| LeNet | AlexNet | GoogLeNet | Inception V3 | VGG | ResNet and ResNeXt |
| Inception-Resnet-V2 | DenseNet | DPN | PolyNet | SENet | NasNet |
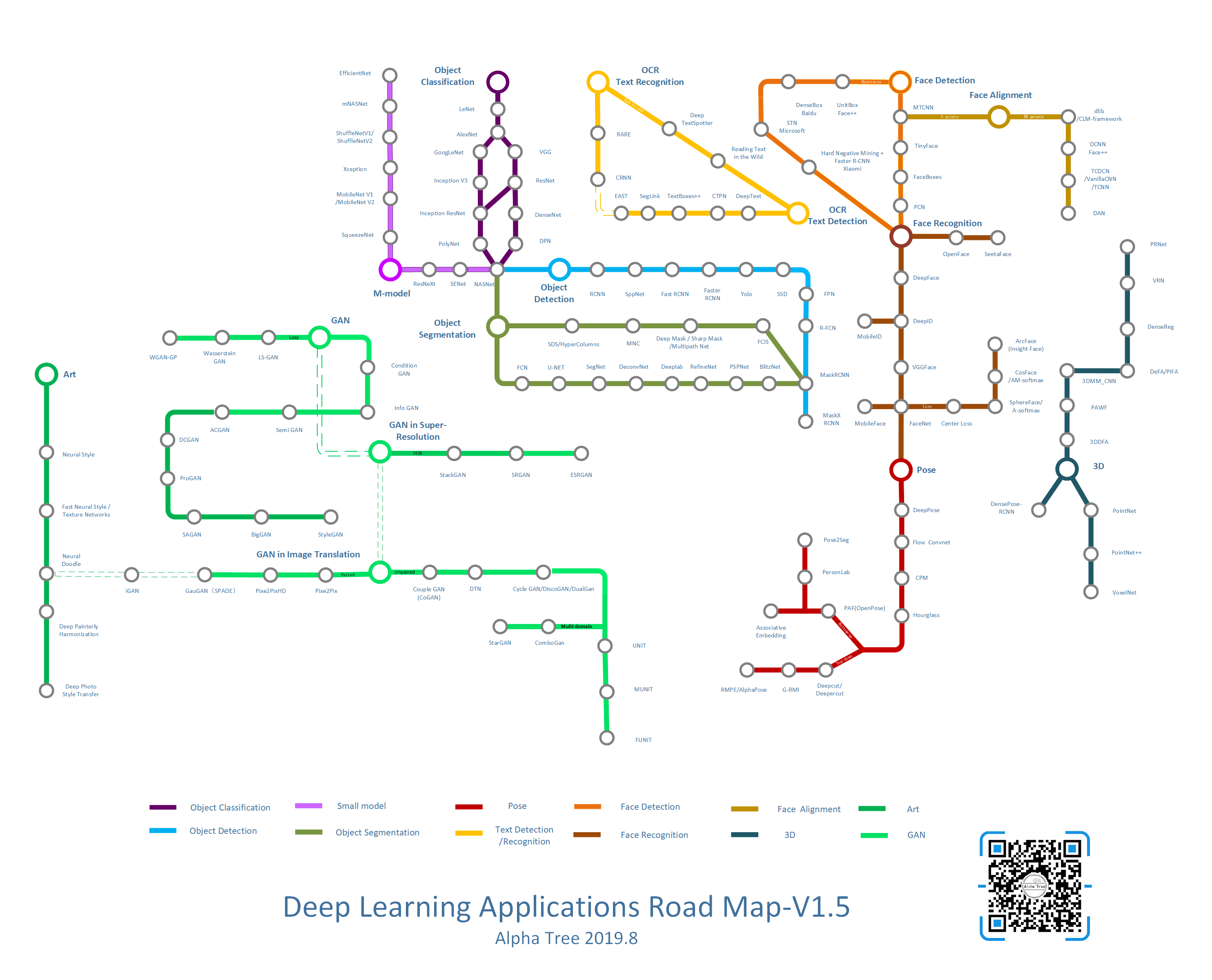
| 轻量级模型 & 剪枝 | 物体检测Object Detection | 物体分割Object Segmentation | OCR |
| 人脸检测Face Detection | 人脸识别Face Recognition | 肢体检测Pose Detection(coming soon) | 3D(coming soon) |
 参考Mohammad KHalooei的教程,我也将GAN分为4个level,第四个level将按照应用层面进行拓展。 这里基础部分包括Gan的定义,GAN训练上的改进,那些优秀的GAN.具体可以参见 [GAN 对抗生成网络发展总览](https://github.com/weslynn/AlphaTree-graphic-deep-neural-network/tree/master/GAN%E5%AF%B9%E6%8A%97%E7%94%9F%E6%88%90%E7%BD%91%E7%BB%9C)
### GAN的定义 Level 0: Definition of GANs
|Level| Title| Co-authors| Publication| Links|
|:---:|:---:|:---:|:---:|:---:|
|Beginner| GAN : Generative Adversarial Nets| Goodfellow & et al.| NeurIPS (NIPS) 2014 |[link](https://papers.nips.cc/paper/5423-generative-adversarial-nets.pdf) |
|Beginner| GAN : Generative Adversarial Nets (Tutorial)| Goodfellow & et al.| NeurIPS (NIPS) 2016 Tutorial| [link](https://arxiv.org/pdf/1701.00160.pdf)|
|Beginner| CGAN : Conditional Generative Adversarial Nets| Mirza & et al.| -- 2014 |[link](https://gist.github.com/shagunsodhani/5d726334de3014defeeb701099a3b4b3) |
|Beginner| InfoGAN : Interpretable Representation Learning by Information Maximizing Generative Adversarial Nets| Chen & et al.| NeuroIPS (NIPS) 2016 ||
模型结构的发展:

