diff --git a/product/en/docs-mvd/v2.4/release-notes.md b/product/en/docs-mvd/v2.4/release-notes.md
index 67aa2aefcd916668c56131c68202027750cc3752..f219a90d34d825a09fd10ee473c82a00ab3ab7ad 100644
--- a/product/en/docs-mvd/v2.4/release-notes.md
+++ b/product/en/docs-mvd/v2.4/release-notes.md
@@ -7,6 +7,34 @@ date: 2021-08-30
# Release Notes
+## v2.4.8 (2022-04-22)
+
+- [mvd_linux_arm64](https://cdn-mogdb.enmotech.com/mvd/MVD_v2.4.8/mvd_linux_arm64)
+- [mvd_linux_x86_64](https://cdn-mogdb.enmotech.com/mvd/MVD_v2.4.8/mvd_linux_x86_64)
+- [mvd_macos_x86_64](https://cdn-mogdb.enmotech.com/mvd/MVD_v2.4.8/mvd_macos_x86_64)
+
+### Feature
+
+- When comparing objects, MogDB adds Package objects (2.1 and later versions) and SYNONYM objects comparison
+- Add recognition of OS local variables (TMPDIR, TMP) for storing temporary data during program runtime when comparing Oracle/DB2 databases
+- Add -Z option to manually specify the time zone used for data comparison in different databases at runtime
+
+### Function Optimization
+
+- Fine-tuned final results presentation for better readability
+- Optimize the output of the --debug-md5 option during data comparison to provide a more detailed view of the bilateral data comparison process
+- Optimize -T mode to support -r specified Schema mapping even in single table comparison mode
+
+### Bugfix
+
+- Fix the issue of abnormal comparison results caused by different sorting rules of primary key tables in openGauss/MogDB when querying
+- Fix the issue of program error caused by the failure of primary key identification in the comparison of non-primary key table.
+- Fix the issue of inconsistent sorting data due to mixed case of primary key field names in different databases ("TID").
+- Fix the issue of inconsistent data in the unilateral database which cannot be correctly identified.
+- Fix the issue that the comparison result of primary key table is incorrect due to the space at the end of the primary key field.
+- Fix the issue that the query field appears several times in Oracle/DB2 (primary key table), which leads to the query error.
+- Fix the issue of incorrect data comparison caused by trailing space of char type in MySQL database.
+
## v2.4.0 (2021-12-20)
- [mvd_linux_arm64](https://cdn-mogdb.enmotech.com/mvd/MVD_v2.4.0/mvd_linux_arm64)
diff --git a/product/en/docs-mvd/v2.4/usage.md b/product/en/docs-mvd/v2.4/usage.md
index 36d9c574da6213516a84afdde35b45553a7b13bc..1f2746d390ab623f01f7c315195f67fea6845af5 100644
--- a/product/en/docs-mvd/v2.4/usage.md
+++ b/product/en/docs-mvd/v2.4/usage.md
@@ -59,6 +59,7 @@ ORACLE|DB2|MYSQL|POSTGRESQL|MOGDB|OPENGAUSS
--row-feedback : Query row data when differences found, otherwise just key condition listed
--ignore-float : Ignore float data type in comparison
-z, --zero-char : Specify a char for chr(0) in comparason, Default is empty char
+ -Z, --time-zone : Specify timezone for DB client, set empty use local, default is UTC(+00:00)
-l, --logfile : Write output information to logfile
Usage:
@@ -94,6 +95,7 @@ Usage:
| --row-feedback | Specifies whether to show the full data of a difference row. Only KEY of a difference row is shown by default. (The KEY indicates ROWID in Oracle and CTID in PostgreSQL.) |
| --ignore-float | Specifies whether to ignore the floating-point type (float, double, real, and other non-precise types) during data comparison. The floating-point type is not ignored by default. |
| -z, --zero-char | Specifies the replacing character of the chr(0) character during comparison. The default value is null, which is to remove the chr(0) invisible characters. |
+| -Z, --time-zone | Specifies the time zone of the client data query, set the empty string to use the local OS time zone, if not set, use UTC (+00:00) time zone |
| -l, --logfile | Specifies the log file for tool running. |
## Examples of Common Commands
diff --git a/product/zh/docs-mogdb/v3.0/developer-guide/dev/1-development-specifications.md b/product/zh/docs-mogdb/v3.0/developer-guide/dev/1-development-specifications.md
index 4fd75238bfcfa79abfb977cff2e84b09dff47c8b..33e013f4b8d303f7eb5a6f7a2ed4ca95a0d1419a 100644
--- a/product/zh/docs-mogdb/v3.0/developer-guide/dev/1-development-specifications.md
+++ b/product/zh/docs-mogdb/v3.0/developer-guide/dev/1-development-specifications.md
@@ -14,6 +14,10 @@ date: 2021-04-27
否则,连接池里面的连接就是有状态的,会对用户后续使用连接池进行操作的正确性带来影响。
+兼容性原则:
+
+新驱动前向兼容数据库,若需使用驱动与数据库同步增加的新特性,必须升级数据库。
+
## 概述
### 简介
diff --git a/product/zh/docs-mogdb/v3.0/developer-guide/dev/2-development-based-on-jdbc/10-example-common-operations.md b/product/zh/docs-mogdb/v3.0/developer-guide/dev/2-development-based-on-jdbc/10-example-common-operations.md
index 7977be04b725e9ede4096db519cebe16c47b776c..7891137469dd3dd73ab384b9c0865cc2873391b0 100644
--- a/product/zh/docs-mogdb/v3.0/developer-guide/dev/2-development-based-on-jdbc/10-example-common-operations.md
+++ b/product/zh/docs-mogdb/v3.0/developer-guide/dev/2-development-based-on-jdbc/10-example-common-operations.md
@@ -23,6 +23,7 @@ import java.sql.PreparedStatement;
import java.sql.SQLException;
import java.sql.Statement;
import java.sql.CallableStatement;
+import java.sql.Types;
public class DBTest {
@@ -128,7 +129,7 @@ public class DBTest {
public static void ExecCallableSQL(Connection conn) {
CallableStatement cstmt = null;
try {
-
+ // 存储过程TESTPROC需提前创建。
cstmt=conn.prepareCall("{? = CALL TESTPROC(?,?,?)}");
cstmt.setInt(2, 50);
cstmt.setInt(1, 20);
@@ -199,21 +200,21 @@ Statement st = conn.createStatement();
// 打开游标,每次获取50行数据
st.setFetchSize(50);
ResultSet rs = st.executeQuery("SELECT * FROM mytable");
-conn.commit();
while (rs.next())
{
System.out.print("a row was returned.");
}
+conn.commit();
rs.close();
// 关闭服务器游标。
st.setFetchSize(0);
rs = st.executeQuery("SELECT * FROM mytable");
-conn.commit();
while (rs.next())
{
System.out.print("many rows were returned.");
}
+conn.commit();
rs.close();
// Close the statement.
@@ -226,3 +227,60 @@ conn.close();
```java
conn.setAutoCommit(true);
```
+
+
+
+## 示例3 常用数据类型使用示例
+
+```java
+//bit类型使用示例,注意此处bit类型取值范围[0,1]
+Statement st = conn.createStatement();
+String sqlstr = "create or replace function fun_1()\n" +
+ "returns bit AS $$\n" +
+ "select col_bit from t_bit limit 1;\n" +
+ "$$\n" +
+ "LANGUAGE SQL;";
+st.execute(sqlstr);
+CallableStatement c = conn.prepareCall("{ ? = call fun_1() }");
+//注册输出类型,位串类型
+c.registerOutParameter(1, Types.BIT);
+c.execute();
+//使用Boolean类型获取结果
+System.out.println(c.getBoolean(1));
+
+// money类型使用示例
+// 表结构中包含money类型列的使用示例。
+st.execute("create table t_money(col1 money)");
+PreparedStatement pstm = conn.prepareStatement("insert into t_money values(?)");
+// 使用PGobject赋值,取值范围[-92233720368547758.08,92233720368547758.07]
+PGobject minMoney = new PGobject();
+minMoney.setType("money");
+minMoney.setValue("-92233720368547758.08");
+pstm.setObject(1, minMoney);
+pstm.execute();
+// 使用PGMoney赋值,取值范围[-9999999.99,9999999.99]
+pstm.setObject(1,new PGmoney(9999999.99));
+pstm.execute();
+
+// 函数返回值为money的使用示例。
+st.execute("create or replace function func_money() " +
+ "return money " +
+ "as declare " +
+ "var1 money; " +
+ "begin " +
+ " select col1 into var1 from t_money limit 1; " +
+ " return var1; " +
+ "end;");
+CallableStatement cs = conn.prepareCall("{? = call func_money()}");
+cs.registerOutParameter(1,Types.DOUBLE);
+cs.execute();
+cs.getObject(1);
+```
+
+
+
+## 示例4 获取驱动版本示例
+
+```java
+Driver.getGSVersion();
+```
diff --git a/product/zh/docs-mogdb/v3.0/developer-guide/dev/2-development-based-on-jdbc/11-example-retrying-sql-queries-for-applications.md b/product/zh/docs-mogdb/v3.0/developer-guide/dev/2-development-based-on-jdbc/11-example-retrying-sql-queries-for-applications.md
index ca8f68fb16dfcba6c9f57474cc4cc1b240802880..aeef569389625703eca608984560a2a50fd32d48 100644
--- a/product/zh/docs-mogdb/v3.0/developer-guide/dev/2-development-based-on-jdbc/11-example-retrying-sql-queries-for-applications.md
+++ b/product/zh/docs-mogdb/v3.0/developer-guide/dev/2-development-based-on-jdbc/11-example-retrying-sql-queries-for-applications.md
@@ -60,14 +60,14 @@ public class SQLRetry {
return conn;
}
-
+
//执行普通SQL语句,创建jdbc_test1表。
public static void CreateTable(Connection conn) {
Statement stmt = null;
try {
stmt = conn.createStatement();
-
+
Runtime.getRuntime().addShutdownHook(new ExitHandler(stmt));
//执行普通SQL语句。
@@ -117,7 +117,7 @@ public class SQLRetry {
e.printStackTrace();
}
}
-
+
//执行预编译语句,更新数据。
private static boolean QueryRedo(Connection conn){
PreparedStatement pstmt = null;
@@ -125,7 +125,7 @@ public class SQLRetry {
try {
pstmt = conn
.prepareStatement("SELECT col1 FROM jdbc_test1 WHERE col2 = ?");
-
+
pstmt.setString(1, "data 10");
ResultSet rs = pstmt.executeQuery();
@@ -133,7 +133,7 @@ public class SQLRetry {
System.out.println("col1 = " + rs.getString("col1"));
}
rs.close();
-
+
pstmt.close();
retValue = true;
} catch (SQLException e) {
@@ -147,8 +147,8 @@ public class SQLRetry {
}
e.printStackTrace();
}
-
- System.out.println("finesh......");
+
+ System.out.println("finesh......");
return retValue;
}
@@ -164,20 +164,20 @@ public class SQLRetry {
boolean ret = QueryRedo(conn);
if(ret == false){
System.out.println("retry, time:" + time);
- Thread.sleep(10000);
+ Thread.sleep(10000);
QueryRedo(conn);
}
} catch (Exception e) {
e.printStackTrace();
}
- } while (null == result && time < maxRetryTime);
-
+ } while (null == result && time < maxRetryTime);
+
}
/**
* 主程序,逐步调用各静态方法。
* @param args
- * @throws InterruptedException
+ * @throws InterruptedException
*/
public static void main(String[] args) throws InterruptedException {
//创建数据库连接。
diff --git a/product/zh/docs-mogdb/v3.0/developer-guide/dev/2-development-based-on-jdbc/12-example-importing-and-exporting-data-through-local-files.md b/product/zh/docs-mogdb/v3.0/developer-guide/dev/2-development-based-on-jdbc/12-example-importing-and-exporting-data-through-local-files.md
index 607d1c30fc37d55508e114d001970cd442031e8f..fa9afb39c39ffb0eef132f5608d7240dd50e2feb 100644
--- a/product/zh/docs-mogdb/v3.0/developer-guide/dev/2-development-based-on-jdbc/12-example-importing-and-exporting-data-through-local-files.md
+++ b/product/zh/docs-mogdb/v3.0/developer-guide/dev/2-development-based-on-jdbc/12-example-importing-and-exporting-data-through-local-files.md
@@ -9,111 +9,111 @@ date: 2021-04-26
在使用JAVA语言基于MogDB进行二次开发时,可以使用CopyManager接口,通过流方式,将数据库中的数据导出到本地文件或者将本地文件导入数据库中,文件格式支持CSV、TEXT等格式。
-样例程序如下,执行时需要加载MogDB jdbc驱动。
+样例程序如下,执行时需要加载MogDB JDBC驱动。
```java
-import java.sql.Connection;
-import java.sql.DriverManager;
+import java.sql.Connection;
+import java.sql.DriverManager;
import java.io.IOException;
import java.io.FileInputStream;
import java.io.FileOutputStream;
-import java.sql.SQLException;
-import org.postgresql.copy.CopyManager;
+import java.sql.SQLException;
+import org.postgresql.copy.CopyManager;
import org.postgresql.core.BaseConnection;
-
-public class Copy{
-
- public static void main(String[] args)
- {
- String urls = new String("jdbc:postgresql://10.180.155.74:8000/postgres"); //数据库URL
- String username = new String("jack"); //用户名
- String password = new String("Gauss@123"); //密码
- String tablename = new String("migration_table"); //定义表信息
- String tablename1 = new String("migration_table_1"); //定义表信息
- String driver = "org.postgresql.Driver";
- Connection conn = null;
-
- try {
- Class.forName(driver);
- conn = DriverManager.getConnection(urls, username, password);
- } catch (ClassNotFoundException e) {
- e.printStackTrace(System.out);
- } catch (SQLException e) {
- e.printStackTrace(System.out);
- }
-
- // 将SELECT * FROM migration_table查询结果导出到本地文件d:/data.txt
+
+public class Copy{
+
+ public static void main(String[] args)
+ {
+ String urls = new String("jdbc:postgresql://10.180.155.74:8000/postgres"); //数据库URL
+ String username = new String("jack"); //用户名
+ String password = new String("Gauss@123"); //密码
+ String tablename = new String("migration_table"); //定义表信息
+ String tablename1 = new String("migration_table_1"); //定义表信息
+ String driver = "org.postgresql.Driver";
+ Connection conn = null;
+
+ try {
+ Class.forName(driver);
+ conn = DriverManager.getConnection(urls, username, password);
+ } catch (ClassNotFoundException e) {
+ e.printStackTrace(System.out);
+ } catch (SQLException e) {
+ e.printStackTrace(System.out);
+ }
+
+ // 将SELECT * FROM migration_table查询结果导出到本地文件d:/data.txt
try {
copyToFile(conn, "d:/data.txt", "(SELECT * FROM migration_table)");
} catch (SQLException e) {
k
e.printStackTrace();
} catch (IOException e) {
-
+
e.printStackTrace();
- }
+ }
//将d:/data.txt中的数据导入到migration_table_1中。
try {
copyFromFile(conn, "d:/data.txt", tablename1);
} catch (SQLException e) {
e.printStackTrace();
} catch (IOException e) {
-
+
e.printStackTrace();
- }
+ }
- // 将migration_table_1中的数据导出到本地文件d:/data1.txt
+ // 将migration_table_1中的数据导出到本地文件d:/data1.txt
try {
copyToFile(conn, "d:/data1.txt", tablename1);
} catch (SQLException e) {
-
+
e.printStackTrace();
} catch (IOException e) {
-
+
e.printStackTrace();
- }
- }
+ }
+ }
// 使用copyIn把数据从文件中导入数据库,
- public static void copyFromFile(Connection connection, String filePath, String tableName)
- throws SQLException, IOException {
-
- FileInputStream fileInputStream = null;
-
- try {
- CopyManager copyManager = new CopyManager((BaseConnection)connection);
- fileInputStream = new FileInputStream(filePath);
- copyManager.copyIn("COPY " + tableName + " FROM STDIN", fileInputStream);
- } finally {
- if (fileInputStream != null) {
- try {
- fileInputStream.close();
- } catch (IOException e) {
- e.printStackTrace();
- }
- }
- }
- }
-
+ public static void copyFromFile(Connection connection, String filePath, String tableName)
+ throws SQLException, IOException {
+
+ FileInputStream fileInputStream = null;
+
+ try {
+ CopyManager copyManager = new CopyManager((BaseConnection)connection);
+ fileInputStream = new FileInputStream(filePath);
+ copyManager.copyIn("COPY " + tableName + " FROM STDIN", fileInputStream);
+ } finally {
+ if (fileInputStream != null) {
+ try {
+ fileInputStream.close();
+ } catch (IOException e) {
+ e.printStackTrace();
+ }
+ }
+ }
+ }
+
// 使用copyOut把数据从数据库中导出到文件中
- public static void copyToFile(Connection connection, String filePath, String tableOrQuery)
- throws SQLException, IOException {
-
- FileOutputStream fileOutputStream = null;
-
- try {
- CopyManager copyManager = new CopyManager((BaseConnection)connection);
- fileOutputStream = new FileOutputStream(filePath);
- copyManager.copyOut("COPY " + tableOrQuery + " TO STDOUT", fileOutputStream);
- } finally {
- if (fileOutputStream != null) {
- try {
- fileOutputStream.close();
- } catch (IOException e) {
- e.printStackTrace();
- }
- }
- }
- }
+ public static void copyToFile(Connection connection, String filePath, String tableOrQuery)
+ throws SQLException, IOException {
+
+ FileOutputStream fileOutputStream = null;
+
+ try {
+ CopyManager copyManager = new CopyManager((BaseConnection)connection);
+ fileOutputStream = new FileOutputStream(filePath);
+ copyManager.copyOut("COPY " + tableOrQuery + " TO STDOUT", fileOutputStream);
+ } finally {
+ if (fileOutputStream != null) {
+ try {
+ fileOutputStream.close();
+ } catch (IOException e) {
+ e.printStackTrace();
+ }
+ }
+ }
+ }
}
```
diff --git a/product/zh/docs-mogdb/v3.0/developer-guide/dev/2-development-based-on-jdbc/13-example-2-migrating-data-from-a-my-database-to-mogdb.md b/product/zh/docs-mogdb/v3.0/developer-guide/dev/2-development-based-on-jdbc/13-example-2-migrating-data-from-a-my-database-to-mogdb.md
index 59d6a8e332235ddc847ff6ddd6d5b72146d6792a..d13870280a22c51c8b331f7c4eb8c92620ce618e 100644
--- a/product/zh/docs-mogdb/v3.0/developer-guide/dev/2-development-based-on-jdbc/13-example-2-migrating-data-from-a-my-database-to-mogdb.md
+++ b/product/zh/docs-mogdb/v3.0/developer-guide/dev/2-development-based-on-jdbc/13-example-2-migrating-data-from-a-my-database-to-mogdb.md
@@ -23,22 +23,22 @@ import org.postgresql.core.BaseConnection;
public class Migration{
public static void main(String[] args) {
- String url = new String("jdbc:postgresql://10.180.155.74:8000/postgres"); //数据库URL
- String user = new String("jack"); //MogDB用户名
- String pass = new String("Gauss@123"); //MogDB密码
- String tablename = new String("migration_table"); //定义表信息
- String delimiter = new String("|"); //定义分隔符
- String encoding = new String("UTF8"); //定义字符集
+ String url = new String("jdbc:postgresql://10.180.155.74:8000/postgres"); //数据库URL
+ String user = new String("jack"); //MogDB用户名
+ String pass = new String("Gauss@123"); //MogDB密码
+ String tablename = new String("migration_table"); //定义表信息
+ String delimiter = new String("|"); //定义分隔符
+ String encoding = new String("UTF8"); //定义字符集
String driver = "org.postgresql.Driver";
- StringBuffer buffer = new StringBuffer(); //定义存放格式化数据的缓存
+ StringBuffer buffer = new StringBuffer(); //定义存放格式化数据的缓存
try {
- //获取源数据库查询结果集
+ //获取源数据库查询结果集
ResultSet rs = getDataSet();
- //遍历结果集,逐行获取记录
- //将每条记录中各字段值,按指定分隔符分割,由换行符结束,拼成一个字符串
- //把拼成的字符串,添加到缓存buffer
+ //遍历结果集,逐行获取记录
+ //将每条记录中各字段值,按指定分隔符分割,由换行符结束,拼成一个字符串
+ //把拼成的字符串,添加到缓存buffer
while (rs.next()) {
buffer.append(rs.getString(1) + delimiter
+ rs.getString(2) + delimiter
@@ -49,16 +49,16 @@ public class Migration{
rs.close();
try {
- //建立目标数据库连接
+ //建立目标数据库连接
Class.forName(driver);
Connection conn = DriverManager.getConnection(url, user, pass);
BaseConnection baseConn = (BaseConnection) conn;
baseConn.setAutoCommit(false);
- //初始化表信息
+ //初始化表信息
String sql = "Copy " + tablename + " from STDIN DELIMITER " + "'" + delimiter + "'" + " ENCODING " + "'" + encoding + "'";
- //提交缓存buffer中的数据
+ //提交缓存buffer中的数据
CopyManager cp = new CopyManager(baseConn);
StringReader reader = new StringReader(buffer.toString());
cp.copyIn(sql, reader);
@@ -76,9 +76,9 @@ public class Migration{
}
}
- //********************************
- // 从源数据库返回查询结果集
- //*********************************
+ //********************************
+ // 从源数据库返回查询结果集
+ //*********************************
private static ResultSet getDataSet() {
ResultSet rs = null;
try {
@@ -94,4 +94,5 @@ public class Migration{
return rs;
}
}
+
```
diff --git a/product/zh/docs-mogdb/v3.0/developer-guide/dev/2-development-based-on-jdbc/14.1-example-parameters-for-connecting-to-the-database-in-different-scenarios.md b/product/zh/docs-mogdb/v3.0/developer-guide/dev/2-development-based-on-jdbc/14.1-example-parameters-for-connecting-to-the-database-in-different-scenarios.md
index 689df80e0831e586016fedb980f41c8a66928603..aa5253747275af41df7796c2bbc90ae46140cc79 100644
--- a/product/zh/docs-mogdb/v3.0/developer-guide/dev/2-development-based-on-jdbc/14.1-example-parameters-for-connecting-to-the-database-in-different-scenarios.md
+++ b/product/zh/docs-mogdb/v3.0/developer-guide/dev/2-development-based-on-jdbc/14.1-example-parameters-for-connecting-to-the-database-in-different-scenarios.md
@@ -58,3 +58,21 @@ jdbc:postgresql://node1/database?defaultRowFetchSize=50000
```java
jdbc:postgresql://node1/database?batchMode=true
```
+
+## 大小写转换场景
+
+在oracle中元数据的默认存储为大写,而在MogDB中元数据默认存储为小写,所以在从oracle迁移到MogDB后,原本大写的元数据会变为小写。如果原本业务中涉及到大写元数据的处理,可以开启此参数,但是不建议通过这种方式来解决问题,最好通过修改业务编码来解决。如果一定要使用,请务必确认当前数据库中的元数据是否全为小写,以避免出现问题。
+
+```
+jdbc:postgresql://node1/database?uppercaseAttributeName=true
+```
+
+对于DatabaseMetaData中涉及的接口,按照入参直接调用即可,对于ResultSetMetaData中涉及的接口使用方法如下所示
+
+```
+Statement stmt = conn.createStatement();
+ResultSet rs = stmt.executeQuery("select * from test_supper");
+ResultSetMetaData rsmd = rs.getMetaData();
+for (int i = 1; i <= rsmd.getColumnCount(); i++) {
+ System.out.println(rsmd.getColumnLabel(i) + " " + rsmd.getColumnName(i));
+```
diff --git a/product/zh/docs-mogdb/v3.0/developer-guide/dev/2-development-based-on-jdbc/15-JDBC/3-java-sql-DatabaseMetaData.md b/product/zh/docs-mogdb/v3.0/developer-guide/dev/2-development-based-on-jdbc/15-JDBC/3-java-sql-DatabaseMetaData.md
index c223704c8e5128c4dad6afac2310dcff59370a20..d84faf524fe59716f7d5ff3053677324ecfa6373 100644
--- a/product/zh/docs-mogdb/v3.0/developer-guide/dev/2-development-based-on-jdbc/15-JDBC/3-java-sql-DatabaseMetaData.md
+++ b/product/zh/docs-mogdb/v3.0/developer-guide/dev/2-development-based-on-jdbc/15-JDBC/3-java-sql-DatabaseMetaData.md
@@ -60,6 +60,7 @@ java.sql.DatabaseMetaData是数据库对象定义接口。
| getMaxUserNameLength() | int | Yes |
| getNumericFunctions() | String | Yes |
| getPrimaryKeys(String catalog, String schema, String table) | ResultSet | Yes |
+| getPartitionTablePrimaryKeys(String catalog, String schema, String table) | ResultSet | Yes |
| getProcedureColumns(String catalog, String schemaPattern, String procedureNamePattern, String columnNamePattern) | ResultSet | Yes |
| getProcedures(String catalog, String schemaPattern, String procedureNamePattern) | ResultSet | Yes |
| getProcedureTerm() | String | Yes |
@@ -187,3 +188,30 @@ java.sql.DatabaseMetaData是数据库对象定义接口。
| getDatabaseMinorVersion() | int | Yes |
| getJDBCMajorVersion() | int | Yes |
| getJDBCMinorVersion() | int | Yes |
+
+> **说明:**
+>
+> uppercaseAttributeName为true时,以下接口会将查询结果转为大写,可转换范围与java中的toUpperCase方法一致。
+>
+> - public ResultSet getProcedures(String catalog, String schemaPattern, String procedureNamePattern)
+> - public ResultSet getProcedureColumns(String catalog, String schemaPattern, String procedureNamePattern, String columnNamePattern)
+> - public ResultSet getTables(String catalog, String schemaPattern, String tableNamePattern, String[] types)
+> - public ResultSet getSchemas(String catalog, String schemaPattern)
+> - public ResultSet getColumns(String catalog, String schemaPattern, String tableNamePattern, String columnNamePattern)
+> - public ResultSet getColumnPrivileges(String catalog, String schema, String table, String columnNamePattern)
+> - public ResultSet getTablePrivileges(String catalog, String schemaPattern, String tableNamePattern)
+> - public ResultSet getBestRowIdentifier(String catalog, String schema, String table, int scope, boolean nullable)
+> - public ResultSet getPrimaryKeys(String catalog, String schema, String table)
+> - protected ResultSet getImportedExportedKeys(String primaryCatalog, String primarySchema, String primaryTable, String foreignCatalog, String foreignSchema, String foreignTable)
+> - public ResultSet getIndexInfo(String catalog, String schema, String tableName, boolean unique, boolean approximate)
+> - public ResultSet getUDTs(String catalog, String schemaPattern, String typeNamePattern, int[] types)
+> - public ResultSet getFunctions(String catalog, String schemaPattern, String functionNamePattern)
+
+> **注意:**
+>
+> getPartitionTablePrimaryKeys(String catalog, String schema, String table)接口用于获取分区表含全局索引的主键列,使用示例如下:
+>
+> ```
+> PgDatabaseMetaData dbmd = (PgDatabaseMetaData)conn.getMetaData();
+> dbmd.getPartitionTablePrimaryKeys("catalogName", "schemaName", "tableName");
+> ```
