diff --git a/week_05/05/18-Thread.md b/week_05/05/18-Thread.md
new file mode 100644
index 0000000000000000000000000000000000000000..aa828e5b86edba56ed6d766134d5a712f7ee23d1
--- /dev/null
+++ b/week_05/05/18-Thread.md
@@ -0,0 +1,186 @@
+# 线程的实现与分析
+
+## TOP 带着问题来分析
+
+1. Java 的线程模型
+2. Java 的线程状态
+3. Java线程的 join 实现原理
+
+## 1. 线程模型
+
+线程是操作系统调度的最小单位,实现线程有三种方式,而 Java Thread 采用的是 **内核线程实现**
+
+### 1.1 用户层实现(N:1)
+
+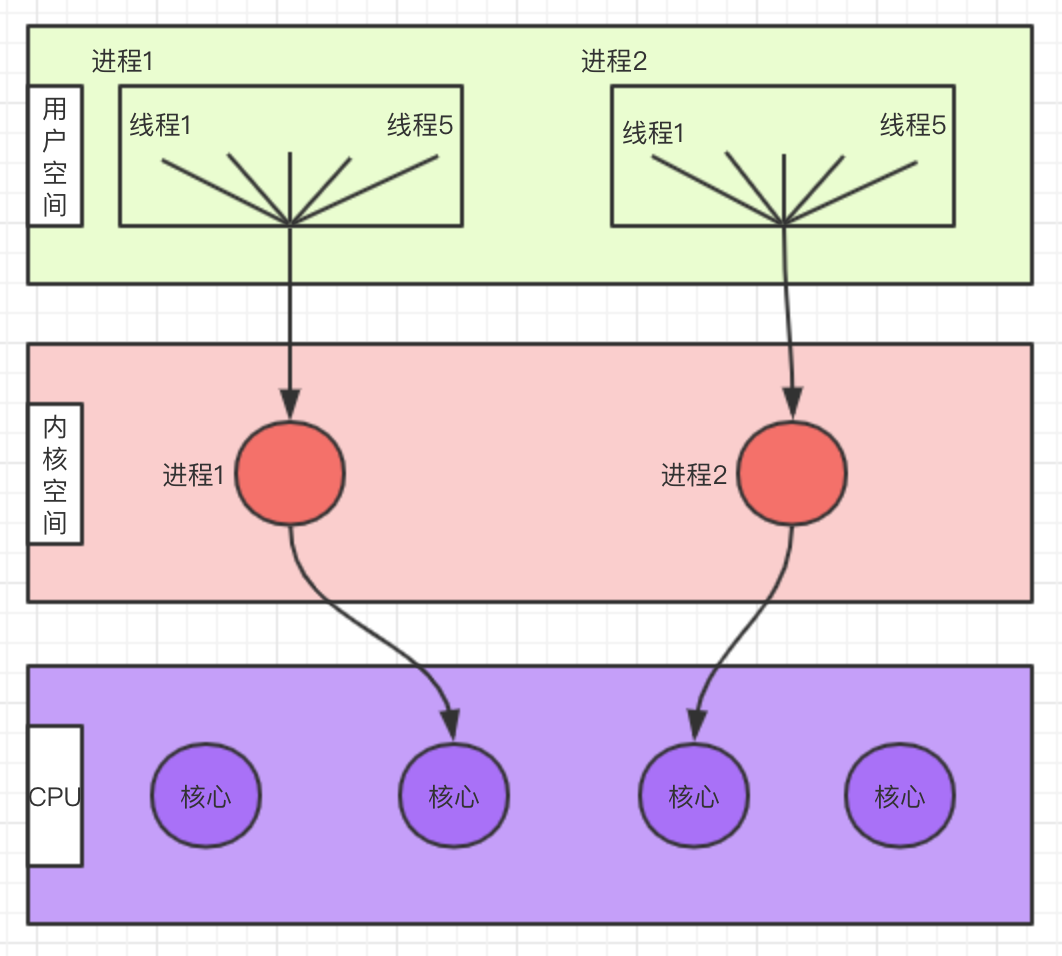 +
+#### 优点:
+
+- 用户线程切换不需要内核介入,切换很快、代价相对低
+- 用户线程操作成本低
+
+#### 缺点:
+
+- 用户线程自己进行管理,比较麻烦
+- 阻塞处理复杂
+- 如何将线程映射到其他处理器
+
+### 1.2 内核线程实现(1:1)
+
+每一个用户线程对应一个内核线程,内核去完成线程的创建和调度。
+
+
+
+#### 优点:
+
+- 用户线程切换不需要内核介入,切换很快、代价相对低
+- 用户线程操作成本低
+
+#### 缺点:
+
+- 用户线程自己进行管理,比较麻烦
+- 阻塞处理复杂
+- 如何将线程映射到其他处理器
+
+### 1.2 内核线程实现(1:1)
+
+每一个用户线程对应一个内核线程,内核去完成线程的创建和调度。
+
+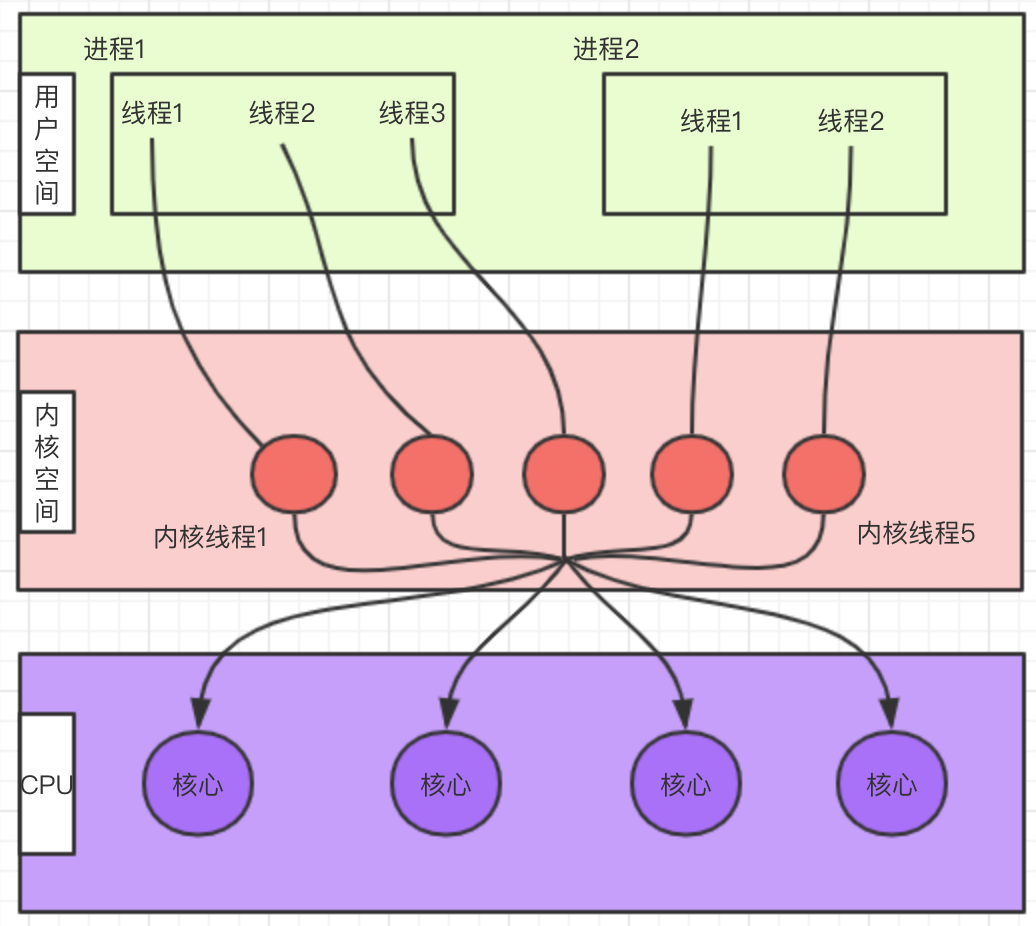 +
+#### 优点:
+
+- 阻塞处理比较简单
+- 充分利用硬件
+
+#### 缺点:
+
+- 用户线程操作涉及到内核调用,代价较高
+
+> 通过跟踪 Java Thread 中 start() 方法:
+>
+> start() -> native start0() -> JVM_StartThread() -> JavaThread() -> os::create_thread() -> pthread_create()
+>
+> 可以发现在 Java 中每次调用 start() 方法,都会在 C++ 的 JavaThread 构造方法里通过 pthread 进行创建一个内核线程。
+>
+> 回到问题 **TOP 1** ,也就是说 **Java 采用的线程模型是 1:1**
+
+### 1.3 混合实现(M:N)
+
+
+
+#### 优点:
+
+- 阻塞处理比较简单
+- 充分利用硬件
+
+#### 缺点:
+
+- 用户线程操作涉及到内核调用,代价较高
+
+> 通过跟踪 Java Thread 中 start() 方法:
+>
+> start() -> native start0() -> JVM_StartThread() -> JavaThread() -> os::create_thread() -> pthread_create()
