# lihang_algorithms
**Repository Path**: icedefender/lihang_algorithms
## Basic Information
- **Project Name**: lihang_algorithms
- **Description**: 用python和sklearn两种方法实现李航《统计学习方法》中的算法
- **Primary Language**: Python
- **License**: Not specified
- **Default Branch**: master
- **Homepage**: None
- **GVP Project**: No
## Statistics
- **Stars**: 0
- **Forks**: 0
- **Created**: 2019-03-27
- **Last Updated**: 2020-12-20
## Categories & Tags
**Categories**: Uncategorized
**Tags**: None
## README
# lihang_algorithms
用python和sklearn实现李航老师的《统计学习方法》中所提到的算法
实验数据:MNIST数据集,这里用kaggle中处理好的数据
官方下载地址:http://yann.lecun.com/exdb/mnist/
kaggle中处理好的数据:https://www.kaggle.com/c/digit-recognizer/data
* * *
## 第二章 感知机
适用问题:二类分类
实验数据:由于是二分类器,所以将MINST数据集[train.csv](https://github.com/fuqiuai/lihang_algorithms/blob/master/data/train.csv)的label列进行了一些微调,label等于0的继续等于0,label大于0改为1。这样就将十分类的数据改为二分类的数据。获取地址[train_binary.csv](https://github.com/fuqiuai/lihang_algorithms/blob/master/data/train_binary.csv)
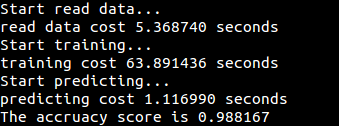
代码:[perceptron/perceptron.py](https://github.com/fuqiuai/lihang_algorithms/blob/master/perceptron/perceptron.py)
运行结果:
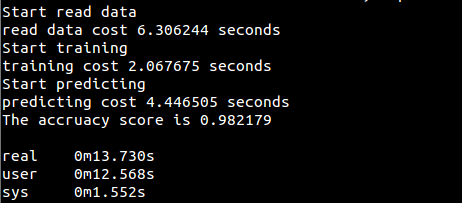
代码(用sklearn实现):[perceptron/perceptron_sklearn.py](https://github.com/fuqiuai/lihang_algorithms/blob/master/perceptron/perceptron_sklearn.py)
运行结果:
## 第三章 k邻近法
适用问题:多类分类
三个基本要素:k值的选择、距离度量及分类决策规则
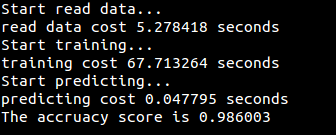
代码:[knn/knn.py](https://github.com/fuqiuai/lihang_algorithms/blob/master/knn/knn.py)
运行结果:
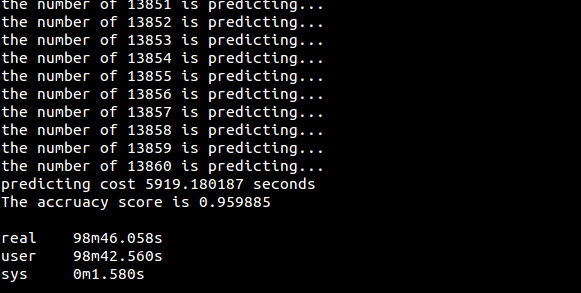
代码(用sklearn实现):[knn/knn_sklearn.py](https://github.com/fuqiuai/lihang_algorithms/blob/master/knn/knn_sklearn.py)
运行结果:
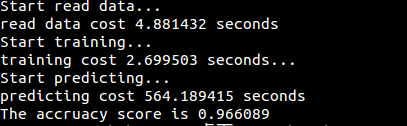
## 第四章 朴素贝叶斯法
适用问题:多类分类
基于贝叶斯定理和特征条件独立假设
常用的三个模型有:
- 高斯模型:处理特征是连续型变量的情况
- 多项式模型:最常见,要求特征是离散数据
- 伯努利模型:要求特征是离散的,且为布尔类型,即true和false,或者1和0
代码(基于多项式模型):[naive_bayes/naive_bayes.py](https://github.com/fuqiuai/lihang_algorithms/blob/master/naive_bayes/naive_bayes.py)
运行结果:
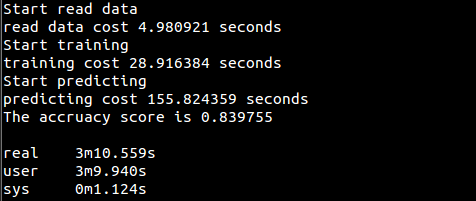
代码(基于多项式模型,用sklearn实现):[naive_bayes/naive_bayes_sklearn.py](https://github.com/fuqiuai/lihang_algorithms/blob/master/naive_bayes/naive_bayes_sklearn.py)
运行结果:
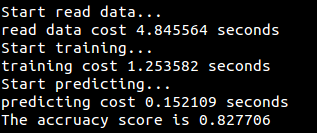
## 第五章 决策树
适用问题:多类分类
三个步骤:特征选择、决策树的生成和决策树的剪枝
常见的决策树算法有:
- **ID3**:特征划分基于**信息增益**
- **C4.5**:特征划分基于**信息增益比**
- **CART**:特征划分基于**基尼指数**
ID3算法代码:[decision_tree/ID3.py](https://github.com/fuqiuai/lihang_algorithms/blob/master/decision_tree/ID3.py)
运行结果:
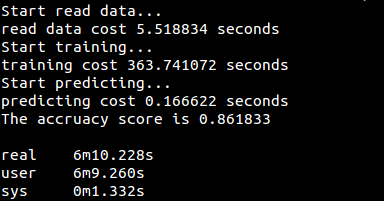
C4.5算法代码:[decision_tree/C45.py](https://github.com/fuqiuai/lihang_algorithms/blob/master/decision_tree/C45.py)