diff --git a/product/zh/docs-mogdb/v3.0/developer-guide/dev/2-development-based-on-jdbc/15-JDBC/7-java-sql-ResultSetMetaData.md b/product/zh/docs-mogdb/v3.0/developer-guide/dev/2-development-based-on-jdbc/15-JDBC/7-java-sql-ResultSetMetaData.md
index 897b8d227243ca77c4b281a6ce9a4ba749203f53..d7ce03f24806381b8f09c531d3a4e1fca8f23f44 100644
--- a/product/zh/docs-mogdb/v3.0/developer-guide/dev/2-development-based-on-jdbc/15-JDBC/7-java-sql-ResultSetMetaData.md
+++ b/product/zh/docs-mogdb/v3.0/developer-guide/dev/2-development-based-on-jdbc/15-JDBC/7-java-sql-ResultSetMetaData.md
@@ -34,3 +34,10 @@ java.sql.ResultSetMetaData是对ResultSet对象相关信息的具体描述。
| isSearchable(int column) | boolean | Yes |
| isSigned(int column) | boolean | Yes |
| isWritable(int column) | boolean | Yes |
+
+> **说明:**
+>
+> uppercaseAttributeName为true时,下面接口会将查询结果转为大写,可转换范围为26个英文字母。
+>
+> - public String getColumnName(int column)
+> - public String getColumnLabel(int column)
diff --git a/product/zh/docs-mogdb/v3.0/developer-guide/dev/2-development-based-on-jdbc/2-jdbc-package-driver-class-and-environment-class.md b/product/zh/docs-mogdb/v3.0/developer-guide/dev/2-development-based-on-jdbc/2-jdbc-package-driver-class-and-environment-class.md
index 9d8e526442e523d16ebf6c937d8532e42585365f..29f70b343491b42019d6ba0d56af585062c64409 100644
--- a/product/zh/docs-mogdb/v3.0/developer-guide/dev/2-development-based-on-jdbc/2-jdbc-package-driver-class-and-environment-class.md
+++ b/product/zh/docs-mogdb/v3.0/developer-guide/dev/2-development-based-on-jdbc/2-jdbc-package-driver-class-and-environment-class.md
@@ -22,7 +22,13 @@ date: 2021-04-26
在创建数据库连接之前,需要加载数据库驱动类"org.postgresql.Driver"。
> **说明:**
-> 由于MogDB在JDBC的使用上与PG的使用方法保持兼容,所以同时在同一进程内使用两个JDBC驱动的时候,可能会类名冲突。
+>
+> - 由于MogDB在JDBC的使用上与PG的使用方法保持兼容,所以同时在同一进程内使用两个JDBC驱动的时候,可能会类名冲突。
+>
+> - 相比于PG驱动,openGauss JDBC驱动主要做了以下特性的增强:
+> - 支持SHA256加密方式登录。
+> - 支持对接实现sf4j接口的第三方日志框架。
+> - 支持容灾切换。
diff --git a/product/zh/docs-mogdb/v3.0/developer-guide/dev/2-development-based-on-jdbc/5-connecting-to-a-database.md b/product/zh/docs-mogdb/v3.0/developer-guide/dev/2-development-based-on-jdbc/5-connecting-to-a-database.md
index 9fcab44982601403f299d9cd569f632c5017a43c..bcff94c4c26d791b8967de9e1810de9a685aa7d1 100644
--- a/product/zh/docs-mogdb/v3.0/developer-guide/dev/2-development-based-on-jdbc/5-connecting-to-a-database.md
+++ b/product/zh/docs-mogdb/v3.0/developer-guide/dev/2-development-based-on-jdbc/5-connecting-to-a-database.md
@@ -27,8 +27,8 @@ JDBC提供了三个方法,用于创建数据库连接。
| 参数 | 描述 |
| :------- | :-------------- |
-| url | postgresql.jar数据库连接描述符。格式如下:
- jdbc:postgresql:database
- jdbc:postgresql://host/database
- jdbc:postgresql://host:port/database
- jdbc:postgresql://host:port/database?param1=value1¶m2=value2
- jdbc:postgresql://host1:port1,host2:port2/database?param1=value1¶m2=value2
说明:
- database为要连接的数据库名称。
- host为数据库服务器名称或IP地址。
连接MogDB的机器与MogDB不在同一网段时,host指定的IP地址应为Manager界面上所设的coo.cooListenIp2(应用访问IP)的取值。
由于安全原因,数据库主节点禁止MogDB内部其他节点无认证接入。如果要在MogDB内部访问数据库主节点,请将JDBC程序部署在数据库主节点所在机器,host使用"127.0.0.1"。否则可能会出现"FATAL: Forbid remote connection with trust method!"错误。
建议业务系统单独部署在MogDB外部,否则可能会影响数据库运行性能。
缺省情况下,连接服务器为localhost。
- port为数据库服务器端口。
缺省情况下,会尝试连接到5431端口的database。
- param为参数名称,即数据库连接属性。
参数可以配置在URL中,以"?"开始配置,以"="给参数赋值,以"&"作为不同参数的间隔。也可以采用info对象的属性方式进行配置,详细示例会在本节给出。
- value为参数值,即数据库连接属性值。|
-| info | 数据库连接属性。常用的属性如下:
- PGDBNAME: String类型。表示数据库名称。(URL中无需配置该参数,自动从URL中解析)
- PGHOST: String类型。主机IP地址。详细示例见下。
- PGPORT: Integer类型。主机端口号。详细示例见下。
- user: String类型。表示创建连接的数据库用户。
- password: String类型。表示数据库用户的密码。
- loggerLevel: String类型。目前支持3种级别: OFF、DEBUG、TRACE。设置为OFF关闭日志,设置为DEBUG和TRACE记录的日志信息详细程度不同。
- loggerFile: String类型。Logger输出的文件名。需要显示指定日志文件名,若未指定目录则生成在客户端运行程序目录。
- allowEncodingChanges: Boolean类型。设置该参数值为"true"进行字符集类型更改,配合characterEncoding=CHARSET设置字符集,二者使用"&"分隔。
- currentSchema: String类型。在search-path中指定要设置的schema。
- hostRecheckSeconds: Integer类型。JDBC尝试连接主机后会保存主机状态: 连接成功或连接失败。在hostRecheckSeconds时间内保持可信,超过则状态失效。缺省值是10秒。
- ssl: Boolean类型。以SSL方式连接。ssl=true可支持NonValidatingFactory通道和使用证书的方式:
1、NonValidatingFactory通道需要配置用户名和密码,同时将SSL设置为true。
2、配置客户端证书、密钥、根证书,将SSL设置为true。
- sslmode: String类型。SSL认证方式。取值范围为: require、verify-ca、verify-full。
- require只尝试SSL连接,如果存在CA文件,则应设置成verify-ca的方式验证。
- verify-ca只尝试SSL连接,并且验证服务器是否具有由可信任的证书机构签发的证书。
- verify-full只尝试SSL连接,并且验证服务器是否具有由可信任的证书机构签发的证书,以及验证服务器主机名是否与证书中的一致。
- sslcert: String类型。提供证书文件的完整路径。客户端和服务端证书的类型为End Entity。
- sslkey: String类型。提供密钥文件的完整路径。使用时将客户端证书转换为DER格式:
*openssl pkcs8 -topk8 -outform DER -in client.key -out client.key.pk8 -nocrypt*
- sslrootcert: String类型。SSL根证书的文件名。根证书的类型为CA。
- sslpassword: String类型。提供给ConsoleCallbackHandler使用。
- sslpasswordcallback: String类型。SSL密码提供者的类名。缺省值: org.postgresql.ssl.jdbc4.LibPQFactory.ConsoleCallbackHandler。
- sslfactory: String类型。提供的值是SSLSocketFactory在建立SSL连接时用的类名。
- sslfactoryarg: String类型。此值是上面提供的sslfactory类的构造函数的可选参数(不推荐使用)。
- sslhostnameverifier: String类型。主机名验证程序的类名。接口实现javax.net.ssl.HostnameVerifier,默认使用org.postgresql.ssl.PGjdbcHostnameVerifier。
- loginTimeout: Integer类型。指建立数据库连接的等待时间。超时时间单位为秒。
- connectTimeout: Integer类型。用于连接服务器操作的超时值。如果连接到服务器花费的时间超过此值,则连接断开。超时时间单位为秒,值为0时表示已禁用,timeout不发生。
- socketTimeout: Integer类型。用于socket读取操作的超时值。如果从服务器读取所花费的时间超过此值,则连接关闭。超时时间单位为秒,值为0时表示已禁用,timeout不发生。
- cancelSignalTimeout: Integer类型。发送取消消息本身可能会阻塞,此属性控制用于取消命令的"connect超时"和"socket超时"。超时时间单位为秒,默认值为10秒。
- tcpKeepAlive: Boolean类型。启用或禁用TCP保活探测功能。默认为false。
- logUnclosedConnections: Boolean类型。客户端可能由于未调用Connection对象的close()方法而泄漏Connection对象。最终这些对象将被垃圾回收,并且调用finalize()方法。如果调用者自己忽略了此操作,该方法将关闭Connection。
- assumeMinServerVersion: String类型。客户端会发送请求进行float精度设置。该参数设置要连接的服务器版本,如assumeMinServerVersion=9.0,可以在建立时减少相关包的发送。
- ApplicationName: String类型。设置正在使用连接的JDBC驱动的名称。通过在数据库主节点上查询pg_stat_activity表可以看到正在连接的客户端信息,JDBC驱动名称显示在application_name列。缺省值为PostgreSQL JDBC Driver。
- connectionExtraInfo: Boolean类型。表示驱动是否上报当前驱动的部署路径、进程属主用户到数据库。取值范围: true或false,默认值为false。设置connectionExtraInfo为true,JDBC驱动会将当前驱动的部署路径、进程属主用户上报到数据库中,记录在connection_info参数里;同时可以在PG_STAT_ACTIVITY中查询到。
- autosave: String类型。共有3种: "always", "never", "conservative"。如果查询失败,指定驱动程序应该执行的操作。在autosave=always模式下,JDBC驱动程序在每次查询之前设置一个保存点,并在失败时回滚到该保存点。在autosave=never模式(默认)下,无保存点。在autosave=conservative模式下,每次查询都会设置保存点,但是只会在"statement XXX无效"等情况下回滚并重试。
- protocolVersion: Integer类型。连接协议版本号,目前仅支持3。注意:设置该参数时将采用md5加密方式,需要同步修改数据库的加密方式: gs_guc set -N all -I all -c "password_encryption_type=1" ,重启MogDB生效后需要创建用md5方式加密口令的用户。同时修改pg_hba.conf,将客户端连接方式修改为md5。用新建用户进行登录(不推荐)。
- prepareThreshold: Integer类型。控制parse语句何时发送。默认值是5。第一次parse一个SQL比较慢,后面再parse就会比较快,因为有缓存了。如果一个会话连续多次执行同一个SQL,在达到prepareThreshold次数以上时,JDBC将不再对这个SQL发送parse命令。
- preparedStatementCacheQueries: Integer类型。确定每个连接中缓存的查询数,默认情况下是256。若在prepareStatement()调用中使用超过256个不同的查询,则最近最少使用的查询缓存将被丢弃。0表示禁用缓存。
- preparedStatementCacheSizeMiB: Integer类型。确定每个连接可缓存的最大值(以兆字节为单位),默认情况下是5。若缓存了超过5MB的查询,则最近最少使用的查询缓存将被丢弃。0表示禁用缓存。
- databaseMetadataCacheFields: Integer类型。默认值是65536。指定每个连接可缓存的最大值。"0"表示禁用缓存。
- databaseMetadataCacheFieldsMiB: Integer类型。默认值是5。每个连接可缓存的最大值,单位是MB。"0"表示禁用缓存。
- stringtype: String类型,可选字段为: false, "unspecified", "varchar"。设置通过setString()方法使用的PreparedStatement参数的类型,如果stringtype设置为VARCHAR(默认值),则这些参数将作为varchar参数发送给服务器。若stringtype设置为unspecified,则参数将作为untyped值发送到服务器,服务器将尝试推断适当的类型。
- batchMode: Boolean类型。用于确定是否使用batch模式连接。
- fetchsize: Integer类型。用于设置数据库连接所创建statement的默认fetchsize。
- reWriteBatchedInserts: Boolean类型。批量导入时,该参数设置为on,可将N条插入语句合并为一条: insert into TABLE_NAME values(values1, …, valuesN), …, (values1, …, valuesN);使用该参数时,需设置batchMode=off。
- unknownLength: Integer类型,默认为Integer.MAX_VALUE。某些postgresql类型(例如TEXT)没有明确定义的长度,当通过ResultSetMetaData.getColumnDisplaySize和ResultSetMetaData.getPrecision等函数返回关于这些类型的数据时,此参数指定未知长度类型的长度。
- defaultRowFetchSize: Integer类型。确定一次fetch在ResultSet中读取的行数。限制每次访问数据库时读取的行数可以避免不必要的内存消耗,从而避免OutOfMemoryException。缺省值是0,这意味着ResultSet中将一次获取所有行。没有负数。
- binaryTransfer: Boolean类型。使用二进制格式发送和接收数据,默认值为"false"。
- binaryTransferEnable: String类型。启用二进制传输的类型列表,以逗号分隔。OID编号和名称二选一,例如binaryTransferEnable=Integer4_ARRAY,Integer8_ARRAY。比如: OID名称为BLOB,编号为88,可以如下配置:
binaryTransferEnable=BLOB 或 binaryTransferEnable=88
- binaryTransferDisEnable: String类型。禁用二进制传输的类型列表,以逗号分隔。OID编号和名称二选一。覆盖binaryTransferEnable的设置。
- blobMode: String类型。用于设置setBinaryStream方法为不同类型的数据赋值,设置为on时表示为blob类型数据赋值,设置为off时表示为bytea类型数据赋值,默认为on。
- socketFactory: String类型。用于创建与服务器socket连接的类的名称。该类必须实现了接口"javax.net.SocketFactory",并定义无参或单String参数的构造函数。
- socketFactoryArg: String类型。此值是上面提供的socketFactory类的构造函数的可选参数,不推荐使用。
- receiveBufferSize: Integer类型。该值用于设置连接流上的SO_RCVBUF。
- sendBufferSize: Integer类型。该值用于设置连接流上的SO_SNDBUF。
- preferQueryMode: String类型。共有4种: "extended", "extendedForPrepared", "extendedCacheEverything", "simple"。用于指定执行查询的模式,simple模式会excute,不parse和bind;extended模式会bind和excute;extendedForPrepared模式为prepared statement扩展使用;extendedCacheEverything模式会缓存每个statement。
- targetServerType: String类型。共有4种: "any"、"master"、"slave"、"preferSlave"。 |
+| url | postgresql.jar数据库连接描述符。格式如下:
- jdbc:postgresql:database
- jdbc:postgresql://host/database
- jdbc:postgresql://host:port/database
- jdbc:postgresql://host:port/database?param1=value1¶m2=value2
- jdbc:postgresql://host1:port1,host2:port2/database?param1=value1¶m2=value2
说明:
- database为要连接的数据库名称。
- host为数据库服务器名称或IP地址。
连接MogDB的机器与MogDB不在同一网段时,host指定的IP地址应为Manager界面上所设的coo.cooListenIp2(应用访问IP)的取值。
由于安全原因,数据库主节点禁止MogDB内部其他节点无认证接入。如果要在MogDB内部访问数据库主节点,请将JDBC程序部署在数据库主节点所在机器,host使用"127.0.0.1"。否则可能会出现"FATAL: Forbid remote connection with trust method!"错误。
建议业务系统单独部署在MogDB外部,否则可能会影响数据库运行性能。
缺省情况下,连接服务器为localhost。
- port为数据库服务器端口。
缺省情况下,会尝试连接到5431端口的database。
- param为参数名称,即数据库连接属性。
参数可以配置在URL中,以"?"开始配置,以"="给参数赋值,以"&"作为不同参数的间隔。也可以采用info对象的属性方式进行配置,详细示例会在本节给出。
- value为参数值,即数据库连接属性值。
- 连接时需配置connectTimeout、socketTimeout,如果未配置,默认为0,即不会超时。在DN与客户端出现网络故障时,客户端一直未收到DN侧ACK确认报文,会启动超时重传机制,不断的进行重传。当超时时间达到系统默认的600s后才会报超时错误,这也就会导致RTO时间很高。 |
+| info | 数据库连接属性(所有属性大小写敏感)。常用的属性如下:
- PGDBNAME: String类型。表示数据库名称。(URL中无需配置该参数,自动从URL中解析)
- PGHOST: String类型。主机IP地址。详细示例见下。
- PGPORT: Integer类型。主机端口号。详细示例见下。
- user: String类型。表示创建连接的数据库用户。
- password: String类型。表示数据库用户的密码。
- enable_ce:String类型。其中enable_ce=1表示JDBC支持密态等值查询。
- loggerLevel: String类型。目前支持3种级别: OFF、DEBUG、TRACE。设置为OFF关闭日志,设置为DEBUG和TRACE记录的日志信息详细程度不同。
- loggerFile: String类型。Logger输出的文件名。需要显示指定日志文件名,若未指定目录则生成在客户端运行程序目录。
- allowEncodingChanges: Boolean类型。设置该参数值为"true"进行字符集类型更改,配合characterEncoding=CHARSET设置字符集,二者使用"&"分隔。
- currentSchema: String类型。在search-path中指定要设置的schema。
- hostRecheckSeconds: Integer类型。JDBC尝试连接主机后会保存主机状态: 连接成功或连接失败。在hostRecheckSeconds时间内保持可信,超过则状态失效。缺省值是10秒。
- ssl: Boolean类型。以SSL方式连接。
ssl=true可支持NonValidatingFactory通道和使用证书的方式:
1、NonValidatingFactory通道需要配置用户名和密码,同时将SSL设置为true。
2、配置客户端证书、密钥、根证书,将SSL设置为true。
- sslmode: String类型。SSL认证方式。取值范围为: require、verify-ca、verify-full。
- require只尝试SSL连接,如果存在CA文件,则应设置成verify-ca的方式验证。
- verify-ca只尝试SSL连接,并且验证服务器是否具有由可信任的证书机构签发的证书。
- verify-full只尝试SSL连接,并且验证服务器是否具有由可信任的证书机构签发的证书,以及验证服务器主机名是否与证书中的一致。
- sslcert: String类型。提供证书文件的完整路径。客户端和服务端证书的类型为End Entity。
- sslkey: String类型。提供密钥文件的完整路径。使用时将客户端证书转换为DER格式:
`openssl pkcs8 -topk8 -outform DER -in client.key -out client.key.pk8 -nocrypt`
- sslrootcert: String类型。SSL根证书的文件名。根证书的类型为CA。
- sslpassword: String类型。提供给ConsoleCallbackHandler使用。
- sslpasswordcallback: String类型。SSL密码提供者的类名。缺省值: org.postgresql.ssl.jdbc4.LibPQFactory.ConsoleCallbackHandler。
- sslfactory: String类型。提供的值是SSLSocketFactory在建立SSL连接时用的类名。
- sslfactoryarg: String类型。此值是上面提供的sslfactory类的构造函数的可选参数(不推荐使用)。
- sslhostnameverifier: String类型。主机名验证程序的类名。接口实现javax.net.ssl.HostnameVerifier,默认使用org.postgresql.ssl.PGjdbcHostnameVerifier。
- loginTimeout: Integer类型。指建立数据库连接的等待时间。超时时间单位为秒。
- connectTimeout: Integer类型。用于连接服务器操作的超时值。如果连接到服务器花费的时间超过此值,则连接断开。超时时间单位为秒,值为0时表示已禁用,timeout不发生。
- socketTimeout: Integer类型。用于socket读取操作的超时值。如果从服务器读取所花费的时间超过此值,则连接关闭。超时时间单位为秒,值为0时表示已禁用,timeout不发生。
- cancelSignalTimeout: Integer类型。发送取消消息本身可能会阻塞,此属性控制用于取消命令的"connect超时"和"socket超时"。超时时间单位为秒,默认值为10秒。
- tcpKeepAlive: Boolean类型。启用或禁用TCP保活探测功能。默认为false。
- logUnclosedConnections: Boolean类型。客户端可能由于未调用Connection对象的close()方法而泄漏Connection对象。最终这些对象将被垃圾回收,并且调用finalize()方法。如果调用者自己忽略了此操作,该方法将关闭Connection。
- assumeMinServerVersion: String类型。客户端会发送请求进行float精度设置。该参数设置要连接的服务器版本,如assumeMinServerVersion=9.0,可以在建立时减少相关包的发送。
- ApplicationName: String类型。设置正在使用连接的JDBC驱动的名称。通过在数据库主节点上查询pg_stat_activity表可以看到正在连接的客户端信息,JDBC驱动名称显示在application_name列。缺省值为PostgreSQL JDBC Driver。
- connectionExtraInfo: Boolean类型。表示驱动是否上报当前驱动的部署路径、进程属主用户到数据库。取值范围: true或false,默认值为false。设置connectionExtraInfo为true,JDBC驱动会将当前驱动的部署路径、进程属主用户上报到数据库中,记录在connection_info参数里;同时可以在PG_STAT_ACTIVITY中查询到。
- autosave: String类型。共有3种: "always", "never", "conservative"。如果查询失败,指定驱动程序应该执行的操作。在autosave=always模式下,JDBC驱动程序在每次查询之前设置一个保存点,并在失败时回滚到该保存点。在autosave=never模式(默认)下,无保存点。在autosave=conservative模式下,每次查询都会设置保存点,但是只会在"statement XXX无效"等情况下回滚并重试。
- protocolVersion: Integer类型。连接协议版本号,目前仅支持3。注意:设置该参数时将采用md5加密方式,需要同步修改数据库的加密方式:gs_guc set -N all -I all -c "password_encryption_type=1" ,重启MogDB生效后需要创建用md5方式加密口令的用户。同时修改pg_hba.conf,将客户端连接方式修改为md5。用新建用户进行登录(不推荐)。
说明:
MD5加密算法安全性低,存在安全风险,建议使用更安全的加密算法。
- prepareThreshold: Integer类型。控制parse语句何时发送。默认值是5。第一次parse一个SQL比较慢,后面再parse就会比较快,因为有缓存了。如果一个会话连续多次执行同一个SQL,在达到prepareThreshold次数以上时,JDBC将不再对这个SQL发送parse命令。
- preparedStatementCacheQueries: Integer类型。确定每个连接中缓存的查询数,默认情况下是256。若在prepareStatement()调用中使用超过256个不同的查询,则最近最少使用的查询缓存将被丢弃。0表示禁用缓存。
- preparedStatementCacheSizeMiB: Integer类型。确定每个连接可缓存的最大值(以兆字节为单位),默认情况下是5。若缓存了超过5MB的查询,则最近最少使用的查询缓存将被丢弃。0表示禁用缓存。
- databaseMetadataCacheFields: Integer类型。默认值是65536。指定每个连接可缓存的最大值。"0"表示禁用缓存。
- databaseMetadataCacheFieldsMiB: Integer类型。默认值是5。每个连接可缓存的最大值,单位是MB。"0"表示禁用缓存。
- stringtype: String类型,可选字段为: false, "unspecified", "varchar"。设置通过setString()方法使用的PreparedStatement参数的类型,如果stringtype设置为VARCHAR(默认值),则这些参数将作为varchar参数发送给服务器。若stringtype设置为unspecified,则参数将作为untyped值发送到服务器,服务器将尝试推断适当的类型。
- batchMode: Boolean类型。用于确定是否使用batch模式连接。默认值为on,表示开启batch模式。
- fetchsize: Integer类型。用于设置数据库连接所创建statement的默认fetchsize。默认值为0,表示一次获取所有结果。
- reWriteBatchedInserts: Boolean类型。批量导入时,该参数设置为on,可将N条插入语句合并为一条: insert into TABLE_NAME values(values1, …, valuesN), …, (values1, …, valuesN);使用该参数时,需设置batchMode=off。
- unknownLength: Integer类型,默认为Integer.MAX_VALUE。某些postgresql类型(例如TEXT)没有明确定义的长度,当通过ResultSetMetaData.getColumnDisplaySize和ResultSetMetaData.getPrecision等函数返回关于这些类型的数据时,此参数指定未知长度类型的长度。
- defaultRowFetchSize: Integer类型。确定一次fetch在ResultSet中读取的行数。限制每次访问数据库时读取的行数可以避免不必要的内存消耗,从而避免OutOfMemoryException。缺省值是0,这意味着ResultSet中将一次获取所有行。没有负数。
- binaryTransfer: Boolean类型。使用二进制格式发送和接收数据,默认值为"false"。
- binaryTransferEnable: String类型。启用二进制传输的类型列表,以逗号分隔。OID编号和名称二选一,例如binaryTransferEnable=Integer4_ARRAY,Integer8_ARRAY。比如:OID名称为BLOB,编号为88,可以如下配置:
binaryTransferEnable=BLOB 或 binaryTransferEnable=88
- binaryTransferDisEnable: String类型。禁用二进制传输的类型列表,以逗号分隔。OID编号和名称二选一。覆盖binaryTransferEnable的设置。
- blobMode: String类型。用于设置setBinaryStream方法为不同类型的数据赋值,设置为on时表示为blob类型数据赋值,设置为off时表示为bytea类型数据赋值,默认为on。
- socketFactory: String类型。用于创建与服务器socket连接的类的名称。该类必须实现了接口"javax.net.SocketFactory",并定义无参或单String参数的构造函数。
- socketFactoryArg: String类型。此值是上面提供的socketFactory类的构造函数的可选参数,不推荐使用。
- receiveBufferSize: Integer类型。该值用于设置连接流上的SO_RCVBUF。
- sendBufferSize: Integer类型。该值用于设置连接流上的SO_SNDBUF。
- preferQueryMode: String类型。共有4种: "extended", "extendedForPrepared", "extendedCacheEverything", "simple"。用于指定执行查询的模式,simple模式会excute,不parse和bind;extended模式会bind和excute;extendedForPrepared模式为prepared statement扩展使用;extendedCacheEverything模式会缓存每个statement。
- targetServerType: String类型。该参数识别主备数据节点是通过查询URL连接串中,数据节点是否允许写操作来实现的,默认为“any”。共有四种:“any”、“master”、“slave”、“preferSlave”:
1. master则尝试连接到URL连接串中的主节点,如果找不到就抛出异常。
2. slave则尝试连接到URL连接串中的备节点,如果找不到就抛出异常。
3. preferSlave则尝试连接到URL连接串中的备数据节点(如果有可用的话),否则连接到主数据节点。
4. any则尝试连接URL连接串中的任何一个数据节点。
- priorityServers:Integer类型。此值用于指定url上配置的前n个节点作为主集群被优先连接。默认值为null。该值为数字,大于0,且小于url上配置的DN数量。例如:jdbc:postgresql://host1:port1,host2:port2,host3:port3,host4:port4,/database?priorityServers=2。即表示host1与host2为主集群节点,host3与host4为容灾集群节点。
- forceTargetServerSlave:Boolean类型。此值用于控制是否开启强制连接备机功能,并在集群发生主备切换时,禁止已存在的连接在升主备机上继续使用。默认值为false,表示不开启强制连接备机功能。true,表示开启强制连接备机功能。 |
| user | 数据库用户。 |
| password | 数据库用户的密码。 |
diff --git a/product/zh/docs-mogdb/v3.0/developer-guide/dev/2-development-based-on-jdbc/6-connecting-to-a-database-using-ssl.md b/product/zh/docs-mogdb/v3.0/developer-guide/dev/2-development-based-on-jdbc/6-connecting-to-a-database-using-ssl.md
index c3f733fe73c0afdfc9b34f2603785c4cb499b917..578994e596b97abd629fca17dec74c1b7c4e1d37 100644
--- a/product/zh/docs-mogdb/v3.0/developer-guide/dev/2-development-based-on-jdbc/6-connecting-to-a-database-using-ssl.md
+++ b/product/zh/docs-mogdb/v3.0/developer-guide/dev/2-development-based-on-jdbc/6-connecting-to-a-database-using-ssl.md
@@ -21,7 +21,7 @@ date: 2021-04-26
2. 生成并配置证书
- 生成SSL证书,具体请参见"证书生成"。将生成出的文件server.crt,server.key,cacert.pem拷贝到服务端数据目录下。
+ 生成SSL证书,具体请参见[证书生成](1-client-access-authentication#证书生成)。将生成出的文件server.crt,server.key,cacert.pem拷贝到服务端数据目录下。
使用如下命令可以查询数据库节点的数据目录,instance列为数据目录。
@@ -51,7 +51,9 @@ date: 2021-04-26
表示允许127.0.0.1/32网段的客户端以ssl认证方式连接到MogDB服务器。
>  **须知:**
- > 如果服务端pg_hba.conf文件中METHOD配置为cert,则只有客户端使用证书(client.crt)中所设置的用户名(common name)才能够成功连接数据库。如果设置为md5或sha256则对连接数据库的用户没有限制。
+ >
+ > - 如果服务端pg_hba.conf文件中METHOD配置为cert,则只有客户端使用证书(client.crt)中所设置的用户名(common name)才能够成功连接数据库。如果设置为md5或sha256则对连接数据库的用户没有限制。
+ > - MD5加密算法安全性低,存在安全风险,建议使用更安全的加密算法。
5. 配置SSL认证相关的数字证书参数。
@@ -78,8 +80,6 @@ date: 2021-04-26
gs_om -t stop && gs_om -t start
```
-7. 生成并上传证书文件
-
## 客户端配置
@@ -92,46 +92,37 @@ date: 2021-04-26
## 示例
-```java
-import java.sql.Connection;
-import java.util.Properties;
-import java.sql.DriverManager;
-import java.sql.Statement;
-import java.sql.ResultSet;
+注:示例1和示例2选择其一。
+```java
public class SSL{
public static void main(String[] args) {
Properties urlProps = new Properties();
String urls = "jdbc:postgresql://10.29.37.136:8000/postgres";
/**
- * ================== 示例1 使用NonValidatingFactory通道,pg_hba.conf文件中MTETHOD不为cert
+ * ================== 示例1 使用NonValidatingFactory通道
*/
-/*
urlProps.setProperty("sslfactory","org.postgresql.ssl.NonValidatingFactory");
urlProps.setProperty("user", "world");
- //此处的test@123为创建用户CRETAE USER world WITH PASSWORD 'test123@'时指定的密码
urlProps.setProperty("password", "test@123");
urlProps.setProperty("ssl", "true");
-*/
/**
- * ================== 示例2 - 5 使用证书,pg_hba.conf文件中MTETHOD为cert
+ * ================== 示例2 使用证书
*/
urlProps.setProperty("sslcert", "client.crt");
- // DER格式的客户端秘钥
urlProps.setProperty("sslkey", "client.key.pk8");
urlProps.setProperty("sslrootcert", "cacert.pem");
urlProps.setProperty("user", "world");
- /* ================== 示例2 设置ssl为true,使用证书认证 */
urlProps.setProperty("ssl", "true");
- /* ================== 示例3 设置sslmode为require,使用证书 */
-// urlProps.setProperty("sslmode", "require");
- /* ================== 示例4 设置sslmode为verify-ca,使用证书 */
-// urlProps.setProperty("sslmode", "verify-ca");
- /* ================== 示例5 设置sslmode为verify-full,使用证书(Linux下验证) */
-// urls = "jdbc:postgresql://world:8000/postgres";
-// urlProps.setProperty("sslmode", "verify-full");
-
+ /* sslmode可配置为:require、verify-ca、verify-full,以下三个示例选择其一*/
+ /* ================== 示例2.1 设置sslmode为require,使用证书 */
+ urlProps.setProperty("sslmode", "require");
+ /* ================== 示例2.2 设置sslmode为verify-ca,使用证书 */
+ urlProps.setProperty("sslmode", "verify-ca");
+ /* ================== 示例2.3 设置sslmode为verify-full,使用证书(Linux下验证) */
+ urls = "jdbc:postgresql://world:8000/postgres";
+ urlProps.setProperty("sslmode", "verify-full");
try {
Class.forName("org.postgresql.Driver").newInstance();
} catch (Exception e) {
@@ -146,4 +137,16 @@ public class SSL{
}
}
}
+/**
+ * 注:将客户端密钥转化为DER格式:
+ * openssl pkcs8 -topk8 -outform DER -in client.key -out client.key.pk8 -nocrypt
+ * openssl pkcs8 -topk8 -inform PEM -in client.key -outform DER -out client.key.der -v1 PBE-MD5-DES
+ * openssl pkcs8 -topk8 -inform PEM -in client.key -outform DER -out client.key.der -v1 PBE-SHA1-3DES
+ * 以上算法由于安全级别较低,不推荐使用。
+ * 如果客户需要采用更高级别的私钥加密算法,启用bouncycastle或者其他第三方私钥解密密码包后可以使用的私钥加密算法如下:
+ * openssl pkcs8 -in client.key -topk8 -outform DER -out client.key.der -v2 AES128
+ * openssl pkcs8 -in client.key -topk8 -outform DER -out client.key.der -v2 aes-256-cbc -iter 1000000
+ * openssl pkcs8 -in client.key -topk8 -out client.key.der -outform Der -v2 aes-256-cbc -v2prf hmacWithSHA512
+ * 启用bouncycastle:使用jdbc的项目引入依赖:bcpkix-jdk15on.jar包,版本建议:1.65以上。
+ */
```
diff --git a/product/zh/docs-mogdb/v3.0/developer-guide/dev/2-development-based-on-jdbc/7-running-sql-statements.md b/product/zh/docs-mogdb/v3.0/developer-guide/dev/2-development-based-on-jdbc/7-running-sql-statements.md
index a4ee1896eb6c977ee8f14c99d1140f2083d75de9..70a66c6cd5cfc10fd837e79613d987740918c207 100644
--- a/product/zh/docs-mogdb/v3.0/developer-guide/dev/2-development-based-on-jdbc/7-running-sql-statements.md
+++ b/product/zh/docs-mogdb/v3.0/developer-guide/dev/2-development-based-on-jdbc/7-running-sql-statements.md
@@ -27,7 +27,10 @@ date: 2021-06-07
```
> **说明:**
- > 数据库中收到的一次执行请求(不在事务块中),如果含有多条语句,将会被打包成一个事务,事务块中不支持vacuum操作。如果其中有一个语句失败,那么整个请求都将会被回滚。
+ >
+ > - 数据库中收到的一次执行请求(不在事务块中),如果含有多条语句,将会被打包成一个事务,事务块中不支持vacuum操作。如果其中有一个语句失败,那么整个请求都将会被回滚。
+ > - 使用Statement执行多语句时应以“;”作为各语句间的分隔符,存储过程、函数、匿名块不支持多语句执行。
+ > - “/”可用作创建单个存储过程、函数、匿名块的结束符。
3. 关闭语句对象。
@@ -140,6 +143,82 @@ MogDB支持通过JDBC直接调用事先创建的存储过程,步骤如下:
> - 当游标作为存储过程的返回值时,如果使用JDBC调用该存储过程,返回的游标将不可用。
>
> - 存储过程不能和普通SQL在同一条语句中执行。
+ >
+ > - 存储过程中inout类型参数必需注册出参。
+
+
+
+## Oracle兼容模式启用重载时,调用存储过程
+
+打开参数behavior_compat_options='proc_outparam_override'后,JDBC调用事先创建的存储过程,步骤如下:
+
+1. 调用Connection的prepareCall方法创建调用语句对象。
+
+ ```
+ Connection conn = DriverManager.getConnection("url","user","password");
+ CallableStatement cs = conn.prepareCall("{ CALL TEST_PROC(?,?,?) }");
+ ```
+
+2. 调用CallableStatement的setInt方法设置参数。
+
+ ```
+ PGobject pGobject = new PGobject();
+ pGobject.setType("public.compfoo"); // 设置复合类型名,格式为“schema.typename”。
+ pGobject.setValue("(1,demo)"); // 绑定复合类型值,格式为“(value1,value2)”。
+ cs.setObject(1, pGobject);
+ ```
+
+3. 调用CallableStatement的registerOutParameter方法注册输出参数。
+
+ ```
+ // 注册out类型的参数,类型为复合类型,格式为“schema.typename”。
+ cs.registerOutParameter(2, Types.STRUCT, "public.compfoo");
+ ```
+
+4. 调用CallableStatement的execute执行方法调用。
+
+ ```
+ cs.execute();
+ ```
+
+5. 调用CallableStatement的getObject方法获取输出参数。
+
+ ```
+ PGobject result = (PGobject)cs.getObject(2); // 获取out参数
+ result.getValue(); // 获取复合类型字符串形式值。
+ result.getArrayValue(); //获取复合类型数组形式值,以复合数据类型字段顺序排序。
+ result.getStruct(); //获取复合类型子类型名,按创建顺序排序。
+ ```
+
+6. 调用CallableStatement的close方法关闭调用语句。
+
+ ```
+ cs.close();
+ ```
+
+ > **说明:**
+ >
+ > - oracle兼容模式开启参数后,调用存储过程必须使用{call proc_name(?,?,?)}形式调用,调用函数必须使用{? = call func_name(?,?)}形式调用(等号左侧的“?”为函数返回值的占位符,用于注册函数返回值)。
+ > - 参数behavior_compat_options='proc_outparam_override'行为变更后,业务需要重新建立连接,否则无法正确调用存储过程和函数。
+ > - 函数和存储过程中包含复合类型时,参数的绑定与注册需要使用schema.typename形式。
+
+示例:
+
+```
+// 在数据库创建复合数据类型。
+CREATE TYPE compfoo AS (f1 int, f3 text);
+// 在数据库中已创建了如下存储过程,它带有out参数。
+create or replace procedure test_proc
+(
+ psv_in in compfoo,
+ psv_out out compfoo
+)
+as
+begin
+ psv_out := psv_in;
+end;
+/
+```
diff --git a/product/zh/docs-mogdb/v3.0/developer-guide/dev/2-development-based-on-jdbc/8-processing-data-in-a-result-set.md b/product/zh/docs-mogdb/v3.0/developer-guide/dev/2-development-based-on-jdbc/8-processing-data-in-a-result-set.md
index 9e33d223708fbc5aefd4eb551c00b5a1a6b08e77..7d081f1d7ddc33fcbcb16d1b313e810391891470 100644
--- a/product/zh/docs-mogdb/v3.0/developer-guide/dev/2-development-based-on-jdbc/8-processing-data-in-a-result-set.md
+++ b/product/zh/docs-mogdb/v3.0/developer-guide/dev/2-development-based-on-jdbc/8-processing-data-in-a-result-set.md
@@ -28,7 +28,7 @@ prepareCall(String sql, int resultSetType, int resultSetConcurrency);
| 参数 | 描述 |
| :------------------- | :-------------------------|
-| resultSetType | 表示结果集的类型,具体有三种类型:
- ResultSet.TYPE_FORWARD_ONLY: ResultSet只能向前移动。是缺省值。
- ResultSet.TYPE_SCROLL_SENSITIVE: 在修改后重新滚动到修改所在行,可以看到修改后的结果。
- ResultSet.TYPE_SCROLL_INSENSITIVE: 对可修改例程所做的编辑不进行显示。
说明:
结果集从数据库中读取了数据之后,即使类型是ResultSet.TYPE_SCROLL_SENSITIVE,也不会看到由其他事务在这之后引起的改变。调用ResultSet的refreshRow()方法,可进入数据库并从其中取得当前游标所指记录的最新数据。 |
+| resultSetType | 表示结果集的类型,具体有三种类型:
- ResultSet.TYPE_FORWARD_ONLY:ResultSet只能向前移动。是缺省值。
- ResultSet.TYPE_SCROLL_SENSITIVE:在修改后重新滚动到修改所在行,可以看到修改后的结果。
- ResultSet.TYPE_SCROLL_INSENSITIVE:对可修改例程所做的编辑不进行显示。
说明:
结果集从数据库中读取了数据之后,即使类型是ResultSet.TYPE_SCROLL_SENSITIVE,也不会看到由其他事务在这之后引起的改变。调用ResultSet的refreshRow()方法,可进入数据库并从其中取得当前游标所指记录的最新数据。 |
| resultSetConcurrency | 表示结果集的并发,具体有两种类型:
- ResultSet.CONCUR_READ_ONLY: 如果不从结果集中的数据建立一个新的更新语句,不能对结果集中的数据进行更新。
- ResultSet.CONCUR_UPDATEABLE: 可改变的结果集。对于可滚动的结果集,可对结果集进行适当的改变。 |
diff --git a/product/zh/docs-mogdb/v3.0/developer-guide/dev/2-development-based-on-jdbc/8.1-log-management.md b/product/zh/docs-mogdb/v3.0/developer-guide/dev/2-development-based-on-jdbc/8.1-log-management.md
index 10d2e1a124c773f6119be4cc4f2d3188560ffad2..9438e915fcb885c53e513936e9812dc8d81583fd 100644
--- a/product/zh/docs-mogdb/v3.0/developer-guide/dev/2-development-based-on-jdbc/8.1-log-management.md
+++ b/product/zh/docs-mogdb/v3.0/developer-guide/dev/2-development-based-on-jdbc/8.1-log-management.md
@@ -2,55 +2,30 @@
title: 日志管理
summary: 日志管理
author: Zhang Cuiping
-date: 2021-10-11
+date: 2022-04-23
---
# 日志管理
-MogDB JDBC驱动程序支持使用日志记录来帮助解决在应用程序中使用MogDB JDBC驱动程序时的问题。MogDB JDBC支持如下三种日志管理方式:
+MogDB JDBC驱动程序支持使用日志记录来帮助解决在应用程序中使用MogDB JDBC驱动程序时的问题。MogDB JDBC支持如下两种日志管理方式:
-1. 使用连接属性指定临时日志文件。
-2. 对接应用程序使用的SLF4J日志框架。
-3. 对接应用程序使用的JdkLogger日志框架。
+1. 对接应用程序使用的SLF4J日志框架。
+2. 对接应用程序使用的JdkLogger日志框架。
SLF4J和JdkLogger是业界Java应用程序日志管理的主流框架,描述应用程序如何使用这些框架超出了本文范围,用户请参考对应的官方文档
- SLF4J:
- JdkLogger
-方式一:使用连接属性。
-
-url上配置loggerLevel和loggerFile。
-
-此种方式,配置简单,适用于调试驱动,但不支持日志级别、文件大小、文件数量管控,若日志不及时手动处理,会占满磁盘,因此,除调试驱动,不建议用此方式管理日志。
-
-示例:
-
-```
-public static Connection GetConnection(String username, String passwd){
-
- String sourceURL = "jdbc:postgresql://10.10.0.13:8000/postgres?loggerLevel=DEBUG&loggerFile=gsjdbc.log";
- Connection conn = null;
-
- try{
- //创建连接
- conn = DriverManager.getConnection(sourceURL,username,passwd);
- System.out.println("Connection succeed!");
- }catch (Exception e){
- e.printStackTrace();
- return null;
- }
- return conn;
-}
-```
-
-方式二:对接应用程序的SLF4J日志框架。
+方式一:对接应用程序的SLF4J日志框架。
在建立连接时,url配置logger=Slf4JLogger。
可采用Log4j或Log4j2来实现SLF4J。当采用Log4j实现SLF4J,需要添加如下jar包:log4j-\*.jar、slf4j-api-\*.jar、slf4j-log4\*-\*.jar,(\*区分版本),和配置文件:log4j.properties。若采用Log4j2实现SLF4J,需要添加如下jar包:log4j-api-\*.jar、log4j-core-\*.jar、log4j-slf4j18-impl-\*.jar、slf4j-api-*-alpha1.jar(\*区分版本),和配置文件:log4j2.xml。
-此方式支持日志管控。SLF4J可通过文件中的相关配置实现强大的日志管控功能,建议使用此方式进行日志管理。注意:此方式依赖slf4j的通用API接口,如org.slf4j.LoggerFactory.getLogger(String name)、org.slf4j.Logger.debug(String var1)、org.slf4j.Logger.info(String var1)、org.slf4j.Logger.warn(String warn)、org.slf4j.Logger.warn(String warn)等,若以上接口发生变更,日志将无法打印。
+此方式支持日志管控。SLF4J可通过文件中的相关配置实现强大的日志管控功能,建议使用此方式进行日志管理。
+
+> 注意:此方式依赖slf4j的通用API接口,如org.slf4j.LoggerFactory.getLogger(String name)、org.slf4j.Logger.debug(String var1)、org.slf4j.Logger.info(String var1)、org.slf4j.Logger.warn(String warn)、org.slf4j.Logger.warn(String warn)等,若以上接口发生变更,日志将无法打印。
示例:
@@ -122,7 +97,7 @@ log4j2.xml示例:
```
-方式三:对接应用程序使用的JdkLogger日志框架。
+方式二:对接应用程序使用的JdkLogger日志框架。
默认的Java日志记录框架将其配置存储在名为logging.properties的文件中。Java会在Java安装目录的文件夹中安装全局配置文件。logging.properties文件也可以创建并与单个项目一起存储。
@@ -143,3 +118,114 @@ java.util.logging.FileHandler.count = 30
java.util.logging.FileHandler.formatter = java.util.logging.SimpleFormatter
java.util.logging.FileHandler.append=false
```
+
+代码中使用示例:
+
+```
+System.setProperty("java.util.logging.FileHandler.pattern","jdbc.log");
+FileHandler fileHandler = new FileHandler(System.getProperty("java.util.logging.FileHandler.pattern"));
+Formatter formatter = new SimpleFormatter();
+fileHandler.setFormatter(formatter);
+Logger logger = Logger.getLogger("org.postgresql");
+logger.addHandler(fileHandler);
+logger.setLevel(Level.ALL);
+logger.setUseParentHandlers(false);
+```
+
+## 链路跟踪功能
+
+MogDB JDBC驱动程序提供了应用到数据库的链路跟踪功能,用于将数据库端离散的SQL和应用程序的请求关联起来。该功能需要应用开发者实现org.postgresql.log.Tracer接口类,并在url中指定接口实现类的全限定名。
+
+url示例:
+
+```
+String URL = "jdbc:postgresql://127.0.0.1:8000/postgres?traceInterfaceClass=xxx.xxx.xxx.OpenGaussTraceImpl";
+```
+
+org.postgresql.log.Tracer接口类定义如下:
+
+```
+public interface Tracer {
+// Retrieves the value of traceId.
+String getTraceId();
+}
+```
+
+org.postgresql.log.Tracer接口实现类示例:
+
+```
+import org.postgresql.log.Tracer;
+
+public class OpenGaussTraceImpl implements Tracer {
+ private static MDC mdc = new MDC();
+
+ private final String TRACE_ID_KEY = "traceId";
+
+ public void set(String traceId) {
+ mdc.put(TRACE_ID_KEY, traceId);
+ }
+
+ public void reset() {
+ mdc.clear();
+ }
+
+ @Override
+ public String getTraceId() {
+ return mdc.get(TRACE_ID_KEY);
+ }
+}
+```
+
+上下文映射示例,用于存放不同请求的生成的traceId。
+
+```
+import java.util.HashMap;
+
+public class MDC {
+ static final private ThreadLocal> threadLocal = new ThreadLocal<>();
+
+ public void put(String key, String val) {
+ if (key == null || val == null) {
+ throw new IllegalArgumentException("key or val cannot be null");
+ } else {
+ if (threadLocal.get() == null) {
+ threadLocal.set(new HashMap<>());
+ }
+ threadLocal.get().put(key, val);
+ }
+ }
+
+ public String get(String key) {
+ if (key == null) {
+ throw new IllegalArgumentException("key cannot be null");
+ } else if (threadLocal.get() == null) {
+ return null;
+ } else {
+ return threadLocal.get().get(key);
+ }
+ }
+
+ public void clear() {
+ if (threadLocal.get() == null) {
+ return;
+ } else {
+ threadLocal.get().clear();
+ }
+ }
+}
+```
+
+业务使用traceId示例。
+
+```
+String traceId = UUID.randomUUID().toString().replaceAll("-", "");
+openGaussTrace.set(traceId);
+pstm = con.prepareStatement("select * from test_trace_id where id = ?");
+pstm.setInt(1, 1);
+pstm.execute();
+pstm = con.prepareStatement("insert into test_trace_id values(?,?)");
+pstm.setInt(1, 2);
+pstm.setString(2, "test");
+pstm.execute();
+openGaussTrace.reset();
+```
diff --git a/product/zh/docs-mogdb/v3.0/developer-guide/dev/2-development-based-on-jdbc/9-closing-a-connection.md b/product/zh/docs-mogdb/v3.0/developer-guide/dev/2-development-based-on-jdbc/9-closing-a-connection.md
index 588c5b611668b49179e729046ad059a6d0636798..6fac602456626be06c612ee6eb37bd663d4132cb 100644
--- a/product/zh/docs-mogdb/v3.0/developer-guide/dev/2-development-based-on-jdbc/9-closing-a-connection.md
+++ b/product/zh/docs-mogdb/v3.0/developer-guide/dev/2-development-based-on-jdbc/9-closing-a-connection.md
@@ -9,4 +9,9 @@ date: 2021-06-07
在使用数据库连接完成相应的数据操作后,需要关闭数据库连接。
-关闭数据库连接可以直接调用其close方法即可。如:**Connection conn = DriverManager.getConnection(“url”,“user”,“password”) ; conn.close()**;
+关闭数据库连接可以直接调用其close方法。例如:
+
+```
+Connection conn = DriverManager.getConnection\("url","user","password"\) ;
+conn.close\(\);
+```
diff --git a/product/zh/docs-mogdb/v3.0/developer-guide/dev/3-development-based-on-odbc/3-configuring-a-data-source-in-the-linux-os.md b/product/zh/docs-mogdb/v3.0/developer-guide/dev/3-development-based-on-odbc/3-configuring-a-data-source-in-the-linux-os.md
index e0b60066799a2a9f642b979b855bf1f3c6af39ef..c072f06d86a5eed4f7218eadfb42bf5d984813bf 100644
--- a/product/zh/docs-mogdb/v3.0/developer-guide/dev/3-development-based-on-odbc/3-configuring-a-data-source-in-the-linux-os.md
+++ b/product/zh/docs-mogdb/v3.0/developer-guide/dev/3-development-based-on-odbc/3-configuring-a-data-source-in-the-linux-os.md
@@ -13,7 +13,11 @@ date: 2021-06-16
## 操作步骤
-1. 获取unixODBC源码包。获取参考地址: 下载后请先按照社区提供的完整性校验算法进行完整性校验。
+1. 获取unixODBC源码包。
+
+ 获取参考地址:
+
+ 下载后请先按照社区提供的完整性校验算法进行完整性校验。
2. 安装unixODBC。如果机器上已经安装了其他版本的unixODBC,可以直接覆盖安装。
@@ -25,7 +29,7 @@ date: 2021-06-16
#修改configure文件(如果不存在,那么请修改configure.ac),找到LIB_VERSION
#将它的值修改为"1:0:0",这样将编译出*.so.1的动态库,与psqlodbcw.so的依赖关系相同。
vim configure
-
+
./configure --enable-gui=no #如果要在鲲鹏服务器上编译,请追加一个configure参数: --build=aarch64-unknown-linux-gnu
make
#安装可能需要root权限
@@ -34,31 +38,31 @@ date: 2021-06-16
3. 替换客户端openGauss驱动程序。
- a. 将openGauss-1.1.0-ODBC.tar.gz解压到"/usr/local/lib"目录下。解压会得 到"psqlodbcw.la"和"psqlodbcw.so"两个文件。
+ a. 将openGauss-1.1.0-ODBC.tar.gz解压。解压后会得到两个文件夹:lib与odbc,在odbc文件夹中还会有一个lib文件夹。/odbc/lib中会有“psqlodbca.la”,“psqlodbca.so”,“psqlodbcw.la”和“psqlodbcw.so”四个文件,将这四个文件拷贝到“/usr/local/lib”目录下。
- b. 将openGauss-1.1.0-ODBC.tar.gz解压后lib目录中的库拷贝到"/usr/local/lib"目录下。
+ b. 将openGauss-1.1.0-ODBC.tar.gz解压后lib目录中的库拷贝到“/usr/local/lib”目录下。
4. 配置数据源。
a. 配置ODBC驱动文件。
- 在`/xxx/odbc/etc/odbcinst.ini`文件中追加以下内容。
+ 在`/usr/local/etc/odbcinst.ini`文件中追加以下内容。
```bash
[GaussMPP]
- Driver64=/xxx/odbc/lib/psqlodbcw.so
- setup=/xxx/odbc/lib/psqlodbcw.so
+ Driver64=/usr/local/lib/psqlodbcw.so
+ setup=/usr/local/lib/psqlodbcw.so
```
odbcinst.ini文件中的配置参数说明如[表1](#odbcinst.ini)所示。
**表 1** odbcinst.ini文件配置参数
- | **参数** | **描述** | **示例** |
- | :----------- | :------------------------------------------- | :---------------------------------- |
- | [DriverName] | 驱动器名称,对应数据源DSN中的驱动名。 | [DRIVER_N] |
- | Driver64 | 驱动动态库的路径。 | Driver64=/xxx/odbc/lib/psqlodbcw.so |
- | setup | 驱动安装路径,与Driver64中动态库的路径一致。 | setup=/xxx/odbc/lib/psqlodbcw.so |
+ | **参数** | **描述** | **示例** |
+ | :----------- | :------------------------------------------- | :----------------------------------- |
+ | [DriverName] | 驱动器名称,对应数据源DSN中的驱动名。 | [DRIVER_N] |
+ | Driver64 | 驱动动态库的路径。 | Driver64=/usr/local/lib/psqlodbcw.so |
+ | setup | 驱动安装路径,与Driver64中动态库的路径一致。 | setup=/usr/local/lib/psqlodbcw.so |
b. 配置数据源文件。
@@ -83,7 +87,7 @@ date: 2021-06-16
| :------------------- | :------------------ |--------------------|
| [DSN] | 数据源的名称。 | [MPPODBC]|
| Driver | 驱动名,对应odbcinst.ini中的DriverName。 | Driver=DRIVER_N|
- | Servername | 服务器的IP地址。 | Servername=10.145.130.26|
+ | Servername | 服务器的IP地址。可配置多个IP地址。 | Servername=10.145.130.26|
| Database | 要连接的数据库的名称。 | Database=postgres |
| Username | 数据库用户名称。 | Username=omm |
| Password | 数据库用户密码。 | Password=
说明:
ODBC驱动本身已经对内存密码进行过清理,以保证用户密码在连接后不会再在内存中保留。
但是如果配置了此参数,由于UnixODBC对数据源文件等进行缓存,可能导致密码长期保留在内存中。
推荐在应用程序连接时,将密码传递给相应API,而非写在数据源配置文件中。同时连接成功后,应当及时清理保存密码的内存段。 |
@@ -94,7 +98,7 @@ date: 2021-06-16
| UseBatchProtocol | 是否开启批量查询协议(打开可提高DML性能);可选值0或者1,默认为1。
当此值为0时,不使用批量查询协议(主要用于与早期数据库版本通信兼容)。
