# data-juicer
**Repository Path**: james-hadoop/data-juicer
## Basic Information
- **Project Name**: data-juicer
- **Description**: No description available
- **Primary Language**: Python
- **License**: Apache-2.0
- **Default Branch**: main
- **Homepage**: None
- **GVP Project**: No
## Statistics
- **Stars**: 0
- **Forks**: 0
- **Created**: 2025-03-28
- **Last Updated**: 2025-06-07
## Categories & Tags
**Categories**: Uncategorized
**Tags**: None
## README
[[英文主页]](README.md) | [[DJ-Cookbook]](docs/tutorial/DJ-Cookbook_ZH.md) | [[算子池]](docs/Operators.md) | [[API]](https://modelscope.github.io/data-juicer/zh_CN/main/api) | [[Awesome LLM Data]](docs/awesome_llm_data.md)
# Data Processing for and with Foundation Models
 

[](https://pypi.org/project/py-data-juicer)
[](https://hub.docker.com/r/datajuicer/data-juicer)
[](https://dail-wlcb.oss-cn-wulanchabu.aliyuncs.com/data_juicer/docker_images/data-juicer-latest.tar.gz)

[](docs/tutorial/DJ-Cookbook_ZH.md)
[](docs/tutorial/DJ-Cookbook_ZH.md)
[](https://modelscope.cn/studios?name=Data-Jiucer&page=1&sort=latest&type=1)
[](https://huggingface.co/spaces?&search=datajuicer)
[](docs/tutorial/DJ-Cookbook.md)
[](docs/tutorial/DJ-Cookbook_ZH.md)
[](docs/Operators.md)
[-B31B1B?logo=arxiv&logoColor=red)](https://arxiv.org/abs/2309.02033)
[](https://arxiv.org/abs/2501.14755)
Data-Juicer 是一个一站式系统,面向大模型的文本及多模态数据处理。我们提供了一个基于 JupyterLab 的 [Playground](http://8.138.149.181/),您可以从浏览器中在线试用 Data-Juicer。 如果Data-Juicer对您的研发有帮助,请支持加星(自动订阅我们的新发布)、以及引用我们的[工作](#参考文献) 。
[阿里云人工智能平台 PAI](https://www.aliyun.com/product/bigdata/learn) 已引用Data-Juicer并将其能力集成到PAI的数据处理产品中。PAI提供包含数据集管理、算力管理、模型工具链、模型开发、模型训练、模型部署、AI资产管理在内的功能模块,为用户提供高性能、高稳定、企业级的大模型工程化能力。数据处理的使用文档请参考:[PAI-大模型数据处理](https://help.aliyun.com/zh/pai/user-guide/components-related-to-data-processing-for-foundation-models/?spm=a2c4g.11186623.0.0.3e9821a69kWdvX)。
Data-Juicer正在积极更新和维护中,我们将定期强化和新增更多的功能和数据菜谱。热烈欢迎您加入我们(issues/PRs/[Slack频道](https://join.slack.com/t/data-juicer/shared_invite/zt-23zxltg9d-Z4d3EJuhZbCLGwtnLWWUDg?spm=a2c22.12281976.0.0.7a8275bc8g7ypp) /[钉钉群](https://qr.dingtalk.com/action/joingroup?code=v1,k1,YFIXM2leDEk7gJP5aMC95AfYT+Oo/EP/ihnaIEhMyJM=&_dt_no_comment=1&origin=11)/...),一起推进大模型的数据-模型协同开发和研究应用!
----
## 新消息
- 🛠️ [2025-06-04] 如何在“经验时代”处理反馈数据?我们提出了 [Trinity-RFT: A General-Purpose and Unified Framework for Reinforcement Fine-Tuning of LLMs](https://arxiv.org/abs/2505.17826),该框架利用 Data-Juicer 为 RFT 场景量身定制数据处理管道。
- 🎉 [2025-06-04] 我们的 [Data-Model Co-development 综述](https://arxiv.org/abs/2407.08583) 已被 IEEE Transactions on Pattern Analysis and Machine Intelligence(**TPAMI**)接收!欢迎探索并贡献[awesome-list](https://modelscope.github.io/data-juicer/en/main/docs/awesome_llm_data.html)。
- 🔎 [2025-06-04] 我们推出了 [DetailMaster: Can Your Text-to-Image Model Handle Long Prompts?](https://www.arxiv.org/abs/2505.16915) 一项合成基准测试,揭示了大模型虽擅长处理短描述,但在长提示下性能显著下降的问题。
- 🎉 [2025-05-06] 我们的 [Data-Juicer Sandbox](https://arxiv.org/abs/2407.11784) 已被接收为 **ICML'25 Spotlight**(处于所有投稿中的前 2.6%)!
- 💡 [2025-03-13] 我们提出[MindGYM: What Matters in Question Synthesis for Thinking-Centric Fine-Tuning?](https://arxiv.org/abs/2503.09499)。一种新的数据合成方法鼓励大模型自我合成高质量、低方差数据,实现高效SFT(如仅使用 *400 个样本* 即可在 [MathVision](https://mathllm.github.io/mathvision/#leaderboard) 上获得 *16%* 的增益)。
- 🤝 [2025-02-28] DJ 已被集成到 [Ray官方 Ecosystem](https://docs.ray.io/en/latest/ray-overview/ray-libraries.html) 和 [Example Gallery](https://docs.ray.io/en/latest/ray-more-libs/data_juicer_distributed_data_processing.html)。此外,我们在 DJ2.0 中的流式 JSON 加载补丁已被 [Apache Arrow 官方集成](https://github.com/apache/arrow/pull/45084)。
- 🎉 [2025-02-27] 我们的对比数据合成工作, [ImgDiff](https://arxiv.org/pdf/2408.04594), 已被 **CVPR'25** 接收!
- 💡 [2025-02-05] 我们提出了一种新的数据选择方法 [Diversity as a Reward: Fine-Tuning LLMs on a Mixture of Domain-Undetermined Data](https://www.arxiv.org/abs/2502.04380),该方法基于理论指导,将数据多样性建模为奖励信号,在 7 个基准测试中,微调 SOTA LLMs 取得了更好的整体表现。
- 🚀 [2025-01-11] 我们发布了 2.0 版论文 [Data-Juicer 2.0: Cloud-Scale Adaptive Data Processing for Foundation Models](https://arxiv.org/abs/2501.14755)。DJ现在可以使用阿里云集群中 50 个 Ray 节点上的 6400 个 CPU 核心在 2.1 小时内处理 70B 数据样本,并使用 8 个 Ray 节点上的 1280 个 CPU 核心在 2.8 小时内对 5TB 数据进行重复数据删除。
- 🛠️ [2025-01-03] 我们通过 20 多个相关的新 [OP](https://github.com/modelscope/data-juicer/releases/tag/v1.0.2) 以及与 LLaMA-Factory 和 ModelScope-Swift 兼容的统一 [数据集格式](https://github.com/modelscope/data-juicer/releases/tag/v1.0.3) 更好地支持Post-Tuning场景。


[](https://pypi.org/project/py-data-juicer)
[](https://hub.docker.com/r/datajuicer/data-juicer)
[](https://dail-wlcb.oss-cn-wulanchabu.aliyuncs.com/data_juicer/docker_images/data-juicer-latest.tar.gz)

[](docs/tutorial/DJ-Cookbook_ZH.md)
[](docs/tutorial/DJ-Cookbook_ZH.md)
[](https://modelscope.cn/studios?name=Data-Jiucer&page=1&sort=latest&type=1)
[](https://huggingface.co/spaces?&search=datajuicer)
[](docs/tutorial/DJ-Cookbook.md)
[](docs/tutorial/DJ-Cookbook_ZH.md)
[](docs/Operators.md)
[-B31B1B?logo=arxiv&logoColor=red)](https://arxiv.org/abs/2309.02033)
[](https://arxiv.org/abs/2501.14755)
Data-Juicer 是一个一站式系统,面向大模型的文本及多模态数据处理。我们提供了一个基于 JupyterLab 的 [Playground](http://8.138.149.181/),您可以从浏览器中在线试用 Data-Juicer。 如果Data-Juicer对您的研发有帮助,请支持加星(自动订阅我们的新发布)、以及引用我们的[工作](#参考文献) 。
[阿里云人工智能平台 PAI](https://www.aliyun.com/product/bigdata/learn) 已引用Data-Juicer并将其能力集成到PAI的数据处理产品中。PAI提供包含数据集管理、算力管理、模型工具链、模型开发、模型训练、模型部署、AI资产管理在内的功能模块,为用户提供高性能、高稳定、企业级的大模型工程化能力。数据处理的使用文档请参考:[PAI-大模型数据处理](https://help.aliyun.com/zh/pai/user-guide/components-related-to-data-processing-for-foundation-models/?spm=a2c4g.11186623.0.0.3e9821a69kWdvX)。
Data-Juicer正在积极更新和维护中,我们将定期强化和新增更多的功能和数据菜谱。热烈欢迎您加入我们(issues/PRs/[Slack频道](https://join.slack.com/t/data-juicer/shared_invite/zt-23zxltg9d-Z4d3EJuhZbCLGwtnLWWUDg?spm=a2c22.12281976.0.0.7a8275bc8g7ypp) /[钉钉群](https://qr.dingtalk.com/action/joingroup?code=v1,k1,YFIXM2leDEk7gJP5aMC95AfYT+Oo/EP/ihnaIEhMyJM=&_dt_no_comment=1&origin=11)/...),一起推进大模型的数据-模型协同开发和研究应用!
----
## 新消息
- 🛠️ [2025-06-04] 如何在“经验时代”处理反馈数据?我们提出了 [Trinity-RFT: A General-Purpose and Unified Framework for Reinforcement Fine-Tuning of LLMs](https://arxiv.org/abs/2505.17826),该框架利用 Data-Juicer 为 RFT 场景量身定制数据处理管道。
- 🎉 [2025-06-04] 我们的 [Data-Model Co-development 综述](https://arxiv.org/abs/2407.08583) 已被 IEEE Transactions on Pattern Analysis and Machine Intelligence(**TPAMI**)接收!欢迎探索并贡献[awesome-list](https://modelscope.github.io/data-juicer/en/main/docs/awesome_llm_data.html)。
- 🔎 [2025-06-04] 我们推出了 [DetailMaster: Can Your Text-to-Image Model Handle Long Prompts?](https://www.arxiv.org/abs/2505.16915) 一项合成基准测试,揭示了大模型虽擅长处理短描述,但在长提示下性能显著下降的问题。
- 🎉 [2025-05-06] 我们的 [Data-Juicer Sandbox](https://arxiv.org/abs/2407.11784) 已被接收为 **ICML'25 Spotlight**(处于所有投稿中的前 2.6%)!
- 💡 [2025-03-13] 我们提出[MindGYM: What Matters in Question Synthesis for Thinking-Centric Fine-Tuning?](https://arxiv.org/abs/2503.09499)。一种新的数据合成方法鼓励大模型自我合成高质量、低方差数据,实现高效SFT(如仅使用 *400 个样本* 即可在 [MathVision](https://mathllm.github.io/mathvision/#leaderboard) 上获得 *16%* 的增益)。
- 🤝 [2025-02-28] DJ 已被集成到 [Ray官方 Ecosystem](https://docs.ray.io/en/latest/ray-overview/ray-libraries.html) 和 [Example Gallery](https://docs.ray.io/en/latest/ray-more-libs/data_juicer_distributed_data_processing.html)。此外,我们在 DJ2.0 中的流式 JSON 加载补丁已被 [Apache Arrow 官方集成](https://github.com/apache/arrow/pull/45084)。
- 🎉 [2025-02-27] 我们的对比数据合成工作, [ImgDiff](https://arxiv.org/pdf/2408.04594), 已被 **CVPR'25** 接收!
- 💡 [2025-02-05] 我们提出了一种新的数据选择方法 [Diversity as a Reward: Fine-Tuning LLMs on a Mixture of Domain-Undetermined Data](https://www.arxiv.org/abs/2502.04380),该方法基于理论指导,将数据多样性建模为奖励信号,在 7 个基准测试中,微调 SOTA LLMs 取得了更好的整体表现。
- 🚀 [2025-01-11] 我们发布了 2.0 版论文 [Data-Juicer 2.0: Cloud-Scale Adaptive Data Processing for Foundation Models](https://arxiv.org/abs/2501.14755)。DJ现在可以使用阿里云集群中 50 个 Ray 节点上的 6400 个 CPU 核心在 2.1 小时内处理 70B 数据样本,并使用 8 个 Ray 节点上的 1280 个 CPU 核心在 2.8 小时内对 5TB 数据进行重复数据删除。
- 🛠️ [2025-01-03] 我们通过 20 多个相关的新 [OP](https://github.com/modelscope/data-juicer/releases/tag/v1.0.2) 以及与 LLaMA-Factory 和 ModelScope-Swift 兼容的统一 [数据集格式](https://github.com/modelscope/data-juicer/releases/tag/v1.0.3) 更好地支持Post-Tuning场景。
History News:
>
- [2024-12-17] 我们提出了 *HumanVBench*,它包含 16 个以人为中心的任务,使用合成数据,从内在情感和外在表现的角度对22个视频 MLLM 的能力进行基准测试。请参阅我们的 [论文](https://arxiv.org/abs/2412.17574) 中的更多详细信息,并尝试使用它 [评估](https://github.com/modelscope/data-juicer/tree/HumanVBench) 您的模型。
- [2024-11-22] 我们发布 DJ [v1.0.0](https://github.com/modelscope/data-juicer/releases/tag/v1.0.0),其中我们重构了 Data-Juicer 的 *Operator*、*Dataset*、*Sandbox* 和许多其他模块以提高可用性,例如支持容错、FastAPI 和自适应资源管理。
- [2024-08-25] 我们在 KDD'2024 中提供了有关多模态 LLM 数据处理的[教程](https://modelscope.github.io/data-juicer/_static/tutorial_kdd24.html)。
- [2024-08-09] 我们提出了Img-Diff,它通过*对比数据合成*来增强多模态大型语言模型的性能,在[MMVP benchmark](https://tsb0601.github.io/mmvp_blog/)中比GPT-4V高出12个点。 更多细节请参阅我们的 [论文](https://arxiv.org/abs/2408.04594), 以及从 [huggingface](https://huggingface.co/datasets/datajuicer/Img-Diff) 和 [modelscope](https://modelscope.cn/datasets/Data-Juicer/Img-Diff)下载这份数据集。
- [2024-07-24] "天池 Better Synth 多模态大模型数据合成赛"——第四届Data-Juicer大模型数据挑战赛已经正式启动!立即访问[竞赛官网](https://tianchi.aliyun.com/competition/entrance/532251),了解赛事详情。
- [2024-07-17] 我们利用Data-Juicer[沙盒实验室套件](https://github.com/modelscope/data-juicer/blob/main/docs/Sandbox-ZH.md),通过数据与模型间的系统性研发工作流,调优数据和模型,在[VBench](https://huggingface.co/spaces/Vchitect/VBench_Leaderboard)文生视频排行榜取得了新的榜首。相关成果已经整理发表在[论文](http://arxiv.org/abs/2407.11784)中,并且模型已在[ModelScope](https://modelscope.cn/models/Data-Juicer/Data-Juicer-T2V)和[HuggingFace](https://huggingface.co/datajuicer/Data-Juicer-T2V)平台发布。
- [2024-07-12] 我们的MLLM-Data精选列表已经演化为一个模型-数据协同开发的角度系统性[综述](https://arxiv.org/abs/2407.08583)。欢迎[浏览](docs/awesome_llm_data.md)或参与贡献!
- [2024-06-01] ModelScope-Sora"数据导演"创意竞速——第三届Data-Juicer大模型数据挑战赛已经正式启动!立即访问[竞赛官网](https://tianchi.aliyun.com/competition/entrance/532219),了解赛事详情。
- [2024-03-07] 我们现在发布了 **Data-Juicer [v0.2.0](https://github.com/modelscope/data-juicer/releases/tag/v0.2.0)**! 在这个新版本中,我们支持了更多的 **多模态数据(包括视频)** 相关特性。我们还启动了 **[DJ-SORA](docs/DJ_SORA_ZH.md)** ,为SORA-like大模型构建开放的大规模高质量数据集!
- [2024-02-20] 我们在积极维护一份关于LLM-Data的*精选列表*,欢迎[访问](docs/awesome_llm_data.md)并参与贡献!
- [2024-02-05] 我们的论文被SIGMOD'24 industrial track接收!
- [2024-01-10] 开启"数据混合"新视界——第二届Data-Juicer大模型数据挑战赛已经正式启动!立即访问[竞赛官网](https://tianchi.aliyun.com/competition/entrance/532174),了解赛事详情。
- [2024-01-05] **Data-Juicer v0.1.3** 版本发布了。
在这个新版本中,我们支持了**更多Python版本**(3.8-3.10),同时支持了**多模态**数据集的[转换](tools/fmt_conversion/multimodal/README_ZH.md)和[处理](docs/Operators.md)(包括文本、图像和音频。更多模态也将会在之后支持)!
此外,我们的论文也更新到了[第三版](https://arxiv.org/abs/2309.02033) 。
- [2023-10-13] 我们的第一届以数据为中心的 LLM 竞赛开始了!
请访问大赛官网,FT-Data Ranker([1B赛道](https://tianchi.aliyun.com/competition/entrance/532157) 、[7B赛道](https://tianchi.aliyun.com/competition/entrance/532158) ) ,了解更多信息。
## 为什么选择 Data-Juicer?
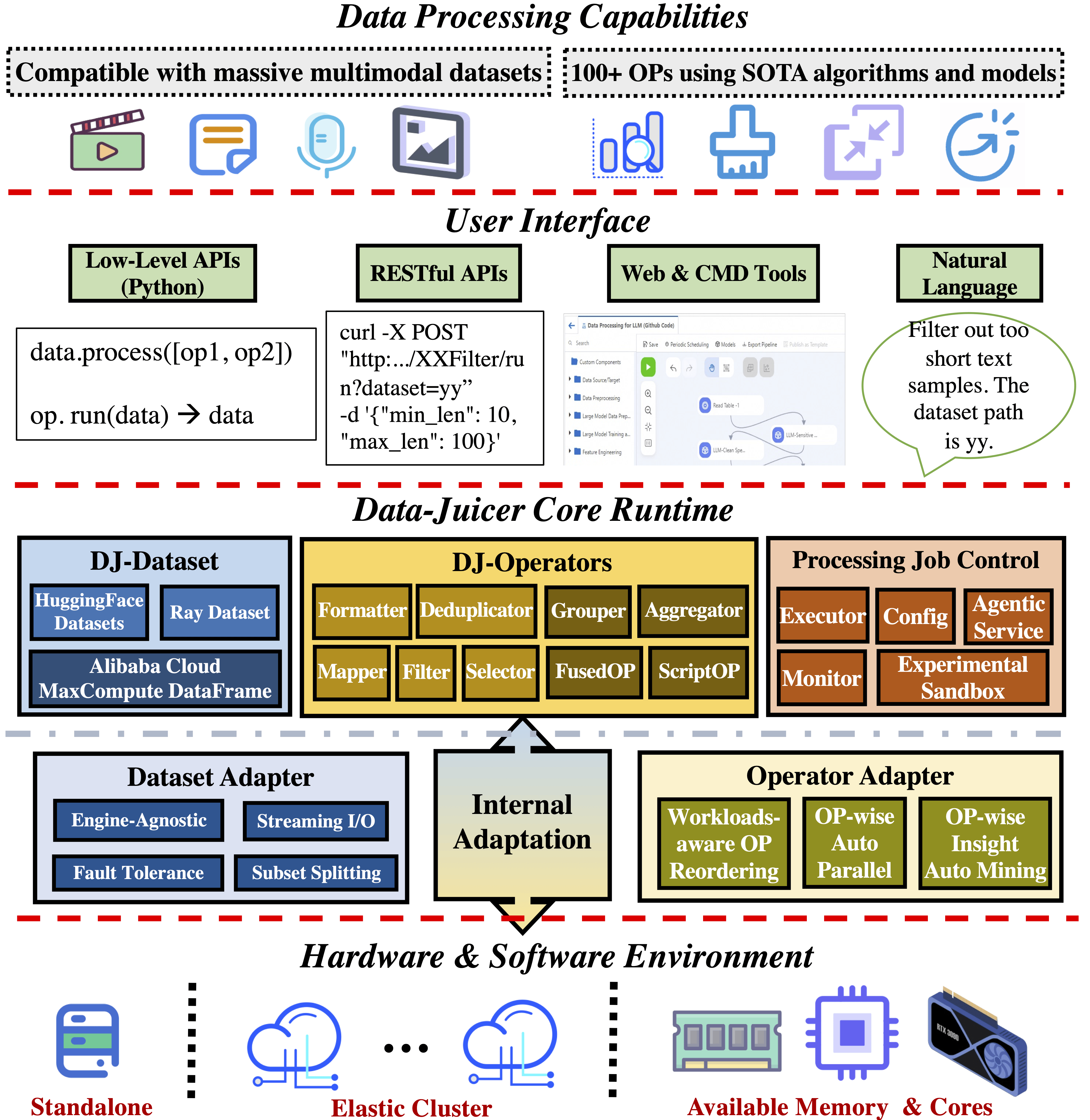 - **系统化和可重用**:
系统化地为用户提供 100 多个核心 [算子](docs/Operators.md) 和 50 多个可重用的数据菜谱和
专用工具套件,旨在解耦于特定的多模态 LLM 数据集和处理管道运行。支持预训练、后训练、英语、中文等场景中的数据分析、清洗和合成。
- **易用、可扩展**:
简洁灵活,提供快速[入门指南](docs/tutorial/QuickStart_ZH.md)和包含丰富使用示例的[DJ-Cookbook](docs/tutorial/DJ-Cookbook_ZH.md)。您可以灵活实现自己的OP,[自定义](docs/DeveloperGuide_ZH.md)数据处理工作流。
- **高效、稳定**:提供性能优化的[并行数据处理能力](docs/Distributed_ZH.md)(Aliyun-PAI\Ray\CUDA\OP Fusion),
更快、更少资源消耗,基于大规模生产环境打磨。
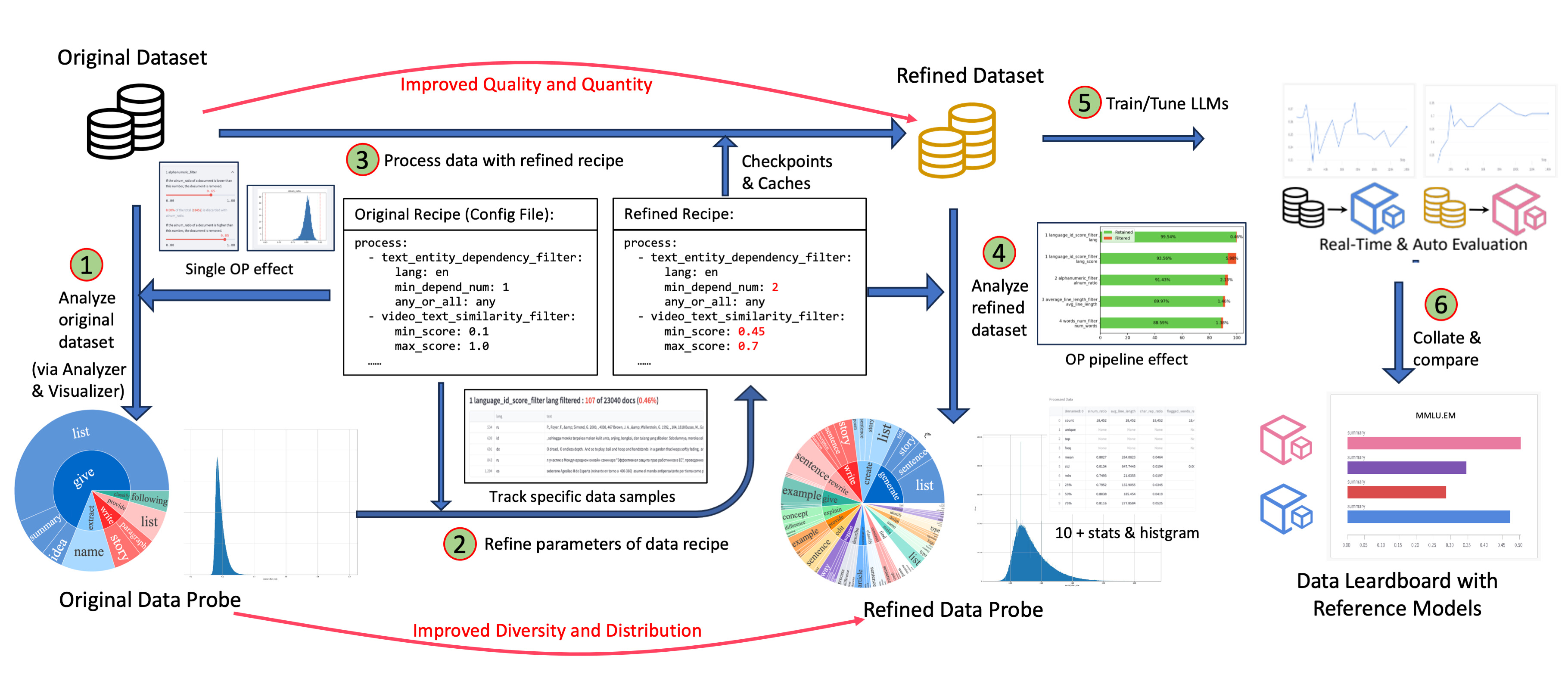
- **效果验证、沙盒**:支持数据模型协同开发,通过[沙盒实验室](docs/Sandbox_ZH.md)实现快速迭代,提供反馈循环、可视化等功能,让您更好地理解和改进数据和模型。已经有许多基于 DJ 衍生的数据菜谱和模型经过了效用验证,譬如在预训练、文生视频、图文生成等场景。
## 文档
- 教程
- [DJ-Cookbook](docs/tutorial/DJ-Cookbook_ZH.md)
- [安装](docs/tutorial/Installation_ZH.md)
- [快速上手](docs/tutorial/QuickStart_ZH.md)
- 其他帮助文档
- [算子提要](docs/Operators.md)
- [数据菜谱Gallery](docs/RecipeGallery_ZH.md)
- [数据集配置指南](docs/DatasetCfg_ZH.md)
- [Awesome Data-Model Co-Development of MLLMs](docs/awesome_llm_data.md)
- [“坏”数据展览](docs/BadDataExhibition_ZH.md)
- [DJ-SORA](docs/DJ_SORA_ZH.md)
- [API服务化](docs/DJ_service_ZH.md)
- [开发者指南](docs/DeveloperGuide_ZH.md)
- [Data-Juicer分布式数据处理](docs/Distributed_ZH.md)
- [沙盒实验室](docs/Sandbox_ZH.md)
- Demos
- [演示](demos/README_ZH.md)
- [自动化评测:HELM 评测及可视化](demos/auto_evaluation_helm/README_ZH.md)
- [为LLM构造角色扮演的system prompt](demos/role_playing_system_prompt/README_ZH.md)
- 工具
- [分布式模糊去重工具](tools/distributed_deduplication/README_ZH.md)
- [Auto Evaluation Toolkit](tools/evaluator/README_ZH.md)
- [GPT EVAL: 使用OpenAI API评测大模型](tools/evaluator/gpt_eval/README_ZH.md)
- [Evaluation Results Recorder](tools/evaluator/recorder/README_ZH.md)
- [格式转换工具](tools/fmt_conversion/README_ZH.md)
- [多模态工具](tools/fmt_conversion/multimodal/README_ZH.md)
- [后微调工具](tools/fmt_conversion/post_tuning_dialog/README_ZH.md)
- [数据菜谱的自动化超参优化](tools/hpo/README_ZH.md)
- [Label Studio Service Utility](tools/humanops/README.md)
- [视频生成评测工具](tools/mm_eval/inception_metrics/README_ZH.md)
- [后处理工具](tools/postprocess/README_ZH.md)
- [预处理工具](tools/preprocess/README_ZH.md)
- [给数据打分](tools/quality_classifier/README_ZH.md)
- 第三方
- [大语言模型生态](thirdparty/LLM_ecosystems/README_ZH.md)
- [第三方模型库](thirdparty/models/README_ZH.md)
## 开源协议
Data-Juicer 在 Apache License 2.0 协议下发布。
## 贡献
大模型是一个高速发展的领域,我们非常欢迎贡献新功能、修复漏洞以及文档改善。请参考[开发者指南](docs/DeveloperGuide_ZH.md)。
## 致谢
Data-Juicer被许多大模型相关产品和研究工作所使用,例如阿里巴巴通义和阿里云人工智能平台 (PAI) 之上的工业界场景。 我们期待更多您的体验反馈、建议和合作共建!
Data-Juicer 感谢社区[贡献者](https://github.com/modelscope/data-juicer/graphs/contributors) 和相关的先驱开源项目,譬如[Huggingface-Datasets](https://github.com/huggingface/datasets), [Bloom](https://huggingface.co/bigscience/bloom), [RedPajama](https://github.com/togethercomputer/RedPajama-Data/tree/rp_v1), [Arrow](https://github.com/apache/arrow), [Ray](https://github.com/ray-project/ray), ....
## 参考文献
如果您发现Data-Juicer对您的研发有帮助,请引用以下工作,[1.0paper](https://arxiv.org/abs/2309.02033), [2.0paper](https://arxiv.org/abs/2501.14755)。
```
@inproceedings{djv1,
title={Data-Juicer: A One-Stop Data Processing System for Large Language Models},
author={Daoyuan Chen and Yilun Huang and Zhijian Ma and Hesen Chen and Xuchen Pan and Ce Ge and Dawei Gao and Yuexiang Xie and Zhaoyang Liu and Jinyang Gao and Yaliang Li and Bolin Ding and Jingren Zhou},
booktitle={International Conference on Management of Data},
year={2024}
}
@article{djv2,
title={Data-Juicer 2.0: Cloud-Scale Adaptive Data Processing for Foundation Models},
author={Chen, Daoyuan and Huang, Yilun and Pan, Xuchen and Jiang, Nana and Wang, Haibin and Ge, Ce and Chen, Yushuo and Zhang, Wenhao and Ma, Zhijian and Zhang, Yilei and Huang, Jun and Lin, Wei and Li, Yaliang and Ding, Bolin and Zhou, Jingren},
journal={arXiv preprint arXiv:2501.14755},
year={2024}
}
```
- **系统化和可重用**:
系统化地为用户提供 100 多个核心 [算子](docs/Operators.md) 和 50 多个可重用的数据菜谱和
专用工具套件,旨在解耦于特定的多模态 LLM 数据集和处理管道运行。支持预训练、后训练、英语、中文等场景中的数据分析、清洗和合成。
- **易用、可扩展**:
简洁灵活,提供快速[入门指南](docs/tutorial/QuickStart_ZH.md)和包含丰富使用示例的[DJ-Cookbook](docs/tutorial/DJ-Cookbook_ZH.md)。您可以灵活实现自己的OP,[自定义](docs/DeveloperGuide_ZH.md)数据处理工作流。
- **高效、稳定**:提供性能优化的[并行数据处理能力](docs/Distributed_ZH.md)(Aliyun-PAI\Ray\CUDA\OP Fusion),
更快、更少资源消耗,基于大规模生产环境打磨。
- **效果验证、沙盒**:支持数据模型协同开发,通过[沙盒实验室](docs/Sandbox_ZH.md)实现快速迭代,提供反馈循环、可视化等功能,让您更好地理解和改进数据和模型。已经有许多基于 DJ 衍生的数据菜谱和模型经过了效用验证,譬如在预训练、文生视频、图文生成等场景。

## 文档
- 教程
- [DJ-Cookbook](docs/tutorial/DJ-Cookbook_ZH.md)
- [安装](docs/tutorial/Installation_ZH.md)
- [快速上手](docs/tutorial/QuickStart_ZH.md)
- 其他帮助文档
- [算子提要](docs/Operators.md)
- [数据菜谱Gallery](docs/RecipeGallery_ZH.md)
- [数据集配置指南](docs/DatasetCfg_ZH.md)
- [Awesome Data-Model Co-Development of MLLMs](docs/awesome_llm_data.md)
- [“坏”数据展览](docs/BadDataExhibition_ZH.md)
- [DJ-SORA](docs/DJ_SORA_ZH.md)
- [API服务化](docs/DJ_service_ZH.md)
- [开发者指南](docs/DeveloperGuide_ZH.md)
- [Data-Juicer分布式数据处理](docs/Distributed_ZH.md)
- [沙盒实验室](docs/Sandbox_ZH.md)
- Demos
- [演示](demos/README_ZH.md)
- [自动化评测:HELM 评测及可视化](demos/auto_evaluation_helm/README_ZH.md)
- [为LLM构造角色扮演的system prompt](demos/role_playing_system_prompt/README_ZH.md)
- 工具
- [分布式模糊去重工具](tools/distributed_deduplication/README_ZH.md)
- [Auto Evaluation Toolkit](tools/evaluator/README_ZH.md)
- [GPT EVAL: 使用OpenAI API评测大模型](tools/evaluator/gpt_eval/README_ZH.md)
- [Evaluation Results Recorder](tools/evaluator/recorder/README_ZH.md)
- [格式转换工具](tools/fmt_conversion/README_ZH.md)
- [多模态工具](tools/fmt_conversion/multimodal/README_ZH.md)
- [后微调工具](tools/fmt_conversion/post_tuning_dialog/README_ZH.md)