运行结果:
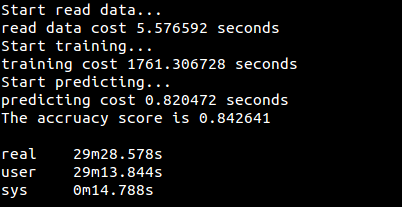
CART算法代码(用sklearn实现):[decision_tree/decision_tree_sklearn.py](https://github.com/fuqiuai/lihang_algorithms/blob/master/decision_tree/decision_tree_sklearn.py)
运行结果:
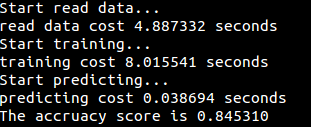
## 第六章 逻辑斯谛回归
### 二项逻辑斯谛回归
适用问题:二类分类
可类比于感知机算法
实验数据:[train_binary.csv](https://github.com/fuqiuai/lihang_algorithms/blob/master/data/train_binary.csv)
代码:[logistic_regression/logistic_regression.py](https://github.com/fuqiuai/lihang_algorithms/blob/master/logistic_regression/logistic_regression.py)
运行结果:
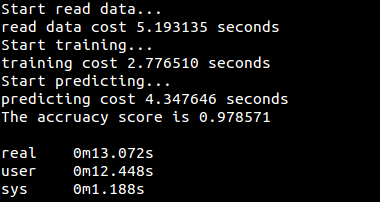
### (多项)逻辑斯谛回归
适用问题:多类分类
实验数据:[train.csv](https://github.com/fuqiuai/lihang_algorithms/blob/master/data/train.csv)
代码(用sklearn实现):[logistic_regression/logistic_regression_sklearn.py](https://github.com/fuqiuai/lihang_algorithms/blob/master/logistic_regression/logistic_regression_sklearn.py)
运行结果:
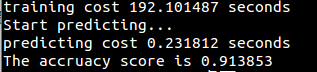
## 第六章 最大熵模型
适用问题:多类分类
下面用改进的迭代尺度法(IIS)学习最大熵模型,将特征函数定义为:
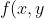=\left\{\begin{matrix}&space;1&space;&&space;(x,y)\in&space;train&space;set&space;\\&space;0&space;&&space;else&space;\end{matrix}\right. "f(x,y)=\left\{\begin{matrix} 1 & (x,y)\in train set \\ 0 & else \end{matrix}\right.")
与其他分类器不同的是,最大熵模型中的f(x,y)中的x是单独的一个特征,不是一个n维特征向量,因此我们需要对每个维度特征加一个区分标签;如X=(x0,x1,x2,...)变为X=(0_x0,1_x1,2_x2,...)
代码:[maxEnt/maxEnt.py](https://github.com/fuqiuai/lihang_algorithms/blob/master/maxEnt/maxEnt.py)
运行结果:
## 第七章 支持向量机
适用问题:二类分类
实验数据:二分类的数据 [train_binary.csv](https://github.com/fuqiuai/lihang_algorithms/blob/master/data/train_binary.csv)
SVM有三种模型,由简至繁为
- 当训练数据训练可分时,通过硬间隔最大化,可学习到**硬间隔支持向量机**,又叫**线性可分支持向量机**
- 当训练数据训练近似可分时,通过软间隔最大化,可学习到**软间隔支持向量机**,又叫**线性支持向量机**
- 当训练数据训练不可分时,通过软间隔最大化及**核技巧(kernel trick)**,可学习到**非线性支持向量机**
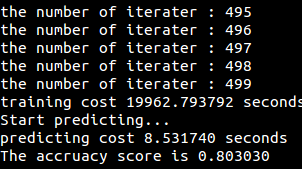
代码(用sklearn实现):[svm/svm_sklearn.py](https://github.com/fuqiuai/lihang_algorithms/blob/master/svm/svm_sklearn.py)
*注:可用拆解法(如OvO,OvR)将svm扩展成适用于多分类问题(其他二分类问题亦可),sklearn中已经实现*
运行结果:
## 第八章 提升方法
提升方法就是组合一系列弱分类器构成一个强分类器,AdaBoost是其代表性算法
### AdaBoost算法
适用问题:二类分类,要处理多类分类需进行改进
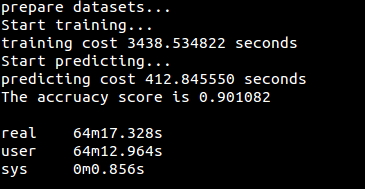
代码(用sklearn实现):[AdaBoost/AdaBoost_sklearn.py](https://github.com/fuqiuai/lihang_algorithms/blob/master/AdaBoost/AdaBoost_sklearn.py)
实验数据为[train.csv](https://github.com/fuqiuai/lihang_algorithms/blob/master/data/train.csv)的运行结果:
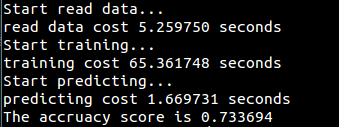
实验数据为[train_binary.csv](https://github.com/fuqiuai/lihang_algorithms/blob/master/data/train_binary.csv)的运行结果: