# loggie
**Repository Path**: codergeek/loggie
## Basic Information
- **Project Name**: loggie
- **Description**: No description available
- **Primary Language**: Go
- **License**: Apache-2.0
- **Default Branch**: brucewang585/main
- **Homepage**: None
- **GVP Project**: No
## Statistics
- **Stars**: 0
- **Forks**: 0
- **Created**: 2025-02-13
- **Last Updated**: 2025-02-13
## Categories & Tags
**Categories**: Uncategorized
**Tags**: None
## README
 [](https://loggie-io.github.io/docs/)
[](https://bestpractices.coreinfrastructure.org/projects/569)
[](https://hub.docker.com/r/loggieio/loggie/)
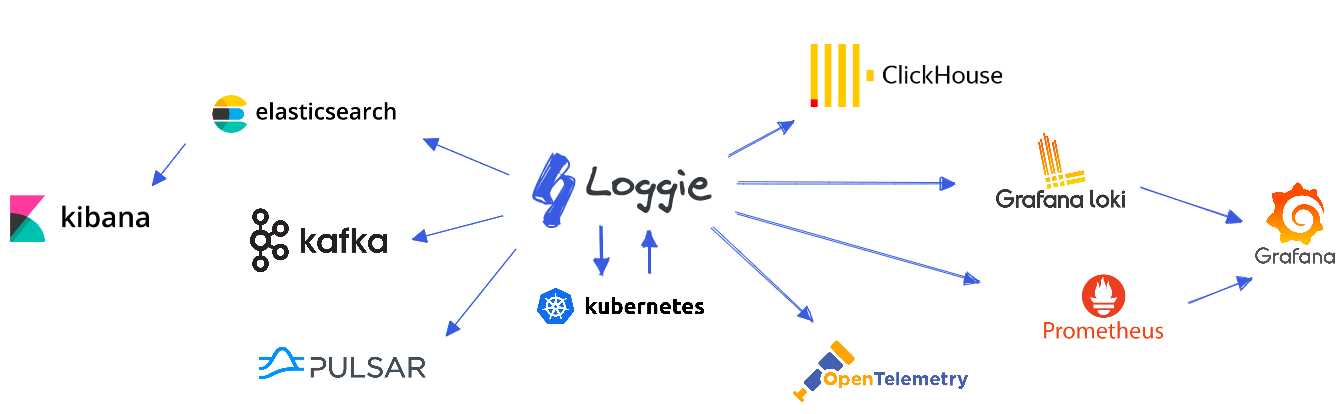
Loggie是一个基于Golang的轻量级、高性能、云原生日志采集Agent和中转处理Aggregator,支持多Pipeline和组件热插拔,提供了:
- **一栈式日志解决方案**:同时支持日志中转、过滤、解析、切分、日志报警等
- **云原生的日志形态**:快速便捷的容器日志采集方式,原生的Kubernetes CRD动态配置下发
- **生产级的特性**:基于长期的大规模运维经验,形成了全方位的可观测性、快速排障、异常预警、自动化运维能力
我们可以基于Loggie,打造一套的云原生可扩展的全链路日志数据平台。
## 特性
### 新一代的云原生日志采集和传输方式
#### 基于CRD的快速配置和使用
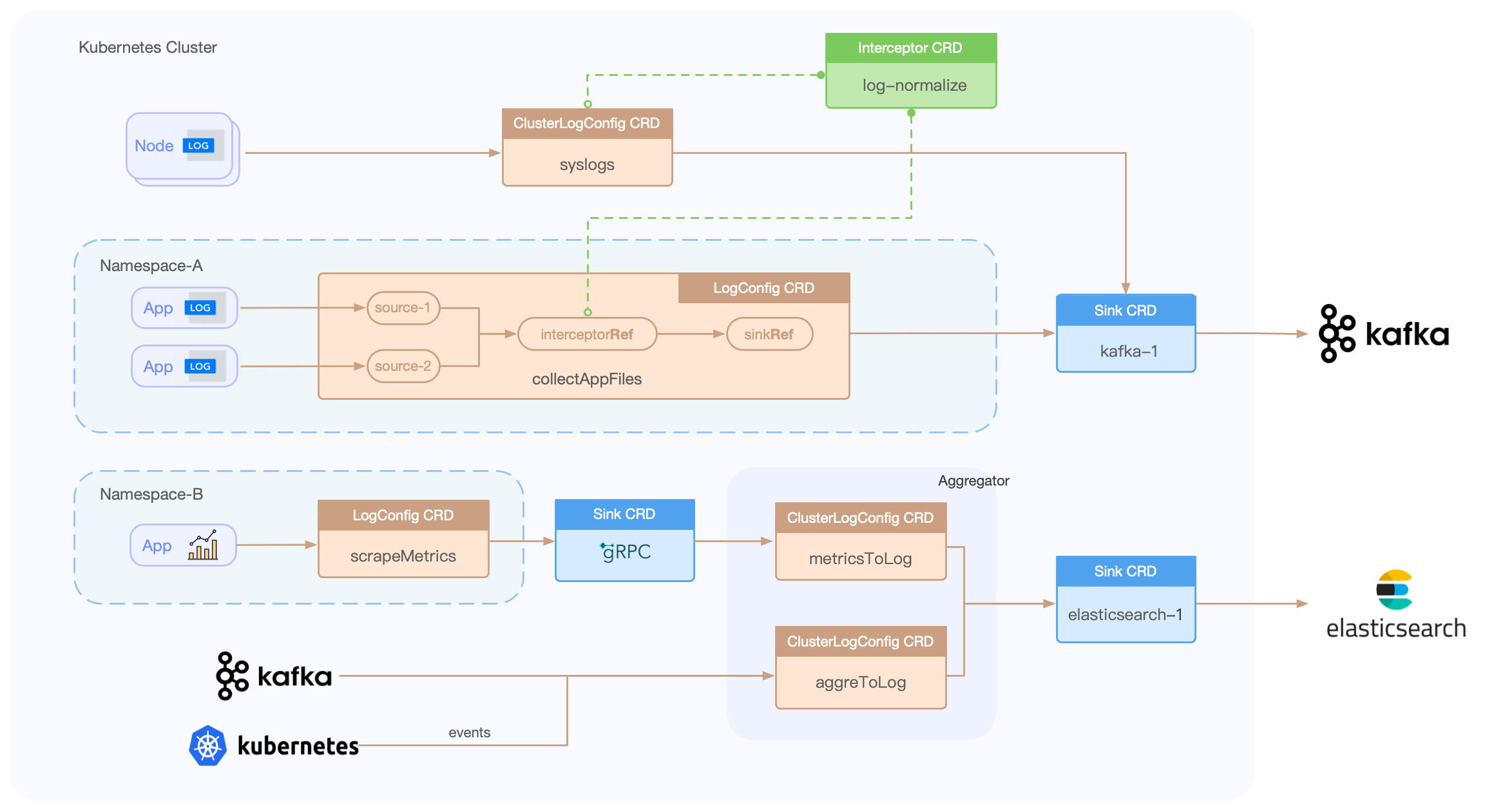
Loggie包含LogConfig/ClusterLogConfig/Interceptor/Sink CRD,只需简单的创建一些YAML文件,即可搭建一系列的数据采集、传输、处理、发送流水线。
示例:
```yaml
apiVersion: loggie.io/v1beta1
kind: LogConfig
metadata:
name: tomcat
namespace: default
spec:
selector:
type: pod
labelSelector:
app: tomcat
pipeline:
sources: |
- type: file
name: common
paths:
- stdout
- /usr/local/tomcat/logs/*.log
sinkRef: default
interceptorRef: default
```
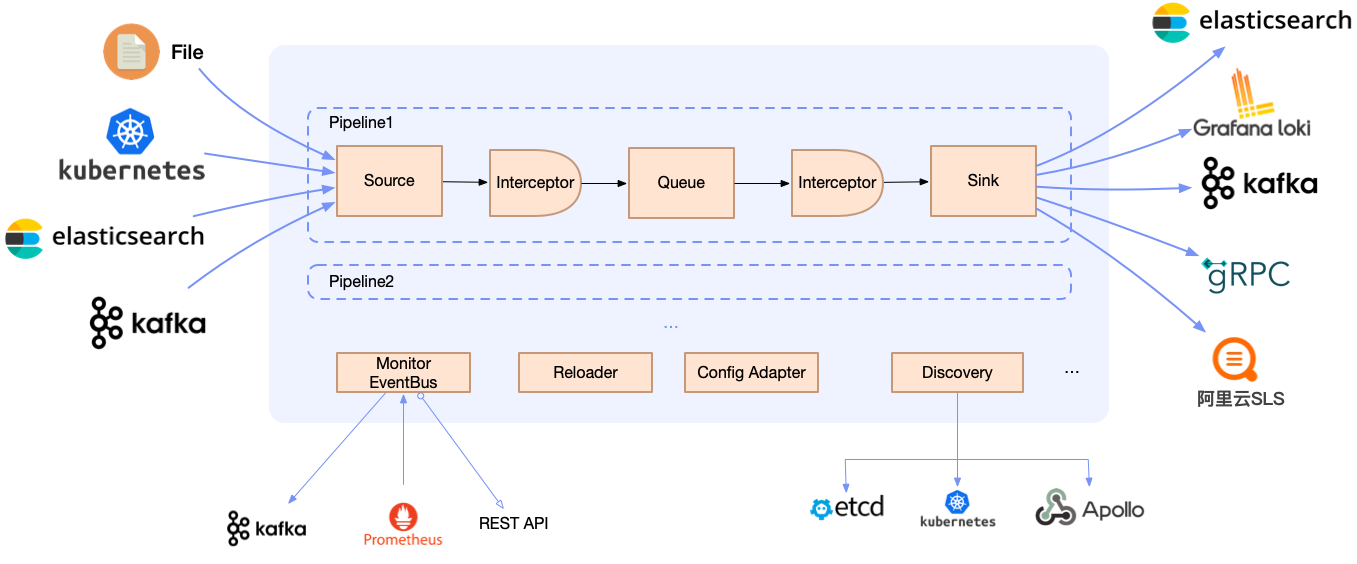
#### 支持多种部署架构
- **Agent**: 使用DaemonSet部署,无需业务容器挂载Volume即可采集日志文件
