> wordCountResult = tupleWords.groupBy(0).sum(1);
wordCountResult.print();
}
}
```
3)流处理版本的Word Count:基于DataStream API,只需要指定模式就可以了。
```java
/**
* 基于无界流处理实现的word count.
*
* 使用netcat来实时的发送数据流.
* command: nc -kl 7777
*
* @author code1997
*/
public class StreamUnboundWordCount {
public static final String HOST_NAME = "host";
public static final String PORT = "port";
public static void main(String[] args) throws Exception {
//1.创建执行环境
StreamExecutionEnvironment executionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment();
//2.读取数据源文件
ParameterTool parameterTool = ParameterTool.fromArgs(args);
String hostname = parameterTool.get(HOST_NAME);
int port = parameterTool.getInt(PORT);
DataStreamSource socketTextStream = executionEnvironment.socketTextStream(hostname, port);
StreamUtils.printWordCount(socketTextStream);
//5.启动执行
executionEnvironment.execute();
}
}
/**
* 流处理API打印word count的结果
* @param streamSource
*/
public static void printWordCount(DataStreamSource streamSource) {
SingleOutputStreamOperator> tuple2Words = streamSource.flatMap((FlatMapFunction>) (s, collector) -> {
String[] words = s.split(" ");
for (String word : words) {
collector.collect(Tuple2.of(word, 1L));
}
}).returns(Types.TUPLE(Types.STRING, Types.LONG));
SingleOutputStreamOperator> streamBoundWordCountResult = tuple2Words.keyBy((KeySelector, Object>) stringLongTuple2 -> stringLongTuple2.f0).sum(1);
/**
* 输出操作:更新状态,前面的编号指的是执行的线程. 在flink中资源的单位是slot槽.分组之后会将同组的放到同一个分区子任务上.
* 4> (java,1)
* 16> (flink,1)
* 11> (world,1)
* 6> (hello,1)
* 6> (hello,2)
* 6> (hello,3)
*/
streamBoundWordCountResult.print();
}
```
### 2 Flink部署
> 本章主要是flink的部署
#### 2.1 Flink的部署模式
- 会话模式(session mode):集群先启动起来,在启动之后资源已经被确定,如果提交job的时候发现资源不够用就会提交任务失败,存在集群中多个job发生竞争的现象。适合于单个规模小,执行时间短的大量作业。
- 单作业模式(Per-Job mode):严格的一对一,集群为这个作业而生,可以实现资源的隔离,可以使得作业在生产环境中更加稳定。每一个作业提交之后,就启动一个集群,适合于单个规模大,执行时间长的作业,需要和其他的资源管理框架结合使用。
- 应用模式(Application mode):前两种模式下,应用代码执行在客户端上,然后客户端提交给Job Manager,这种方式客户端需要占用大量网络带宽(下载依赖和二进制数据传输)。因为提交作业使用的是同一个客户端,会加重客户端所在的节点的资源消耗。应用模式不需要客户端,直接将应用提交到Job Manager上运行,Job Manager为job而生,每提交一个job,就启动一个Job Manager;job执行结束,Job Manager就关闭了,这就是所谓的应用模式。
1. 将jar包放到`lib`目录下
2. 启动JobManager
```shell
./bin/standalone-job.sh --job-classname 全类名
```
3. 启动taskManager
```shell
./bin/taskmanager.sh start
```
4. 停止集群
```shell
./bin/standalone-job.sh stop
./bin/taskmanager.sh stop
```
#### 2.2 standlone模式
> 前提:三台虚拟机,配置好静态ip,关闭防火墙,jdk,免密登录
>
> flink版本选择:1.13.6
集群规划:
| hostname | role |
| -------- | --------------------------- |
| hadoop02 | Job Manager: job管理和规划 |
| hadoop03 | Task Manager:干活的 |
| hadoop04 | Task Manager:干活的 |
1 上传tar包并解压
2 修改`con/flink-conf.yaml`
```yaml
jobmanager.rpc.address: hadoop02
```
3 修改`conf/workers`文件
```txt
hadoop03
hadoop04
```
4 分发`flink`到其他节点
5 启动flink集群

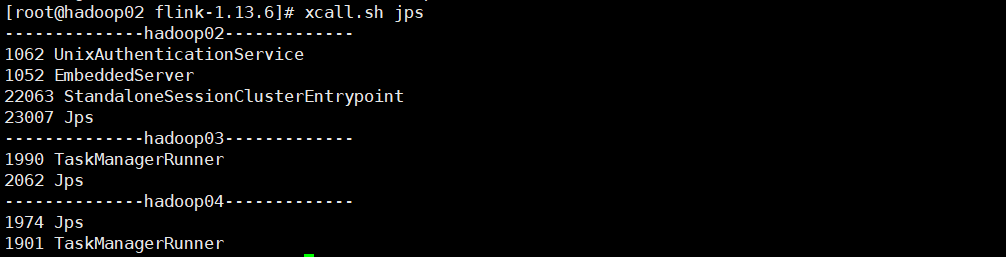
6 查看进程信息:xcall是一个自己写的脚本,实际上是调用jps查看java进程。
- StandaloneSessionClusterEntrypoint:master接入点
- TaskManagerRunner:work进程
7 访问flink dashboard
url:http://hadoop02:8081/#/overview
#### 2.3 yarn模式
> standlone模式最常见的是会话模式,无法动态的分配资源,一旦集群启动,那么资源就已经确定了。yarn模式下flink会向yarn的NodeManager申请容器,在这些容器上,Flink会部署JobManager和TaskManager的实力,从而启动集群。Flink会根据运行在JobManager上的作业所需要的Slot数量动态分配TaskManager资源。
前置条件:配置好hadoop已经相关的环境变量。
##### 2.3.1 yarn-session模式
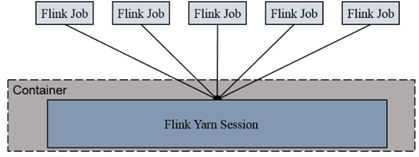
在 yarn 中初始化一个 flink 集群,开辟指定的资源,以后提交任务都向这里提交。这个 flink 集群会常驻在 yarn 集群中, 除非手工停止。所有作业共享 Dispatcher 和 ResourceManager;共享资源;适合规模小执行时间短的作业。
1 启动yarn-session模式:如果有hdfs配置了kerberos认证,那么就需要进行kinit
```shell
./bin/yarn-session.sh -nm test
```
可配参数:
- -d:分离模式,守护进程的方式执行。
- -jm(--jobManagerMemory):配置JobManager所需要的内存,默认单位MB。
- -nm(--name):配置在yarn ui上显示的任务名字。
- -qu(--queue):指定yarn队列名字。
- -tm(--taskManager):配置每个TaskManager所需要的内存。
- 注:1.11版本不再使用-n和-s参数分别指定TaskManager和Slot的数量,yarn会按照需求动态分配TaskManager和Slot的数量,这方面来说,yarn的会话模式也不会把集群资源固定,同样也是动态分配。

web ui:
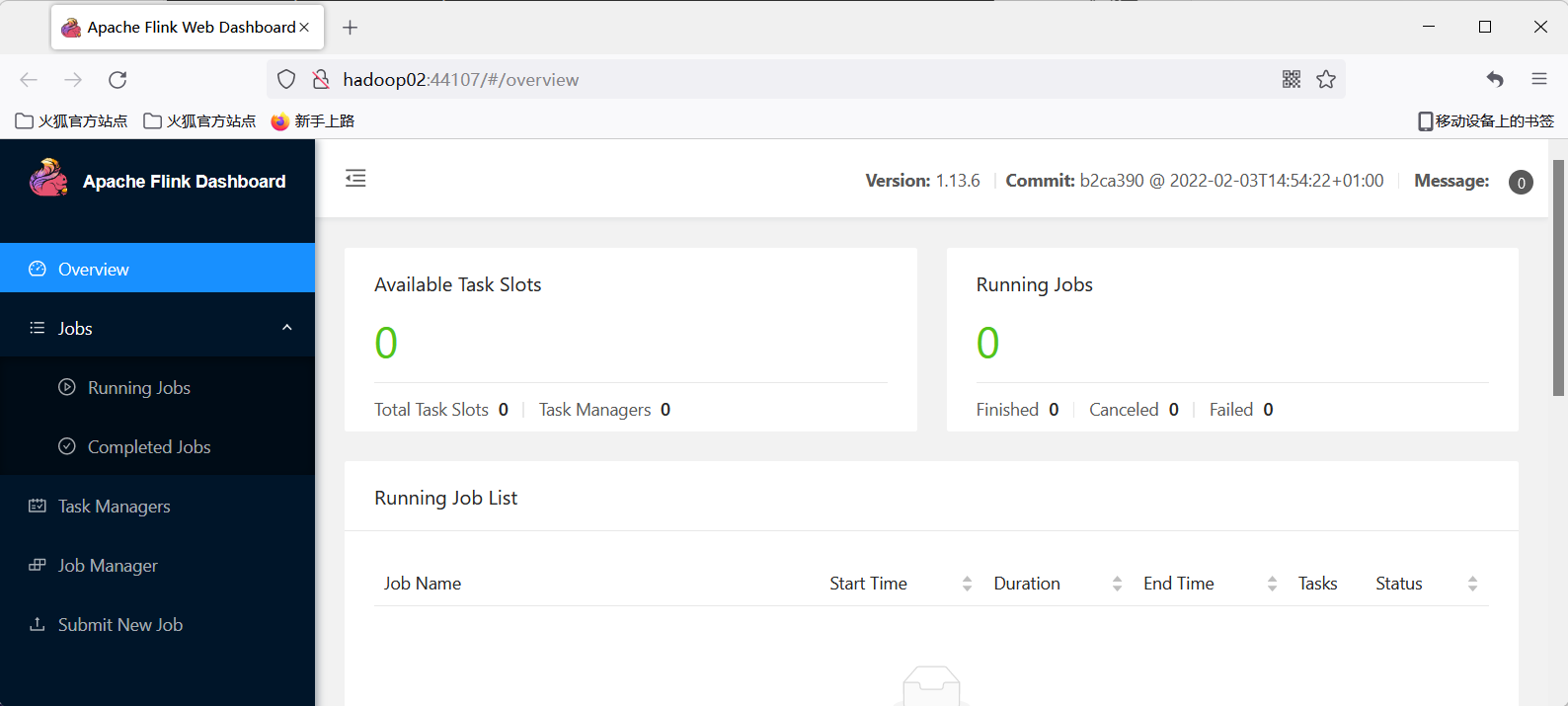
error:如果报如下错误
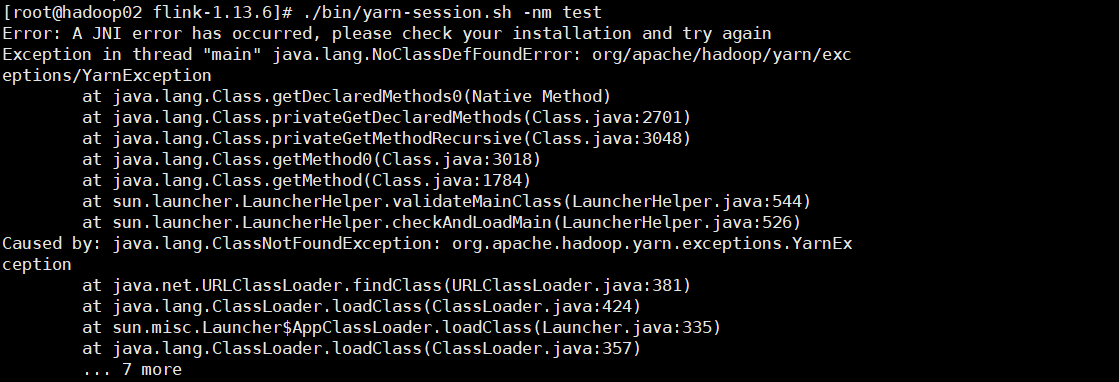
解决方式:/${flink_home}/lib/下面放置`flink-shaded-hadoop-3-uber-3.1.1.7.1.1.0-565-9.0.jar`
##### 2.3.2 yarn-per-job模式
```shell
bin/flink run -d -t yarn-per-job -c com.it.word_count.StreamUnboundWordCount -p 2 ./project_jars/flink-code1997-1.0-SNAPSHOT.jar --host hadoop02 --port 7777
# 早期写法
./flink run –m yarn-cluster -c com.atguigu.wc.StreamWordCount
FlinkTutorial-1.0-SNAPSHOT-jar-with-dependencies.jar --host lcoalhost –port 7777
```
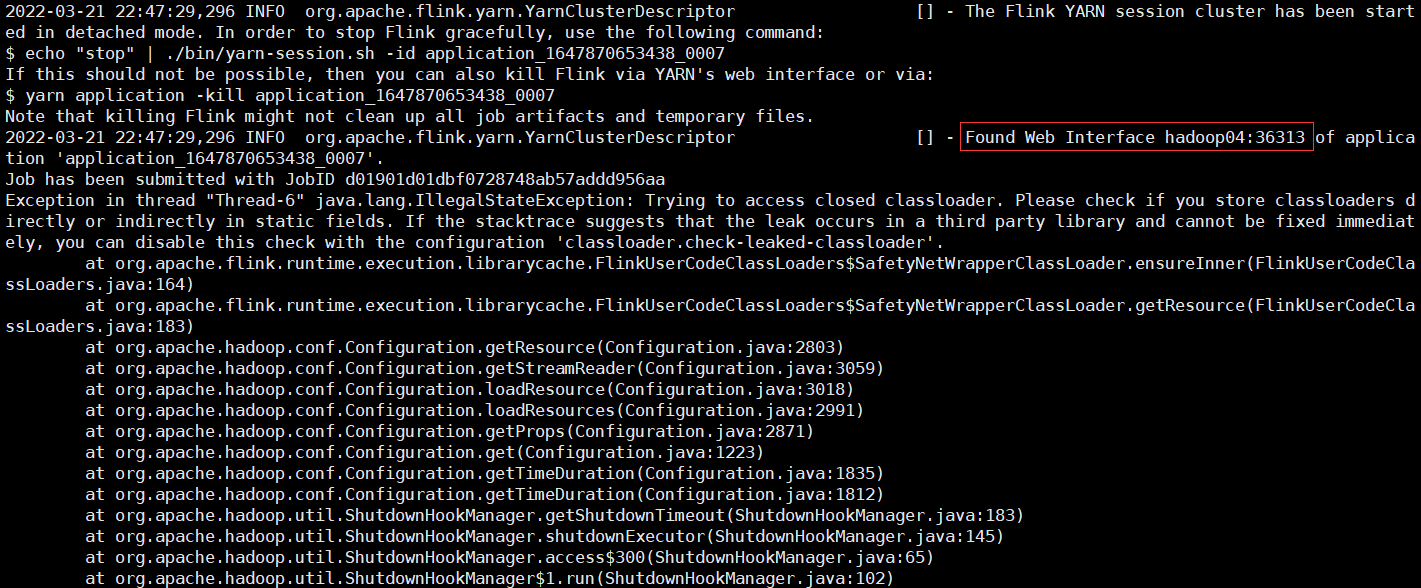
web-ui:
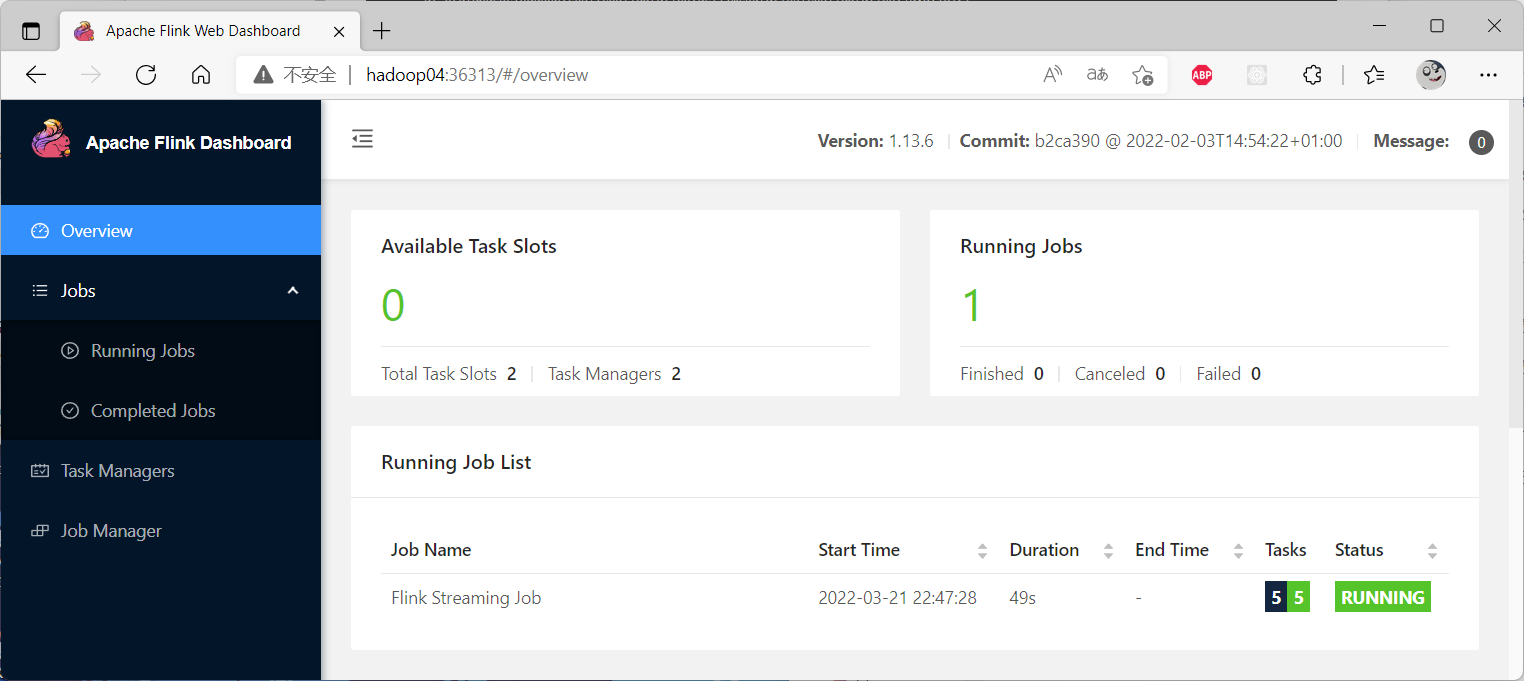
error:Trying to access closed classloader. Please check if you store classloaders directly or indirectly in static fields
解决:修改`flink-conf.yaml`文件,添加如下参数
```yaml
classloader.check-leaked-classloader: false
```
#### 2.4提交项目
##### 2.1 使用flink dashboard
1 上传jar包
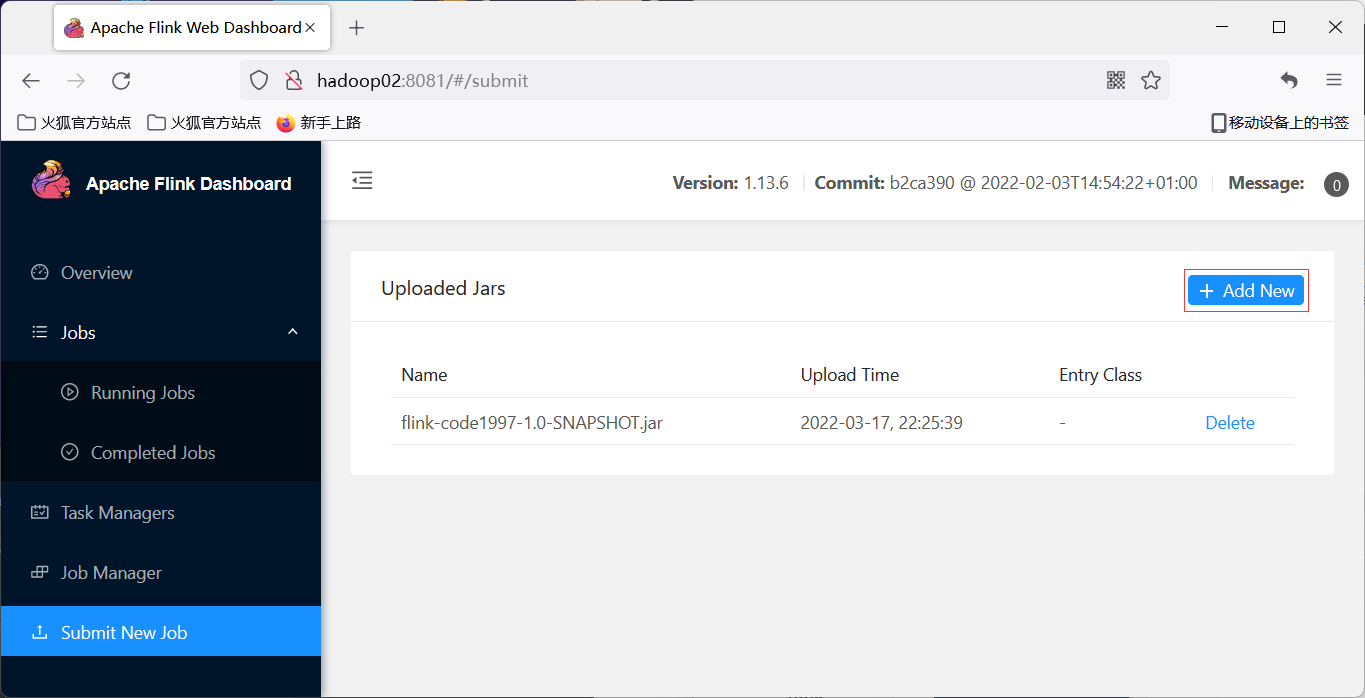
2 启动nc `nc -lk 7777`
3 提交job
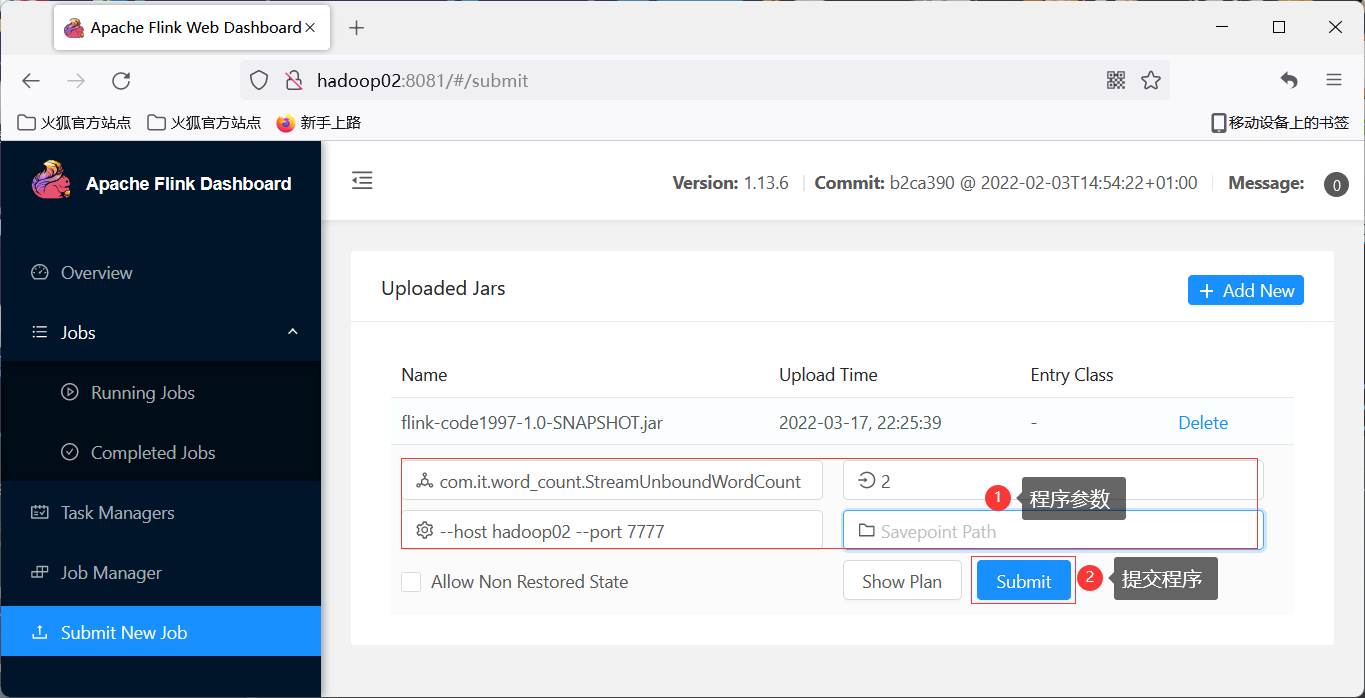
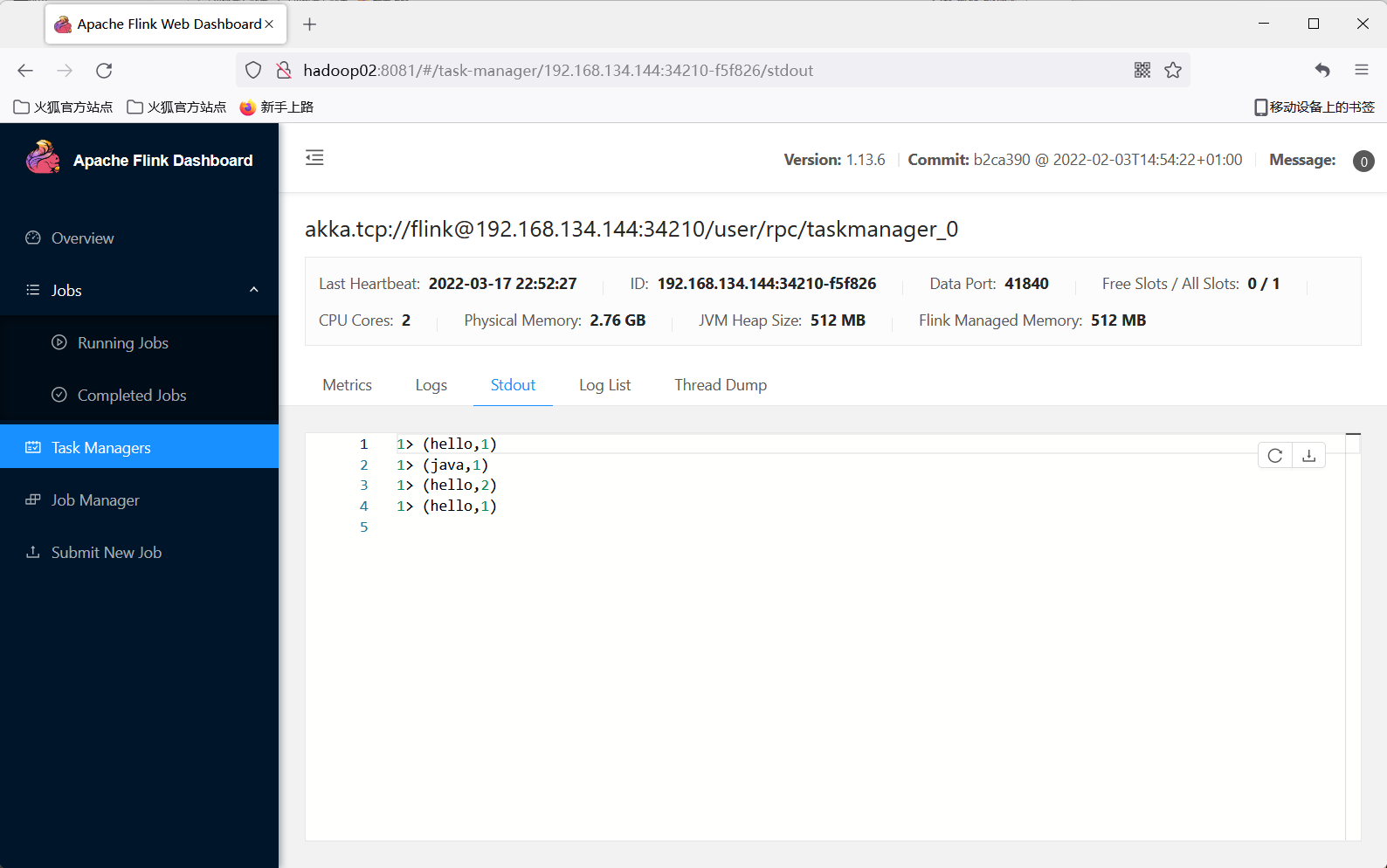
4 使用nc向7777端口发送数据

5 查看程序运行输出:因为之前有输出过,所以可能不太一致
##### 2.2 使用命令行
1 上传jar包到集群

2 启动nc监听7777端口
3 提交job
```shell
bin/flink run -m hadoop02:8081 -c com.it.word_count.StreamUnboundWordCount -p 2 ./project_jars/flink-code1997-1.0-SNAPSHOT.jar --host hadoop02 --port 7777
```

4 web dashboard查看

5 命令行cancel job
```shell
[root@hadoop02 flink-1.13.6]# bin/flink cancel dc9fc1b48ed8417363fa272b9aca5f2c
```

注:如果没有资源了,那么job提交就会失败。
### 3 运行时架构
#### 3.1 flink运行时架构
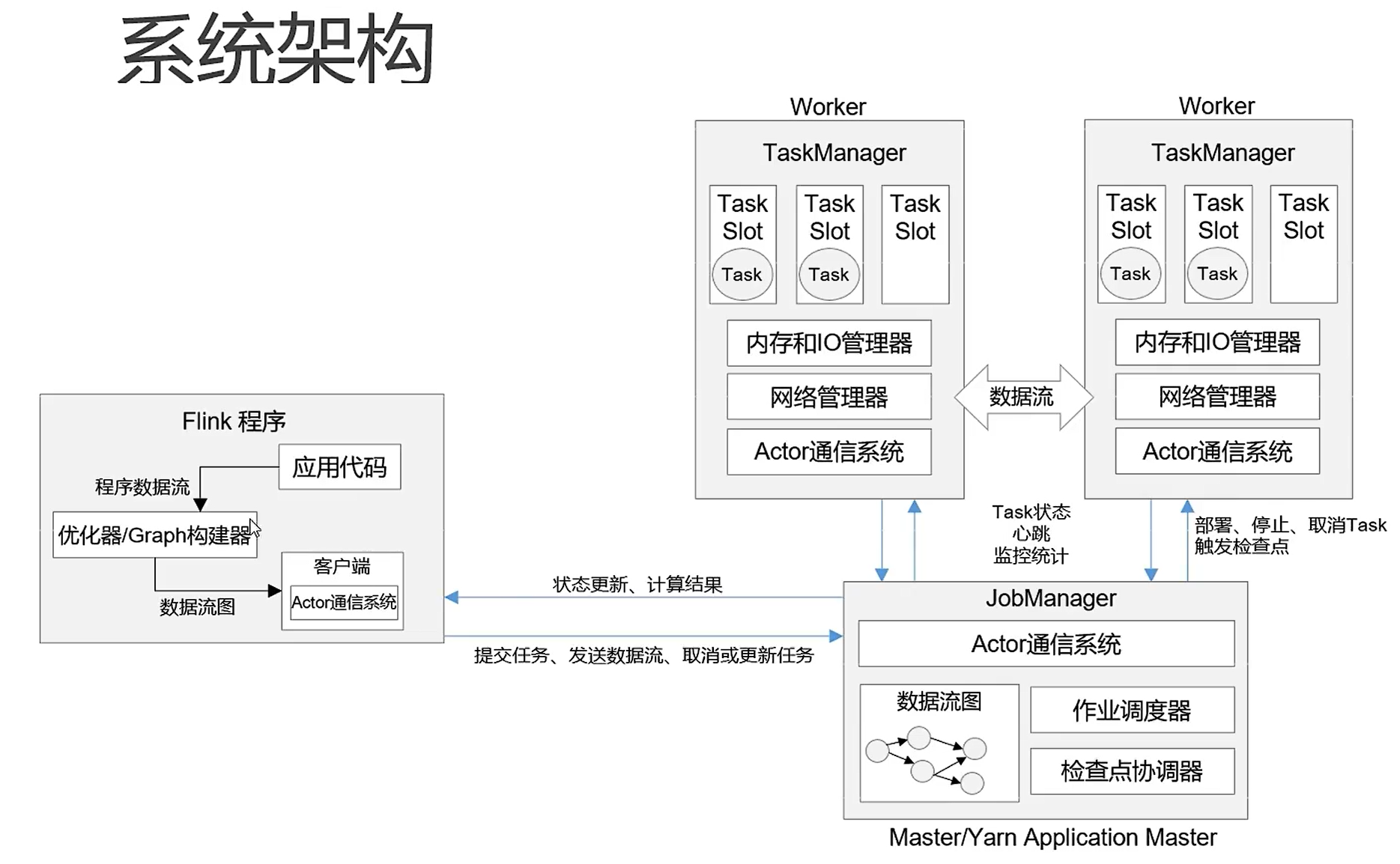
- Job Manager:控制一个应用程序执行的主进程,是Flink集群中任务管理和调度的核心。
- Job Master:是Job Manager中最核心的组件,负责处理单独的作业(Job)。
- 作业提交时,Job Master会先接收到要执行的应用程序,一般是由客户端提交来的,包含:jar包,数据流图,作业图。
- Job Master会将Job Graph转换成物理层面的数据流图,这个图被叫做“执行图”(ExecutionGraph),包含了所有可以并发执行的任务。JobManager 会向资源管理器(ResourceManager)请求执行任务必要的资源,也就是任务管理器(TaskManager)上的插槽( slot)。一旦它获取到了足够的资源,就会将执行图分发到真正运行它们的TaskManager 上。而在运行过程中,JobManager 会负责所有需要中央协调的操作,比如说检查点(checkpoints)的协调。
- 资源管理器(ResourceManager):主要负责管理任务管理器(TaskManager)的插槽(slot),在Flink集群中只有一个。所谓的资源,主要指的是task slots。任务槽就是Flink集群中的资源调配单元,包含了机器用来执行计算的一组CPU和内存资源。每一个任务都需要分配一个slot来执行。
- 分发器(Dispatcher):可以跨作业运行,它为应用提交提供了 REST 接口。当一个应用被提交执行时,分发器就会启动并将应用移交给一个 JobManager。由于是 REST 接口,所以 Dispatcher 可以作为集群的一个 HTTP 接入点,这样就能够不受防火墙阻挡。Dispatcher 也会启动一个Web UI,用来方便地展示和监控作业执行的信息。Dispatcher 在架构中可能并不是必需的,这取决于应用提交运行的方式。
- 任务管理器(TaskManager):Flink 中的工作进程。通常在 Flink 中会有多个 TaskManager 运行,每一个 TaskManager都包含了一定数量的插槽(slots)。插槽的数量限制了 TaskManager 能够执行的任务数量。启动之后, TaskManager 会向`资源管理器`注册它的插槽;收到资源管理器的指令后, TaskManager 就会将一个或者多个插槽提供给 JobManager 调用。JobManager 就可以向插槽分配任务(tasks)来执行了。在执行过程中,一个 TaskManager 可以跟其它运行`同一应用程序`的 TaskManager 交换数据。
#### 3.2 任务提交流程
1)高层次的图:
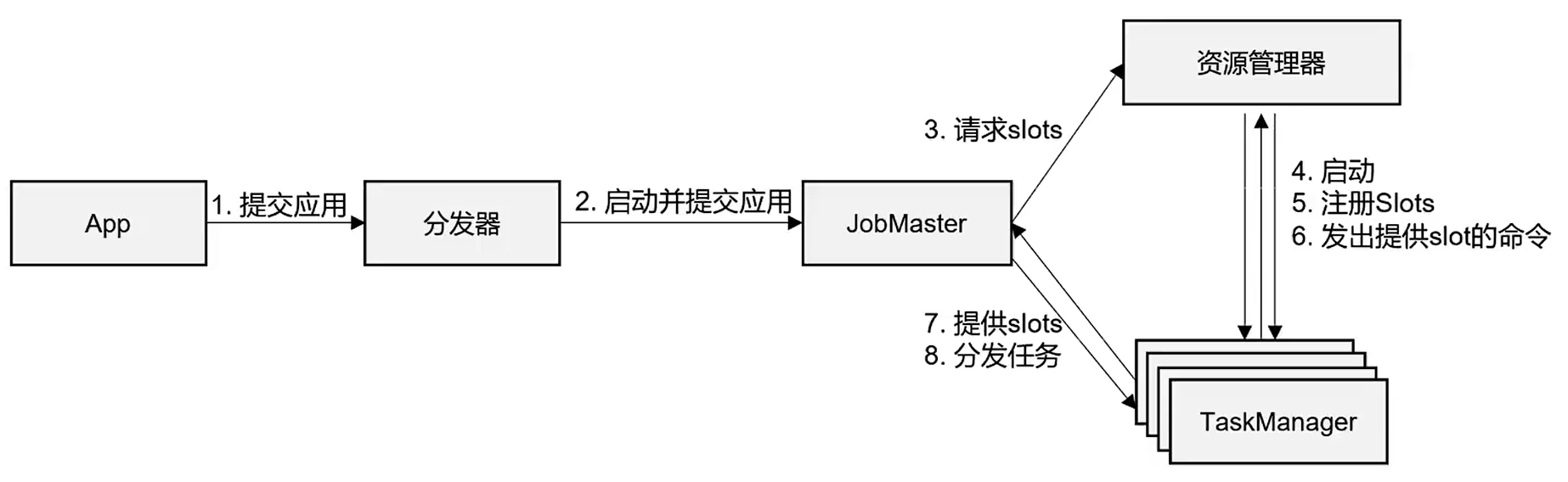
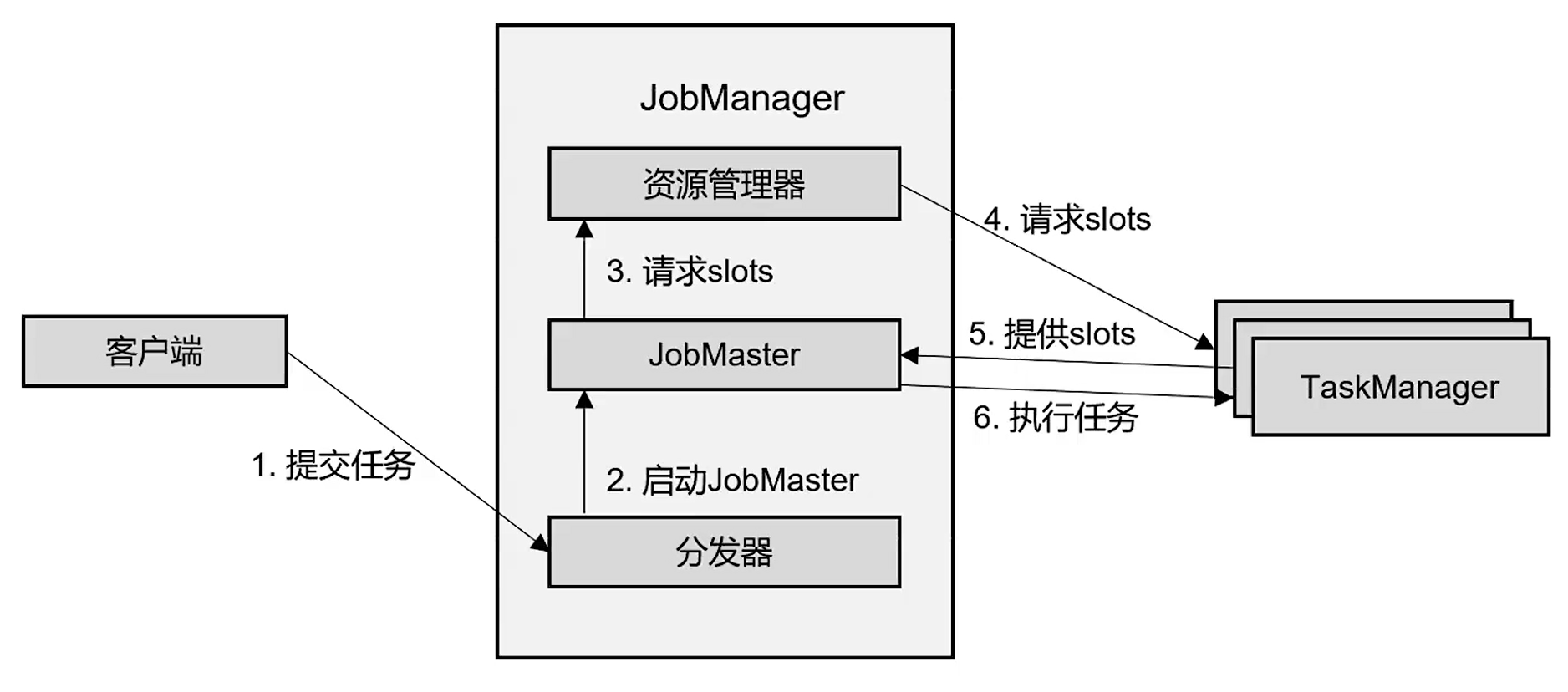
2)standlone模式:常用于`会话模式`
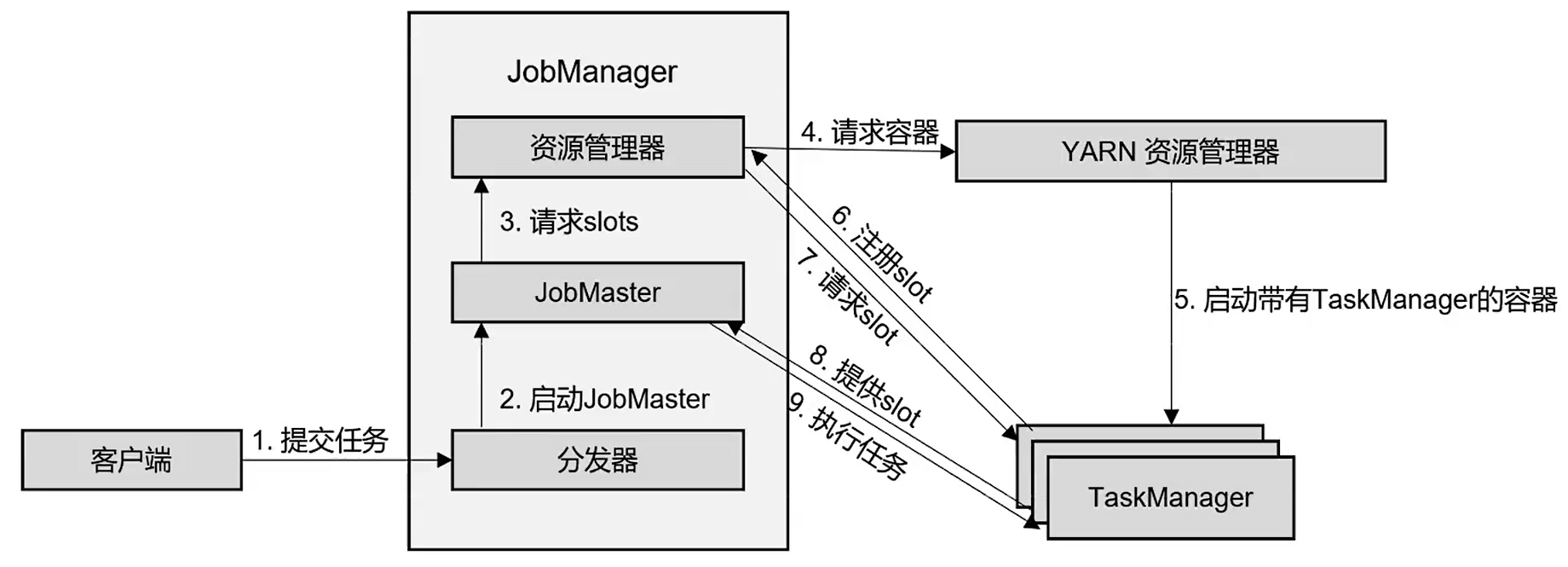
3)yarn会话模式:Task Manager是`动态启动`的。
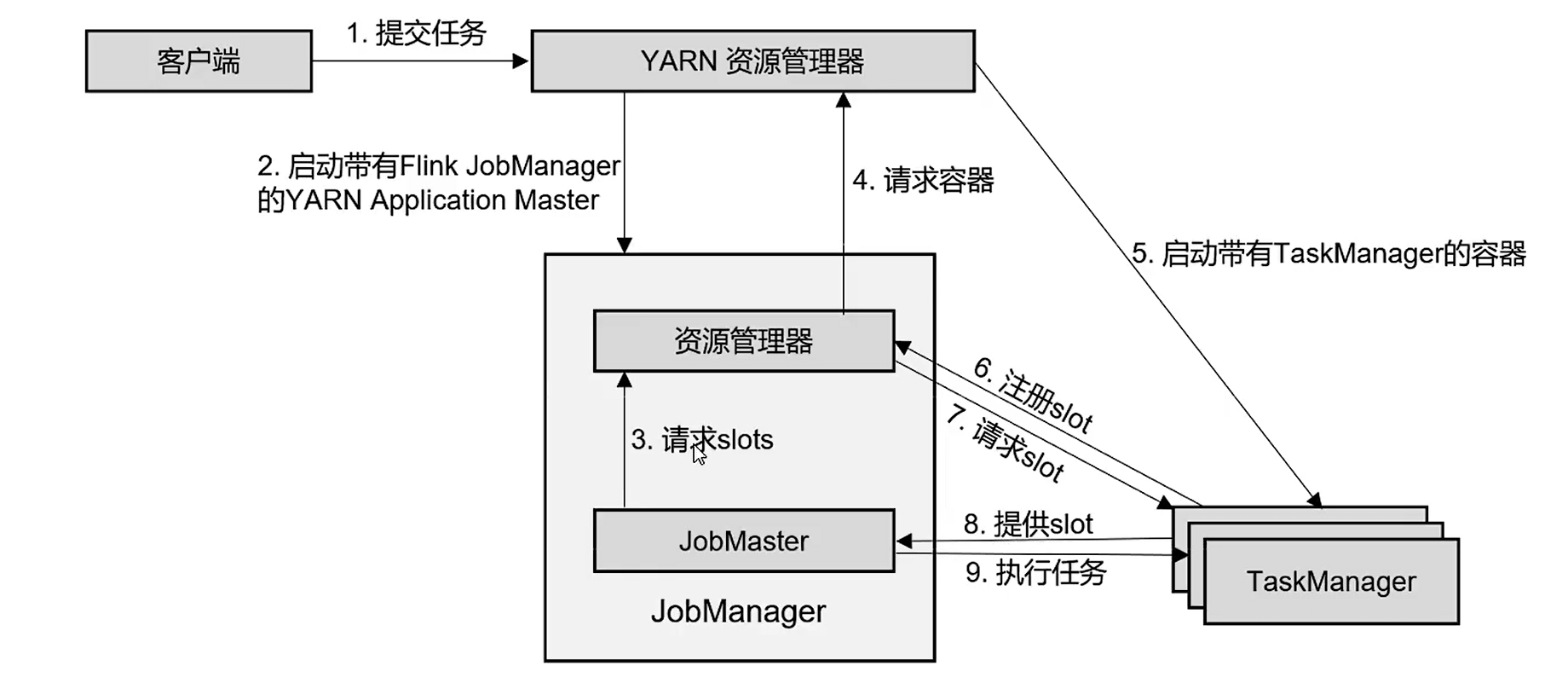
4)yarn-per-job模式:每启动一个job都会启动一个Job Manager
#### 3.3 一些概念
1)数据流
所有的flink程序都可以拆分为三部分:source,Transformation和Sink。
- source:负责读取数据源。
- Transformation:利用各种算子进行处理加工。
- Sink:负责输出。
在运行时,Flink上运行的程序都会被映射成“逻辑数据流”,他包含了三部分:
- 每个dataflow都以一个或者多个source开始;以一个或多个sinks结束。类似于任意的有向无环图。
- 在大部分情况下,程序中的转换运算(Transformation)跟dataflow中的算子(operator)是一一对应的关系。
2)并行度:数据并行+任务并行
每一个算子(operator)可以包含一个或多个子任务(operator subtask),这些子任务在不同的线程,不同的物理机或者不同的容器中完全独立的执行。一个特定的算子的子任务的个数称之为其并行度(parallelism)。可以方法来设置某个算子的并行度。
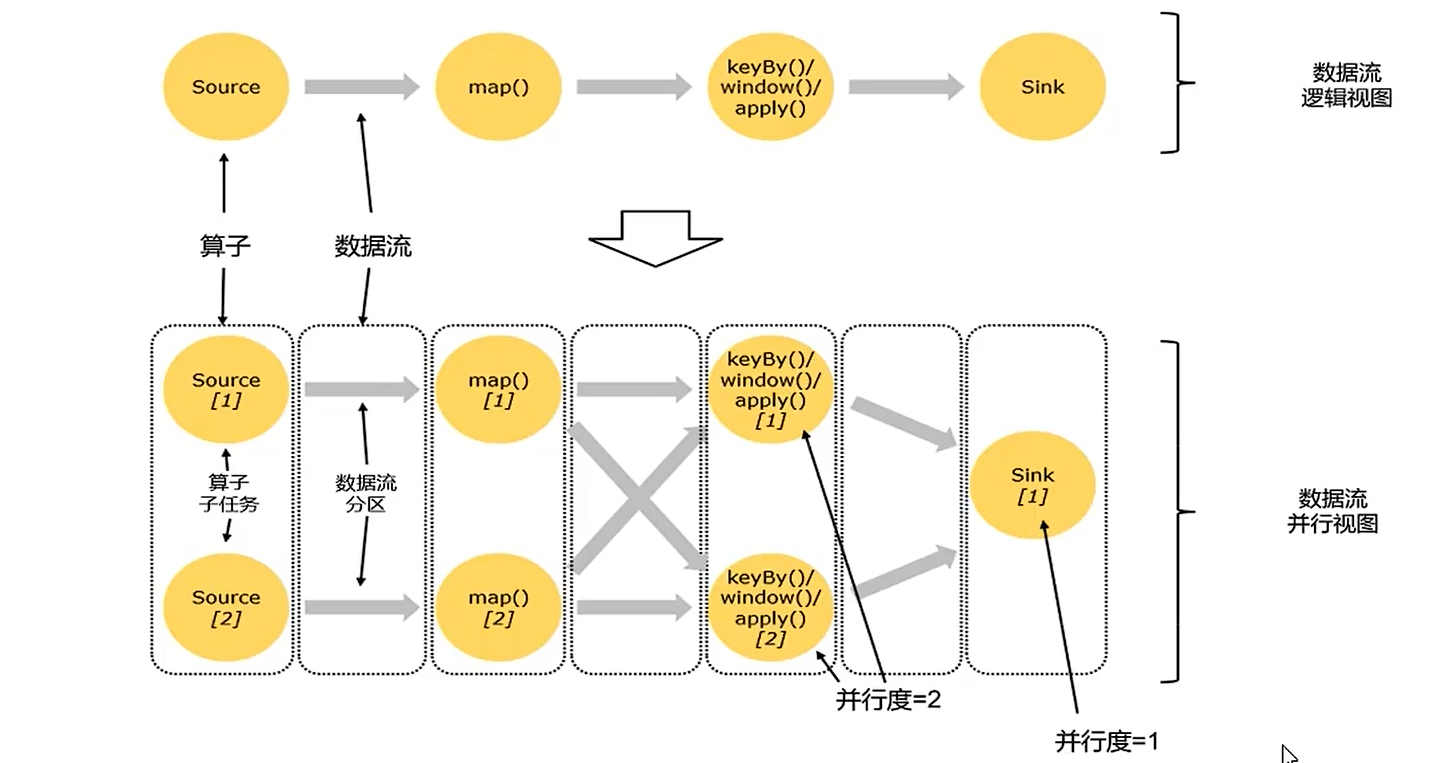
设置并行度:算子>env>命令行的方式>集群环境的设置(flink-conf.yaml)
```java
operator.setParallelism()
executionEnvironment.setParallelism(2);
命令行:-p来设定并行度。
parallelism.default: 1
```
3)数据传输形式
一个程序中,不同的个算子之间可能具有不同的并行度。算子之间传输数据的形式可以是one-to-one(forwarding)的模式,也可以是redistributing的模式,具体是哪一种形式,取决于算子的种类。
- one-to-one:stream维护着分区以及元素的顺序(比如source和map之间),这意味着map算子的子任务看到的元素的个数以及顺序跟source算子的子任务生产的元素的个数,顺序相同。例如:map,filter,flatMap都算One-to-One的对应关系,类似于spark中的`窄依赖`。
- redistributing:分区会发生改变,类似于spark中的shuffle,类似于spark中的`宽依赖`,但是不一定分区会发生变化,例如keyBy。
如果多one-to-one类型的算子链接到一起,我们可以称之为`算子链`。一旦出现充分去或者并行度发生变化就需要断开。
如何手动断开算子链?
- 我们也可以使用`.disableChaining()`来禁用算子链来断开算子前后。
- `.startNewChain()`来断开之前。
- `executionEnvironment.disableOperatorChaining()`全局设置不进行算子链接。
4)执行图
flink中的执行图可以分为四层:StreamGraph->JobGraph->ExecutionGraph->物理执行图
- StreamGraph:根据用户通过StreamApi编写的代码生成的最初的图,表示程序的拓扑结构。
- JobGraph:StreamGraph经过优化之后生成JobGraph,提交给JobManager的数据结构,将多个符合条件的算子链接在一起,形成一个`算子链`。
- ExecutionGraph:JobManager根据JobGraph生成的`并行化版本`,是调度层核心的数据结构。
- 物理执行图:JobManager根据ExecutionGraph对Job进行调度之后,在TaskManager上部署Task后形成的图,并不是一个具体的数据结构。
5)task和task slot:slot槽任务共享
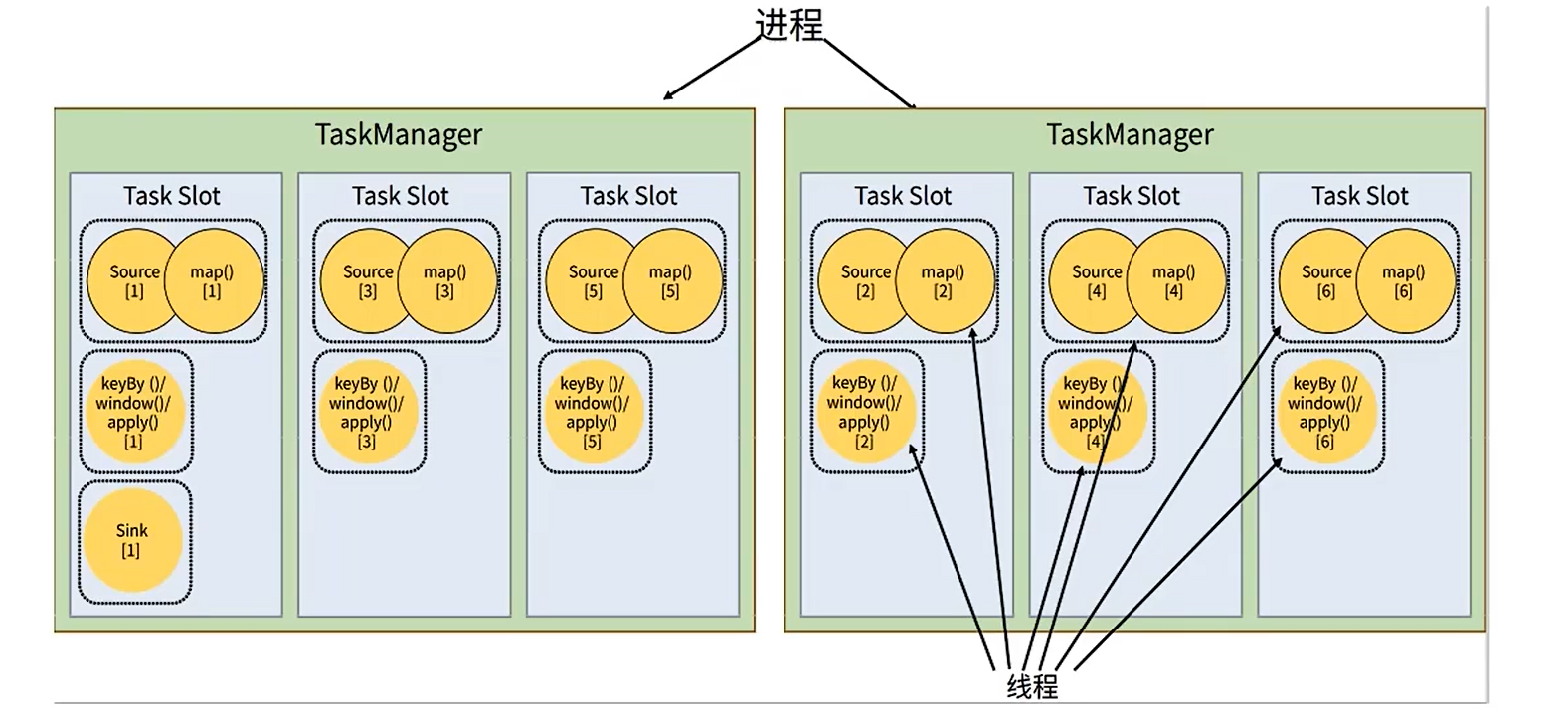
flnik中每一个task manager都是一个JVM进程,他可能会在独立的线程上执行一个或多个子任务。为了控制一个task Manager能接收多少个task,task manager通过task slot来进行控制(一个task manager至少有一个slot)。
默认情况下,flink允许子任务共享slot,结果就是一个slot可以保存作业的整个管道。当我们将资源密集型和非密集型的任务同时放到一个slot中,他们就可以自行分配对资源占用的比例,从而保证最重的活平均的分配给所有的Task Manager,而且可以防止某个Task Manager挂掉之后,导致整个job无法运行,提高了稳定性。
**我们可以使用算子中最大的并行度作为占用slot槽的数量。**
如何禁止slot槽任务共享?默认情况下都属于共享组`default`。
- slotSharingGroup("1"),算子之后的共享都会被改为1。
### 4 DataStream ApI
> Flink程序实际上由四大部分组成:执行环境,source,transformation,sink。
#### 4.1 执行环境
1)getExecutionEnvironment()
会自动进行判断,如果不是jar包中执行,则返回local模式的执行环境;如果是在jar包中,则会返回集群环境的执行环境。
```java
StreamExecutionEnvironment executionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment();
```
2)createLocalEnvironment(3)
创建本地执行环境,可以指定并行度。
```java
StreamExecutionEnvironment executionEnvironment = StreamExecutionEnvironment.createLocalEnvironment(3);
```
3)创建远程执行环境:可以指定主机名以及JobManager的端口号,jarPath等信息
```java
StreamExecutionEnvironment executionEnvironment = StreamExecutionEnvironment.createRemoteEnvironment("hadoop02",8081,3,"jarPath");
```
#### 4.2 source
##### 4.2.1 对接数据源
1)对接socketTextStream
```java
DataStreamSource socketTextStream = executionEnvironment.socketTextStream(hostname, port);
```
2)对接Kafka
添加pom依赖:
```xml
org.apache.flink
flink-connector-kafka_2.12
1.13.6
```
```java
Properties props = new Properties();
props.setProperty(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "hadoop02:9092");
props.setProperty(ConsumerConfig.GROUP_ID_CONFIG, "flink-kafka-source");
props.setProperty(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringDeserializer");
props.setProperty(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringDeserializer");
props.setProperty(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "latest");
DataStreamSource kafkaSource = executionEnvironment.addSource(new FlinkKafkaConsumer<>("flink-clicks", new SimpleStringSchema(), props));
```
3)自定义source:
非并行的:实现SourceFunction
并行的:实现ParallelSourceFunction接口
```java
DataStreamSource sourceStream = executionEnvironment.addSource(new SourceFunction() {
private volatile boolean running = true;
@Override
public void run(SourceContext ctx) throws InterruptedException {
//随机生成数据
Random random = new Random();
//定义字段的选取的数据集
String[] users = {"tom", "ailis", "kangkang"};
String[] urls = {"./index", "./home", "./fav", "./order?id=10"};
//执行数据的范围
while (running) {
String user = users[random.nextInt(users.length)];
String url = urls[random.nextInt(urls.length)];
ctx.collect(new Event(user, url, System.currentTimeMillis()));
Thread.sleep(100);
}
}
@Override
public void cancel() {
//update flag to control job
running = false;
}
});
```
##### 4.2.2 支持的数据类型
> Flink作为分布式数据处理框架,要分布式的处理这些数据,那么就不可避免的要面对数据的网络传输,状态落盘,故障恢复等问题,这就需要对数据进行序列化和反序列化。Flink使用TypeInfomation作为类型的基石。
1)基本数据类型
可以在BasicTypeInfo中找到基本数据类型以及其包装类,加上Void,String,Date,BigDecimal,BigInteger
2)数组类型
包含基本数据类型数组(primitive Array)和对象数组(object Array)
3)复杂数据类型
- Java元组类型:这是Flink内置的元组类型,是Java API的一部分,从Tuple0-25
- scala的样例类以及元组类型:不支持空字段。
- 行类型:可以认为是具有任意个字段的元组,并支持空字段。
- POJO:Flink自定义的类似于Java bean模式的类。
- 类是public和没有非静态的内部类。
- 类存在公共的无参构造器。
- 类中的所有字段是public且非final;或者有一个public的getter和setter方法。
- 辅助类型:option,Either,list,map等
- 泛型类型(Generic):Flink支持所有的java类和scala类,如果没有按照POJO类型的要求来定义,会被当作Flink的泛型类处理,无法获取其内部属性,且使用kryo来进行序列化。
4)Type Hints
Flink还具有一个类型提取系统,可以分析函数的输入和返回类型,自动获取类型信息,从而获取对应的序列化和反序列化器。但是Java中存在泛型擦除,在某些特殊的情况下(例如lambda表达式),自动提取的信息不够精细,这样就需要我们显示的提供类型信息。为了解决这类问题,Java API提供了专门的`Type Hints`。例如我们之前的word count。
使用之前:
```java
SingleOutputStreamOperator> tuple2Words = streamSource.flatMap((FlatMapFunction>) (s, collector) -> {
String[] words = s.split(" ");
for (String word : words) {
collector.collect(Tuple2.of(word, 1L));
}
}).returns(Types.TUPLE(Types.STRING, Types.LONG));
```
使用之后:
```java
.returns(new TypeHint>(){});
```
#### 4.3 转换算子
> 数据源读入数据之后,我们可以使用各种转换算子,将一个或多个DataStream转换为新的DataStream,Flink程序的核心就是所有的转换操作,他们决定了处理的业务逻辑。
##### 4.3.1 基本转换算子
> 本小节涉及到的转换算子
1. map
```java
SingleOutputStreamOperator users = eventSource.map(event -> event.user);
```
2. filter
```java
SingleOutputStreamOperator vips = eventSource.filter(event -> "jerry".equals(event.user));
```
3. FlatMap
```java
SingleOutputStreamOperator flatMapedSource = eventSource.flatMap((FlatMapFunction) (value, out) -> {
String[] data = value.split(" ");
for (String d : data) {
out.collect(d);
}
}).returns(new TypeHint() {
});
```
##### 4.3.2 聚合算子
> 计算的结果不仅仅依赖当前数据,还和之前的数据有关,相当于将所有的数据聚合到一起进行汇总合并,这就是所谓的"聚合"操作。
前置操作:keyBy(按键分区)
对于flink而言,DataStream没有直接进行聚合的API,因为我们对海量数据进行聚合肯定要进行分区并行处理,才可以提高效率,因此在FLink中,要做聚合,需要先进行分区,这个操作就是通过keyBy来完成的。
实现:通过计算key的hash值,然后对分区数进行取模运算来是实现的,所以key如果是POJO的话,必须重写hashCode方法。
1. max以及maxBy
```java
//max:只更改我们传入的列为最大值,其他列是该key是第一次出现的值:Event{user='tom', url='./index', timestamp=1970-01-01 08:00:40.0}
eventSource.keyBy((KeySelector) value -> value.user).max("timestamp").print("max:");
//maxBy:按照传入列,找到了列最大的那条记录:Event{user='tom', url='./order?id=10', timestamp=1970-01-01 08:00:40.0}
eventSource.keyBy((KeySelector) value -> value.user).maxBy("timestamp").print("maxBy:");
```
2.使用reduce来实现聚合操作
```java
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment executionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment();
executionEnvironment.setParallelism(1);
SingleOutputStreamOperator eventSource = SourceUtils.getEventSource(executionEnvironment);
//统计每个用户的访问频次
SingleOutputStreamOperator> userF = eventSource.map(event -> Tuple2.of(event.user, 1L)).returns(Types.TUPLE(Types.STRING,Types.LONG))
.keyBy(data -> data.f0)
.reduce((ReduceFunction>) (value1, value2) -> Tuple2.of(value1.f0, value1.f1 + value2.f1));
//选取当前最活跃的用户:我们想使用reduce进行操作,那么就必须使用keyBy,就必须要指定一个key,我们可以写死一个key来将所有的数据分到同一个分区中去,
// 这种方式要谨慎使用。
SingleOutputStreamOperator> maxClickUser = userF.keyBy(data -> "key").maxBy(1);
maxClickUser.print();
//reduce:可以实现一些自定义的聚合逻辑.
SingleOutputStreamOperator> maxClickUser2 = userF.keyBy(data -> "key")
.reduce((ReduceFunction>) (value1, value2) -> value1.f1>value2.f1?value1:value2);
maxClickUser2.print();
executionEnvironment.execute();
}
```
##### 4.3.3 自定义函数(UDF)
“富函数类”是DataStream API提供的一个函数类的接口,所有的Flink函数都有其Rich版本,一般以抽象类的形式出现。例如:RichMapFunction, RichFilterFunction等。相对于常规的函数类提供更多,更丰富的功能,可以获取运行时环境的上下文,并且拥有一些生命周期的方法。
- 生命周期方法
- Open:会开启一个算子的生命周期,适合做一些文件IO/数据库链接的创建,配置文件读取等一次性工作。
- Close:是生命周期中最后一个调用的方法,类似于解构方法,一般用来做清理的工作。
```java
public class Operator_RichMapFunction {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment executionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment();
executionEnvironment.setParallelism(1);
SingleOutputStreamOperator eventSource = SourceUtils.getEventSource(executionEnvironment);
eventSource.map(new MyRichFunction()).setParallelism(2).print();
executionEnvironment.execute();
}
public static class MyRichFunction extends RichMapFunction{
/**
* 当前任务实例被创建的时候调用一次
*/
@Override
public void open(Configuration parameters) throws Exception {
super.open(parameters);
System.out.println("open 生命周期方法被调用 " + getRuntimeContext().getIndexOfThisSubtask());
}
/**
* 当前任务实例被销毁的时候调用一次
*/
@Override
public void close() throws Exception {
super.close();
System.out.println("close 生命周期方法被调用 " + getRuntimeContext().getIndexOfThisSubtask());
}
@Override
public Integer map(Event value) throws Exception {
return value.user.length();
}
}
}
```
##### 4.3.4 物理分区--数据倾斜情况下
> 分区操作就是要将数据进行重新分布,传递到不同的流分区中进行下一步。keyBy是按照hash进行分区,是否分的均匀或者分到了哪里都是无法控制的,因此我们也称之为逻辑上的分区。Flink上下游任务之间的分区数不同的时候会自动的进行负载均衡。默认情况下使用rebalance的方式。
- shuffle:随机分区,尽量将数据分配的均匀
- rebalance:轮询分区
- rescale:重新缩放分区,将数据分成几个小组,然后小组内进行rebalance。如果存在Job执行存在多个TaskManager,多个Slot。使用Rescale可能会减少数据的网络传输,提高性能。
- broadcast:广播,主要用于将小数据集缓存到各个分区中,以分区为单位缓存一份数据据。
- global:全局分区,将全部的分区收集到一个分区,即便是后面的算子设置了并行度也没有用。
- partitionCustom:自定义重分区,传入一个分区器以及keySelector。
```java
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment executionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment();
executionEnvironment.setParallelism(1);
SingleOutputStreamOperator eventSource = SourceUtils.getEventSource(executionEnvironment);
//1.shuffle:随机分区,尽量将数据分配的均匀
//eventSource.shuffle().print().setParallelism(3);
//2.rebalance:轮询分区
//eventSource.rebalance().print().setParallelism(3);
//3.rescale:重新缩放分区,将数据分成几个小组,然后小组内进行rebalance。
DataStreamSource parallelSource = executionEnvironment.addSource(new RichParallelSourceFunction() {
@Override
public void run(SourceContext ctx) throws Exception {
for (int i = 1; i <= 8; i++) {
//将奇/偶分别发我往不同的task子任务
if (i % 2 == getRuntimeContext().getIndexOfThisSubtask()) {
ctx.collect(i);
}
}
}
@Override
public void cancel() {
}
});
parallelSource.setParallelism(2).rescale().print().setParallelism(4);
//parallelSource.setParallelism(2).global().print();
//最后打印出的并行度也是2
executionEnvironment.fromElements(1,2,3,4,5,6,7,8).partitionCustom(new Partitioner() {
@Override
public int partition(Integer key, int numPartitions) {
return key%2;
}
}, new KeySelector() {
@Override
public Integer getKey(Integer value) throws Exception {
return value;
}
}).print().setParallelism(4);
executionEnvironment.execute();
}
```
#### 4.4 Sink--输出算子
> Flink作为数据处理框架,最终还是要把计算处理的结果写入外部存储,为外部应用提供支持,Sink算子主要就是为了输出数据到外部系统。
##### 4.4.1 目前支持的连接器
- [Apache Kafka](https://nightlies.apache.org/flink/flink-docs-release-1.14/docs/connectors/datastream/kafka/) (source/sink)
- [Apache Cassandra](https://nightlies.apache.org/flink/flink-docs-release-1.14/docs/connectors/datastream/cassandra/) (sink)
- [Amazon Kinesis Streams](https://nightlies.apache.org/flink/flink-docs-release-1.14/docs/connectors/datastream/kinesis/) (source/sink)
- [Elasticsearch](https://nightlies.apache.org/flink/flink-docs-release-1.14/docs/connectors/datastream/elasticsearch/) (sink)
- [FileSystem](https://nightlies.apache.org/flink/flink-docs-release-1.14/docs/connectors/datastream/filesystem/) (sink)
- [RabbitMQ](https://nightlies.apache.org/flink/flink-docs-release-1.14/docs/connectors/datastream/rabbitmq/) (source/sink)
- [Google PubSub](https://nightlies.apache.org/flink/flink-docs-release-1.14/docs/connectors/datastream/pubsub/) (source/sink)
- [Hybrid Source](https://nightlies.apache.org/flink/flink-docs-release-1.14/docs/connectors/datastream/hybridsource/) (source)
- [Apache NiFi](https://nightlies.apache.org/flink/flink-docs-release-1.14/docs/connectors/datastream/nifi/) (source/sink)
- [Apache Pulsar](https://nightlies.apache.org/flink/flink-docs-release-1.14/docs/connectors/datastream/pulsar/) (source)
- [Twitter Streaming API](https://nightlies.apache.org/flink/flink-docs-release-1.14/docs/connectors/datastream/twitter/) (source)
- [JDBC](https://nightlies.apache.org/flink/flink-docs-release-1.14/docs/connectors/datastream/jdbc/) (sink)
- Apache Bahir项目附加的连接器:
- [Apache ActiveMQ](https://bahir.apache.org/docs/flink/current/flink-streaming-activemq/) (source/sink)
- [Apache Flume](https://bahir.apache.org/docs/flink/current/flink-streaming-flume/) (sink)
- [Redis](https://bahir.apache.org/docs/flink/current/flink-streaming-redis/) (sink)
- [Akka](https://bahir.apache.org/docs/flink/current/flink-streaming-akka/) (sink)
- [Netty](https://bahir.apache.org/docs/flink/current/flink-streaming-netty/) (source)
##### 4.4.2 常见的sink方式
1.FileSink
- writeAsText or writeAsCSV: 不支持同时写一份文件,因此最后写出的时候需要将并行设置为1.而且对于数据一致性无法保证。
- StreamingFileSink: implements CheckpointedFunction, CheckpointListener,因此可以保证数据一致性 。将数据先写入到不同的bucket,将bucket中的数据分割成一个个大小有限的分区文件。
- BulkFormatBuilder:对接hadoop的parquet格式的列数存储。
- RowFormatBuilder:对接行编码的方式
```java
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment executionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment();
SingleOutputStreamOperator eventSource = SourceUtils.getEventSource(executionEnvironment);
//eventSource.writeAsText("data/chapter01/sink/file_sink");
StreamingFileSink fileSink = StreamingFileSink.forRowFormat(new Path("data/chapter01/sink/file_sink"), new SimpleStringEncoder<>("UTF-8"))
.withRollingPolicy(DefaultRollingPolicy.builder()
//设置文件的最大大小
.withMaxPartSize(1024 * 1024 * 1024)
//设置一个文件的最长写入的最长时间
.withRolloverInterval(TimeUnit.MINUTES.toMillis(15))
//设置如果多长时间不活跃就重新开一个文件
.withInactivityInterval(TimeUnit.MINUTES.toMillis(5)).build())
.build();
eventSource.map(Event::toString).addSink(fileSink);
executionEnvironment.execute();
}
```
2.kafkaSink
```java
/**
* 从kafka中读取数据-->进行数据转换-->写回到kafka中。
*
* @author code1997
*/
public class KafkaSink {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment executionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment();
executionEnvironment.setParallelism(1);
Properties properties = new Properties();
properties.setProperty(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "hadoop02:9092");
DataStreamSource kafkaSource = executionEnvironment.addSource(new FlinkKafkaConsumer("flink-clicks", new SimpleStringSchema(), properties));
//flink进行转换处理
SingleOutputStreamOperator events = kafkaSource.map(new MapFunction() {
@Override
public String map(String value) throws Exception {
String[] fields = value.split(",");
return new Event(fields[0].trim(), fields[1].trim(), Long.valueOf(fields[2].trim())).toString();
}
});
//写回到kafka中去
Properties produceConfig = new Properties();
produceConfig.setProperty(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "hadoop02:9092");
events.addSink(new FlinkKafkaProducer<>("flink-events", new SimpleStringSchema(), produceConfig));
executionEnvironment.execute();
}
}
```
3.RedisSink--Bahir
pom
```xml
org.apache.bahir
flink-connector-redis_2.11
1.0
```
code:
```java
/**
* 将数据写入到redis中
*
* @author code1997
*/
public class RedisSinkDemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment executionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment();
SingleOutputStreamOperator eventSource = SourceUtils.getEventSource(executionEnvironment);
FlinkJedisPoolConfig redisConfig = new FlinkJedisPoolConfig.Builder().setHost("docker_server").build();
eventSource.addSink(new RedisSink<>(redisConfig, new RedisMapper() {
/**
* 通过什么方式来操作redis
*/
@Override
public RedisCommandDescription getCommandDescription() {
//用户的点击事件表
return new RedisCommandDescription(RedisCommand.HSET, "users");
}
@Override
public String getKeyFromData(Event event) {
return event.user;
}
@Override
public String getValueFromData(Event event) {
return event.toString();
}
}));
executionEnvironment.execute();
}
}
```
4. ES
pom:
```xml
org.apache.flink
flink-connector-elasticsearch7_${scala.binary.version}
${flink.version}
```
code:
```java
/**
* 存储数据到es然后使用kibana进行查询.
* GET _search
* {
* "query": {
* "match": {
* "_index": "clicks"
* }
* }
*
* @author code1997
*/
public class EsSinkDemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment executionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment();
SingleOutputStreamOperator eventSource = SourceUtils.getEventSource(executionEnvironment);
ArrayList hosts = new ArrayList<>();
hosts.add(new HttpHost("docker_server", 9200));
eventSource.addSink(new ElasticsearchSink.Builder<>(hosts, new ElasticsearchSinkFunction() {
@Override
public void process(Event event, RuntimeContext runtimeContext, RequestIndexer requestIndexer) {
HashMap map = new HashMap<>();
map.put(event.user, event.toString());
IndexRequest indexRequest = Requests.indexRequest().index("clicks").source(map);
requestIndexer.add(indexRequest);
}
}).build());
executionEnvironment.execute();
}
}
```
5. mysql
pom:
```xml
org.apache.flink
flink-connector-jdbc_${scala.binary.version}
${flink.version}
mysql
mysql-connector-java
8.0.20
```
code:
```java
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment executionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment();
SingleOutputStreamOperator eventSource = SourceUtils.getEventSource(executionEnvironment);
String sql = "insert into flink_demo.clicks values(?,?)";
eventSource.addSink(JdbcSink.sink(sql, new JdbcStatementBuilder() {
@Override
public void accept(PreparedStatement preparedStatement, Event event) throws SQLException {
preparedStatement.setString(1, event.user);
preparedStatement.setString(2, event.url);
}
}, new JdbcConnectionOptions.JdbcConnectionOptionsBuilder()
.withUrl("jdbc:mysql://docker_server:3306/flink_demo?useSSL=true&useUnicode=true&characterEncoding=utf-8&serverTimezone=Asia/Shanghai")
.withDriverName("com.mysql.cj.jdbc.Driver")
.withUsername("root")
.withPassword("19971001")
.build()));
executionEnvironment.execute();
}
```
result:
6. 自定义Sink输出
> 实际就是自定义类实现SinkFunction或者RichSinkFunction接口,重写invoke方法。但是我们可能无法实现数据一致性的保障,因此在不需要保证数据一致性的情况下,我们可以自定义实现sourceFunction。
### 5 window
#### 5.1 时间
时间:一般分为事件时间和处理时间两种。事件流在分布式系统中因为各种原因可能会出现乱序,因此我们就需要考量我们需要哪一种时间。对于事件事件,Flink使用另外的标志来表示事件时间进展,在Flink中把它叫做事件时间的水位线(water marks)。
Flink:早期的版本默认的时间语义是处理时间,在1.12版本开始,Flink将事件事件作为默认的时间语义。
##### 5.1.1 水位线
在窗口的处理过程中,我们可以基于数据的时间戳来进行时间的推进。在Flink中,用来衡量事件时间(Event Time)进展的标记,就被称作水位线(WaterMark)。
1.什么时候产生水位线
1)有序流
1. 如果数据比较稀疏:那么我们对每条数据提取时间戳是没有问题的。
2. 如果数据比较多:我们对每一条数据都提取数据,那么就会加大处理的压力,那么我们可以周期性的提取一些数据,使用他们的时间戳来推动水位线的前进。
2)无序流
1. 如果数据比较稀疏:那么我们对每条数据提取时间戳+时间比对。
2. 如果数据比较多:周期性处理+时间比对。
如果使用以上两种方式来统计数据,结果可能存在偏差,我们无法处理迟到的数据,为了让窗口可以正确的收集到迟到的数据,我们可以等上一段时间(经验上考虑等多久)。水位线代表当前的事件时间时钟,而且可以在数据的时间戳基础上加一点延迟来保证不丢数据。
2.水位线的特点
- 水位线是插入到数据流中的一个标记,可以认为是一个特殊的数据。
- 水位线的主要内容是一个时间戳,用来表示当前事件时间的进展。
- Watermark 是用于处理乱序事件的, 而正确的处理乱序事件, 通常用
Watermark 机制结合 window 来实现。
Watermark 可以理解成一个延迟触发机制,我们可以设置 Watermark 的延时时长 t,每次系统会校验已经到达的数据中最大的 maxEventTime,然后认定 eventTime小于 maxEventTime - t 的所有数据都已经到达,如果有窗口的停止时间等于maxEventTime – t,那么这个窗口被触发执行。
3.水位线的生成原则
水位线是用来保证窗口处理结果的正确性,如果不能正确处理所有乱序数据,可以尝试调大延迟时间。
- 如果我们想要数据更加准确,那么我们可以将水位线的延迟设置的更高一点,等待的时间越长,越不容易漏掉数据,不过延迟就会增大。
- 如果我们希望处理的快,实时性强,那么我们可以将水位线延迟设置的更低一点,这样的情况下,可能会导致窗口漏数据,导致窗口计算结果不精确。
4.代码实现
WatermarkGenerator(指定watermark生成策略:事件触发或者断点式)+ TimestampAssigner(如何提取时间戳)。
- 有序数据:forMonotonousTimestamps
```java
SingleOutputStreamOperator eventSource = SourceUtils.getEventSource(executionEnvironment)
//调用flink内置的针对于有序流的watermark策略
.assignTimestampsAndWatermarks(WatermarkStrategy.forMonotonousTimestamps().withTimestampAssigner(new SerializableTimestampAssigner() {
@Override
public long extractTimestamp(Event element, long recordTimestamp) {
return element.timestamp;
}
}));
```
- 无序数据:forBoundedOutOfOrderness
```java
SingleOutputStreamOperator eventSource2 = SourceUtils.getEventSource(executionEnvironment)
//调用flink内置的针对于有序流的watermark策略
.assignTimestampsAndWatermarks(WatermarkStrategy.forBoundedOutOfOrderness(Duration.ofSeconds(2)).withTimestampAssigner(new SerializableTimestampAssigner() {
@Override
public long extractTimestamp(Event element, long recordTimestamp) {
return element.timestamp;
}
}));
```
水位线是前闭合后开放的,源码中实现:最大事件-延迟时间-1ms。
```java
/**
* A WatermarkGenerator for situations where records are out of order, but you can place an upper
* bound on how far the events are out of order. An out-of-order bound B means that once an event
* with timestamp T was encountered, no events older than {@code T - B} will follow any more.
*
* The watermarks are generated periodically. The delay introduced by this watermark strategy is
* the periodic interval length, plus the out-of-orderness bound.
*/
@Public
public class BoundedOutOfOrdernessWatermarks implements WatermarkGenerator {
/** The maximum timestamp encountered so far. */
private long maxTimestamp;
/** The maximum out-of-orderness that this watermark generator assumes. */
private final long outOfOrdernessMillis;
/**
* Creates a new watermark generator with the given out-of-orderness bound.
*
* @param maxOutOfOrderness The bound for the out-of-orderness of the event timestamps.
*/
public BoundedOutOfOrdernessWatermarks(Duration maxOutOfOrderness) {
checkNotNull(maxOutOfOrderness, "maxOutOfOrderness");
checkArgument(!maxOutOfOrderness.isNegative(), "maxOutOfOrderness cannot be negative");
this.outOfOrdernessMillis = maxOutOfOrderness.toMillis();
// start so that our lowest watermark would be Long.MIN_VALUE.
this.maxTimestamp = Long.MIN_VALUE + outOfOrdernessMillis + 1;
}
// ------------------------------------------------------------------------
@Override
public void onEvent(T event, long eventTimestamp, WatermarkOutput output) {
maxTimestamp = Math.max(maxTimestamp, eventTimestamp);
}
@Override
public void onPeriodicEmit(WatermarkOutput output) {
output.emitWatermark(new Watermark(maxTimestamp - outOfOrdernessMillis - 1));
}
}
```
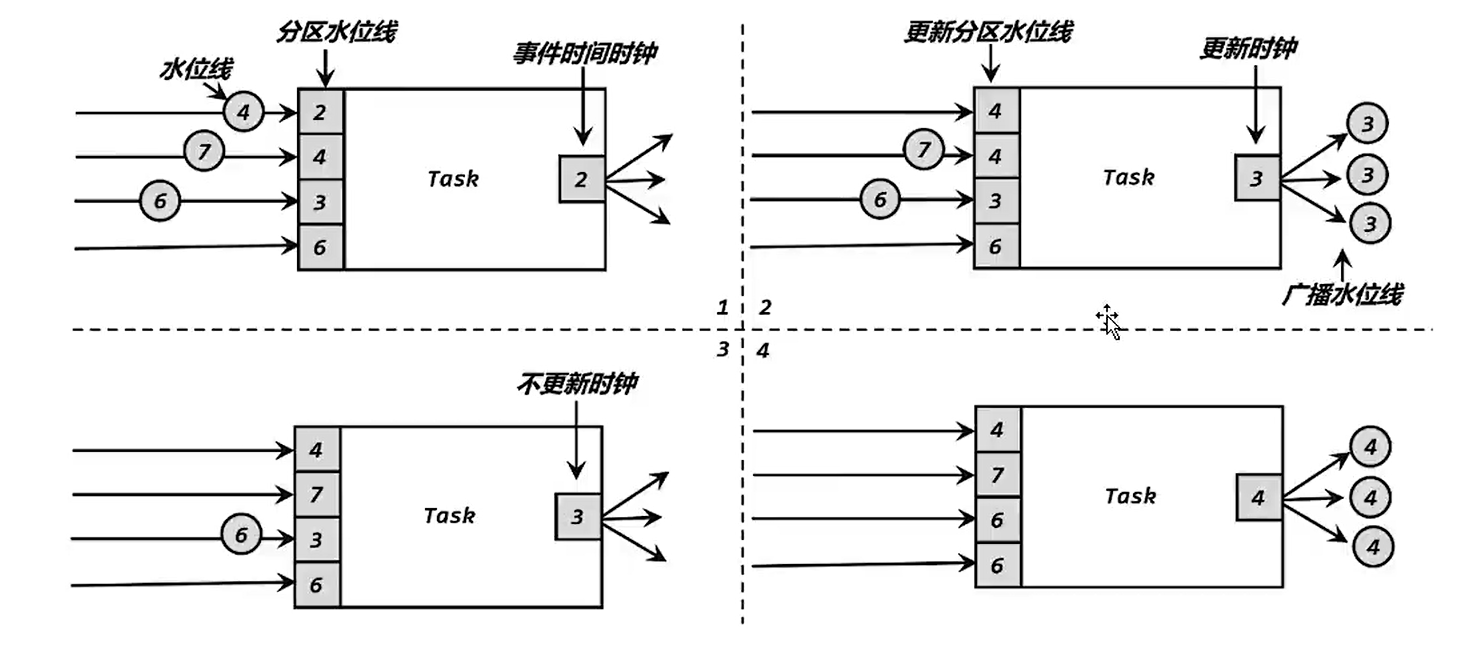
5.水位线的传递
水位线是由上游任务广播到下游任务的,如果上游有多个分区的数据传递过来的水位线是不一样的,下游会将所有分区的watermark保存起来,然后比较,以最小的为准。
#### 5.2 window的类型
1. window的理解
streaming 流式计算是一种被设计用于处理无限数据集的数据处理引擎,而无限数据集是指一种不断增长的本质上无限的数据集,而 window 是一种切割无限数据为有限块进行处理的手段。
Window 是Flink无限数据流处理的核心,Window 将一个无限的 stream 拆分成有限大小的” buckets” 桶, 我们可以在这些桶上做计算操作。
2. bucket
> 桶不是静态准备好的,而是当该时间段的数据到了之后,自动创建的。
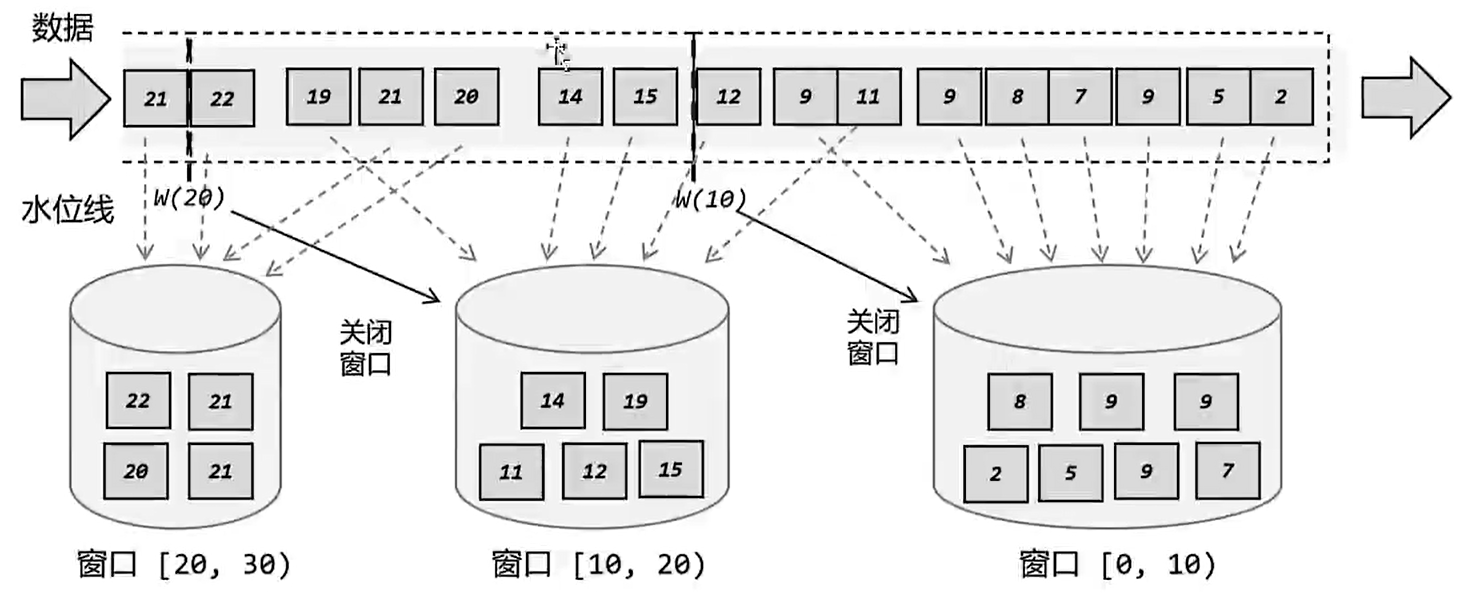
3.窗口的分类
1. 按照驱动类型分类
1. 时间窗口:按照时间段去截取数据窗口。
2. 计数窗口:按照固定的数据的个数来划分窗口,每一个窗口中的数据是一样的。
2. 按照窗口分配数据的规则分类
1. 滚动窗口(Tumbling windows):有固定的大小,是一种对数据进行均匀切片的划分方式,窗口之间不能重叠,所以数据只能被分到唯一的一个窗口中。可以基于时间定义,也可以基于数量来定义,只需要指定窗口大小。
2. 滑动窗口(Sliding windows):和滚动窗口类似,大小也是固定的,但是窗口之间不是首位相接的,而是可以错开一定的位置的。需要传入两个参数:窗口大小,滑动步长(可以理解为统计的频次)。如果我们将滑动步长和窗口大小设置为一样,那么实际上就是滚动窗口了。
3. 会话窗口:基于会话来对数据进行分组,只能基于时间来定义。最重要的参数是会话的超时时间(gap),如果两个数据的时间间隔小于指定的大小,那说明还在保持会话,他们就属于同一个窗口;如果大于size,那么新来的数据就应该属于新的会话窗口,前一个窗口就应该关闭了。
4. 全局窗口:全局有效,会将相同的key的所有数据都分配到同一个窗口中,这种窗口没有结束的时候,默认是不会触发计算的,如果希望他能对数据进行计算处理,还需要自定义“触发器(trigger)”。Flink 的计数窗口(Count window)底层就是使用全局窗口实现的。
3.是否按键分区
1. 按键分区窗口:使用keyBy操作之后,数据流会按照key被分为多条逻辑流,这个就是KeyedStream,基于这种流做窗口操作的时候,窗口计算会在多个并行子任务上同时执行,相同的key的数据会被发送到同一个并行子任务,窗口操作会基于每个key进行单独处理,可以认为每个key上都定义了一组窗口,各自独立的进行统计计算。
```java
stream.keyBy().window()
```
2. 非按键分区:这种方式窗口逻辑只会在一个task上执行任务,相当于并行度变成了1,实际应用中`不推荐`。
```java
stream.windowAll()
```
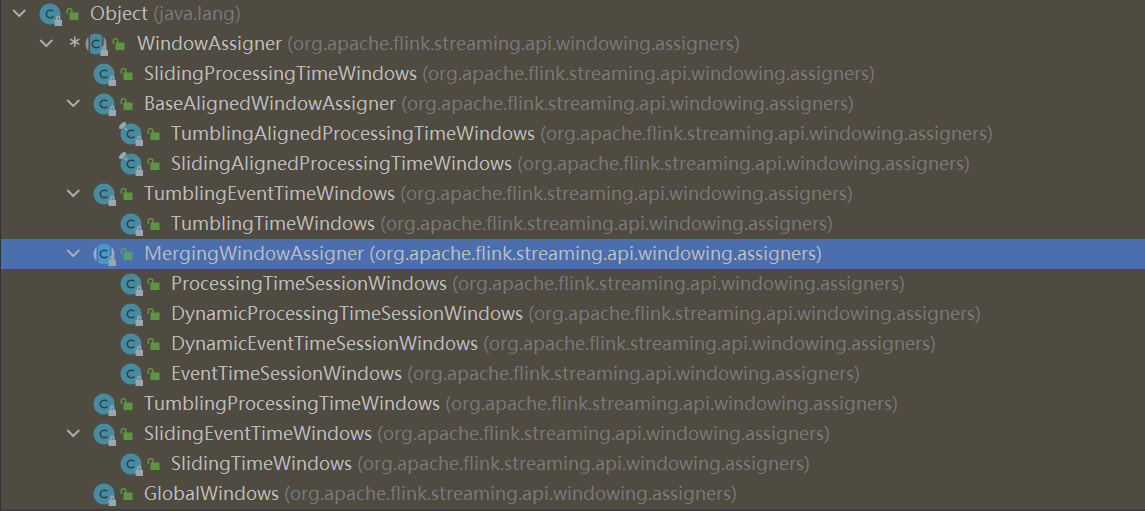
4.窗口分配器(window Assigners)
作用:主要用于定义数据应该被分配到哪一个窗口中。
5 窗口函数
作用:单独的window Assigners是不构成operator的,需要和一个窗口函数配合使用,根据处理的方式,我们分为两类:增量聚合函数和全窗口函数。
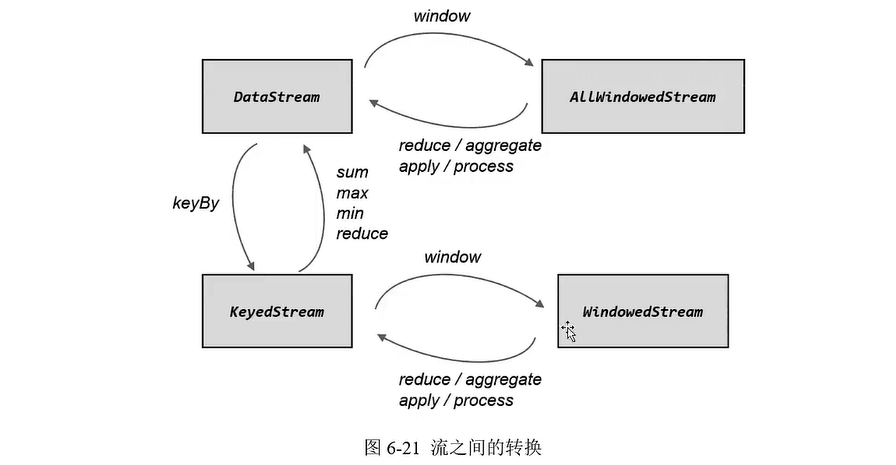
- 增量聚合函数:使用流处理的思路,每来一个数据我们就在之前的结果上聚合一次,这就是“增量聚合”。例如:ReduceFunction和AggregateFunction。
- ReduceFunction:规约函数要求输入输出的数据类型是一致的。
- AggregateFunction:输出/输出类型可以不一致
- 存在三个类型:
- 输入类型IN:输入流中元素的数据类型。
- 累加器类型ACC:我们进行聚合的中间状态类型。
- 输出类型OUT:最终计算结果的类型。
- 四个接口:
- createAccumulator:创建一个累加器,这就是为聚合创建了一个初始状态,每个聚合任务只会调用一次。
- add:将输入的元素添加到累加器中。
- getResult:从累加器中提取聚合的输出结果。
- merge:合并两个累加器,并将合并后的在状态作为一个累加器返回。
- 全窗口函数:批处理的方式,计算先收集窗口中的数据,并在内部缓存起来,等到窗口要输出结果的时候再取出数据进行计算。
- 窗口函数(WindowFunction):通过WindowedStream.apply()的方式使用,早期版本,会被ProcessWindowFunction所取代。
- ProcessWindowFunction:继承AbstractRichFunction可以获取应用上下文信息。
实际的项目中:增量聚合函数(agg)+全窗口函数(processWindow)
```java
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment executionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment();
SingleOutputStreamOperator eventSource = SourceUtils.getEventSource(executionEnvironment)
//调用flink内置的针对于有序流的watermark策略
.assignTimestampsAndWatermarks(WatermarkStrategy.forBoundedOutOfOrderness(Duration.ofSeconds(2)).withTimestampAssigner(new SerializableTimestampAssigner() {
@Override
public long extractTimestamp(Event element, long recordTimestamp) {
return element.timestamp;
}
}));
eventSource.keyBy(event -> event.url)
//滑动事件时间窗口
//.window(SlidingEventTimeWindows.of(Time.hours(1)))
//滚动事件时间窗口:默认是整点,可以通过offset来进行调整
.window(TumblingEventTimeWindows.of(Time.seconds(2L)))
//聚合函数:
.aggregate(new WindowAggAndProcessTest.MyAggFunction(),
new WindowAggAndProcessTest.MyProcessFunction()
).print();
executionEnvironment.execute();
}
static class MyAggFunction implements AggregateFunction {
@Override
public Long createAccumulator() {
return 0L;
}
@Override
public Long add(Event value, Long accumulator) {
return accumulator + 1;
}
@Override
public Long getResult(Long accumulator) {
return accumulator;
}
@Override
public Long merge(Long a, Long b) {
return null;
}
}
static class MyProcessFunction extends ProcessWindowFunction {
@Override
public void process(String s, ProcessWindowFunction.Context context, Iterable elements, Collector out) throws Exception {
long start = context.window().getStart();
long end = context.window().getEnd();
long count = elements.iterator().next();
out.collect(new UrlVisitBean(s, count, start, end));
}
}
```
6 其他API
1. 触发器(Trigger):用于定义什么时候触发计算,Trigger是窗口算子内部属性,每个窗口分配器(windowAssigner)都会对应一个默认的触发器;对于Flink内置的窗口类型,他们的触发器已经做了实现。
2. 允许延迟(Allowed Lateness):真正的延迟窗口的关闭时间。
3. 将迟到的数据放到侧输出流中sideOutputLateData:如果数据在窗口关闭之后依旧有漏网之鱼,我们可以使用侧输出流的方式,最终将两个流的数据merge到一起,实现最终一致性。
#### 5.3 处理迟到数据
- watermark:来处理迟到数据,它实际是将所有的操作都延迟,这个操作过重。一般情况下我们设置watermark的延迟时间在1,2ms。
- allowedLateness:延迟窗口关闭时间,还是允许一段时间内还可以将数据放过来。
- 侧输出流:类似于lambda架构,使用双流的方式实现对延迟数据的处理
```java
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment executionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment();
executionEnvironment.setParallelism(1);
executionEnvironment.getConfig().setAutoWatermarkInterval(100);
SingleOutputStreamOperator socketStream = executionEnvironment.socketTextStream("hadoop02", 7777).map(new MapFunction() {
@Override
public Event map(String value) throws Exception {
String[] data = value.split(",");
return new Event(data[0].trim(), data[1].trim(), Long.valueOf(data[2].trim()));
}
}).assignTimestampsAndWatermarks(WatermarkStrategy.forBoundedOutOfOrderness(Duration.ofSeconds(2L)).withTimestampAssigner(new SerializableTimestampAssigner() {
@Override
public long extractTimestamp(Event element, long recordTimestamp) {
return element.timestamp;
}
}));
socketStream.print("input");
//定义输出标签:注意泛型擦除
OutputTag lateTag = new OutputTag("lateStream") {
};
SingleOutputStreamOperator result = socketStream.keyBy(data -> data.url).window(TumblingEventTimeWindows.of(Time.seconds(10L)))
//延迟1秒+2秒watermark=3s延迟,如果小于这个延迟时间,那么数据就会放到result里面,但是如果延迟超过这个时间那么就会输出到late的流中.
.allowedLateness(Time.seconds(1))
.sideOutputLateData(lateTag)
.aggregate(new WindowAggAndProcessTest.MyAggFunction(), new WindowAggAndProcessTest.MyProcessFunction());
result.print("result");
//获取侧输出流的结果:只要前一个窗口没有关闭,一旦来属于其中的数据,那么就会触发一次计算.
result.getSideOutput(lateTag).print("late");
executionEnvironment.execute();
}
```
### 6 处理函数--ProcessFunction
#### 6.1 基本介绍
1. 为什么使用?
如果我们需要对时间有更精细的控制,获取水位线,设置要把控时间,这就不是基本的时间窗口可以实现的了,就需要使用更底层ProcessFunction。提供一个定时服务(TimerService),我们可以通过它访问流中的事件(event),事件戳(timestamp),水位线(watermark),甚至可以注册“定时事件”。继承了AbstractRichFunction类,所以可以获取各种状态和上下文信息,是DataStream Api的底层基础。
2. 分类
- ProcessFunction:无法注册定时器
- KeyedProcessFunction:可以使用定时器
- ProcessWindowFunction:无法直接使用定时器,但是可以使用trigger来实现。
- CoProcessFunction
- ProcessJoinFunction
- BroadcastProcessFunction
- KeyedBroadcastProcessFunction
- ProcessAllWindowFunction
#### 6.2 TopN
> 方案1:使用ProcessAllwindowFunction的方式,处理分区数目为1,数据量大的时候会出现问题。
```java
public class TopNTest2 {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment executionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment();
SingleOutputStreamOperator sourceStream = SourceUtils.getEventSource(executionEnvironment).assignTimestampsAndWatermarks(WatermarkStrategy.forBoundedOutOfOrderness(Duration.ZERO).withTimestampAssigner(new SerializableTimestampAssigner() {
@Override
public long extractTimestamp(Event element, long recordTimestamp) {
return element.timestamp;
}
}));
sourceStream.map(data -> data.url)
.windowAll(SlidingEventTimeWindows.of(Time.seconds(10), Time.seconds(5)))
.aggregate(new UrlHashMapCountAgg(), new UrlAllWindowResult()).print();
executionEnvironment.execute();
}
public static class UrlHashMapCountAgg implements AggregateFunction, ArrayList>> {
@Override
public HashMap createAccumulator() {
return new HashMap<>();
}
@Override
public HashMap add(String value, HashMap accumulator) {
Long oldCount = accumulator.getOrDefault(value, 0L);
accumulator.put(value, oldCount + 1);
return accumulator;
}
@Override
public ArrayList> getResult(HashMap accumulator) {
ArrayList> list = new ArrayList<>();
for (Map.Entry entry : accumulator.entrySet()) {
list.add(Tuple2.of(entry.getKey(), entry.getValue()));
}
list.sort(new Comparator>() {
@Override
public int compare(Tuple2 o1, Tuple2 o2) {
return (int) (o2.f1 - o1.f1);
}
});
return list;
}
@Override
public HashMap merge(HashMap a, HashMap b) {
return null;
}
}
public static class UrlAllWindowResult extends ProcessAllWindowFunction>, String, TimeWindow> {
@Override
public void process(ProcessAllWindowFunction>, String, TimeWindow>.Context context, Iterable>> elements, Collector out) throws Exception {
ArrayList> list = elements.iterator().next();
StringBuilder result = new StringBuilder();
Timestamp start = new Timestamp(context.window().getStart());
Timestamp end = new Timestamp(context.window().getEnd());
result.append("------------ window [" + start + "~" + end + "]Top 2--------------------\n");
for (int i = 0; i < list.size() && i < 2; i++) {
Tuple2 urlInfo = list.get(i);
result.append("No" + i + ". " + urlInfo.f0 + " = " + urlInfo.f1 + "\n");
}
result.append("----------------------------------------\n");
out.collect(result.toString());
}
}
}
```
> 方案2:聚合+windowEndTimeKeyby+KeyedProcessFunction+状态列表
```java
public class TopNTest1 {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment executionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment();
SingleOutputStreamOperator sourceStream = SourceUtils.getEventSource(executionEnvironment)
.assignTimestampsAndWatermarks(WatermarkStrategy.forBoundedOutOfOrderness(Duration.ZERO).withTimestampAssigner(new SerializableTimestampAssigner() {
@Override
public long extractTimestamp(Event element, long recordTimestamp) {
return element.timestamp;
}
}));
SingleOutputStreamOperator urlCountStream = sourceStream.keyBy(event -> event.url)
.window(SlidingEventTimeWindows.of(Time.seconds(10), Time.seconds(5)))
.aggregate(new WindowAggAndProcessTest.MyAggFunction(), new WindowAggAndProcessTest.MyProcessFunction());
urlCountStream.print("url count");
urlCountStream.keyBy(data -> data.windowEnd)
.process(new TopNProcessResult(2))
.print("top n");
executionEnvironment.execute();
}
public static class TopNProcessResult extends KeyedProcessFunction {
private Integer n;
//定义状态列表,而且这个对象需要交给flink进行管理,所以不能直接初始化,应该在生命周期函数中进行初始化。
private ListState urlViewCountListState;
public TopNProcessResult(Integer n) {
this.n = n;
}
@Override
public void open(Configuration parameters) throws Exception {
urlViewCountListState = getRuntimeContext().getListState(
new ListStateDescriptor("url_count_list", Types.POJO(UrlVisitBean.class))
);
}
@Override
public void processElement(UrlVisitBean value, KeyedProcessFunction.Context ctx, Collector out) throws Exception {
urlViewCountListState.add(value);
//注册一个windowEnd+1ms的定时器
ctx.timerService().registerEventTimeTimer(ctx.getCurrentKey() + 1);
}
@Override
public void onTimer(long timestamp, KeyedProcessFunction.OnTimerContext ctx, Collector out) throws Exception {
//定时器处理
ArrayList list = new ArrayList<>();
for (UrlVisitBean urlVisitBean : urlViewCountListState.get()) {
list.add(urlVisitBean);
}
list.sort(new Comparator() {
@Override
public int compare(UrlVisitBean o1, UrlVisitBean o2) {
return (int) (o2.count - o1.count);
}
});
StringBuilder result = new StringBuilder();
Timestamp end = new Timestamp(ctx.getCurrentKey());
result.append("------------ window [ 窗口结束时间:" + end + "]Top 2--------------------\n");
for (int i = 0; i < list.size() && i < 2; i++) {
UrlVisitBean urlInfo = list.get(i);
result.append("No" + i + ". " + urlInfo.url + " = " + urlInfo.count + "\n");
}
result.append("----------------------------------------\n");
out.collect(result.toString());
}
}
}
```
### 7 多流转换
> 多流转换可以分为`分流`和`合流`两大类。目前分流主要通过侧输出流来实现。合流的算子比较丰富,根据不同的需求可以掉哟个union,connect,join以及coGroup等接口进行连接合并操作。
#### 7.1 分流
> 使用侧输出流的方式实现。
```java
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment executionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment();
SingleOutputStreamOperator eventSource = SourceUtils.getEventSource(executionEnvironment).assignTimestampsAndWatermarks(WatermarkStrategy.forBoundedOutOfOrderness(Duration.ZERO).withTimestampAssigner(new SerializableTimestampAssigner() {
@Override
public long extractTimestamp(Event element, long recordTimestamp) {
return element.timestamp;
}
}));
//如果用户是tom,那么将数据输出到
OutputTag> tomTag = new OutputTag<>("tom", Types.TUPLE(Types.STRING, Types.STRING, Types.LONG));
SingleOutputStreamOperator processedStream = eventSource.process(new ProcessFunction() {
@Override
public void processElement(Event value, ProcessFunction.Context ctx, Collector out) throws Exception {
if ("tom".equals(value.user)) {
ctx.output(tomTag, Tuple3.of(value.user, value.url, value.timestamp));
} else {
out.collect(value);
}
}
});
processedStream.getSideOutput(tomTag).print("tom stream");
processedStream.print("other user stream");
executionEnvironment.execute();
}
```
#### 7.2 合流
> 将多条流合并起来。
##### 7.2.1 Union
要求流中的数据类型必须相同,合并之后的新流会包括所有流的元素,数据类型不变,使用。
问题:如果两个流的watermark延迟是不一样的,那么合并之后的水位线是什么?--注意水位线的滞后,先处理再更新水位线。
demo:
```java
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment executionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment();
executionEnvironment.setParallelism(1);
String hostname = "hadoop02";
int port1 = 7777;
int port2 = 8888;
SingleOutputStreamOperator source1 = executionEnvironment.socketTextStream(hostname, port1).map(data -> {
String[] split = data.split(",");
return new Event(split[0].trim(), split[1].trim(), Long.valueOf(split[2].trim()));
}).returns(Types.POJO(Event.class))
.assignTimestampsAndWatermarks(WatermarkStrategy.forBoundedOutOfOrderness(Duration.ofSeconds(5)).withTimestampAssigner(new SerializableTimestampAssigner() {
@Override
public long extractTimestamp(Event element, long recordTimestamp) {
return element.timestamp;
}
}));
source1.print("source1");
SingleOutputStreamOperator source2 = executionEnvironment.socketTextStream(hostname, port2).map(data -> {
String[] split = data.split(",");
return new Event(split[0].trim(), split[1].trim(), Long.valueOf(split[2].trim()));
}).returns(Types.POJO(Event.class))
.assignTimestampsAndWatermarks(WatermarkStrategy.forBoundedOutOfOrderness(Duration.ofSeconds(10)).withTimestampAssigner(new SerializableTimestampAssigner() {
@Override
public long extractTimestamp(Event element, long recordTimestamp) {
return element.timestamp;
}
}));
source2.print("source2");
source1.union(source2).process(new ProcessFunction() {
@Override
public void processElement(Event value, ProcessFunction.Context ctx, Collector out) throws Exception {
out.collect("水位线:" + ctx.timerService().currentWatermark());
}
}).print("watermark");
executionEnvironment.execute();
}
```
console:
```txt
source2> Event{user='tom', url='./index', timestamp=1970-01-01 08:00:01.0}
watermark> 水位线:-9223372036854775808
source1> Event{user='tom', url='./index', timestamp=1970-01-01 08:00:02.0}
watermark> 水位线:-9223372036854775808
source1> Event{user='tom', url='./index', timestamp=1970-01-01 08:00:02.0}
watermark> 水位线:-9001
source2> Event{user='tom', url='./index', timestamp=1970-01-01 08:00:10.0}
watermark> 水位线:-9001
source1> Event{user='tom', url='./index', timestamp=1970-01-01 08:00:09.0}
watermark> 水位线:-3001
source1> Event{user='tom', url='./index', timestamp=1970-01-01 08:00:09.0}
watermark> 水位线:-1
source2> Event{user='tom', url='./index', timestamp=1970-01-01 08:00:10.0}
watermark> 水位线:-1
```
结论:水位线会取多个流中比较小的那个,水位线的延迟会取多个流中延迟大的。
##### 7.2.2 Connect
> 多个流的类型不一致,可以使用connect进行连接,获取的是connectedStream
1. 如果想要再次获取DataStream,我们需要协同函数进行类型转换,map/flatmap中传入CoMapFunction/CoFlatMapFunction,将多个流的类型统一起来。
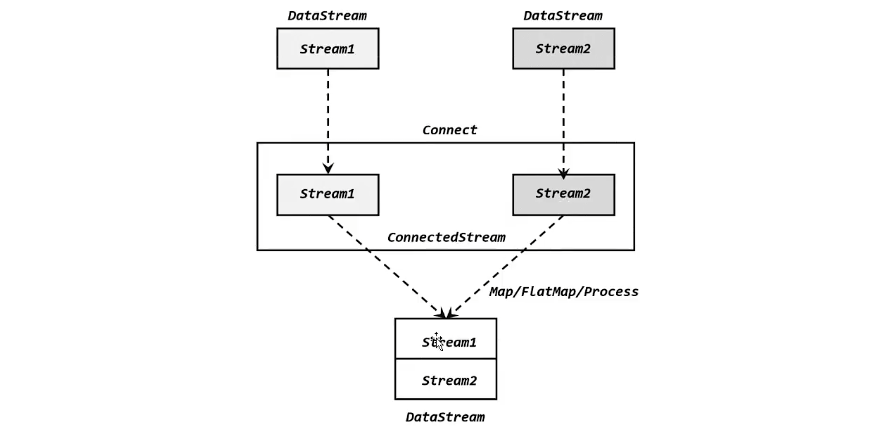
CoMapFunction Demo:
```java
DataStreamSource source1 = executionEnvironment.fromElements(1, 2, 3);
DataStreamSource source2 = executionEnvironment.fromElements(4L, 5L, 6L);
source1.connect(source2).map(new CoMapFunction() {
@Override
public String map1(Integer value) throws Exception {
return "Integer type: " + value;
}
@Override
public String map2(Long value) throws Exception {
return "Long type: " + value;
}
}).print("result");
```
2. 双流connect来对账功能:使用keyBy可以将两个流连接到一起进行处理
```java
/**
* connect实现对账功能.
*
* @author code1997
*/
public class BillCheckDemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment executionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment();
executionEnvironment.setParallelism(1);
SingleOutputStreamOperator> appStream = executionEnvironment.fromElements(
Tuple3.of("order-1", "app", 1000L),
Tuple3.of("order-2", "app", 2000L),
Tuple3.of("order-3", "app", 3500L)
).assignTimestampsAndWatermarks(WatermarkStrategy.>forBoundedOutOfOrderness(Duration.ZERO).withTimestampAssigner(new SerializableTimestampAssigner>() {
@Override
public long extractTimestamp(Tuple3 element, long recordTimestamp) {
return element.f2;
}
}));
SingleOutputStreamOperator> thirdPartStream = executionEnvironment.fromElements(
Tuple4.of("order-1", "third-party", "success", 3000L),
Tuple4.of("order-3", "third-party", "success", 4000L)
).assignTimestampsAndWatermarks(WatermarkStrategy.>forBoundedOutOfOrderness(Duration.ZERO).withTimestampAssigner(new SerializableTimestampAssigner>() {
@Override
public long extractTimestamp(Tuple4 element, long recordTimestamp) {
return element.f3;
}
}));
appStream.connect(thirdPartStream).keyBy(data -> data.f0, data -> data.f0)
.process(new OrderMatchResult())
.print();
executionEnvironment.execute();
}
public static class OrderMatchResult extends CoProcessFunction, Tuple4, String> {
//定义状态变量,用来保存已经到达的事件
private ValueState> appEventState;
private ValueState> thirdPartyEventState;
@Override
public void open(Configuration parameters) throws Exception {
appEventState = getRuntimeContext().getState(new ValueStateDescriptor<>("app-event", Types.TUPLE(Types.STRING, Types.STRING, Types.LONG)));
thirdPartyEventState = getRuntimeContext().getState(new ValueStateDescriptor<>("third-party-event", Types.TUPLE(Types.STRING, Types.STRING, Types.STRING, Types.LONG)));
}
@Override
public void processElement1(Tuple3 value, CoProcessFunction, Tuple4, String>.Context ctx, Collector out) throws Exception {
//查看thirdPartyEvent的值是否来过
if (thirdPartyEventState.value() != null) {
out.collect("对账成功:" + value + " " + thirdPartyEventState.value());
thirdPartyEventState.clear();
} else {
appEventState.update(value);
//注意一个五秒后的定时器。等待令一个流的事件.
ctx.timerService().registerEventTimeTimer(value.f2 + 5000L);
}
}
@Override
public void processElement2(Tuple4 value, CoProcessFunction, Tuple4, String>.Context ctx, Collector out) throws Exception {
//查看thirdPartyEvent的值是否来过
if (appEventState.value() != null) {
out.collect("对账成功:" + appEventState.value() + " " + value);
appEventState.clear();
} else {
thirdPartyEventState.update(value);
//这个流要晚于appEvent的流
ctx.timerService().registerEventTimeTimer(value.f3);
}
}
@Override
public void onTimer(long timestamp, CoProcessFunction, Tuple4, String>.OnTimerContext ctx, Collector out) throws Exception {
//判断状态,如果某个状态不为null,说明另一条流的事件没来.
if (appEventState.value() != null) {
out.collect("对账失败:" + appEventState.value() + " " + "第三方支付平台信息未到");
}
if (thirdPartyEventState.value() != null) {
out.collect("对账失败:" + thirdPartyEventState.value() + " " + "app的信息未到");
}
appEventState.clear();
thirdPartyEventState.clear();
}
}
}
```
##### 7.2.3 双流join
1)window join
使用:DataStream.join,实际上是内连接。
```java
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment executionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment();
executionEnvironment.setParallelism(1);
SingleOutputStreamOperator> appStream = executionEnvironment.fromElements(
Tuple3.of("order-1", "app", 1000L),
Tuple3.of("order-2", "app", 2000L),
Tuple3.of("order-3", "app", 3500L)
).assignTimestampsAndWatermarks(WatermarkStrategy.>forBoundedOutOfOrderness(Duration.ZERO).withTimestampAssigner(new SerializableTimestampAssigner>() {
@Override
public long extractTimestamp(Tuple3 element, long recordTimestamp) {
return element.f2;
}
}));
SingleOutputStreamOperator> thirdPartStream = executionEnvironment.fromElements(
Tuple4.of("order-1", "third-party", "success", 3000L),
Tuple4.of("order-3", "third-party", "success", 4000L)
).assignTimestampsAndWatermarks(WatermarkStrategy.>forBoundedOutOfOrderness(Duration.ZERO).withTimestampAssigner(new SerializableTimestampAssigner>() {
@Override
public long extractTimestamp(Tuple4 element, long recordTimestamp) {
return element.f3;
}
}));
appStream.join(thirdPartStream)
.where(data -> data.f0)
.equalTo(data -> data.f0)
.window(TumblingEventTimeWindows.of(Time.seconds(5)))
.apply(new JoinFunction, Tuple4, String>() {
@Override
public String join(Tuple3 first, Tuple4 second) throws Exception {
return "first join second: " + first + second;
}
}).print();
executionEnvironment.execute();
}
```
console:
```java
first join second: (order-1,app,1000)(order-1,third-party,success,3000)
first join second: (order-3,app,3500)(order-3,third-party,success,4000)
```
2)间隔联接
没有固定的窗口,以左边流中的每一个元素指定一个时间上下限为界和其他流进行匹配。
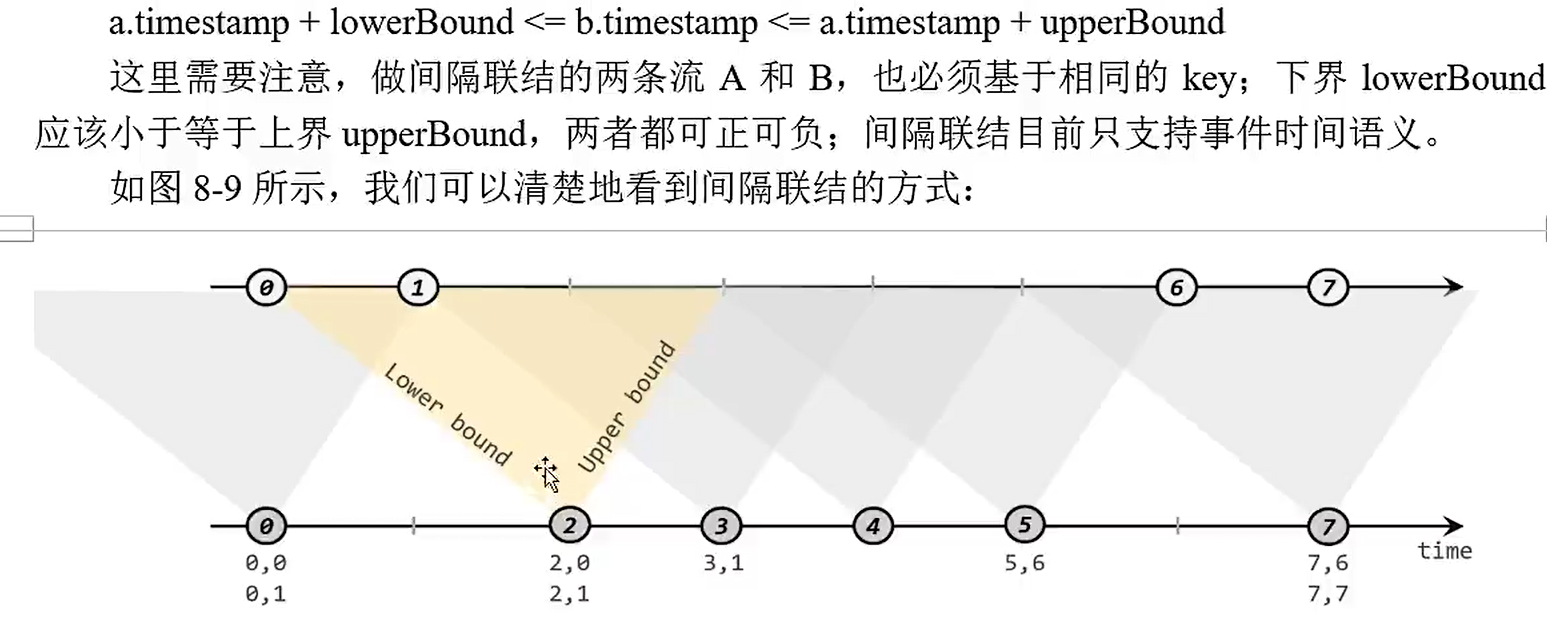
使用:keyStream.intervalJoin.between.process
案例:在电商网站中,某些用户行为往往存在短时间内的强关联。如果我们有两个流,一个是下订单的流,一个是浏览数据的流。我们可以针对同一童虎,做一个间隔联结,使用一个用户的下订单事件和这个用户最近十分钟的浏览数据进行一个联结查询。
code:
```java
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment executionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment();
SingleOutputStreamOperator eventSource = executionEnvironment.fromElements(new Event("tom", "./index", 1000L),
new Event("tom", "./product?id=10", 2000L),
new Event("lily", "./index", 1000L),
new Event("tom", "./product?id=20", 3000L),
new Event("tom", "./product?id=30", 4000L),
new Event("tom", "./product?id=20", 5000L),
new Event("tom", "./order?id=30", 6000L),
new Event("tom", "./product?id=50", 7000L),
new Event("tom", "./product?id=60", 8000L),
new Event("tom", "./product?id=70", 9000L),
new Event("lily", "./product?id=100", 7000L))
.assignTimestampsAndWatermarks(WatermarkStrategy.forBoundedOutOfOrderness(Duration.ZERO).withTimestampAssigner(new SerializableTimestampAssigner() {
@Override
public long extractTimestamp(Event element, long recordTimestamp) {
return element.timestamp;
}
}));
SingleOutputStreamOperator> orderSource = executionEnvironment.fromElements(Tuple2.of("tom", 7000L)).assignTimestampsAndWatermarks(WatermarkStrategy.>forBoundedOutOfOrderness(Duration.ZERO).withTimestampAssigner(new SerializableTimestampAssigner>() {
@Override
public long extractTimestamp(Tuple2 element, long recordTimestamp) {
return element.f1;
}
}));
orderSource.keyBy(data -> data.f0).intervalJoin(eventSource.keyBy(data -> data.user))
.between(Time.seconds(-4L), Time.seconds(1L)).process(new ProcessJoinFunction, Event, String>() {
@Override
public void processElement(Tuple2 left, Event right, ProcessJoinFunction, Event, String>.Context ctx, Collector out) throws Exception {
out.collect(new StringBuilder().append("user:").append(left.f0).append("下了一个单,时间为:").append(left.f1).append(", 最近访问url为:").append(right.url).append(" , time is ").append(right.timestamp).toString());
}
}).print("near view urls ");
executionEnvironment.execute();
}
```
console:
```java
near view urls :4> user:tom下了一个单,时间为:7000, 最近访问url为:./product?id=20 , time is 3000
near view urls :4> user:tom下了一个单,时间为:7000, 最近访问url为:./product?id=30 , time is 4000
near view urls :4> user:tom下了一个单,时间为:7000, 最近访问url为:./product?id=20 , time is 5000
near view urls :4> user:tom下了一个单,时间为:7000, 最近访问url为:./order?id=30 , time is 6000
near view urls :4> user:tom下了一个单,时间为:7000, 最近访问url为:./product?id=50 , time is 7000
near view urls :4> user:tom下了一个单,时间为:7000, 最近访问url为:./product?id=60 , time is 8000
```
3)CoGroup
> 之前的window join实际上是sql的内连接,如果coGroup实际上是更一般化的方法。
```java
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment executionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment();
executionEnvironment.setParallelism(1);
SingleOutputStreamOperator> appStream = executionEnvironment.fromElements(
Tuple3.of("order-1", "app", 1000L),
Tuple3.of("order-2", "app", 2000L),
Tuple3.of("order-3", "app", 3500L)
).assignTimestampsAndWatermarks(WatermarkStrategy.>forBoundedOutOfOrderness(Duration.ZERO).withTimestampAssigner(new SerializableTimestampAssigner>() {
@Override
public long extractTimestamp(Tuple3 element, long recordTimestamp) {
return element.f2;
}
}));
SingleOutputStreamOperator> thirdPartStream = executionEnvironment.fromElements(
Tuple4.of("order-1", "third-party", "success", 3000L),
Tuple4.of("order-3", "third-party", "success", 4000L)
).assignTimestampsAndWatermarks(WatermarkStrategy.>forBoundedOutOfOrderness(Duration.ZERO).withTimestampAssigner(new SerializableTimestampAssigner>() {
@Override
public long extractTimestamp(Tuple4 element, long recordTimestamp) {
return element.f3;
}
}));
appStream.coGroup(thirdPartStream)
.where(data -> data.f0)
.equalTo(data -> data.f0)
.window(TumblingEventTimeWindows.of(Time.seconds(5)))
.apply(new CoGroupFunction, Tuple4, String>() {
@Override
public void coGroup(Iterable> first, Iterable> second, Collector out) throws Exception {
//first是第一个流的所有元素,second是第二个流的所有元素
out.collect(first + "=>" + second);
}
}).print();
executionEnvironment.execute();
}
```
console:
```txt
[(order-1,app,1000)]=>[(order-1,third-party,success,3000)]
[(order-3,app,3500)]=>[(order-3,third-party,success,4000)]
[(order-2,app,2000)]=>[]
```
### 8 状态编程
> Flink处理机制的核心就是有状态的流式计算。
#### 8.1 Flink中的状态
##### 8.1.1 状态的管理
在传统的事务性应用中,我们一般将数据存放到数据库中,如果为了更好的性能,也可以存储到redis等内存数据中,但是当数据量非常大的时候,网络传输也是一种比较大的影响。Flink则直接将状态存放到了内存中,而Flink作为一个分布式的计算框架,在低延迟,高吞吐的基础上还需要保证容错性,就带来了比较大的挑战。
- 状态的访问权限:flink的聚合和窗口操作一般是基于KeyedStream的,会按照key的哈希值进行分区,聚合的结果只对当前key有效,然后而一个分区上执行的任务实例可能会包含多个key的数据,他们同时访问和更改本地变量可能会导致计算结果出错。
- 容错性:内存的不稳定性,我们需要考虑故障恢复,因此需要将状态持久化的保存,以便于发生故障之后可以从这个备份中恢复状态。
- 分布式应用的横向扩展:如果我们对计算资源进行扩容,调大并行度,那么状态又需要进行重组调整。
##### 8.1.2 状态划分
状态依据是否需要其他数据的参与分为有状态和无状态两种,在Flink中如果我们继承RichFunction那么就可以自定义状态。
依据管理者的不同分为托管状态和原始状态:
- 托管状态就是由Flink的runtime统一管理的,存储访问,故障恢复和重组都是由Flink实现的。聚合和窗口等算子的内置状态,Flink也提供了ValueState,ListState,MapState等多种状态。
- 算子状态:一个算子会按照并行度划分为多个并行子任务执行,而不同的子任务会占据不同的任务槽,由于不同的slot在计算资源上是物理隔离的,所以算子状态只对当前并行子任务有效,不能跨子任务进行共享。
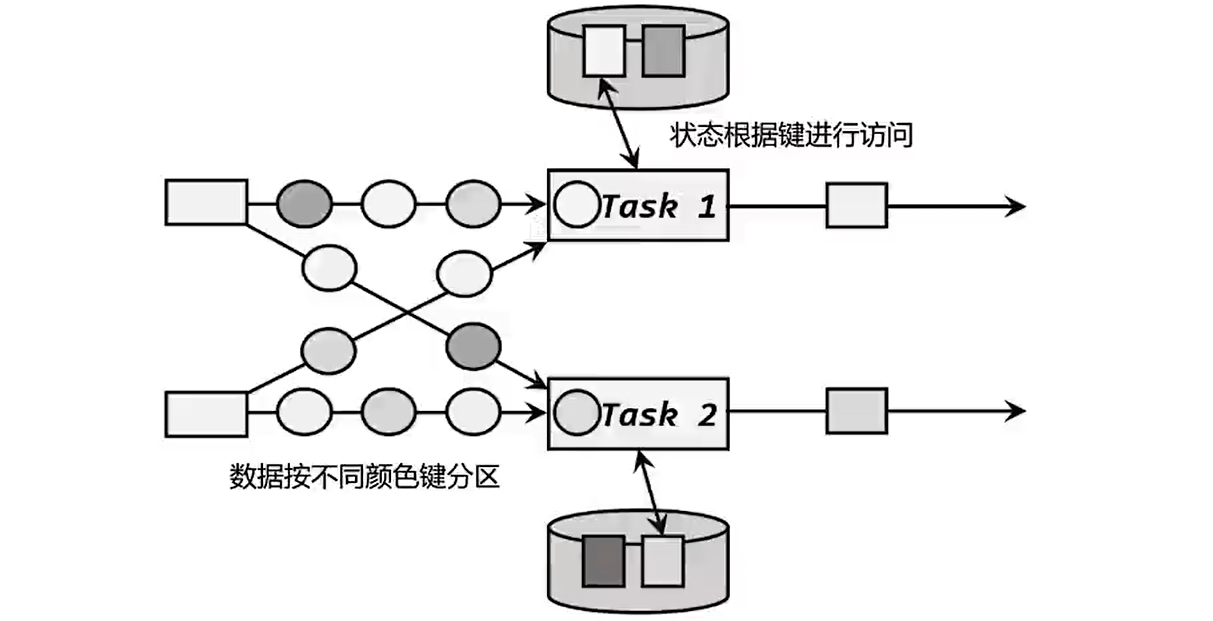
- 按键分区状态:一个子任务依据key将状态分割开来,按键分区状态的作用范围是指定的key。之前的聚合算子需要在keyBy之后才可以使用的原因就是聚合的结果是以Keyed State的形式保存的。在底层Keyed State类似于一个分布式的映射(map)数据结构,所有的状态会根据key保存成key-value的形式,当一个数据到来的时候,任务会自动的将状态的访问范围限定为当前数据的key,从而实现不同的key之间是彼此隔离的。不同的key对应的keyed State可以进一步组成key groups,每一组对应着一个并行子任务,键组是Flink重新分配keyed state的单元,键组的数量就等于最大的并行度,当算子并行度发生改变时,KeyState也会进行重新平均分配,保证运行时各个子任务的负载相同。
- 原始状态是由我们自定义的,相当于开辟了一块内存,需要我们自己管理,实现状态的序列化和故障恢复,Flink只会将这些状态存储为最原始的字节数组来存储。
##### 8.1.3 KeyedState支持的数据结构
> 状态的关键是需要运行时上下文的配合,而为了让运行时上下文清楚到底是哪一个状态,我们还需要创建一个“状态描述器(StateDescriptor)”来提供状态的基本信息。
- ValueState:值状态,保存单个值。
- ListState:列表状态,可以使用双流join实现两个表的联结。
- MapState:映射状态,可以使用mapState来模拟窗口的功能,例如统计每个url的每个窗口期间的点击数。
```java
/**
* 使用MapState来模拟时间窗口的功能.