+>
+> 可以发现在 Java 中每次调用 start() 方法,都会在 C++ 的 JavaThread 构造方法里通过 pthread 进行创建一个内核线程。
+>
+> 回到问题 **TOP 1** ,也就是说 **Java 采用的线程模型是 1:1**
+
+### 1.3 混合实现(M:N)
+
+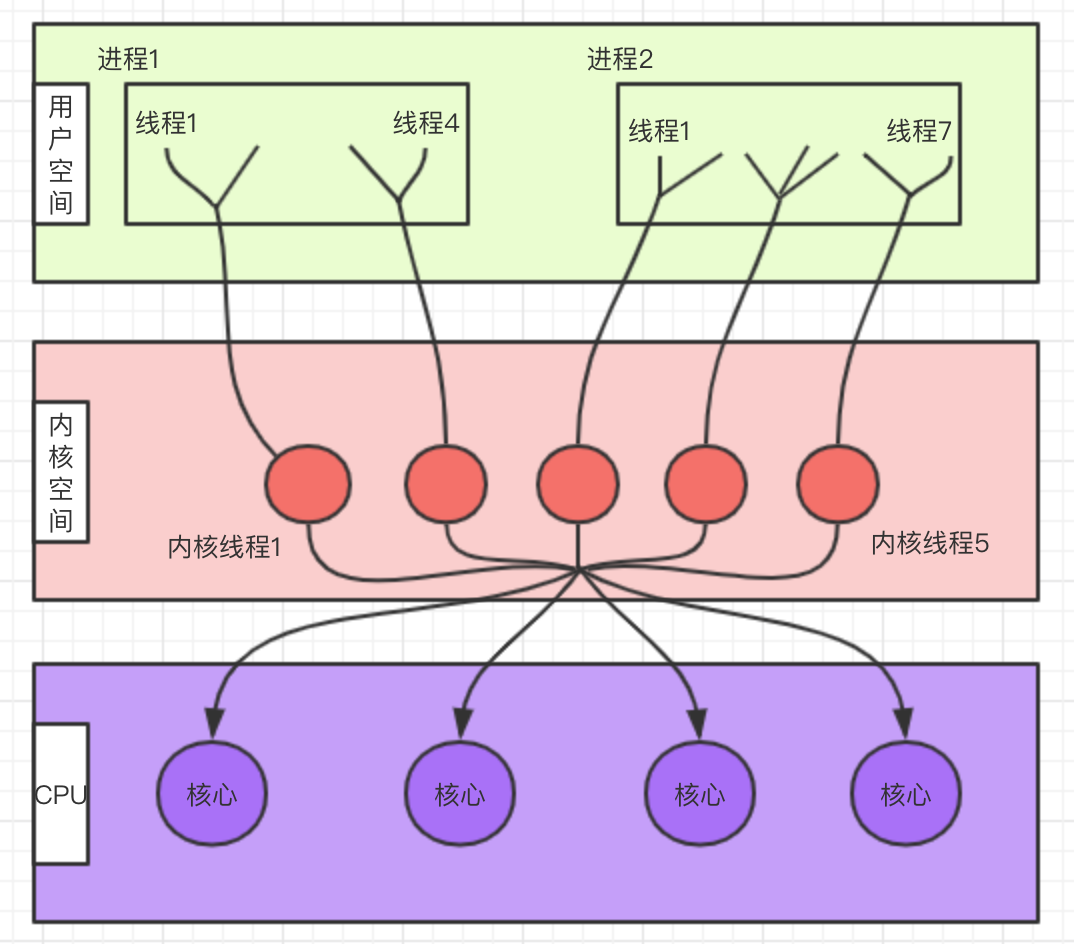 +
+#### 优点:
+
+- 用户线程的操作成本低
+- 充分利用硬件
+- 阻塞问题折中处理
+
+#### 缺点:
+
+- 需要用户层管理和映射
+
+## 2. 线程状态分析
+
+在状态枚举类 *java.lang.Thread.State* 中我们看到了一共有 6 种状态
+
+- **NEW**
+
+ 新建状态,线程还没调用 start() 方法
+
+- **RUNNABLE**
+
+ 可运行状态,调用 start() 方法后,正在运行或等待系统资源
+
+- **BLOCKED**
+
+ 阻塞状态,等待锁、Object#wait()-notify() 后都会进入阻塞状态
+
+- **WAITING**
+
+ 等待状态,调用 Object#wait()、join()、LockSupport#park() ,注意这里都是没有超时时间
+
+- **TIMED_WAITING**
+
+ 超时等待状态,调用 Thread#sleep()、Object#wait(long)、join(long)、LockSupport#parkNanos、LockSupport#parkUntil,可以发现这里都是有超时时间
+
+- **TERMINATED**
+
+ 终止状态,线程已经执行完毕
+
+### 2.1 线程状态流程图
+
+
+
+#### 优点:
+
+- 用户线程的操作成本低
+- 充分利用硬件
+- 阻塞问题折中处理
+
+#### 缺点:
+
+- 需要用户层管理和映射
+
+## 2. 线程状态分析
+
+在状态枚举类 *java.lang.Thread.State* 中我们看到了一共有 6 种状态
+
+- **NEW**
+
+ 新建状态,线程还没调用 start() 方法
+
+- **RUNNABLE**
+
+ 可运行状态,调用 start() 方法后,正在运行或等待系统资源
+
+- **BLOCKED**
+
+ 阻塞状态,等待锁、Object#wait()-notify() 后都会进入阻塞状态
+
+- **WAITING**
+
+ 等待状态,调用 Object#wait()、join()、LockSupport#park() ,注意这里都是没有超时时间
+
+- **TIMED_WAITING**
+
+ 超时等待状态,调用 Thread#sleep()、Object#wait(long)、join(long)、LockSupport#parkNanos、LockSupport#parkUntil,可以发现这里都是有超时时间
+
+- **TERMINATED**
+
+ 终止状态,线程已经执行完毕
+
+### 2.1 线程状态流程图
+
+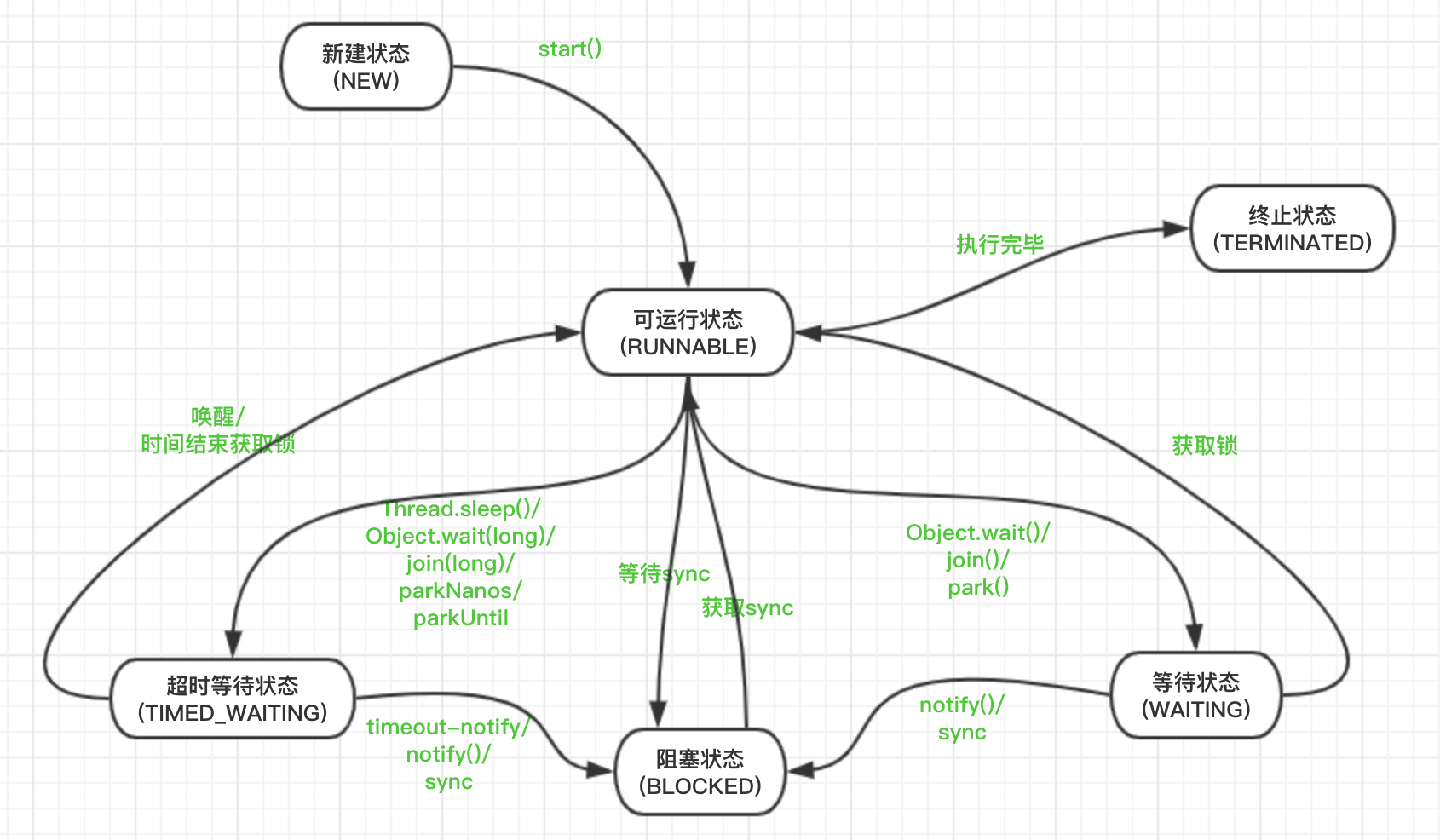 +
+回到问题 **TOP 2** ,相信看完这个流程图会对状态流转更清晰一些
