# weiboSpider
**Repository Path**: jishichang/weiboSpider
## Basic Information
- **Project Name**: weiboSpider
- **Description**: 新浪微博爬虫,用python爬取新浪微博数据
- **Primary Language**: Unknown
- **License**: Not specified
- **Default Branch**: master
- **Homepage**: None
- **GVP Project**: No
## Statistics
- **Stars**: 1
- **Forks**: 0
- **Created**: 2020-11-27
- **Last Updated**: 2021-05-17
## Categories & Tags
**Categories**: Uncategorized
**Tags**: None
## README
* [功能](#功能)
* [输出](#输出)
* [实例](#实例)
* [运行环境](#运行环境)
* [使用说明](#使用说明)
* [版本](#0版本)
* [下载脚本](#1下载脚本)
* [安装依赖](#2安装依赖)
* [程序设置](#3程序设置)
* [设置数据库(可选)](#4设置数据库可选)
* [运行脚本](#5运行脚本)
* [按需求修改脚本(可选)](#6按需求修改脚本可选)
* [定期自动爬取微博(可选)](#7定期自动爬取微博可选)
* [如何获取cookie](#如何获取cookie)
* [如何获取user_id](#如何获取user_id)
* [注意事项](#注意事项)
## 功能
连续爬取**一个**或**多个**新浪微博用户(如[胡歌](https://weibo.cn/u/1223178222)、[迪丽热巴](https://weibo.cn/u/1669879400)、[郭碧婷](https://weibo.cn/u/1729370543))的数据,并将结果信息写入**文件**或**数据库**。写入信息几乎包括了用户微博的所有数据,主要有**用户信息**和**微博信息**两大类,前者包含用户昵称、关注数、粉丝数、微博数等等;后者包含微博正文、发布时间、发布工具、评论数等等,因为内容太多,这里不再赘述,详细内容见[输出](#输出)部分。
具体的写入文件类型如下:
- 写入**txt文件**(默认)
- 写入**csv文件**(默认)
- 写入**json文件**(可选)
- 写入**MySQL数据库**(可选)
- 写入**MongoDB数据库**(可选)
- 下载用户**原创**微博中的原始**图片**(可选)
- 下载用户**转发**微博中的原始**图片**([免cookie版](https://github.com/dataabc/weibo-crawler)特有)
- 下载用户**原创**微博中的**视频**(可选)
- 下载用户**转发**微博中的**视频**([免cookie版](https://github.com/dataabc/weibo-crawler)特有)
- 下载用户**原创**微博**Live Photo**中的**视频**([免cookie版](https://github.com/dataabc/weibo-crawler)特有)
- 下载用户**转发**微博**Live Photo**中的**视频**([免cookie版](https://github.com/dataabc/weibo-crawler)特有)
当然,如果你只对用户信息感兴趣,而不需要爬用户的微博,也可以通过设置实现只爬取微博用户信息的功能。
程序也可以实现**爬取结果自动更新**,即:现在爬取了目标用户的微博,几天之后,目标用户可能又发新微博了。通过设置,可以实现每隔几天**增量爬取**用户这几天发的新微博。具体方法见[定期自动爬取微博](#7定期自动爬取微博可选)。
本程序需要设置用户cookie,以获取微博访问权限,后面会讲解如何获取cookie。如需[免cookie版](https://github.com/dataabc/weibo-crawler),大家可以访问,二者功能类似,免cookie版获取的信息更多,用法更简单,而且不需要cookie。
