+ ![]() +
+
 +
+  +
+  +
+  +
+  +
+  +
+  +
+
+ 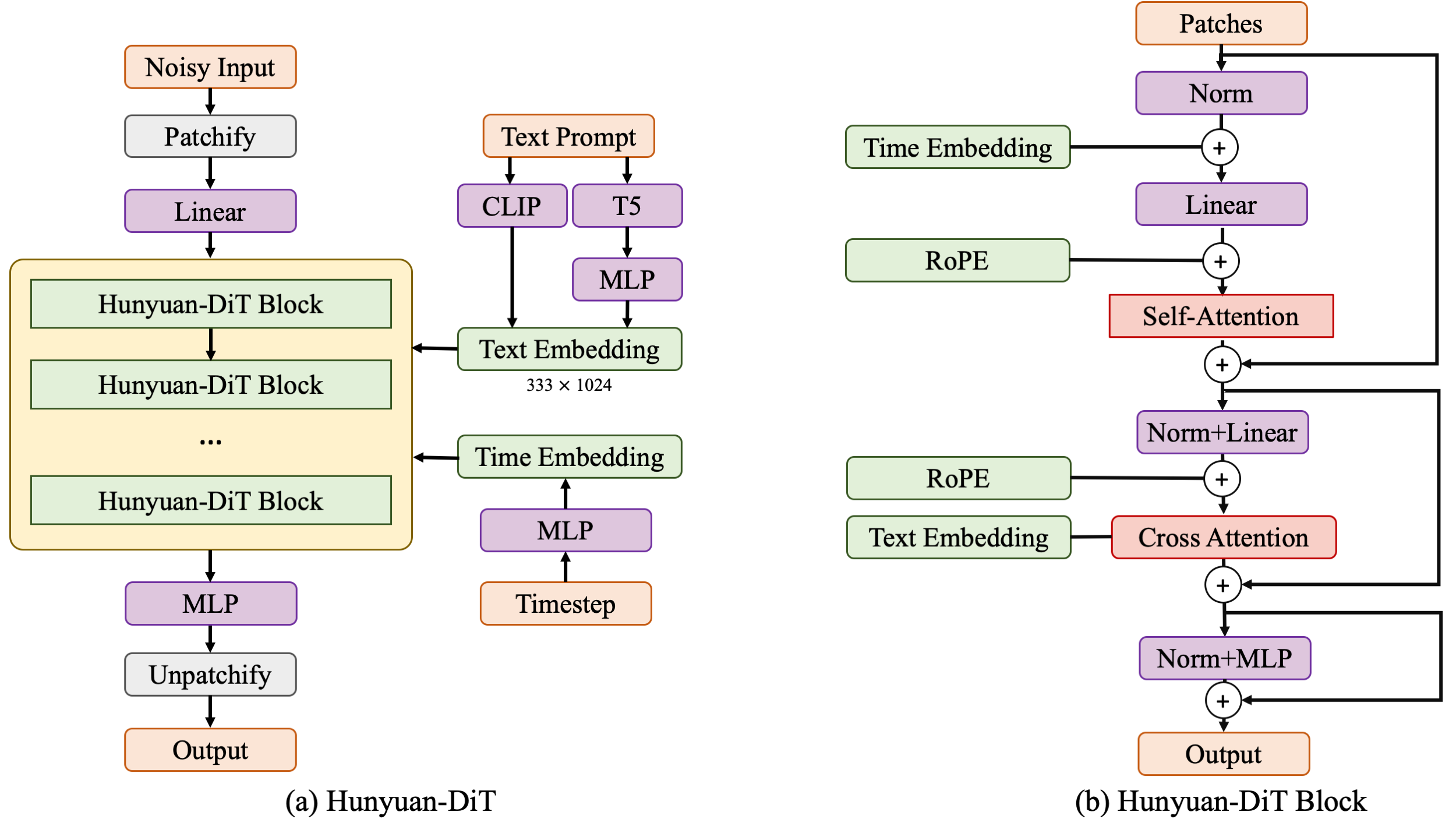 +
+
+  +
+
+
| Model | Open Source | Text-Image Consistency (%) | Excluding AI Artifacts (%) | Subject Clarity (%) | Aesthetics (%) | Overall (%) | +
|---|---|---|---|---|---|---|
| SDXL | ✔ | 64.3 | 60.6 | 91.1 | 76.3 | 42.7 | +
| PixArt-α | ✔ | 68.3 | 60.9 | 93.2 | 77.5 | 45.5 | +
| Playground 2.5 | ✔ | 71.9 | 70.8 | 94.9 | 83.3 | 54.3 | +
| SD 3 | ✘ | 77.1 | 69.3 | 94.6 | 82.5 | 56.7 | + +
| MidJourney v6 | ✘ | 73.5 | 80.2 | 93.5 | 87.2 | 63.3 | +
| DALL-E 3 | ✘ | 83.9 | 80.3 | 96.5 | 89.4 | 71.0 | +
| Hunyuan-DiT | ✔ | 74.2 | 74.3 | 95.4 | 86.6 | 59.0 | +
+  +
+
+  +
+
| Examples of training data | +|||
 |
+  |
+  |
+  |
+
| 青花瓷风格,一只蓝色的鸟儿站在蓝色的花瓶上,周围点缀着白色花朵,背景是白色 (Porcelain style, a blue bird stands on a blue vase, surrounded by white flowers, with a white background. +) | +青花瓷风格,这是一幅蓝白相间的陶瓷盘子,上面描绘着一只狐狸和它的幼崽在森林中漫步,背景是白色 (Porcelain style, this is a blue and white ceramic plate depicting a fox and its cubs strolling in the forest, with a white background.) | +青花瓷风格,在黑色背景上,一只蓝色的狼站在蓝白相间的盘子上,周围是树木和月亮 (Porcelain style, on a black background, a blue wolf stands on a blue and white plate, surrounded by trees and the moon.) | +青花瓷风格,在蓝色背景上,一只蓝色蝴蝶和白色花朵被放置在中央 (Porcelain style, on a blue background, a blue butterfly and white flowers are placed in the center.) | +
| Examples of inference results | +|||
 |
+  |
+  |
+  |
+
| 青花瓷风格,苏州园林 (Porcelain style, Suzhou Gardens.) | +青花瓷风格,一朵荷花 (Porcelain style, a lotus flower.) | +青花瓷风格,一只羊(Porcelain style, a sheep.) | +青花瓷风格,一个女孩在雨中跳舞(Porcelain style, a girl dancing in the rain.) | +
| Condition Input | +||
| Canny ControlNet | +Depth ControlNet | +Pose ControlNet | +
| 在夜晚的酒店门前,一座古老的中国风格的狮子雕像矗立着,它的眼睛闪烁着光芒,仿佛在守护着这座建筑。背景是夜晚的酒店前,构图方式是特写,平视,居中构图。这张照片呈现了真实摄影风格,蕴含了中国雕塑文化,同时展现了神秘氛围 (At night, an ancient Chinese-style lion statue stands in front of the hotel, its eyes gleaming as if guarding the building. The background is the hotel entrance at night, with a close-up, eye-level, and centered composition. This photo presents a realistic photographic style, embodies Chinese sculpture culture, and reveals a mysterious atmosphere.) |
+ 在茂密的森林中,一只黑白相间的熊猫静静地坐在绿树红花中,周围是山川和海洋。背景是白天的森林,光线充足 (In the dense forest, a black and white panda sits quietly in green trees and red flowers, surrounded by mountains, rivers, and the ocean. The background is the forest in a bright environment.) |
+ 一位亚洲女性,身穿绿色上衣,戴着紫色头巾和紫色围巾,站在黑板前。背景是黑板。照片采用近景、平视和居中构图的方式呈现真实摄影风格 (An Asian woman, dressed in a green top, wearing a purple headscarf and a purple scarf, stands in front of a blackboard. The background is the blackboard. The photo is presented in a close-up, eye-level, and centered composition, adopting a realistic photographic style) |
+
 |
+  |
+  |
+
+
| ControlNet Output | +||
 |
+  |
+  |
+


{prompt}
' + conversation += [((input_text, response))] + return [conversation, history_messages], conversation + +# 页面设计 +def upload_image(state, image_input): + conversation = state[0] + history_messages = state[1] + input_image = Image.open(image_input.name).resize( + (224, 224)).convert('RGB') + input_image.save(image_input.name) # Overwrite with smaller image. + system_prompt = '请先判断用户的意图,若为画图则在输出前加入<画图>:' + history_messages, response = request_dialogGen(question="这张图描述了什么?",history_messages=history_messages, + image=image_input.name) + conversation += [(f'powered by DialogGen and HunyuanDiT
''') + + + text_input.submit(pipeline, [text_input, gr_state, infer_steps, seed, size_dropdown], [gr_state, chatbot]) + text_input.submit(lambda: "", None, text_input) # Reset chatbox. + submit_btn.click(pipeline, [text_input, gr_state, infer_steps, seed, size_dropdown], [gr_state, chatbot]) + submit_btn.click(lambda: "", None, text_input) # Reset chatbox. + + # image_btn.upload(upload_image, [gr_state, image_btn], [gr_state, chatbot]) + clear_last_btn.click(reset_last, [gr_state], [gr_state, chatbot]) + clear_btn.click(reset, [], [gr_state, chatbot]) + + interface = demo + interface.launch(server_name="0.0.0.0", server_port=443, share=False) diff --git a/PyTorch/built-in/mlm/HunyuanDiT/comfyui-hydit/LICENSE b/PyTorch/built-in/mlm/HunyuanDiT/comfyui-hydit/LICENSE new file mode 100644 index 0000000000000000000000000000000000000000..150218d6ccaf298ca67d92545ff4d9e5b170ce30 --- /dev/null +++ b/PyTorch/built-in/mlm/HunyuanDiT/comfyui-hydit/LICENSE @@ -0,0 +1,21 @@ +MIT License + +Copyright (c) 2023 Limitex + +Permission is hereby granted, free of charge, to any person obtaining a copy +of this software and associated documentation files (the "Software"), to deal +in the Software without restriction, including without limitation the rights +to use, copy, modify, merge, publish, distribute, sublicense, and/or sell +copies of the Software, and to permit persons to whom the Software is +furnished to do so, subject to the following conditions: + +The above copyright notice and this permission notice shall be included in all +copies or substantial portions of the Software. + +THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR +IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, +FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE +AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER +LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, +OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE +SOFTWARE. diff --git a/PyTorch/built-in/mlm/HunyuanDiT/comfyui-hydit/README.md b/PyTorch/built-in/mlm/HunyuanDiT/comfyui-hydit/README.md new file mode 100644 index 0000000000000000000000000000000000000000..2a97025c55b765619f3394f6c35af8903938c35f --- /dev/null +++ b/PyTorch/built-in/mlm/HunyuanDiT/comfyui-hydit/README.md @@ -0,0 +1,133 @@ +# comfyui-hydit + +This repository houses a tailored node and workflow designed specifically for HunYuan DIT. The official tests conducted on DDPM, DDIM, and DPMMS have consistently yielded results that align with those obtained through the Diffusers library. However, it's important to note that we cannot assure the consistency of results from other ComfyUI native samplers with the Diffusers inference. We cordially invite users to explore our workflow and are open to receiving any inquiries or suggestions you may have. + +## Overview + + +### Workflow text2image + + +[workflow_diffusers](workflow/workflow_diffusers.json) file for HunyuanDiT txt2image with diffusers backend. + +[workflow_ksampler](workflow/workflow_ksampler.json) file for HunyuanDiT txt2image with ksampler backend. + +[workflow_lora_controlnet_diffusers](workflow/workflow_lora_controlnet.json) file for HunyuanDiT lora and controlnet model with diffusers backend. + + +## Usage + +Make sure you run the following command inside [ComfyUI](https://github.com/comfyanonymous/ComfyUI) project with our [comfyui-hydit](.) and have correct conda environment. + +```shell +# Please use python 3.10 version with cuda 11.7 +# Download comfyui code +git clone https://github.com/comfyanonymous/ComfyUI.git + +# Install torch, torchvision, torchaudio +pip install torch==2.0.1 torchvision==0.15.2 torchaudio==2.0.2 --index-url https://download.pytorch.org/whl/cu117 --default-timeout=100 future + +# Install Comfyui essential python package +cd ComfyUI +pip install -r requirements.txt + +# ComfyUI has been successfully installed! + + +# Move to the ComfyUI custom_nodes folder and copy comfyui-hydit folder from HunyuanDiT Repo. +cd custom_nodes +git clone https://github.com/Tencent/HunyuanDiT.git +cp -r HunyuanDiT/comfyui-hydit ./ +rm -rf HunyuanDiT +cd comfyui-hydit + +# !!! If using windows system !!! +cd custom_nodes +git clone https://github.com/Tencent/HunyuanDiT.git +xcopy /E /I HunyuanDiT\comfyui-hydit comfyui-hydit +rmdir /S /Q HunyuanDiT +cd comfyui-hydit + +# Install some essential python Package. +pip install -r requirements.txt + +# Our tool has been successfully installed! + +# Go to ComfyUI main folder +cd ../.. +# Run the ComfyUI Lauch command +python main.py --listen --port 80 + +# Running ComfyUI successfully! +``` + +## Download weights for diffusers mode + +```shell +python -m pip install "huggingface_hub[cli]" +mkdir models/hunyuan +huggingface-cli download Tencent-Hunyuan/HunyuanDiT-v1.1 --local-dir ./models/hunyuan/ckpts +huggingface-cli download Tencent-Hunyuan/Distillation-v1.1 pytorch_model_distill.pt --local-dir ./models/hunyuan/ckpts/t2i/model +``` + +## Download weights for ksampler mode +Download the [clip encoder](https://huggingface.co/Tencent-Hunyuan/HunyuanDiT/blob/main/t2i/clip_text_encoder/pytorch_model.bin) and place it in `ComfyUI/models/clip` +Download the [mt5](https://huggingface.co/Tencent-Hunyuan/HunyuanDiT/blob/main/t2i/mt5/pytorch_model.bin) and place it in `ComfyUI/models/t5` +Download the [base model](https://huggingface.co/Tencent-Hunyuan/HunyuanDiT/blob/main/t2i/model/pytorch_model_ema.pt) and place it in `ComfyUI/models/checkpoints` +Download the [sdxl vae](https://huggingface.co/Tencent-Hunyuan/HunyuanDiT/blob/main/t2i/sdxl-vae-fp16-fix/diffusion_pytorch_model.bin) and place it in `ComfyUI/models/vae` + + +## Custom Node +Below I'm trying to document all the nodes, thanks for some good work[[1]](#1)[[2]](#2). +#### HunYuan Pipeline Loader +- Loads the full stack of models needed for HunYuanDiT. +- **pipeline_folder_name** is