+
+## 3. 核心方法分析
+
+### 3.1 join()
+
+例如我们 主线程A 要等待 子线程B 完成再往下执行,可以调用 子线程B 的join() 方法
+
+回到问题 **TOP 3** ,其实就是通过 wait 方法来让主线程等待,最后子线程完成后会唤醒主线程来实现了一个线程之间的通信。
+
+```java
+public final void join() throws InterruptedException {
+ join(0);
+}
+
+public final synchronized void join(long millis)
+throws InterruptedException {
+ // 获取当前时间
+ long base = System.currentTimeMillis();
+ long now = 0;
+ // 入参校验
+ if (millis < 0) {
+ throw new IllegalArgumentException("timeout value is negative");
+ }
+ // 默认 join()参数走这个分支
+ if (millis == 0) {
+ // 只要线程还未完成
+ while (isAlive()) {
+ // 0 是一直等待下去
+ wait(0);
+ }
+ } else {
+ while (isAlive()) {
+ // 还剩下多少时间
+ long delay = millis - now;
+ // 时间到了就跳出
+ if (delay <= 0) {
+ break;
+ }
+ // 调用wait方法等待
+ wait(delay);
+ // 当前已经过了多久
+ now = System.currentTimeMillis() - base;
+ }
+ }
+}
+```
+
+### 3.2 interrupt()
+
+我们知道 stop() 方法由于太暴力和不安全已经设置为过期,现在基本上是采用 interrupt() 来交给我们优雅的处理。为什么这样说呢?
+
+我们看下面 interrupt() 的实现可以看到实际上只是设置了一个中断标识(通知线程应该中断了),并不会真正停止一个线程。
+
+```java
+public void interrupt() {
+ if (this != Thread.currentThread())
+ checkAccess();
+
+ synchronized (blockerLock) {
+ Interruptible b = blocker;
+ if (b != null) {
+ interrupt0(); // Just to set the interrupt flag
+ b.interrupt(this);
+ return;
+ }
+ }
+ interrupt0();
+}
+```
+
+但是我们可以通过这个中断的通知来自己处理是继续运行还是中断,例如我们想要中断后停止线程:
+
+```java
+Thread thread = new Thread(() -> {
+ while (!Thread.interrupted()) {
+ // do more work.
+ }
+});
+thread.start();
+
+// 一段时间以后
+thread.interrupt();
+```
+
+> 需要注意的是,在一些可中断阻塞函数中,会抛出 InterruptedException,需要注意的是如果你不想处理继续往上抛,需要再次调用 interrupt() 方法(因为中断状态已经被重置了)。
+
+## 4. 总结
+
+我们这篇文章主要是分析了线程模型和线程的状态,已经几个核心方法的实现,相信看完会对线程有了更深一层的认识。
diff --git a/week_05/05/19-ThreadLocal.md b/week_05/05/19-ThreadLocal.md
new file mode 100644
index 0000000000000000000000000000000000000000..08ae9fb858ac5bcb56a04658833c5b20489ff3cb
--- /dev/null
+++ b/week_05/05/19-ThreadLocal.md
@@ -0,0 +1,272 @@
+# ThreadLocal 源码分析
+
+## TOP 带着问题看源码
+
+1. ThreadLocal 是怎么保证不同线程内部的变量隔离的
+2. 你说了ThreadLocalMap,那它是如何解决Hash冲突的
+3. ThreadLocal 什么情况下会内存泄漏
+
+## 1. 基本介绍
+
+我们知道解决共享变量不安全的一种方式,就是利用每个线程的私有变量来操作,避免共享变量导致的线程不安全问题。
+
+ThreadLocal 就是提供一个局部变量,不会遇到并发问题。
+
+## 2. 成员变量 & 核心类分析
+
+```java
+// 计算hash值
+private final int threadLocalHashCode = nextHashCode();
+// 使用原子类记录hash值
+private static AtomicInteger nextHashCode =
+ new AtomicInteger();
+// 魔数,更好的分散数据
+private static final int HASH_INCREMENT = 0x61c88647;
+
+// Thread.class
+// 每个线程类都会有一个 ThreadLocalMap
+ThreadLocal.ThreadLocalMap threadLocals = null;
+
+// java.lang.ThreadLocal.ThreadLocalMap
+// 初始化容量
+private static final int INITIAL_CAPACITY = 16;
+// 存储数据数组
+private Entry[] table;
+// 元素个数
+private int size = 0;
+// 扩容的阈值
+private int threshold;
+// 构造方法,初始化值
+ThreadLocalMap(ThreadLocal firstKey, Object firstValue) {
+ table = new Entry[INITIAL_CAPACITY];
+ int i = firstKey.threadLocalHashCode & (INITIAL_CAPACITY - 1);
+ table[i] = new Entry(firstKey, firstValue);
+ size = 1;
+ setThreshold(INITIAL_CAPACITY);
+}
+```
+
+回到问题 **TOP 1** ,可以知道是不同线程都有自己的 ThreadLocalMap ,也就天然做到了隔离
+
+### 2.1 ThreadLocal 内存泄漏的原因
+
+通过对变量和核心类的分析,相信对 ThreadLocal 的一个结构有了大致的了解,接下来我们先来看下 ThreadLocal 的 map 是怎么定义的。
+
+```java
+static class Entry extends WeakReference> {
+ Object value;
+ // 注意,这里 k 作为弱引用
+ // 原因是如果是强引用,我们如果把 threadlocal 置为 null 不再使用,但是其在线程中的 threadlocalmap还在,导致无法gc
+ Entry(ThreadLocal k, Object v) {
+ super(k);
+ value = v;
+ }
+}
+```
+
+回到问题 **TOP 3** ,由此可以分析,在 gc 的情况下,k 会出现为 null,也就会出现 value 还在但是无法拿到的情况(内存泄漏)。
+
+实际上在 ThreadLocal 中这个问题并不是想象的那么可怕,其核心方法基本都会对这种无效的数据进行清理。
+
+## 3. 核心方法分析
+
+### 3.1 set 数据
+
+核心逻辑就是:
+
+1. 把数据放到当前线程的 ThreadLocalMap 的 value
+2. 如果当前 key 的位置已经有了就覆盖
+3. 如果当前位置的元素与当前 key 不相等,就插入下一个可以放置元素的地方
+
+```java
+public void set(T value) {
+ // 获取当前线程
+ Thread t = Thread.currentThread();
+ // 获取当前线程的 ThreadLocalMap
+ ThreadLocalMap map = getMap(t);
+ if (map != null)
+ // 这里this是指的调用这个方法的threadlocal对象
+ // 调用 set 方法
+ map.set(this, value);
+ else
+ // 还没有就创建一个map
+ createMap(t, value);
+}
+
+private void set(ThreadLocal key, Object value) {
+ Entry[] tab = table;
+ int len = tab.length;
+ // 根据 hash 计算位置
+ int i = key.threadLocalHashCode & (len-1);
+ // 循环,如果第一次没有获取到 key 相同的,就循环下一个位置
+ for (Entry e = tab[i];
+ e != null;
+ e = tab[i = nextIndex(i, len)]) {
+ // 获取 key
+ ThreadLocal k = e.get();
+ // key 相同,直接覆盖
+ if (k == key) {
+ e.value = value;
+ return;
+ }
+ // key 为空就调用 replaceStaleEntry,见下文
+ if (k == null) {
+ replaceStaleEntry(key, value, i);
+ return;
+ }
+ }
+ // 走到这里说明目标位置是空的,构建元素放到存储数组中
+ tab[i] = new Entry(key, value);
+ // 增加元素个数
+ int sz = ++size;
+ // 如果不再有无用元素,并且容量超过了阈值,就扩容
+ if (!cleanSomeSlots(i, sz) && sz >= threshold)
+ rehash();
+}
+```
+
+回到问题 **TOP 2** ,可以知道其处理 hash 冲突采用的是开放寻址法,位置已被占就会找下一个。在数据量较少的场景,这个是很合适的。
+
+### 3.2 get 数据
+
+核心逻辑就是:
+
+1. 把当前线程的 ThreadLocalMap 的 value 取出来
+2. 如果按照 hash 查找到的 key 不一样,说明出现 hash 冲突了,调用 `getEntryAfterMiss()`
+
+```java
+public T get() {
+ // 获取当前线程
+ Thread t = Thread.currentThread();
+ // 获取当前线程的 ThreadLocalMap
+ ThreadLocalMap map = getMap(t);
+ if (map != null) {
+ // 调用 getEntry 根据 key 查找到 value
+ ThreadLocalMap.Entry e = map.getEntry(this);
+ if (e != null) {
+ @SuppressWarnings("unchecked")
+ T result = (T)e.value;
+ return result;
+ }
+ }
+ return setInitialValue();
+}
+
+private Entry getEntry(ThreadLocal key) {
+ // 根据hash值确定位置,获取元素
+ int i = key.threadLocalHashCode & (table.length - 1);
+ Entry e = table[i];
+ if (e != null && e.get() == key)
+ return e;
+ else
+ // 如果 key 不相同或者值为null,调用 getEntryAfterMiss
+ return getEntryAfterMiss(key, i, e);
+}
+```
+
+### 3.3 辅助方法
+
+#### 3.3.1 getEntryAfterMiss
+
+该方法主要是用来处理 hash 冲突的
+
+```java
+private Entry getEntryAfterMiss(ThreadLocal key, int i, Entry e) {
+ Entry[] tab = table;
+ int len = tab.length;
+ // 死循环
+ while (e != null) {
+ ThreadLocal k = e.get();
+ // 当 key 也相同时候就返回
+ if (k == key)
+ return e;
+ // 如果 key 为 null 调用 expungeStaleEntry
+ if (k == null)
+ expungeStaleEntry(i);
+ else
+ // 获取下一个位置
+ i = nextIndex(i, len);
+ // 获取新的位置元素
+ e = tab[i];
+ }
+ return null;
+}
+```
+
+#### 3.3.2 expungeStaleEntry
+
+核心逻辑就是:
+
+1. 清理无效的 entity
+2. 往后继续搜索和清理,直到 tab[i] == null 退出
+
+```java
+private int expungeStaleEntry(int staleSlot) {
+ Entry[] tab = table;
+ int len = tab.length;
+
+ // 删除无效元素
+ tab[staleSlot].value = null;
+ tab[staleSlot] = null;
+ size--;
+
+ // Rehash until we encounter null
+ Entry e;
+ int i;
+ // 循环,直到 tab[i] == null 退出
+ for (i = nextIndex(staleSlot, len);
+ (e = tab[i]) != null;
+ i = nextIndex(i, len)) {
+ ThreadLocal k = e.get();
+ // 如果再次发现 key 为 null 的都删掉
+ if (k == null) {
+ e.value = null;
+ tab[i] = null;
+ size--;
+ } else {
+ // 处理 rehash 情况
+ int h = k.threadLocalHashCode & (len - 1);
+ if (h != i) {
+ tab[i] = null;
+
+ // Unlike Knuth 6.4 Algorithm R, we must scan until
+ // null because multiple entries could have been stale.