当此值为1,并且数据库support_batch_bind参数存在且为on时,将打开批量查询协议。 | UseBatchProtocol=1 |
| ForExtensionConnector | 这个开关控制着savepoint是否发送,savepoint相关问题可以注意这个开关。 | ForExtensionConnector=1 |
| UnamedPrepStmtThreshold | 每次调用SQLFreeHandle释放Stmt时,ODBC都会向server端发送一个Deallocate plan_name语句,业务中存在大量这类语句。为了减少这类语句的发送,我们将 stmt->plan_name置空,从而使得数据库识别这个为unamed stmt。增加这个参数对unamed stmt的阈值进行控制。 | UnamedPrepStmtThreshold=100 |
- | ConnectionExtraInfo | GUC参数connection_info(参见connection_info)中显示驱动部署路径和进程属主用户的开关。 | ConnectionExtraInfo=1
说明:
默认值为0。当设置为1时,ODBC驱动会将当前驱动的部署路径、进程属主用户上报到数据库中,记录在connection_info参数(参见connection_info)里;同时可以在PG_STAT_ACTIVITY中查询到。 |
+ | ConnectionExtraInfo | GUC参数connection_info(参见[connection_info](1-connection-settings#connection_info))中显示驱动部署路径和进程属主用户的开关。 | ConnectionExtraInfo=1
说明:
默认值为0。当设置为1时,ODBC驱动会将当前驱动的部署路径、进程属主用户上报到数据库中,记录在connection_info参数(参见[connection_info](1-connection-settings#connection_info))里;同时可以在[PG_STAT_ACTIVITY](PG_STAT_ACTIVITY)中查询到。 |
| BoolAsChar | 设置为Yes是,Bools值将会映射为SQL_CHAR。如不设置将会映射为SQL_BIT。 | BoolsAsChar = Yes |
| RowVersioning | 当尝试更新一行数据时,设置为Yes会允许应用检测数据有没有被其他用户进行修改。 | RowVersioning=Yes |
| ShowSystemTables | 驱动将会默认系统表格为普通SQL表格。 | ShowSystemTables=Yes |
@@ -112,14 +116,18 @@ date: 2021-06-16
| verify-ca | 是 | 必须使用SSL安全连接,并且验证数据库是否具有可信证书机构签发的证书。 |
| verify-full | 是 | 必须使用SSL安全连接,在verify-ca的验证范围之外,同时验证数据库所在主机的主机名是否与证书内容一致。MogDB不支持此模式。 |
-5. (可选)生成SSL证书。此步骤和[6](#6)在服务端与客户端通过ssl方式连接的情况下需要执行。非ssl方式连接情况下可以跳过。
+5. (可选)生成SSL证书,具体请参见[证书生成](1-client-access-authentication#证书生成)。此步骤和[6](#6)在服务端与客户端通过ssl方式连接的情况下需要执行。非ssl方式连接情况下可以跳过。
-6. (可选)替换SSL证书,具体请参见"证书替换"。
+6. (可选)替换SSL证书,具体请参见[证书替换](1-client-access-authentication#证书替换)。
7. SSL模式:
+ 声明如下环境变量,同时保证client.key*系列文件为600权限:
+
```
退回根目录,创建.postgresql目录,并将root.crt,client.crt,client.key,client.key.cipher,client.key.rand,client.req,server.crt,server.key,server.key.cipher,server.key.rand,server.req放在此路径下。
+ Unix系统下,server.crt、server.key的权限设置必须禁止任何外部或组的访问,请执行如下命令实现这一点。
+ chmod 0600 server.key
将root.crt以及server开头的证书相关文件全部拷贝进数据库install/data目录下(与postgresql.conf文件在同一路径)。
修改postgresql.conf文件:
ssl = on
@@ -315,7 +323,7 @@ date: 2021-06-16
> - 但是当老版本升级到新版本时,由于哈希的不可逆性,所以数据库无法还原用户口令,进而生成新格式的哈希,所以仍然只保留了SHA256格式的哈希,导致仍然无法使用MD5做口令认证。
> - MD5加密算法安全性低,存在安全风险,建议使用更安全的加密算法。
- 要解决该问题,可以更新用户口令(参见[ALTER USER](29-ALTER-USER));或者新建一个用户(参见CREATE USER),赋于同等权限,使用新用户连接数据库。
+ 要解决该问题,可以更新用户口令(参见[ALTER USER](29-ALTER-USER));或者新建一个用户(参见[CREATE USER](68-CREATE-USER)),赋于同等权限,使用新用户连接数据库。
- unsupported frontend protocol 3.51: server supports 1.0 to 3.0
diff --git a/product/zh/docs-mogdb/v3.0/developer-guide/dev/3-development-based-on-odbc/4-development-process.md b/product/zh/docs-mogdb/v3.0/developer-guide/dev/3-development-based-on-odbc/4-development-process.md
index dbea0e1781f7de49192c603939b7f86c04be07cb..70c618390980ca529e285e734a33b56718dc59cb 100644
--- a/product/zh/docs-mogdb/v3.0/developer-guide/dev/3-development-based-on-odbc/4-development-process.md
+++ b/product/zh/docs-mogdb/v3.0/developer-guide/dev/3-development-based-on-odbc/4-development-process.md
@@ -37,4 +37,8 @@ date: 2021-04-26
| 释放句柄资源 | SQLFreeHandle: 释放句柄资源,可替代如下函数:
- SQLFreeEnv: 释放环境句柄
- SQLFreeConnect: 释放连接句柄
- SQLFreeStmt: 释放语句句柄 |
>  **说明:**
-> 数据库中收到的一次执行请求(不在事务块中),如果含有多条语句,将会被打包成一个事务,同时如果其中有一个语句失败,那么整个请求都将会被回滚。
+> 数据库中收到的一次执行请求(不在事务块中),如果含有多条语句,将会被打包成一个事务,同时如果其中有一个语句失败,那么整个请求都将会被回滚。
+>
+>  **警告:**
+>
+> ODBC为应用程序与数据库的中心层,负责把应用程序发出的SQL指令传到数据库当中,自身并不解析SQL语法。故在应用程序中写入带有保密信息的SQL语句时(如明文密码),保密信息会被暴露在驱动日志中。
diff --git a/product/zh/docs-mogdb/v3.0/performance-tuning/2-sql/9-hint-based-tuning.md b/product/zh/docs-mogdb/v3.0/performance-tuning/2-sql/9-hint-based-tuning.md
index 4f34de755189fbd2c77da466069ef720e7d0d986..df3855056a18614eadcbb3a88f44fd500d8de110 100644
--- a/product/zh/docs-mogdb/v3.0/performance-tuning/2-sql/9-hint-based-tuning.md
+++ b/product/zh/docs-mogdb/v3.0/performance-tuning/2-sql/9-hint-based-tuning.md
@@ -17,7 +17,7 @@ Plan Hint为用户提供了直接影响执行计划生成的手段,用户可
### 功能描述
-Plan Hint仅支持在SELECT关键字后通过如下形式指定:
+Plan Hint支持在SELECT关键字后通过如下形式指定:
```sql
/*+ */
@@ -521,7 +521,7 @@ blockname (table)
>  **说明:**
>
-> - **blockname hint**仅在对应的子链接块提升时才会被上层查询使用。目前支持的子链接提升包括IN子链接提升、EXISTS子链接提升和包含Agg等值相关子链接提升。该hint通常会和前面章节提到的hint联合使用。
+> - **blockname hint**仅在对应的子链接块没有提升时才会被上层查询使用。目前支持的子链接提升包括IN子链接提升、EXISTS子链接提升和包含Agg等值相关子链接提升。该hint通常会和前面章节提到的hint联合使用。
> - 对于FROM关键字后的子查询,则需要使用子查询的别名进行hint,blockname hint不会被用到。
> - 如果子链接中含有多个表,则提升后这些表可与外层表以任意优化顺序连接,hint也不会被用到。
@@ -634,6 +634,10 @@ set(param value)
- 浮点类:
cost_weight_index, default_limit_rows, seq_page_cost, random_page_cost, cpu_tuple_cost, cpu_index_tuple_cost, cpu_operator_cost, effective_cache_size
+
+ - 枚举类型:
+
+ try_vector_engine_strategy
>  **说明:**
>
@@ -672,7 +676,6 @@ set(param value)
强制使用Custom Plan
```sql
-set enable_fast_query_shipping = off;
create table t (a int, b int, c int);
prepare p as select /*+ use_cplan */ * from t where a = $1;
explain execute p(1);
@@ -690,7 +693,7 @@ prepare p as select /*+ use_gplan */ * from t where a = $1;
explain execute p(1);
```
-计划如下。可以看到过滤条件为待填充的入参,即此计划为Custom Plan。
+计划如下。可以看到过滤条件为待填充的入参,即此计划为Generic Plan。
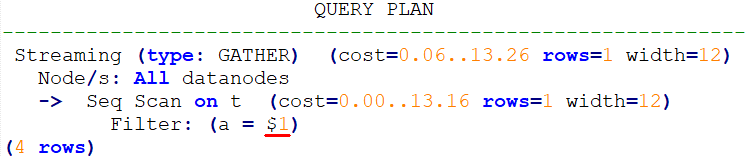
@@ -747,3 +750,67 @@ no_gpc

dbe_perf.global_plancache_status视图中无结果即没有计划被全局缓存。
+
+## 同层参数化路径的Hint
+
+### 功能描述
+
+通过predpush_same_level Hint来指定同层表或物化视图之间参数化路径生成。
+
+### 语法格式
+
+```
+predpush_same_level(src, dest)
+predpush_same_level(src1 src2 ..., dest)
+```
+
+> **说明:** 本参数仅在rewrite_rule中的predpushforce选项打开时生效。
+
+### 示例
+
+准备参数和表及索引:
+
+```
+mogdb=# set rewrite_rule = 'predpushforce';
+SET
+mogdb=# create table t1(a int, b int);
+CREATE TABLE
+mogdb=# create table t2(a int, b int);
+CREATE TABLE
+mogdb=# create index idx1 on t1(a);
+CREATE INDEX
+mogdb=# create index idx2 on t2(a);
+CREATE INDEX
+```
+
+执行语句查看计划:
+
+```
+mogdb=# explain select * from t1, t2 where t1.a = t2.a;
+ QUERY PLAN
+------------------------------------------------------------------
+ Hash Join (cost=27.50..56.25 rows=1000 width=16)
+ Hash Cond: (t1.a = t2.a)
+ -> Seq Scan on t1 (cost=0.00..15.00 rows=1000 width=8)
+ -> Hash (cost=15.00..15.00 rows=1000 width=8)
+ -> Seq Scan on t2 (cost=0.00..15.00 rows=1000 width=8)
+(5 rows)
+```
+
+可以看到t1.a = t2.a条件过滤在Join上面,此时可以通过predpush_same_level(t1, t2)将条件下推至t2的扫描算子上:
+
+```
+mogdb=# explain select /*+predpush_same_level(t1, t2)*/ * from t1, t2 where t1.a = t2.a;
+ QUERY PLAN
+---------------------------------------------------------------------
+ Nested Loop (cost=0.00..335.00 rows=1000 width=16)
+ -> Seq Scan on t1 (cost=0.00..15.00 rows=1000 width=8)
+ -> Index Scan using idx2 on t2 (cost=0.00..0.31 rows=1 width=8)
+ Index Cond: (a = t1.a)
+(4 rows)
+```
+
+> **须知:**
+>
+> - predpush_same_level可以指定多个src,但是所有的src必须在同一个条件中。
+> - 如果指定的src和dest条件不存在,或该条件不符合参数化路径要求,则本hint不生效。
\ No newline at end of file
diff --git a/product/zh/docs-mogdb/v3.0/performance-tuning/3-wdr/wdr-report.md b/product/zh/docs-mogdb/v3.0/performance-tuning/3-wdr/wdr-report.md
new file mode 100644
index 0000000000000000000000000000000000000000..b494f088d40e521c176ea018d25c7de561262d8c
--- /dev/null
+++ b/product/zh/docs-mogdb/v3.0/performance-tuning/3-wdr/wdr-report.md
@@ -0,0 +1,385 @@
+---
+title: 查看WDR报告
+summary: 查看WDR报告
+author: Guo Huan
+date: 2022-04-23
+---
+
+# 查看WDR报告
+
+## Database Stat
+
+Database Stat列名称及描述如下表所示。
+
+**表 1** Database Stat报表主要内容
+
+| 列名称 | 描述 |
+| :------------- | :--------------------------------------------------- |
+| DB Name | 数据库名称。 |
+| Backends | 连接到该数据库的后端数。 |
+| Xact Commit | 此数据库中已经提交的事务数。 |
+| Xact Rollback | 此数据库中已经回滚的事务数。 |
+| Blks Read | 在这个数据库中读取的磁盘块的数量。 |
+| Blks Hit | 高速缓存中已经发现的磁盘块的次数。 |
+| Tuple Returned | 顺序扫描的行数。 |
+| Tuple Fetched | 随机扫描的行数。 |
+| Tuple Inserted | 通过数据库查询插入的行数。 |
+| Tuple Updated | 通过数据库查询更新的行数。 |
+| Tup Deleted | 通过数据库查询删除的行数。 |
+| Conflicts | 由于数据库恢复冲突取消的查询数量。 |
+| Temp Files | 通过数据库查询创建的临时文件数量。 |
+| Temp Bytes | 通过数据库查询写入临时文件的数据总量。 |
+| Deadlocks | 在该数据库中检索的死锁数。 |
+| Blk Read Time | 通过数据库后端读取数据文件块花费的时间,以毫秒计算。 |
+| Blk Write Time | 通过数据库后端写入数据文件块花费的时间,以毫秒计算。 |
+| Stats Reset | 重置当前状态统计的时间。 |
+
+## Load Profile
+
+Load Profile指标名称及描述如下表所示。
+
+**表 2** Load Profile报表主要内容
+
+| 指标名称 | 描述 |
+| :------------------------ | :------------------------------- |
+| DB Time(us) | 作业运行的elapse time总和。 |
+| CPU Time(us) | 作业运行的CPU时间总和。 |
+| Redo size(blocks) | 产生的WAL的大小(块数)。 |
+| Logical read (blocks) | 表或者索引文件的逻辑读(块数)。 |
+| Physical read (blocks) | 表或者索引的物理读(块数)。 |
+| Physical write (blocks) | 表或者索引的物理写(块数)。 |
+| Read IO requests | 表或者索引的读次数。 |
+| Write IO requests | 表或者索引的写次数。 |
+| Read IO (MB) | 表或者索引的读大小(MB)。 |
+| Write IO (MB) | 表或者索引的写大小(MB)。 |
+| Logons | 登录次数。 |
+| Executes (SQL) | SQL执行次数。 |
+| Rollbacks | 回滚事务数。 |
+| Transactions | 事务数。 |
+| SQL response time P95(us) | 95%的SQL的响应时间。 |
+| SQL response time P80(us) | 80%的SQL的响应时间。 |
+
+## Instance Efficiency Percentages
+
+Instance Efficiency Percentages指标名称及描述如下表所示。
+
+**表 3** Instance Efficiency Percentages报表主要内容
+
+| 指标名称 | 描述 |
+| :---------------- | :---------------------------------------------- |
+| Buffer Hit % | Buffer Pool命中率。 |
+| Effective CPU % | CPU time占DB time的比例。 |
+| WalWrite NoWait % | 访问WAL Buffer的event次数占总wait event的比例。 |
+| Soft Parse % | 软解析的次数占总的解析次数的比例。 |
+| Non-Parse CPU % | 非parse的时间占执行总时间的比例。 |
+
+## Top 10 Events by Total Wait Time
+
+Top 10 Events by Total Wait Time列名称及描述如下表所示。
+
+**表 4** Top 10 Events by Total Wait Time报表主要内容
+
+| 列名称 | 描述 |
+| :------------------ | :--------------------- |
+| Event | Wait Event名称。 |
+| Waits | wait次数。 |
+| Total Wait Time(us) | 总wait时间(微秒)。 |
+| Avg Wait Time(us) | 平均wait时间(微秒)。 |
+| Type | Wait Event类别。 |
+
+## Wait Classes by Total Wait Time
+
+Wait Classes by Total Wait Time列名称及描述如下表所示。
+
+**表 5** Wait Classes by Total Wait Time报表主要内容
+
+| 列名称 | 描述 |
+| :------------------ | :----------------------------------------------------------- |
+| Type | Wait Event类别名称:
- STATUS。
- LWLOCK_EVENT。
- LOCK_EVENT。
- IO_EVENT。 |
+| Waits | Wait次数。 |
+| Total Wait Time(us) | 总Wait时间(微秒)。 |
+| Avg Wait Time(us) | 平均Wait时间(微秒)。 |
+
+## Host CPU
+
+Host CPU列名称及描述如下表所示。
+
+**表 6** Host CPU报表主要内容
+
+| 列名称 | 描述 |
+| :----------------- | :----------------------------- |
+| Cpus | CPU数量。 |
+| Cores | CPU核数。 |
+| Sockets | CPU Sockets数量。 |
+| Load Average Begin | 开始snapshot的Load Average值。 |
+| Load Average End | 结束snapshot的Load Average值。 |
+| %User | 用户态在CPU时间上的占比。 |
+| %System | 内核态在CPU时间上的占比。 |
+| %WIO | Wait IO在CPU时间上的占比。 |
+| %Idle | 空闲时间在CPU时间上的占比。 |
+
+## IO Profile
+
+IO Profile指标名称及描述如下表所示。
+
+**表 7** IO Profile指标表主要内容
+
+| 指标名称 | 描述 |
+| :---------------- | :------------------ |
+| Database requests | Database IO次数。 |
+| Database (MB) | Database IO数据量。 |
+| Database (blocks) | Database IO数据块。 |
+| Redo requests | Redo IO次数。 |
+| Redo (MB) | Redo IO量。 |
+
+## Memory Statistics
+
+Memory Statistics指标名称及描述如下表所示。
+
+**表 8** Memory Statistics报表主要内容
+
+| 指标名称 | 描述 |
+| :------------------ | :--------------------------- |
+| shared_used_memory | 已经使用共享内存大小(MB)。 |
+| max_shared_memory | 最大共享内存(MB)。 |
+| process_used_memory | 进程已经使用内存(MB)。 |
+| max_process_memory | 最大进程内存(MB)。 |
+
+## Time Model
+
+Time Model名称及描述如下表所示。
+
+**表 9** Time Model报表主要内容
+
+| 名称 | 描述 |
+| :------------------ | :----------------------------------------------------------- |
+| DB_TIME | 所有线程端到端的墙上时间(WALL TIME)消耗总和(单位:微秒)。 |
+| EXECUTION_TIME | 消耗在执行器上的时间总和(单位:微秒)。 |
+| PL_EXECUTION_TIME | 消耗在PL/SQL执行上的时间总和(单位:微秒)。 |
+| CPU_TIME | 所有线程CPU时间消耗总和(单位:微秒)。 |