the official weight folder path for hunyuan dit including clip_text_encoder, model, mt5, sdxl-vae-fp16-fix and tokenizer. +- **lora** optional to load lora weight. + +#### HunYuan Checkpoint Loader +- Loads the base model for HunYuanDiT in ksampler backend. +- **model_name** is the weight list of comfyui checkpoint folder. + + +#### HunYuan CLIP Loader +- Loads the clip and mt5 model for HunYuanDiT in ksampler backend. +- **text_encoder_path** is the weight list of comfyui clip model folder. +- **t5_text_encoder_path** is the weight list of comfyui t5 model folder. + +#### HunYuan VAE Loader +- Loads the vae model for HunYuanDiT in ksampler backend. +- **model_name** is the weight list of comfyui vae model folder. + +#### HunYuan Scheduler Loader +- Loads the scheduler algorithm for HunYuanDiT. +- **Input** is the algorithm name including ddpm, ddim and dpmms. +- **Output** is the instance of diffusers.schedulers. + +#### HunYuan Model Makeup +- Assemble the models and scheduler module. +- **Input** is the instance of StableDiffusionPipeline and diffusers.schedulers. +- **Output** is the updated instance of StableDiffusionPipeline. + +#### HunYuan Clip Text Encode +- Assemble the models and scheduler module. +- **Input** is the string of positive and negative prompts. +- **Output** is the converted string for model. + +#### HunYuan Sampler +- Similar with KSampler in ComfyUI. +- **Input** is the instance of StableDiffusionPipeline and some hyper-parameters for sampling. +- **Output** is the generated image. + +#### HunYuan Lora Loader +- Loads the lora model for HunYuanDiT in diffusers backend. +- **lora_name** is the weight list of comfyui lora folder. + +#### HunYuan ControNet Loader +- Loads the controlnet model for HunYuanDiT in diffusers backend. +- **controlnet_path** is the weight list of comfyui controlnet folder. + +## Reference +[1] +https://github.com/Limitex/ComfyUI-Diffusers +[2] +https://github.com/Tencent/HunyuanDiT/pull/59 diff --git a/PyTorch/built-in/mlm/HunyuanDiT/comfyui-hydit/__init__.py b/PyTorch/built-in/mlm/HunyuanDiT/comfyui-hydit/__init__.py new file mode 100644 index 0000000000000000000000000000000000000000..ee645d67e7e7dcc87d5a66f104197569e88c2c89 --- /dev/null +++ b/PyTorch/built-in/mlm/HunyuanDiT/comfyui-hydit/__init__.py @@ -0,0 +1,4 @@ +from .nodes import * +#aa = DiffusersSampler() +#print(aa) +__all__ = ["NODE_CLASS_MAPPINGS", "NODE_DISPLAY_NAME_MAPPINGS"] diff --git a/PyTorch/built-in/mlm/HunyuanDiT/comfyui-hydit/clip.py b/PyTorch/built-in/mlm/HunyuanDiT/comfyui-hydit/clip.py new file mode 100644 index 0000000000000000000000000000000000000000..0dd2690f8af7402e4897f8cfe7b9d46345469d3b --- /dev/null +++ b/PyTorch/built-in/mlm/HunyuanDiT/comfyui-hydit/clip.py @@ -0,0 +1,150 @@ +import comfy.supported_models_base +import comfy.latent_formats +import comfy.model_patcher +import comfy.model_base +import comfy.utils +from .hydit.modules.text_encoder import MT5Embedder +from transformers import BertModel, BertTokenizer, AutoTokenizer +import torch +import os +from transformers import T5Config, T5EncoderModel, BertConfig, BertModel +from transformers import AutoTokenizer, modeling_utils +#import pdb + +class CLIP: + def __init__(self, root, text_encoder_path = None, t5_text_encoder_path = None): + self.device = "cuda" if torch.cuda.is_available() else "cpu" + if text_encoder_path == None: + text_encoder_path = os.path.join(root,"clip_text_encoder") + clip_text_encoder = BertModel.from_pretrained(str(text_encoder_path), False, revision=None).to(self.device) + else: + config = BertConfig.from_json_file(os.path.join(os.path.dirname(os.path.realpath(__file__)),"config_clip.json")) + with modeling_utils.no_init_weights(): + clip_text_encoder = BertModel(config) + sd = comfy.utils.load_torch_file(text_encoder_path) + prefix = "bert." + state_dict = {} + for key in sd: + nkey = key + if key.startswith(prefix): + nkey = key[len(prefix):] + state_dict[nkey] = sd[key] + + m, e = clip_text_encoder.load_state_dict(state_dict, strict=False) + if len(m) > 0 or len(e) > 0: + print(f"HYDiT: clip missing {len(m)} keys ({len(e)} extra)") + #clip_text_encoder.load_state_dict(sd, strict=False) + clip_text_encoder.eval().to(self.device) + + tokenizer_path = os.path.join(os.path.dirname(os.path.realpath(__file__)), "tokenizer_clip") + self.tokenizer = HyBertTokenizer(tokenizer_path) + #assert(0) + + if t5_text_encoder_path == None: + t5_text_encoder_path = os.path.join(root,'mt5') + embedder_t5 = MT5Embedder(t5_text_encoder_path, torch_dtype=torch.float16, max_length=256) + self.tokenizer_t5 = HyT5Tokenizer(embedder_t5.tokenizer, max_length=embedder_t5.max_length) + self.embedder_t5 = embedder_t5.model + else: + + embedder_t5 = MT5Embedder(t5_text_encoder_path, torch_dtype=torch.float16, max_length=256, ksampler = True) + self.tokenizer_t5 = HyT5Tokenizer(embedder_t5.tokenizer, max_length=embedder_t5.max_length) + self.embedder_t5 = embedder_t5.model + + + self.cond_stage_model = clip_text_encoder + + + def tokenize(self, text): + tokens = self.tokenizer.tokenize(text) + t5_tokens = self.tokenizer_t5.tokenize(text) + tokens.update(t5_tokens) + return tokens + + def tokenize_t5(self, text): + return self.tokenizer_t5.tokenize(text) + + def encode_from_tokens(self, tokens, return_pooled=False): + attention_mask = tokens['attention_mask'].to(self.device) + with torch.no_grad(): + prompt_embeds = self.cond_stage_model( + tokens['text_input_ids'].to(self.device), + attention_mask=attention_mask + ) + prompt_embeds = prompt_embeds[0] + t5_attention_mask = tokens['t5_attention_mask'].to(self.device) + with torch.no_grad(): + t5_prompt_cond = self.embedder_t5( + tokens['t5_text_input_ids'].to(self.device), + attention_mask=t5_attention_mask + ) + t5_embeds = t5_prompt_cond[0] + + addit_embeds = { + "t5_embeds": t5_embeds, + "attention_mask": attention_mask.float(), + "t5_attention_mask": t5_attention_mask.float() + } + prompt_embeds.addit_embeds = addit_embeds + + if return_pooled: + return prompt_embeds, None + else: + return prompt_embeds + +class HyBertTokenizer: + def __init__(self, tokenizer_path=None, max_length=77, truncation=True, return_attention_mask=True, device='cpu'): + self.tokenizer = BertTokenizer.from_pretrained(str(tokenizer_path)) + self.max_length = self.tokenizer.model_max_length or max_length + self.truncation = truncation + self.return_attention_mask = return_attention_mask + self.device = device + + def tokenize(self, text:str): + text_inputs = self.tokenizer( + text, + padding="max_length", + max_length=self.max_length, + truncation=self.truncation, + return_attention_mask=self.return_attention_mask, + add_special_tokens = True, + return_tensors="pt", + ) + text_input_ids = text_inputs.input_ids + attention_mask = text_inputs.attention_mask + tokens = { + 'text_input_ids': text_input_ids, + 'attention_mask': attention_mask + } + return tokens + +class HyT5Tokenizer: + def __init__(self, tokenizer, tokenizer_path = None, max_length=77, truncation=True, return_attention_mask=True, device='cpu'): + if tokenizer_path: + self.tokenizer = AutoTokenizer.from_pretrained(str(tokenizer_path)) + else: + self.tokenizer = tokenizer + + self.max_length = max_length + self.truncation = truncation + self.return_attention_mask = return_attention_mask + self.device = device + + def tokenize(self, text:str): + text_inputs = self.tokenizer( + text, + padding="max_length", + max_length=self.max_length, + truncation=self.truncation, + return_attention_mask=self.return_attention_mask, + add_special_tokens = True, + return_tensors="pt", + ) + text_input_ids = text_inputs.input_ids + attention_mask = text_inputs.attention_mask + tokens = { + 't5_text_input_ids': text_input_ids, + 't5_attention_mask': attention_mask + } + return tokens + diff --git a/PyTorch/built-in/mlm/HunyuanDiT/comfyui-hydit/config_clip.json b/PyTorch/built-in/mlm/HunyuanDiT/comfyui-hydit/config_clip.json new file mode 100644 index 0000000000000000000000000000000000000000..f6298741b427e1045bae70d7f7c62b53641ad0a5 --- /dev/null +++ b/PyTorch/built-in/mlm/HunyuanDiT/comfyui-hydit/config_clip.json @@ -0,0 +1,34 @@ +{ + "_name_or_path": "hfl/chinese-roberta-wwm-ext-large", + "architectures": [ + "BertModel" + ], + "attention_probs_dropout_prob": 0.1, + "bos_token_id": 0, + "classifier_dropout": null, + "directionality": "bidi", + "eos_token_id": 2, + "hidden_act": "gelu", + "hidden_dropout_prob": 0.1, + "hidden_size": 1024, + "initializer_range": 0.02, + "intermediate_size": 4096, + "layer_norm_eps": 1e-12, + "max_position_embeddings": 512, + "model_type": "bert", + "num_attention_heads": 16, + "num_hidden_layers": 24, + "output_past": true, + "pad_token_id": 0, + "pooler_fc_size": 768, + "pooler_num_attention_heads": 12, + "pooler_num_fc_layers": 3, + "pooler_size_per_head": 128, + "pooler_type": "first_token_transform", + "position_embedding_type": "absolute", + "torch_dtype": "float32", + "transformers_version": "4.22.1", + "type_vocab_size": 2, + "use_cache": true, + "vocab_size": 47020 +} diff --git a/PyTorch/built-in/mlm/HunyuanDiT/comfyui-hydit/config_mt5.json b/PyTorch/built-in/mlm/HunyuanDiT/comfyui-hydit/config_mt5.json new file mode 100644 index 0000000000000000000000000000000000000000..a9f8cc780dd2b8a4cd8af99b90263c3dc41a842a --- /dev/null +++ b/PyTorch/built-in/mlm/HunyuanDiT/comfyui-hydit/config_mt5.json @@ -0,0 +1,28 @@ +{ + "_name_or_path": "/home/patrick/t5/mt5-xl", + "architectures": [ + "MT5ForConditionalGeneration" + ], + "d_ff": 5120, + "d_kv": 64, + "d_model": 2048, + "decoder_start_token_id": 0, + "dropout_rate": 0.1, + "eos_token_id": 1, + "feed_forward_proj": "gated-gelu", + "initializer_factor": 1.0, + "is_encoder_decoder": true, + "layer_norm_epsilon": 1e-06, + "model_type": "mt5", + "num_decoder_layers": 24, + "num_heads": 32, + "num_layers": 24, + "output_past": true, + "pad_token_id": 0, + "relative_attention_num_buckets": 32, + "tie_word_embeddings": false, + "tokenizer_class": "T5Tokenizer", + "transformers_version": "4.10.0.dev0", + "use_cache": true, + "vocab_size": 250112 +} diff --git a/PyTorch/built-in/mlm/HunyuanDiT/comfyui-hydit/constant.py b/PyTorch/built-in/mlm/HunyuanDiT/comfyui-hydit/constant.py new file mode 100644 index 0000000000000000000000000000000000000000..0937ffd874e02edaf318921e07c0ff952e3ee18b --- /dev/null +++ b/PyTorch/built-in/mlm/HunyuanDiT/comfyui-hydit/constant.py @@ -0,0 +1,10 @@ +import os +from .hydit.constants import SAMPLER_FACTORY + +base_path = os.path.dirname(os.path.realpath(__file__)) +HUNYUAN_PATH = os.path.join(base_path, "..", "..", "models", "hunyuan") +SCHEDULERS_hunyuan = list(SAMPLER_FACTORY.keys()) + + +T5_PATH = os.path.join(base_path, "..", "..", "models", "t5") +LORA_PATH = os.path.join(base_path, "..", "..", "models", "loras") \ No newline at end of file diff --git a/PyTorch/built-in/mlm/HunyuanDiT/comfyui-hydit/dit.py b/PyTorch/built-in/mlm/HunyuanDiT/comfyui-hydit/dit.py new file mode 100644 index 0000000000000000000000000000000000000000..237f542f0cb9c46c8c1dd46fd11ed04132aefcf0 --- /dev/null +++ b/PyTorch/built-in/mlm/HunyuanDiT/comfyui-hydit/dit.py @@ -0,0 +1,145 @@ +import comfy.supported_models_base +import comfy.latent_formats +import comfy.model_patcher +import comfy.model_base +import comfy.utils +from comfy import model_management +from .supported_dit_models import HunYuan_DiT, HYDiT_Model, ModifiedHunYuanDiT +from .clip import CLIP +import os +import folder_paths +import torch + +sampling_settings = { + "beta_schedule" : "linear", + "linear_start" : 0.00085, + "linear_end" : 0.03, + "timesteps" : 1000, +} + +hydit_conf = { + "G/2": { # Seems to be the main one + "unet_config": { + "depth" : 40, + "num_heads" : 16, + "patch_size" : 2, + "hidden_size" : 1408, + "mlp_ratio" : 4.3637, + "input_size": (1024//8, 1024//8), + #"disable_unet_model_creation": True, + }, + "sampling_settings" : sampling_settings, + }, +} + +def load_dit(model_path, output_clip=True, output_model=True, output_vae=True, MODEL_PATH = None, VAE_PATH = None): + if MODEL_PATH: + state_dict = comfy.utils.load_torch_file(MODEL_PATH) + else: + state_dict = comfy.utils.load_torch_file(os.path.join(model_path, "t2i", "model", "pytorch_model_ema.pt")) + + + state_dict = state_dict.get("model", state_dict) + parameters = comfy.utils.calculate_parameters(state_dict) + unet_dtype = model_management.unet_dtype(model_params=parameters) + load_device = comfy.model_management.get_torch_device() + offload_device = comfy.model_management.unet_offload_device() + clip = None, + vae = None + model_patcher = None + + # ignore fp8/etc and use directly for now + manual_cast_dtype = model_management.unet_manual_cast(unet_dtype, load_device) + root = os.path.join(model_path, "t2i") + if manual_cast_dtype: + print(f"DiT: falling back to {manual_cast_dtype}") + unet_dtype = manual_cast_dtype + + #model_conf["unet_config"]["num_classes"] = state_dict["y_embedder.embedding_table.weight"].shape[0] - 1 # adj. for empty + + if output_model: + model_conf = HunYuan_DiT(hydit_conf["G/2"]) + model = HYDiT_Model( + model_conf, + model_type=comfy.model_base.ModelType.V_PREDICTION, + device=model_management.get_torch_device() + ) + + #print(model_conf.unet_config) + #assert(0) + + model.diffusion_model = ModifiedHunYuanDiT(model_conf.dit_conf, **model_conf.unet_config).half().to(load_device) + + model.diffusion_model.load_state_dict(state_dict) + model.diffusion_model.eval() + model.diffusion_model.to(unet_dtype) + + model_patcher = comfy.model_patcher.ModelPatcher( + model, + load_device = load_device, + offload_device = offload_device, + current_device = "cpu", + ) + if output_clip: + clip = CLIP(root) + + if output_vae: + if VAE_PATH: + vae_path = VAE_PATH + else: + vae_path = os.path.join(root, "sdxl-vae-fp16-fix", "diffusion_pytorch_model.safetensors") + #print(vae_path) + sd = comfy.utils.load_torch_file(vae_path) + vae = comfy.sd.VAE(sd=sd) + + return (model_patcher, clip, vae) + + +def load_checkpoint(model_path): + + state_dict = comfy.utils.load_torch_file(model_path) + + + state_dict = state_dict.get("model", state_dict) + parameters = comfy.utils.calculate_parameters(state_dict) + unet_dtype = model_management.unet_dtype(model_params=parameters) + load_device = comfy.model_management.get_torch_device() + offload_device = comfy.model_management.unet_offload_device() + model_patcher = None + + # ignore fp8/etc and use directly for now + manual_cast_dtype = model_management.unet_manual_cast(unet_dtype, load_device) + if manual_cast_dtype: + print(f"DiT: falling back to {manual_cast_dtype}") + unet_dtype = manual_cast_dtype + + + model_conf = HunYuan_DiT(hydit_conf["G/2"]) + model = HYDiT_Model( + model_conf, + model_type=comfy.model_base.ModelType.V_PREDICTION, + device=model_management.get_torch_device() + ) + + + model.diffusion_model = ModifiedHunYuanDiT(model_conf.dit_conf, **model_conf.unet_config).half().to(load_device) + + model.diffusion_model.load_state_dict(state_dict) + model.diffusion_model.eval() + model.diffusion_model.to(unet_dtype) + + model_patcher = comfy.model_patcher.ModelPatcher( + model, + load_device = load_device, + offload_device = offload_device, + current_device = "cpu",) + return (model_patcher,) + + + +def load_vae(vae_path): + + sd = comfy.utils.load_torch_file(vae_path) + vae = comfy.sd.VAE(sd=sd) + + return (vae,) \ No newline at end of file diff --git a/PyTorch/built-in/mlm/HunyuanDiT/comfyui-hydit/hydit/__init__.py b/PyTorch/built-in/mlm/HunyuanDiT/comfyui-hydit/hydit/__init__.py new file mode 100644 index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391 diff --git a/PyTorch/built-in/mlm/HunyuanDiT/comfyui-hydit/hydit/annotator/dwpose/__init__.py b/PyTorch/built-in/mlm/HunyuanDiT/comfyui-hydit/hydit/annotator/dwpose/__init__.py new file mode 100644 index 0000000000000000000000000000000000000000..2d17d0033b243cad48f26f5555d3dadac266a8f6 --- /dev/null +++ b/PyTorch/built-in/mlm/HunyuanDiT/comfyui-hydit/hydit/annotator/dwpose/__init__.py @@ -0,0 +1,143 @@ +# Openpose +# Original from CMU https://github.com/CMU-Perceptual-Computing-Lab/openpose +# 2nd Edited by https://github.com/Hzzone/pytorch-openpose +# 3rd Edited by ControlNet +# 4th Edited by ControlNet (added face and correct hands) + +import os +import random + +os.environ["KMP_DUPLICATE_LIB_OK"] = "TRUE" + +import torch +import numpy as np +from . import util +from .wholebody import Wholebody + + +def draw_pose(pose, H, W, draw_body=True): + bodies = pose['bodies'] + faces = pose['faces'] + hands = pose['hands'] + candidate = bodies['candidate'] + subset = bodies['subset'] + canvas = np.zeros(shape=(H, W, 3), dtype=np.uint8) + + if draw_body: + canvas = util.draw_bodypose(canvas, candidate, subset) + + canvas = util.draw_handpose(canvas, hands) + + canvas = util.draw_facepose(canvas, faces) + + return canvas + + +def keypoint2bbox(keypoints): + valid_keypoints = keypoints[keypoints[:, 0] >= 0] # Ignore keypoints with confidence 0 + if len(valid_keypoints) == 0: + return np.zeros(4) + x_min, y_min = np.min(valid_keypoints, axis=0) + x_max, y_max = np.max(valid_keypoints, axis=0) + + return np.array([x_min, y_min, x_max, y_max]) + +def expand_bboxes(bboxes, expansion_rate=0.5, image_shape=(0, 0)): + expanded_bboxes = [] + for bbox in bboxes: + x_min, y_min, x_max, y_max = map(int, bbox) + width = x_max - x_min + height = y_max - y_min + + # 扩展宽度和高度 + new_width = width * (1 + expansion_rate) + new_height = height * (1 + expansion_rate) + + # 计算新的边界框坐标 + x_min_new = max(0, x_min - (new_width - width) / 2) + x_max_new = min(image_shape[1], x_max + (new_width - width) / 2) + y_min_new = max(0, y_min - (new_height - height) / 2) + y_max_new = min(image_shape[0], y_max + (new_height - height) / 2) + + expanded_bboxes.append([x_min_new, y_min_new, x_max_new, y_max_new]) + + return expanded_bboxes + +def create_mask(image_width, image_height, bboxs): + mask = np.zeros((image_height, image_width), dtype=np.float32) + for bbox in bboxs: + x1, y1, x2, y2 = map(int, bbox) + mask[y1:y2+1, x1:x2+1] = 1.0 + return mask + +threshold = 0.4 +class DWposeDetector: + def __init__(self): + + self.pose_estimation = Wholebody() + + def __call__(self, oriImg, return_index=False, return_yolo=False, return_mask=False): + oriImg = oriImg.copy() + H, W, C = oriImg.shape + with torch.no_grad(): + candidate, subset = self.pose_estimation(oriImg) + candidate = np.zeros((1, 134, 2), dtype=np.float32) if candidate is None else candidate + subset = np.zeros((1, 134), dtype=np.float32) if subset is None else subset + nums, keys, locs = candidate.shape + candidate[..., 0] /= float(W) + candidate[..., 1] /= float(H) + # import pdb; pdb.set_trace() + if return_yolo: + candidate[subset < threshold] = -0.1 + subset = np.expand_dims(subset >= threshold, axis=-1) + keypoint = np.concatenate([candidate, subset], axis=-1) + + # return pose + hand + return np.concatenate([keypoint[:, :18], keypoint[:, 92:]], axis=1) + + body = candidate[:, :18].copy() + body = body.reshape(nums * 18, locs) + score = subset[:, :18] + for i in range(len(score)): + for j in range(len(score[i])): + if score[i][j] > threshold: + score[i][j] = int(18 * i + j) + else: + score[i][j] = -1 + + un_visible = subset < threshold + candidate[un_visible] = -1 + + foot = candidate[:, 18:24] + + faces = candidate[:, 24:92] + + hands1 = candidate[:, 92:113] + hands2 = candidate[:, 113:] + hands = np.vstack([hands1, hands2]) + + # import pdb; pdb.set_trace() + hands_ = hands[hands.max(axis=(1, 2)) > 0] + if len(hands_) == 0: + bbox = np.array([0, 0, 0, 0]).astype(int) + else: + hand_random = random.choice(hands_) + bbox = (keypoint2bbox(hand_random) * H).astype(int) # [0, 1] -> [h, w] + + + + bodies = dict(candidate=body, subset=score) + pose = dict(bodies=bodies, hands=hands, faces=faces) + + if return_mask: + bbox = [(keypoint2bbox(hand) * H).astype(int) for hand in hands_] + # bbox = expand_bboxes(bbox, expansion_rate=0.5, image_shape=(H, W)) + mask = create_mask(W, H, bbox) + return draw_pose(pose, H, W), mask + + if return_index: + return pose + else: + return draw_pose(pose, H, W), bbox + + diff --git a/PyTorch/built-in/mlm/HunyuanDiT/comfyui-hydit/hydit/annotator/dwpose/onnxdet.py b/PyTorch/built-in/mlm/HunyuanDiT/comfyui-hydit/hydit/annotator/dwpose/onnxdet.py new file mode 100644 index 0000000000000000000000000000000000000000..48056f54338de43cbd3430339b957922f37fc8c8 --- /dev/null +++ b/PyTorch/built-in/mlm/HunyuanDiT/comfyui-hydit/hydit/annotator/dwpose/onnxdet.py @@ -0,0 +1,129 @@ +import cv2 +import numpy as np + +import onnxruntime + + +def nms(boxes, scores, nms_thr): + """Single class NMS implemented in Numpy.""" + x1 = boxes[:, 0] + y1 = boxes[:, 1] + x2 = boxes[:, 2] + y2 = boxes[:, 3] + + areas = (x2 - x1 + 1) * (y2 - y1 + 1) + order = scores.argsort()[::-1] + + keep = [] + while order.size > 0: + i = order[0] + keep.append(i) + xx1 = np.maximum(x1[i], x1[order[1:]]) + yy1 = np.maximum(y1[i], y1[order[1:]]) + xx2 = np.minimum(x2[i], x2[order[1:]]) + yy2 = np.minimum(y2[i], y2[order[1:]]) + + w = np.maximum(0.0, xx2 - xx1 + 1) + h = np.maximum(0.0, yy2 - yy1 + 1) + inter = w * h + ovr = inter / (areas[i] + areas[order[1:]] - inter) + + inds = np.where(ovr <= nms_thr)[0] + order = order[inds + 1] + + return keep + + +def multiclass_nms(boxes, scores, nms_thr, score_thr): + """Multiclass NMS implemented in Numpy. Class-aware version.""" + final_dets = [] + num_classes = scores.shape[1] + for cls_ind in range(num_classes): + cls_scores = scores[:, cls_ind] + valid_score_mask = cls_scores > score_thr + if valid_score_mask.sum() == 0: + continue + else: + valid_scores = cls_scores[valid_score_mask] + valid_boxes = boxes[valid_score_mask] + keep = nms(valid_boxes, valid_scores, nms_thr) + if len(keep) > 0: + cls_inds = np.ones((len(keep), 1)) * cls_ind + dets = np.concatenate( + [valid_boxes[keep], valid_scores[keep, None], cls_inds], 1 + ) + final_dets.append(dets) + if len(final_dets) == 0: + return None + return np.concatenate(final_dets, 0) + + +def demo_postprocess(outputs, img_size, p6=False): + grids = [] + expanded_strides = [] + strides = [8, 16, 32] if not p6 else [8, 16, 32, 64] + + hsizes = [img_size[0] // stride for stride in strides] + wsizes = [img_size[1] // stride for stride in strides] + + for hsize, wsize, stride in zip(hsizes, wsizes, strides): + xv, yv = np.meshgrid(np.arange(wsize), np.arange(hsize)) + grid = np.stack((xv, yv), 2).reshape(1, -1, 2) + grids.append(grid) + shape = grid.shape[:2] + expanded_strides.append(np.full((*shape, 1), stride)) + + grids = np.concatenate(grids, 1) + expanded_strides = np.concatenate(expanded_strides, 1) + outputs[..., :2] = (outputs[..., :2] + grids) * expanded_strides + outputs[..., 2:4] = np.exp(outputs[..., 2:4]) * expanded_strides + + return outputs + + +def preprocess(img, input_size, swap=(2, 0, 1)): + if len(img.shape) == 3: + padded_img = np.ones((input_size[0], input_size[1], 3), dtype=np.uint8) * 114 + else: + padded_img = np.ones(input_size, dtype=np.uint8) * 114 + + r = min(input_size[0] / img.shape[0], input_size[1] / img.shape[1]) + resized_img = cv2.resize( + img, + (int(img.shape[1] * r), int(img.shape[0] * r)), + interpolation=cv2.INTER_LINEAR, + ).astype(np.uint8) + padded_img[: int(img.shape[0] * r), : int(img.shape[1] * r)] = resized_img + + padded_img = padded_img.transpose(swap) + padded_img = np.ascontiguousarray(padded_img, dtype=np.float32) + return padded_img, r + + +def inference_detector(session, oriImg): + input_shape = (640, 640) + img, ratio = preprocess(oriImg, input_shape) + + ort_inputs = {session.get_inputs()[0].name: img[None, :, :, :]} + output = session.run(None, ort_inputs) + predictions = demo_postprocess(output[0], input_shape)[0] + + boxes = predictions[:, :4] + scores = predictions[:, 4:5] * predictions[:, 5:] + + boxes_xyxy = np.ones_like(boxes) + boxes_xyxy[:, 0] = boxes[:, 0] - boxes[:, 2] / 2. + boxes_xyxy[:, 1] = boxes[:, 1] - boxes[:, 3] / 2. + boxes_xyxy[:, 2] = boxes[:, 0] + boxes[:, 2] / 2. + boxes_xyxy[:, 3] = boxes[:, 1] + boxes[:, 3] / 2. + boxes_xyxy /= ratio + dets = multiclass_nms(boxes_xyxy, scores, nms_thr=0.45, score_thr=0.1) + if dets is not None: + final_boxes, final_scores, final_cls_inds = dets[:, :4], dets[:, 4], dets[:, 5] + isscore = final_scores > 0.3 + iscat = final_cls_inds == 0 + isbbox = [i and j for (i, j) in zip(isscore, iscat)] + final_boxes = final_boxes[isbbox] + return final_boxes + else: + return None diff --git a/PyTorch/built-in/mlm/HunyuanDiT/comfyui-hydit/hydit/annotator/dwpose/onnxpose.py b/PyTorch/built-in/mlm/HunyuanDiT/comfyui-hydit/hydit/annotator/dwpose/onnxpose.py new file mode 100644 index 0000000000000000000000000000000000000000..79cd4a06241123af81ea22446a4ca8816716443f --- /dev/null +++ b/PyTorch/built-in/mlm/HunyuanDiT/comfyui-hydit/hydit/annotator/dwpose/onnxpose.py @@ -0,0 +1,360 @@ +from typing import List, Tuple + +import cv2 +import numpy as np +import onnxruntime as ort + +def preprocess( + img: np.ndarray, out_bbox, input_size: Tuple[int, int] = (192, 256) +) -> Tuple[np.ndarray, np.ndarray, np.ndarray]: + """Do preprocessing for RTMPose model inference. + + Args: + img (np.ndarray): Input image in shape. + input_size (tuple): Input image size in shape (w, h). + + Returns: + tuple: + - resized_img (np.ndarray): Preprocessed image. + - center (np.ndarray): Center of image. + - scale (np.ndarray): Scale of image. + """ + # get shape of image + img_shape = img.shape[:2] + out_img, out_center, out_scale = [], [], [] + if len(out_bbox) == 0: + out_bbox = [[0, 0, img_shape[1], img_shape[0]]] + for i in range(len(out_bbox)): + x0 = out_bbox[i][0] + y0 = out_bbox[i][1] + x1 = out_bbox[i][2] + y1 = out_bbox[i][3] + bbox = np.array([x0, y0, x1, y1]) + + # get center and scale + center, scale = bbox_xyxy2cs(bbox, padding=1.25) + + # do affine transformation + resized_img, scale = top_down_affine(input_size, scale, center, img) + + # normalize image + mean = np.array([123.675, 116.28, 103.53]) + std = np.array([58.395, 57.12, 57.375]) + resized_img = (resized_img - mean) / std + + out_img.append(resized_img) + out_center.append(center) + out_scale.append(scale) + + return out_img, out_center, out_scale + + +def inference(sess: ort.InferenceSession, img: np.ndarray) -> np.ndarray: + """Inference RTMPose model. + + Args: + sess (ort.InferenceSession): ONNXRuntime session. + img (np.ndarray): Input image in shape. + + Returns: + outputs (np.ndarray): Output of RTMPose model. + """ + all_out = [] + # build input + for i in range(len(img)): + input = [img[i].transpose(2, 0, 1)] + + # build output + sess_input = {sess.get_inputs()[0].name: input} + sess_output = [] + for out in sess.get_outputs(): + sess_output.append(out.name) + + # run model + outputs = sess.run(sess_output, sess_input) + all_out.append(outputs) + + return all_out + + +def postprocess(outputs: List[np.ndarray], + model_input_size: Tuple[int, int], + center: Tuple[int, int], + scale: Tuple[int, int], + simcc_split_ratio: float = 2.0 + ) -> Tuple[np.ndarray, np.ndarray]: + """Postprocess for RTMPose model output. + + Args: + outputs (np.ndarray): Output of RTMPose model. + model_input_size (tuple): RTMPose model Input image size. + center (tuple): Center of bbox in shape (x, y). + scale (tuple): Scale of bbox in shape (w, h). + simcc_split_ratio (float): Split ratio of simcc. + + Returns: + tuple: + - keypoints (np.ndarray): Rescaled keypoints. + - scores (np.ndarray): Model predict scores. + """ + all_key = [] + all_score = [] + for i in range(len(outputs)): + # use simcc to decode + simcc_x, simcc_y = outputs[i] + keypoints, scores = decode(simcc_x, simcc_y, simcc_split_ratio) + + # rescale keypoints + keypoints = keypoints / model_input_size * scale[i] + center[i] - scale[i] / 2 + all_key.append(keypoints[0]) + all_score.append(scores[0]) + + return np.array(all_key), np.array(all_score) + + +def