## 输出
本部分为爬取到的字段信息说明,为了与[免cookie版](https://github.com/dataabc/weibo-crawler)区分,下面将两者爬取到的信息都列出来。如果是免cookie版所特有的信息,会有免cookie标注,没有标注的为二者共有的信息。
**用户信息**
- 用户id:微博用户id,如"1669879400",其实这个字段本来就是已知字段
- 昵称:用户昵称,如"Dear-迪丽热巴"
- 性别(免cookie版):微博用户性别
- 生日(免cookie版):用户出生日期
- 所在地(免cookie版):用户所在地
- 大学(免cookie版):用户上学时学校的名字
- 公司(免cookie版):用户所属公司名字
- 阳光信用(免cookie版):用户的阳光信用
- 微博注册时间(免cookie版):用户微博注册日期
- 微博数:用户的全部微博数(转发微博+原创微博)
- 关注数:用户关注的微博数量
- 粉丝数:用户的粉丝数
- 简介(免cookie版):用户简介
- 主页地址(免cookie版):微博移动版主页url,如
- 头像url(免cookie版):用户头像url
- 高清头像url(免cookie版):用户高清头像url
- 微博等级(免cookie版):用户微博等级
- 会员等级(免cookie版):微博会员用户等级,普通用户该等级为0
- 是否认证(免cookie版):用户是否认证,为布尔类型
- 认证类型(免cookie版):用户认证类型,如个人认证、企业认证、政府认证等
- 认证信息(免cookie版):为认证用户特有,用户信息栏显示的认证信息
***
**微博信息**
- 微博id:微博唯一标志
- 微博内容:微博正文
- 原始图片url:原创微博图片和转发微博转发理由中图片的url,若某条微博存在多张图片,每个url以英文逗号分隔,若没有图片则值为"无"
- 视频url: 微博中的视频url,若微博中没有视频,则值为"无"
- 微博发布位置:位置微博中的发布位置
- 微博发布时间:微博发布时的时间,精确到分
- 点赞数:微博被赞的数量
- 转发数:微博被转发的数量
- 评论数:微博被评论的数量
- 微博发布工具:微博的发布工具,如iPhone客户端、HUAWEI Mate 20 Pro等
- 结果文件:保存在当前目录weibo文件夹下以用户昵称为名的文件夹里,名字为"user_id.csv"和"user_id.txt"的形式
- 微博图片:原创微博中的图片和转发微博转发理由中的图片,保存在以用户昵称为名的文件夹下的img文件夹里
- 微博视频:原创微博中的视频,保存在以用户昵称为名的文件夹下的video文件夹里
- 微博bid(免cookie版):为[免cookie版](https://github.com/dataabc/weibo-crawler)所特有,与本程序中的微博id是同一个值
- 话题(免cookie版):微博话题,即两个#中的内容,若存在多个话题,每个url以英文逗号分隔,若没有则值为''
- @用户(免cookie版):微博@的用户,若存在多个@用户,每个url以英文逗号分隔,若没有则值为''
- 原始微博(免cookie版):为转发微博所特有,是转发微博中那条被转发的微博,存储为字典形式,包含了上述微博信息中的所有内容,如微博id、微博内容等等
## 实例
以爬取迪丽热巴的微博为例,我们需要修改**config.json**文件,文件内容如下:
```
{
"user_id_list": ["1669879400"],
"filter": 1,
"since_date": "1900-01-01",
"write_mode": ["csv", "txt", "json"],
"pic_download": 1,
"video_download": 1,
"cookie": "your cookie"
}
```
对于上述参数的含义以及取值范围,这里仅作简单介绍,详细信息见[程序设置](#3程序设置)。
>**user_id_list**代表我们要爬取的微博用户的user_id,可以是一个或多个,也可以是文件路径,微博用户Dear-迪丽热巴的user_id为1669879400,具体如何获取user_id见[如何获取user_id](#如何获取user_id);
**filter**的值为1代表爬取全部原创微博,值为0代表爬取全部微博(原创+转发);
**since_date**代表我们要爬取since_date日期之后发布的微博,因为我要爬迪丽热巴的全部原创微博,所以since_date设置了一个非常早的值;
**write_mode**代表结果文件的保存类型,我想要把结果写入txt文件、csv文件和json文件,所以它的值为["csv", "txt", "json"],如果你想写入数据库,具体设置见[设置数据库](#4设置数据库可选);
**pic_download**值为1代表下载微博中的图片,值为0代表不下载;
**video_download**值为1代表下载微博中的视频,值为0代表不下载;
**cookie**是爬虫微博的cookie,具体如何获取cookie见[如何获取cookie](#如何获取cookie),获取cookie后把"your cookie"替换成真实的cookie值即可。
cookie修改完成后运行程序:
```bash
$ python weibospider.py
```
程序会自动生成一个weibo文件夹,我们以后爬取的所有微博都被存储在这里。然后程序在该文件夹下生成一个名为"Dear-迪丽热巴"的文件夹,迪丽热巴的所有微博爬取结果都在这里。"Dear-迪丽热巴"文件夹里包含一个csv文件、一个txt文件、一个json文件、一个img文件夹和一个video文件夹,img文件夹用来存储下载到的图片,video文件夹用来存储下载到的视频。如果你设置了保存数据库功能,这些信息也会保存在数据库里,数据库设置见[设置数据库](#4设置数据库可选)部分。
**csv结果文件如下所示:**
*1669879400.csv*
**txt结果文件如下所示:**
*1669879400.txt*
json文件包含迪丽热巴的用户信息和上千条微博信息,内容较多。为了表达清晰,这里仅展示两条微博。
**json结果文件如下所示:**
```
{
"user": {
"nickname": "Dear-迪丽热巴",
"weibo_num": 1086,
"following": 248,
"followers": 65594012,
"id": "1669879400"
},
"weibo": [
{
"id": "IonM9ryMy",
"content": "2019#微博之夜#盛典即将开启,以微博之力,让世界更美。1月11日,不见不散@微博之夜 原图 ",
"original_pictures": "http://wx1.sinaimg.cn/large/63885668ly1gao0a01kfzj20ku112k98.jpg",
"video_url": "无",
"publish_place": "无",
"publish_time": "2020-01-07 14:59",
"publish_tool": "无",
"up_num": 239242,
"retweet_num": 71914,
"comment_num": 55916
},
{
"id": "InB4Df73X",
"content": "#happyNEOyear#都到了2020,还不换点新pose配新装[來] 穿上@adidasneo 迪士尼联名款,让#生来好动#的我们一起玩“新”大发、自拍不重样🤳http://t.cn/AiF7nREj adidasneo的微博视频 ",
"original_pictures": "无",
"video_url": "http://f.video.weibocdn.com/000pYrGmlx07zPTskBQQ010412008AOY0E010.mp4?label=mp4_hd&template=852x480.25.0&trans_finger=62b30a3f061b162e421008955c73f536&Expires=1578569162&ssig=IV3JEbh3Zu&KID=unistore,video",
"publish_place": "无",
"publish_time": "2020-01-02 11:00",
"publish_tool": "无",
"up_num": 275419,
"retweet_num": 376734,
"comment_num": 131069
}
]
}
```