+ while (tab[h] != null)
+ h = nextIndex(h, len);
+ tab[h] = e;
+ }
+ }
+ }
+ return i;
+}
+```
+
+#### 3.3.3 cleanSomeSlots
+
+```java
+private boolean cleanSomeSlots(int i, int n) {
+ boolean removed = false;
+ Entry[] tab = table;
+ int len = tab.length;
+ do {
+ // 获取下一个索引值
+ i = nextIndex(i, len);
+ Entry e = tab[i];
+ // 如果这个索引对应的 value 不为空 并且 key 是空的
+ if (e != null && e.get() == null) {
+ // 重置n为哈希表大小
+ n = len;
+ removed = true;
+ // 清理无效的 entity
+ // expungeStaleEntry我们前面也分析了,会往后找到所有无效的 entity
+ i = expungeStaleEntry(i);
+ }
+ // 每次搜索范围减少一半
+ } while ( (n >>>= 1) != 0);
+ return removed;
+}
+```
+
+## 4. 总结
+
+可以看到,ThreadLocal 在完成基本功能之外,做了很多辅助操作来避免内存泄漏,这种严谨的做法也值得我们在工作中来做。
\ No newline at end of file
diff --git a/week_05/05/20-ThreadPoolExecutor.md b/week_05/05/20-ThreadPoolExecutor.md
new file mode 100644
index 0000000000000000000000000000000000000000..e1d2a018542149bc0f503bf71716404beef4beea
--- /dev/null
+++ b/week_05/05/20-ThreadPoolExecutor.md
@@ -0,0 +1,371 @@
+# ThreadPoolExecutor 源码分析
+
+## 1. 基本介绍
+
+前面文章的 Thread 我们也分析了,因为 Java 中的Thread 和 内核线程是 1 : 1 的,所以线程是一个重量级的对象,应该避免频繁创建和销毁,我们可以使用线程池来避免。
+
+ThreadPoolExecutor 是 Java 实现的线程池,它并没有采取常见的池化资源的设计方法,而是采用的 **生产者-消费者** 模式。
+
+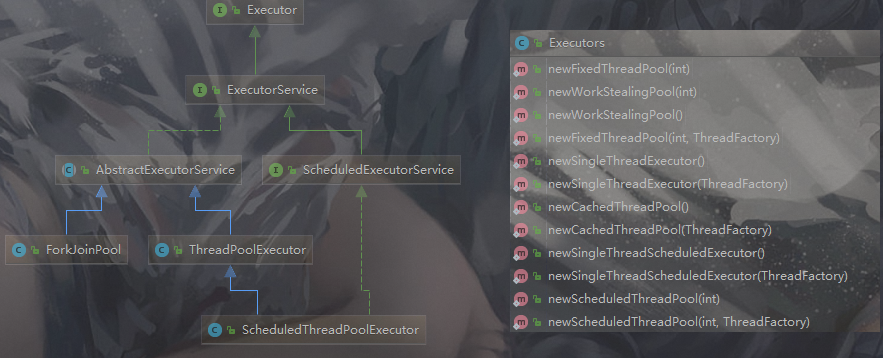
+
+上图的左边是线程池的核心体系,右边是 JDK 提供创建线程池的工具类。
+
+*Executor 接口*
+
+提供最基础的执行方法 execute(Runnable command)
+
+*ExecutorService 接口*
+
+基于 Executor 接口,新增了线程池的一些操作能力
+
+*AbstractExecutorService 抽象类*
+
+使用模板模式,丰富了一部分操作的细节流程
+
+*ForkJoinPool 实现类*
+
+jdk1.7 中新增的线程池类,适用于分治的场景
+
+## 2. 成员变量 & 核心类分析
+
+```java
+// 控制变量 前 3 位标示运行状态,后 29 位标识工作线程的数量
+// 初始化为 RUNNING 状态
+private final AtomicInteger ctl = new AtomicInteger(ctlOf(RUNNING, 0));
+// 移位的段
+private static final int COUNT_BITS = Integer.SIZE - 3;
+// 后29位,标识容量
+// 0001 1111 1111 1111 1111 1111 1111 1111
+private static final int CAPACITY = (1 << COUNT_BITS) - 1;
+// 下面是线程池状态
+// 表示可以接受新任务,且可执行队列的任务
+// 111 0 0000 ... 0000
+private static final int RUNNING = -1 << COUNT_BITS;
+// 不接收新任务,但可以执行队列的任务
+// 000 0 0000 ... 0000
+private static final int SHUTDOWN = 0 << COUNT_BITS;
+// 中断正在执行的,不再接收和执行队列的任务
+// 001 0 0000 ... 0000
+private static final int STOP = 1 << COUNT_BITS;
+// 半中止状态,所有任务都已中止且无工作线程,修改为这个状态,然后执行 terminated() 方法
+// 010 0 0000 ... 0000
+private static final int TIDYING = 2 << COUNT_BITS;
+// 中止状态,已经执行过 terminated() 方法
+// 011 0 0000 ... 0000
+private static final int TERMINATED = 3 << COUNT_BITS;
+// 获取状态
+private static int runStateOf(int c) { return c & ~CAPACITY; }
+// 获取工作线程的数量
+private static int workerCountOf(int c) { return c & CAPACITY; }
+// ctl 的值
+private static int ctlOf(int rs, int wc) { return rs | wc; }
+```
+
+## 3. 核心方法分析
+
+### 3.1 普通任务提交
+
+#### 3.1.1 execute(Runnable command)
+
+主要过程就是:
+
+1. 如果当前工作线程没有达到核心线程数量阈值,就直接添加一个核心工作线程
