛应用于数据密集型和计算密集型场景中,是高性能计算、机器学习、数据中心、海量存储等领域的重要解决方案。
+
+过去,RDMA 只能在一些数据中心网络中通过网卡和交换机紧密配合使用,部署复杂度高。如今,阿里云弹性 RDMA 将复杂的 RDMA 技术带到云上,使普通的 ECS 用户也能使用高性能的 RDMA 传输,无需关心底层复杂的网卡、交换机等物理网络环境配置,使其成为一种亲民、普惠的技术。
+
+但是,由于 RDMA 技术基于 IB verbs 接口,相较于常用的 POSIX socket 接口存在巨大的差异。现有 socket 应用程序迁移至 RDMA 网络往往面临着大量的改造,使用 RDMA 技术仍存在较高的技术门槛。
+
+于是,为了充分挖掘弹性 RDMA 的潜力,为云上用户提供更好的网络性能,Alibaba Cloud Linux 3 与龙蜥社区 Anolis OS 提供并优化了 SMC-R。在高效使用 RDMA 技术的同时,保留对标准 TCP 应用的兼容,使更多的应用无需做任何修改便能享受 RDMA 所带来的性能红利。
+
+# 二、核心优势
+
+## 1. 高性能
+
+得益于 RDMA 技术将网络协议栈从内核卸载至硬件网卡,SMC-R 相较于传统 TCP 协议栈在合适场景下可获得更低的时延、更高的吞吐量,以及更小的 CPU 负载。
+
+- 硬件卸载;
+- 更低的网络时延、更高的吞吐、更少的 CPU 占用率;
+- 高效可靠的远程内存直接访问;
+
+## 2. 透明替换
+
+得益于 SMC-R 对 POSIX socket 接口的兼容以及协议栈透明替换能力,socket 应用程序可以在无修改的情况下完成 TCP 协议栈到 SMC-R 协议栈的切换,无需额外的应用改造或开发成本。
+
+- 兼容 socket 接口的共享内存通信;
+- 多维度协议栈无损透明替换;
+- 自动协议协商和安全回退机制;
+
+# 三、技术架构
+
+## 1. 协议层次与透明替换
+
+SMC-R 工作于内核空间,向上支持用户态程序通过 socket 接口描述的网络行为,向下使用 IB verbs 接口实现 RDMA 网络传输。RDMA 资源的使用、管理与维护均由 SMC-R 协议栈完成,应用程序不会感知到内核中的 RDMA 实体。
+
+
+
+Alibaba Cloud Linux 3 提供了进程或 net namespace 纬度的 TCP 至 SMC-R 协议栈透明替换机制。通过 LD_PRELOAD/eBFP 或 net.smc.tcp2smc sysctl 将应用程序原本的 AF_INET 协议族 socket 透明替换为 AF_SMC 协议族 socket,让网络传输运行于 SMC-R 协议栈,使应用程序不做任何修改即可享受 RDMA 带来的网络性能提升。
+
+## 2. 自动协商和安全回退
+
+SMC-R 具备自动协商协议、动态回退的能力。
+
+建立 SMC-R 通信前,协议栈首先在内核中与通信对端建立 TCP 连接,在握手过程中使用特殊的 TCP 选项表明自身支持 SMC-R,并确认对端同样支持 SMC-R。
+
+若协商成功,通信两侧 SMC-R 协议栈将创建新的,或复用已有的 RDMA 资源,建立可用的 RDMA RC 链路。从此网络传输将基于 RDMA 网络完成。
+
+若协商失败,如一侧不具备 RDMA 设备,SMC-R 协议栈将自动回退到 TCP 协议栈,使用协商时建立的 TCP 连接完成数据传输。
+
+需要注意的是,SMC-R 仅支持连接协商期间回退至 TCP 协议栈,但不支持数据传输过程中的回退。
+
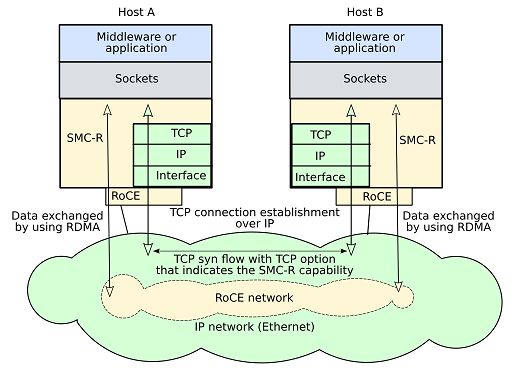
+
+
+(图片来自于 https://www.ibm.com/docs/en/aix/7.2?topic=access-shared-memory-communications-over-rdma-smc-r)
+
+## 3. 基于 RDMA 的共享内存通信
+
+完成协议协商并建立连接后,SMC-R 为每侧分配一块用于缓存待发送数据的环形缓冲区 sndbuf 和一块用于缓存待接收数据的环形缓冲区 RMB(Remote Memory Buffer)。
+
+发送端应用程序通过 socket 接口将待发送数据拷贝到本侧 sndbuf 中,由 SMC-R 协议栈通过 RDMA WRITE 操作直接高效地写入对侧节点的 RMB 中。同时,伴随着使用 RDMA SEND/RECV 操作交互连接数据管理 (Connection Data Control, CDC) 消息,用于更新、同步环形缓冲区中的数据游标 (Cursor)。
+
+接收端 SMC-R 协议栈感知到 RMB 中填入新数据后,通过 epoll 等方式告知接收端应用程序将 RMB 中的数据拷贝到用户态,完成数据传输。所以在 SMC-R 中,RMB 充当传输过程中的共享内存。
+
+
+
+# 四、应用场景
+
+## 1. 时延敏感的数据查询和处理
+
+Redis、memcached、PostgreSQL 等高性能数据查询与处理的场景,对网络性能有极高的要求。SMC-R 为应用提供无侵入式透明替换 TCP 协议栈的能力,无需应用二次开发和适配,即可为应用提供最高 50% 的 QPS 提升。
+
+## 2. 高吞吐的数据传输
+
+集群内的大规模数据交互与传输,往往需要占用大量的带宽和 CPU 资源。得益于 RDMA 技术带来的远程内存直接访问,SMC-R 在相同的吞吐性能下,CPU 资源使用显著低于传统 TCP 协议栈,为应用节省更多的计算资源。
+
+# 五、使用说明
+
+Alibaba Cloud Linux 3 提供并优化了 SMC-R 内核协议栈,并配合以完善的 SMC-R 状态监控和故障诊断工具。您可以通过下述步骤使用 SMC-R:
+
+## 1. 配置带有 ERI 的 ECS 实例
+