*1669879400.json*
**下载的图片如下所示:**
*img文件夹*
本次下载了793张图片,大小一共1.21GB,包括她原创微博中的图片和转发微博转发理由中的图片。图片名为yyyymmdd+微博id的形式,若某条微博存在多张图片,则图片名中还会包括它在微博图片中的序号。若某张图片因为网络等原因下载失败,程序则会以“weibo_id:pic_url”的形式将出错微博id和图片url写入同文件夹下的not_downloaded.txt里;
**下载的视频如下所示:**
*video文件夹*
本次下载了70个视频,是她原创微博中的视频,视频名为yyyymmdd+微博id的形式。其中有一个视频因为网络原因下载失败,程序将它的微博id和视频url以“weibo_id:video_url”的形式写到了同文件夹下的not_downloaded.txt里。
因为我本地没有安装MySQL数据库和MongoDB数据库,所以暂时设置成不写入数据库。如果你想要将爬取结果写入数据库,只需要先安装数据库(MySQL或MongoDB),再安装对应包(pymysql或pymongo),然后将mysql_write或mongodb_write值设置为1即可。写入MySQL需要用户名、密码等配置信息,这些配置如何设置见[设置数据库](#4设置数据库可选)部分。
## 运行环境
- 开发语言:python2/python3
- 系统: Windows/Linux/macOS
## 使用说明
### 0.版本
本程序有两个版本,**功能完成一样**。你现在看到的是单文件版,另一个是多文件版,[多文件版](https://github.com/dataabc/weiboSpider/tree/multi-file)位于multi-file分支。
二者的区别在于:
>单文件版是所有代码都写到一个文件里,即[weiboSpider.py](https://github.com/dataabc/weiboSpider/blob/master/weiboSpider.py)。多文件版重构了单文件版,按照代码功能分成了几个文件,代码更清晰,更易读。如果你仅仅想使用程序,这两个版本用哪一个都一样;如果你不仅想使用,还想开发新功能,多文件版可能更容易。
多文件版由[songzy12](https://github.com/songzy12)重构。songzy12非常认真负责,对于我发现的问题都很耐心地修复了,而且效率非常高,在此感谢。
本使用说明是单文件版的使用说明。
### 1.下载脚本
```bash
$ git clone https://github.com/dataabc/weibospider.git
```
运行上述命令,将本项目下载到当前目录,如果下载成功当前目录会出现一个名为"weibospider"的文件夹;
### 2.安装依赖
```bash
$ pip install -r requirements.txt
```
### 3.程序设置
打开**config.json**文件,你会看到如下内容:
```
{
"user_id_list": ["1669879400"],
"filter": 1,
"since_date": "2018-01-01",
"write_mode": ["csv", "txt"],
"pic_download": 1,
"video_download": 1,
"cookie": "your cookie",
"mysql_config": {
"host": "localhost",
"port": 3306,
"user": "root",
"password": "123456",
"charset": "utf8mb4"
}
}
```
下面讲解每个参数的含义与设置方法。
**设置user_id_list**
user_id_list是我们要爬取的微博的id,可以是一个,也可以是多个,例如:
```
"user_id_list": ["1223178222", "1669879400", "1729370543"],
```
上述代码代表我们要连续爬取user_id分别为“1223178222”、 “1669879400”、 “1729370543”的三个用户的微博,具体如何获取user_id见[如何获取user_id](#如何获取user_id)。