+2. 如果达到了核心线程数量阈值,就入任务队列,如果状态不正常,执行拒绝策略
+3. 如果队列满了,就创建非核心线程
+4. 如果创建非核心线程失败(达到了最大数量阈值、线程池状态不正常),执行拒绝策略
+
+```java
+public void execute(Runnable command) {
+ // 校验是否为空
+ if (command == null)
+ throw new NullPointerException();
+ int c = ctl.get();
+ // 如果工作线程数小于核心数
+ if (workerCountOf(c) < corePoolSize) {
+ // 添加一个核心工作线程
+ if (addWorker(command, true))
+ return;
+ c = ctl.get();
+ }
+ // 如果线程池状态正常,并且达到了核心数量,就入队列
+ if (isRunning(c) && workQueue.offer(command)) {
+ int recheck = ctl.get();
+ // 再次检查状态,如果不是运行状态就移除任务并执行拒绝策略
+ if (! isRunning(recheck) && remove(command))
+ reject(command);
+ // 再次检查,如果工作线程数量是0,就创建一个
+ else if (workerCountOf(recheck) == 0)
+ addWorker(null, false);
+ }
+ // 如果入队列失败,就尝试创建非核心工作线程
+ else if (!addWorker(command, false))
+ // 创建非核心线程失败,执行拒绝策略
+ reject(command);
+}
+```
+
+#### 3.1.2 addWorker(Runnable firstTask, boolean core)
+
+`addWorker` 方法主要作用就是创建一个工作线程,并加入到工作线程的集合中,然后启动。在此期间会进行状态和数量的校验。
+
+```java
+private boolean addWorker(Runnable firstTask, boolean core) {
+ retry:
+ for (;;) {
+ int c = ctl.get();
+ int rs = runStateOf(c);
+
+ // 校验状态
+ if (rs >= SHUTDOWN &&
+ ! (rs == SHUTDOWN &&
+ firstTask == null &&
+ ! workQueue.isEmpty()))
+ return false;
+
+ for (;;) {
+ int wc = workerCountOf(c);
+ // 校验工作线程数量
+ if (wc >= CAPACITY ||
+ wc >= (core ? corePoolSize : maximumPoolSize))
+ return false;
+ // 数量+1 跳出循环
+ if (compareAndIncrementWorkerCount(c))
+ break retry;
+ c = ctl.get(); // Re-read ctl
+ if (runStateOf(c) != rs)
+ continue retry;
+ // else CAS failed due to workerCount change; retry inner loop
+ }
+ }
+
+ boolean workerStarted = false;
+ boolean workerAdded = false;
+ Worker w = null;
+ try {
+ // 创建工作线程,把 firstTask 封装到 Worker 对象,然后把 Worker 对象传给 thread
+ w = new Worker(firstTask);
+ final Thread t = w.thread;
+ if (t != null) {
+ final ReentrantLock mainLock = this.mainLock;
+ mainLock.lock();
+ try {
+ int rs = runStateOf(ctl.get());
+ // 再次检查状态
+ if (rs < SHUTDOWN ||
+ (rs == SHUTDOWN && firstTask == null)) {
+ if (t.isAlive()) // precheck that t is startable
+ throw new IllegalThreadStateException();
+ // 加入到工作线程集合
+ workers.add(w);
+ // 目前集合的数量
+ int s = workers.size();
+ if (s > largestPoolSize)
+ largestPoolSize = s;
+ // 标记添加成功
+ workerAdded = true;
+ }
+ } finally {
+ mainLock.unlock();
+ }
+ if (workerAdded) {
+ // 添加成功就启动线程
+ // 通过上面 new Worker 的分析,我们知道这里会调用 Worker对象的 run方法
+ // run 方法里接着调用 runWorker(this)
+ t.start();
+ workerStarted = true;
+ }
+ }
+ } finally {
+ // 没有启动成功,执行降级方法(从集合中清除掉、数量减少、)
+ if (! workerStarted)
+ addWorkerFailed(w);
+ }
+ return workerStarted;
+}
+```
+
+#### 3.1.3 runWorker(Worker w)
+
+如果有第一个任务就先执行,之后从任务队列取任务执行。
+
+```java
+final void runWorker(Worker w) {
+ // 获取当前工作线程
+ Thread wt = Thread.currentThread();
+ Runnable task = w.firstTask;
+ w.firstTask = null;
+ // ???