bbox_xyxy2cs(bbox: np.ndarray, + padding: float = 1.) -> Tuple[np.ndarray, np.ndarray]: + """Transform the bbox format from (x,y,w,h) into (center, scale) + + Args: + bbox (ndarray): Bounding box(es) in shape (4,) or (n, 4), formatted + as (left, top, right, bottom) + padding (float): BBox padding factor that will be multilied to scale. + Default: 1.0 + + Returns: + tuple: A tuple containing center and scale. + - np.ndarray[float32]: Center (x, y) of the bbox in shape (2,) or + (n, 2) + - np.ndarray[float32]: Scale (w, h) of the bbox in shape (2,) or + (n, 2) + """ + # convert single bbox from (4, ) to (1, 4) + dim = bbox.ndim + if dim == 1: + bbox = bbox[None, :] + + # get bbox center and scale + x1, y1, x2, y2 = np.hsplit(bbox, [1, 2, 3]) + center = np.hstack([x1 + x2, y1 + y2]) * 0.5 + scale = np.hstack([x2 - x1, y2 - y1]) * padding + + if dim == 1: + center = center[0] + scale = scale[0] + + return center, scale + + +def _fix_aspect_ratio(bbox_scale: np.ndarray, + aspect_ratio: float) -> np.ndarray: + """Extend the scale to match the given aspect ratio. + + Args: + scale (np.ndarray): The image scale (w, h) in shape (2, ) + aspect_ratio (float): The ratio of ``w/h`` + + Returns: + np.ndarray: The reshaped image scale in (2, ) + """ + w, h = np.hsplit(bbox_scale, [1]) + bbox_scale = np.where(w > h * aspect_ratio, + np.hstack([w, w / aspect_ratio]), + np.hstack([h * aspect_ratio, h])) + return bbox_scale + + +def _rotate_point(pt: np.ndarray, angle_rad: float) -> np.ndarray: + """Rotate a point by an angle. + + Args: + pt (np.ndarray): 2D point coordinates (x, y) in shape (2, ) + angle_rad (float): rotation angle in radian + + Returns: + np.ndarray: Rotated point in shape (2, ) + """ + sn, cs = np.sin(angle_rad), np.cos(angle_rad) + rot_mat = np.array([[cs, -sn], [sn, cs]]) + return rot_mat @ pt + + +def _get_3rd_point(a: np.ndarray, b: np.ndarray) -> np.ndarray: + """To calculate the affine matrix, three pairs of points are required. This + function is used to get the 3rd point, given 2D points a & b. + + The 3rd point is defined by rotating vector `a - b` by 90 degrees + anticlockwise, using b as the rotation center. + + Args: + a (np.ndarray): The 1st point (x,y) in shape (2, ) + b (np.ndarray): The 2nd point (x,y) in shape (2, ) + + Returns: + np.ndarray: The 3rd point. + """ + direction = a - b + c = b + np.r_[-direction[1], direction[0]] + return c + + +def get_warp_matrix(center: np.ndarray, + scale: np.ndarray, + rot: float, + output_size: Tuple[int, int], + shift: Tuple[float, float] = (0., 0.), + inv: bool = False) -> np.ndarray: + """Calculate the affine transformation matrix that can warp the bbox area + in the input image to the output size. + + Args: + center (np.ndarray[2, ]): Center of the bounding box (x, y). + scale (np.ndarray[2, ]): Scale of the bounding box + wrt [width, height]. + rot (float): Rotation angle (degree). + output_size (np.ndarray[2, ] | list(2,)): Size of the + destination heatmaps. + shift (0-100%): Shift translation ratio wrt the width/height. + Default (0., 0.). + inv (bool): Option to inverse the affine transform direction. + (inv=False: src->dst or inv=True: dst->src) + + Returns: + np.ndarray: A 2x3 transformation matrix + """ + shift = np.array(shift) + src_w = scale[0] + dst_w = output_size[0] + dst_h = output_size[1] + + # compute transformation matrix + rot_rad = np.deg2rad(rot) + src_dir = _rotate_point(np.array([0., src_w * -0.5]), rot_rad) + dst_dir = np.array([0., dst_w * -0.5]) + + # get four corners of the src rectangle in the original image + src = np.zeros((3, 2), dtype=np.float32) + src[0, :] = center + scale * shift + src[1, :] = center + src_dir + scale * shift + src[2, :] = _get_3rd_point(src[0, :], src[1, :]) + + # get four corners of the dst rectangle in the input image + dst = np.zeros((3, 2), dtype=np.float32) + dst[0, :] = [dst_w * 0.5, dst_h * 0.5] + dst[1, :] = np.array([dst_w * 0.5, dst_h * 0.5]) + dst_dir + dst[2, :] = _get_3rd_point(dst[0, :], dst[1, :]) + + if inv: + warp_mat = cv2.getAffineTransform(np.float32(dst), np.float32(src)) + else: + warp_mat = cv2.getAffineTransform(np.float32(src), np.float32(dst)) + + return warp_mat + + +def top_down_affine(input_size: dict, bbox_scale: dict, bbox_center: dict, + img: np.ndarray) -> Tuple[np.ndarray, np.ndarray]: + """Get the bbox image as the model input by affine transform. + + Args: + input_size (dict): The input size of the model. + bbox_scale (dict): The bbox scale of the img. + bbox_center (dict): The bbox center of the img. + img (np.ndarray): The original image. + + Returns: + tuple: A tuple containing center and scale. + - np.ndarray[float32]: img after affine transform. + - np.ndarray[float32]: bbox scale after affine transform. + """ + w, h = input_size + warp_size = (int(w), int(h)) + + # reshape bbox to fixed aspect ratio + bbox_scale = _fix_aspect_ratio(bbox_scale, aspect_ratio=w / h) + + # get the affine matrix + center = bbox_center + scale = bbox_scale + rot = 0 + warp_mat = get_warp_matrix(center, scale, rot, output_size=(w, h)) + + # do affine transform + img = cv2.warpAffine(img, warp_mat, warp_size, flags=cv2.INTER_LINEAR) + + return img, bbox_scale + + +def get_simcc_maximum(simcc_x: np.ndarray, + simcc_y: np.ndarray) -> Tuple[np.ndarray, np.ndarray]: + """Get maximum response location and value from simcc representations. + + Note: + instance number: N + num_keypoints: K + heatmap height: H + heatmap width: W + + Args: + simcc_x (np.ndarray): x-axis SimCC in shape (K, Wx) or (N, K, Wx) + simcc_y (np.ndarray): y-axis SimCC in shape (K, Wy) or (N, K, Wy) + + Returns: + tuple: + - locs (np.ndarray): locations of maximum heatmap responses in shape + (K, 2) or (N, K, 2) + - vals (np.ndarray): values of maximum heatmap responses in shape + (K,) or (N, K) + """ + N, K, Wx = simcc_x.shape + simcc_x = simcc_x.reshape(N * K, -1) + simcc_y = simcc_y.reshape(N * K, -1) + + # get maximum value locations + x_locs = np.argmax(simcc_x, axis=1) + y_locs = np.argmax(simcc_y, axis=1) + locs = np.stack((x_locs, y_locs), axis=-1).astype(np.float32) + max_val_x = np.amax(simcc_x, axis=1) + max_val_y = np.amax(simcc_y, axis=1) + + # get maximum value across x and y axis + mask = max_val_x > max_val_y + max_val_x[mask] = max_val_y[mask] + vals = max_val_x + locs[vals <= 0.] = -1 + + # reshape + locs = locs.reshape(N, K, 2) + vals = vals.reshape(N, K) + + return locs, vals + + +def decode(simcc_x: np.ndarray, simcc_y: np.ndarray, + simcc_split_ratio) -> Tuple[np.ndarray, np.ndarray]: + """Modulate simcc distribution with Gaussian. + + Args: + simcc_x (np.ndarray[K, Wx]): model predicted simcc in x. + simcc_y (np.ndarray[K, Wy]): model predicted simcc in y. + simcc_split_ratio (int): The split ratio of simcc. + + Returns: + tuple: A tuple containing center and scale. + - np.ndarray[float32]: keypoints in shape (K, 2) or (n, K, 2) + - np.ndarray[float32]: scores in shape (K,) or (n, K) + """ + keypoints, scores = get_simcc_maximum(simcc_x, simcc_y) + keypoints /= simcc_split_ratio + + return keypoints, scores + + +def inference_pose(session, out_bbox, oriImg): + h, w = session.get_inputs()[0].shape[2:] + model_input_size = (w, h) + resized_img, center, scale = preprocess(oriImg, out_bbox, model_input_size) + outputs = inference(session, resized_img) + keypoints, scores = postprocess(outputs, model_input_size, center, scale) + + return keypoints, scores \ No newline at end of file diff --git a/PyTorch/built-in/mlm/HunyuanDiT/comfyui-hydit/hydit/annotator/dwpose/util.py b/PyTorch/built-in/mlm/HunyuanDiT/comfyui-hydit/hydit/annotator/dwpose/util.py new file mode 100644 index 0000000000000000000000000000000000000000..a1453ab66d3d7a2f161aa6fd45acf70729990863 --- /dev/null +++ b/PyTorch/built-in/mlm/HunyuanDiT/comfyui-hydit/hydit/annotator/dwpose/util.py @@ -0,0 +1,298 @@ +import math +import numpy as np +import matplotlib +import cv2 + + +eps = 0.01 + + +def smart_resize(x, s): + Ht, Wt = s + if x.ndim == 2: + Ho, Wo = x.shape + Co = 1 + else: + Ho, Wo, Co = x.shape + if Co == 3 or Co == 1: + k = float(Ht + Wt) / float(Ho + Wo) + return cv2.resize(x, (int(Wt), int(Ht)), interpolation=cv2.INTER_AREA if k < 1 else cv2.INTER_LANCZOS4) + else: + return np.stack([smart_resize(x[:, :, i], s) for i in range(Co)], axis=2) + + +def smart_resize_k(x, fx, fy): + if x.ndim == 2: + Ho, Wo = x.shape + Co = 1 + else: + Ho, Wo, Co = x.shape + Ht, Wt = Ho * fy, Wo * fx + if Co == 3 or Co == 1: + k = float(Ht + Wt) / float(Ho + Wo) + return cv2.resize(x, (int(Wt), int(Ht)), interpolation=cv2.INTER_AREA if k < 1 else cv2.INTER_LANCZOS4) + else: + return np.stack([smart_resize_k(x[:, :, i], fx, fy) for i in range(Co)], axis=2) + + +def padRightDownCorner(img, stride, padValue): + h = img.shape[0] + w = img.shape[1] + + pad = 4 * [None] + pad[0] = 0 # up + pad[1] = 0 # left + pad[2] = 0 if (h % stride == 0) else stride - (h % stride) # down + pad[3] = 0 if (w % stride == 0) else stride - (w % stride) # right + + img_padded = img + pad_up = np.tile(img_padded[0:1, :, :]*0 + padValue, (pad[0], 1, 1)) + img_padded = np.concatenate((pad_up, img_padded), axis=0) + pad_left = np.tile(img_padded[:, 0:1, :]*0 + padValue, (1, pad[1], 1)) + img_padded = np.concatenate((pad_left, img_padded), axis=1) + pad_down = np.tile(img_padded[-2:-1, :, :]*0 + padValue, (pad[2], 1, 1)) + img_padded = np.concatenate((img_padded, pad_down), axis=0) + pad_right = np.tile(img_padded[:, -2:-1, :]*0 + padValue, (1, pad[3], 1)) + img_padded = np.concatenate((img_padded, pad_right), axis=1) + + return img_padded, pad + + +def transfer(model, model_weights): + transfered_model_weights = {} + for weights_name in model.state_dict().keys(): + transfered_model_weights[weights_name] = model_weights['.'.join(weights_name.split('.')[1:])] + return transfered_model_weights + + +def draw_bodypose(canvas, candidate, subset): + H, W, C = canvas.shape + candidate = np.array(candidate) + subset = np.array(subset) + + stickwidth = 4 + + limbSeq = [[2, 3], [2, 6], [3, 4], [4, 5], [6, 7], [7, 8], [2, 9], [9, 10], \ + [10, 11], [2, 12], [12, 13], [13, 14], [2, 1], [1, 15], [15, 17], \ + [1, 16], [16, 18], [3, 17], [6, 18]] + + colors = [[255, 0, 0], [255, 85, 0], [255, 170, 0], [255, 255, 0], [170, 255, 0], [85, 255, 0], [0, 255, 0], \ + [0, 255, 85], [0, 255, 170], [0, 255, 255], [0, 170, 255], [0, 85, 255], [0, 0, 255], [85, 0, 255], \ + [170, 0, 255], [255, 0, 255], [255, 0, 170], [255, 0, 85]] + + for i in range(17): + for n in range(len(subset)): + index = subset[n][np.array(limbSeq[i]) - 1] + if -1 in index: + continue + Y = candidate[index.astype(int), 0] * float(W) + X = candidate[index.astype(int), 1] * float(H) + mX = np.mean(X) + mY = np.mean(Y) + length = ((X[0] - X[1]) ** 2 + (Y[0] - Y[1]) ** 2) ** 0.5 + angle = math.degrees(math.atan2(X[0] - X[1], Y[0] - Y[1])) + polygon = cv2.ellipse2Poly((int(mY), int(mX)), (int(length / 2), stickwidth), int(angle), 0, 360, 1) + # import pdb; pdb.set_trace() + cv2.fillConvexPoly(canvas, polygon, colors[i]) + + canvas = (canvas * 0.6).astype(np.uint8) + + for i in range(18): + for n in range(len(subset)): + index = int(subset[n][i]) + if index == -1: + continue + x, y = candidate[index][0:2] + x = int(x * W) + y = int(y * H) + cv2.circle(canvas, (int(x), int(y)), 4, colors[i], thickness=-1) + + return canvas + + +def draw_handpose(canvas, all_hand_peaks): + H, W, C = canvas.shape + + edges = [[0, 1], [1, 2], [2, 3], [3, 4], [0, 5], [5, 6], [6, 7], [7, 8], [0, 9], [9, 10], \ + [10, 11], [11, 12], [0, 13], [13, 14], [14, 15], [15, 16], [0, 17], [17, 18], [18, 19], [19, 20]] + + for peaks in all_hand_peaks: + peaks = np.array(peaks) + + for ie, e in enumerate(edges): + x1, y1 = peaks[e[0]] + x2, y2 = peaks[e[1]] + x1 = int(x1 * W) + y1 = int(y1 * H) + x2 = int(x2 * W) + y2 = int(y2 * H) + if x1 > eps and y1 > eps and x2 > eps and y2 > eps: + cv2.line(canvas, (x1, y1), (x2, y2), matplotlib.colors.hsv_to_rgb([ie / float(len(edges)), 1.0, 1.0]) * 255, thickness=2) + + for i, keyponit in enumerate(peaks): + x, y = keyponit + x = int(x * W) + y = int(y * H) + if x > eps and y > eps: + cv2.circle(canvas, (x, y), 4, (0, 0, 255), thickness=-1) + return canvas + + +def draw_facepose(canvas, all_lmks): + H, W, C = canvas.shape + for lmks in all_lmks: + lmks = np.array(lmks) + for lmk in lmks: + x, y = lmk + x = int(x * W) + y = int(y * H) + if x > eps and y > eps: + cv2.circle(canvas, (x, y), 3, (255, 255, 255), thickness=-1) + return canvas + + +# detect hand according to body pose keypoints +# please refer to https://github.com/CMU-Perceptual-Computing-Lab/openpose/blob/master/src/openpose/hand/handDetector.cpp +def handDetect(candidate, subset, oriImg): + # right hand: wrist 4, elbow 3, shoulder 2 + # left hand: wrist 7, elbow 6, shoulder 5 + ratioWristElbow = 0.33 + detect_result = [] + image_height, image_width = oriImg.shape[0:2] + for person in subset.astype(int): + # if any of three not detected + has_left = np.sum(person[[5, 6, 7]] == -1) == 0 + has_right = np.sum(person[[2, 3, 4]] == -1) == 0 + if not (has_left or has_right): + continue + hands = [] + #left hand + if has_left: + left_shoulder_index, left_elbow_index, left_wrist_index = person[[5, 6, 7]] + x1, y1 = candidate[left_shoulder_index][:2] + x2, y2 = candidate[left_elbow_index][:2] + x3, y3 = candidate[left_wrist_index][:2] + hands.append([x1, y1, x2, y2, x3, y3, True]) + # right hand + if has_right: + right_shoulder_index, right_elbow_index, right_wrist_index = person[[2, 3, 4]] + x1, y1 = candidate[right_shoulder_index][:2] + x2, y2 = candidate[right_elbow_index][:2] + x3, y3 = candidate[right_wrist_index][:2] + hands.append([x1, y1, x2, y2, x3, y3, False]) + + for x1, y1, x2, y2, x3, y3, is_left in hands: + # pos_hand = pos_wrist + ratio * (pos_wrist - pos_elbox) = (1 + ratio) * pos_wrist - ratio * pos_elbox + # handRectangle.x = posePtr[wrist*3] + ratioWristElbow * (posePtr[wrist*3] - posePtr[elbow*3]); + # handRectangle.y = posePtr[wrist*3+1] + ratioWristElbow * (posePtr[wrist*3+1] - posePtr[elbow*3+1]); + # const auto distanceWristElbow = getDistance(poseKeypoints, person, wrist, elbow); + # const auto distanceElbowShoulder = getDistance(poseKeypoints, person, elbow, shoulder); + # handRectangle.width = 1.5f * fastMax(distanceWristElbow, 0.9f * distanceElbowShoulder); + x = x3 + ratioWristElbow * (x3 - x2) + y = y3 + ratioWristElbow * (y3 - y2) + distanceWristElbow = math.sqrt((x3 - x2) ** 2 + (y3 - y2) ** 2) + distanceElbowShoulder = math.sqrt((x2 - x1) ** 2 + (y2 - y1) ** 2) + width = 1.5 * max(distanceWristElbow, 0.9 * distanceElbowShoulder) + # x-y refers to the center --> offset to topLeft point + # handRectangle.x -= handRectangle.width / 2.f; + # handRectangle.y -= handRectangle.height / 2.f; + x -= width / 2 + y -= width / 2 # width = height + # overflow the image + if x < 0: x = 0 + if y < 0: y = 0 + width1 = width + width2 = width + if x + width > image_width: width1 = image_width - x + if y + width > image_height: width2 = image_height - y + width = min(width1, width2) + # the max hand box value is 20 pixels + if width >= 20: + detect_result.append([int(x), int(y), int(width), is_left]) + + ''' + return value: [[x, y, w, True if left hand else False]]. + width=height since the network require squared input. + x, y is the coordinate of top left + ''' + return detect_result + + +# Written by Lvmin +def faceDetect(candidate, subset, oriImg): + # left right eye ear 14 15 16 17 + detect_result = [] + image_height, image_width = oriImg.shape[0:2] + for person in subset.astype(int): + has_head = person[0] > -1 + if not has_head: + continue + + has_left_eye = person[14] > -1 + has_right_eye = person[15] > -1 + has_left_ear = person[16] > -1 + has_right_ear = person[17] > -1 + + if not (has_left_eye or has_right_eye or has_left_ear or has_right_ear): + continue + + head, left_eye, right_eye, left_ear, right_ear = person[[0, 14, 15, 16, 17]] + + width = 0.0 + x0, y0 = candidate[head][:2] + + if has_left_eye: + x1, y1 = candidate[left_eye][:2] + d = max(abs(x0 - x1), abs(y0 - y1)) + width = max(width, d * 3.0) + + if has_right_eye: + x1, y1 = candidate[right_eye][:2] + d = max(abs(x0 - x1), abs(y0 - y1)) + width = max(width, d * 3.0) + + if has_left_ear: + x1, y1 = candidate[left_ear][:2] + d = max(abs(x0 - x1), abs(y0 - y1)) + width = max(width, d * 1.5) + + if has_right_ear: + x1, y1 = candidate[right_ear][:2] + d = max(abs(x0 - x1), abs(y0 - y1)) + width = max(width, d * 1.5) + + x, y = x0, y0 + + x -= width + y -= width + + if x < 0: + x = 0 + + if y < 0: + y = 0 + + width1 = width * 2 + width2 = width * 2 + + if x + width > image_width: + width1 = image_width - x + + if y + width > image_height: + width2 = image_height - y + + width = min(width1, width2) + + if width >= 20: + detect_result.append([int(x), int(y), int(width)]) + + return detect_result + + +# get max index of 2d array +def npmax(array): + arrayindex = array.argmax(1) + arrayvalue = array.max(1) + i = arrayvalue.argmax() + j = arrayindex[i] + return i, j diff --git a/PyTorch/built-in/mlm/HunyuanDiT/comfyui-hydit/hydit/annotator/dwpose/wholebody.py b/PyTorch/built-in/mlm/HunyuanDiT/comfyui-hydit/hydit/annotator/dwpose/wholebody.py new file mode 100644 index 0000000000000000000000000000000000000000..108fa670ceaee0a263291b87674032ea3b663066 --- /dev/null +++ b/PyTorch/built-in/mlm/HunyuanDiT/comfyui-hydit/hydit/annotator/dwpose/wholebody.py @@ -0,0 +1,56 @@ +import os +import cv2 +import numpy as np + +import onnxruntime as ort +from .onnxdet import inference_detector +from .onnxpose import inference_pose + +class Wholebody: + def __init__(self): + rank = int(os.getenv('LOCAL_RANK', '0')) + device = f'cuda:{rank}' + providers = ['CPUExecutionProvider'] if device == 'cpu' else [("CUDAExecutionProvider", {"device_id": rank})] + onnx_det = 'hydit/annotator/ckpts/yolox_l.onnx' + onnx_pose = 'hydit/annotator/ckpts/dw-ll_ucoco_384.onnx' + + self.session_det = ort.InferenceSession(path_or_bytes=onnx_det, providers=providers) + self.session_pose = ort.InferenceSession(path_or_bytes=onnx_pose, providers=providers) + + def __call__(self, oriImg): + det_result = inference_detector(self.session_det, oriImg) + if det_result is None: + return None, None + keypoints, scores = inference_pose(self.session_pose, det_result, oriImg) + + keypoints_info = np.concatenate( + (keypoints, scores[..., None]), axis=-1) + # compute neck joint + neck = np.mean(keypoints_info[:, [5, 6]], axis=1) + # neck score when visualizing pred + neck[:, 2:4] = np.logical_and( + keypoints_info[:, 5, 2:4] > 