user_id_list的值也可以是文件路径,我们可以把要爬的所有微博用户的user_id都写到txt文件里,然后把文件的位置路径赋值给user_id_list。
在txt文件中,每个user_id占一行,也可以在user_id后面加注释(可选),如用户昵称等信息,user_id和注释之间必需要有空格,文件名任意,类型为txt,位置位于本程序的同目录下,文件内容示例如下:
```
1223178222 胡歌
1669879400 迪丽热巴
1729370543 郭碧婷
```
假如文件叫user_id_list.txt,则user_id_list设置代码为:
```
"user_id_list": "user_id_list.txt",
```
**设置filter**
filter控制爬取范围,值为1代表爬取全部原创微博,值为0代表爬取全部微博(原创+转发)。例如,如果要爬全部原创微博,请使用如下代码:
```
"filter": 1,
```
**设置since_date**
since_date值可以是日期,也可以是整数。如果是日期,代表爬取该日期之后的微博,格式应为“yyyy-mm-dd”,如:
```
"since_date": "2018-01-01",
```
代表爬取从2018年1月1日到现在的微博。
如果是整数,代表爬取最近n天的微博,如:
```
"since_date": 10,
```
代表爬取最近10天的微博,这个说法不是特别准确,准确说是爬取发布时间从**10天前到本程序开始执行时**之间的微博。
**since_date是所有user的爬取起始时间,非常不灵活。如果你要爬多个用户,并且想单独为每个用户设置一个since_date,可以使用[定期自动爬取微博](#7定期自动爬取微博可选)方法二中的方法,该方法可以为多个用户设置不同的since_date,非常灵活。**
**设置write_mode**
write_mode控制结果文件格式,取值范围是csv、txt、json、mongo和mysql,分别代表将结果文件写入csv、txt、json、MongoDB和MySQL数据库。write_mode可以同时包含这些取值中的一个或几个,如:
```
"write_mode": ["csv", "txt"],
```
代表将结果信息写入csv文件和txt文件。特别注意,如果你想写入数据库,除了在write_mode添加对应数据库的名字外,还应该安装相关数据库和对应python模块,具体操作见[设置数据库](#4设置数据库可选)部分。
**设置pic_download**
pic_download控制是否下载微博中的图片,值为1代表下载,值为0代表不下载,如
```
"pic_download": 1,
```
代表下载微博中的图片。
**设置video_download**
video_download控制是否下载微博中的视频,值为1代表下载,值为0代表不下载,如
```
"video_download": 1,
```
代表下载微博中的视频。
**设置cookie**
请按照[如何获取cookie](#如何获取cookie),获取cookie,然后将“your cookie”替换成真实的cookie值。
**设置mysql_config(可选)**
mysql_config控制mysql参数配置。如果你不需要将结果信息写入mysql,这个参数可以忽略,即删除或保留都无所谓;如果你需要写入mysql且config.json文件中mysql_config的配置与你的mysql配置不一样,请将该值改成你自己mysql中的参数配置。
### 4.设置数据库(可选)
本部分是可选部分,如果不需要将爬取信息写入数据库,可跳过这一步。本程序目前支持MySQL数据库和MongoDB数据库,如果你需要写入其它数据库,可以参考这两个数据库的写法自己编写。
**MySQL数据库写入**
要想将爬取信息写入MySQL,请根据自己的系统环境安装MySQL,然后命令行执行:
```bash
$ pip install pymysql
```
**MongoDB数据库写入**
要想将爬取信息写入MongoDB,请根据自己的系统环境安装MongoDB,然后命令行执行:
```bash
$ pip install pymongo
```