+SMC-R 基于 RDMA 实现。因此使用 SMC-R 前需要配置带有 ERI 的 ECS 实例,以获得云上 RDMA 能力。具体流程可以参见: [使用 ERI](https://help.aliyun.com/document_detail/336853.html?spm=a2c4g.11186623.0.0.6e244762X1zZKA)
+
+## 2. 加载 SMC 模块
+
+Alibaba Cloud Linux 3 中,SMC-R 均以内核模块的形式提供,因此首先需要加载 smc 与 smc_diag 内核模块。
+
+```
+modprobe smc
+modprobe smc_diag
+```
+
+在 dmesg 中可以观察到,模块被加载成功。
+
+```
+[60342.499847] NET: Registered protocol family 43
+[60342.499868] smc: netns ffffffff912dcf40 reserved ports for eRDMA OOB
+[60342.499869] smc: adding ib device iwp0s7 with port count 1
+[60342.499870] smc: ib device iwp0s7 port 1 has pnetid
+```
+
+**需要说明的是,由于 SMC-R + eRDMA 的实现方式的特殊性,加载 SMC-R 模块后将占用当前可访问 ERI 网卡的 net namespace 中从 33800 开始的 16 个 socket 端口用于建立 OOB 建连,若端口占用失败将无法加载 SMC-R 模块;卸载 SMC-R 模块时将解除端口占用。**
+
+## 3. 安装 smc-tools
+
+smc-tools 是 IBM 开发 SMC 监控诊断工具,拥有丰富的运维诊断功能。
+
+通过 yum 源安装 smc-tools
+
+```
+yum install -y smc-tools
+```
+
+## 4. 基于 SMC 协议栈运行 TCP socket 应用程序
+
+### 4.1 net namespace 维度透明替换
+
+Alibaba Cloud Linux 3 提供了 net namespace 纬度的协议透明替换功能。将同时符合以下所有条件的 TCP socket
+
+- family 为 AF_INET 或 AF_INET6;
+- type 为 SOCK_STREAM;
+- protocol 为 IPPROTO_IP 或 IPPROTO_TCP;
+
+替换为
+
+- family 为 AF_SMC;
+- type 为 SOCK_STREAM;
+- protocol 为 SMCPROTO_SMC 或 SMCPROTO_SMC6;
+
+的 SMC socket。
+
+
+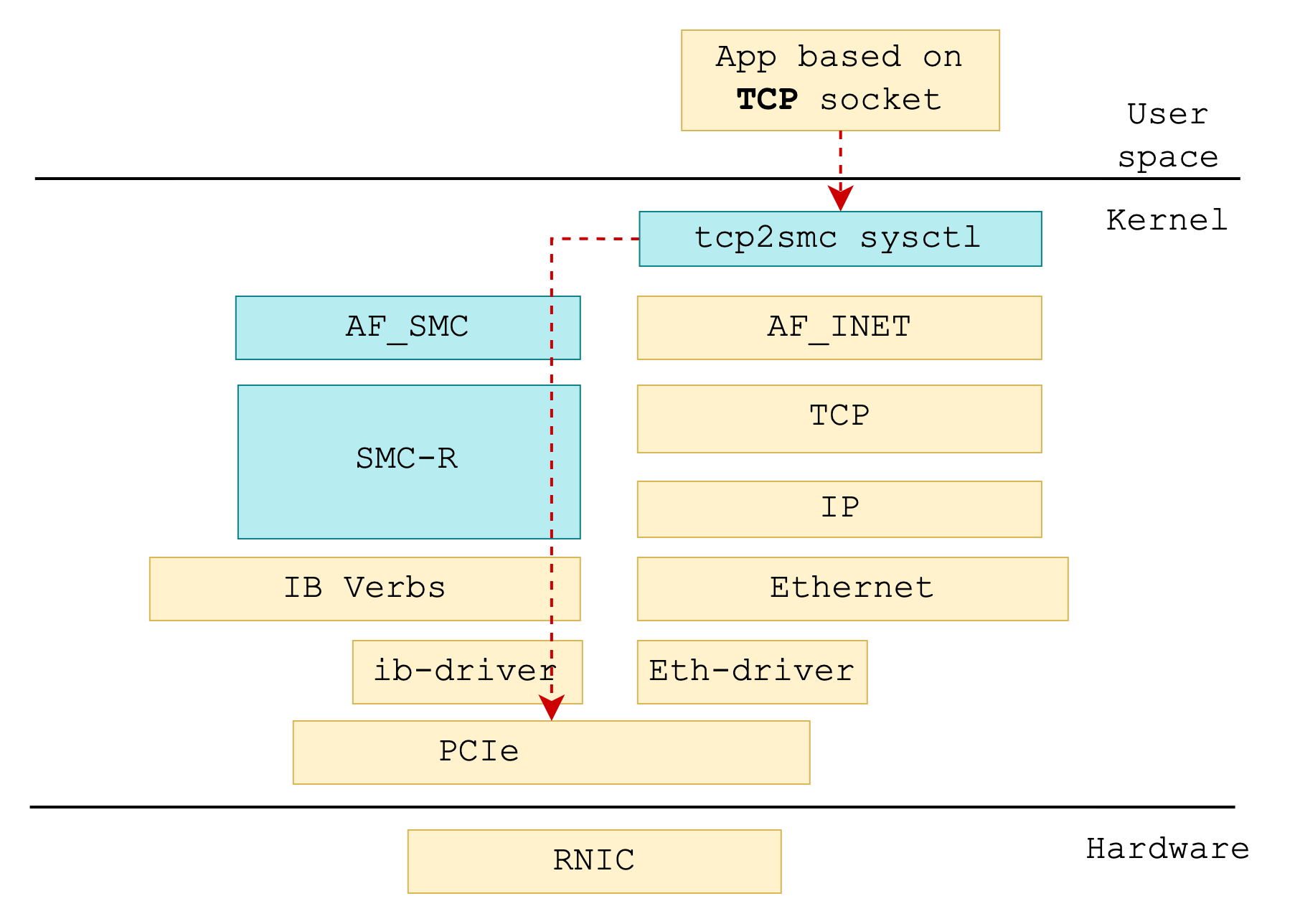
+
+1)打开 net namespace 范围全局替换开关 net.smc.tcp2smc
+
+```
+sysctl net.smc.tcp2smc=1
+```
+默认情况下,sysctl tcp2smc = 0,处在关闭状态。
+
+2)在此 net namespace 中运行 TCP socket 应用程序
+
+```
+./foo
+```
+
+此时 foo 应用程序创建的 TCP socket 将被透明替换为 SMC socket。通过 SMC-R 协议栈处理应用程序网络行为。如“自动协商与安全回退”小节所述,若通信对侧同样支持 SMC-R 协议并协商成功,则将基于 RDMA 网络完成数据传输;否则将安全回退使用 TCP 网络传输。
+
+3)关闭 net namespace 范围全局替换开关 net.smc.tcp2smc
+
+```
+sysctl net.smc.tcp2smc=0
+```
+
+### 4.2 进程维度透明替换
+
+Alibaba Cloud Linux 3 与 Anolis OS 还提供了进程维度的协议透明替换功能——使用 LD_PRELOAD 方式替换。使用 LD_PRELOAD 替换至 SMC 协议栈依赖 smc-tools 工具,smc-tools 的安装可见“3. 安装 smc-tools”中所述。
+
+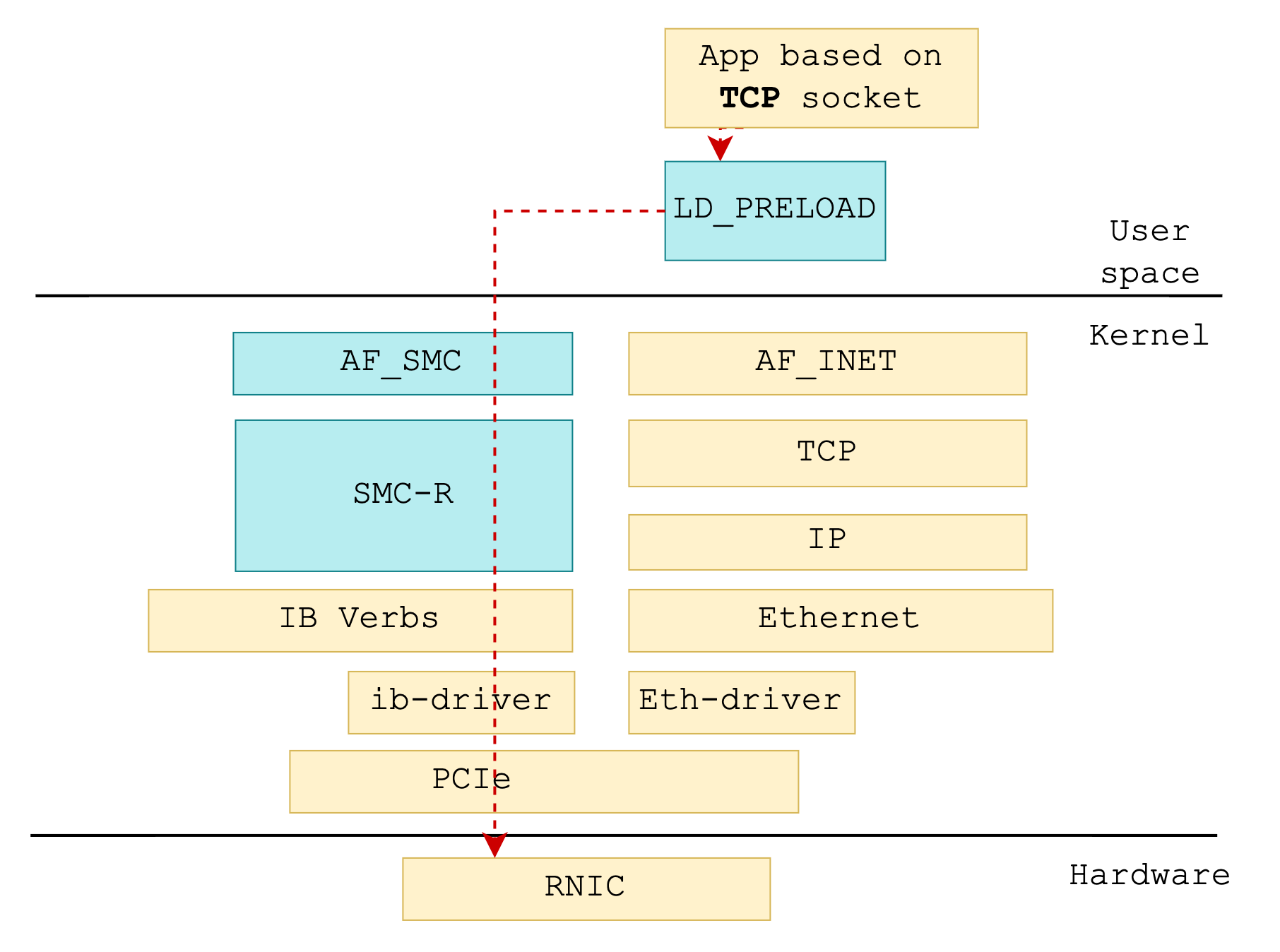
+
+利用 smc-tools 工具集中的脚本 smc_run 运行应用程序时,通过 LD_PRELOAD 环境变量将 smc-tools 工具集中的 libsmc-preload.so 定义为优先加载的动态库。
+libsmc-preload.so 将把应用程序及其子进程中符合以下所有条件的 TCP socket
+
+- family 为 AF_INET 或 AF_INET6;
+- type 为 SOCK_STREAM;
+- protocol 为 IPPROTO_IP 或 IPPROTO_TCP;
+
+替换为
+
+- family 为 AF_SMC;
+- type 为 SOCK_STREAM;
+- protocol 为 SMCPROTO_SMC 或 SMCPROTO_SMC6;
+
+的 SMC socket。
+
+指定 TCP socket 程序 foo 运行在 SMC-R 协议栈:
+
+```
+smc_run ./foo
+```
+
+此时 foo 应用程序创建的 TCP socket 将被透明替换为 SMC socket。通过 SMC-R 协议栈处理应用程序网络行为。如“自动协商与安全回退”小节所述,若通信对侧同样支持 SMC-R 协议并协商成功,则将基于 RDMA 网络完成数据传输;否则将安全回退使用 TCP 网络传输。
+
+## 5. 跟踪诊断 SMC-R 连接与 RDMA 资源
+
+### 5.1 smc-tools
+
+smc-tools 工具集提供了多个维度的 SMC-R 跟踪诊断,主要包括:
+
+- smcr:提供 SMC-R 相关资源统计信息;
+- smcss:提供 SMC socket 相关信息;
+
+
+**1. 使用 smcr**
+
+- 查看 smcr 指令 manual
+
+```
+man smcr
+```
+- 查看支持 SMC-R 的设备:
+
+```
+[root ~]# smcr device
+Net-Dev IB-Dev IB-P IB-State Type Crit #Links PNET-ID
+eth0 iwp0s7 1 ACTIVE 0x107f No 0
+```
+
+- 如查看 linkgroup(即 SMC-R 协议栈维护的 RDMA 链路)信息:
+
+```
+[root ~]# smcr l
+LG-ID LG-Role LG-Type VLAN #Conns PNET-ID
+00000100 CLNT SINGLE 0 32
+00000200 CLNT SINGLE 0 32
+00000300 CLNT SINGLE 0 32
+00000400 CLNT SINGLE 0 32
+00000500 CLNT SINGLE 0 32
+00000600 CLNT SINGLE 0 32
+00000700 CLNT SINGLE 0 8
+```
+此时客户端 SMC-R 协议栈共创建了 7 条 RDMA 链路,每条 RDMA 链路承载最多 32 条 SMC-R 连接。
+
+
+- 如查看各类统计信息:
+
+```
+[root@iZ2zee1mqxjh17ugngyg2bZ smc-tools]# smcr -dd stats
+SMC-R Connections Summary
+ Total connections handled 509
+SMC connections 509 (client 0, server 509)
+ v1 509
+ v2 0
+Handshake errors 0 (client 0, server 0)
+ Avg requests per SMC conn 1603405.0
+TCP fallback 0 (client 0, server 0)
+
+ RX Stats
+Data transmitted (Bytes) 17954924988 (17.95G)
+ Total requests 408066678
+Buffer full 0 (0.00%)
+ Buffer downgrades 0
+ Buffer reuses 308
+ 8KB 16KB 32KB 64KB 128KB 256KB 512KB >512KB
+ Bufs 0 0 0 0 0 509 0 0
+ Reqs 408.1M 0 0 0 0 0 0 0
+ TX Stats
+Data transmitted (Bytes) 70595498981 (70.60G)
+ Total requests 408066477
+ Buffer full 0 (0.00%)
+ Buffer full (remote) 0 (0.00%)
+ Buffer too small 0 (0.00%)
+Buffer too small (remote) 0 (0.00%)
+ Buffer downgrades 0
+ Buffer reuses 308
+ 8KB 16KB 32KB 64KB 128KB 256KB 512KB >512KB
+ Bufs 0 0 0 0 509 0 0 0
+ Reqs 408.1M 0 0 0 0 0 0 0
+
+ Extras
+ Special socket calls 508
+ cork 0
+ nodelay 508
+ sendpage 0
+ splice 0
+ urgent data 0
+```
+
+**2. 使用 smcss**
+
+- smcss 类似于 ss 工具,查看 smcss manual:
+
+```
+man smcss
+```
+
+- 查看当前所有的 SMC-R sockets 的详细信息:
+
+```
+[root ~]# smcss -R
+State UID Inode Local Address Peer Address Intf Mode Role IB-device Port Linkid GID Peer-GID
+ACTIVE 00000 0141987 192.168.99.21:33144 192.168.99.22:8090 0000 SMCR CLNT iwp0s7 01 01 0016:3e08:8b8b:0000:0000:0000:0000:0000 0016:3e10:3fb4:0000:0000:0000:0000:0000
+ACTIVE 00000 0141989 192.168.99.21:33148 192.168.99.22:8090 0000 SMCR CLNT iwp0s7 01 01 0016:3e08:8b8b:0000:0000:0000:0000:0000 0016:3e10:3fb4:0000:0000:0000:0000:0000
+ACTIVE 00000 0141991 192.168.99.21:33164 192.168.99.22:8090 0000 SMCR CLNT iwp0s7 01 01 0016:3e08:8b8b:0000:0000:0000:0000:0000 0016:3e10:3fb4:0000:0000:0000:0000:0000
+ACTIVE 00000 0141993 192.168.99.21:33168 192.168.99.22:8090 0000 SMCR CLNT iwp0s7 01 01 0016:3e08:8b8b:0000:0000:0000:0000:0000 0016:3e10:3fb4:0000:0000:0000:0000:0000
+ACTIVE 00000 0141995 192.168.99.21:33174 192.168.99.22:8090 0000 SMCR CLNT iwp0s7 01 01 0016:3e08:8b8b:0000:0000:0000:0000:0000 0016:3e10:3fb4:0000:0000:0000:0000:0000
+ACTIVE 00000 0141997 192.168.99.21:33178 192.168.99.22:8090 0000 SMCR CLNT iwp0s7 01 01 0016:3e08:8b8b:0000:0000:0000:0000:0000 0016:3e10:3fb4:0000:0000:0000:0000:0000
+```
+
+- 特别的,当 SMC-R 协议协商失败安全回退到 TCP 时,也可以通过 smcss 观察到:
+
+```
+[root@iZ2zee1mqxjh17ugngyg2aZ ~]# smcss -a
+State UID Inode Local Address Peer Address Intf Mode
+ACTIVE 00000 0156721 192.168.99.21:60188 192.168.99.22:8090 0000 TCP 0x03010000
+ACTIVE 00000 0156723 192.168.99.21:60194 192.168.99.22:8090 0000 TCP 0x03010000
+ACTIVE 00000 0156725 192.168.99.21:60204 192.168.99.22:8090 0000 TCP 0x03010000
+ACTIVE 00000 0156727 192.168.99.21:60206 192.168.99.22:8090 0000 TCP 0x03010000
+ACTIVE 00000 0156729 192.168.99.21:60214 192.168.99.22:8090 0000 TCP 0x03010000
+```
+
+最后一列的 0x03010000 是回退原因代码。回退原因代码含义如下:
+
+```
+#define SMC_CLC_DECL_MEM 0x01010000 /* insufficient memory resources */
+#define SMC_CLC_DECL_TIMEOUT_CL 0x02010000 /* timeout w4 QP confirm link */
+#define SMC_CLC_DECL_TIMEOUT_AL 0x02020000 /* timeout w4 QP add link */
+#define SMC_CLC_DECL_CNFERR 0x03000000 /* configuration error */
+#define SMC_CLC_DECL_PEERNOSMC 0x03010000 /* peer did not indicate SMC */
+#define SMC_CLC_DECL_IPSEC 0x03020000 /* IPsec usage */
+#define SMC_CLC_DECL_NOSMCDEV 0x03030000 /* no SMC device found (R or D) */
+#define SMC_CLC_DECL_NOSMCDDEV 0x03030001 /* no SMC-D device found */
+#define SMC_CLC_DECL_NOSMCRDEV 0x03030002 /* no SMC-R device found */
+#define SMC_CLC_DECL_NOISM2SUPP 0x03030003 /* hardware has no ISMv2 support */
+#define SMC_CLC_DECL_NOV2EXT 0x03030004 /* peer sent no clc v2 extension */
+#define SMC_CLC_DECL_NOV2DEXT 0x03030005 /* peer sent no clc SMC-Dv2 ext. */
+#define SMC_CLC_DECL_NOSEID 0x03030006 /* peer sent no SEID */
+#define SMC_CLC_DECL_NOSMCD2DEV 0x03030007 /* no SMC-Dv2 device found */
+#define SMC_CLC_DECL_NOUEID 0x03030008 /* peer sent no UEID */
+#define SMC_CLC_DECL_MODEUNSUPP 0x03040000 /* smc modes do not match (R or D)*/
+#define SMC_CLC_DECL_RMBE_EC 0x03050000 /* peer has eyecatcher in RMBE */
+#define SMC_CLC_DECL_OPTUNSUPP 0x03060000 /* fastopen sockopt not supported */
+#define SMC_CLC_DECL_DIFFPREFIX 0x03070000 /* IP prefix / subnet mismatch */
+#define SMC_CLC_DECL_GETVLANERR 0x03080000 /* err to get vlan id of ip device*/
+#define SMC_CLC_DECL_ISMVLANERR 0x03090000 /* err to reg vlan id on ism dev */
+#define SMC_CLC_DECL_NOACTLINK 0x030a0000 /* no active smc-r link in lgr */
+#define SMC_CLC_DECL_NOSRVLINK 0x030b0000 /* SMC-R link from srv not found */
+#define SMC_CLC_DECL_VERSMISMAT 0x030c0000 /* SMC version mismatch */
+#define SMC_CLC_DECL_MAX_DMB 0x030d0000 /* SMC-D DMB limit exceeded */
+#define SMC_CLC_DECL_NOROUTE 0x030e0000 /* SMC-Rv2 conn. no route to peer */
+#define SMC_CLC_DECL_NOINDIRECT 0x030f0000 /* SMC-Rv2 conn. indirect mismatch*/
+#define SMC_CLC_DECL_SYNCERR 0x04000000 /* synchronization error */
+#define SMC_CLC_DECL_PEERDECL 0x05000000 /* peer declined during handshake */
+#define SMC_CLC_DECL_INTERR 0x09990000 /* internal error */
+#define SMC_CLC_DECL_ERR_RTOK 0x09990001 /* rtoken handling failed */
+#define SMC_CLC_DECL_ERR_RDYLNK 0x09990002 /* ib ready link failed */
+#define SMC_CLC_DECL_ERR_REGBUF 0x09990003 /* reg rdma bufs failed */
+#define SMC_CLC_DECL_CREDITSERR 0x09990004 /* announce credits failed */
+```
diff --git "a/sig/high-perf-network-sig/content/projects/SMC/5_\346\234\200\344\275\263\345\256\236\350\267\265-\344\275\277\347\224\250SMC\345\222\214ERI\351\200\217\346\230\216\345\212\240\351\200\237Redis\345\272\224\347\224\250.md" "b/sig/high-perf-network-sig/content/projects/SMC/5_\346\234\200\344\275\263\345\256\236\350\267\265-\344\275\277\347\224\250SMC\345\222\214ERI\351\200\217\346\230\216\345\212\240\351\200\237Redis\345\272\224\347\224\250.md"
new file mode 100644
index 0000000000000000000000000000000000000000..dce39d40739c4c364085a01f9318fb50d0c83224
--- /dev/null
+++ "b/sig/high-perf-network-sig/content/projects/SMC/5_\346\234\200\344\275\263\345\256\236\350\267\265-\344\275\277\347\224\250SMC\345\222\214ERI\351\200\217\346\230\216\345\212\240\351\200\237Redis\345\272\224\347\224\250.md"
@@ -0,0 +1,160 @@
+通过本文您可以了解:如何使用 Alibaba Cloud Linux 3 操作系统提供的 SMC 高性能网络协议栈和阿里云 ERI 技术,透明加速 Redis 和应用客户端,无需修改运行环境和重新编译应用,即可获得性能提升。
+
+# 背景
+
+Redis 是一款开源的高性能内存存储,广泛运用在数据库、缓存、流计算和消息网关等场景。Redis 一大优势是提供极高的读取和写入性能,此时网络时延对于端到端的性能影响将会成倍放大。翻阅 Redis 官方文档,多次提到网络时延和带宽对于性能的影响[1][2],因此我们需要解决 Redis 默认协议栈 TCP 的性能瓶颈,降低时延和 CPU 资源消耗,进而提升性能。
+同时,Redis 社区版本尚未提供高性能网络的解决方案,在早期业务和团队规模相对较小的情况下,开发和运维一套非社区的高性能 Redis 方案的成本将会异常昂贵。并且应用访问 Redis 服务所使用的 SDK 千差万别,难以做到统一适配、维护和升级,也极大提高了接入和迁移成本。
+Alibaba Cloud Linux 3 提供了基于阿里云弹性 RDMA (ERI) 的高性能网络解决方案 SMC。SMC 兼具 DPU 卸载 RDMA 协议栈的高性能和传统 TCP 协议栈的通用性,透明替换 TCP 应用的同时,性能得到显著提升,此时应用无需任何侵入性的改造或者重新编译。
+
+# 实现方案
+
+借助阿里云 ERI 网卡和 Alibaba Cloud Linux 3 操作系统的 SMC 高性能网络协议栈,可以实现代码、环境无侵入替换 Redis 和应用。SMC 通过在内核选择性地替换 Redis 和应用的 TCP socket 链接,透明地使用 RDMA 加速传统 TCP/IP,因此我们需要准备以下环境:
+
+- ECS 使用 Alibaba Linux 3 操作系统[3];
+- ECS 启用“弹性 RDMA 接口”,确保 ECS 中有至少一张 ERI[4];
+
+## ECS 环境配置
+
+1. 创建 ECS 时,在“基础配置”页面选择最新的 Alibaba Cloud Linux 3 镜像[5],此时操作系统将默认包含 SMC 高性能网络协议栈。
+
+
+
+接下来在“网络和安全组”页面,弹性网卡中勾选“弹性 RDMA 接口”。
+
+
+
+对于已经创建的 ECS,可以选择升级到 Alibaba Cloud Linux 3 内核,或者确保数据已经安全备份的情况下更换操作系统[6]。同时添加辅助网卡并启用 ERI 能力[7]。