*
* @author code1997
*/
public class FakeWindowDemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment executionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment();
SingleOutputStreamOperator eventSource = SourceUtils.getEventSource(executionEnvironment);
eventSource.print("input");
eventSource.keyBy(data -> data.url)
.process(new FakeWindowFunction(5000L))
.print();
executionEnvironment.execute();
}
public static class FakeWindowFunction extends KeyedProcessFunction {
Long windowSize;
//保存窗口的统计数据
MapState fakeWindows;
public FakeWindowFunction(Long ts) {
windowSize = ts;
}
@Override
public void open(Configuration parameters) throws Exception {
fakeWindows = getRuntimeContext().getMapState(new MapStateDescriptor("fake_windows", Types.LONG, Types.LONG));
}
@Override
public void processElement(Event value, KeyedProcessFunction.Context ctx, Collector out) throws Exception {
//计算窗口的范围
Long windowStart = value.timestamp / windowSize * windowSize;
long windowEnd = windowStart + windowSize;
//注册定时器
ctx.timerService().registerEventTimeTimer(windowEnd - 1);
//更新状态,进行增量聚合
Long oldCount = fakeWindows.get(windowStart);
fakeWindows.put(windowStart, oldCount == null ? 1 : oldCount + 1);
}
@Override
public void onTimer(long timestamp, KeyedProcessFunction.OnTimerContext ctx, Collector out) throws Exception {
long windowEnd = timestamp + 1;
long windStart = windowEnd - windowSize;
String currentUrl = ctx.getCurrentKey();
Long count = fakeWindows.get(windStart);
//时间到了,进行结果的收集
out.collect("窗口:" + new Timestamp(windStart) + "~" + new Timestamp(windowEnd) + ", url:" + currentUrl + " 的点击数为:" + count);
//模拟窗口关闭,删除对应的状态
fakeWindows.remove(windStart);
}
}
}
```
- reducingState:调用add的时候不是往状态中添加元素,而是直接把新数据和之前的状态进行规约,并用得到的结果更新状态。
- AggregatingState:聚合状态,可以传入一个更加一般化的聚合函数,也就是之前我们讲过的AggregateFunction,里面通过一个累加器来表示状态,这也就是之前我们讲过的AggrateFunction,里面通过一个累加器来表示状态,聚合的状态类型可以和添加进来的数据类型完全不同,更加灵活。
代码实现:
```java
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment executionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment();
executionEnvironment.setParallelism(1);
SingleOutputStreamOperator eventStream = SourceUtils.getEventSource(executionEnvironment).assignTimestampsAndWatermarks(WatermarkStrategy.forBoundedOutOfOrderness(Duration.ZERO).withTimestampAssigner(new SerializableTimestampAssigner() {
@Override
public long extractTimestamp(Event element, long recordTimestamp) {
return element.timestamp;
}
}));
eventStream.keyBy(data -> data.user)
.flatMap(new MyFlatMapFunction()).print();
executionEnvironment.execute();
}
public static class MyFlatMapFunction extends RichFlatMapFunction {
ValueState myValueState;
ListState myListState;
MapState myMapState;
ReducingState myReducingState;
AggregatingState myAggregatingState;
@Override
public void open(Configuration parameters) throws Exception {
//状态的初始化放到算子的生命周期方法中
myValueState = getRuntimeContext().getState(new ValueStateDescriptor("myValueState", Types.POJO(Event.class)));
myListState = getRuntimeContext().getListState(new ListStateDescriptor("myListState", Types.POJO(Event.class)));
myMapState = getRuntimeContext().getMapState(new MapStateDescriptor("myMapState", Types.STRING, Types.LONG));
myReducingState = getRuntimeContext().getReducingState(new ReducingStateDescriptor("myReducingState", new ReduceFunction() {
@Override
public Long reduce(Long value1, Long value2) throws Exception {
return value1 + value2;
}
}, Types.LONG));
myAggregatingState = getRuntimeContext().getAggregatingState(new AggregatingStateDescriptor("myAggregatingState", new AggregateFunction() {
@Override
public String createAccumulator() {
return "url的集合:\n";
}
@Override
public String add(Event value, String accumulator) {
return accumulator + "\n" + value.url;
}
@Override
public String getResult(String accumulator) {
return accumulator;
}
@Override
public String merge(String a, String b) {
return null;
}
}, Types.STRING));
}
@Override
public void flatMap(Event value, Collector out) throws Exception {
//value
//System.out.println(myValueState.value());
myValueState.update(value);
//System.out.println("==update==" + myValueState.value());
//list
myListState.add(value);
//map
Long tempCount = myMapState.get(value.user);
myMapState.put(value.user, (tempCount == null) ? 1 : (tempCount + 1));
System.out.println("==myMapState::" + value.user + "==" + myMapState.get(value.user));
//myReducingState
myReducingState.add(value.timestamp);
System.out.println("==myReducingState==" + myReducingState.get());
//myAggregatingState
myAggregatingState.add(value);
System.out.println("==myAggregatingState==" + myAggregatingState.get());
}
}
```
##### 8.1.4 状态的TTL
对于flink来说,我们不能将状态的回收直接交给GC来进行处理,类似于redis的TTL,我们可以设置某个状态的超时时间,如果一个key超过指定TTL时间没有被访问,下一次被访问的时候会被删除掉;如果没有超过则会刷新生存时间。
```
StateTtlConfig stateTtlConfig = StateTtlConfig.newBuilder(Time.hours(1)).build();
myValueState.enableTimeToLive(stateTtlConfig);
```
source code:
```java
/**
updateType: default is OnCreateAndWrite
stateVisibility: default is NeverReturnExpired
ttlTimeCharacteristic: default is ProcessingTime
*/
@Nonnull
public StateTtlConfig build() {
return new StateTtlConfig(
updateType,
stateVisibility,
ttlTimeCharacteristic,
ttl,
new CleanupStrategies(strategies, isCleanupInBackground));
}
```
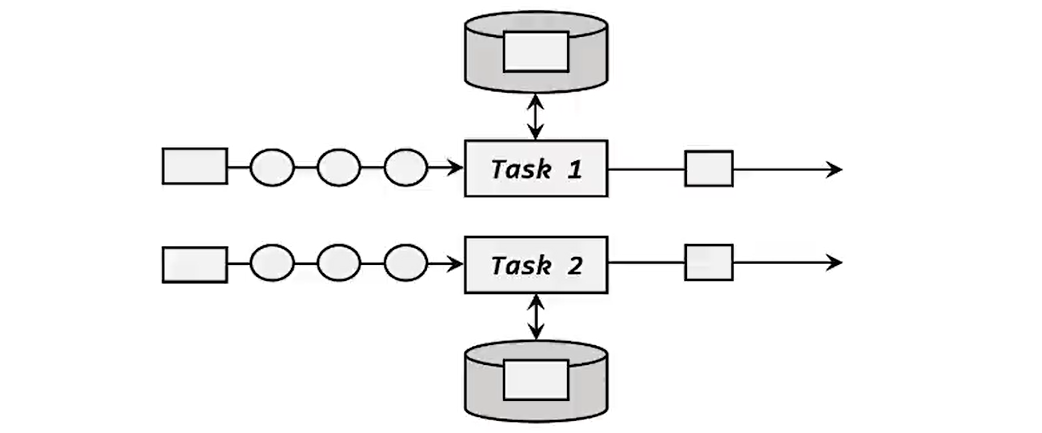
##### 8.1.5 算子状态
除了按键分区状态之外,另一类的状态就是算子状态。算子状态跟数据的key没有关系,所以不同的key的数据只要被分到同一个并行子任务,就会访问到同一个Operator state,一般用于source或者sink和外部系统进行连接的时候。
算子状态支持以下三种类型:
- ListState:每一个并行子任务上只保存一个列表,当算子的并行进行缩放调整的时候,会将算子的列表状态中的所有元素项统一收集起来形成大列表,然后使用轮询的方式将元素项平均分配,这种方式也叫做平均分割重组。
- UnionListState:联合列表状态也是一个列表和列表状态的区别在于算子并行度进行缩放调整的时候对于状态的分配方式不同。联合列表状态也会将状态联合成一个大的列表,然后将完整的列表广播出去,并行子任务获取到完整的状态项之后,可以自行选择要使用/丢弃的状态项,这种分配方式也叫做联合重组。如果列表中的状态项数量太多,为资源和效率考虑一般不建议使用重组的方式。
- BroadcastState:有时候我们希望算子并行子任务保持同一份”全局“状态来作为统一的配置和规则设定,这时所有的分区的所有数据都会访问到同一个状态,这种特殊的算子被称为广播状态。在底层使用类似于map的方式来保存的,且必须基于广播流来创建。
状态和本地变量的区别在于Flink会为状态提供完整的管理机制,来保证他的持久化保存,以便于发生故障恢复的时候`状态恢`复以及需要对`不同的key保存独立的状态实例`。KeyedState对两个功能都要考虑;而算子状态并不考虑key的影响,所以主要任务是状态持久化和保存,对于keyStream来说因为相同的key使用会分到同一个分区中,只要状态也按照key的hash值计算出对应的分区,进行重新分配就可以了,恢复状态后处理数据也可以按照key找到对应的状态也就保证了结果的一致性,而这些事情Flink已经做好了,我们不需要做任何处理。但是对于算子状态就需要我们进行处理。因此Flink给我们提供了接口供我们自己去实现。
- CheckpointedFunction:用于对状态进行持久化保存的快照机制称为检查点。
```java
@Public
public interface CheckpointedFunction {
/**
* This method is called when a snapshot for a checkpoint is requested. This acts as a hook to
* the function to ensure that all state is exposed by means previously offered through {@link
* FunctionInitializationContext} when the Function was initialized, or offered now by {@link
* FunctionSnapshotContext} itself.
*
* @param context the context for drawing a snapshot of the operator
* @throws Exception Thrown, if state could not be created ot restored.
*/
void snapshotState(FunctionSnapshotContext context) throws Exception;
/**
* This method is called when the parallel function instance is created during distributed
* execution. Functions typically set up their state storing data structures in this method.
*
* @param context the context for initializing the operator
* @throws Exception Thrown, if state could not be created ot restored.
*/
void initializeState(FunctionInitializationContext context) throws Exception;
}
```
-
demo:自定义的sinkFunction在CheckpointedFunction中进行数据缓存,然后统一发送到下游。
```java
/**
* 批量写出以及故障恢复.
* @author code1997
*/
public class BufferingSinkDemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment executionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment();
SingleOutputStreamOperator eventSource = SourceUtils.getEventSource(executionEnvironment);
eventSource.print("input");
eventSource.addSink(new BufferingSink(5));
executionEnvironment.execute();
}
public static class BufferingSink implements SinkFunction, CheckpointedFunction {
private final int bufferSize;
private final List bufferedElements;
private ListState checkPointedState;
public BufferingSink(int bz) {
if (bz < 1) {
throw new IllegalArgumentException("buffer size must be more than 1");
}
this.bufferSize = bz;
this.bufferedElements = new ArrayList<>();
}
/**
* 每来一个数据我们需要做的.
*/
@Override
public void invoke(Event value, Context context) throws Exception {
bufferedElements.add(value);
//判断如果达到阈值,就批量写入
if (bufferedElements.size() == bufferSize) {
//写入数据到外部系统
for (Event event : bufferedElements) {
System.out.println(event);
}
System.out.println("========写出完毕=======");
bufferedElements.clear();
}
}
@Override
public void snapshotState(FunctionSnapshotContext context) throws Exception {
//需要清理状态
checkPointedState.clear();
//对状态进行持久化,复制缓存的列表到列表状态
for (Event event : bufferedElements) {
checkPointedState.add(event);
}
}
@Override
public void initializeState(FunctionInitializationContext context) throws Exception {
//初始化状态
ListStateDescriptor listStateDescriptor = new ListStateDescriptor<>("buffered_states", Types.POJO(Event.class));
checkPointedState = context.getOperatorStateStore().getListState(listStateDescriptor);
//如果从故障恢复,需要将ListState中所有元素复制到列表中
if (context.isRestored()) {
for (Event event : checkPointedState.get()) {
bufferedElements.add(event);
}
}
}
}
}
```
广播状态:动态配置或者动态规则的时候可以使用广播状态实现。使用流处理的事件驱动思路,将这动态的配置数据看作一条流,将这条流和本身要处理的数据流进行连接,这样就可以实时的更新配置进行计算了。
```java
/**
* 检测用户登录-下单,登录-支付的频次.
*
* @author code1997
*/
public class BehaviorPatternDetectDemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment executionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment();
executionEnvironment.setParallelism(1);
DataStreamSource actionSource = executionEnvironment.fromElements(
new Action("Alice", "login"),
new Action("Alice", "pay"),
new Action("Bob", "login"),
new Action("Bob", "order")
);
//定义广播状态描述器
MapStateDescriptor rules = new MapStateDescriptor<>("rules", Types.VOID, Types.POJO(Pattern.class));
BroadcastStream patternBroadcastStream = executionEnvironment.fromElements(
new Pattern("login", "pay"),
new Pattern("login", "order")
).broadcast(rules);
actionSource.keyBy(data -> data.user)
.connect(patternBroadcastStream)
.process(new KeyedBroadcastProcessFunction>() {
//定义一个keyedState用于保存上一次用户的行为.
ValueState prevAction;
@Override
public void open(Configuration parameters) throws Exception {
prevAction = getRuntimeContext().getState(new ValueStateDescriptor<>("prev_action", Types.STRING));
}
@Override
public void processElement(Action value, KeyedBroadcastProcessFunction>.ReadOnlyContext ctx, Collector> out) throws Exception {
ReadOnlyBroadcastState pattern = ctx.getBroadcastState(new MapStateDescriptor<>("rules", Types.VOID, Types.POJO(Pattern.class)));
Pattern rule = pattern.get(null);
//获取用户上一次的行为
String prevAct = prevAction.value();
if (prevAct != null && rule != null) {
if (rule.action1.equalsIgnoreCase(prevAct) && rule.action2.equalsIgnoreCase(value.action)) {
out.collect(Tuple2.of(ctx.getCurrentKey(), rule));
}
}
prevAction.update(value.action);
}
@Override
public void processBroadcastElement(Pattern value, KeyedBroadcastProcessFunction>.Context ctx, Collector> out) throws Exception {
//从上下文中获取广播状态并更新广播状态
BroadcastState curPattern = ctx.getBroadcastState(new MapStateDescriptor<>("rules", Types.VOID, Types.POJO(Pattern.class)));
curPattern.put(null, value);
}
}).returns(Types.TUPLE(Types.STRING, Types.POJO(Pattern.class))).print();
executionEnvironment.execute();
}
public static class Action {
public String user;
public String action;
public Action(String user, String action) {
this.user = user;
this.action = action;
}
}
public static class Pattern {
public String action1;
public String action2;
public Pattern(){
}
public Pattern(String action1, String action2) {
this.action1 = action1;
this.action2 = action2;
}
@Override
public String toString() {
return "Pattern{" +
"action1='" + action1 + '\'' +
", action2='" + action2 + '\'' +
'}';
}
}
}
```
#### 8.2 持久化
Flink对状态进行持久化,将当前的分布式快照进行状态保存到外部的存储系统中,一般称为检查点,Flink还提供了保存点机制(savePoint),但是需要我们手动去实现。存储系统一般为分布式存储系统。
##### 8.2.1 检查点
Flink发生故障之后,Flink就会用最近一次成功保存的检查点来恢复应用的状态,重启处理流程,类似于游戏读档功能。
如果保存检查点之后又处理了一些数据,然后发生了故障,那么重启恢复状态之后,这些数据带来的状态改变会丢失,为了最终处理结果的正确,要求数据源具有重新读取的功能,例如kafka,这样就可以是按至少一次的状态一致性的保证,如果想要实现精确一次的一致性,那么还需要数据写入外部系统的保证。默认情况下,检查点是被金庸的,需要手动开启。
```java
executionEnvironment.enableCheckpointing(1000);
```
source code:
```java
/**
* Enables checkpointing for the streaming job. The distributed state of the streaming dataflow
* will be periodically snapshotted. In case of a failure, the streaming dataflow will be
* restarted from the latest completed checkpoint. This method selects {@link
* CheckpointingMode#EXACTLY_ONCE} guarantees.
*
* The job draws checkpoints periodically, in the default interval. The state will be stored
* in the configured state backend.
*
*
NOTE: Checkpointing iterative streaming dataflows in not properly supported at the moment.
* For that reason, iterative jobs will not be started if used with enabled checkpointing. To
* override this mechanism, use the {@link #enableCheckpointing(long, CheckpointingMode,
* boolean)} method.
*
* @deprecated Use {@link #enableCheckpointing(long)} instead.
*/
@Deprecated
@PublicEvolving
public StreamExecutionEnvironment enableCheckpointing() {
checkpointCfg.setCheckpointInterval(500);
return this;
}
```
##### 8.2.2 状态后端--State backends
检查点保存依赖于JobManager和TaskManager以及外部存储系统的协调。在应用进行检查点保存时,首先会由JobManager向TaskManager发出触发检查点的命令,TaskManager收到之后,会将当前任务的所有状态进行快照保存,持久化到远程的存储介质中,完成之后向JobManager返回确认信息,当所有的TaskManager向JobManager返回确认信息之后,那么JobManager就会确认当前检查保存成功。在Flink中这一切就交给状态后端来处理。在Flink中状态后端被用来处理以下事情:
- 本地的状态管理。
- 将检查点写入远程的持久化存储。
状态后端被设定为开箱即用的组件,可以在不改变应用程序逻辑的情况下独立配置,Flink提供了两类不同的状态后端:
- 哈希表状态后端:HashMapStateBackend,默认的状态后端。将状态当作对象保存在TaskManager的JVM堆内存上,底层是一个哈希表,都会以键值对的方式存储起来。
- RocksDb状态后端:RockDb也是一种内嵌的Key-value存储介质,可以见数据持久化到本地磁盘。配置之后,会将处理中数据全部放到RocksDB数据库中,RocksDB默认存储在TaskManager的本地数据目录中。数据被村委序列化的字节数组,读写操作需要序列化/反序列化,因此状态的访问性能要差一些,key的比较也是按照字节进行的。对于检查点,是中执行的是异步快照,因此不会因为保存检查点而阻塞数据的处理,而且提供了增量式保存检查点的机制,可以提升保存的效率。状态非常大,窗口非常长的应用常见是一个很好选择,同样对于所有高可用性设置有效。
如何配置?
1)配置`flink-conf.yaml`的方式
```yaml
# 默认的状态后端:hashmap
state.backend: hashmap
#state.backend: rocksdb
# 检查点的文件路径
state.checkpoints.dir: hdfs://namenode:40010/flink/checkpoint
```
2)为每个job单独配置状态后端
```java
executionEnvironment.setStateBackend(new HashMapStateBackend());
```
使用:rocksdb
```xml
org.apache.flink
flink-statebackend-rocksdb_${scala.binary.version}
${flink.version}
```
```java
executionEnvironment.setStateBackend(new EmbeddedRocksDBStateBackend());
```
### 9 容错机制
> 流式处理程序是持续运行的,没有一个明确的退出时间,如果发生故障了怎么办呢?最简单的方式就是重启机器/应用,而分布式状态需要保存下来才可以实现故障恢复。
#### 9.1 检查点
##### 9.1.1 检查点的保存
1)什么时候进行检查点保存?
随时保存:如果每处理完一个数据就保存一下当前的状态,如果发生故障,只需要故障恢复之后就再重新处理数据就可以了。这种方式可以做到故障恢复比较快,但是因为过于及时,会导致性能正常处理数据的性能受到一些影响,不会很划算。
周期性保存:每隔一段时间去做一次存档,这样不会影响数据的正常处理,也不会有太大的延迟(故障的次数不多)。
在flink中,检查点的保存是周期性触发的,间隔时间可以进行设置。
2)检查点的保存触发时,TaskManager正在处理某个数据,这个时候怎么办?
立即保存:在某个时刻按下暂停键,让所有的任务停止处理数据,然后保存状态,之后再恢复数据处理,这种方式存在很多问题,是`不太现实`的,因为我们无法得知任务实际执行到了哪里。
从source开始保存偏移量:当所有的任务都恰好处理完一个相同的输入数据的时候,将他们的状态保存下来。如果出现故障,那么就重新提交偏移量,请求重放数据,这也是`Flink实际选择`的方式。
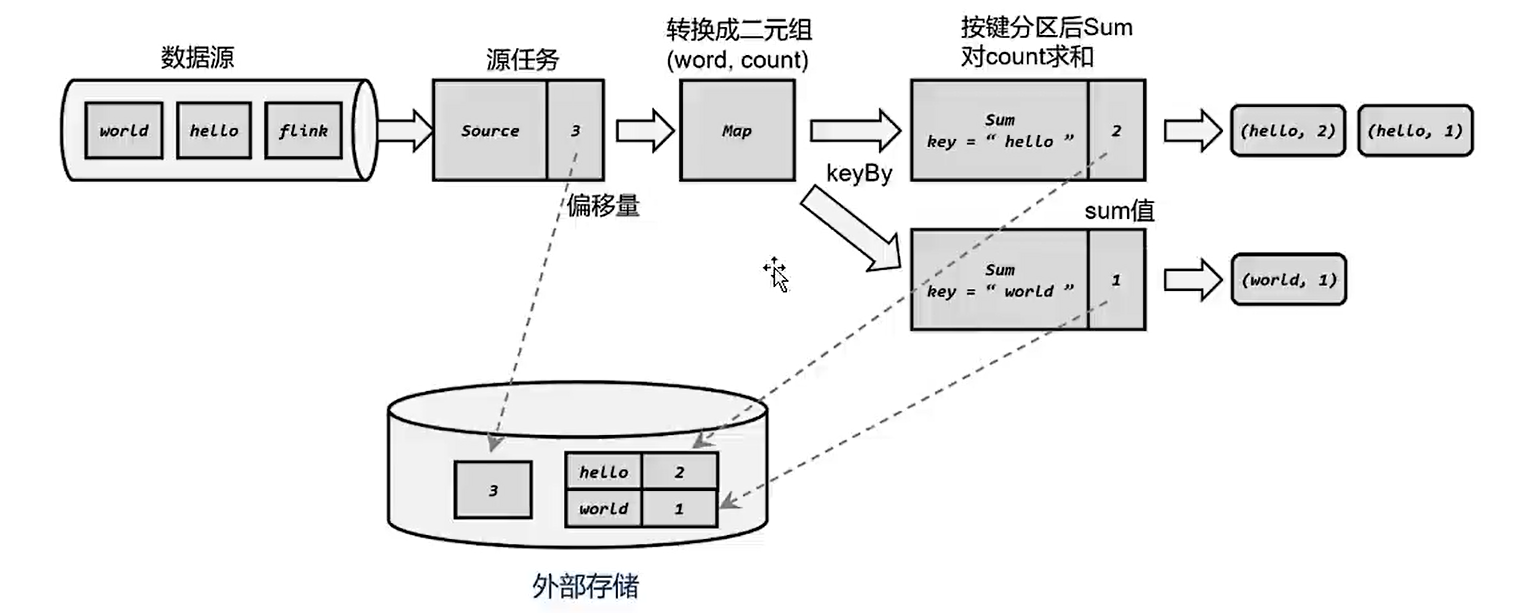
##### 9.1.2 从检查点恢复状态
Flink在运行流处理程序的时候,Flink会周期性的保存检查点,当发生故障时需要找到最近一次成功保存的检查点来恢复状态。
1. 重启应用:所有任务的状态会被清空。

2. 读取检查点,重置状态:找到最近一次保存的检查点,从中读取每一个算子任务状态的快照,分别填充到对应的状态。此时,Flink内部的所有任务的状态就恢复到了保存检查点的那一时刻。
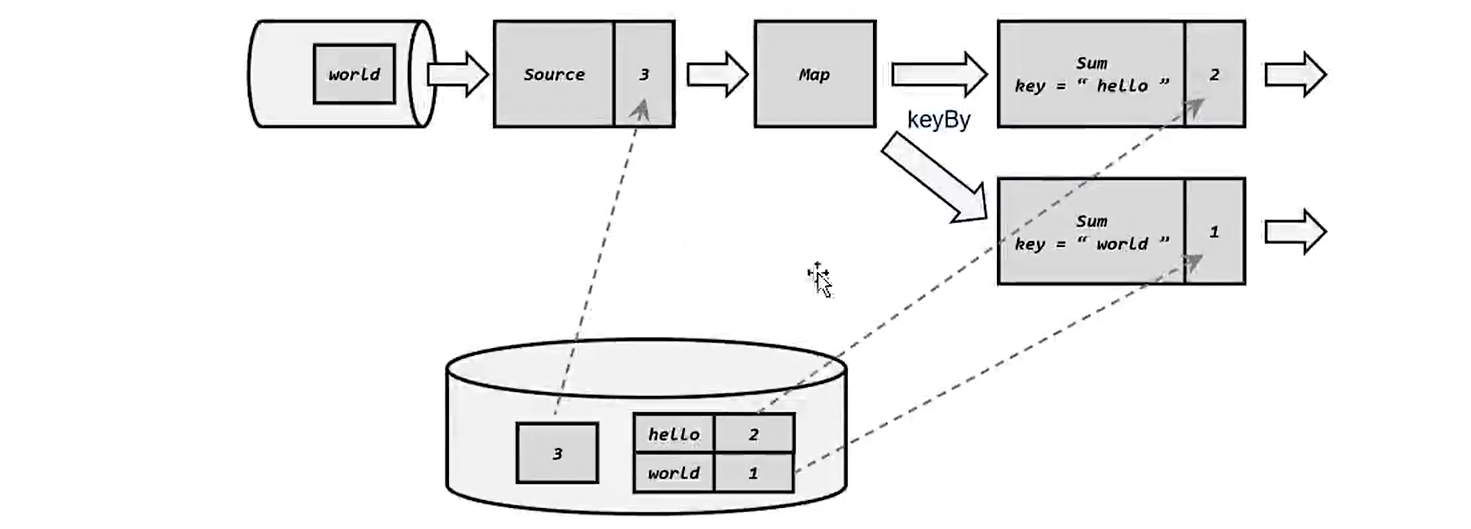
3.重放数据:保存检查点之后,到发生故障的这段时间内的数据丢掉了,这会造成计算结果的错误,为了不丢失数据,我们应该从保存检查点后开始读取数据,通过source向外部数据源重新提交偏移量来实现,这也就要求外部系统可以实现偏移量的重置。此时系统就恢复到故障之前的状态了。
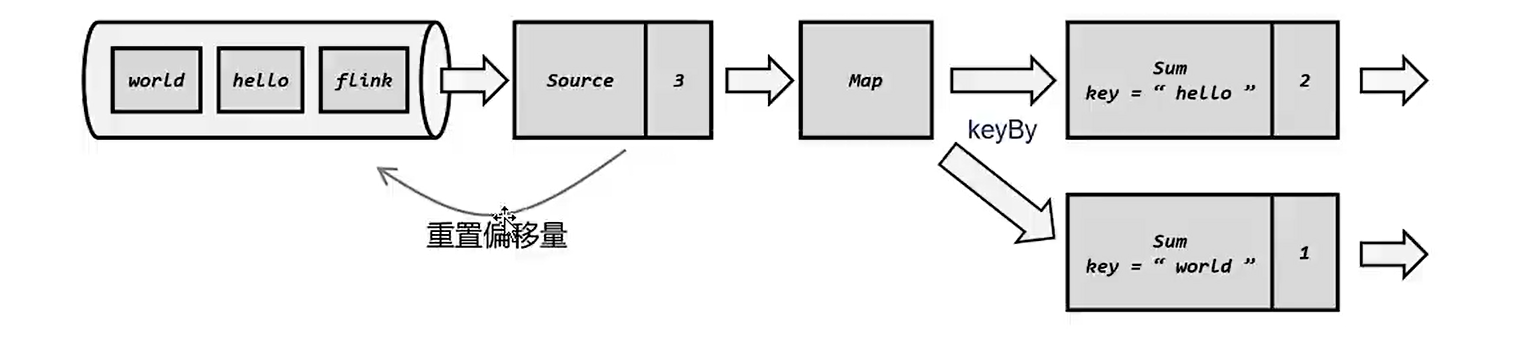
4.继续处理数据
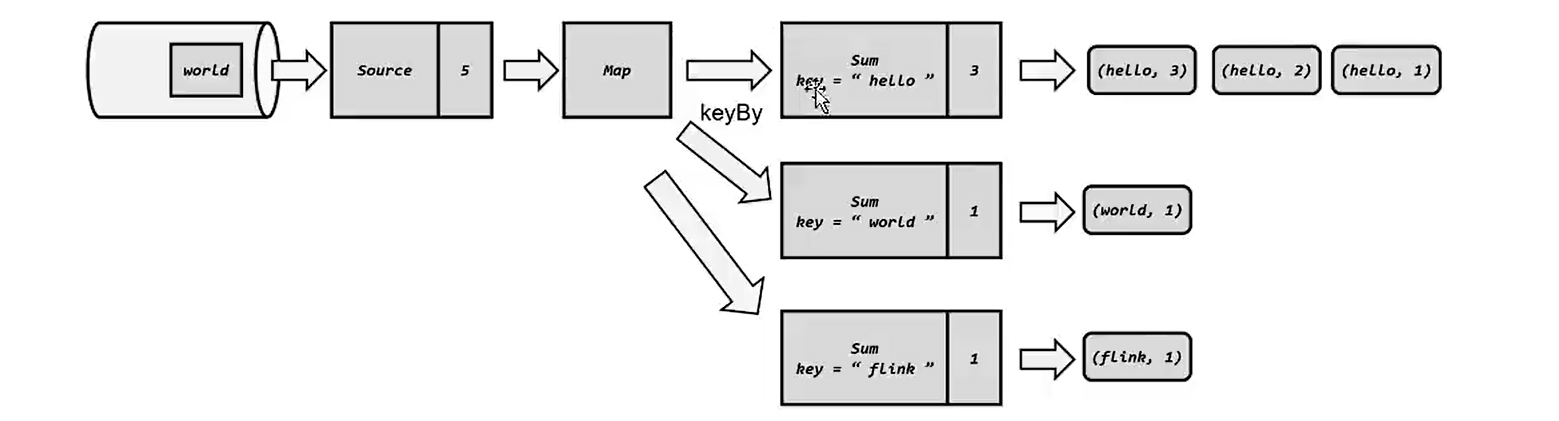
发生故障前后,我们既没有丢失数据,有没有重复计算数据,这就保证了计算结果的正确性,在分布式系统中这就叫做`精确一次性`(exactly-once)的状态一致性保证。
##### 9.1.3 检查点算法
Flink在保存检查点的时间点是所有的任务处理完同一个输入数据的时候,但是不同的任务处理数据的速度不同,而且整个Flink任务是一个图结构,存在逻辑上的先后顺序,而且每个任务都可能对数据进行各种转换,Flink是如何识别是同一个数据呢?
简单的做法是:JobManager发出保存检查点的指令后,Source算子任务处理完当前数据就暂停等待,不再读取新数据,等大家都处理完,那么保存一下状态,这种机制会导致资源闲置和延迟的增加。
Flink:在不暂停整体流处理的前提下,将状态备份保存到检查点,采用Chandy-Lamport算法的分布式快照。
1)检查点分界线(Barrier)
不暂停流处理的情况下,让每个任务认出要触发保存点保存的数据,那么可以添加一个特殊的标志,但是如果要做检查点的时候,source没有新的数据,那么就无法实现。
参考Watermark的方式,在数据流中插入一个特殊的数据结构,专门用来表示触发检查点保存的时间点。收到保存检查点的指令后,Source任务可以在当前数据流中插入这个结构,之后的所有任务只要遇到它就开始对状态做持久化快照保存,由于数据流是保持顺序依次处理的,因此遇到这个标识就代表之前的数据都处理完了,可以保存下一个检查点,他之后的数据,引起的状态改变就不会体现在这个检查点中,而是保存到下一个检查点,这种特殊的数据形式,把一条流上的数据按照不同的检查点分隔开,所以就叫做检查点的分界线(Checkpoint Barrier)。
分界线由source算子注入到常规的数据流中,他的位置是先定好的,带有一个检查点ID,也是当前要保存的检查点的唯一标识。分界线将数据流逻辑上分为两部分,分界线来之前数据导致的状态更改都会被包含在当前分界线所表示的检查点中,而基于分界线之后的数据导致的状态更改,则会被包含在之后的检查点中。
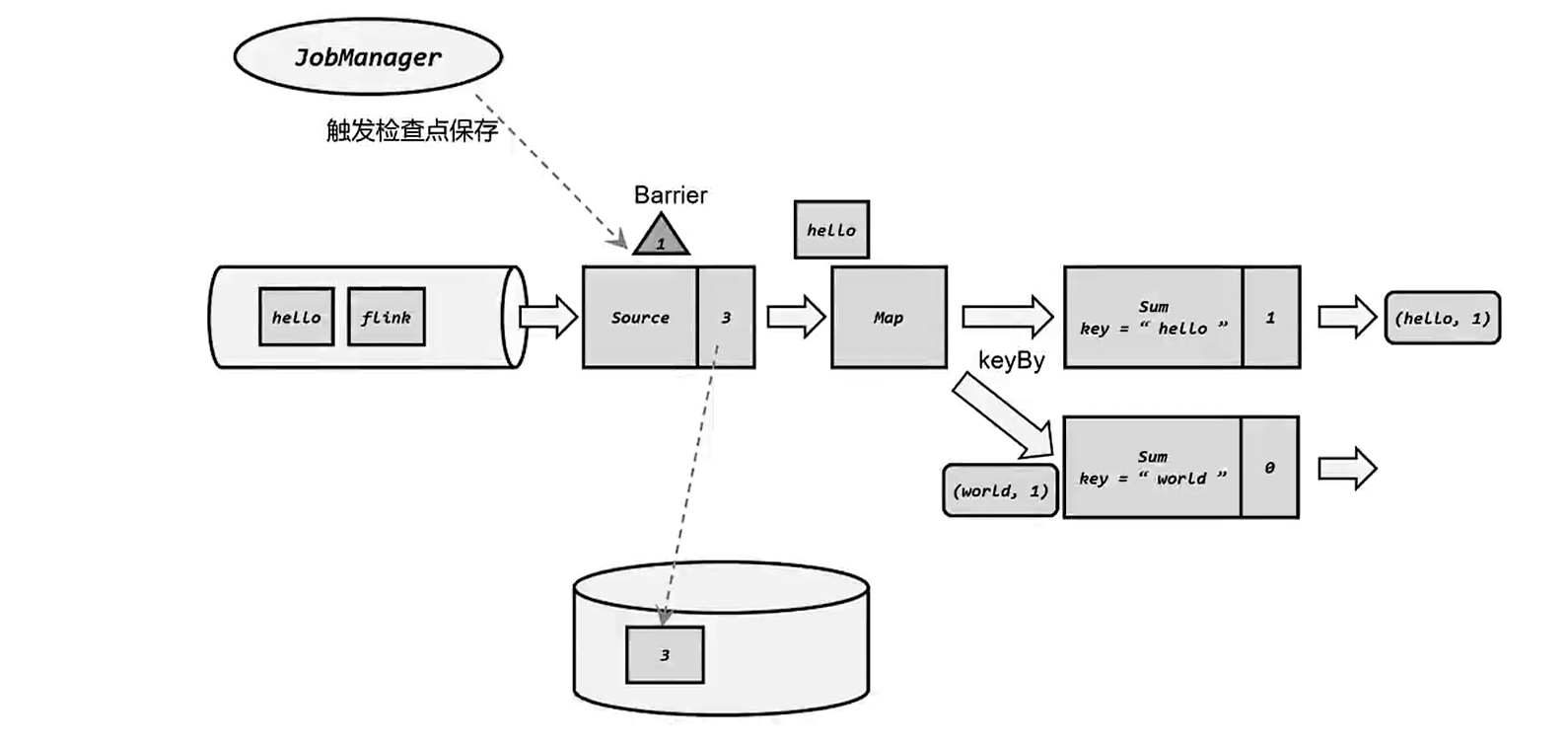
2)分布式快照算法
在一条单一的流上数据依次进行处理,顺序保持不变是可以的,但是对于分布式流处理来说,因为存在多个分区,想要维持数据的顺序就不那么容易了。
对于水位线来说:水位线的含义是水位线时间以前的数据已经全部到齐了。所以就出现以下两种情况:
- 上游任务向多个并行下游任务传递的时候,需要广播出去;
- 多个上游任务向同一个下游任务传递的时候,则需要下游任务为每一个上游并行任务维护一个分区水位线,取其中最小的那个作为当前任务的事件时钟。
对于分界线:Flink使用Chandy-Lamport算法的一种变体,被称为`异步分界线快照`算法。算法的核心就是两个原则:
- 当上游任务向多个并行下游任务发送barrier时,需要广播出去;
- 而当多个上游任务向同一个下游任务传递barrier的时候,需要在下游任务执行`分界线对齐`操作,也就是等所有的并行分区barrier都到齐,才可以开始状态的保存。
以并行度为2的word count为例:
1. Job Manager发送指令,触发检查点的保存:source任务保存状态,插入分界线,并将`偏移量`保存到远程的持久化存储中。
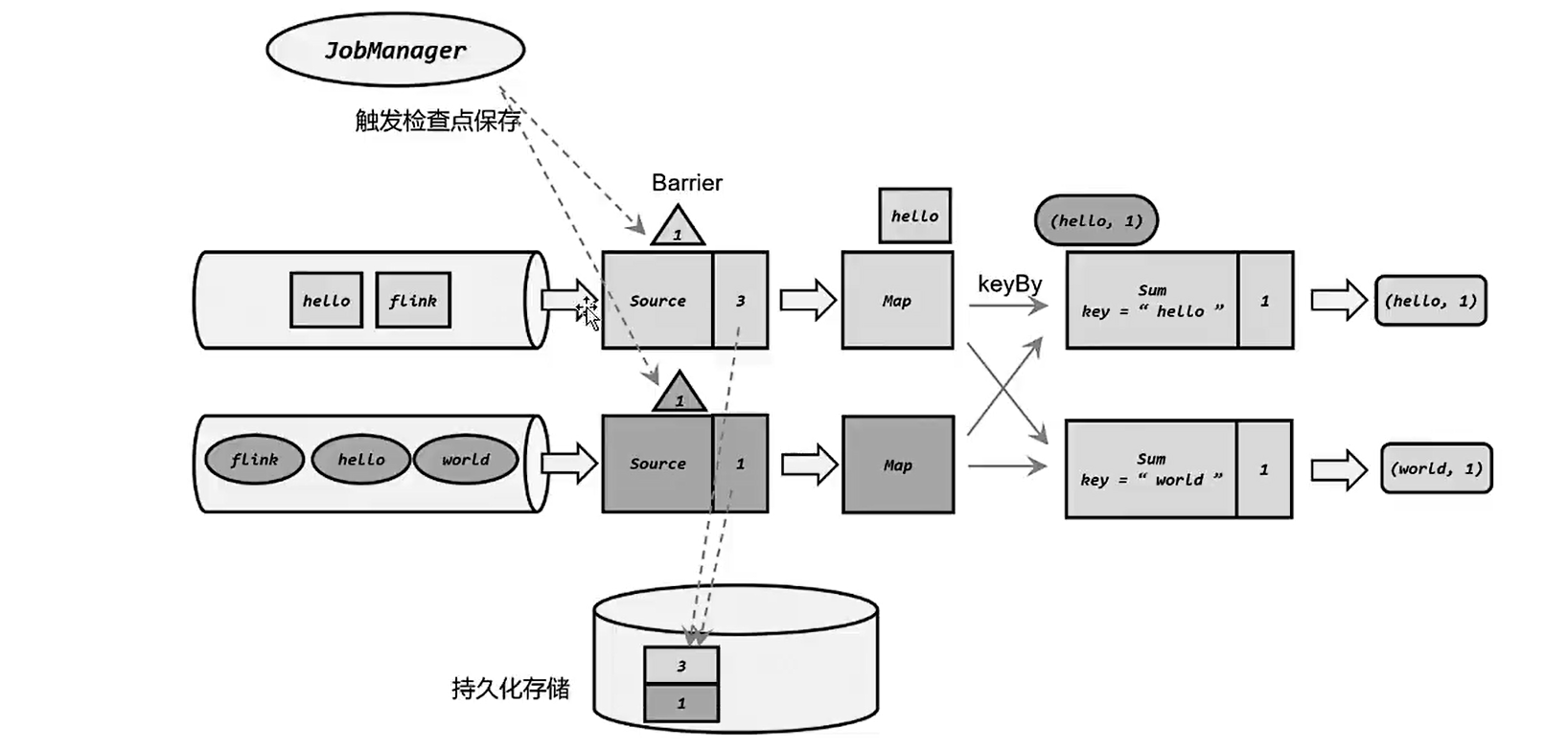
2. source状态快照保存完成,分界线向下游传递。
3. 向下游多个并行子任务广播分界线,执行分界线对齐:如果下游任务没有状态,则可以继续向下游传递;如果下游任务存在状态,则下游子任务接收到分界线之后需要等到所有的barrier到达之后,执行`分界线对齐`的操作。如果在执行分界线对齐的操作过程中来了新的数据,那就需要将这些数据暂时缓存起来,等状态保存之后再继续执行数据操作。
4. 分界线对齐之后,保存状态到持久化存储。这个分区的分区线对齐之后,就可以对当前状态做快照,保存到持久化存储中,存储完成之后,同样将barrier向下游继续传递,并通知JobManager保存完毕。
5. 处理缓存数据,然后处理正常数据:因为需要分界线对齐,所以某个分区可能堆积比较多的缓存数据,也被称为`背压`。为了应对这个场景,Flink 1.11之后提供了`不对齐的检查点保存`方式,可以将未处理的缓冲数据也保存进入检查点,这样当我们遇到一个分区barrier时就不需要继续等待对齐,而是可以直接启动状态的保存了,但是这种方式会导致检查点的持久化的数据变多。
##### 9.1.4 检查点配置
检查点时为了故障恢复的,我们不能因为保存检查点占据大量的时间,导致数据处理性能明显降低,为了兼容容错性和处理性能,我们可以在代码中对检查点进行配置。
1)启用检查点:每1000ms触发一次检查点保存。
```java
executionEnvironment.enableCheckpointing(1000);
```
2)检查点存储
```java
//默认的存储方式:将检查点存放到JObManager的内存中,一旦Job Manager挂掉,那么检查点的数据就丢失了。
executionEnvironment.getCheckpointConfig().setCheckpointStorage(new JobManagerCheckpointStorage());
//保存到hdfs上
executionEnvironment.getCheckpointConfig().setCheckpointStorage("hdfs://namenode:8020/flink/checkpoints");
```
3)超时时间:如果检查点保存的时间超过超时时间,那么就会丢弃掉。
```java
CheckpointConfig checkpointConfig = executionEnvironment.getCheckpointConfig();
checkpointConfig.setCheckpointTimeout(60000L);
```
4)设置检查点的一致性级别:默认为精确一致性
```java
checkpointConfig.setCheckpointingMode(CheckpointConfig.DEFAULT_MODE);
/** The default checkpoint mode: exactly once. */
public static final CheckpointingMode DEFAULT_MODE = CheckpointingMode.EXACTLY_ONCE;
```
5)设置检查点之间的最小间隔:与前一个checkPoint的结束时间差小于500ms则不触发本次检查点保存。
```java
checkpointConfig.setMinPauseBetweenCheckpoints(500L);
```
6)最大并发的检查点数量:当某个检查点保存的时间比较长的时候,可能会出现并发检查点保存的情况。
```java
checkpointConfig.setMaxConcurrentCheckpoints(2);
```
7)取消分界线对齐保存机制:减少出现背压的时候检查点的保存时间。
前提:精确一致性模式+允许并发保存检查点的数量为1。
```java
checkpointConfig.enableUnalignedCheckpoints();
```
8)cancle job之后是否删除外部检查点数据
```java
//默认
checkpointConfig.setExternalizedCheckpointCleanup(CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION);
```
9)是否允许检查点保存失败:默认不允许保存失败
```java
checkpointConfig.setTolerableCheckpointFailureNumber(2);
```
##### 9.1.5 保存点
保存点(Savepoint):保存点是通过检查点的机制来创建流式作业状态的一致性镜像的。保存的原理和算法和检查点完全相同,但是多了一些元数据。保存点的状态快照是以`算子ID`和`状态名称`组织起来的,相当于一个键值对。从保存点启动应用程序时,Flink会保存点的状态数据重新分配给相应的算子任务。
1)保存点的用途
触发时机不同:检查点是由Flink自动管理的,定期创建,主要用于故障恢复;保存点需要用户手动触发保存操作,相当于手动存盘,主要用于有计划的手动备份和恢复。
保存点可以当作一个强大的运维工具使用,在需要的时候创建一个保存点,然后停止应用,做一些处理调整之后再从保存点重启。具体如下:
- 版本管理和归档存储:对重要的节点进行手动备份,设置某一版本,归档存储应用程序的状态。
- 更新Flink版本:创建保存点,停止应用,升级Flink,从保存点重启。
- 更新应用程序:不更改程序的拓扑结构和数据类型的情况下,更新应用程序。因为保存点的状态快照依赖于算子的uid,所以强烈建议我们在代码中指定算子的UID。
- 调整并行度
- 暂停应用:只是单纯的将应用暂停,释放一些资源处理其他的应用程序。
2)使用保存点
1. 创建保存点
```shell
bin/flink savepoint :jobId [:targetDirectory]
```
默认路径:`flink-conf.yaml`
```yaml
state.savepoints.dir: hdfs:///flink/savepoints
```
代码中设置:
```java
executionEnvironment.setDefaultSavepointDirectory("hdfs:///flink/savepoints");
```
停止job的时候同时保存一个保存点
```shell
bin/flink stop --savepointPath [:targetDirectory] :jobId
```
2.从保存点启动应用程序
command的方式:
```java
bin/flink run -s :savepointPath [:runArgs]
```
Web ui也可以通过输入保存点的路径实现从保存点启动应用程序。
#### 9.2 状态一致性
> 对于流处理保证计算结果要准确,一条数据不因该丢失,也不应该被重复计算,遇到故障时也可以恢复状态,继续计算,结果也是正确的。
##### 9.2.1 状态一致性分类
- At most once:一个事件最多被处理一次,可能会数据丢失。
- At least once:一个事件最少被处理一次,可能会数据重复。
- Exactly-once:精确一次,事件不丢失,内部状态只更新一次。
##### 9.2.2 一致性的保障
Flink使用一种轻量级快照机制,检查点来保证Exactly-once语义,也是FLink故障恢复机制的核心。检查点:所有的任务的状态在某一个时间点的一份拷贝,这个时间点是所有任务都敲好处理完一个相同的输入数据的时候。
Flink的检查点机制只是保证了Flink处理流程的Exactly-once,如果想要保证系统的Exactly-once一致性语义,那么还需要考虑`source`和`sink`。端到端的一致性取决于所有组件中一致性最弱的组件。
- 内部保证-check point
- source端:可重新设置数据读取位置,这样可以保证At least once,保证数据不丢失。
- sink端:从故障恢复时,数据不会重复写入外部系统。
- 幂等性:一个操作,可以重复执行很多次,但是只导致一次结果更改,后续重复执行不起作用。例如:redis,相同的key,重复写时没问题,只会更行值。
- 事务写入:多个操作就具有原子性,构建的十五对应着checkpoint,等到checkpoint真正完成的时候,才将结果写入到sink系统中。实现方式如下:
- 预写日志:将结果数据先当成状态保存,然后再收到checkpoint完成的通知时,一次性写入到sink系统中,这样对外部系统没有什么要求,这种方式延迟比较大。模板类:`GenericWriteAheadSink`。可以保证最少一次,大多数情况下可以实现刚好一次的一次性语义。
- 两阶段提交:Two-Phase-Commit,简称2PC。开启一个事务,将接下来所有的数据添加到食物中,将这些数据写入到sink系统中,但是不提交,这叫`预提交`。等checkpoint完成,他才正式提交事务,实现结果的真正写入,需要外部系统支持事务。Flink提供了TwoPhaseCommitSinkFunction接口。
- 不同source和sink的一致性保证
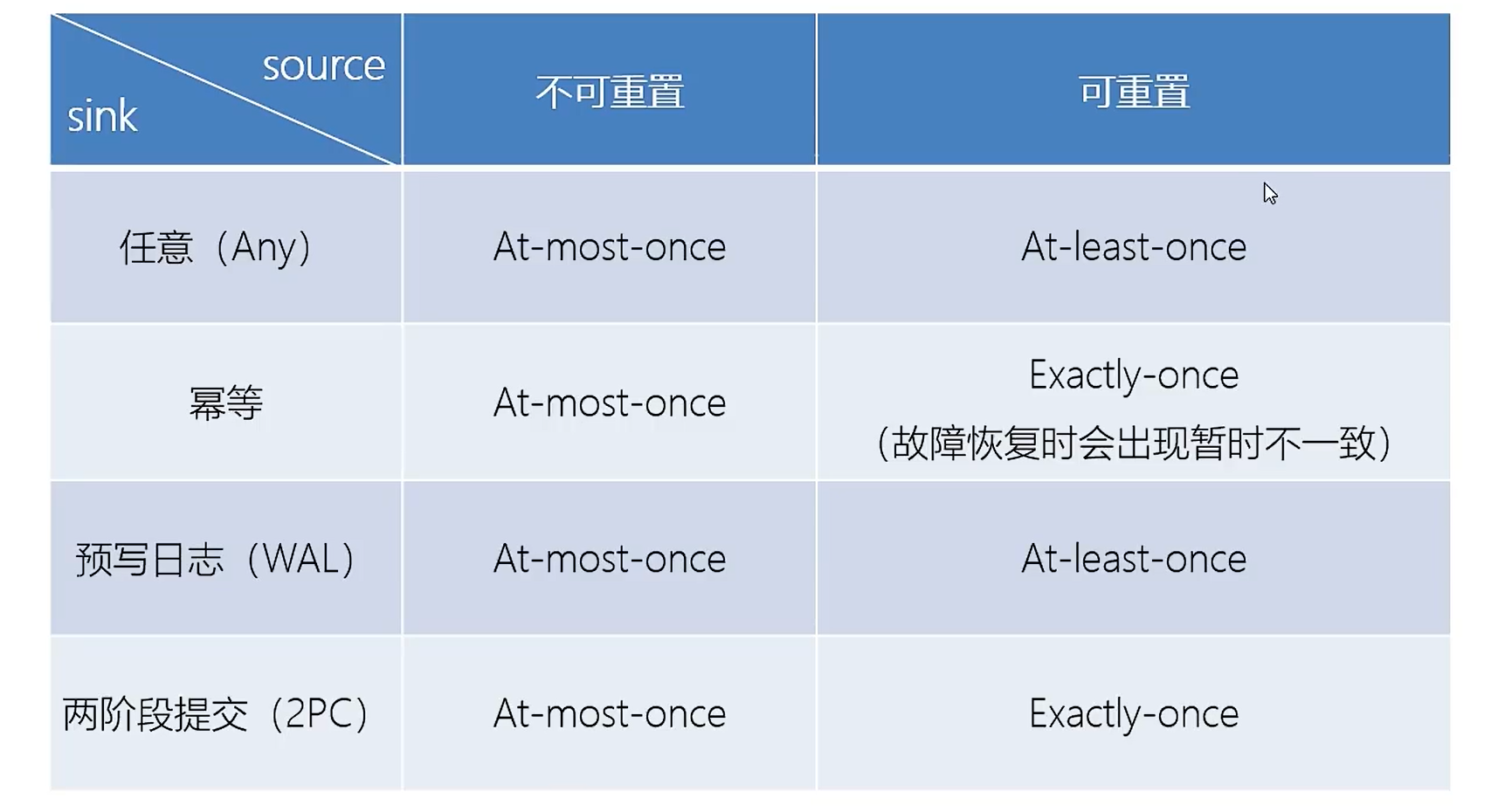
#### 9.3 Flink对接kafka的精确一次性保证
> 流处理应用中,kafka是常见数据源,实际上项目中我们也常看到kafka作为数据源和写入外部系统的应用。
##### 9.3.1 基本分析
1)Flink内部
使用检查点机制来保证状态和处理结果的精确一次性语义。
2)输入端
Kafka对数据进行了持久化保存,并可以重置偏移量,这样最少就保证了最少一次的一致性语义。Flink和Kafka连接器的`FlinkKafkaConsumer`中将当前读取的偏移量保存为算子状态,写入到检查点中;当发生故障时,从检查点中读取恢复状态,并由连接器`FlinkKafkaConsumer`向kafka重置偏移量,重新消费数据,保证结果的一致性。
3)输出端
`FlinkKafkaProducer`通过实现`TwoPhaseCommitSinkFunction`的方式实现写出的`刚好一次`一致性语义。
```java
public class FlinkKafkaProducer extends TwoPhaseCommitSinkFunction
```
##### 9.3.2 配置
> 在具体的应用中,想要实现真正的端到端exactly-once语义,还需要一些额外的配置。
1. 开启检查点。
2. `FlinkKafkaProducer`的构造函数中传入参数`Semantic.EXACTLY_ONCE`。
3. 配置Kafka读取数据的消费者的隔离级别。默认为`read_uncommmited`,外部客户可以读取到未提交的数据,为了精确一致性的保证,应该设置为`read_commmited`,但是这样的情况下,外部应用新消费数据就会存在显著的延时。
4. 事务的超时配置:如果checkpoint的保存时间比较长,那么可能会弧线导致事务超时而丢失预提交的数据。Flink的Kafka连接器中配置的事务超时时间默认为1小时,Kafka集群配置的事务最大超时时间默认为15分钟。所以我们配置Flink的Kafka连接器的事务超时时间应该小于集群的配置。
### 10 Table API&SQL
> Table API和SQL都是Flink高层的API,实际上是Dataset/Datastream API的封装。
#### 10.1 快速上手
##### 10.1.1 DataStream/Table Api转换
1)导入依赖
桥接器:
```xml
org.apache.flink
flink-table-api-java-bridge_${scala.binary.version}
${flink.version}
```
Ide中的额外依赖:
```xml
org.apache.flink
flink-table-planner-blink_${scala.binary.version}
${flink.version}
org.apache.flink
flink-streaming-scala_${scala.binary.version}
${flink.version}
```
2)创建table 执行环境:基于流的执行方式
```java
StreamExecutionEnvironment executionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment();
executionEnvironment.setParallelism(1);
SingleOutputStreamOperator eventSource = SourceUtils.getEventSource(executionEnvironment)
.assignTimestampsAndWatermarks(WatermarkStrategy.forBoundedOutOfOrderness(Duration.ZERO).withTimestampAssigner(new SerializableTimestampAssigner() {
@Override
public long extractTimestamp(Event element, long recordTimestamp) {
return element.timestamp;
}
}));
//创建表执行环境
StreamTableEnvironment streamTableEnvironment = StreamTableEnvironment.create(executionEnvironment);
//将DataStream转换成Table
Table table = streamTableEnvironment.fromDataStream(eventSource);
```
3)使用sql转换
```java
//方式1:直接写SQL进行转换
Table resultTable = streamTableEnvironment.sqlQuery("select user,url,`timestamp` from " + table);
//打印表结构
resultTable.printSchema();
//打印表数据:result> +I[tom, ./order?id=10] +I代表insert。应该是基于流的table api再这样调用。
streamTableEnvironment.toDataStream(resultTable).print("result");
```
4)基于Table直接转换:表达式的方式
```java
Table result2 = table.select($("user"), $("url"))
.where($("user").isEqual("tom"));
//转换为流打印输出
streamTableEnvironment.toDataStream(result2).print("result2");
```
##### 10.1.2 基本API
1)表环境
对于Flink这样的流处理框架来说,数据流和表在结构上还是有所去别的,所以使用Table API和SQL需要一个特殊的运行时环境,即所谓的表环境,主要负责:
- 注册Catalog和表。
- 执行SQL查询。
- 注册用户自定义函数(UDF)
- DataStream和表之间的转换。
Catalog就是”目录“,主要用来管理所有database和table的元数据,通过Catalog可以方便的对数据库和表进行查询的管理,我们可可以认为我们所定义的表都会”挂靠“在某个目录下,用于快速检索,在表环境中可以由用户自定义Catalog,并在其中注册表和自定义函数,默认的Catalog叫做`default_catalog`。
基于`blink`版本的方式的创建方式:不依赖流式处理的方式
```java
//默认就是stream模式和blink的分析器
EnvironmentSettings setting = EnvironmentSettings.newInstance().inStreamingMode().useBlinkPlanner().build();
TableEnvironment tableEnvironment = TableEnvironment.create(setting);
//batch版本
EnvironmentSettings setting2 = EnvironmentSettings.newInstance().inBatchMode().useBlinkPlanner().build();
TableEnvironment batchTableEnvironment = TableEnvironment.create(setting);
```
基于`老版本的planner`进行批处理
```java
ExecutionEnvironment batchExecutionEnvironment = ExecutionEnvironment.getExecutionEnvironment();
BatchTableEnvironment batchTableEnvironment1 = BatchTableEnvironment.create(batchExecutionEnvironment);
```
2)创建表
Flink中表是由多个行数据构成,每个行可以定义多个列字段,从整体上看,表就是固定类型的数据组成的二维矩阵。
为了方便查询表,表环境会维护一个目录(catalog)和表的对应关系:所有表都是通过Catalog来进行注册创建的。表环境中有一个唯一的id,由目录,数据库名,表名组成,默认的Catalog是`default_catalog`,database是`default_database`,所以默认为:`default_catalog.default_database.table`。
- 创建连接表:直接和外部连接器连接的表类似于source和sink
```java
//默认就是stream模式和blink的分析器
EnvironmentSettings setting = EnvironmentSettings.newInstance().build();
TableEnvironment tableEnvironment = TableEnvironment.create(setting);
//直接连接外部连接器的表被称为连接表
String clickDDL = "CREATE TABLE click_source (" +
"`user` STRING, " +
"`url` STRING, " +
"`ts` BIGINT" +
") WITH (" +
" 'connector' = 'filesystem' ," +
" 'path' = 'data/chapter01/click.txt' ," +
" 'format' = 'csv'" +
")";
tableEnvironment.executeSql(clickDDL);
String outClickDDL = "CREATE TABLE click_sink (" +
"`user` STRING, " +
"`url` STRING" +
") WITH (" +
" 'connector' = 'filesystem' ," +
" 'path' = 'data/chapter01/output' ," +
" 'format' = 'csv'" +
")";
tableEnvironment.executeSql(outClickDDL);
```
- 创建临时表:类似于view,在实际使用的时候才会将SQL嵌入到执行计划中。
```java
tableEnvironment.createTemporaryView("table_name",table);
```
3)表查询
表的查询转换,对应于流数据的转换(transform)处理。Flink提供了两种查询方式:SQL和Table API。
- SQL进行查询,Flink是基于`Apache Calcite`来提供对SQL的支持,很多大数据框架都是通过继承Calcite来实现对SQL的支持。
- Table API:通过环境获取表对象,然后进行操作。
```java
Table source = tableEnvironment.from("");
```
Demo:从文本中读取数据,进行数据转换,并输出到文件系统中,默认为并行执行的。
```java
public static void main(String[] args) {
//默认就是stream模式和blink的分析器
EnvironmentSettings setting = EnvironmentSettings.newInstance().build();
TableEnvironment tableEnvironment = TableEnvironment.create(setting);
//直接连接外部连机器的表被称为连接表
String clickDDL = "CREATE TABLE click_source (" +
"`user` STRING, " +
"`url` STRING, " +
"`ts` BIGINT" +
") WITH (" +
" 'connector' = 'filesystem' ," +
" 'path' = 'data/chapter01/click.txt' ," +
" 'format' = 'csv'" +
")";
tableEnvironment.executeSql(clickDDL);
String outClickDDL = "CREATE TABLE click_sink (" +
"`user` STRING, " +
"`url` STRING" +
") WITH (" +
" 'connector' = 'filesystem' ," +
" 'path' = 'data/chapter01/output' ," +
" 'format' = 'csv'" +
")";
tableEnvironment.executeSql(outClickDDL);
Table result = tableEnvironment.sqlQuery("select `user`,`url` from click_source");
result.executeInsert("click_sink");
}
```
结果:
demo:打印结果到console,列对应是按照index。
```java
String clickDDLToConsole = "CREATE TABLE click_sink_console (" +
"`user` STRING , " +
"`url` STRING " +
") WITH (" +
" 'connector' = 'print'" +
")";
tableEnvironment.executeSql(clickDDLToConsole);
result.executeInsert("click_sink_console");
```
结果:
4)聚合计算
可以直接使用SQL中的聚合函数来操作数据。
demo:统计每个用户的点击次数。
```java
public static void main(String[] args) {
//默认就是stream模式和blink的分析器
EnvironmentSettings setting = EnvironmentSettings.newInstance().build();
TableEnvironment tableEnvironment = TableEnvironment.create(setting);
//直接连接外部连机器的表被称为连接表
String clickDDL = "CREATE TABLE click_source (" +
"`user` STRING, " +
"`url` STRING, " +
"`ts` BIGINT" +
") WITH (" +
" 'connector' = 'filesystem' ," +
" 'path' = 'data/chapter01/click.txt' ," +
" 'format' = 'csv'" +
")";
tableEnvironment.executeSql(clickDDL);
Table result = tableEnvironment.sqlQuery("select `user`, COUNT(`url`) as cnt from click_source group by `user`");
String clickDDLToConsole = "CREATE TABLE click_sink_console (" +
"`user` STRING , " +
"`cnt` BIGINT " +
") WITH (" +
" 'connector' = 'print'" +
")";
tableEnvironment.executeSql(clickDDLToConsole);
result.executeInsert("click_sink_console");
}
```
结果:

- +I :insert
- -U:删除,+U:添加。两者成对出现,表示更新。
5)表和流的转换
- 表转化为流
- StreamTableEnvironment.toDataStream():适用于没有update操作,也就是没有聚合操作。
- StreamTableEnvironment.toChangelogStream():同样适用与update操作,将update分为两部分完成:先删除后添加,即先-U后+U。
- 流转换为表
- tableEnvironment.fromDataStream(eventSource,$("`timestamp`").as("ts")):可以直接将流转换为表,于此同时还可以提取我们想要的字段并重命名。
- createTemporaryView:从dataStream中提取一部分字段并直接注册为新的临时view。
- fromChangelogStream:可以将一个更新日志流转换成表。这个方法要求流中的数据类型只能是Row,并且每一个数据都需要指定当前行的更行类型(RowKind),一般连接器直接帮我们实现的。
注意:支持的类型
- 原子类型:基础类型,通用数据类型。
- Tuple类型:如果不重命名,默认的字段名为“f0”,即将原子类型看作一元组。我们可以重排序或重命名。
- Pojo类型
- Row类型:Row类型也是一种复合类型,长度固定,而且无法推断出每个字段的类型。所以在使用时必须知名具体的类型信息。
#### 10.2 流处理中的表
##### 10.2.1 动态表和持续查询
> Flink流处理框架来说,要处理源源不断的无界数据流,我们无法等到数据都到齐之后再做查询,每来一条数据就应该更新一次结果,如果我们使用table和sql API处理的时候,就发现有些别扭。
1)关系型数据库的查询和流查询的对比:
| | 关系型表 | 流处理 |
| ---------------- | ------------------------ | ---------------------------------------- |
| 处理的数据对象 | 字段元组的有界集合 | 字段元组的无限序列 |
| 查询对数据的访问 | 可以访问完整的数据输入 | 无法访问所有的数据,必须持续等待流式输入 |
| 查询终止条件 | 生成固定大小的结果集之后 | 不停止,根据接收的输入不停的更新查询结果 |
2)动态表
当流中有新数据到来,初始表中会插入一行,而基于这个表定义的SQL查询就应该在之前的基础上更新结果,这样得到的表就会不断地动态变化,因此被称为“动态表”。
数据库中的表其实就是一系列insert,update,delete语句执行的结果,我们一般称之为`更新日志流`。如果我们保存某一时刻的快照,那么接下来只要读取更新日志流,就可以得到表之后的变化过程和最终结果了。
3)持续查询
动态表可以像静态的批处理表一样进行查询操作,但是由于数据在不断的变化,因此基于他定义的sql查询也不可能执行一次就得到结果,这样我们对动态表的查询就不会停止,这样的查询就叫做`持续查询`。每次数据输入就会出发查询,可以认为一次查询面对的数据集,就是当前输入动态表中的所有数据,当作对有限数据进行批处理相当于对目前已有的输入做了一个`快照`;流式数据的到来会连续不断地触发快照查询,像动画一样连贯起来,就构成了`持续查询`。
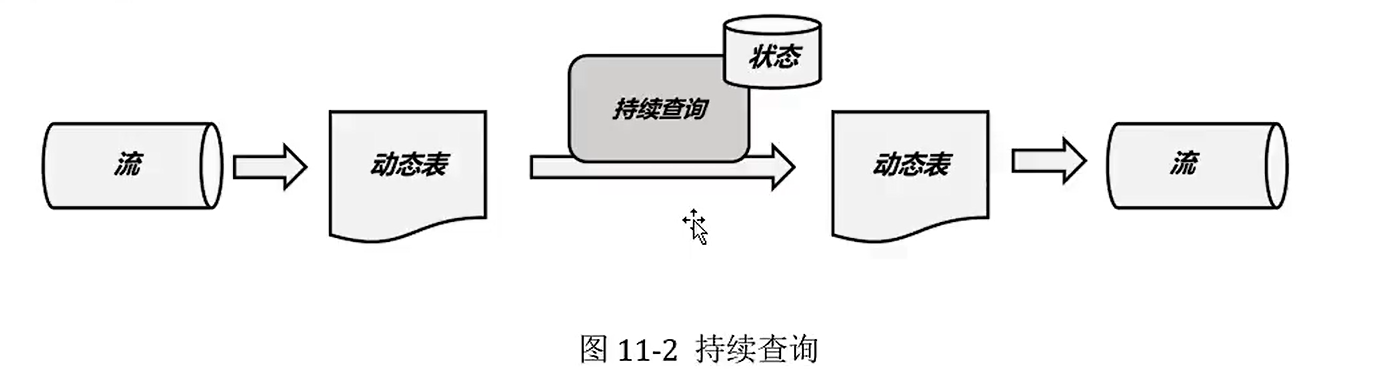
4)持续查询之更新查询
持续查询的过程中会更新状态,例如统计每个人的url点击量。
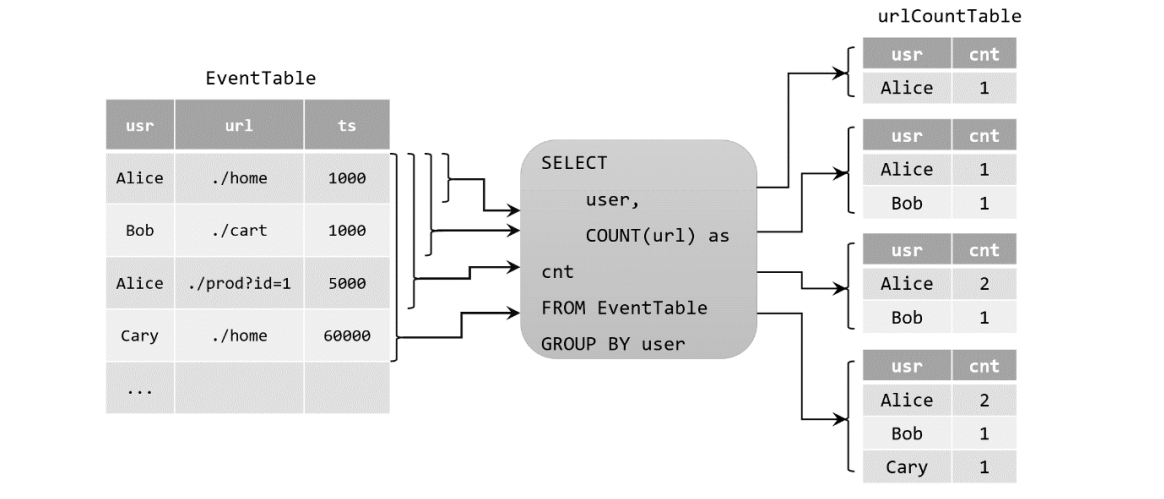
步骤如下:
- 当查询启动的时候,原始动态表EventTable为空;
- 当第一行Alice的点击数据插入EventTable表时,查询开始计算结果表,UrlCountTable中插入一行数据[Alice,1]
- 当第二行 Bob 点击数据插入 EventTable 表时,查询将更新结果表并插入新行[Bob, 1]。
- 第三行数据到来,同样是 Alice 的点击事件,这时不会插入新行,而是生成一个针 对已有行的更新操作。这样,结果表中第一行[Alice,1]就更新为[Alice,2]。
- 当第四行 Cary 的点击数据插入到 EventTable 表时,查询将第三行[Cary,1]插入到 结果表中。
5)持续查询之追加查询
- 如果我们执行一 个简单的条件查询,结果表中就会像原始表 EventTable 一样,只有插入(Insert)操作了,这样的查询也可以被称为`追加查询`。
- 窗口聚合:窗口关闭的时候只会计算一次,因此也只有insert操作,所以可以认为也是追加查询。
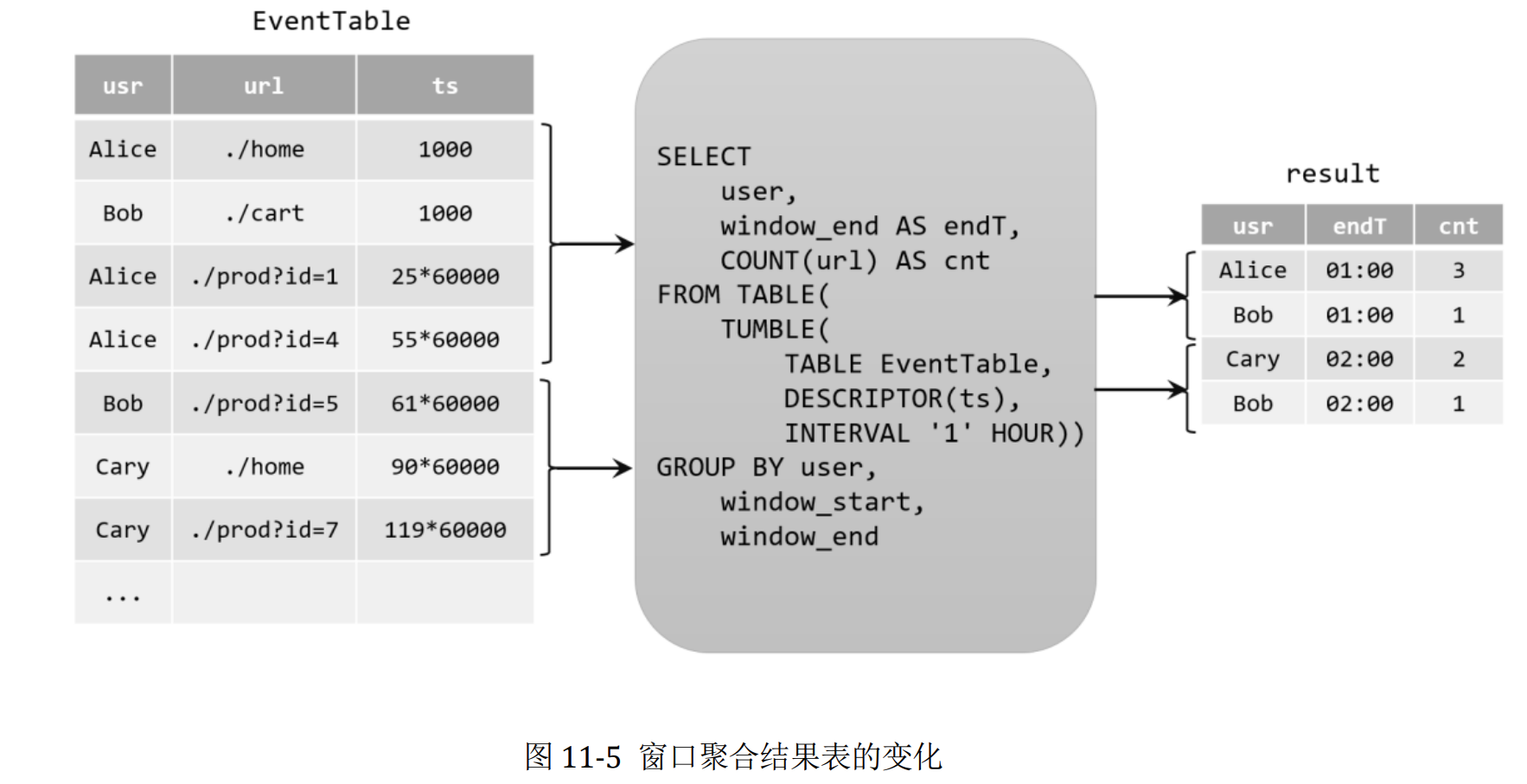
6)查询限制
实际应用中,有些持续查询也会因为计算代价太高而受到限制。
- 状态大小:随着时间的推移,用户数越来越大,需要维护的状态也越来越大。
- 更新计算:有些查询计算的复杂度可能很高,每来一条新的数据,更新结果的时候可能需要全部重新计算,并且对很多已经输出的行进行更新。一个典型的例子是Rank函数。
##### 10.2.2 动态表转换为流
动态表通过插入,更新和删除操作,进行持续的更改。将动态表转换为流或者将其写入外部系统时,就需要进行编码。Flink中目前支持以下三种编码:
- 仅追加流(toDataStream):仅存在插入方式。
- 撤回流(toChangelogStream):支持添加(add)和撤回(retract)消息。
- 添加:add
- 删除:通过retract实现
- 更新:先retract后add
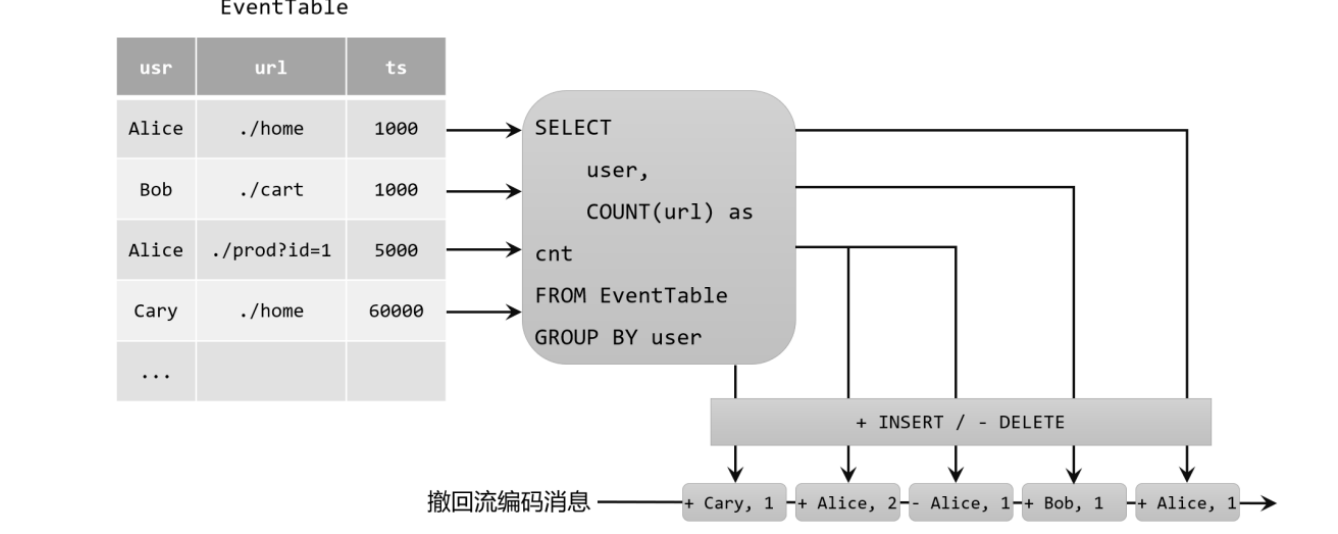
- 更新插入流:包含更新插入(update)和删除(delete)
- INSERT 插 入操作和UPDATE更新操作,统一被编码为upsert消息,要求动态表中存在唯一key,如果key不存在则是插入,如果key存在则是更新
- DELETE删除操作则被编码为delete 消息。
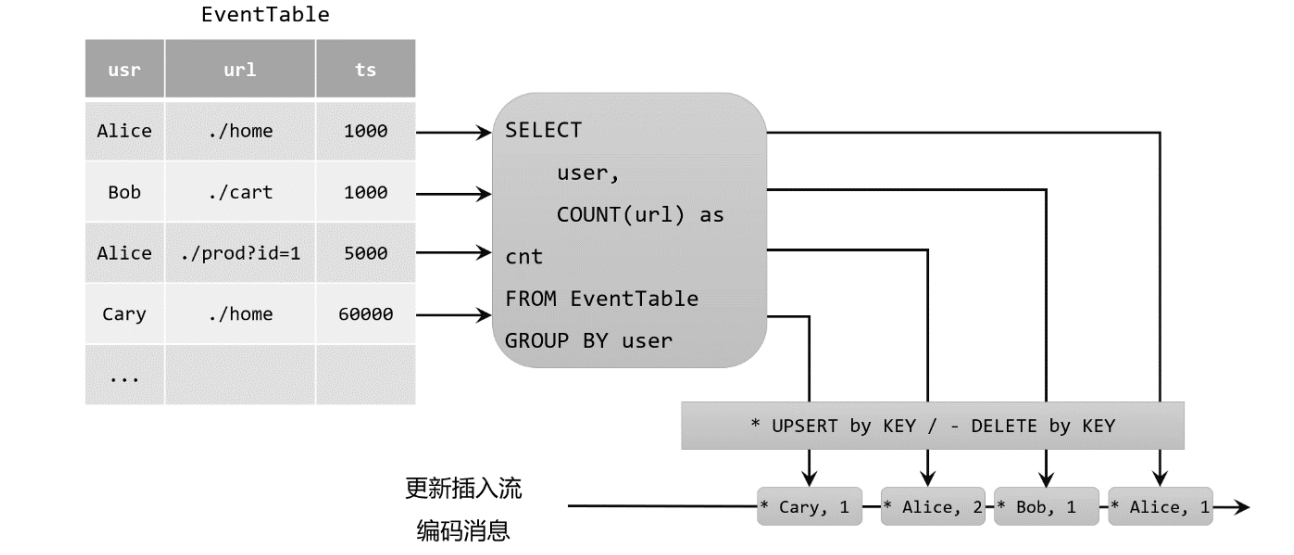
#### 10.3 时间属性和窗口
> 基于时间的操作需要定义相关的时间语义和时间数据来源。Flink的Table和SQL Api中会给表单独提供一个逻辑上的时间字段,专门用来在表处理程序中指示时间。
##### 10.3.1 事件时间
事件时间语义最大的用途就是处理乱序事件或者延迟事件的场景,我们可以通过设置`watermark`来表示事件时间的进展,而水位线可以根据数据的最大时间戳设置一个延迟时间,可以处理一定乱序的情况。为了处理无序时间,并区分流中的迟到事件,Flink需要从事件数据中提取时间戳,并生成水位线,用来推进事件时间的进展。事件时间属性可以在建立表的DDL中定义,也可以在数据流和表的转换中定义。
1)DDL中定义
通过`WATERMARK`语句来定义事件时间属性,主要来定义水位线的生成表达式,这个表达式会将带有事件时间戳的字段标记为事件时间属性,并在它基础上给出水位线的 延迟时间。
示例:ts字段定义事件时间属性并设置5s的水位线延迟。
FlinkFlink 中支持的事件时间属性数据类型必须为 TIMESTAMP 或者 TIMESTAMP_LTZ(带有本地时区信息的时间戳)。
```sql
CREATE TABLE EventTable(
user STRING,
url STRING,
ts TIMESTAMP(3),
WATERMARK FOR ts AS ts - INTERVAL '5' SECOND
) WITH (
...
);
```
而如果原始的时间戳就是一个长整型的毫秒数,这时就需要另外定义一个字段来表示事件时间属性,类型定义为 TIMESTAMP_LTZ 会更方便
```sql
CREATE TABLE events (
user STRING,
url STRING,
ts BIGINT,
ts_ltz AS TO_TIMESTAMP_LTZ(ts, 3),
WATERMARK FOR ts_ltz AS ts_ltz - INTERVAL '5' SECOND
) WITH (
...
);
```
2)数据流转换为表的时候定义
调用 fromDataStream() 方法创建表时,可以追加参数来定义表中的字段结构;这时可以给某个字段加上`.rowtime()` 后 缀,就表示将当前字段指定为事件时间属性。这个字段可以是数据中本不存在、额外追加上去 的“逻辑字段”,就像之前 DDL 中定义的第二种情况;也可以是本身固有的字段,那么这个 字段就会被事件时间属性所覆盖,类型也会被转换为 TIMESTAMP。不论那种方式,时间属性 字段中保存的都是事件的时间戳(TIMESTAMP 类型)。
需要注意的是,这种方式只负责指定时间属性,而时间戳的提取和水位线的生成应该之前 就在 DataStream 上定义好了。由于 DataStream 中没有时区概念,因此 Flink 会将事件时间属 性解析成不带时区的 TIMESTAMP 类型,所有的时间值都被当作 UTC 标准时间。
```java
// 方法一:
// 流中数据类型为二元组 Tuple2,包含两个字段;需要自定义提取时间戳并生成水位线
DataStream> stream =
inputStream.assignTimestampsAndWatermarks(...);
// 声明一个额外的逻辑字段作为事件时间属性
Table table = tEnv.fromDataStream(stream, $("user"), $("url"),
$("ts").rowtime());
// 方法二:
// 流中数据类型为三元组 Tuple3,最后一个字段就是事件时间戳
DataStream> stream =
inputStream.assignTimestampsAndWatermarks(...);
// 不再声明额外字段,直接用最后一个字段作为事件时间属性
Table table = tEnv.fromDataStream(stream, $("user"), $("url"),
$("ts").rowtime());
```
##### 10.3.2 处理时间
处理时间就比较简单了,它就是我们的系统时间,使用时不需要提取时间戳 (timestamp)和生成水位线(watermark)。因此在定义处理时间属性时,必须要额外声明一个 字段,专门用来保存当前的处理时间。处理时间属性的定义也有两种方式:
1)在创建表的 DDL 中定义
这里的时间属性,其实是以“计算列”(computed column)的形式定义出来的。
```sql
CREATE TABLE EventTable(
user STRING,
url STRING,
ts AS PROCTIME()
) WITH (
...