MySQL和MongDB数据库的写入内容一样。程序首先会创建一个名为"weibo"的数据库,然后再创建"user"表和"weibo"表,包含爬取的所有内容。爬取到的微博**用户信息**或插入或更新,都会存储到user表里;爬取到的**微博信息**或插入或更新,都会存储到weibo表里,两个表通过user_id关联。如果想了解两个表的具体字段,请点击"详情"。
详情
**user表**
**id**:存储用户id,如"1669879400";
**nickname**:存储用户昵称,如"Dear-迪丽热巴";
**weibo_num**:存储微博数;
**following**:存储关注数;
**followers**:存储粉丝数。
***
**weibo表**
**id**:存储微博id;
**user_id**:存储微博发布者的用户id,如"1669879400";
**content**:存储微博正文;
**original_pictures**:存储原创微博的原始图片url和转发微博转发理由中的图片url。若某条微博有多张图片,则存储多个url,以英文逗号分割;若某微博没有图片,则值为"无";
**retweet_pictures**:存储被转发微博中的原始图片url。当最新微博为原创微博或者为没有图片的转发微博时,则值为"无",否则为被转发微博的图片url。若有多张图片,则存储多个url,以英文逗号分割;
**publish_place**:存储微博的发布位置。如果某条微博没有位置信息,则值为"无";
**publish_time**:存储微博的发布时间;
**up_num**:存储微博获得的点赞数;
**retweet_num**:存储微博获得的转发数;
**comment_num**:存储微博获得的评论数;
**publish_tool**:存储微博的发布工具。
### 5.运行脚本
大家可以根据自己的运行环境选择运行方式,Linux可以通过
```bash
$ python weibospider.py
```
运行;
### 6.按需求修改脚本(可选)
本部分为可选部分,如果你不需要自己修改代码或添加新功能,可以忽略此部分。
本程序所有代码都位于weiboSpider.py文件,程序主体是一个Weibo类,上述所有功能都是通过在main函数调用Weibo类实现的,默认的调用代码如下:
```python
config_path = os.path.split(
os.path.realpath(__file__))[0] + os.sep + 'config.json'
if not os.path.isfile(config_path):
sys.exit(u'当前路径:%s 不存在配置文件config.json' %
(os.path.split(os.path.realpath(__file__))[0] + os.sep))
with open(config_path) as f:
config = json.loads(f.read())
wb = Weibo(config)
wb.start() # 爬取微博信息
```
用户可以按照自己的需求调用或修改Weibo类。
通过执行本程序,我们可以得到很多信息:
**wb.nickname**:用户昵称;
**wb.weibo_num**:微博数;
**wb.following**:关注数;
**wb.followers**:粉丝数;
**wb.weibo**:除不包含上述信息外,wb.weibo包含爬取到的所有微博信息,如**微博id**、**微博正文**、**原始图片url**、**发布位置**、**发布时间**、**发布工具**、**点赞数**、**转发数**、**评论数**等。如果爬的是全部微博(原创+转发),除上述信息之外,还包含被**转发微博原始图片url**、**是否为原创微博**等。wb.weibo是一个列表,包含了爬取的所有微博信息。wb.weibo[0]为爬取的第一条微博,wb.weibo[1]为爬取的第二条微博,以此类推。当filter=1时,wb.weibo[0]为爬取的第一条**原创**微博,以此类推。wb.weibo[0]['id']为第一条微博的id,wb.weibo[0]['content']为第一条微博的正文,wb.weibo[0]['publish_time']为第一条微博的发布时间,还有其它很多信息不在赘述,大家可以点击下面的"详情"查看具体用法。
详情