+
+2. ECS 启动成功后,执行下面命令验证是否包含 SMC 模块:
+
+```
+modinfo smc
+```
+
+如果命令有返回且有具体的内核模块 ko(输出结果的版本、签名等信息不一定完全相同),则说明具备 SMC 高性能网络协议栈。
+
+```
+filename: /lib/modules/5.10.134-12.al8.aarch64/kernel/net/smc/smc.ko
+alias: tcp-ulp-smc
+alias: smc
+alias: net-pf-43
+license: GPL
+description: smc socket address family
+author: Ursula Braun
+srcversion: C36162B1FA971B0FBCA3CEC
+depends: ib_core
+intree: Y
+name: smc
+vermagic: 5.10.134-12.al8.aarch64 SMP mod_unload modversions aarch64
+sig_id: PKCS#7
+signer: Aliyun Linux Driver update signing key
+sig_key: 6B:9A:30:96:2D:8A:02:77:86:25:B9:48:3D:F8:5C:D7:00:C0:91:34
+sig_hashalgo: sha256
+signature: 2B:93:6D:6D:97:86:9C:C0:33:09:FF:5A:06:18:D2:15:A1:1B:8B:85:
+B0:9B:D6:89:2D:3B:14:7F:15:7F:28:18:0F:62:88:A9:C4:74:09:96:
+F0:40:4A:65:65:10:D2:0A:61:E8:80:18:38:CA:BB:66:A2:D6:4F:03:
+31:13:86:9B:C2:0A:4D:84:77:C1:31:64:B8:F0:30:34:7A:7F:E8:5A:
+AB:6E:F6:2D:3F:06:38:BD:4C:F3:A5:FA:8F:30:C4:D9:A8:B1:BF:72:
+68:95:B7:35:C6:94:EF:D8:75:0D:90:34:00:B6:A4:44:F8:BD:47:84:
+53:FD:B0:88:ED:06:A2:AA:E4:2C:88:CC:8D:9B:D0:F6:D6:6E:EE:8B:
+6C:EA:53:B8:B0:85:C2:0B:0F:80:C9:82:76:48:49:40:AB:12:37:59:
+32:5A:8E:1A:DF:43:15:E4:09:6D:67:05:6A:F9:45:72:5D:38:4F:BF:
+47:A2:23:A1:90:A0:D5:36:B5:38:70:6B:52:C6:66:2B:4B:37:F5:6E:
+27:36:98:45:80:8D:89:9F:DB:4E:CD:2F:36:90:ED:6A:0B:56:30:CB:
+31:A9:F7:D2:D6:7D:9A:4C:81:00:6C:14:00:95:A1:8F:9F:41:3F:52:
+7E:A5:EC:9A:8E:5E:CE:DD:2B:C7:8E:A2:D9:67:27:64
+```
+
+此时执行下面命令,加载 SMC 内核模块:
+
+```
+modprobe smc
+```
+
+3. 加载 ERI 驱动[7],执行下面命令:
+
+```
+modprobe erdma
+```
+
+执行下面命令,如果命令有包含“erdma”字符串的返回则说明 ERDMA 驱动加载成功:
+
+```
+lsmod | grep erdma
+```
+
+返回结果,第二个值不一定完全相同。
+
+```
+erdma 98304 0
+```
+
+4. 使用 SMC 透明加速 Redis 需要使用 smc-tools 工具,执行下面命令获取并安装工具包。
+
+```
+sudo yum install smc-tools
+```
+
+执行下面的命令,验证工具安装成功,同时检查 ERI 是否正确注册到 SMC:
+
+```
+smcr d
+```
+
+如果返回值如下(设备名不一定完全相同),则说明 ERI 网卡已被成功注册:
+
+```
+Net-Dev IB-Dev IB-P IB-State Type Crit #Links PNET-ID
+eth0 iwp4s0 1 ACTIVE 0x107f No 0
+```
+
+执行完上述命令和检查之后,ERI 和 SMC 已经顺利加载到内核,并具备加速应用的能力。
+
+## 透明加速 Redis
+
+为了简化测试,我们使用 smc-tools 提供的 smc_run 快速透明替换 Redis 应用,更加详细的使用说明请参考使用文档[8]。
+启动 Redis 并使用 SMC 加速 TCP,执行下面命令将直接启动 Redis(此处省略详细的 Redis 配置参数):
+
+```
+smc_run redis-server # 原始启动命令为 redis-server,只需在命令头部加入 smc_run 前缀即可
+```
+
+如果 Redis 通过脚本启动,则可以使用 smc_run 直接启动脚本,SMC 加速效果将会覆盖子进程。
+
+## 透明加速应用
+
+使用 SMC 加速应用和上面 Redis 类似,我们可以使用 smc_run 快速透明替换应用的 TCP 连接,如需更复杂的替换规则(选择满足特定条件的 TCP 连接),请参考使用文档[8]。
+启动应用(此处以 redis-benchmark 为例),执行下面命令将直接启动应用:
+
+```
+smc_run redis-benchmark -h 11.213.45.34 --threads 4 -n 100000 -c 200 -d 10
+```
+
+如果通过脚本启动应用,则可以是用 smc_run 直接启动脚本,同上。
+