- **Sidecar**: 支持Loggie sidecar无侵入自动注入,无需手动添加到Deployment/StatefulSet部署模版
- **Aggregator**: 支持Deployment独立部署成中转机形态,可接收聚合Loggie Agent发送的数据,也可单独用于消费处理各类数据源
但不管是哪种部署架构,Loggie仍然保持着简单直观的内部设计。
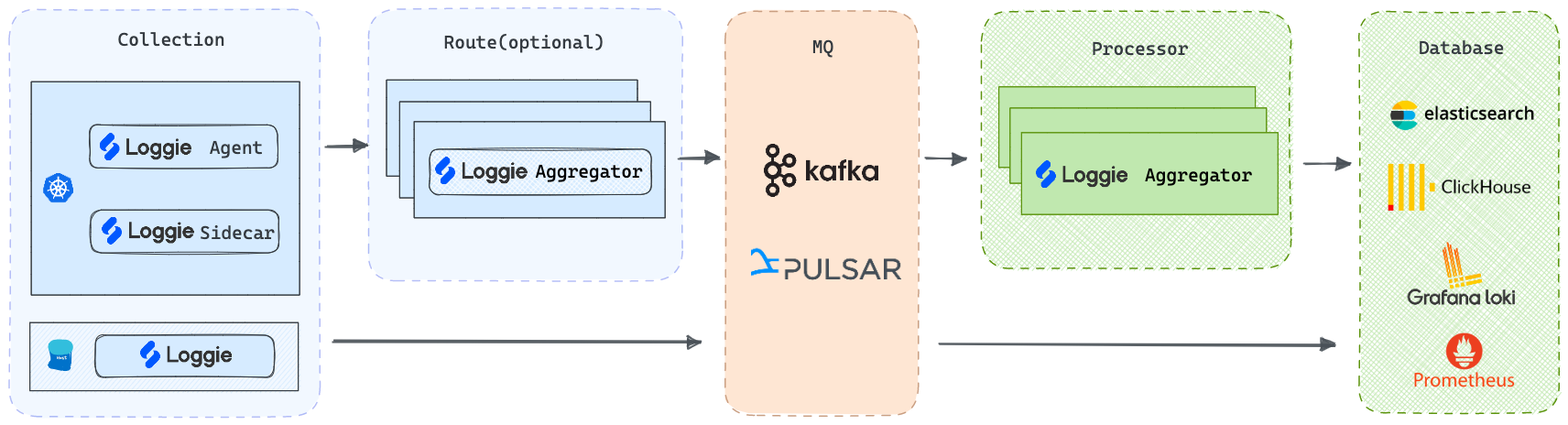
### 轻量级和高性能
#### 基准压测对比
配置Filebeat和Loggie采集日志,并发送至Kafka某个Topic,不使用客户端压缩,Kafka Topic配置Partition为3。
在保证Agent规格资源充足的情况下,修改采集的文件个数、发送客户端并发度(配置Filebeat worker和Loggie parallelism),观察各自的CPU、Memory和Pod网卡发送速率。
| Agent | 文件大小 | 日志文件数 | 发送并发度 | CPU | MEM (rss) | 网卡发包速率 |
|----------|------|-------|-------|----------|-----------|-----------|
| Filebeat | 3.2G | 1 | 3 | 7.5~8.5c | 63.8MiB | 75.9MiB/s |
| Filebeat | 3.2G | 1 | 8 | 10c | 65MiB | 70MiB/s |
| Filebeat | 3.2G | 10 | 8 | 11c | 65MiB | 80MiB/s |
| | | | | | | |
| Loggie | 3.2G | 1 | 3 | 2.1c | 60MiB | 120MiB/s |
| Loggie | 3.2G | 1 | 8 | 2.4c | 68.7MiB | 120MiB/s |
| Loggie | 3.2G | 10 | 8 | 3.5c | 70MiB | 210MiB/s |
#### 自适应sink并发度
打开sink并发度配置后,Loggie可做到:
- 根据下游数据响应的实际情况,自动调整下游数据发送并行数,尽量发挥下游服务端的性能,且不影响其性能。
- 在上游数据收集被阻塞时,适当调整下游数据发送速度,缓解上游阻塞。
### 轻量级流式数据分析与监控
日志本身是一种通用的,和平台、系统无关的数据,如何更好的利用到这些数据,是Loggie关注和主要发展的核心能力。
#### 实时解析和转换
只需配置transformer interceptor,通过配置函数式的action,即可实现:
- 各种数据格式的解析(json, grok, regex, split...)
- 各种字段的转换(add, copy, move, set, del, fmt...)
- 支持条件判断和处理逻辑(if, else, return, dropEvent, ignoreError...)
可用于:
- 日志提取出日志级别level,并且drop掉DEBUG日志
- 日志里混合包括有json和plain的日志形式,可以判断json形式的日志并且进行处理
- 根据访问日志里的status code,增加不同的topic字段
示例:
```yaml
interceptors:
- type: transformer
actions:
- action: regex(body)
pattern: (?\S+) (?\S+) (?\S+) (?