若目标微博用户存在微博,则:
**id**:存储微博id。如wb.weibo[0]['id']为最新一条微博的id;
**content**:存储微博正文。如wb.weibo[0]['content']为最新一条微博的正文;
**original_pictures**:存储原创微博的原始图片url和转发微博转发理由中的图片url。如wb.weibo[0]['original_pictures']为最新一条微博的原始图片url,若该条微博有多张图片,则存储多个url,以英文逗号分割;若该微博没有图片,则值为"无";
**retweet_pictures**:存储被转发微博中的原始图片url。当最新微博为原创微博或者为没有图片的转发微博时,则值为"无",否则为被转发微博的图片url。若有多张图片,则存储多个url,以英文逗号分割;
**publish_place**:存储微博的发布位置。如wb.weibo[0]['publish_place']为最新一条微博的发布位置,如果该条微博没有位置信息,则值为"无";
**publish_time**:存储微博的发布时间。如wb.weibo[0]['publish_time']为最新一条微博的发布时间;
**up_num**:存储微博获得的点赞数。如wb.weibo[0]['up_num']为最新一条微博获得的点赞数;
**retweet_num**:存储微博获得的转发数。如wb.weibo[0]['retweet_num']为最新一条微博获得的转发数;
**comment_num**:存储微博获得的评论数。如wb.weibo[0]['comment_num']为最新一条微博获得的评论数;
**publish_tool**:存储微博的发布工具。如wb.weibo[0]['publish_tool']为最新一条微博的发布工具。
### 7.定期自动爬取微博(可选)
我们爬取了微博以后,很多微博账号又可能发了一些新微博,定期自动爬取微博就是每隔一段时间自动运行程序,自动爬取这段时间产生的新微博(忽略以前爬过的旧微博)。本部分为可选部分,如果不需要可以忽略。
思路是**利用第三方软件,如crontab,让程序每隔一段时间运行一次**。因为是要跳过以前爬过的旧微博,只爬新微博。所以需要**设置一个动态的since_date**。很多时候我们使用的since_date是固定的,比如since_date="2018-01-01",程序就会按照这个设置从最新的微博一直爬到发布时间为2018-01-01的微博(包括这个时间)。因为我们想追加新微博,跳过旧微博。第二次爬取时since_date值就应该是当前时间到上次爬取的时间。
如果我们使用最原始的方式实现追加爬取,应该是这样:
```
假如程序第一次执行时间是2019-06-06,since_date假如为2018-01-01,那这一次就是爬取从2018-01-01到2019-06-06这段时间用户所发的微博;
第二次爬取,我们想要接着上次的爬,那since_date的值应该是上次程序执行的日期,即2019-06-06
```
上面的方法太麻烦,因为每次都要手动设置since_date。因此我们需要动态设置since_date,即程序根据实际情况,自动生成since_date。
有两种方法实现动态更新since_date:
**方法一:将since_date设置成整数**
将config.json文件中的since_date设置成整数,如:
```
"since_date": 10,
```
这个配置告诉程序爬取最近10天的微博,更准确说是爬取发布时间从**10天前到本程序开始执行时**之间的微博。这样since_date就是一个动态的变量,每次程序执行时,它的值就是当前日期减10。配合crontab每9天或10天执行一次,就实现了定期追加爬取。
**方法二:将上次执行程序的时间写入文件(推荐)**
这个方法很简单,就是用户把要爬的用户id写入txt文件,然后再把文件路径赋值给config.json中的user_id_list参数。
txt文件名格式可以参考[程序设置](#3程序设置)中的**设置user_id_list**,这样设置就全部结束了。
说下这个方法的好处和原理,假如你的txt文件内容为:
```
1669879400
1223178222 胡歌
1729370543 郭碧婷 2019-01-01 19:28