+## 性能收益
+
+通过 smc_run 命令分别启动 Redis 和应用后,二者间通信的 TCP 连接将会被替换为 SMC,应用访问不支持 SMC 协议的链接将会被回退为 TCP,不影响应用访问其他服务。
+此处以 redis-benchmark 结果为例,详细结果请参考性能测试[9]文档。
+
+
+
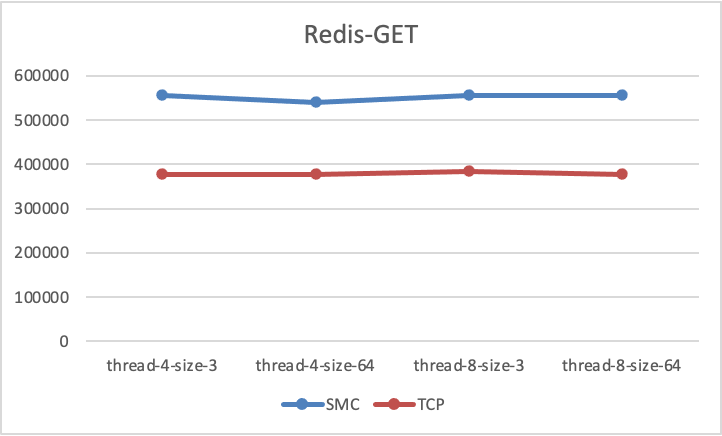
+
+
+从测试结果可以看出,无论是 GET 测试还是 SET 测试,SMC 相对于 TCP 带来了至少 40%+ 的性能测试数据提升。
+
+# 总结
+
+使用 SMC 高性能网络协议栈和阿里云弹性 RDMA 网卡,可以透明加速应用访问 Redis 的性能,满足应用对于高性能场景的需求,同时无需应用修改代码即可享受技术红利。
+
+# 引用
+
+[1] https://redis.io/docs/management/optimization/latency/#latency-induced-by-network-and-communication
+[2] https://redis.io/docs/management/optimization/benchmarks/#factors-impacting-redis-performance
+[3] https://help.aliyun.com/document_detail/111881.htm?spm=a2c4g.11186623.0.0.17e88778WwUw9r#concept-rgv-rvd-2hb
+[4] https://help.aliyun.com/document_detail/336853.html?spm=a2c4g.11186623.0.0.6e244762X1zZKA
+[5] https://help.aliyun.com/document_detail/212634.html
+[6] https://help.aliyun.com/document_detail/25436.html
+[7] https://help.aliyun.com/document_detail/336853.html
+[8]
+[9]
diff --git a/sig/high-perf-network-sig/content/projects/SMC/6_QA.md b/sig/high-perf-network-sig/content/projects/SMC/6_QA.md
new file mode 100644
index 0000000000000000000000000000000000000000..09b61540d3159f4848a0d7bf3f6bfc5e6e9f207b
--- /dev/null
+++ b/sig/high-perf-network-sig/content/projects/SMC/6_QA.md
@@ -0,0 +1,26 @@
+# 常见问题汇总
+
+## SMC-R 导致端口不通
+
+**Q**: 开启 SMC-R 后访问部分端口出现不通的情况
+
+**A**:
+- 解决方法
+
+载入 SMC 模块(modprobe smc),并将执行 sysctl net.smc.sysctl_smc_experiments=1 命令,将该配置打开。如需持久化该配置,可以添加到 /etc/sysctl.conf 中;
+重新发起新的 SMC 链接后将不会出现此问题。
+
+- 问题原因
+
+某些服务在处理 TCP options 时,例如网关或者反向代理服务器,会将请求的 TCP options 重放,此时 SMC 通过 TCP 握手时所携带的 TCP options 将会被重放,SMC client 将会误认为对端 server 支持 SMC 能力导致例如 curl 请求失败,但是 ping(ICMP 协议)正常。打开上述 sysctl 将会使用不同的 TCP options 解决 TCP options 重放问题。该问题经过我们验证互联网中的服务,仅存在极少数服务中,绝大多数可以正常建连。
+
+
+## SMC-R 导致部分端口不可用,返回 EADDRINUSE 错误
+
+**Q**: 加载 SMC-R 后 33800 后的 16 个端口不可用,返回 EADDRINUSE 错误
+
+**A**:
+
+- 问题原因
+
+由于 SMC-R + eRDMA 实现方式的特殊性,SMC-R 模块将会占用 ERI 所在 net namespace 下 33800 开始的 16 个端口作为 OOB 建连的预留端口,若端口占用失败则 SMC 模块加载失败。SMC 模块卸载后将会释放这些端口。
diff --git a/sig/high-perf-network-sig/content/projects/SMC/README.md b/sig/high-perf-network-sig/content/projects/SMC/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..bb97a1a5129ef159d329497e98c12a95136ddd10
--- /dev/null
+++ b/sig/high-perf-network-sig/content/projects/SMC/README.md
@@ -0,0 +1,37 @@
+# 背景
+
+共享内存通信(Shared Memory Communication,SMC)是一种兼容 socket 层,利用共享内存操作实现高性能通信的内核网络协议栈。当共享内存通信基于远程内存直接访问(Remote Direct Memory Access,RDMA)技术实现时,称为 SMC over RDMA(SMC-R)。
+
+SMC-R 兼容 socket 接口的特点使 TCP 应用程序无需任何改造即可运行在 SMC 协议栈上;底层使用的 RDMA 网络使 SMC 拥有相较于 TCP 更好的网络性能。SMC 协议栈通过 TCP 连接自主发现对侧 SMC 能力,协商成功后使用 SMC 协议栈承载应用数据流量;协商失败则安全回退至 TCP/IP 协议栈,保证数据正常传输。
+
+阿里云 Alibaba Cloud Linux 3 操作系统基于阿里云弹性 RDMA(elastic RDMA, eRDMA)技术首次将 SMC-R 带入云上场景,实现云上 TCP 协议栈的透明无损替换,为数据库、RPC、批量数据传输等场景提供相比 TCP 更好的网络性能。相较于上游 Linux SMC-R 实现,Alibaba Cloud Linux 3 中的 SMC-R 更适配阿里云 eRDMA 技术、拥有更好的性能、可靠的稳定性、丰富成熟的透明替换方案和及时的更新维护。
+
+
+
+# 组织原则
+
+共赢、平等、开源
+
+# 目标愿景
+
+- 探索 SMC 更多可能性, 推进 SMC 在更多场景下的实现与落地
+- 促进技术交流
+- 提供技术帮助
+- 为各个伙伴提供需求输入
+- 同步各个伙伴的开发进展
+- 促进各个伙伴之间的合作
+
+# 组织形式
+
+- 定期收集参与伙伴的 topic。有 topic 的情况下, 会召开开放性会议。日常 SMC 相关讨论将以周会形式召开,会议纪要将公开并存档。
+- 通过邮件及钉钉群的方式申报交流议题
+- 开放性会议将以云会议的方式,会议开始一天前会将会议 ID 以及议题汇总发送到 SIG 相关邮件列表和钉钉群
+- 议结束后纪要通过邮件列表发出,并在 SIG 中归档
+
+# 邮件列表
+
+netdev@lists.openanolis.cn
+
+# 联系
+
+邮件列表或钉钉群: 34264214
diff --git a/sig/high-perf-network-sig/content/reports/2022/2022.12.md b/sig/high-perf-network-sig/content/reports/2022/2022.12.md
index 22929f4f4a32d452e7e2608e8f87b5e15302159f..0faa18b91a8451eaaea024e95cd4913497200dc3 100644
--- a/sig/high-perf-network-sig/content/reports/2022/2022.12.md
+++ b/sig/high-perf-network-sig/content/reports/2022/2022.12.md
@@ -7,8 +7,8 @@
# Anolis OS
### 问题修复
-本月 ANCK 网络方向共计修复 48 个 CVE,覆盖 tcp/netfilter/ip/tc/vsock/wifi/bluetooth/can 等模块,CVE 列表:
-CVE-2022-42895, CVE-2022-3435, CVE-2022-3633, CVE-2022-3535, CVE-2022-0812, CVE-2022-39190, CVE-2022-42719, CVE-2022-1015, CVE-2022-42895, CVE-2021-4203, CVE-2022-1204, CVE-2022-1012, CVE-2021-33135, CVE-2022-1012, CVE-2022-1966, CVE-2022-1966, CVE-2022-1679, CVE-2022-3028, CVE-2022-3028, CVE-2022-2663, CVE-2022-3567, CVE-2022-3586, CVE-2022-41674, CVE-2022-42722, CVE-2022-42721, CVE-2022-42720, CVE-2022-3566, CVE-2022-3521, CVE-2022-3524, CVE-2022-3435, CVE-2022-3564, CVE-2022-3625, CVE-2022-4378, CVE-2022-4378, CVE-2022-20368, CVE-2022-42895, CVE-2022-42896, CVE-2022-3564, CVE-2022-3566, CVE-2022-2588, CVE-2022-36879, CVE-2022-1966, CVE-2022-3535, CVE-2022-3524, CVE-2022-42722, CVE-2022-33741, CVE-2022-1966, CVE-2022-1204
+本月 ANCK 网络方向共计修复 33 个 CVE(包含一个高危 CVE-2022-4378),覆盖 tcp/netfilter/ip/tc/vsock/wifi/bluetooth/can 等模块,CVE 列表:
+CVE-2022-42895, CVE-2022-3435, CVE-2022-3633, CVE-2022-3535, CVE-2022-0812, CVE-2022-39190, CVE-2022-42719, CVE-2022-1015, CVE-2022-42895, CVE-2021-4203, CVE-2022-1204, CVE-2022-1012, CVE-2021-33135, CVE-2022-1012, CVE-2022-1966, CVE-2022-1966, CVE-2022-1679, CVE-2022-3028, CVE-2022-3028, CVE-2022-2663, CVE-2022-3567, CVE-2022-3586, CVE-2022-41674, CVE-2022-42722, CVE-2022-42721, CVE-2022-42720, CVE-2022-3566, CVE-2022-3521, CVE-2022-3524, CVE-2022-3435, CVE-2022-3564, CVE-2022-3625, CVE-2022-4378
### 功能增强
- PR908 5.10 内核 ipvs 支持通过 run_estimation sysctl 关闭 estimation