--------------------------------------------------------------------------
参考Mohammad KHalooei的教程,我也将GAN分为4个level,第四个level将按照应用层面进行拓展。 这里基础部分包括Gan的定义,GAN训练上的改进,那些优秀的GAN.具体可以参见 [GAN 对抗生成网络发展总览](https://github.com/weslynn/AlphaTree-graphic-deep-neural-network/tree/master/GAN%E5%AF%B9%E6%8A%97%E7%94%9F%E6%88%90%E7%BD%91%E7%BB%9C)
### GAN的定义 Level 0: Definition of GANs
|Level| Title| Co-authors| Publication| Links|
|:---:|:---:|:---:|:---:|:---:|
|Beginner| GAN : Generative Adversarial Nets| Goodfellow & et al.| NeurIPS (NIPS) 2014 |[link](https://papers.nips.cc/paper/5423-generative-adversarial-nets.pdf) |
|Beginner| GAN : Generative Adversarial Nets (Tutorial)| Goodfellow & et al.| NeurIPS (NIPS) 2016 Tutorial| [link](https://arxiv.org/pdf/1701.00160.pdf)|
|Beginner| CGAN : Conditional Generative Adversarial Nets| Mirza & et al.| -- 2014 |[link](https://gist.github.com/shagunsodhani/5d726334de3014defeeb701099a3b4b3) |
|Beginner| InfoGAN : Interpretable Representation Learning by Information Maximizing Generative Adversarial Nets| Chen & et al.| NeuroIPS (NIPS) 2016 ||
模型结构的发展:

--------------------------------------------------------------------------
| CGAN | LAPGAN | IcGAN | ACGAN | SemiGan /SSGAN | InfoGan |
| 图像翻译 (Image Translation) | 超分辨率 (Super-Resolution) | 图像上色(Colourful Image Colorization) |
| 图像修复(Image Inpainting) | 图像去噪(Image denoising) | 交互式图像生成 |
| 漫画 (comic、anime、manga) | 换脸 (face changing) |