diff --git a/product/zh/docs-mogdb/v3.0/characteristic-description/enterprise-level-features/19-transaction-async-submit.md b/product/zh/docs-mogdb/v3.0/characteristic-description/enterprise-level-features/19-transaction-async-submit.md
new file mode 100644
index 0000000000000000000000000000000000000000..8db3ec60bcc6cb06e9ea87ac9733e12bc764091f
--- /dev/null
+++ b/product/zh/docs-mogdb/v3.0/characteristic-description/enterprise-level-features/19-transaction-async-submit.md
@@ -0,0 +1,30 @@
+---
+title: 事务异步提交
+summary: 事务异步提交
+author: Guo Huan
+date: 2022-06-13
+---
+
+# 事务异步提交
+
+## 可获得性
+
+本特性自MogDB 3.0.0版本开始引入。
+
+## 特性简介
+
+在MogDB的线程池模式下为每个线程组增加了committer线程,当事务提交过程中等待日志刷盘的时候将session挂起,交由committer线程在日志刷盘完成之后继续提交事务,而原worker线程在该session挂起之后可以去处理其他待处理的session。
+
+## 客户价值
+
+在TP场景中,对高并发下事务处理的性能有较高的需求。然而MogDB中事务提交的过程中需要同步等待日志落盘,这一期间的worker线程处于空闲状态,并不能被利用去处理其他的事务。虽然在MogDB中有“synchronous_commit=off”的实现,但该实现并不能保证数据库中途崩溃之后数据的完整性。
+
+本特性能够实现真正意义上的事务异步提交,在保证数据库可靠性的前提下更加充分利用CPU,提升高并发场景下事务处理处理能力,尤其在小查询的增删改操作上会有明显的体现。
+
+## 特性约束
+
+- 该功能仅在线程池模式下打开有效,非线程池模式下不支持事务异步提交。即设置enable_threadpool = on”和“synchronous_commit=on”。
+
+## 相关页面
+
+[GS_ASYNC_SUBMIT_SESSIONS_STATUS](GS_ASYNC_SUBMIT_SESSIONS_STATUS)、[async_submit](20-MogDB-transaction#async_submit)、[LOCAL_THREADPOOL_STATUS](LOCAL_THREADPOOL_STATUS)
\ No newline at end of file
diff --git a/product/zh/docs-mogdb/v3.0/characteristic-description/enterprise-level-features/20-copy-import-optimization.md b/product/zh/docs-mogdb/v3.0/characteristic-description/enterprise-level-features/20-copy-import-optimization.md
new file mode 100644
index 0000000000000000000000000000000000000000..1a623cc4b796095910e45414e631ac5b91d4bcc7
--- /dev/null
+++ b/product/zh/docs-mogdb/v3.0/characteristic-description/enterprise-level-features/20-copy-import-optimization.md
@@ -0,0 +1,42 @@
+---
+title: COPY导入优化
+summary: COPY导入优化
+author: Guo Huan
+date: 2022-06-16
+---
+
+# COPY导入优化
+
+## 可获得性
+
+本特性自MogDB 3.0.0版本开始引入。
+
+## 特性简介
+
+COPY是使用较多的导入用户表数据的方式,本特性通过利用现代CPU的SIMD特性来提升COPY在解析阶段的性能,从而提升COPY的性能,提升导入的速度。
+
+COPY从文件中导入数据的时候在解析阶段查找分隔符以及在判断CSV/TEXT解析出的数据是否合法的时候,理论上都是字符串比较操作,可以利用SIMD特性将现有一次一个字符比较转换成一次比较多个字符,从而减少分支判断次数提升性能。
+
+## 客户价值
+
+利用SIMD指令针对COPY解析过程中的分隔符查找以及数据合法性检查等操作做优化。本特性的最终用户为普通客户群体,如数据库DBA,软件开发人员等。COPY性能提升为10%-30%。
+
+## 特性约束
+
+因为该字符串比较指令值是SSE4.2才开始支持,所以只有支持SSE4.2的X86才可以使用该优化。
+
+可以使用如下命令来判断机器是否支持SSE4.2指令集:
+
+```shell
+grep -q sse4_2 /proc/cpuinfo && echo "SSE 4.2 supported" || echo "SSE 4.2 not supported"
+```
+
+提供config编译参数”--disable-sse42”来决定是否显示关闭该功能,默认会在脚本里面检查编译的机器是否支持sse42指令集,如果支持且没有显示--disable-sse42则默认打开该功能。
+
+在支持该指令集的机器上编译出来的安装包需要在不支持该指令集的机器上正常安装启动。
+
+加一个全局变量,初始化的时候对全局变量赋值,检查机器是否支持SSE4.2指令集,在所有使用指令集的代码前加判断,判断该变量是否为真。
+
+## 相关页面
+
+[COPY](COPY)
\ No newline at end of file
diff --git a/product/zh/docs-mogdb/v3.0/characteristic-description/enterprise-level-features/21-dynamic-partition-pruning.md b/product/zh/docs-mogdb/v3.0/characteristic-description/enterprise-level-features/21-dynamic-partition-pruning.md
new file mode 100644
index 0000000000000000000000000000000000000000..3bb72f88b8925a2101700ca79d8781fdee9c83db
--- /dev/null
+++ b/product/zh/docs-mogdb/v3.0/characteristic-description/enterprise-level-features/21-dynamic-partition-pruning.md
@@ -0,0 +1,32 @@
+---
+title: 动态分区裁剪
+summary: 动态分区裁剪
+author: Guo Huan
+date: 2022-06-17
+---
+
+# 动态分区裁剪
+
+## 可获得性
+
+本特性自MogDB 3.0.0版本开始引入。
+
+## 特性简介
+
+本特性主要实现如下几个目标:
+
+1. 重构现有的分区裁剪功能,主要涉及在优化器上静态分区裁剪。
+
+2. 实现在执行器进行动态分区裁剪,主要涉及在执行器的init阶段和runing阶段。
+
+3. 支持NESTLOOP进行分区裁剪。
+
+4. 支持通过EXPLAIN ANALYZE查看动态分区裁剪结果。
+
+## 客户价值
+
+本特性主要对分区裁剪特性进行加固,主要涉及对当前支持的静态裁剪进行重构,引入动态分区裁剪,同时支持通过EXPLAIN ANALYZE查看分区裁剪结果。符合动态分区裁剪要求的场景,在SQL执行阶段裁剪掉不需要的分区,再扫描分区表,从而提升分区表的查询性能。
+
+## 相关页面
+
+[静态分区裁剪](static-partition-pruning)、[动态分区裁剪](dynamic-partition-pruning)
\ No newline at end of file
diff --git a/product/zh/docs-mogdb/v3.0/characteristic-description/enterprise-level-features/22-sql-running-status-observation.md b/product/zh/docs-mogdb/v3.0/characteristic-description/enterprise-level-features/22-sql-running-status-observation.md
new file mode 100644
index 0000000000000000000000000000000000000000..2e19edec034c882a35685c71f1f46228dae9dd67
--- /dev/null
+++ b/product/zh/docs-mogdb/v3.0/characteristic-description/enterprise-level-features/22-sql-running-status-observation.md
@@ -0,0 +1,93 @@
+---
+title: SQL运行状态观测
+summary: SQL运行状态观测
+author: Guo Huan
+date: 2022-06-17
+---
+
+# SQL运行状态观测
+
+## 可获得性
+
+本特性自MogDB 3.0.0版本开始引入。
+
+## 特性简介
+
+本特性支持在现有采样框架中对执行算子plan_node_id的采样。
+
+## 客户价值
+
+本特性的最终用户为普通客户群体,如数据库DBA,软件开发人员等。DBA或者研发可以在现有采样框架中查询到算子的采样情况。
+
+## 特性描述
+
+在现有采样框架中添加对执行算子plan_node_id的采样,即在[dbe_perf.local_active_session](LOCAL_ACTIVE_SESSION)和[GS_ASP](GS_ASP)中新增一列plan_node_id来记录算子的采样情况。
+
+现有采样框架的监控级别由guc参数[resource_track_level](13-load-management#resource_track_level)控制,该参数按照级别存在三个值,none表示不开启资源记录功能;query表示开启query级别资源记录功能;operator表示开启query级别和算子级别资源记录功能,所以只有当将resource_track_level设成operator的时候才会对算子进行采样。
+