[](https://loggie-io.github.io/docs/)
[](https://bestpractices.coreinfrastructure.org/projects/569)
[](https://hub.docker.com/r/loggieio/loggie/)
Loggie是一个基于Golang的轻量级、高性能、云原生日志采集Agent和中转处理Aggregator,支持多Pipeline和组件热插拔,提供了:
- **一栈式日志解决方案**:同时支持日志中转、过滤、解析、切分、日志报警等
- **云原生的日志形态**:快速便捷的容器日志采集方式,原生的Kubernetes CRD动态配置下发
- **生产级的特性**:基于长期的大规模运维经验,形成了全方位的可观测性、快速排障、异常预警、自动化运维能力
我们可以基于Loggie,打造一套的云原生可扩展的全链路日志数据平台。

## 特性
### 新一代的云原生日志采集和传输方式
#### 基于CRD的快速配置和使用
Loggie包含LogConfig/ClusterLogConfig/Interceptor/Sink CRD,只需简单的创建一些YAML文件,即可搭建一系列的数据采集、传输、处理、发送流水线。
示例:
```yaml
apiVersion: loggie.io/v1beta1
kind: LogConfig
metadata:
name: tomcat
namespace: default
spec:
selector:
type: pod
labelSelector:
app: tomcat
pipeline:
sources: |
- type: file
name: common
paths:
- stdout
- /usr/local/tomcat/logs/*.log
sinkRef: default
interceptorRef: default
```

#### 支持多种部署架构
- **Agent**: 使用DaemonSet部署,无需业务容器挂载Volume即可采集日志文件
- **Sidecar**: 支持Loggie sidecar无侵入自动注入,无需手动添加到Deployment/StatefulSet部署模版
- **Aggregator**: 支持Deployment独立部署成中转机形态,可接收聚合Loggie Agent发送的数据,也可单独用于消费处理各类数据源
但不管是哪种部署架构,Loggie仍然保持着简单直观的内部设计。

### 轻量级和高性能
#### 基准压测对比
配置Filebeat和Loggie采集日志,并发送至Kafka某个Topic,不使用客户端压缩,Kafka Topic配置Partition为3。
在保证Agent规格资源充足的情况下,修改采集的文件个数、发送客户端并发度(配置Filebeat worker和Loggie parallelism),观察各自的CPU、Memory和Pod网卡发送速率。
| Agent | 文件大小 | 日志文件数 | 发送并发度 | CPU | MEM (rss) | 网卡发包速率 |
|----------|------|-------|-------|----------|-----------|-----------|
| Filebeat | 3.2G | 1 | 3 | 7.5~8.5c | 63.8MiB | 75.9MiB/s |
| Filebeat | 3.2G | 1 | 8 | 10c | 65MiB | 70MiB/s |
| Filebeat | 3.2G | 10 | 8 | 11c | 65MiB | 80MiB/s |
| | | | | | | |
| Loggie | 3.2G | 1 | 3 | 2.1c | 60MiB | 120MiB/s |
| Loggie | 3.2G | 1 | 8 | 2.4c | 68.7MiB | 120MiB/s |
| Loggie | 3.2G | 10 | 8 | 3.5c | 70MiB | 210MiB/s |
#### 自适应sink并发度
打开sink并发度配置后,Loggie可做到:
- 根据下游数据响应的实际情况,自动调整下游数据发送并行数,尽量发挥下游服务端的性能,且不影响其性能。
- 在上游数据收集被阻塞时,适当调整下游数据发送速度,缓解上游阻塞。
### 轻量级流式数据分析与监控
日志本身是一种通用的,和平台、系统无关的数据,如何更好的利用到这些数据,是Loggie关注和主要发展的核心能力。

#### 实时解析和转换
只需配置transformer interceptor,通过配置函数式的action,即可实现:
- 各种数据格式的解析(json, grok, regex, split...)
- 各种字段的转换(add, copy, move, set, del, fmt...)
- 支持条件判断和处理逻辑(if, else, return, dropEvent, ignoreError...)
可用于:
- 日志提取出日志级别level,并且drop掉DEBUG日志
- 日志里混合包括有json和plain的日志形式,可以判断json形式的日志并且进行处理
- 根据访问日志里的status code,增加不同的topic字段
示例:
```yaml
interceptors:
- type: transformer
actions:
- action: regex(body)
pattern: (?\S+) (?\S+) (?\S+) (?