);
```
2)在数据流转换为表时定义
处 理 时 间 属 性 同 样 可 以 在 将 DataStream 转 换 为 表 的 时 候 来 定 义 。 我 们 调 用 fromDataStream()方法创建表时,可以用.proctime()后缀来指定处理时间属性字段。由于处理时 间是系统时间,原始数据中并没有这个字段,所以处理时间属性一定不能定义在一个已有字段 上,只能定义在表结构所有字段的最后,作为额外的逻辑字段出现。
```java
DataStream> stream = ...;
// 声明一个额外的字段作为处理时间属性字段
Table table = tEnv.fromDataStream(stream, $("user"), $("url"),
$("ts").proctime());
```
##### 10.3.3 窗口
有了时间属性,接下来就可以定义窗口进行计算了。我们知道,窗口可以将无界流切割成 大小有限的“桶”(bucket)来做计算,通过截取有限数据集来处理无限的流数据。
1)分组窗口(group window,老版本)
`分组窗口的功能比较有限,只支持窗口聚合,所以目前已经处于弃用(deprecated)的状态。`
在 Flink 1.12 之前的版本中,Table API 和 SQL 提供了一组“分组窗口”(Group Window) 函数,常用的时间窗口如滚动窗口、滑动窗口、会话窗口都有对应的实现;具体在 SQL 中就 是调用 TUMBLE()、HOP()、SESSION(),传入时间属性字段、窗口大小等参数就可以了。
以滚动窗口为例:
```sql
TUMBLE(ts, INTERVAL '1' HOUR)
```
ts 是定义好的时间属性字段,窗口大小用”时间间隔“INTERVAL来定义。
在进行窗口计算时,分组窗口是将窗口本身当作一个字段对数据进行分组的,可以对组内 的数据进行聚合。基本使用方式如下:
```java
Table result = tableEnv.sqlQuery(
"SELECT " +
"user, " +
"TUMBLE_END(ts, INTERVAL '1' HOUR) as endT, " +
"COUNT(url) AS cnt " +
"FROM EventTable " +
"GROUP BY " + // 使用窗口和用户名进行分组
"user, " +
"TUMBLE(ts, INTERVAL '1' HOUR)" // 定义 1 小时滚动窗口
);
```
2)窗口表值函数(Windowing TVFs,新版本)
从 1.13 版本开始,Flink 开始使用窗口表值函数(Windowing table-valued functions, Windowing TVFs)来定义窗口。窗口表值函数是 Flink 定义的多态表函数(PTF),可以将表 进行扩展后返回。表函数(table function)可以看作是返回一个表的函数。目前 Flink 提供了以下几个窗口 TVF:
- 滚动窗口(Tumbling Windows);
- 滑动窗口(Hop Windows,跳跃窗口);
- 累积窗口(Cumulate Windows);
- 会话窗口(Session Windows,目前尚未完全支持)。
相当于与GroupBy window的特点:
- 窗口 TVF 更符合 SQL 标准,性能得到 了优化,拥有更强大的功能。
- 可以支持基于窗口的复杂计算,例如窗口 Top-N、窗口联结(window join)
- 但是会话窗口和很多高级功能还不支持,不过正在快速地更新完善。
在窗口 TVF 的返回值中,除去原始表中的所有列,还增加了用来描述窗口的额外 3 个列:
- “窗口起始点”(window_start)
- “窗口结束点”(window_end)
- “窗口时间”(window_time):窗口中的时间属性,它的值等于 `window_end - 1ms`,所以相当于是窗口中能够包含数据的最大时间戳。
实例:
- 滚动窗口:通过调用 TUMBLE()函数就可以声明一个滚动窗口,只有一个核心参数就是窗 口大小(size)。
```java
TUMBLE(TABLE EventTable, DESCRIPTOR(ts), INTERVAL '1' HOUR)
```
- 滑动窗口(HOP):在 SQL 中通过调用 HOP()来声明滑动窗口;除了也要传入表名、时间属性外,还需要传入窗口大小(size) 和滑动步长(slide)两个参数。
```java
HOP(TABLE EventTable, DESCRIPTOR(ts), INTERVAL '5' MINUTES, INTERVAL '1' HOURS));
```
- 累积窗口(CUMULATE):滚动窗口和滑动窗口,可以用来计算大多数周期性的统计指标。如果我们想要统计网站的当天的PV(page view),如果用1天的滚动窗口,那么只有等这天结束的时候才知道结果;如果使用滑动窗口,那么统计的是最近24小时的访问量。而我们真正想要的是按照自然日统计每天PV,不过每隔一小时就输出一次当天到目前为止的PV值。
- 开始时,创建的第一个窗口大小就是步长 step。
- 之后的每个窗口都会在之前的基础上再 扩展 step 的长度,直到达到最大窗口长度。
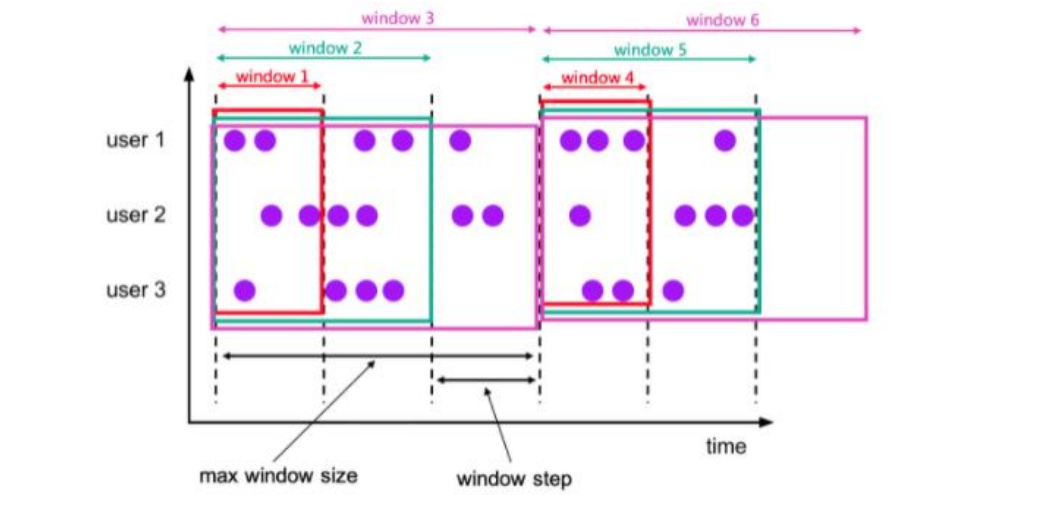
```java
CUMULATE(TABLE EventTable, DESCRIPTOR(ts), INTERVAL '1' HOURS, INTERVAL '1' DAYS))
```
#### 10.4 聚合查询
>一个很常见的功能就是对某一列的多条数据做一个合并统计,得到一个或多 个结果值;比如求和、最大最小值、平均值等等,这种操作叫作聚合(Aggregation)查询。
##### 10.4.1 分组聚合
SQL中的聚合函数,例如sum,max,min,avg,count。我们也可以使用group by根据某个字段进行分组,然后进行聚合计算。例如按照用户名进行分组,统计每个用户点击url的次数。
```sql
SELECT user, COUNT(url) as cnt FROM EventTable GROUP BY use
```
这种聚合方式,就叫作“分组聚合”(group aggregation)。从概念上讲,SQL 中的分组聚 合可以对应 DataStream API 中 keyBy 之后的聚合转换,它们都是按照某个 key 对数据进行了 划分,各自维护状态来进行聚合统计的。在流处理中,分组聚合同样是一个持续查询,而且是 一个更新查询,得到的是一个动态表;每当流中有一个新的数据到来时,都会导致结果表的更 新操作。因此,想要将结果表转换成流或输出到外部系统,必须采用撤回流(retract stream) 或更新插入流(upsert stream)的编码方式;如果在代码中直接转换成 DataStream 打印输出, 需要调用 toChangelogStream()。
另外,在持续查询的过程中,由于用于分组的 key 可能会不断增加,因此计算结果所需要 维护的状态也会持续增长。为了防止状态无限增长耗尽资源,Flink Table API 和 SQL 可以在表 环境中配置状态的生存时间(TTL):
```java
TableEnvironment tableEnv = ...
// 获取表环境的配置
TableConfig tableConfig = tableEnv.getConfig();
// 配置状态保持时间
tableConfig.setIdleStateRetention(Duration.ofMinutes(60));
或者
TableEnvironment tableEnv = ...
Configuration configuration = tableEnv.getConfig().getConfiguration();
configuration.setString("table.exec.state.ttl", "60 min");
```
##### 10.4.2 窗口聚合
流处理中,往往需要将无限数据流划分成有界数据集,这就是所谓的`窗口`。在 Flink 的 Table API 和 SQL 中,窗口的计算是通过“窗口聚合”(window aggregation) 来实现的。与分组聚合类似,窗口聚合也需要调用 SUM()、MAX()、MIN()、COUNT()一类的 聚合函数,通过 GROUP BY 子句来指定分组的字段。只不过窗口聚合时,需要将窗口信息作 为分组 key 的一部分定义出来。
- 在 Flink 1.12 版本之前,是直接把窗口自身作为分组 key 放在 GROUP BY 之后的,所以也叫“分组窗口聚合”
- 而 1.13 版本开始使用了 “窗口表值函数”(Windowing TVF),窗口本身返回的是就是一个表,所以窗口会出现在 FROM 后面,GROUP BY 后面的则是窗口新增的字段 window_start 和 window_end。
实例:这里我们以 ts 作为时间属性字段、基于 EventTable 定义了 1 小时的滚动窗口,希望统计 出每小时每个用户点击 url 的次数。
```java
Table result = tableEnv.sqlQuery(
"SELECT " +
"user, " +
"window_end AS endT, " +
"COUNT(url) AS cnt " +
"FROM TABLE( " +
"TUMBLE( TABLE EventTable, " +
"DESCRIPTOR(ts), " +
"INTERVAL '1' HOUR)) " +
"GROUP BY user, window_start, window_end "
);
```
与分组聚合不同,窗口聚合不会将中间聚合的状态输出,只会最后输出一个结果。所有数据都是以 INSERT 操作追加到结果动态表中的,因此输出每行前面都有+I 的 前缀。所以窗口聚合查询都属于追加查询,没有更新操作,代码中可以直接用 toDataStream() 将结果表转换成流。
##### 10.4.3 开窗(over)聚合
分组聚合和窗口值函数都是对一组数据进行聚合,都是`多对一`的关系,将数据分组之后每组只会得到一个聚合结果。而开窗函数是对每 行都要做一次开窗聚合,因此聚合之后表中的行数不会有任何减少,是一个“多对多”的关系。
```sql
SELECT
<聚合函数> OVER (
[PARTITION BY <字段 1>[, <字段 2>, ...]]
ORDER BY <时间属性字段>
<开窗范围>),
...
FROM ...
```
- Partition by:用来指定分区的键(key),类似于Group BY的分组。
- Order by:在 Flink 的流处理中, 目前只支持按照时间属性的升序排列,所以这里 ORDER BY 后面的字段必须是定义好的时间属性。
- 开窗范围:对于开窗函数而言,必须要指定开窗的范围,也就是到底要扩展多少行来做聚合,这个范围是由between <下界> and <上界>来定义的。目前支持的上界只能是 CURRENT ROW,也就是定义一个“从之前某一行到当前行”。所以一般的形式为:
```sql
BETWEEN ... PRECEDING AND CURRENT ROW
```
开窗选择的范围可以是基于时间的,也可以是基于数据的数量。所以需要指定:
- 范围间隔:Range intervals。范围间隔以 RANGE 为前缀,就是基于 ORDER BY 指定的时间字段去选取一个范围,一 般就是当前行时间戳之前的一段时间。例如开窗范围选择当前行之前 1 小时的数据:
```java
RANGE BETWEEN INTERVAL '1' HOUR PRECEDING AND CURRENT ROW
```
- 行间隔:Row intervals。行间隔以 ROWS 为前缀,就是直接确定要选多少行,由当前行出发向前选取就可以了。 例如开窗范围选择当前行之前的 5 行数据(最终聚合会包括当前行,所以一共 6 条数据):
```java
ROWS BETWEEN 5 PRECEDING AND CURRENT ROW
```
示例:们以 ts 作为时间属性字段,对 EventTable 中的每行数据都选取它之前 1 小时的所 有数据进行聚合,统计每个用户访问 url 的总次数,并重命名为 cnt。最终将表中每行的 user, ts 以及扩展出 cnt 提取出来。
```sql
SELECT user, ts,
COUNT(url) OVER (
PARTITION BY user
ORDER BY ts
RANGE BETWEEN INTERVAL '1' HOUR PRECEDING AND CURRENT ROW
) AS cnt
FROM EventTable
```
开窗聚合与窗口聚合(窗口 TVF 聚合)本质上不同,不过也还是有一些相似之处的:它 们都是在无界的数据流上划定了一个范围,截取出有限数据集进行聚合统计。在 Table API 中确实就定义了两类窗口:分组窗口(GroupWindow)和开 窗窗口(OverWindow);而在 SQL 中,也可以用 WINDOW 子句来在 SELECT 外部单独定义 一个 OVER 窗口:
```java
SELECT user, ts,
COUNT(url) OVER w AS cnt,
342
MAX(CHAR_LENGTH(url)) OVER w AS max_url
FROM EventTable
WINDOW w AS (
PARTITION BY user
ORDER BY ts
ROWS BETWEEN 2 PRECEDING AND CURRENT ROW)
```
##### 10.4.4 Top N
1)普通Top N
在 Flink SQL 中,是通过 OVER 聚合和一个条件筛选来实现 Top N 的。具体来说,是通过 将一个特殊的聚合函数ROW_NUMBER()应用到OVER窗口上,统计出每一行排序后的行号, 作为一个字段提取出来;然后再用 WHERE 子句筛选行号小于等于 N 的那些行返回。
```sql
SELECT ...
FROM (
SELECT ...,
ROW_NUMBER() OVER (
[PARTITION BY <字段 1>[, <字段 1>...]]
ORDER BY <排序字段 1> [asc|desc][, <排序字段 2> [asc|desc]...]
) AS row_num
FROM ...)
WHERE row_num <= N [AND <其它条件>]
```
OVER 窗口目前并不完善,不过针对 Top N 这样一个经典应用场景,Flink SQL 专门用 OVER 聚合做了优化实现。所以只有在 Top N 的应用场景中,OVER 窗口 ORDER BY 后才可以指定其它排序字段;而要想实现 Top N,就必须按照上面的格式进行定义,否则 Flink SQL 的优化器将无法正常解析。而且,目前 Table API 中并不支持 ROW_NUMBER()函数,所 以也只有 SQL 中这一种通用的 Top N 实现方式。
2)窗口Top N
例如:电商行业,实际应用中往往有这样的需求:统计一段时间内的热门商品。这就需要先 开窗口,在窗口中统计每个商品的点击量;然后将统计数据收集起来,按窗口进行分组,并按 点击量大小降序排序,选取前 N 个作为结果返回。
实现思路:可以先做一个窗口聚合,将窗口信息 window_start、window_end 连同每个商 品的点击量一并返回,这样就得到了聚合的结果表,包含了窗口信息、商品和统计的点击量。 接下来就可以像一般的 Top N 那样定义 OVER 窗口了,按窗口分组,按点击量排序,用 ROW_NUMBER()统计行号并筛选前 N 行就可以得到结果。所以窗口 Top N 的实现就是窗口 聚合与 OVER 聚合的结合使用。
案例:由于用户访问事件 Event 中没有商品相关信息,因此我 们统计的是每小时内有最多访问行为的用户,取前两名,相当于是一个每小时活跃用户的查询。
```java
public class TopNByWindow {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment executionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment();
//设置水位线
SingleOutputStreamOperator eventSource = executionEnvironment.fromElements(
new Event("tom", "./index", 1000L),
new Event("tom", "./product?id=10", 2000L),
new Event("lily", "./index", 3000L),
new Event("tom", "./order?id=10", 40000L),
new Event("ailis", "./index", 5000L),
new Event("tom", "./pay?id=10", 16000L),
new Event("tom", "./pay?id=1000", 20000L))
.assignTimestampsAndWatermarks(WatermarkStrategy.forBoundedOutOfOrderness(Duration.ZERO)
.withTimestampAssigner(new SerializableTimestampAssigner() {
@Override
public long extractTimestamp(Event element, long recordTimestamp) {
return element.timestamp;
}
}));
//创建表环境
StreamTableEnvironment streamTableEnvironment = StreamTableEnvironment.create(executionEnvironment);
//流转换为表
Table sourceTable = streamTableEnvironment.fromDataStream(eventSource, $("user"), $("url"), $("timestamp"), $("timestamp").rowtime().as("ts"));
//注册为临时表
streamTableEnvironment.createTemporaryView("event_source", sourceTable);
//定义TVF
String subQuery = "SELECT window_start, window_end, `user`, COUNT(url) as cnt " +
"FROM TABLE ( " +
"TUMBLE (TABLE event_source, DESCRIPTOR(ts), INTERVAL '10' SECOND))" +
"GROUP BY window_start,window_end,`user`";
String midQuery = "SELECT sub_view.window_start, sub_view.window_end, sub_view.`user`, sub_view.cnt ," +
"row_number() over (partition by window_start,window_end order by cnt desc) as rown " +
"FROM (" +
subQuery +
") AS sub_view";
String topQuery = "SELECT * FROM (" +
midQuery +
") AS top where top.rown <= 2";
Table result = streamTableEnvironment.sqlQuery(topQuery);
streamTableEnvironment.toDataStream(result).print();
executionEnvironment.execute();
}
}
```
console:

#### 10.5 联结查询
常规联结(Regular Join)是 SQL 中原生定义的 Join 方式,是最通用的一类联结操作。在两个动态表的联结中,任何一侧表的插入(INSERT)或更改(UPDATE)操作都会让 联结的结果表发生改变。例如,如果左侧有新数据到来,那么它会与右侧表中所有之前的数据 进行联结合并,右侧表之后到来的新数据也会与这条数据连接合并。所以,常规联结查询一般 是更新(Update)查询。
Flink目前仅支持“等值条件”。
##### 10.5.1 等值内连接
内联结用 INNER JOIN 来定义,会返回两表中符合联接条件的所有行的组合,也就是所谓 的`笛卡尔积`(Cartesian product)
```sql
SELECT *
FROM Order
INNER JOIN Product
ON Order.product_id = Product.id
```
##### 10.5.2 等值外连接
和标准SQL中的联结方式和含义一致。
```sql
SELECT *
FROM Order
LEFT JOIN Product
ON Order.product_id = Product.id;
SELECT *
FROM Order
RIGHT JOIN Product
ON Order.product_id = Product.id;
SELECT *
FROM Order
FULL OUTER JOIN Product
ON Order.product_id = Product.id
```
##### 10.5.3 间隔联结查询
我们曾经学习过 DataStream API 中的双流 Join,包括窗口联结(window join) 和间隔联结(interval join)。在SQL中对应两个表的Join,这是流中特有的联结方式,目前Flink SQL还不支持窗口联结,而间隔联结已经实现。
间隔联结(Interval Join)返回的,同样是符合约束条件的两条中数据的笛卡尔积。只不 过这里的“约束条件”除了常规的联结条件外,还多了一个时间间隔的限制。
- 两表的联结:间隔联结不需要用 JOIN 关键字,直接在 FROM 后将要联结的两表列出来就可以,用逗 号分隔。这与标准 SQL 中的语法一致,表示一个“交叉联结”(Cross Join),会返回两表中所有 行的笛卡尔积。
- 联结条件:联结条件用 WHERE 子句来定义,用一个等值表达式描述。交叉联结之后再用 WHERE 进行条件筛选,效果跟内联结 INNER JOIN ... ON ...非常类似。
- 时间间隔限制:我们可以在 WHERE 子句中,联结条件后用 AND 追加一个时间间隔的限制条件;做法是 提取左右两侧表中的时间字段,然后用一个表达式来指明两者需要满足的间隔限制。具体定义 方式有下面三种,这里分别用 ltime 和 rtime 表示左右表中的时间字段:
- ltime = rtime
- ltime >= rtime AND ltime < rtime + INTERVAL '10' MINUTE
- ltime BETWEEN rtime - INTERVAL '10' SECOND AND rtime + INTERVAL '5' SECOND
判断两者相等,这是最强的时间约束,要求两表中数据的时间必须完全一致才能匹配;我们还是会放宽一些,给出一个间隔。间隔的定义可以用<,<=,>=,>这一类的 关系不等式,也可以用 BETWEEN ... AND ...这样的表达式。
示例:我们现在除了订单表 Order 外,还有一个“发货表”Shipment,要求在收到订单后四 个小时内发货。那么我们就可以用一个间隔联结查询,把所有订单与它对应的发货信息连接合 并在一起返回。
```sql
SELECT *
FROM Order o, Shipment s
WHERE o.id = s.order_id
AND o.order_time BETWEEN s.ship_time - INTERVAL '4' HOUR AND s.ship_time
```
在流处理中,间隔联结查询只支持具有时间属性的“仅追加”(Append-only)表。那对于有更新操作的表,又怎么办呢?除了间隔联结之外,Flink SQL 还支持时间联结 (Temporal Join),这主要是针对“版本表”(versioned table)而言的,关于版本表可以参照官网。
#### 10.6 函数
>在 SQL 中,我们可以把一些数据的转换操作包装起来,嵌入到 SQL 查询中统一调用,这 就是“函数”(functions)。
Flink SQL 中的函数可以分为两类:
- SQL 中内置的系统函数,直接通过函数名调用,比如COUNT()、CHAR_LENGTH()、。
- 另一类函数则是用户自定义的函数(UDF),需要在表环境中注册才能使用。
##### 10.6.1 系统函数
用法和标准SQL一致。
##### 10.6.2 自定义函数(UDF)
Flink 的 Table API 和 SQL 提供了多种自定义函数的接口,以抽象类的形式定义。当前 UDF 主要有以下几类:
- 标量函数(Scalar Functions):将输入的标量值转换成一个新的标量值;
- 表函数(Table Functions):将标量值转换成一个或多个新的行数据,也就是 扩展成一个表;
- 聚合函数(Aggregate Functions):将多行数据里的标量值转换成一个新的标 量值;
- 表聚合函数(Table Aggregate Functions):将多行数据里的标量值转换成一 个或多个新的行数据。
自定义UDF的步骤:
1. 注册函数:
```java
//创建系统函数:全局的
tableEnv.createTemporarySystemFunction("MyFunction", MyFunction.class);
//创建目录函数:当前database可用
tableEnv.createTemporaryFunction("MyFunction", MyFunction.class);
```
2. 调用方式
- Table Api
```java
tableEnv.from("MyTable").select(call("MyFunction", $("myField")));
//or 内联的方式
tableEnv.from("MyTable").select(call(SubstringFunction.class, $("myField")));
```
- SQL中调用
```java
tableEnv.sqlQuery("SELECT MyFunction(myField) FROM MyTable");
```
1)标量函数--Scalar function
自定义标量函数可以把 0 个、 1 个或多个标量值转换成一个标量值,它对应的输入是一 行数据中的字段,输出则是唯一的值。所以从输入和输出表中行数据的对应关系看,标量函数 是“一对一”的转换。
要求:
- 我们需要自定义一个类来继承抽象类 ScalarFunction,并实 现叫作 eval() 的求值方法
- 标量函数的行为就取决于求值方法的定义,它必须是公有的(public), 而且名字必须是 eval。
- 求值方法 eval 可以重载多次,任何数据类型都可作为求值方法的参数 和返回值类型。
```java
public static class HashFunction extends ScalarFunction {
// 接受任意类型输入,返回 INT 型输出
public int eval(@DataTypeHint(inputGroup = InputGroup.ANY) Object o) {
return o.hashCode();
}
}
// 注册函数
tableEnv.createTemporarySystemFunction("HashFunction", HashFunction.class);
// 在 SQL 里调用注册好的函数
tableEnv.sqlQuery("SELECT HashFunction(myField) FROM MyTable");
```
2)表函数
跟标量函数一样,表函数的输入参数也可以是 0 个、1 个或多个标量值;不同的是,它可 以返回任意多行数据。“多行数据”事实上就构成了一个表,所以“表函数”可以认为就是返回一 个表的函数,这是一个“一对多”的转换关系。之前我们介绍过的窗口 TVF,本质上就是表函数。
要求:
- 需要自定义类来继承抽象类 TableFunction,内部必须要实现的也是一个名为 eval 的求值方法。
- 与标量函数不同的是,TableFunction 类本身是有一 个泛型参数T 的,这就是表函数返回数据的类型;而 eval()方法没有返回类型,内部也没有 return 语句,是通过调用 collect()方法来发送想要输出的行数据的。
- 在 SQL 中调用表函数,需要使用 LATERAL TABLE()来生成扩展的“侧向 表”,然后与原始表进行联结(Join)。这里的 Join 操作可以是直接做交叉联结(cross join), 在 FROM 后用逗号分隔两个表就可以;也可以是以 ON TRUE 为条件的左联结(LEFT JOIN)。
示例:我们实现了一个分隔字符串的函数 SplitFunction,可以将 一个字符串转换成(字符串,长度)的二元组。
```java
// 注意这里的类型标注,输出是 Row 类型,Row 中包含两个字段:word 和 length。
@FunctionHint(output = @DataTypeHint("ROW"))
public static class SplitFunction extends TableFunction {
public void eval(String str) {
for (String s : str.split(" ")) {
// 使用 collect()方法发送一行数据
collect(Row.of(s, s.length()));
}
}
}
// 注册函数
tableEnv.createTemporarySystemFunction("SplitFunction", SplitFunction.class);
355
// 在 SQL 里调用注册好的函数
// 1. 交叉联结
tableEnv.sqlQuery(
"SELECT myField, word, length " +
"FROM MyTable, LATERAL TABLE(SplitFunction(myField))");
// 2. 带 ON TRUE 条件的左联结
tableEnv.sqlQuery(
"SELECT myField, word, length " +
"FROM MyTable " +
"LEFT JOIN LATERAL TABLE(SplitFunction(myField)) ON TRUE");
// 重命名侧向表中的字段
tableEnv.sqlQuery(
"SELECT myField, newWord, newLength " +
"FROM MyTable " +
"LEFT JOIN LATERAL TABLE(SplitFunction(myField)) AS T(newWord, newLength) ON
TRUE");
```
3)聚合函数
用户自定义聚合函数(User Defined AGGregate function,UDAGG)会把一行或多行数据 (也就是一个表)聚合成一个标量值。这是一个标准的“多对一”的转换。
工作原理:
1. 它需要创建一个累加器(accumulator),用来存储聚合的中间结果。这与 DataStream API 中的 AggregateFunction 非常类似,累加器就可以看作是一个聚合状态。调用 createAccumulator()方法可以创建一个空的累加器。
2. 对于输入的每一行数据,都会调用 accumulate()方法来更新累加器,这是聚合的核心 过程。
3. 当所有的数据都处理完之后,通过调用 getValue()方法来计算并返回最终的结果。所以,每个 AggregateFunction 都必须实现以下几个方法:
- createAccumulator():创建累加器的方法,没有输入参数,返回类型为累加器类型ACC。
- accumulate():进行聚合计算的核心方法,每来一行数据都会调用。它的第一个参数是确定的,就是 当前的累加器,类型为 ACC,表示当前聚合的中间状态;后面的参数则是聚合函数调用时传 入的参数,可以有多个,类型也可以不同。这个方法主要是更新聚合状态,所以没有返回类型。 需要注意的是,accumulate()与之前的求值方法 eval()类似,也是底层架构要求的,必须为 public, 方法名必须为 accumulate,且无法直接 override、只能手动实现。
- getValue():得到最终返回结果的方法。输入参数是 ACC 类型的累加器,输出类型为 T。
- 遇到复杂类型时,Flink的类型推导可能无法得到正确的结果,所以AggregateFunctionye可以专门对累加器和返回结果的类型进行声明。这是通过 getAccumulatorType()和 getResultType()两个方法来指定的。
示例:计算加权平均数。
```java
// 累加器类型定义
public static class WeightedAvgAccumulator {
public long sum = 0; // 加权和
public int count = 0; // 数据个数
}
// 自定义聚合函数,输出为长整型的平均值,累加器类型为 WeightedAvgAccumulator
public static class WeightedAvg extends AggregateFunction {
@Override
public WeightedAvgAccumulator createAccumulator() {
return new WeightedAvgAccumulator(); // 创建累加器
}
@Override
public Long getValue(WeightedAvgAccumulator acc) {
if (acc.count == 0) {
return null; // 防止除数为 0
} else {
return acc.sum / acc.count; // 计算平均值并返回
}
}
// 累加计算方法,每来一行数据都会调用
public void accumulate(WeightedAvgAccumulator acc, Long iValue, Integer
iWeight) {
acc.sum += iValue * iWeight;
acc.count += iWeight;
}
}
// 注册自定义聚合函数
tableEnv.createTemporarySystemFunction("WeightedAvg", WeightedAvg.class);
// 调用函数计算加权平均值
Table result = tableEnv.sqlQuery(
"SELECT student, WeightedAvg(score, weight) FROM ScoreTable GROUP BY
student"
);
```
4)表聚合函数
用户自定义表聚合函数(UDTAGG)可以把一行或多行数据(也就是一个表)聚合成另 一张表,结果表中可以有多行多列。很明显,这就像表函数和聚合函数的结合体,是一个“多 对多”的转换。
要求:
- 自定义表聚合函数需要继承抽象类 TableAggregateFunction。实现其中的三个方法。
- createAccumulator()
- accumulate()
- emitValue()
例如:Top 2
```java
// 聚合累加器的类型定义,包含最大的第一和第二两个数据
public static class Top2Accumulator {
public Integer first;
public Integer second;
}
// 自定义表聚合函数,查询一组数中最大的两个,返回值为(数值,排名)的二元组
public static class Top2 extends TableAggregateFunction,
Top2Accumulator> {
@Override
public Top2Accumulator createAccumulator() {
Top2Accumulator acc = new Top2Accumulator();
acc.first = Integer.MIN_VALUE; // 为方便比较,初始值给最小值
acc.second = Integer.MIN_VALUE;
return acc;
}
// 每来一个数据调用一次,判断是否更新累加器
public void accumulate(Top2Accumulator acc, Integer value) {
if (value > acc.first) {
acc.second = acc.first;
acc.first = value;
} else if (value > acc.second) {
acc.second = value;
}
}
// 输出(数值,排名)的二元组,输出两行数据
public void emitValue(Top2Accumulator acc, Collector>
out) {
if (acc.first != Integer.MIN_VALUE) {
out.collect(Tuple2.of(acc.first, 1));
}
if (acc.second != Integer.MIN_VALUE) {
out.collect(Tuple2.of(acc.second, 2));
}
}
}
```
目前 SQL 中没有直接使用表聚合函数的方式,所以需要使用 Table API 的方式来调用:
```java
// 注册表聚合函数函数
tableEnv.createTemporarySystemFunction("Top2", Top2.class);
// 在 Table API 中调用函数
tableEnv.from("MyTable")
.groupBy($("myField"))
.flatAggregate(call("Top2", $("value")).as("value", "rank"))
.select($("myField"), $("value"), $("rank"));
```
这里使用了 flatAggregate()方法,它就是专门用来调用表聚合函数的接口。对 MyTable 中 数据按 myField 字段进行分组聚合,统计 value 值最大的两个;并将聚合结果的两个字段重命 名为 value 和 rank,之后就可以使用 select()将它们提取出来了。
#### 10.7 SQL客户端
>SQL 客户端提供了一个命令行交互界面(CLI),我们可以在里面非 常容易地编写 SQL 进行查询,就像使用 MySQL 一样;整个 Flink 应用编写、提交的过程全变 成了写 SQL,不需要写一行 Java/Scala 代码。
使用流程如下:
1. 启动本地集群:
```shell
./bin/start-cluster.sh
```
2. 启动 Flink SQL 客户端:默认的启动模式是 embedded,也就 是说客户端是一个嵌入在本地的进程,这是目前唯一支持的模式。未来会支持连接到远程 SQL 客户端的模式。
```shell
./bin/sql-client.sh
```
3. 设置运行模式:启动客户端后,就进入了命令行界面,这时就可以开始写 SQL 了。一般我们会在开始之 前对环境做一些设置,比较重要的就是运行模式。
1. 首先是表环境的运行时模式,有流处理和批处理两个选项。默认为流处理:
```shell
Flink SQL> SET 'execution.runtime-mode' = 'streaming';
```
2. 其次是 SQL 客户端的“执行结果模式”,主要有 table、changelog、tableau 三种,默认为 table 模式:table 模式就是最普通的表处理模式,结果会以逗号分隔每个字段;changelog 则是更新日 志模式,会在数据前加上“+”(表示插入)或“-”(表示撤回)的前缀;而 tableau 则是经典 的可视化表模式,结果会是一个虚线框的表格。
```shell
Flink SQL> SET 'sql-client.execution.result-mode' = 'table';
```
4. 执行 SQL 查询
```shell
Flink SQL> CREATE TABLE EventTable(
> user STRING,
> url STRING,
> `timestamp` BIGINT
> ) WITH (
> 'connector' = 'filesystem',
> 'path' = 'events.csv',
> 'format' = 'csv'
> );
Flink SQL> CREATE TABLE ResultTable (
> user STRING,
361
> cnt BIGINT
> ) WITH (
> 'connector' = 'print'
> );
Flink SQL> INSERT INTO ResultTable SELECT user, COUNT(url) as cnt FROM EventTable
GROUP BY user
```
在 SQL 客户端中,每定义一个 SQL 查询,就会把它作为一个 Flink 作业提交到集群上执 行。所以通过这种方式,我们可以快速地对流处理程序进行开发测试。
#### 10.8 连接外部系统
在 Table API 和 SQL 编写的 Flink 程序中,可以在创建表的时候用 WITH 子句指定连接器 (connector),这样就可以连接到外部系统进行数据交互了。