```
第一次执行时,因为第一行和第二行都没有写时间,程序会按照config.json文件中since_date的值爬取,第三行有时间“2019-01-01 19:28”,程序就会把这个时间当作since_date。每个用户爬取结束程序都会自动更新txt文件,每一行第一部分是user_id,第二部分是用户昵称,第三部分是程序**准备**爬取该用户第一条微博(最新微博)时的时间。爬完三个用户后,txt文件的内容自动更新为:
```
1669879400 Dear-迪丽热巴 2020-01-13 19:18
1223178222 胡歌 2020-01-13 19:28
1729370543 郭碧婷 2020-01-13 19:33
```
下次再爬取微博的时候,程序会把每行的时间数据作为since_date。这样的好处一是不用修改since_date,程序自动更新;二是每一个用户都可以单独拥有只属于自己的since_date,每个用户的since_date相互独立,互不干扰。since_date既可以是“yyyy-mm-dd”格式,也可以是“yyyy-mm-dd hh:mm”格式。比如,现在又添加了一个新用户,例如杨紫,你想获取她从2018-01-23到现在的全部微博,只需要这样修改txt文件:
```
1669879400 Dear-迪丽热巴 2020-01-13 19:18
1223178222 胡歌 2020-01-13 19:28
1729370543 郭碧婷 2020-01-13 19:33
1227368500 杨紫 2018-01-23
```
注意每一行的用户配置参数以空格分隔,如果第一个参数全部由数字组成,程序就认为此行为一个用户的配置,否则程序会认为该行只是注释,跳过该行;第二个参数可以为任意格式,建议写用户昵称;第三个如果是日期格式(yyyy-mm-dd),程序就将该日期设置为用户自己的since_date,否则使用config.json中的since_date爬取该用户的微博,第二个参数和第三个参数也可以不填。
推荐第二种方法,本方法是[Evifly](https://github.com/Evifly)想出的,非常热心非常有想法的网友,在此感谢。
## 如何获取cookie
1.用Chrome打开;
2.输入微博的用户名、密码,登录,如图所示:
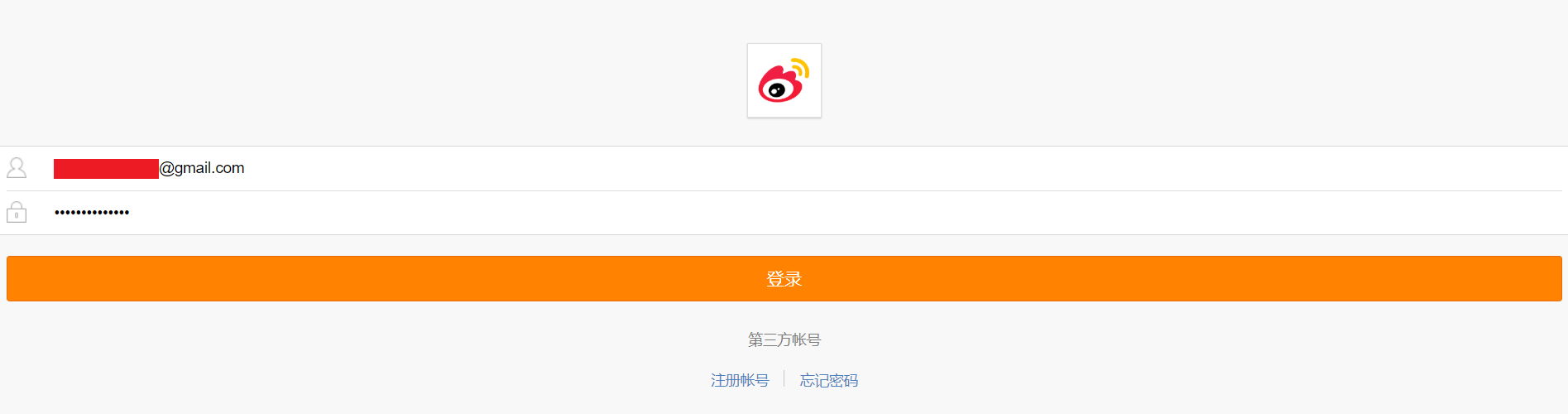
登录成功后会跳转到;
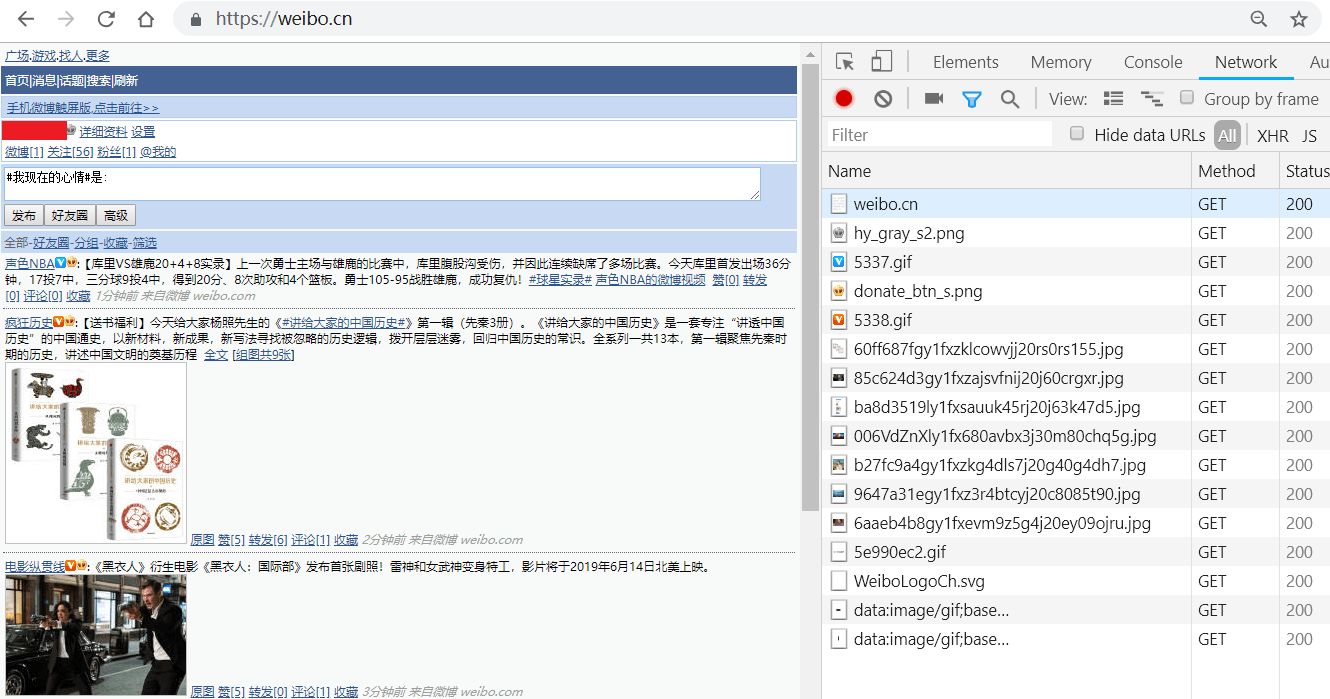
3.按F12键打开Chrome开发者工具,在地址栏输入并跳转到,跳转后会显示如下类似界面:
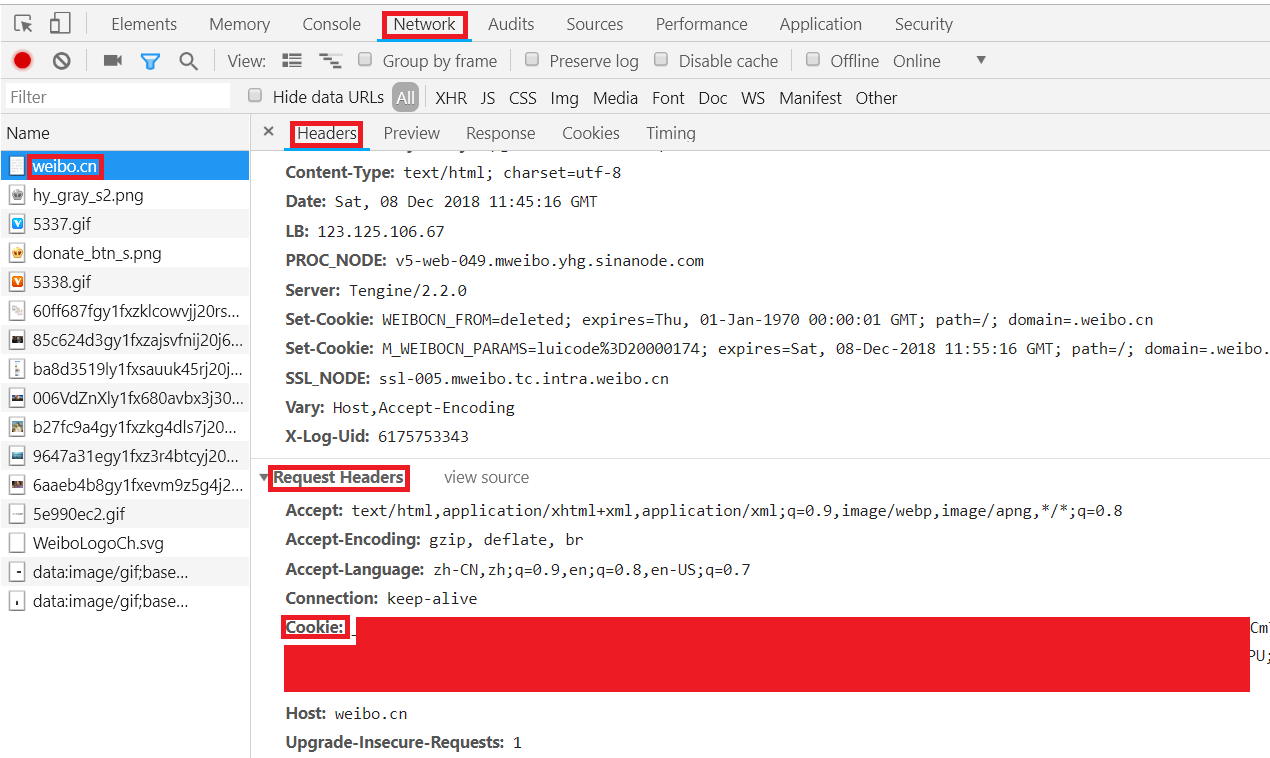
4.依此点击Chrome开发者工具中的Network->Name中的weibo.cn->Headers->Request Headers,"Cookie:"后的值即为我们要找的cookie值,复制即可,如图所示:
## 如何获取user_id
1.打开网址,搜索我们要找的人,如"迪丽热巴",进入她的主页;
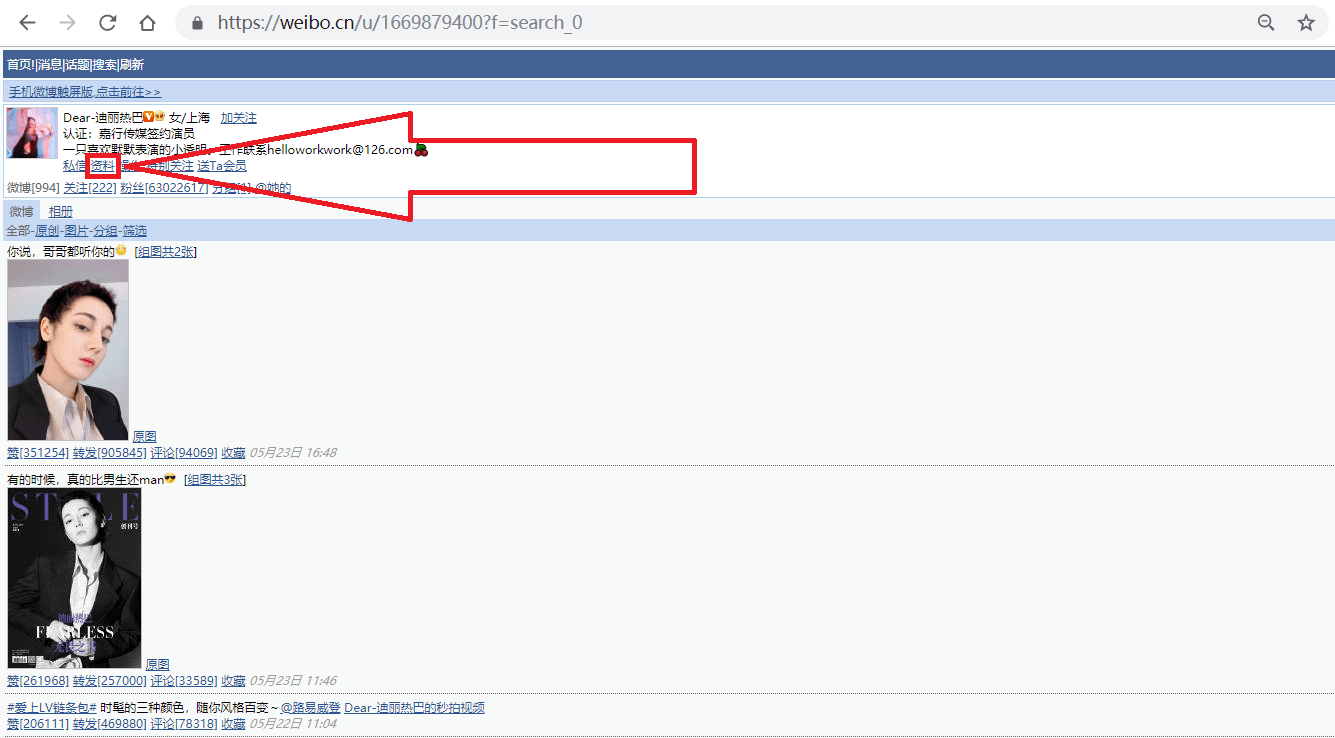
2.按照上图箭头所指,点击"资料"链接,跳转到用户资料页面;
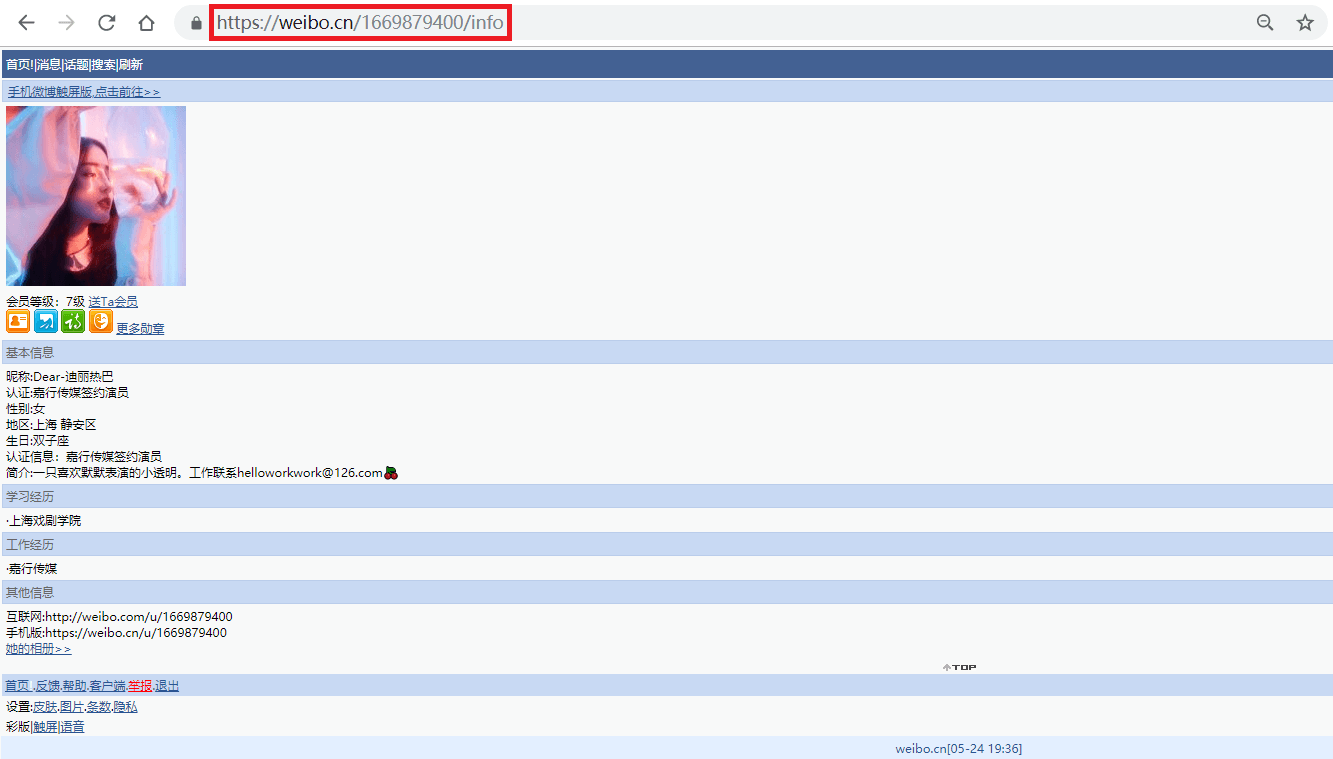
如上图所示,迪丽热巴微博资料页的地址为"",其中的"1669879400"即为此微博的user_id。
事实上,此微博的user_id也包含在用户主页()中,之所以我们还要点击主页中的"资料"来获取user_id,是因为很多用户的主页不是""的形式,而是""或""的形式。其中"微号"和user_id都是一串数字,如果仅仅通过主页地址提取user_id,很容易将"微号"误认为user_id。
## 注意事项
1.user_id不能为爬虫微博的user_id。因为要爬微博信息,必须先登录到某个微博账号,此账号我们姑且称为爬虫微博。爬虫微博访问自己的页面和访问其他用户的页面,得到的网页格式不同,所以无法爬取自己的微博信息;如果想要爬取爬虫微博内容,可以参考[获取自身微博信息](https://github.com/dataabc/weiboSpider/issues/113)。
2.cookie有期限限制,超过有效期需重新更新cookie。