+| PLAN_TIME | 消耗在执行计划生成上的时间总和(单位:微秒)。 |
+| REWRITE_TIME | 消耗在查询重写上的时间总和(单位:微秒)。 |
+| PL_COMPILATION_TIME | 消耗在SQL编译上的时间总和(单位:微秒)。 |
+| PARSE_TIME | 消耗在SQL解析上的时间总和(单位:微秒)。 |
+| NET_SEND_TIME | 消耗在网络发送上的时间总和(单位:微秒)。 |
+| DATA_IO_TIME | 消耗在数据读写上的时间总和(单位:微秒)。 |
+
+## SQL Statistics
+
+SQL Statistics列名称及描述如下表所示。
+
+**表 10** SQL Statistics报表主要内容
+
+| 列名称 | 描述 |
+| :-------------------- | :--------------------------------------------- |
+| Unique SQL Id | 归一化的SQL ID。 |
+| Node Name | 节点名称。 |
+| User Name | 用户名称。 |
+| Tuples Read | 访问的元组数量。 |
+| Calls | 调用次数。 |
+| Min Elapse Time(us) | 最小执行时间(us)。 |
+| Max Elapse Time(us) | 最大执行时间(us)。 |
+| Total Elapse Time(us) | 总执行时间(us)。 |
+| Avg Elapse Time(us) | 平均执行时间(us)。 |
+| Returned Rows | SELECT返回行数。 |
+| Tuples Affected | Insert/Update/Delete行数。 |
+| Logical Read | Buffer逻辑读次数。 |
+| Physical Read | Buffer物理读次数。 |
+| CPU Time(us) | CPU时间(us)。 |
+| Data IO Time(us) | IO上的时间花费(us)。 |
+| Sort Count | 排序执行的次数。 |
+| Sort Time(us) | 排序执行的时间(us)。 |
+| Sort Mem Used(KB) | 排序过程中使用的work memory大小(KB)。 |
+| Sort Spill Count | 排序过程中,若发生落盘,写文件的次数。 |
+| Sort Spill Size(KB) | 排序过程中,若发生落盘,使用的文件大小(KB)。 |
+| Hash Count | hash执行的次数。 |
+| Hash Time(us) | hash执行的时间(us)。 |
+| Hash Mem Used(KB) | hash过程中使用的work memory大小(KB)。 |
+| Hash Spill Count | hash过程中,若发生落盘,写文件的次数。 |
+| Hash Spill Size(KB) | hash过程中,若发生落盘,使用的文件大小(KB)。 |
+| SQL Text | 归一化SQL字符串。 |
+
+## Wait Events
+
+Wait Events列名称及描述如下表所示。
+
+**表 11** Wait Events报表主要内容
+
+| 列名称 | 描述 |
+| :------------------- | :----------------------------------------------------------- |
+| Type | Wait Event类别名称:
- STATUS。
- LWLOCK_EVENT。
- LOCK_EVENT。
- IO_EVENT。 |
+| Event | Wait Event名称。 |
+| Total Wait Time (us) | 总Wait时间(us)。 |
+| Waits | 总Wait次数。 |
+| Failed Waits | Wait失败次数。 |
+| Avg Wait Time (us) | 平均Wait时间(us)。 |
+| Max Wait Time (us) | 最大Wait时间(us)。 |
+
+## Cache IO Stats
+
+Cache IO Stats包含User table和User index两张表,列名称及描述如下所示。
+
+### User table IO activity ordered by heap blks hit ratio
+
+**表 12** User table IO activity ordered by heap blks hit ratio报表主要内容
+
+| 列名称 | 描述 |
+| :------------------- | :-------------------------------------------- |
+| DB Name | Database名称。 |
+| Schema Name | Schema名称。 |
+| Table Name | Table名称。 |
+| %Heap Blks Hit Ratio | 此表的Buffer Pool命中率。 |
+| Heap Blks Read | 该表中读取的磁盘块数。 |
+| Heap Blks Hit | 此表缓存命中数。 |
+| Idx Blks Read | 表中所有索引读取的磁盘块数。 |
+| Idx Blks Hit | 表中所有索引命中缓存数。 |
+| Toast Blks Read | 此表的TOAST表读取的磁盘块数(如果存在)。 |
+| Toast Blks Hit | 此表的TOAST表命中缓冲区数(如果存在)。 |
+| Tidx Blks Read | 此表的TOAST表索引读取的磁盘块数(如果存在)。 |
+| Tidx Blks Hit | 此表的TOAST表索引命中缓冲区数(如果存在)。 |
+
+### User index IO activity ordered by idx blks hit ratio
+
+**表 13** User index IO activity ordered by idx blks hit ratio报表主要内容
+
+| 列名称 | 描述 |
+| :------------------ | :----------------------- |
+| DB Name | Database名称。 |
+| Schema Name | Schema名称。 |
+| Table Name | Table名称。 |
+| Index Name | Index名称。 |
+| %Idx Blks Hit Ratio | Index的命中率。 |
+| Idx Blks Read | 所有索引读取的磁盘块数。 |
+| Idx Blks Hit | 所有索引命中缓存数。 |
+
+## Utility status
+
+Utility status包含Replication slot和Replication stat两张表,列名称及描述如下所示。
+
+### Replication slot
+
+**表 14** Replication slot报表主要内容
+
+| 列名称 | 描述 |
+| :------------ | :----------------------- |
+| Slot Name | 复制节点名。 |
+| Slot Type | 复制节点类型。 |
+| DB Name | 复制节点数据库名称。 |
+| Active | 复制节点状态。 |
+| Xmin | 复制节点事务标识。 |
+| Restart Lsn | 复制节点的Xlog文件信息。 |
+| Dummy Standby | 复制节点假备。 |
+
+### Replication stat
+
+**表 15** Replication stat报表主要内容
+
+| 列名称 | 描述 |
+| :----------------------- | :--------------------- |
+| Thread Id | 线程的PID。 |
+| Usesys Id | 用户系统ID。 |
+| Usename | 用户名称。 |
+| Application Name | 应用程序。 |
+| Client Addr | 客户端地址。 |
+| Client Hostname | 客户端主机名。 |
+| Client Port | 客户端端口。 |
+| Backend Start | 程序起始时间。 |
+| State | 日志复制状态。 |
+| Sender Sent Location | 发送端发送日志位置。 |
+| Receiver Write Location | 接收端write日志位置。 |
+| Receiver Flush Location | 接收端flush日志位置。 |
+| Receiver Replay Location | 接收端replay日志位置。 |
+| Sync Priority | 同步优先级。 |
+| Sync State | 同步状态。 |
+
+## Object stats
+
+Object stats包含User Tables stats、User index stats和Bad lock stats三张表,列名称及描述如下所示。
+
+### User Tables stats
+
+**表 16** User Tables stats报表主要内容
+
+| 列名称 | 描述 |
+| :---------------- | :-------------------------------------------------- |
+| DB Name | Database名称。 |
+| Schema | Schema名称。 |
+| Relname | Relation名称。 |
+| Seq Scan | 此表发起的顺序扫描数。 |
+| Seq Tup Read | 顺序扫描抓取的活跃行数。 |
+| Index Scan | 此表发起的索引扫描数。 |
+| Index Tup Fetch | 索引扫描抓取的活跃行数。 |
+| Tuple Insert | 插入行数。 |
+| Tuple Update | 更新行数。 |
+| Tuple Delete | 删除行数。 |
+| Tuple Hot Update | HOT更新行数(即没有更新所需的单独索引)。 |
+| Live Tuple | 估计活跃行数。 |
+| Dead Tuple | 估计死行数。 |
+| Last Vacuum | 最后一次此表是手动清理的(不计算VACUUM FULL)时间。 |
+| Last Autovacuum | 上次被autovacuum守护进程清理的时间。 |
+| Last Analyze | 上次手动分析这个表的时间。 |
+| Last Autoanalyze | 上次被autovacuum守护进程分析的时间。 |
+| Vacuum Count | 这个表被手动清理的次数(不计算VACUUM FULL)。 |
+| Autovacuum Count | 这个表被autovacuum清理的次数。 |
+| Analyze Count | 这个表被手动分析的次数。 |
+| Autoanalyze Count | 这个表被autovacuum守护进程分析的次数。 |
+
+### User index stats
+
+**表 17** User index stats报表主要内容
+
+| 列名称 | 描述 |
+| :---------------- | :--------------------------------------- |
+| DB Name | Database名称。 |
+| Schema | Schema名称。 |
+| Relname | Relation名称。 |
+| Index Relname | Index名称。 |
+| Index Scan | 索引上开始的索引扫描数。 |
+| Index Tuple Read | 通过索引上扫描返回的索引项数。 |
+| Index Tuple Fetch | 通过使用索引的简单索引扫描抓取的表行数。 |
+
+### Bad lock stats
+
+**表 18** Bad lock stats报表主要内容
+
+| 列名称 | 描述 |
+| :------------ | :----------------- |
+| DB Id | 数据库的OID。 |
+| Tablespace Id | 表空间的OID。 |
+| Relfilenode | 文件对象ID。 |
+| Fork Number | 文件类型。 |
+| Error Count | 失败计数。 |
+| First Time | 第一次发生时间。 |
+| Last Time | 最近一次发生时间。 |
+
+## Configuration settings
+
+Configuration settings列名称及描述如下表所示。
+
+**表 19** Configuration settings报表主要内容
+
+| 列名称 | 描述 |
+| :------------ | :----------------------------- |
+| Name | GUC名称。 |
+| Abstract | GUC描述。 |
+| Type | 数据类型。 |
+| Curent Value | 当前值。 |
+| Min Value | 合法最小值。 |
+| Max Value | 合法最大值。 |
+| Category | GUC类别。 |
+| Enum Values | 如果是枚举值,列举所有枚举值。 |
+| Default Value | 数据库启动时参数默认值。 |
+| Reset Value | 数据库重置时参数默认值。 |
+
+## SQL Detail
+
+SQL Detail列名称及描述如下表所示。
+
+**表 20** SQL Detail报表主要内容
+
+| 列名称 | 描述 |
+| :------------ | :--------------------------------- |
+| Unique SQL Id | 归一化SQL ID。 |
+| User Name | 用户名称。 |
+| Node Name | 节点名称。Node模式下不显示该字段。 |
+| SQL Text | 归一化SQL文本。 |
diff --git a/product/zh/docs-mogdb/v3.0/performance-tuning/wdr-snapshot-schema.md b/product/zh/docs-mogdb/v3.0/performance-tuning/3-wdr/wdr-snapshot-schema.md
similarity index 56%
rename from product/zh/docs-mogdb/v3.0/performance-tuning/wdr-snapshot-schema.md
rename to product/zh/docs-mogdb/v3.0/performance-tuning/3-wdr/wdr-snapshot-schema.md
index 87e40cd13c3b8c33a4dbd169c82cc1e973f81448..40890597226d0c245205345e66039130e2e0b89b 100644
--- a/product/zh/docs-mogdb/v3.0/performance-tuning/wdr-snapshot-schema.md
+++ b/product/zh/docs-mogdb/v3.0/performance-tuning/3-wdr/wdr-snapshot-schema.md
@@ -1,11 +1,11 @@
---
-title: WDR解读指南
-summary: WDR解读指南
+title: WDR Snapshot Schema
+summary: WDR Snapshot Schema
author: Zhang Cuiping
date: 2021-03-11
---
-# WDR解读指南
+# WDR Snapshot Schema
WDR Snasphot在启动后(打开参数enable_wdr_snapshot),会在用户表空间"pg_default",数据库"postgres"下新建schema "snapshot",用于持久化WDR快照数据。默认初始化用户或monadmin用户可以访问Snapshot Schema。
@@ -65,52 +65,65 @@ WDR Snapshot数据表来源为"DBE_PERF Schema"下所有的视图。
**前提条件**
-WDR Snasphot启动(即参数enable_wdr_snapshot)为on时, 且快照数量大于等于2时可以生成报告。
+WDR Snasphot启动(即参数enable_wdr_snapshot)为on时, 且快照数量大于等于2。
**操作步骤**
-1. 执行以下命令连接postgres数据库。
+1. 执行如下命令新建报告文件。
+
+ ```
+ touch /home/om/wdrTestNode.html
+ ```
+
+2. 执行以下命令连接postgres数据库。
```
gsql -d postgres -p 端口号 -r
```
-2. 执行如下命令查询已经生成的快照,以获取快照的snapshot_id。
+3. 执行如下命令查询已经生成的快照,以获取快照的snapshot_id。
- ```sql
+ ```
select * from snapshot.snapshot;
```
-3. (可选)在CCN上执行如下命令手动创建快照。数据库中只有一个快照或者需要查询在当前时段数据库监控的监控数据,可以选择手动执行快照操作,该命令需要用户具有sysadmin权限。
+4. (可选)在CCN上执行如下命令手动创建快照。数据库中只有一个快照或者需要查看在当前时间段数据库的监控数据,可以选择手动执行快照操作,该命令需要用户具有sysadmin权限。
- ```sql
+ ```
select create_wdr_snapshot();
```
- >  **说明:** 执行“cm_ctl query -Cdvi”,回显中“Central Coordinator State”下显示的信息即为CCN信息。
+ > **说明:** 执行“cm_ctl query -Cdvi”,回显中“Central Coordinator State”下显示的信息即为CCN信息。
-4. 执行如下步骤生成性能报告。
+5. 执行如下命令,在本地生成HTML格式的WDR报告。
- a. 执行如下命令生成格式化性能报告文件。
+ a. 执行如下命令,设置报告格式。\a: 不显示表行列符号, \t: 不显示列名 ,\o: 指定输出文件。
- ```sql
- \a \t \o 服务器文件路径
+ ```
+ gsql> \a
+ gsql> \t
+ gsql> \o /home/om/wdrTestNode.html
```
- 上述命令涉及参数说明如下:
+ b. 执行如下命令,生成HTML格式的WDR报告。
- - \\a: 切换非对齐模式。
- - \\t: 切换输出的字段名的信息和行计数脚注。
- - \\o: 把所有的查询结果发送至服务器文件里。
- - 服务器文件路径:生成性能报告文件存放路径。用户需要拥有此路径的读写权限。
+ ```
+ gsql> select generate_wdr_report(begin_snap_id Oid, end_snap_id Oid, int report_type, int report_scope, int node_name );
+ ```
- b. 执行如下命令将查询到的信息写入性能报告中。
+ 示例一,生成集群级别的报告:
- ```sql
- select generate_wdr_report(begin_snap_id bigint, end_snap_id bigint, report_type cstring, report_scope cstring, node_name cstring);
+ ```
+ select generate_wdr_report(1, 2, 'all', 'cluster',null);
```
- 命令中涉及的参数说明如下。
+ 示例二,生成某个节点的报告:
+
+ ```
+ select generate_wdr_report(1, 2, 'all', 'node', pgxc_node_str()::cstring);
+ ```
+
+ >  **说明:** 当前MogDB的节点名固定是“dn_6001_6002_6003”,也可直接代入。
**表 3** generate_wdr_report函数参数说明
@@ -120,50 +133,41 @@ WDR Snasphot启动(即参数enable_wdr_snapshot)为on时, 且快照数量
| end_snap_id | 查询时间段结束snapshot的id。默认end_snap_id大于begin_snap_id(表snapshot.snaoshot中的snapshot_id)。 | - |
| report_type | 指定生成report的类型。例如,summary/detail/all。 | summary: 汇总数据。
detail: 明细数据。
all: 包含summary和detail。 |
| report_scope | 指定生成report的范围,可以为cluster或者node。 | cluster: 数据库级别的信息。
node: 节点级别的信息。 |
- | node_name | 在report_scope指定为node时,需要把该参数指定为对应节点的名称。(节点名称可以执行select * from pg_node_env;查询)。在report_scope为cluster时,该值可以指定为省略、空或者为NULL。 | node: MogDB中的节点名称。
cluster: 省略、空或者NULL。 |
+ | node_name | 在report_scope指定为node时,需要把该参数指定为对应节点的名称。(节点名称可以执行select * from pg_node_env;查询)。在report_scope为cluster时,该值可以指定为省略、空或者为NULL。 | node: MogDB中的节点名称。
cluster: 省略、空或者NULL。 |
- c.执行如下命令关闭输出选项及格式化输出命令。
+ c. 执行如下命令关闭输出选项及格式化输出命令。
```
\o \a \t
```
-5. 根据需要查看WDR报告内容。
-
- **表 4** WDR报表主要内容
-
- | 项目 | 描述 |
- | :------------------------------------------------- | :----------------------------------------------------------- |
- | Database Stat(数据库范围) | 数据库维度性能统计信息:事务,读写,行活动,写冲突,死锁等。 |
- | Load Profile(数据库范围) | 数据库维度的性能统计信息:CPU时间,DB时间,逻辑读/物理读,IO性能,登入登出,负载强度,负载性能表现等。 |
- | Instance Efficiency Percentages(数据库/节点范围) | 数据库级或者节点Buffer Hit(缓冲命中率),Effective CPU(CPU使用率),WalWrite NoWait(获取Wal Buffer成功率),Soft Parse(软解析率),Non-parse CPU(CPU非解析时间比例)。 |
- | Top 10 Events by Total Wait Time(节点范围) | 最消耗时间的事件。 |
- | Wait Classes by Total Wait Time(节点范围) | 最消耗时间的等待事件分类。 |
- | Host CPU(节点范围) | 主机CPU消耗。 |
- | Memory Statistics(节点范围) | 内核内存使用分布。 |
- | Object stats(节点范围) | 表,索引维度的性能统计信息。 |
- | Database Configuration(节点范围) | 节点配置。 |
- | SQL Statistics(节点范围) | SQL语句各个维度性能统计:端到端时间,行活动,缓存命中,CPU消耗,时间消耗细分。 |
- | SQL Detail(节点范围) | SQL语句文本详情。 |
+6. 在/home/om/下根据需要查看WDR报告。
**示例**
```sql
+--创建报告文件
+touch /home/om/wdrTestNode.html
+
+--连接数据库
+gsql -d postgres -p 端口号 -r
+
--查询已经生成的快照。
mogdb=# select * from snapshot.snapshot;
- snapshot_id | start_ts | end_ts
+ snapshot_id | start_ts | end_ts
-------------+-------------------------------+-------------------------------
1 | 2020-09-07 10:20:36.763244+08 | 2020-09-07 10:20:42.166511+08
2 | 2020-09-07 10:21:13.416352+08 | 2020-09-07 10:21:19.470911+08
(2 rows)
+
--生成格式化性能报告wdrTestNode.html。
mogdb=# \a \t \o /home/om/wdrTestNode.html
Output format is unaligned.
