![]()
📖 一站式构建多源、干净、个性化的阅读环境
琉璃开净界,薜荔启禅关
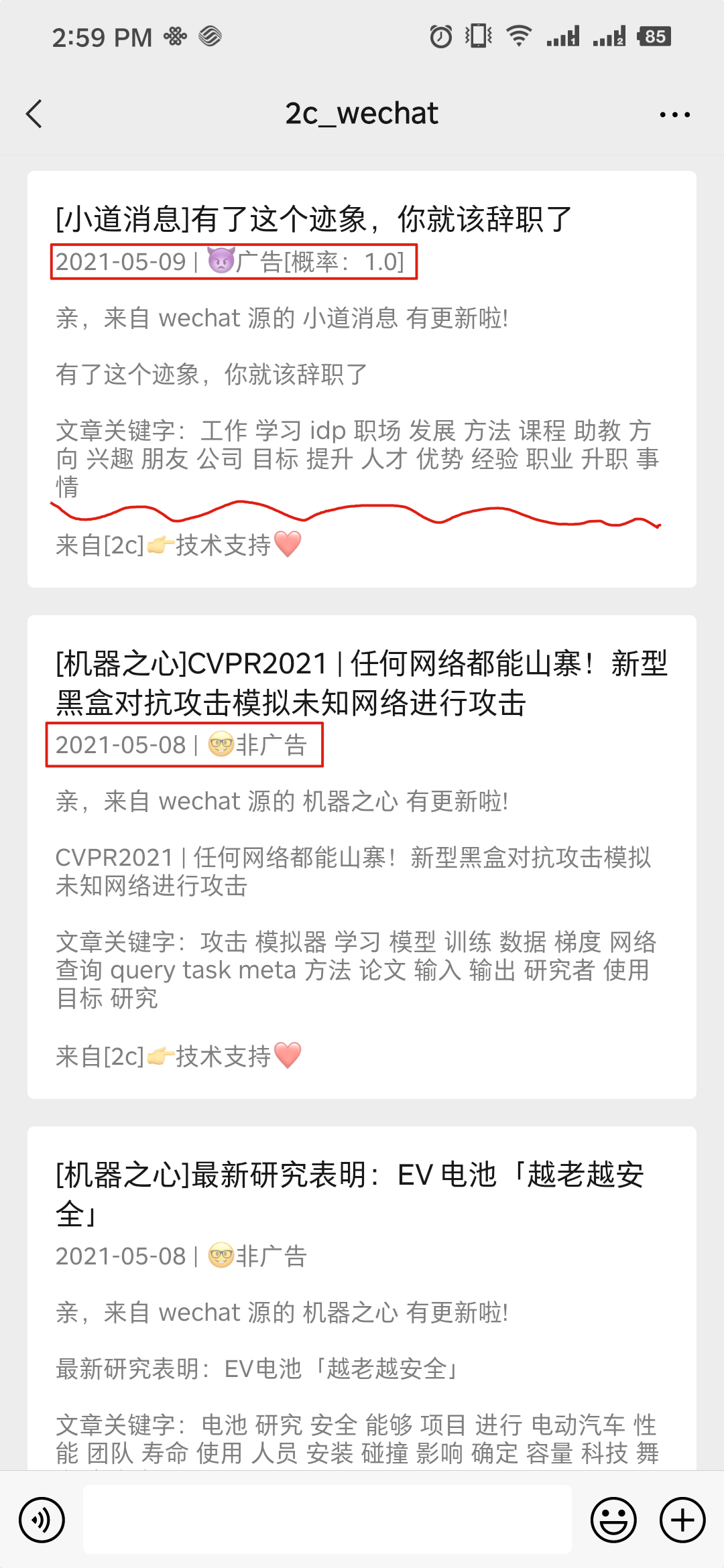
## ✨ 特性 使用`Liuli`,你可以得到: - [x] 配置化开发,自定义输入、处理、输出 - [x] 信息备份(支持跨源): Github, MongoDB - [ ] 机器学习赋能:验证码识别、广告分类、智能标签 - [ ] 阅读源管控,构建知识管理平台 - [x] 官方案例技术支持 使用场景: - [ ] 目标监控 - [x] 公众号: - [x] **广告问题**:[打造一个干净且个性化的公众号阅读环境](https://mp.weixin.qq.com/s/NKnTiLixjB9h8fSd7Gq8lw) - [x] **RSS订阅问题**:[基于Liuli构建纯净的RSS公众号信息流](https://mp.weixin.qq.com/s/rxoq97YodwtAdTqKntuwMA) - [x] 书籍(小说)追更订阅:[基于Liuli追更&阅读小说](https://mp.weixin.qq.com/s/RSVZFxiq8G7a51te4q93gQ) ## 🍥 使用 教程[使用前必读]: - [01.使用教程](./docs/01.使用教程.md) - [02.环境变量](./docs/02.环境变量.md) - [03.分发器配置](./docs/03.分发器配置.md) - [04.备份器配置](./docs/04.备份器配置.md) 快速开始,请先确保安装`Docker`: ```shell mkdir liuli && cd liuli # 数据库目录 mkdir mongodb_data # 任务配置目录 mkdir liuli_config wget -O liuli_config/default.json https://raw.githubusercontent.com/howie6879/liuli/main/liuli_config/default.json # 配置 pro.env 具体查看 doc/02.环境变量.md vim pro.env # 下载 docker-compose wget https://raw.githubusercontent.com/howie6879/liuli/main/docker-compose.yaml # 启动 docker-compose up -d ``` 代码安装使用过程如下: ```shell # 确保有Python3.7+环境 git clone https://github.com/liuli-io/liuli.git --depth=1 cd liuli # 创建基础环境 pipenv install --python={your_python3.7+_path} --dev --skip-lock # 配置.env 具体查看 doc/02.环境变量.md 启动调度 pipenv run dev_schedule ``` 启动成功日志如下: ```shell Loading .env environment variables... [2021:12:23 23:08:35] INFO Liuli Schedule started successfully :) [2021:12:23 23:08:35] INFO Liuli Schedule time: 00:00 06:00 [2021:12:23 23:09:36] INFO Liuli playwright 匹配公众号 老胡的储物柜(howie_locker) 成功! 正在提取最新文章: 我的周刊(第018期) [2021:12:23 23:09:39] INFO Liuli 公众号文章持久化成功! 👉 老胡的储物柜 [2021:12:23 23:09:40] INFO Liuli 🤗 微信公众号文章更新完毕(1/1) ``` 推送效果如图: