
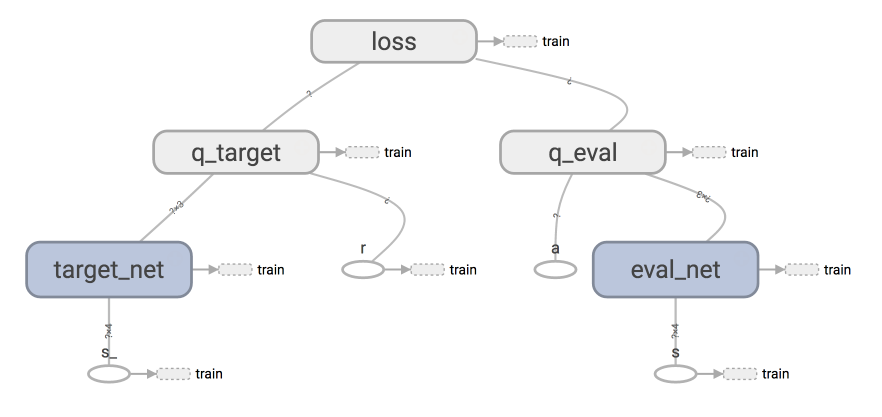
 ### [Double DQN](contents/5.1_Double_DQN)
### [Double DQN](contents/5.1_Double_DQN)
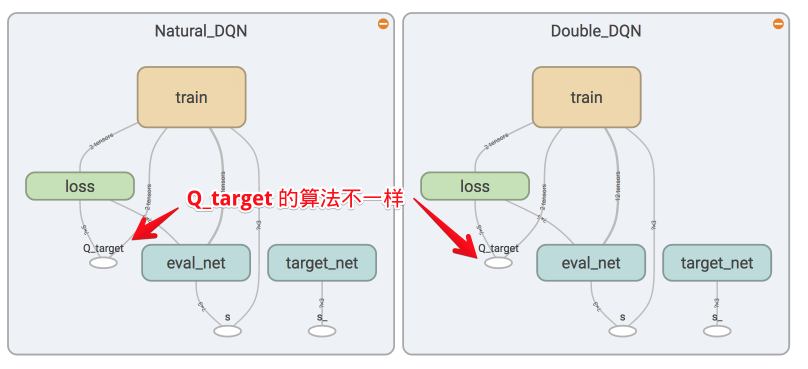 ### [Dueling DQN](contents/5.3_Dueling_DQN)
### [Dueling DQN](contents/5.3_Dueling_DQN)
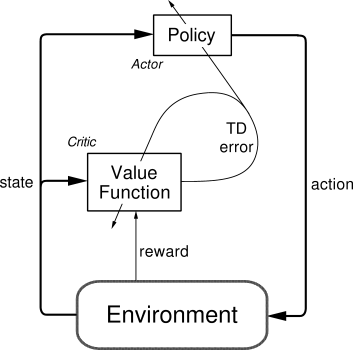
 ### [Actor Critic](contents/8_Actor_Critic_Advantage)
### [Actor Critic](contents/8_Actor_Critic_Advantage)
 ### [Deep Deterministic Policy Gradient](contents/9_Deep_Deterministic_Policy_Gradient_DDPG)
### [Deep Deterministic Policy Gradient](contents/9_Deep_Deterministic_Policy_Gradient_DDPG)
 ### [A3C](contents/10_A3C)
### [A3C](contents/10_A3C)
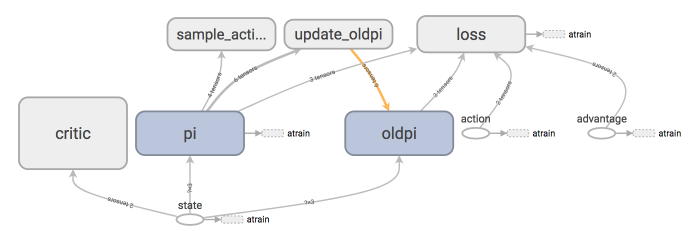
 ### [Proximal Policy Optimization (PPO)](contents/12_Proximal_Policy_Optimization)
### [Proximal Policy Optimization (PPO)](contents/12_Proximal_Policy_Optimization)
 ### [Curiosity Model](/contents/Curiosity_Model)
### [Curiosity Model](/contents/Curiosity_Model)
 # Donation
*If this does help you, please consider donating to support me for better tutorials. Any contribution is greatly appreciated!*
# Donation
*If this does help you, please consider donating to support me for better tutorials. Any contribution is greatly appreciated!*