- [数据菜谱的自动化超参优化](tools/hpo/README_ZH.md)
- [Label Studio Service Utility](tools/humanops/README.md)
- [视频生成评测工具](tools/mm_eval/inception_metrics/README_ZH.md)
- [后处理工具](tools/postprocess/README_ZH.md)
- [预处理工具](tools/preprocess/README_ZH.md)
- [给数据打分](tools/quality_classifier/README_ZH.md)
- 第三方
- [大语言模型生态](thirdparty/LLM_ecosystems/README_ZH.md)
- [第三方模型库](thirdparty/models/README_ZH.md)
## 开源协议
Data-Juicer 在 Apache License 2.0 协议下发布。
## 贡献
大模型是一个高速发展的领域,我们非常欢迎贡献新功能、修复漏洞以及文档改善。请参考[开发者指南](docs/DeveloperGuide_ZH.md)。
## 致谢
Data-Juicer被许多大模型相关产品和研究工作所使用,例如阿里巴巴通义和阿里云人工智能平台 (PAI) 之上的工业界场景。 我们期待更多您的体验反馈、建议和合作共建!
Data-Juicer 感谢社区[贡献者](https://github.com/modelscope/data-juicer/graphs/contributors) 和相关的先驱开源项目,譬如[Huggingface-Datasets](https://github.com/huggingface/datasets), [Bloom](https://huggingface.co/bigscience/bloom), [RedPajama](https://github.com/togethercomputer/RedPajama-Data/tree/rp_v1), [Arrow](https://github.com/apache/arrow), [Ray](https://github.com/ray-project/ray), ....
## 参考文献
如果您发现Data-Juicer对您的研发有帮助,请引用以下工作,[1.0paper](https://arxiv.org/abs/2309.02033), [2.0paper](https://arxiv.org/abs/2501.14755)。
```
@inproceedings{djv1,
title={Data-Juicer: A One-Stop Data Processing System for Large Language Models},
author={Daoyuan Chen and Yilun Huang and Zhijian Ma and Hesen Chen and Xuchen Pan and Ce Ge and Dawei Gao and Yuexiang Xie and Zhaoyang Liu and Jinyang Gao and Yaliang Li and Bolin Ding and Jingren Zhou},
booktitle={International Conference on Management of Data},
year={2024}
}
@article{djv2,
title={Data-Juicer 2.0: Cloud-Scale Adaptive Data Processing for Foundation Models},
author={Chen, Daoyuan and Huang, Yilun and Pan, Xuchen and Jiang, Nana and Wang, Haibin and Ge, Ce and Chen, Yushuo and Zhang, Wenhao and Ma, Zhijian and Zhang, Yilei and Huang, Jun and Lin, Wei and Li, Yaliang and Ding, Bolin and Zhou, Jingren},
journal={arXiv preprint arXiv:2501.14755},
year={2024}
}
```
更多Data-Juicer团队关于数据的论文:
>
- (ICML'25 Spotlight) [Data-Juicer Sandbox: A Feedback-Driven Suite for Multimodal Data-Model Co-development](https://arxiv.org/abs/2407.11784)
- (CVPR'25) [ImgDiff: Contrastive Data Synthesis for Vision Large Language Models](https://arxiv.org/abs/2408.04594)
- (TPAMI'25) [The Synergy between Data and Multi-Modal Large Language Models: A Survey from Co-Development Perspective](https://arxiv.org/abs/2407.08583)
- (Benchmark Data) [HumanVBench: Exploring Human-Centric Video Understanding Capabilities of MLLMs with Synthetic Benchmark Data](https://arxiv.org/abs/2412.17574)
- (Benchmark Data) [DetailMaster: Can Your Text-to-Image Model Handle Long Prompts?](https://www.arxiv.org/abs/2505.16915)
- (Data Synthesis) [Diversity as a Reward: Fine-Tuning LLMs on a Mixture of Domain-Undetermined Data](https://www.arxiv.org/abs/2502.04380)
- (Data Synthesis) [MindGYM: What Matters in Question Synthesis for Thinking-Centric Fine-Tuning?](https://arxiv.org/abs/2503.09499)
- (Data Scaling) [BiMix: A Bivariate Data Mixing Law for Language Model Pretraining](https://arxiv.org/abs/2405.14908)