+MogDB启动后会启动一个后台worker采样线程,该采样线程不会时刻对MogDB进行采样,时刻采样没必要且浪费资源,所以该worker线程会每隔一个采样周期对MogDB进行采样,收集MogDB当时的运行快照保存到内存中,查询视图dbe_perf.local_active_session可以查询到实时的采样信息,该采样周期由guc参数[asp_sample_interval](27-system-performance-snapshot#asp_sample_interval)控制,默认采样周期为1s,MogDB会每在内存中采样100000行(由guc参数[asp_sample_num](27-system-performance-snapshot#asp_sample_num)控制)就将内存中的采样数据刷新到GS_ASP表中以供历史查询,所以只有语句执行时间大于采样时间,才会被采样线程收集到运行信息。
+
+## 使用场景
+
+1. 首先在session1中创建表test,并执行插入操作:
+
+ ```sql
+ MogDB=# create table test(c1 int);
+ CREATE TABLE
+ MogDB=# insert into test select generate_series(1, 100000000000);
+ ```
+
+2. 在session2中,从活跃会话视图中查询出该SQL的query_id
+
+ ```sql
+ MogDB=# select query,query_id from pg_stat_activity where query like 'insert into test select%';
+ query | query_id
+ -----------------------------------------------------------+-----------------
+ insert into test select generate_series(1, 100000000000); | 562949953421368
+ (1 row)
+ ```
+
+3. 在session2中,根据该query_id从活跃作业管理视图中查询出该语句的带plan_node_id的执行计划(该语句执行cost需要大于guc值**resource_track_cost**才会被记录到该视图中,该guc参数默认值为100000,session级别可更新,所以为了方便测试,可在测试中将该值改成10)
+
+ ```sql
+ MogDB=# select query_plan from dbe_perf.statement_complex_runtime where queryid = 562949953421368;
+ query_plan
+ ----------------------------------------------------------------------------
+ Coordinator Name: datanode1 +
+ 1 | Insert on test (cost=0.00..17.51 rows=1000 width=8) +
+ 2 | -> Subquery Scan on "*SELECT*" (cost=0.00..17.51 rows=1000 width=8) +
+ 3 | -> Result (cost=0.00..5.01 rows=1000 width=0) +
+ +
+ (1 row)
+ ```
+
+4. 在session2中,根据query_id从采样视图dbe_perf.local_active_session中查询出该语句的采样情况,结合上面查询的执行计划做性能分析。
+
+ ```sql
+ MogDB=# select plan_node_id, count(plan_node_id) from dbe_perf.local_active_session where query_id = 562949953421368 group by plan_node_id;
+ plan_node_id | count
+ --------------+-------
+ 3 | 12
+ 1 | 366
+ 2 | 2
+ (3 rows)
+ ```
+
+ 采样出的plan_node_id与(3)中查询出的query_plan的plan_node_id做对应,也就是这里每行数据的plan_node_id可能为(3)的1,2,3中的一个,采样线程默认每隔1s对执行中的语句做采样,采样的时候正在执行哪个算子就会把该算子对应的plan_node_id数字记录到该行中。
+
+5. 在session2中执行,当内存数据到达上限值(由guc参数**asp_sample_num**控制)的时候,则会将现有内存的采样数据刷新到gs_asp表中,刷盘后查询gs_asp表也会查到该语句的算子采样的数据。
+
+ ```sql
+ MogDB=# select plan_node_id, count(plan_node_id) from gs_asp where query_id = 562949953421368 group by plan_node_id;
+ plan_node_id | count
+ --------------+-------
+ 3 | 19
+ 1 | 582
+ 2 | 3
+
+ (3 rows)
+ ```
+
+## 相关页面
+
+[GS_ASP](GS_ASP)、[LOCAL_ACTIVE_SESSION](LOCAL_ACTIVE_SESSION)
\ No newline at end of file
diff --git a/product/zh/docs-mogdb/v3.0/characteristic-description/enterprise-level-features/23-index-creation-parallel-control.md b/product/zh/docs-mogdb/v3.0/characteristic-description/enterprise-level-features/23-index-creation-parallel-control.md
new file mode 100644
index 0000000000000000000000000000000000000000..47395c23e33e21dcb722f68691b6bb07c809f97e
--- /dev/null
+++ b/product/zh/docs-mogdb/v3.0/characteristic-description/enterprise-level-features/23-index-creation-parallel-control.md
@@ -0,0 +1,28 @@
+---
+title: 索引创建并行控制
+summary: 索引创建并行控制
+author: Guo Huan
+date: 2022-06-17
+---
+
+# 索引创建并行控制
+
+## 可获得性
+
+本特性自MogDB 3.0.0版本开始引入。
+
+## 特性简介
+
+本特性支持直接在索引创建语句中指定并行度,更加有效地利用资源,同时提高使用灵活性。
+
+## 客户价值
+
+本特性在创建索引的语法中增加指定并行度的选项,便于DBA及交付测试人员从语法层面实现对索引创建并发度的控制,达到最优执行效果。
+
+## 特性描述
+
+在进行索引创建的时候增加parallel语法,来控制索引创建的并行度。
+
+## 相关页面
+
+[CREATE INDEX](CREATE-INDEX)
\ No newline at end of file
diff --git a/product/zh/docs-mogdb/v3.0/developer-guide/partition-management/partition-pruning/benefits-of-partition-pruning.md b/product/zh/docs-mogdb/v3.0/developer-guide/partition-management/partition-pruning/benefits-of-partition-pruning.md
new file mode 100644
index 0000000000000000000000000000000000000000..22d6d1c219797f296982463a0b653f0857dc0133
--- /dev/null
+++ b/product/zh/docs-mogdb/v3.0/developer-guide/partition-management/partition-pruning/benefits-of-partition-pruning.md
@@ -0,0 +1,22 @@
+---
+title: 分区裁剪的好处
+summary: 分区裁剪的好处
+author: Guo Huan
+date: 2022-06-14
+---
+
+# 分区裁剪的好处
+
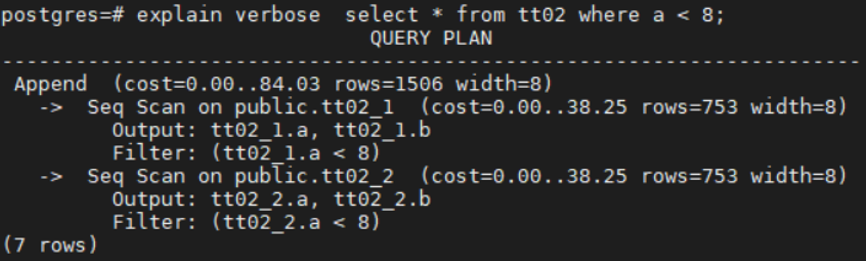
+分区裁剪是分区表中常用的性能优化手段。在扫描分区表前,如果能通过检查分区约束条件与每个分区的定义,提前排除不需要扫描的分区,可以极大地提升扫描性能。在查询规划阶段,如果分区约束为确定的表达式,在查询规划阶段就可以根据分区约束表达式裁掉不需要扫描的分区,这种分区裁剪方式一般称为**静态分区裁剪**。静态裁剪从EXPLAIN VERBOSE输出就可以看出裁剪结果,如下图1所示。
+
+
+
+***图 1** 静态裁剪结果*
+
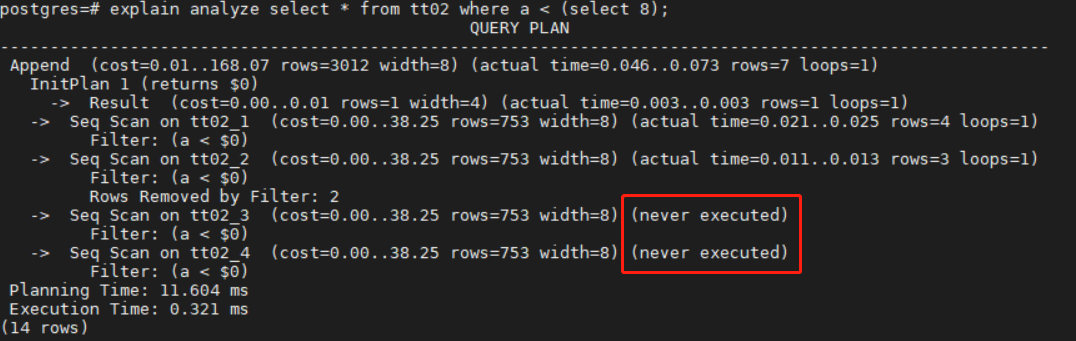
+但是在很多场景下,例如PREPARE-EXECUTE执行方式和分区约束表达式中包含子查询的场景在查询规划阶段,分区约束表达式是不确定的或包含未知的参数,查询规划阶段是不能裁剪的,只能在执行阶段,通过外部参数和子查询的结果确定分区表达式后进行裁剪,通常将在执行器上做的裁剪称为**动态分区裁剪**。动态裁剪从查询计划是看不到裁剪结果的,但可以通过EXPLAIN ANALYZE查询执行过程中未被扫描的分区,如下图2所示。
+
+
+
+***图 2** 动态裁剪后的实际执行计划*
+
+MogDB自3.0版本后引入了分区表的动态裁剪,大大减少了从磁盘检索的数据量并缩短了处理时间,从而提高查询性能并优化资源利用率。
diff --git a/product/zh/docs-mogdb/v3.0/developer-guide/partition-management/partition-pruning/dynamic-partition-pruning.md b/product/zh/docs-mogdb/v3.0/developer-guide/partition-management/partition-pruning/dynamic-partition-pruning.md
new file mode 100644
index 0000000000000000000000000000000000000000..16b7013fbe0c4a30eb4e1ab9f2b8e65251d4b5d8
--- /dev/null
+++ b/product/zh/docs-mogdb/v3.0/developer-guide/partition-management/partition-pruning/dynamic-partition-pruning.md
@@ -0,0 +1,54 @@
+---
+title: 动态分区裁剪
+summary: 动态分区裁剪
+author: Guo Huan
+date: 2022-06-14
+---
+
+# 动态分区裁剪
+
+动态分区裁剪要求分区表达式一侧为分区键,另一侧为表达式,该表达式包含如下三种类型。
+
+1. 表达式类型为外部参数,一般为Prepare-Execute执行方式。
+
+2. 表达式类型为内部参数,一般为子查询。
+
+3. NestLoop参数化查询,即查询计划为NestLoop + indexScan查询方式,要求分区表的分区键为两个表的连接键,同时分区键上创建有索引。
+
+以下为动态分区裁剪的案例。
+
+```sql
+drop table if exists prune_tt01;
+CREATE TABLE prune_tt01(a int, b int)
+PARTITION BY RANGE(a)
+(
+ PARTITION prune_tt01_p1 VALUES LESS THAN(5),
+ PARTITION prune_tt01_p2 VALUES LESS THAN(10),
+ PARTITION prune_tt01_p3 VALUES LESS THAN(15),
+ PARTITION prune_tt01_p4 VALUES LESS THAN(MAXVALUE)
+);
+INSERT INTO prune_tt01 VALUES (generate_series(1, 20), generate_series(1,20));
+CREATE INDEX index_prune_tt01 ON prune_tt01 USING btree(a) LOCAL;
+
+drop table if exists tt02;
+create table tt02(a int, b int);
+INSERT INTO tt02 VALUES (generate_series(1, 20), generate_series(1,20));
+
+
+--prepare-execute场景:
+prepare ps(int) as select * from prune_tt01 where a > $1;
+explain verbose execute ps(12);
+explain analyze execute ps(12);
+
+
+--子查询场景:
+explain verbose select * from prune_tt01 where a > (select 12);
+explain analyze select * from prune_tt01 where a > (select 12);
+
+--nestloop参数化路径:
+SET enable_material = OFF;
+SET enable_mergejoin = OFF;
+SET enable_hashjoin = OFF;
+explain verbose select * from prune_tt01 inner join tt02 on prune_tt01.a = tt02.a;
+explain analyze select * from prune_tt01 inner join tt02 on prune_tt01.a = tt02.a;
+```
\ No newline at end of file
diff --git a/product/zh/docs-mogdb/v3.0/developer-guide/partition-management/partition-pruning/information-that-can-be-used-for-partition-pruning.md b/product/zh/docs-mogdb/v3.0/developer-guide/partition-management/partition-pruning/information-that-can-be-used-for-partition-pruning.md
new file mode 100644
index 0000000000000000000000000000000000000000..61c81ad6b6fc1915b0e5c1d95a846630a32150c1
--- /dev/null
+++ b/product/zh/docs-mogdb/v3.0/developer-guide/partition-management/partition-pruning/information-that-can-be-used-for-partition-pruning.md
@@ -0,0 +1,46 @@
+---
+title: 可用于分区裁剪的信息
+summary: 可用于分区裁剪的信息
+author: Guo Huan
+date: 2022-06-14
+---
+
+# 可用于分区裁剪的信息
+
+可以对分区列执行分区裁剪。
+
+当您在范围或列表分区列上使用范围、`LIKE`、等式和`IN`列表谓词,以及在哈希分区列上使用等式和`IN`列表谓词时,MogDB会裁剪分区。
+
+对于复合分区对象,MogDB可以使用相关谓词在两个层次上进行裁剪。例如示例1中,表sales_range_hash在列s_saledate上按范围分区,对列s_productid使用哈希子分区。
+
+MogDB使用分区列上的谓词来执行分区裁剪,如下所示。
+
+- 当使用范围分区时,MogDB只访问分区sal99q2和sal99q3,代表1999年第三季度和第四季度的分区。
+
+- 当使用哈希子分区时,MogDB只访问每个分区中存储有`s_productid=1200`的行的一个子分区。子分区和谓词之间的映射是根据MogDB的内部哈希分布函数计算出来的。
+
+引用分区表可以通过与引用表的连接来充分利用分区裁剪带来的好处。基于虚拟列的分区表受益于在SQL语句中使用虚拟列定义表达式的语句的分区裁剪。
+
+**示例1 创建带有分区裁剪的表**
+
+```sql
+CREATE TABLE sales_range_hash(
+ s_productid NUMBER,
+ s_saledate DATE,
+ s_custid NUMBER,
+ s_totalprice NUMBER)
+PARTITION BY RANGE (s_saledate)
+SUBPARTITION BY HASH (s_productid) SUBPARTITIONS 8
+ (PARTITION sal99q1 VALUES LESS THAN
+ (TO_DATE('01-APR-1999', 'DD-MON-YYYY')),
+ PARTITION sal99q2 VALUES LESS THAN
+ (TO_DATE('01-JUL-1999', 'DD-MON-YYYY')),
+ PARTITION sal99q3 VALUES LESS THAN
+ (TO_DATE('01-OCT-1999', 'DD-MON-YYYY')),
+ PARTITION sal99q4 VALUES LESS THAN
+ (TO_DATE('01-JAN-2000', 'DD-MON-YYYY')));
+
+SELECT * FROM sales_range_hash
+WHERE s_saledate BETWEEN (TO_DATE('01-JUL-1999', 'DD-MON-YYYY'))
+ AND (TO_DATE('01-OCT-1999', 'DD-MON-YYYY')) AND s_productid = 1200;
+```
diff --git a/product/zh/docs-mogdb/v3.0/developer-guide/partition-management/partition-pruning/static-partition-pruning.md b/product/zh/docs-mogdb/v3.0/developer-guide/partition-management/partition-pruning/static-partition-pruning.md
new file mode 100644
index 0000000000000000000000000000000000000000..371b05192ec06f7e6c1415d8661ac64da980a9d1
--- /dev/null
+++ b/product/zh/docs-mogdb/v3.0/developer-guide/partition-management/partition-pruning/static-partition-pruning.md
@@ -0,0 +1,39 @@
+---
+title: 静态分区裁剪
+summary: 静态分区裁剪
+author: Guo Huan
+date: 2022-06-14
+---
+
+# 静态分区裁剪
+
+MogDB主要根据静态谓词确定何时使用静态裁剪。
+
+一般情况下,MogDB会在查询规划阶段确定要访问的分区。如果您使用静态谓词,则会使用静态分区裁剪,但以下情况除外:
+
+- 表达式类型为外部参数,一般为Prepare-Execute执行方式。
+- 表达式类型为内部参数,一般为子查询。
+- NestLoop参数化查询。
+
+这三种情况会使用动态裁剪。
+
+如果在解析时MogDB可以识别访问了哪个连续的分区集合,则执行计划中的`PSTART`和`PSTOP`列显示正在访问的分区的开始值和结束值。对于任何其他分区裁剪情况(包括动态裁剪),MogDB都会显示`PSTART`和`PSTOP`的KEY值(可选择显示其他属性)。
+
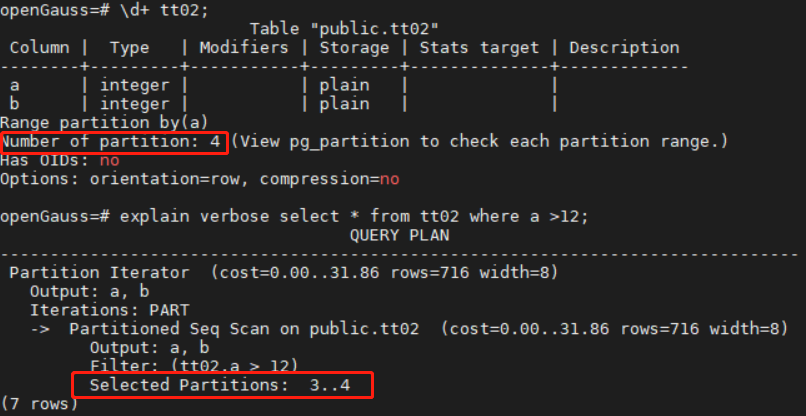
+静态分区裁剪可通过[EXPLAIN VERBOSE](EXPLAIN)语句查看执行计划。如下示例查询中,tt02表有四个分区,查询计划中显示SeqScan支持扫描的分区为3和4,从而确定分区1和2已经在查询计划中裁剪掉。
+
+
+
+
+
+静态分区裁剪的详细支持范围如下表所示。
+
+**表1** 静态分区裁剪的详细支持范围
+
+| 序号 | 约束名称 | 约束范围 |
+| ---- | ---------------- | ------------------------------------------------------------ |
+| 1 | 分区表类型 | Range分区、List分区、Hash分区 |
+| 2 | 分区表达式类型 | - 分区约束为单个表达式,如`a >12;`
- 分区约束为BOOL表达式,如`a > 2 and a < 12;`
- 分区约束为数组,如`a in (2, 3);`
- 分区约束为常量表达式,如`1 = 1;` |
+| 3 | 分区表达式操作符 | - Range分区表支持:`=`、`>`、`>=`、`<`、`<=`五种操作符
- List分区和Hash分区只支持`=`操作符 |
+| 4 | 分区表达式参数 | 一侧为分区键,另一侧为常量,例如:`a > 12` |
+| 5 | 二级分区 | Range、List和Hash三种分区表的组合,例如:Range-List等等 |
+| 6 | 分区裁剪结果显示 | Explain verbose显示裁剪分区链表 |
diff --git a/product/zh/docs-mogdb/v3.0/developer-guide/partition-management/recommendations-for-choosing-a-partitioning-strategy/when-to-use-hash-partitioning.md b/product/zh/docs-mogdb/v3.0/developer-guide/partition-management/recommendations-for-choosing-a-partitioning-strategy/when-to-use-hash-partitioning.md
new file mode 100644
index 0000000000000000000000000000000000000000..6c6f81075019284d4d24ed06f56aa84d6283b8ce
--- /dev/null
+++ b/product/zh/docs-mogdb/v3.0/developer-guide/partition-management/recommendations-for-choosing-a-partitioning-strategy/when-to-use-hash-partitioning.md
@@ -0,0 +1,41 @@
+---
+title: 何时使用哈希分区
+summary: 何时使用哈希分区
+author: Guo Huan
+date: 2022-06-14
+---
+
+# 何时使用哈希分区
+
+哈希分区对于基于哈希算法在分区之间随机分布数据,而不是对相似数据进行分组很有用。
+
+在有些情况下,虽然可以确定分区关键字,但分区数据应该位于哪个分区并不明显。有些情况则不希望像范围分区那样对相似数据进行分组,而是希望数据的分布与其业务或逻辑视图不一致。哈希分区根据将关键字传递给哈希算法的结果,将某一行放入某个分区中。
+
+使用这种方法,数据在分区中随机分布而非分组。这对于某些数据来说是一种很好的方法,但可能不适用于管理历史数据。然而,哈希分区与范围分区具有一些相同的性能特征。例如,分区裁剪仅限于等式谓词。您还可以使用分区连接、并行索引访问和并行DML。
+
+哈希分区的优点是,数据的分布几乎是随机的,所以分布相对均匀,能够在一定程度上避免热点问题。
+
+哈希分区的缺点是:
+
+- 在不额外存储数据的情况下,无法执行范围查询。
+- 在添加或删除节点时,由于每个节点都需要一个相应的哈希值,所以增加节点需要修改哈希函数,这会导致许多现有的数据都要重新映射,引起数据大规模移动。并且在此期间,系统可能无法继续工作。
+
+示例1使用列`s_productid`作为分区关键字为表`sales_hash`创建了四个哈希分区。与products表的并行连接可以利用部分或完全分区连接。此时分区裁剪有利于仅访问单个产品或一部分产品的销售数据的查询。
+
+如果您没有明确指定分区名称,而是指定哈希分区的编号,那么MogDB会自动为分区生成内部名称。此外,您可以使用`STORE` `IN`子句以循环方式将哈希分区分配给表空间。
+
+**示例1 创建具有哈希分区的表**
+
+```sql
+CREATE TABLE sales_hash
+ (s_productid NUMBER,
+ s_saledate DATE,
+ s_custid NUMBER,
+ s_totalprice NUMBER)
+PARTITION BY HASH(s_productid)
+( PARTITION p1 TABLESPACE tbs1
+, PARTITION p2 TABLESPACE tbs2
+, PARTITION p3 TABLESPACE tbs3
+, PARTITION p4 TABLESPACE tbs4
+);
+```
\ No newline at end of file
diff --git a/product/zh/docs-mogdb/v3.0/developer-guide/partition-management/recommendations-for-choosing-a-partitioning-strategy/when-to-use-list-partitioning.md b/product/zh/docs-mogdb/v3.0/developer-guide/partition-management/recommendations-for-choosing-a-partitioning-strategy/when-to-use-list-partitioning.md
new file mode 100644
index 0000000000000000000000000000000000000000..b52464b4780fbcfe7c8b4838caa75fa38163566f
--- /dev/null
+++ b/product/zh/docs-mogdb/v3.0/developer-guide/partition-management/recommendations-for-choosing-a-partitioning-strategy/when-to-use-list-partitioning.md
@@ -0,0 +1,33 @@
+---
+title: 何时使用列表分区
+summary: 何时使用列表分区
+author: Guo Huan
+date: 2022-06-14
+---
+
+# 何时使用列表分区
+
+列表分区可基于离散值将行显式映射到分区。
+
+在示例1中,俄勒冈州和华盛顿州的所有客户都存储在一个分区中,而其他州的客户则存储在不同的分区中。按区域分析帐户的客户经理可有效利用分区裁剪。
+
+**示例1 创建具有列表分区的表**
+
+```sql
+CREATE TABLE accounts
+( id NUMBER
+, account_number NUMBER
+, customer_id NUMBER
+, branch_id NUMBER
+, region VARCHAR(2)
+, status VARCHAR2(1)
+)
+PARTITION BY LIST (region)
+( PARTITION p_northwest VALUES ('OR', 'WA')
+, PARTITION p_southwest VALUES ('AZ', 'UT', 'NM')
+, PARTITION p_northeast VALUES ('NY', 'VM', 'NJ')
+, PARTITION p_southeast VALUES ('FL', 'GA')
+, PARTITION p_northcentral VALUES ('SD', 'WI')
+, PARTITION p_southcentral VALUES ('OK', 'TX')
+);
+```
\ No newline at end of file
diff --git a/product/zh/docs-mogdb/v3.0/developer-guide/partition-management/recommendations-for-choosing-a-partitioning-strategy/when-to-use-range-or-interval-partitioning.md b/product/zh/docs-mogdb/v3.0/developer-guide/partition-management/recommendations-for-choosing-a-partitioning-strategy/when-to-use-range-or-interval-partitioning.md
new file mode 100644
index 0000000000000000000000000000000000000000..7819621588628389caa9dc9be82753db9f98aeb2
--- /dev/null
+++ b/product/zh/docs-mogdb/v3.0/developer-guide/partition-management/recommendations-for-choosing-a-partitioning-strategy/when-to-use-range-or-interval-partitioning.md
@@ -0,0 +1,48 @@
+---
+title: 何时使用范围或间隔分区
+summary: 何时使用范围或间隔分区
+author: Guo Huan
+date: 2022-06-14
+---
+
+# 何时使用范围或间隔分区
+
+范围分区和间隔分区在组织类似的数据时很有用,尤其是日期和时间数据。
+
+范围分区是一种方便的历史数据分区方法。范围分区的边界定义了表或索引中分区的顺序。
+
+间隔分区是范围分区的拓展,当超出某个临界点时,分区由间隔定义。将数据插入分区时,数据库会自动创建间隔分区。
+
+范围或间隔分区通常用于对类型为`DATE`的列按时间间隔组织数据。因此,大多数访问范围分区的SQL语句都关注时间范围。例如类似于“从特定时间段选择数据”的SQL语句。在这种情况下,如果每个分区代表一个月内的数据,则“查找2006年12月的数据”这一查询必须仅访问2006年12月的分区。这可以将扫描的数据量减少为总数据的一小部分,这种优化方法称为**分区裁剪**。
+
+当您需要定期加载新数据并清除旧数据时,范围分区也很有用,因为范围分区很容易添加或删除。例如,系统通常会保留一个滚动的数据窗口,将过去36个月的数据保持为在线状态。范围分区简化了这个过程。要添加新月份的数据时,将其加载到一张单独的表中,对其进行清理、索引,然后使用`EXCHANGE` `PARTITION`语句将其添加到范围分区表中,同时原始表保持在线状态。添加新分区后,您可以使用`DROP` `PARTITION`语句删除其后的月份。除了使用`DROP PARTITION`语句外,还可以将分区归档并将其设置为只读,但这只有在分区位于不同的表空间时才有效。您还可以使用插入分区表的方式来实现滚动数据窗口。
+
+间隔分区提供了一种在写入数据时自动创建间隔分区的简单方法。间隔分区也可用于所有其他分区维护操作。
+
+总之,在以下情况下您可以考虑使用范围或间隔分区:
+
+- 经常需要对大型表中容易分区的列进行范围谓词扫描,例如`ORDER_DATE`或`PURCHASE_DATE`。在该列上对表进行分区可启用分区裁剪。
+- 希望维护一个滚动的数据窗口。
+- 无法在指定时间范围内对大型表完成管理操作,例如备份和还原,但可以根据分区范围列将其分成更小的逻辑块。
+
+示例1创建了`salestable`表用于存储2005年和2006年的数据,并根据列`s_salesdate`按范围分区,将数据分成8个季度,每个季度对应一个分区。未来的分区将通过月份间隔定义自动创建。间隔分区以循环方式在提供的表空间列表中创建。分区裁剪有利于针对较短的时间间隔分析销售数据。销售表还支持滚动窗口方法。
+
+**示例1 创建具有范围和间隔分区的表**
+
+```sql
+CREATE TABLE salestable
+ (s_productid NUMBER,
+ s_saledate DATE,
+ s_custid NUMBER,
+ s_totalprice NUMBER)
+PARTITION BY RANGE(s_saledate)
+INTERVAL(NUMTOYMINTERVAL(1,'MONTH')) STORE IN (tbs1,tbs2,tbs3,tbs4)
+ (PARTITION sal05q1 VALUES LESS THAN (TO_DATE('01-APR-2005', 'DD-MON-YYYY')) TABLESPACE tbs1,
+ PARTITION sal05q2 VALUES LESS THAN (TO_DATE('01-JUL-2005', 'DD-MON-YYYY')) TABLESPACE tbs2,
+ PARTITION sal05q3 VALUES LESS THAN (TO_DATE('01-OCT-2005', 'DD-MON-YYYY')) TABLESPACE tbs3,
+ PARTITION sal05q4 VALUES LESS THAN (TO_DATE('01-JAN-2006', 'DD-MON-YYYY')) TABLESPACE tbs4,
+ PARTITION sal06q1 VALUES LESS THAN (TO_DATE('01-APR-2006', 'DD-MON-YYYY')) TABLESPACE tbs1,
+ PARTITION sal06q2 VALUES LESS THAN (TO_DATE('01-JUL-2006', 'DD-MON-YYYY')) TABLESPACE tbs2,
+ PARTITION sal06q3 VALUES LESS THAN (TO_DATE('01-OCT-2006', 'DD-MON-YYYY')) TABLESPACE tbs3,
+ PARTITION sal06q4 VALUES LESS THAN (TO_DATE('01-JAN-2007', 'DD-MON-YYYY')) TABLESPACE tbs4);
+```
diff --git a/product/zh/docs-mogdb/v3.0/reference-guide/guc-parameters/20-MogDB-transaction.md b/product/zh/docs-mogdb/v3.0/reference-guide/guc-parameters/20-MogDB-transaction.md
index 69609bd32f8622210204495cf41e3fa52446f04d..a0422ba535200bc49ba34e8590d1f2ddd25fb1c8 100644
--- a/product/zh/docs-mogdb/v3.0/reference-guide/guc-parameters/20-MogDB-transaction.md
+++ b/product/zh/docs-mogdb/v3.0/reference-guide/guc-parameters/20-MogDB-transaction.md
@@ -136,4 +136,16 @@ date: 2021-04-20
- on表示延迟计算快照xmin和oldestxmin。
- off表示实时计算快照xmin和oldestxmin。
-**默认值**: on
+**默认值**:on
+
+## async_submit
+
+**参数说明**:可以在session级别控制是否使用事务异步提交。该开关仅在“[enable_threadpool](32-thread-pool#enable_thread_pool) = on”和“[synchronous_commit](1-settings#synchronous_commit)”不为“off”时有效。
+
+**取值范围**:布尔型。
+
+- on:表示打开事务异步提交,该session上所有事务提交将异步完成。
+
+- off:该session上所有事务按照原有的逻辑提交。
+
+**默认值**:off
diff --git a/product/zh/docs-mogdb/v3.0/reference-guide/guc-parameters/32-thread-pool.md b/product/zh/docs-mogdb/v3.0/reference-guide/guc-parameters/32-thread-pool.md
index 6708e28f68ba10103e50c33d2be2b3200d2cc6e6..c9d4c222d8f755769d105a63813322f545173f6d 100644
--- a/product/zh/docs-mogdb/v3.0/reference-guide/guc-parameters/32-thread-pool.md
+++ b/product/zh/docs-mogdb/v3.0/reference-guide/guc-parameters/32-thread-pool.md
@@ -26,8 +26,8 @@ date: 2021-06-07
该参数分为3个部分,'thread_num, group_num, cpubind_info',这3个部分的具体含义如下:
-- thread_num:线程池中的线程总数,取值范围是0~4096。其中0的含义是数据库根据系统CPU core的数量来自动配置线程池的线程数,如果参数值大于0,线程池中的线程数等于thread_num。线程池大小推荐根据硬件配置设置,计算公式为thread_num=CPU核数*3~5,thread_num最大值4096。
-- group_num:线程池中的线程分组个数,取值范围是0~64。其中0的含义是数据库根据系统NUMA组的个数来自动配置线程池的线程分组个数,如果参数值大于0,线程池中的线程组个数等于group_num。
+- thread_num:线程池中的线程总数,取值范围是0-4096。其中0的含义是数据库根据系统CPU core的数量来自动配置线程池的线程数,如果参数值大于0,线程池中的线程数等于thread_num。线程池大小推荐根据硬件配置设置,计算公式为thread_num=CPU核数*3~5,thread_num最大值4096。
+- group_num:线程池中的线程分组个数,取值范围是0-64。其中0的含义是数据库根据系统NUMA组的个数来自动配置线程池的线程分组个数,如果参数值大于0,线程池中的线程组个数等于group_num。
- cpubind_info:线程池是否绑核的配置参数。可选择的配置方式有集中:
1. '(nobind)' ,线程不做绑核;
2. '(allbind)',利用当前系统所有能查询到的CPU core做线程绑核;
diff --git a/product/zh/docs-mogdb/v3.0/reference-guide/schema/DBE_PERF/session-thread/LOCAL_ACTIVE_SESSION.md b/product/zh/docs-mogdb/v3.0/reference-guide/schema/DBE_PERF/session-thread/LOCAL_ACTIVE_SESSION.md
index e27c67c5bb7f60cfc6d4d30ef98874127ba01b2c..a0ebbf8fa94b4be06c23904b1cfc6f73123a4a30 100644
--- a/product/zh/docs-mogdb/v3.0/reference-guide/schema/DBE_PERF/session-thread/LOCAL_ACTIVE_SESSION.md
+++ b/product/zh/docs-mogdb/v3.0/reference-guide/schema/DBE_PERF/session-thread/LOCAL_ACTIVE_SESSION.md
@@ -41,3 +41,4 @@ LOCAL_ACTIVE_SESSION视图显示本节点上的ACTIVE SESSION PROFILE内存中
| final_block_sessionid | bigint | 表示源头阻塞会话ID。 |
| wait_status | text | 描述event列的更多详细信息。 |
| global_sessionid | text | 全局会话ID。 |
+| plan_node_id | int | 执行计划树的算子id |
diff --git a/product/zh/docs-mogdb/v3.0/reference-guide/schema/DBE_PERF/session-thread/LOCAL_THREADPOOL_STATUS.md b/product/zh/docs-mogdb/v3.0/reference-guide/schema/DBE_PERF/session-thread/LOCAL_THREADPOOL_STATUS.md
index 96991973aeeca02a018bd7c345d450bdd89b20ad..41329dcf357b51c9f5c9c52684f26191407ebc67 100644
--- a/product/zh/docs-mogdb/v3.0/reference-guide/schema/DBE_PERF/session-thread/LOCAL_THREADPOOL_STATUS.md
+++ b/product/zh/docs-mogdb/v3.0/reference-guide/schema/DBE_PERF/session-thread/LOCAL_THREADPOOL_STATUS.md
@@ -20,3 +20,4 @@ LOCAL_THREADPOOL_STATUS视图显示线程池下工作线程及会话的状态信
| listener | integer | 该线程池组的Listener线程数量。 |
| worker_info | text | 线程池中线程相关信息,包括以下信息:
- default: 该线程池组中的初始线程数量。
- new: 该线程池组中新增线程的数量。
- expect: 该线程池组中预期线程的数量。
- actual: 该线程池组中实际线程的数量。
- idle: 该线程池组中空闲线程的数量。
- pending: 该线程池组中等待线程的数量。 |
| session_info | text | 线程池中会话相关信息,包括以下信息:
- total: 该线程池组中所有的会话数量。
- waiting: 该线程池组中等待调度的会话数量。
- running: 该线程池中正在执行的会话数量。
- idle: 该线程池组中空闲的会话数量。 |
+| committer_info | text | committer运行状态,正在运行以及空闲个数。 |
diff --git a/product/zh/docs-mogdb/v3.0/reference-guide/sql-syntax/CREATE-INDEX.md b/product/zh/docs-mogdb/v3.0/reference-guide/sql-syntax/CREATE-INDEX.md
index 82c34196626eb3a1311c0d22e5ed820cd411e698..e0b81e680830525ef437d3f00b824aea591f7057 100644
--- a/product/zh/docs-mogdb/v3.0/reference-guide/sql-syntax/CREATE-INDEX.md
+++ b/product/zh/docs-mogdb/v3.0/reference-guide/sql-syntax/CREATE-INDEX.md
@@ -40,7 +40,8 @@ date: 2021-05-10
[ INCLUDE ( column_name [, ...] )]
[ WITH ( {storage_parameter = value} [, ... ] ) ]
[ TABLESPACE tablespace_name ]
- [ WHERE predicate ];
+ [ WHERE predicate ]
+ [ PARALLEL num ];
```
- 在分区表上创建索引。
@@ -51,7 +52,8 @@ date: 2021-05-10
[ LOCAL [ ( { PARTITION index_partition_name | SUBPARTITION index_subpartition_name [ TABLESPACE index_partition_tablespace ] } [, ...] ) ] | GLOBAL ]
[ INCLUDE ( column_name [, ...] )]
[ WITH ( { storage_parameter = value } [, ...] ) ]
- [ TABLESPACE tablespace_name ];
+ [ TABLESPACE tablespace_name ]
+ [ PARALLEL num ];
```
## 参数说明
@@ -281,8 +283,70 @@ date: 2021-05-10
索引参数,设置索引压缩字节差分预处理。只能与compress_byte_convert一起使用。在一些场景下可以提升压缩效果,同时会导致一定性能劣化。
取值范围:布尔值,默认关闭。
-
-## 示例
+
+- **PARALLEL num**
+
+ 在索引创建语句中直接指定并行度,根据对当前资源环境以及自身需求来指定并行度,可以更加有效地利用资源,同时提高使用灵活性。
+
+ 取值范围:1-32
+
+ 最终并行度由下列几个要素决定:
+
+ 1、表的parallel_workers属性(必要因素)
+
+ 当parallel_workers=0时,PARALLEL num无效
+
+ 当parallel_workers=[1-32]时,PARALLEL num应当<=parallel_workers
+
+ 如何设置/修改/查询表的parallel_workers属性:
+
+ ```sql
+ MogDB=# create table t_1(aid integer);
+ CREATE TABLE
+
+ --查看表的并行度parallel_workers
+ MogDB=# select reloptions from pg_class where relname='t_1';
+ reloptions
+ ----------------------------------
+ {orientation=row,compression=no}
+ (1 row)
+
+ --设置表的并行度parallel_workers=8
+ MogDB=# alter table t_1 set (parallel_workers=8);
+ ALTER TABLE
+ MogDB=# select reloptions from pg_class where relname='t_1';
+ reloptions
+ -----------------------------------------------------
+ {orientation=row,compression=no,parallel_workers=8}
+ (1 row)
+
+ --设置表的并行度parallel_workers=1
+ MogDB=# alter table t_1 set (parallel_workers=1);
+ ALTER TABLE
+ MogDB=# select reloptions from pg_class where relname='t_1';
+
+ reloptions
+ -----------------------------------------------------
+
+ {orientation=row,compression=no,parallel_workers=1}
+ (1 row)
+ ```
+
+ 2、指定值
+
+ 我们在创建索引中指定的值parallel num,num取值范围是1-32,超过该范围会报错。
+
+ 3、目标表类型
+
+ i. 如果目标表是一个普通表,那么并行度就按照上述计算结果。
+
+ ii. 如果目标表是一个分区表并且创建索引的类型为全局索引,那么并行度取分区个数和上述结果中较小的值作为最终的并行度。
+
+ iii. 如果目标表为分区表,并且是local的index,对于每一个分区按照上述指定值进行并行创建。
+
+ >  **注意**:仅有btree类型索引支持并行,因此该语法也仅支持btree索引。
+
+## 示例1
```sql
--创建表tpcds.ship_mode_t1。
@@ -367,10 +431,10 @@ MogDB=# CREATE INDEX ds_customer_address_p1_index2 ON tpcds.customer_address_p1(
TABLESPACE example2;
--创建GLOBAL分区索引
-mogdb=CREATE INDEX ds_customer_address_p1_index3 ON tpcds.customer_address_p1(CA_ADDRESS_ID) GLOBAL;
+MogDB=# CREATE INDEX ds_customer_address_p1_index3 ON tpcds.customer_address_p1(CA_ADDRESS_ID) GLOBAL;
--不指定关键字,默认创建GLOBAL分区索引
-mogdb=CREATE INDEX ds_customer_address_p1_index4 ON tpcds.customer_address_p1(CA_ADDRESS_ID);
+MogDB=# CREATE INDEX ds_customer_address_p1_index4 ON tpcds.customer_address_p1(CA_ADDRESS_ID);
--修改分区表索引CA_ADDRESS_SK_index2的表空间为example1。
MogDB=# ALTER INDEX tpcds.ds_customer_address_p1_index2 MOVE PARTITION CA_ADDRESS_SK_index2 TABLESPACE example1;
@@ -398,6 +462,38 @@ MogDB=# create index cgin_test on cgin_create_test using gin(to_tsvector('ngram'
CREATE INDEX
```
+## 示例2:并行创建索引
+
+```sql
+--创建表
+MogDB=# create table crepara_index_t1(c1 int,c2 int,c3 int,c4 text,c5 text,c6 text);
+CREATE TABLE
+
+--模拟800万条数据
+insert into crepara_index_t1 select random()*10000,random() *10000,random()*10000,to_hex(random()*10000000),to_hex(random()*10000000),to_hex(random()*10000000) from generate_series(1,8000000);
+INSERT 0 8000000
+Time: 71333.366 ms
+
+--查询记录总数
+MogDB=# select count(*) from crepara_index_t1 ;
+count
+---------
+8000000
+(1 row)
+Time: 1068.158 ms
+
+--修改表的属性parallel_workers=32
+MogDB=# alter table crepara_index_t1 set (parallel_workers=32);
+ALTER TABLE
+--也可以在建表时指定parallel_workers例:
+--create table crepara_index_t1_new(c1 int,c2 int,c3 int,c4 text,c5 text,c6 text) with(parallel_workers=32);
+
+--创建索引并指定并行度为32
+MogDB=# create index crepara_idx_01 on crepara_index_t1(c1,c2) parallel 32;
+CREATE INDEX
+Time: 11146.399 ms
+```
+
## 相关链接
[ALTER INDEX](ALTER-INDEX),[DROP INDEX](DROP-INDEX)
diff --git a/product/zh/docs-mogdb/v3.0/reference-guide/sql-syntax/CREATE-SERVER.md b/product/zh/docs-mogdb/v3.0/reference-guide/sql-syntax/CREATE-SERVER.md
index e651b0a5e5c586bc4be887cf814ac6b4efb10d00..820143d8bc946b90bb3b8fb063f3310fb084358a 100644
--- a/product/zh/docs-mogdb/v3.0/reference-guide/sql-syntax/CREATE-SERVER.md
+++ b/product/zh/docs-mogdb/v3.0/reference-guide/sql-syntax/CREATE-SERVER.md
@@ -31,7 +31,7 @@ CreateServer ::= CREATE SERVER server_name
指定外部数据封装器的名称。
- 取值范围: dist_fdw,hdfs_fdw,log_fdw,file_fdw,mot_fdw。
+ 取值范围: dist_fdw,hdfs_fdw,log_fdw,file_fdw,mot_fdw,oracle_fdw,mysql_fdw,postgres_fdw。
- **OPTIONS ( { option_name ' value ' } [, ...] )**
diff --git a/product/zh/docs-mogdb/v3.0/reference-guide/system-catalogs-and-system-views/system-catalogs/GS_ASP.md b/product/zh/docs-mogdb/v3.0/reference-guide/system-catalogs-and-system-views/system-catalogs/GS_ASP.md
index 17d3c234b2b3fcf2e1c836eea4013fae3c269bd7..2491629447cb90769b2383d588519116de68290f 100644
--- a/product/zh/docs-mogdb/v3.0/reference-guide/system-catalogs-and-system-views/system-catalogs/GS_ASP.md
+++ b/product/zh/docs-mogdb/v3.0/reference-guide/system-catalogs-and-system-views/system-catalogs/GS_ASP.md
@@ -39,4 +39,5 @@ GS_ASP显示被持久化的ACTIVE SESSION PROFILE样本,该表只在系统库
| lockmode | text | 会话等待锁模式:
- LW_EXCLUSIVE:排他锁
- LW_SHARED:共享锁
- LW_WAIT_UNTIL_FREE:等待LW_EXCLUSIVE可用 |
| block_sessionid | bigint | 如果会话正在等待锁,阻塞该会话获取锁的会话标识。 |
| wait_status | text | 描述event列的更多详细信息。 |
-| global_sessionid | text | 全局会话ID。 |
\ No newline at end of file
+| global_sessionid | text | 全局会话ID。 |
+| plan_node_id | int | 执行计划树的算子id |
\ No newline at end of file
diff --git a/product/zh/docs-mogdb/v3.0/reference-guide/system-catalogs-and-system-views/system-views/GS_ASYNC_SUBMIT_SESSIONS_STATUS.md b/product/zh/docs-mogdb/v3.0/reference-guide/system-catalogs-and-system-views/system-views/GS_ASYNC_SUBMIT_SESSIONS_STATUS.md
new file mode 100644
index 0000000000000000000000000000000000000000..195103b67194b7be5615bda9ac11d6182106923b
--- /dev/null
+++ b/product/zh/docs-mogdb/v3.0/reference-guide/system-catalogs-and-system-views/system-views/GS_ASYNC_SUBMIT_SESSIONS_STATUS.md
@@ -0,0 +1,24 @@
+---
+title: GS_ASYNC_SUBMIT_SESSIONS_STATUS
+summary: GS_ASYNC_SUBMIT_SESSIONS_STATUS
+author: Guo Huan
+date: 2022-06-13
+---
+
+# GS_ASYNC_SUBMIT_SESSIONS_STATUS
+
+GS_ASYNC_SUBMIT_SESSIONS_STATUS视图用于查看使用异步提交的session状态。
+
+**表 1** GS_ASYNC_SUBMIT_SESSIONS_STATUS字段
+
+| 名称 | 类型 | 描述 |
+| ------------------------------------- | ---- | ------------------------------------------------------------ |
+| nodename | text | 节点名 |
+| groupid | int | 线程组号 |
+| waiting_xlog_flush_session_num | int | 等待日志刷盘的session数 |
+| waiting_async_rep_receive_session_num | int | 等待备份同步日志receive的session数 |
+| waiting_async_rep_write_session_num | int | 等待备份同步日志write的session数 |
+| waiting_async_rep_flush_session_num | int | 等待备份同步日志flush的session数 |
+| waiting_async_rep_apply_session_num | int | 等待备份同步日志apply的session数 |
+| waiting_commit_session_num | int | 已经完成日志刷盘(和备份同步)但还没有完成异步提交的session数 |
+| finished_commit_session_num | int | 已经完成异步提交的session数 |
diff --git a/product/zh/docs-mogdb/v3.0/toc.md b/product/zh/docs-mogdb/v3.0/toc.md
index 853e99d8e5946c8541cbfdcd957bb54823ef75f5..9b6afb781de5a0af97a79b36b2a0810e853ad170 100644
--- a/product/zh/docs-mogdb/v3.0/toc.md
+++ b/product/zh/docs-mogdb/v3.0/toc.md
@@ -111,6 +111,11 @@
+ [发布订阅](/characteristic-description/enterprise-level-features/16-publication-subscription.md)
+ [外键锁增强](/characteristic-description/enterprise-level-features/17-foreign-key-lock-enhancement.md)
+ [支持OLTP场景数据压缩](/characteristic-description/enterprise-level-features/18-data-compression-in-oltp-scenarios.md)
+ + [事务异步提交](/characteristic-description/enterprise-level-features/19-transaction-async-submit.md)
+ + [索引创建并行控制](/characteristic-description/enterprise-level-features/23-index-creation-parallel-control.md)
+ + [动态分区裁剪](/characteristic-description/enterprise-level-features/21-dynamic-partition-pruning.md)
+ + [COPY导入优化](/characteristic-description/enterprise-level-features/20-copy-import-optimization.md)
+ + [SQL运行时状态观测](/characteristic-description/enterprise-level-features/22-sql-running-status-observation.md)
+ 应用开发接口
+ [支持标准SQL](/characteristic-description/application-development-interfaces/1-standard-sql.md)
+ [支持标准开发接口](/characteristic-description/application-development-interfaces/2-standard-development-interfaces.md)
@@ -486,6 +491,16 @@
+ [启动资源负载管理功能](/developer-guide/resource-load-management/resource-management-preparation/enabling-resource-load-management.md)
+ [设置控制组](/developer-guide/resource-load-management/resource-management-preparation/setting-a-cgroup.md)
+ [创建资源池](/developer-guide/resource-load-management/resource-management-preparation/creating-a-resource-pool.md)
+ + 分区管理
+ + 分区裁剪
+ + [分区裁剪的好处](/developer-guide/partition-management/partition-pruning/benefits-of-partition-pruning.md)
+ + [可用于分区裁剪的信息](/developer-guide/partition-management/partition-pruning/information-that-can-be-used-for-partition-pruning.md)
+ + [静态分区裁剪](/developer-guide/partition-management/partition-pruning/static-partition-pruning.md)
+ + [动态分区裁剪](/developer-guide/partition-management/partition-pruning/dynamic-partition-pruning.md)
+ + 选择分区策略的建议
+ + [何时使用范围或间隔分区](/developer-guide/partition-management/recommendations-for-choosing-a-partitioning-strategy/when-to-use-range-or-interval-partitioning.md)
+ + [何时使用列表分区](/developer-guide/partition-management/recommendations-for-choosing-a-partitioning-strategy/when-to-use-list-partitioning.md)
+ + [何时使用哈希分区](/developer-guide/partition-management/recommendations-for-choosing-a-partitioning-strategy/when-to-use-hash-partitioning.md)
+ 性能优化指南
+ 系统优化指南
+ [操作系统参数调优](/performance-tuning/1-system/1-optimizing-os-parameters.md)
@@ -626,6 +641,7 @@
+ [GS_AUDITING](./reference-guide/system-catalogs-and-system-views/system-views/GS_AUDITING.md)
+ [GS_AUDITING_ACCESS](./reference-guide/system-catalogs-and-system-views/system-views/GS_AUDITING_ACCESS.md)
+ [GS_AUDITING_PRIVILEGE](./reference-guide/system-catalogs-and-system-views/system-views/GS_AUDITING_PRIVILEGE.md)
+ + [GS_ASYNC_SUBMIT_SESSIONS_STATUS](./reference-guide/system-catalogs-and-system-views/system-views/GS_ASYNC_SUBMIT_SESSIONS_STATUS.md)
+ [GS_CLUSTER_RESOURCE_INFO](./reference-guide/system-catalogs-and-system-views/system-views/GS_CLUSTER_RESOURCE_INFO.md)
+ [GS_DB_PRIVILEGES](./reference-guide/system-catalogs-and-system-views/system-views/GS_DB_PRIVILEGES.md)
+ [GS_FILE_STAT](./reference-guide/system-catalogs-and-system-views/system-views/GS_FILE_STAT.md)
diff --git a/product/zh/docs-mogdb/v3.0/toc_characteristic_description.md b/product/zh/docs-mogdb/v3.0/toc_characteristic_description.md
index ad0c5c3973ab446e4a2fe8c0127a577c25cff5f0..21d49d78b336b647d2c2c240726f5caa04dc7fc6 100644
--- a/product/zh/docs-mogdb/v3.0/toc_characteristic_description.md
+++ b/product/zh/docs-mogdb/v3.0/toc_characteristic_description.md
@@ -75,6 +75,11 @@
+ [发布订阅](/characteristic-description/enterprise-level-features/16-publication-subscription.md)
+ [外键锁增强](/characteristic-description/enterprise-level-features/17-foreign-key-lock-enhancement.md)
+ [支持OLTP场景数据压缩](/characteristic-description/enterprise-level-features/18-data-compression-in-oltp-scenarios.md)
+ + [事务异步提交](/characteristic-description/enterprise-level-features/19-transaction-async-submit.md)
+ + [索引创建并行控制](/characteristic-description/enterprise-level-features/23-index-creation-parallel-control.md)
+ + [动态分区裁剪](/characteristic-description/enterprise-level-features/21-dynamic-partition-pruning.md)
+ + [COPY导入优化](/characteristic-description/enterprise-level-features/20-copy-import-optimization.md)
+ + [SQL运行时状态观测](/characteristic-description/enterprise-level-features/22-sql-running-status-observation.md)
+ 应用开发接口
+ [支持标准SQL](/characteristic-description/application-development-interfaces/1-standard-sql.md)
+ [支持标准开发接口](/characteristic-description/application-development-interfaces/2-standard-development-interfaces.md)
diff --git a/product/zh/docs-mogdb/v3.0/toc_dev.md b/product/zh/docs-mogdb/v3.0/toc_dev.md
index 63865c4ab7b583509fc3c011a37147974851abfa..777530852f99e206a3c827f093331d42295e0ab9 100644
--- a/product/zh/docs-mogdb/v3.0/toc_dev.md
+++ b/product/zh/docs-mogdb/v3.0/toc_dev.md
@@ -206,3 +206,13 @@
+ [启动资源负载管理功能](/developer-guide/resource-load-management/resource-management-preparation/enabling-resource-load-management.md)
+ [设置控制组](/developer-guide/resource-load-management/resource-management-preparation/setting-a-cgroup.md)
+ [创建资源池](/developer-guide/resource-load-management/resource-management-preparation/creating-a-resource-pool.md)
++ 分区管理
+ + 分区裁剪
+ + [分区裁剪的好处](/developer-guide/partition-management/partition-pruning/benefits-of-partition-pruning.md)
+ + [可用于分区裁剪的信息](/developer-guide/partition-management/partition-pruning/information-that-can-be-used-for-partition-pruning.md)
+ + [静态分区裁剪](/developer-guide/partition-management/partition-pruning/static-partition-pruning.md)
+ + [动态分区裁剪](/developer-guide/partition-management/partition-pruning/dynamic-partition-pruning.md)
+ + 选择分区策略的建议
+ + [何时使用范围或间隔分区](/developer-guide/partition-management/recommendations-for-choosing-a-partitioning-strategy/when-to-use-range-or-interval-partitioning.md)
+ + [何时使用列表分区](/developer-guide/partition-management/recommendations-for-choosing-a-partitioning-strategy/when-to-use-list-partitioning.md)
+ + [何时使用哈希分区](/developer-guide/partition-management/recommendations-for-choosing-a-partitioning-strategy/when-to-use-hash-partitioning.md)
\ No newline at end of file
diff --git a/product/zh/docs-mogdb/v3.0/toc_system-catalogs-and-functions.md b/product/zh/docs-mogdb/v3.0/toc_system-catalogs-and-functions.md
index 8f6d1765e6da2c8aa80730995ec26d76fb041823..82df63370bb57f3c6fab3820c99cd1753d2fe609 100644
--- a/product/zh/docs-mogdb/v3.0/toc_system-catalogs-and-functions.md
+++ b/product/zh/docs-mogdb/v3.0/toc_system-catalogs-and-functions.md
@@ -123,6 +123,7 @@
+ [GS_AUDITING](./reference-guide/system-catalogs-and-system-views/system-views/GS_AUDITING.md)
+ [GS_AUDITING_ACCESS](./reference-guide/system-catalogs-and-system-views/system-views/GS_AUDITING_ACCESS.md)
+ [GS_AUDITING_PRIVILEGE](./reference-guide/system-catalogs-and-system-views/system-views/GS_AUDITING_PRIVILEGE.md)
+ + [GS_ASYNC_SUBMIT_SESSIONS_STATUS](./reference-guide/system-catalogs-and-system-views/system-views/GS_ASYNC_SUBMIT_SESSIONS_STATUS.md)
+ [GS_CLUSTER_RESOURCE_INFO](./reference-guide/system-catalogs-and-system-views/system-views/GS_CLUSTER_RESOURCE_INFO.md)
+ [GS_DB_PRIVILEGES](./reference-guide/system-catalogs-and-system-views/system-views/GS_DB_PRIVILEGES.md)
+ [GS_FILE_STAT](./reference-guide/system-catalogs-and-system-views/system-views/GS_FILE_STAT.md)