0.3, + keypoints_info[:, 6, 2:4] > 0.3).astype(int) + new_keypoints_info = np.insert( + keypoints_info, 17, neck, axis=1) + mmpose_idx = [ + 17, 6, 8, 10, 7, 9, 12, 14, 16, 13, 15, 2, 1, 4, 3 + ] + openpose_idx = [ + 1, 2, 3, 4, 6, 7, 8, 9, 10, 12, 13, 14, 15, 16, 17 + ] + new_keypoints_info[:, openpose_idx] = \ + new_keypoints_info[:, mmpose_idx] + keypoints_info = new_keypoints_info + + keypoints, scores = keypoints_info[ + ..., :2], keypoints_info[..., 2] + + return keypoints, scores + + def to(self, device): + self.session_det.set_providers([device]) + self.session_pose.set_providers([device]) + return self + + diff --git a/PyTorch/built-in/mlm/HunyuanDiT/comfyui-hydit/hydit/annotator/glyph.py b/PyTorch/built-in/mlm/HunyuanDiT/comfyui-hydit/hydit/annotator/glyph.py new file mode 100644 index 0000000000000000000000000000000000000000..8bb67813897e90e051a218fcf157ee7261dc59b5 --- /dev/null +++ b/PyTorch/built-in/mlm/HunyuanDiT/comfyui-hydit/hydit/annotator/glyph.py @@ -0,0 +1,249 @@ +# MIT License +# Copyright (c) 2023 AIGText +# https://github.com/AIGText/GlyphControl-release + +from PIL import Image, ImageFont, ImageDraw +import random +import numpy as np +import cv2 + + +# resize height to image_height first, then shrink or pad to image_width +def resize_and_pad_image(pil_image, image_size): + if isinstance(image_size, (tuple, list)) and len(image_size) == 2: + image_width, image_height = image_size + elif isinstance(image_size, int): + image_width = image_height = image_size + else: + raise ValueError(f"Image size should be int or list/tuple of int not {image_size}") + + while pil_image.size[1] >= 2 * image_height: + pil_image = pil_image.resize( + tuple(x // 2 for x in pil_image.size), resample=Image.BOX + ) + + scale = image_height / pil_image.size[1] + pil_image = pil_image.resize(tuple(round(x * scale) for x in pil_image.size), resample=Image.BICUBIC) + + # shrink + if pil_image.size[0] > image_width: + pil_image = pil_image.resize((image_width, image_height), resample=Image.BICUBIC) + + # padding + if pil_image.size[0] < image_width: + img = Image.new(mode="RGBA", size=(image_width, image_height), color=(255, 255, 255, 0)) + width, _ = pil_image.size + img.paste(pil_image, ((image_width - width) // 2, 0)) + pil_image = img + + return pil_image + + +def resize_and_pad_image2(pil_image, image_size): + if isinstance(image_size, (tuple, list)) and len(image_size) == 2: + image_width, image_height = image_size + elif isinstance(image_size, int): + image_width = image_height = image_size + else: + raise ValueError(f"Image size should be int or list/tuple of int not {image_size}") + + while pil_image.size[1] >= 2 * image_height: + pil_image = pil_image.resize( + tuple(x // 2 for x in pil_image.size), resample=Image.BOX + ) + + scale = image_height / pil_image.size[1] + pil_image = pil_image.resize(tuple(round(x * scale) for x in pil_image.size), resample=Image.BICUBIC) + + # shrink + if pil_image.size[0] > image_width: + pil_image = pil_image.resize((image_width, image_height), resample=Image.BICUBIC) + + # padding + if pil_image.size[0] < image_width: + img = Image.new(mode="RGB", size=(image_width, image_height), color="white") + width, _ = pil_image.size + img.paste(pil_image, ((image_width - width) // 2, 0)) + pil_image = img + + return pil_image + + +def draw_visual_text(image_size, bboxes, rendered_txt_values, num_rows_values=None, align="center"): + # aligns = ["center", "left", "right"] + """Render text image based on the glyph instructions, i.e., the list of tuples (text, bbox, num_rows). + Currently we just use Calibri font to render glyph images. + """ + # print(image_size, bboxes, rendered_txt_values, num_rows_values, align) + background = Image.new("RGB", image_size, "white") + font = ImageFont.truetype("simfang.ttf", encoding='utf-8', size=512) + if num_rows_values is None: + num_rows_values = [1] * len(rendered_txt_values) + + text_list = [] + for text, bbox, num_rows in zip(rendered_txt_values, bboxes, num_rows_values): + + if len(text) == 0: + continue + + text = text.strip() + if num_rows != 1: + word_tokens = text.split() + num_tokens = len(word_tokens) + index_list = range(1, num_tokens + 1) + if num_tokens > num_rows: + index_list = random.sample(index_list, num_rows) + index_list.sort() + line_list = [] + start_idx = 0 + for index in index_list: + line_list.append( + " ".join(word_tokens + [start_idx: index] + ) + ) + start_idx = index + text = "\n".join(line_list) + + if 'ratio' not in bbox or bbox['ratio'] == 0 or bbox['ratio'] < 1e-4: + image4ratio = Image.new("RGB", (512, 512), "white") + draw = ImageDraw.Draw(image4ratio) + _, _, w, h = draw.textbbox(xy=(0, 0), text=text, font=font) + ratio = w / h + else: + ratio = bbox['ratio'] + + width = int(bbox['width'] * image_size[1]) + height = int(width / ratio) + top_left_x = int(bbox['top_left_x'] * image_size[0]) + top_left_y = int(bbox['top_left_y'] * image_size[1]) + yaw = bbox['yaw'] + + text_image = Image.new("RGB", (512, 512), "white") + draw = ImageDraw.Draw(text_image) + x, y, w, h = draw.textbbox(xy=(0, 0), text=text, font=font) + text_image = Image.new("RGBA", (w, h), (255, 255, 255, 0)) + draw = ImageDraw.Draw(text_image) + draw.text((-x / 2, -y / 2), text, (0, 0, 0, 255), font=font, align=align) + + text_image_ = resize_and_pad_image2(text_image.convert('RGB'), (288, 48)) + # import pdb; pdb.set_trace() + text_list.append(np.array(text_image_)) + + text_image = resize_and_pad_image(text_image, (width, height)) + text_image = text_image.rotate(angle=-yaw, expand=True, fillcolor=(255, 255, 255, 0)) + # image = Image.new("RGB", (w, h), "white") + # draw = ImageDraw.Draw(image) + background.paste(text_image, (top_left_x, top_left_y), mask=text_image) + + return background, text_list + + +# [{'width': 0.1601562201976776, 'ratio': 81.99999451637203, 'yaw': 0.0, 'top_left_x': 0.712890625, 'top_left_y': 0.0}, +# {'width': 0.134765625, 'ratio': 34.5, 'yaw': 0.0, 'top_left_x': 0.4453125, 'top_left_y': 0.0}, + + +def insert_spaces(string, nSpace): + if nSpace == 0: + return string + new_string = "" + for char in string: + new_string += char + " " * nSpace + return new_string[:-nSpace] + + +def draw_glyph(text, font='simfang.ttf'): + if isinstance(font, str): + font = ImageFont.truetype(font, encoding='utf-8', size=512) + g_size = 50 + W, H = (512, 80) + new_font = font.font_variant(size=g_size) + img = Image.new(mode='1', size=(W, H), color=0) + draw = ImageDraw.Draw(img) + left, top, right, bottom = new_font.getbbox(text) + text_width = max(right-left, 5) + text_height = max(bottom - top, 5) + ratio = min(W*0.9/text_width, H*0.9/text_height) + new_font = font.font_variant(size=int(g_size*ratio)) + + text_width, text_height = new_font.getsize(text) + offset_x, offset_y = new_font.getoffset(text) + x = (img.width - text_width) // 2 + y = (img.height - text_height) // 2 - offset_y//2 + draw.text((x, y), text, font=new_font, fill='white') + img = np.expand_dims(np.array(img), axis=2).astype(np.float64) + + return img + + +def draw_glyph2(text, polygon, font='simfang.ttf', vertAng=10, scale=1, width=1024, height=1024, add_space=True): + if isinstance(font, str): + font = ImageFont.truetype(font, encoding='utf-8', size=60) + enlarge_polygon = polygon*scale + rect = cv2.minAreaRect(enlarge_polygon) + box = cv2.boxPoints(rect) + box = np.int0(box) + w, h = rect[1] + angle = rect[2] + if angle < -45: + angle += 90 + angle = -angle + if w < h: + angle += 90 + + vert = False + if (abs(angle) % 90 < vertAng or abs(90-abs(angle) % 90) % 90 < vertAng): + _w = max(box[:, 0]) - min(box[:, 0]) + _h = max(box[:, 1]) - min(box[:, 1]) + if _h >= _w: + vert = True + angle = 0 + + img = np.zeros((height*scale, width*scale, 3), np.uint8) + img = Image.fromarray(img) + + # infer font size + image4ratio = Image.new("RGB", img.size, "white") + draw = ImageDraw.Draw(image4ratio) + _, _, _tw, _th = draw.textbbox(xy=(0, 0), text=text, font=font) + text_w = min(w, h) * (_tw / _th) + if text_w <= max(w, h): + # add space + if len(text) > 1 and not vert and add_space: + for i in range(1, 100): + text_space = insert_spaces(text, i) + _, _, _tw2, _th2 = draw.textbbox(xy=(0, 0), text=text_space, font=font) + if min(w, h) * (_tw2 / _th2) > max(w, h): + break + text = insert_spaces(text, i-1) + font_size = min(w, h)*0.80 + else: + # shrink = 0.75 if vert else 0.85 + shrink = 1.0 + font_size = min(w, h) / (text_w/max(w, h)) * shrink + new_font = font.font_variant(size=int(font_size)) + + left, top, right, bottom = new_font.getbbox(text) + text_width = right-left + text_height = bottom - top + + layer = Image.new('RGBA', img.size, (0, 0, 0, 0)) + draw = ImageDraw.Draw(layer) + if not vert: + draw.text((rect[0][0]-text_width//2, rect[0][1]-text_height//2-top), text, font=new_font, fill=(255, 255, 255, 255)) + else: + x_s = min(box[:, 0]) + _w//2 - text_height//2 + y_s = min(box[:, 1]) + for c in text: + draw.text((x_s, y_s), c, font=new_font, fill=(255, 255, 255, 255)) + _, _t, _, _b = new_font.getbbox(c) + y_s += _b + + rotated_layer = layer.rotate(angle, expand=1, center=(rect[0][0], rect[0][1])) + + x_offset = int((img.width - rotated_layer.width) / 2) + y_offset = int((img.height - rotated_layer.height) / 2) + img.paste(rotated_layer, (x_offset, y_offset), rotated_layer) + img = np.expand_dims(np.array(img.convert('1')), axis=2).astype(np.float64) + + return img diff --git a/PyTorch/built-in/mlm/HunyuanDiT/comfyui-hydit/hydit/annotator/util.py b/PyTorch/built-in/mlm/HunyuanDiT/comfyui-hydit/hydit/annotator/util.py new file mode 100644 index 0000000000000000000000000000000000000000..e0b217ef9adf92dd5b1fe0debcfb07d0f241a4cb --- /dev/null +++ b/PyTorch/built-in/mlm/HunyuanDiT/comfyui-hydit/hydit/annotator/util.py @@ -0,0 +1,98 @@ +import random + +import numpy as np +import cv2 +import os + + +annotator_ckpts_path = os.path.join(os.path.dirname(__file__), 'ckpts') + + +def HWC3(x): + assert x.dtype == np.uint8 + if x.ndim == 2: + x = x[:, :, None] + assert x.ndim == 3 + H, W, C = x.shape + assert C == 1 or C == 3 or C == 4 + if C == 3: + return x + if C == 1: + return np.concatenate([x, x, x], axis=2) + if C == 4: + color = x[:, :, 0:3].astype(np.float32) + alpha = x[:, :, 3:4].astype(np.float32) / 255.0 + y = color * alpha + 255.0 * (1.0 - alpha) + y = y.clip(0, 255).astype(np.uint8) + return y + + +def resize_image(input_image, resolution): + H, W, C = input_image.shape + H = float(H) + W = float(W) + k = float(resolution) / min(H, W) + H *= k + W *= k + H = int(np.round(H / 64.0)) * 64 + W = int(np.round(W / 64.0)) * 64 + img = cv2.resize(input_image, (W, H), interpolation=cv2.INTER_LANCZOS4 if k > 1 else cv2.INTER_AREA) + return img + + +def nms(x, t, s): + x = cv2.GaussianBlur(x.astype(np.float32), (0, 0), s) + + f1 = np.array([[0, 0, 0], [1, 1, 1], [0, 0, 0]], dtype=np.uint8) + f2 = np.array([[0, 1, 0], [0, 1, 0], [0, 1, 0]], dtype=np.uint8) + f3 = np.array([[1, 0, 0], [0, 1, 0], [0, 0, 1]], dtype=np.uint8) + f4 = np.array([[0, 0, 1], [0, 1, 0], [1, 0, 0]], dtype=np.uint8) + + y = np.zeros_like(x) + + for f in [f1, f2, f3, f4]: + np.putmask(y, cv2.dilate(x, kernel=f) == x, x) + + z = np.zeros_like(y, dtype=np.uint8) + z[y > t] = 255 + return z + + +def make_noise_disk(H, W, C, F): + noise = np.random.uniform(low=0, high=1, size=((H // F) + 2, (W // F) + 2, C)) + noise = cv2.resize(noise, (W + 2 * F, H + 2 * F), interpolation=cv2.INTER_CUBIC) + noise = noise[F: F + H, F: F + W] + noise -= np.min(noise) + noise /= np.max(noise) + if C == 1: + noise = noise[:, :, None] + return noise + + +def min_max_norm(x): + x -= np.min(x) + x /= np.maximum(np.max(x), 1e-5) + return x + + +def safe_step(x, step=2): + y = x.astype(np.float32) * float(step + 1) + y = y.astype(np.int32).astype(np.float32) / float(step) + return y + + +def img2mask(img, H, W, low=10, high=90): + assert img.ndim == 3 or img.ndim == 2 + assert img.dtype == np.uint8 + + if img.ndim == 3: + y = img[:, :, random.randrange(0, img.shape[2])] + else: + y = img + + y = cv2.resize(y, (W, H), interpolation=cv2.INTER_CUBIC) + + if random.uniform(0, 1) < 0.5: + y = 255 - y + + return y < np.percentile(y, random.randrange(low, high)) diff --git a/PyTorch/built-in/mlm/HunyuanDiT/comfyui-hydit/hydit/config.py b/PyTorch/built-in/mlm/HunyuanDiT/comfyui-hydit/hydit/config.py new file mode 100644 index 0000000000000000000000000000000000000000..07106b9dcd4377252c9427e8355fb1d635cded31 --- /dev/null +++ b/PyTorch/built-in/mlm/HunyuanDiT/comfyui-hydit/hydit/config.py @@ -0,0 +1,200 @@ + +import argparse + +from .constants import * +from .modules.models import HUNYUAN_DIT_CONFIG, HUNYUAN_DIT_MODELS +from .diffusion.gaussian_diffusion import ModelVarType + +import deepspeed + +def model_var_type(value): + try: + return ModelVarType[value] + except KeyError: + raise ValueError(f"Invalid choice '{value}', valid choices are {[v.name for v in ModelVarType]}") + + +def get_args(default_args=None): + parser = argparse.ArgumentParser() + parser.add_argument("--task-flag", type=str) + + # General Setting + parser.add_argument("--batch-size", type=int, default=1, help="Per-GPU batch size") + parser.add_argument('--seed', type=int, default=42, help="A seed for all the prompts.") + parser.add_argument("--use-fp16", action="store_true", help="Use FP16 precision.") + parser.add_argument("--no-fp16", dest="use_fp16", action="store_false") + parser.set_defaults(use_fp16=True) + parser.add_argument("--extra-fp16", action="store_true", help="Use extra fp16 for vae and text_encoder.") + + # HunYuan-DiT + parser.add_argument("--model", type=str, choices=list(HUNYUAN_DIT_CONFIG.keys()), default='DiT-g/2') + parser.add_argument("--image-size", type=int, nargs='+', default=[1024, 1024], + help='Image size (h, w). If a single value is provided, the image will be treated to ' + '(value, value).') + parser.add_argument("--qk-norm", action="store_true", help="Query Key normalization. See http://arxiv.org/abs/2302.05442 for details.") + parser.set_defaults(qk_norm=True) + parser.add_argument("--norm", type=str, choices=["rms", "laryer"], default="layer", help="Normalization layer type") + parser.add_argument("--text-states-dim", type=int, default=1024, help="Hidden size of CLIP text encoder.") + parser.add_argument("--text-len", type=int, default=77, help="Token length of CLIP text encoder output.") + parser.add_argument("--text-states-dim-t5", type=int, default=2048, help="Hidden size of CLIP text encoder.") + parser.add_argument("--text-len-t5", type=int, default=256, help="Token length of T5 text encoder output.") + + # LoRA config + parser.add_argument("--training-parts", type=str, default='all', choices=['all', 'lora'], help="Training parts") + parser.add_argument("--rank", type=int, default=64, help="Rank of LoRA") + parser.add_argument("--lora-ckpt", type=str, default=None, help="LoRA checkpoint") + parser.add_argument('--target-modules', type=str, nargs='+', default=['Wqkv', 'q_proj', 'kv_proj', 'out_proj'], + help="Target modules for LoRA fine tune") + parser.add_argument("--output-merge-path", type=str, default=None, help="Output path for merged model") + + # controlnet config + parser.add_argument("--control-type", type=str, default='canny', choices=['canny', 'depth', 'pose'], help="Controlnet condition type") + parser.add_argument("--control-weight", type=float, default=1.0, help="Controlnet weight") + parser.add_argument("--condition-image-path", type=str, default=None, help="Inference condition image path") + + # Diffusion + parser.add_argument("--learn-sigma", action="store_true", help="Learn extra channels for sigma.") + parser.add_argument("--no-learn-sigma", dest="learn_sigma", action="store_false") + parser.set_defaults(learn_sigma=True) + parser.add_argument("--predict-type", type=str, choices=list(PREDICT_TYPE), default="v_prediction", + help="Diffusion predict type") + parser.add_argument("--noise-schedule", type=str, choices=list(NOISE_SCHEDULES), default="scaled_linear", + help="Noise schedule") + parser.add_argument("--beta-start", type=float, default=0.00085, help="Beta start value") + parser.add_argument("--beta-end", type=float, default=0.03, help="Beta end value") + parser.add_argument("--sigma-small", action="store_true") + parser.add_argument("--mse-loss-weight-type", type=str, default="constant", + help="Min-SNR-gamma. Can be constant or min_snr_| Condition Input | +||
| Canny ControlNet | +Depth ControlNet | +Pose ControlNet | +
| 在夜晚的酒店门前,一座古老的中国风格的狮子雕像矗立着,它的眼睛闪烁着光芒,仿佛在守护着这座建筑。背景是夜晚的酒店前,构图方式是特写,平视,居中构图。这张照片呈现了真实摄影风格,蕴含了中国雕塑文化,同时展现了神秘氛围 (At night, an ancient Chinese-style lion statue stands in front of the hotel, its eyes gleaming as if guarding the building. The background is the hotel entrance at night, with a close-up, eye-level, and centered composition. This photo presents a realistic photographic style, embodies Chinese sculpture culture, and reveals a mysterious atmosphere.) |
+ 在茂密的森林中,一只黑白相间的熊猫静静地坐在绿树红花中,周围是山川和海洋。背景是白天的森林,光线充足 (In the dense forest, a black and white panda sits quietly in green trees and red flowers, surrounded by mountains, rivers, and the ocean. The background is the forest in a bright environment.) |
+ 一位亚洲女性,身穿绿色上衣,戴着紫色头巾和紫色围巾,站在黑板前。背景是黑板。照片采用近景、平视和居中构图的方式呈现真实摄影风格 (An Asian woman, dressed in a green top, wearing a purple headscarf and a purple scarf, stands in front of a blackboard. The background is the blackboard. The photo is presented in a close-up, eye-level, and centered composition, adopting a realistic photographic style) |
+
 |
+  |
+  |
+
+
| ControlNet Output | +||
 |
+  |
+  |
+
| Examples of training data | +|||
 |
+  |
+  |
+  |
+
| 青花瓷风格,一只蓝色的鸟儿站在蓝色的花瓶上,周围点缀着白色花朵,背景是白色 (Porcelain style, a blue bird stands on a blue vase, surrounded by white flowers, with a white background. +) | +青花瓷风格,这是一幅蓝白相间的陶瓷盘子,上面描绘着一只狐狸和它的幼崽在森林中漫步,背景是白色 (Porcelain style, this is a blue and white ceramic plate depicting a fox and its cubs strolling in the forest, with a white background.) | +青花瓷风格,在黑色背景上,一只蓝色的狼站在蓝白相间的盘子上,周围是树木和月亮 (Porcelain style, on a black background, a blue wolf stands on a blue and white plate, surrounded by trees and the moon.) | +青花瓷风格,在蓝色背景上,一只蓝色蝴蝶和白色花朵被放置在中央 (Porcelain style, on a blue background, a blue butterfly and white flowers are placed in the center.) | +
| Examples of inference results | +|||
 |
+  |
+  |
+  |
+
| 青花瓷风格,苏州园林 (Porcelain style, Suzhou Gardens.) | +青花瓷风格,一朵荷花 (Porcelain style, a lotus flower.) | +青花瓷风格,一只羊(Porcelain style, a sheep.) | +青花瓷风格,一个女孩在雨中跳舞(Porcelain style, a girl dancing in the rain.) | +

 '
+ msg = img_str + msg.replace('
'
+ msg = img_str + msg.replace('