Showing only tuples.
--向性能报告wdrTestNode.html中写入数据。
-mogdb=# select generate_wdr_report(1, 2, 'all', 'node', 'dn');
+mogdb=# select generate_wdr_report(1, 2, 'all', 'node', 'dn_6001_6002_6003');
--关闭性能报告wdrTestNode.html。
mogdb=# \o
@@ -178,4 +182,4 @@ mogdb=# select generate_wdr_report(1, 2, 'all', 'cluster');
mogdb=# \o \a \t
Output format is aligned.
Tuples only is off.
-```
+```
\ No newline at end of file
diff --git a/product/zh/docs-mogdb/v3.0/performance-tuning/tuning-with-vector-engine.md b/product/zh/docs-mogdb/v3.0/performance-tuning/tuning-with-vector-engine.md
new file mode 100644
index 0000000000000000000000000000000000000000..fd6f1f7420a1d8da37dd0e535b51d4f332b57a43
--- /dev/null
+++ b/product/zh/docs-mogdb/v3.0/performance-tuning/tuning-with-vector-engine.md
@@ -0,0 +1,59 @@
+---
+title: 使用向量化执行引擎进行调优
+summary: 使用向量化执行引擎进行调优
+author: Guo Huan
+date: 2022-04-23
+---
+
+# 使用向量化执行引擎进行调优
+
+MogDB数据库支持行执行引擎和向量化执行引擎,分别对应行存表和列存表。
+
+- 一次一个batch,读取更多数据,节省IO。
+- batch中记录较多,CPU cache命中率提升。
+- Pipeline模式执行,函数调用次数少。
+- 一次处理一批数据,效率高。
+
+MogDB数据库所以对于分析类的复杂查询能够获得更好的查询性能。但列存表在数据插入和数据更新上表现不佳,对于存在数据频繁插入和更新的业务无法使用列存表。
+
+为了提升行存表在分析类的复杂查询上的查询性能,MogDB数据库提供行存表使用向量化执行引擎的能力。通过设置GUC参数try_vector_engine_strategy,可以将包含行存表的查询语句转换为向量化执行计划执行。
+
+行存表转换为向量化执行引擎执行不是对所有的查询场景都适用。参考向量化引擎的优势,如果查询语句中包含表达式计算、多表join、聚集等操作时,通过转换为向量化执行能够获得性能提升。从原理上分析,行存表转换为向量化执行,会产生转换的开销,导致性能下降。而上述操作的表达式计算、join操作、聚集操作转换为向量化执行之后,能够获得获得性能提升。所以查询转换为向量化执行后,性能是否提升,取决于查询转换为向量化之后获得的性能提升能否高于转换产生的性能开销。
+
+以TPCH Q1为例,使用行执行引擎时,扫描算子的执行时间为405210ms,聚集操作的执行时间为2618964ms;而转换为向量化执行引擎后,扫描算子(SeqScan + VectorAdapter)的执行时间为470840ms,聚集操作的执行时间为212384ms,所以查询能够获得性能提升。
+
+TPCH Q1 行执行引擎执行计划:
+
+```
+ QUERY PLAN
+-------------------------------------------------------------------------------------------------------------------------------------------
+ Sort (cost=43539570.49..43539570.50 rows=6 width=260) (actual time=3024174.439..3024174.439 rows=4 loops=1)
+ Sort Key: l_returnflag, l_linestatus
+ Sort Method: quicksort Memory: 25kB
+ -> HashAggregate (cost=43539570.30..43539570.41 rows=6 width=260) (actual time=3024174.396..3024174.403 rows=4 loops=1)
+ Group By Key: l_returnflag, l_linestatus
+ -> Seq Scan on lineitem (cost=0.00..19904554.46 rows=590875396 width=28) (actual time=0.016..405210.038 rows=596140342 loops=1)
+ Filter: (l_shipdate <= '1998-10-01 00:00:00'::timestamp without time zone)
+ Rows Removed by Filter: 3897560
+ Total runtime: 3024174.578 ms
+(9 rows)
+```
+
+TPCH Q1 向量化执行引擎执行计划:
+
+```
+ QUERY PLAN
+--------------------------------------------------------------------------------------------------------------------------------------------------------------------
+ Row Adapter (cost=43825808.18..43825808.18 rows=6 width=298) (actual time=683224.925..683224.927 rows=4 loops=1)
+ -> Vector Sort (cost=43825808.16..43825808.18 rows=6 width=298) (actual time=683224.919..683224.919 rows=4 loops=1)
+ Sort Key: l_returnflag, l_linestatus
+ Sort Method: quicksort Memory: 3kB
+ -> Vector Sonic Hash Aggregate (cost=43825807.98..43825808.08 rows=6 width=298) (actual time=683224.837..683224.837 rows=4 loops=1)
+ Group By Key: l_returnflag, l_linestatus
+ -> Vector Adapter(type: BATCH MODE) (cost=19966853.54..19966853.54 rows=596473861 width=66) (actual time=0.982..470840.274 rows=596140342 loops=1)
+ Filter: (l_shipdate <= '1998-10-01 00:00:00'::timestamp without time zone)
+ Rows Removed by Filter: 3897560
+ -> Seq Scan on lineitem (cost=0.00..19966853.54 rows=596473861 width=66) (actual time=0.364..199301.737 rows=600037902 loops=1)
+ Total runtime: 683225.564 ms
+(11 rows)
+```
\ No newline at end of file
diff --git a/product/zh/docs-mogdb/v3.0/toc.md b/product/zh/docs-mogdb/v3.0/toc.md
index 2f71bf53b08d4e41a3a49e34a528a248ead66a46..3fee13a60a3b38a02f5c25389fbcb1e1419175b8 100644
--- a/product/zh/docs-mogdb/v3.0/toc.md
+++ b/product/zh/docs-mogdb/v3.0/toc.md
@@ -190,7 +190,10 @@
+ [SQL语句改写规则](/performance-tuning/2-sql/7-experience-in-rewriting-sql-statements.md)
+ [SQL调优关键参数调整](/performance-tuning/2-sql/8-resetting-key-parameters-during-sql-tuning.md)
+ [使用Plan Hint进行调优](/performance-tuning/2-sql/9-hint-based-tuning.md)
- + [WDR解读指南](/performance-tuning/wdr-snapshot-schema.md)
+ + WDR解读指南
+ + [WDR Snapshot Schema](/performance-tuning/3-wdr/wdr-snapshot-schema.md)
+ + [查看WDR报告](/performance-tuning/3-wdr/wdr-report.md)
+ + [使用向量化执行引擎进行调优](/performance-tuning/tuning-with-vector-engine.md)
+ [TPCC性能优化指南](/performance-tuning/TPCC-performance-tuning-guide.md)
+ 开发者指南
+ 应用程序开发教程
diff --git a/product/zh/docs-mogdb/v3.0/toc_performance.md b/product/zh/docs-mogdb/v3.0/toc_performance.md
index 55742ec896c7d94415fdeffd35f4fcc000729bde..9b4c3c366d94624581bf35aac64bb8cb537e5925 100644
--- a/product/zh/docs-mogdb/v3.0/toc_performance.md
+++ b/product/zh/docs-mogdb/v3.0/toc_performance.md
@@ -19,5 +19,8 @@
+ [SQL语句改写规则](/performance-tuning/2-sql/7-experience-in-rewriting-sql-statements.md)
+ [SQL调优关键参数调整](/performance-tuning/2-sql/8-resetting-key-parameters-during-sql-tuning.md)
+ [使用Plan Hint进行调优](/performance-tuning/2-sql/9-hint-based-tuning.md)
-+ [WDR解读指南](/performance-tuning/wdr-snapshot-schema.md)
++ WDR解读指南
+ + [WDR Snapshot Schema](/performance-tuning/3-wdr/wdr-snapshot-schema.md)
+ + [查看WDR报告](/performance-tuning/3-wdr/wdr-report.md)
++ [使用向量化执行引擎进行调优](/performance-tuning/tuning-with-vector-engine.md)
+ [TPCC性能优化指南](/performance-tuning/TPCC-performance-tuning-guide.md)
diff --git a/product/zh/docs-mvd/v2.4/release-notes.md b/product/zh/docs-mvd/v2.4/release-notes.md
index 63aaf56c49720fb81035a514daf8661ed84b11b0..22486ac9d86dae36f2c2278d517aae93fea151e7 100644
--- a/product/zh/docs-mvd/v2.4/release-notes.md
+++ b/product/zh/docs-mvd/v2.4/release-notes.md
@@ -7,6 +7,34 @@ date: 2021-08-30
# 发布记录
+## v2.4.8 (2022-04-22)
+
+- [mvd_linux_arm64](https://cdn-mogdb.enmotech.com/mvd/MVD_v2.4.8/mvd_linux_arm64)
+- [mvd_linux_x86_64](https://cdn-mogdb.enmotech.com/mvd/MVD_v2.4.8/mvd_linux_x86_64)
+- [mvd_macos_x86_64](https://cdn-mogdb.enmotech.com/mvd/MVD_v2.4.8/mvd_macos_x86_64)
+
+### 新增功能
+
+- 对象对比时,MogDB 库增加 Package 对象(2.1及以后版本),以及 SYNONYM 对象的对比
+- Oracle/DB2 数据库对比时,增加对 OS 本地变量的识别(TMPDIR, TMP),用于存储程序运行时的临时数据
+- 增加 -Z 选项,可在运行时手动指定不同数据库中数据对比所使用的时区
+
+### 功能优化
+
+- 最终结果展示微调,可读性更优
+- 优化 --debug-md5 选项在数据对比过程中的输出,能输出更加细致的双边数据对比过程
+- 优化 -T 模式,使得单表对比模式下也支持 -r 指定 Schema 映射
+
+### 问题修复
+
+- 修复 openGauss/MogDB 库中的主键表,查询时排序规则不同,导致的对比结果异常的问题
+- 修复非主键表对比过程中,主键标识识别失败,导致的程序报错问题
+- 修复不同数据库中,主键字段名称大小写混合,导致排序数据不一致的问题 ("TID")
+- 修复单边库中数据不一致时,无法正确识别的问题
+- 修复主键字段尾部空格,导致主键表对比结果不正确的问题
+- 修复 Oracle/DB2 中查询字段多次出现(主键表),导致查询报错的问题
+- 修复 MySQL 库中 char 类型尾部空格导致的数据对比不正确的问题
+
## v2.4.0 (2021-12-20)
- [mvd_linux_arm64](https://cdn-mogdb.enmotech.com/mvd/MVD_v2.4.0/mvd_linux_arm64)
diff --git a/product/zh/docs-mvd/v2.4/usage.md b/product/zh/docs-mvd/v2.4/usage.md
index 24b5b9401ec94de8ba8a3fb27b0cbdddd207d50d..b7ba8d4727e4089291c7b8f7ad97608936dbd29d 100644
--- a/product/zh/docs-mvd/v2.4/usage.md
+++ b/product/zh/docs-mvd/v2.4/usage.md
@@ -54,6 +54,7 @@ Options:
--row-feedback : Query row data when differences found, otherwise just key condition listed
--ignore-float : Ignore float data type in comparison
-z, --zero-char : Specify a char for chr(0) in comparason, Default is empty char
+ -Z, --time-zone : Specify timezone for DB client, set empty use local, default is UTC(+00:00)
-l, --logfile : Write output information to logfile
Usage:
@@ -88,6 +89,7 @@ Usage:
| --row-feedback | 是否回显差异行的完整数据,默认只显示差异行的 KEY (Oracle 中的 ROWID, PG 中的 CTID 等) |
| --ignore-float | 是否在数据对比过程中,忽略浮点类型 (float, double, real 等非精确类型),默认不忽略 |
| -z, --zero-char | 指定 chr(0) 字符在对比中的替代字符,默认为空字符,即移除 chr(0) 不可见字符 |
+| -Z, --time-zone | 指定客户端数据查询的时区,设置空字符串则使用本地操作系统时区,不设置则使用 UTC (+00:00) 时区 |
| -l, --logfile | 指定工具运行的日志文件 |
## 常用命令示例