+ w.unlock(); // allow interrupts
+ boolean completedAbruptly = true;
+ try {
+ // task如果为空就取任务,如果任务也取不到就结束循环
+ // getTask() 方法主要就是从任务队列中取任务
+ while (task != null || (task = getTask()) != null) {
+ w.lock();
+ // 检查状态
+ if ((runStateAtLeast(ctl.get(), STOP) ||
+ (Thread.interrupted() &&
+ runStateAtLeast(ctl.get(), STOP))) &&
+ !wt.isInterrupted())
+ wt.interrupt();
+ try {
+ // 任务执行前扩展方法,例如:可以在执行前等待实现暂停的效果
+ beforeExecute(wt, task);
+ Throwable thrown = null;
+ try {
+ // 执行任务
+ task.run();
+ } catch (RuntimeException x) {
+ thrown = x; throw x;
+ } catch (Error x) {
+ thrown = x; throw x;
+ } catch (Throwable x) {
+ thrown = x; throw new Error(x);
+ } finally {
+ // 任务执行后扩展方法,例如:可以在执行后释放一些资源
+ afterExecute(task, thrown);
+ }
+ } finally {
+ // 置 null,重新从队列取
+ task = null;
+ // 增加完成数
+ w.completedTasks++;
+ w.unlock();
+ }
+ }
+ completedAbruptly = false;
+ } finally {
+ processWorkerExit(w, completedAbruptly);
+ }
+}
+```
+
+### 3.2 异步任务提交
+
+#### 3.2.1 submit(Callable task)
+
+`submit` 方法定义在模板类 `AbstractExecutorService` 中,然后把 task 封装为 `FutureTask` , 最后调用 `execute` 方法来提交任务
+
+*AbstractExecutorService#submit*
+
+```java
+public Future submit(Callable task) {
+ if (task == null) throw new NullPointerException();
+ RunnableFuture ftask = newTaskFor(task);
+ execute(ftask);
+ return ftask;
+}
+
+protected RunnableFuture newTaskFor(Runnable runnable, T value) {
+ return new FutureTask(runnable, value);
+}
+```
+
+我们上面分析 `execute` 方法知道其最终执行的地方还是调用的 task 的 run 方法,所以我们来分析 FutureTask 的 run 方法。
+
+#### 3.2.2 run()
+
+主要是多了一个执行结果的记录
+
+```java
+public void run() {
+ // 线程状态不为 NEW 或者 修改当前线程来运行当前任务失败,直接返回
+ if (state != NEW ||
+ !UNSAFE.compareAndSwapObject(this, runnerOffset,
+ null, Thread.currentThread()))
+ return;
+ try {
+ Callable c = callable;
+ // 再次校验线程状态
+ if (c != null && state == NEW) {
+ // 注意盯着这个运行结果变量
+ V result;
+ boolean ran;
+ try {
+ // 任务执行
+ result = c.call();
+ ran = true;
+ } catch (Throwable ex) {
+ result = null;
+ ran = false;
+ // 执行异常就修改线程状态为 EXCEPTIONAL
+ setException(ex);
+ }
+ if (ran)
+ // 执行正常就修改线程的状态为 NORMAL
+ set(result);
+ }
+ } finally {
+ runner = null;
+ // state must be re-read after nulling runner to prevent
+ // leaked interrupts
+ int s = state;
+ if (s >= INTERRUPTING)
+ handlePossibleCancellationInterrupt(s);
+ }
+}
+```
+
+#### 3.2.3 get()
+
+主要思路就是自旋等待线程执行完
+
+```java
+public V get() throws InterruptedException, ExecutionException {
+ int s = state;
+ // 如果线程状态没完成,就进入等待队列
+ if (s <= COMPLETING)
+ s = awaitDone(false, 0L);
+ return report(s);
+}
+
+private int awaitDone(boolean timed, long nanos)
+ throws InterruptedException {
+ final long deadline = timed ? System.nanoTime() + nanos : 0L;
+ WaitNode q = null;
+ boolean queued = false;
+ // 自旋
+ for (;;) {
+ if (Thread.interrupted()) {
+ removeWaiter(q);
+ throw new InterruptedException();
+ }
+
+ int s = state;
+ // 已完成就返回
+ if (s > COMPLETING) {
+ if (q != null)
+ q.thread = null;
+ return s;
+ }
+ // 快完成(异常),就等一会
+ else if (s == COMPLETING) // cannot time out yet
+ Thread.yield();
+ // 第一次进来一般会走到这里,把当前线程构建一个等待节点
+ else if (q == null)
+ q = new WaitNode();
+ // 第二次循环尝试把节点入队
+ else if (!queued)
+ queued = UNSAFE.compareAndSwapObject(this, waitersOffset,
+ q.next = waiters, q);
+ // 如果有超时时间
+ else if (timed) {
+ nanos = deadline - System.nanoTime();
+ if (nanos <= 0L) {
+ removeWaiter(q);
+ return state;
+ }
+ LockSupport.parkNanos(this, nanos);
+ }
+ // 如果发现入队失败(已经入队过了),就挂起当前线程
+ else
+ LockSupport.park(this);
+ }
+}
+```
+
+## 4. 总结
+
+可以看到,线程池实际上是一个生产-消费模型的实现,其支持普通任务提交和异步任务提交(ps.. 其实叫异步并不是很合适,对于用户来说线程池本来就是异步的)。
+
+知道了核心数量以及等待队列还有最大数量这些功能的实现,相信对如何更好的使用线程池会更有帮助。
\ No newline at end of file
diff --git a/week_05/05/21-Executors.md b/week_05/05/21-Executors.md
new file mode 100644
index 0000000000000000000000000000000000000000..e2142fcd64aabfe3bcc117b5c2736209e40f63d4
--- /dev/null
+++ b/week_05/05/21-Executors.md
@@ -0,0 +1,72 @@
+# Executors 源码分析
+
+## TOP 带着问题看源码
+
+1. 为什么阿里巴巴的开发规范不提倡使用 Executors 呢
+
+## 1. 基本介绍
+
+Executors 是辅助线程池创建的工具类,我们可以使用它来很方便的创建出来一个想要的线程池,而不用关心线程池很多复杂的构造参数。
+
+以下是它的 API:
+
+
+
+回到问题 **TOP 2** ,相信看完这个流程图会对状态流转更清晰一些
+
+## 3. 核心方法分析
+
+### 3.1 join()
+
+例如我们 主线程A 要等待 子线程B 完成再往下执行,可以调用 子线程B 的join() 方法
+
+回到问题 **TOP 3** ,其实就是通过 wait 方法来让主线程等待,最后子线程完成后会唤醒主线程来实现了一个线程之间的通信。
+
+```java
+public final void join() throws InterruptedException {
+ join(0);
+}
+
+public final synchronized void join(long millis)
+throws InterruptedException {
+ // 获取当前时间
+ long base = System.currentTimeMillis();
+ long now = 0;
+ // 入参校验
+ if (millis < 0) {
+ throw new IllegalArgumentException("timeout value is negative");
+ }
+ // 默认 join()参数走这个分支
+ if (millis == 0) {
+ // 只要线程还未完成
+ while (isAlive()) {
+ // 0 是一直等待下去
+ wait(0);
+ }
+ } else {
+ while (isAlive()) {
+ // 还剩下多少时间
+ long delay = millis - now;
+ // 时间到了就跳出
+ if (delay <= 0) {
+ break;
+ }
+ // 调用wait方法等待
+ wait(delay);
+ // 当前已经过了多久
+ now = System.currentTimeMillis() - base;
+ }
+ }
+}
+```
+
+### 3.2 interrupt()
+
+我们知道 stop() 方法由于太暴力和不安全已经设置为过期,现在基本上是采用 interrupt() 来交给我们优雅的处理。为什么这样说呢?
+
+我们看下面 interrupt() 的实现可以看到实际上只是设置了一个中断标识(通知线程应该中断了),并不会真正停止一个线程。
+
+```java
+public void interrupt() {
+ if (this != Thread.currentThread())
+ checkAccess();
+
+ synchronized (blockerLock) {
+ Interruptible b = blocker;
+ if (b != null) {
+ interrupt0(); // Just to set the interrupt flag
+ b.interrupt(this);
+ return;
+ }
+ }
+ interrupt0();
+}
+```
+
+但是我们可以通过这个中断的通知来自己处理是继续运行还是中断,例如我们想要中断后停止线程:
+
+```java
+Thread thread = new Thread(() -> {
+ while (!Thread.interrupted()) {
+ // do more work.
+ }
+});
+thread.start();
+
+// 一段时间以后
+thread.interrupt();
+```
+
+> 需要注意的是,在一些可中断阻塞函数中,会抛出 InterruptedException,需要注意的是如果你不想处理继续往上抛,需要再次调用 interrupt() 方法(因为中断状态已经被重置了)。
+
+## 4. 总结
+
+我们这篇文章主要是分析了线程模型和线程的状态,已经几个核心方法的实现,相信看完会对线程有了更深一层的认识。
diff --git a/week_05/05/19-ThreadLocal.md b/week_05/05/19-ThreadLocal.md
new file mode 100644
index 0000000000000000000000000000000000000000..08ae9fb858ac5bcb56a04658833c5b20489ff3cb
--- /dev/null
+++ b/week_05/05/19-ThreadLocal.md
@@ -0,0 +1,272 @@
+# ThreadLocal 源码分析
+
+## TOP 带着问题看源码
+
+1. ThreadLocal 是怎么保证不同线程内部的变量隔离的
+2. 你说了ThreadLocalMap,那它是如何解决Hash冲突的
+3. ThreadLocal 什么情况下会内存泄漏
+
+## 1. 基本介绍
+
+我们知道解决共享变量不安全的一种方式,就是利用每个线程的私有变量来操作,避免共享变量导致的线程不安全问题。
+
+ThreadLocal 就是提供一个局部变量,不会遇到并发问题。
+
+## 2. 成员变量 & 核心类分析
+
+```java
+// 计算hash值
+private final int threadLocalHashCode = nextHashCode();
+// 使用原子类记录hash值
+private static AtomicInteger nextHashCode =
+ new AtomicInteger();
+// 魔数,更好的分散数据
+private static final int HASH_INCREMENT = 0x61c88647;
+
+// Thread.class
+// 每个线程类都会有一个 ThreadLocalMap
+ThreadLocal.ThreadLocalMap threadLocals = null;
+
+// java.lang.ThreadLocal.ThreadLocalMap
+// 初始化容量
+private static final int INITIAL_CAPACITY = 16;
+// 存储数据数组
+private Entry[] table;
+// 元素个数
+private int size = 0;
+// 扩容的阈值
+private int threshold;
+// 构造方法,初始化值
+ThreadLocalMap(ThreadLocal firstKey, Object firstValue) {
+ table = new Entry[INITIAL_CAPACITY];
+ int i = firstKey.threadLocalHashCode & (INITIAL_CAPACITY - 1);
+ table[i] = new Entry(firstKey, firstValue);
+ size = 1;
+ setThreshold(INITIAL_CAPACITY);
+}
+```
+
+回到问题 **TOP 1** ,可以知道是不同线程都有自己的 ThreadLocalMap ,也就天然做到了隔离
+
+### 2.1 ThreadLocal 内存泄漏的原因
+
+通过对变量和核心类的分析,相信对 ThreadLocal 的一个结构有了大致的了解,接下来我们先来看下 ThreadLocal 的 map 是怎么定义的。
+
+```java
+static class Entry extends WeakReference> {
+ Object value;
+ // 注意,这里 k 作为弱引用
+ // 原因是如果是强引用,我们如果把 threadlocal 置为 null 不再使用,但是其在线程中的 threadlocalmap还在,导致无法gc
+ Entry(ThreadLocal k, Object v) {
+ super(k);
+ value = v;
+ }
+}
+```
+
+回到问题 **TOP 3** ,由此可以分析,在 gc 的情况下,k 会出现为 null,也就会出现 value 还在但是无法拿到的情况(内存泄漏)。
+
+实际上在 ThreadLocal 中这个问题并不是想象的那么可怕,其核心方法基本都会对这种无效的数据进行清理。
+
+## 3. 核心方法分析
+
+### 3.1 set 数据
+
+核心逻辑就是:
+
+1. 把数据放到当前线程的 ThreadLocalMap 的 value
+2. 如果当前 key 的位置已经有了就覆盖
+3. 如果当前位置的元素与当前 key 不相等,就插入下一个可以放置元素的地方
+
+```java
+public void set(T value) {
+ // 获取当前线程
+ Thread t = Thread.currentThread();
+ // 获取当前线程的 ThreadLocalMap
+ ThreadLocalMap map = getMap(t);
+ if (map != null)
+ // 这里this是指的调用这个方法的threadlocal对象
+ // 调用 set 方法
+ map.set(this, value);
+ else
+ // 还没有就创建一个map
+ createMap(t, value);
+}
+
+private void set(ThreadLocal key, Object value) {
+ Entry[] tab = table;
+ int len = tab.length;
+ // 根据 hash 计算位置
+ int i = key.threadLocalHashCode & (len-1);
+ // 循环,如果第一次没有获取到 key 相同的,就循环下一个位置
+ for (Entry e = tab[i];
+ e != null;
+ e = tab[i = nextIndex(i, len)]) {
+ // 获取 key
+ ThreadLocal k = e.get();
+ // key 相同,直接覆盖
+ if (k == key) {
+ e.value = value;
+ return;
+ }
+ // key 为空就调用 replaceStaleEntry,见下文
+ if (k == null) {
+ replaceStaleEntry(key, value, i);
+ return;
+ }
+ }
+ // 走到这里说明目标位置是空的,构建元素放到存储数组中
+ tab[i] = new Entry(key, value);
+ // 增加元素个数
+ int sz = ++size;
+ // 如果不再有无用元素,并且容量超过了阈值,就扩容
+ if (!cleanSomeSlots(i, sz) && sz >= threshold)
+ rehash();
+}
+```
+
+回到问题 **TOP 2** ,可以知道其处理 hash 冲突采用的是开放寻址法,位置已被占就会找下一个。在数据量较少的场景,这个是很合适的。
+
+### 3.2 get 数据
+
+核心逻辑就是:
+
+1. 把当前线程的 ThreadLocalMap 的 value 取出来
+2. 如果按照 hash 查找到的 key 不一样,说明出现 hash 冲突了,调用 `getEntryAfterMiss()`
+
+```java
+public T get() {
+ // 获取当前线程
+ Thread t = Thread.currentThread();
+ // 获取当前线程的 ThreadLocalMap
+ ThreadLocalMap map = getMap(t);
+ if (map != null) {
+ // 调用 getEntry 根据 key 查找到 value
+ ThreadLocalMap.Entry e = map.getEntry(this);
+ if (e != null) {
+ @SuppressWarnings("unchecked")
+ T result = (T)e.value;
+ return result;
+ }
+ }
+ return setInitialValue();
+}
+
+private Entry getEntry(ThreadLocal key) {
+ // 根据hash值确定位置,获取元素
+ int i = key.threadLocalHashCode & (table.length - 1);
+ Entry e = table[i];
+ if (e != null && e.get() == key)
+ return e;
+ else
+ // 如果 key 不相同或者值为null,调用 getEntryAfterMiss
+ return getEntryAfterMiss(key, i, e);
+}
+```
+
+### 3.3 辅助方法
+
+#### 3.3.1 getEntryAfterMiss
+
+该方法主要是用来处理 hash 冲突的
+
+```java
+private Entry getEntryAfterMiss(ThreadLocal key, int i, Entry e) {
+ Entry[] tab = table;
+ int len = tab.length;
+ // 死循环
+ while (e != null) {
+ ThreadLocal k = e.get();
+ // 当 key 也相同时候就返回
+ if (k == key)
+ return e;
+ // 如果 key 为 null 调用 expungeStaleEntry
+ if (k == null)
+ expungeStaleEntry(i);
+ else
+ // 获取下一个位置
+ i = nextIndex(i, len);
+ // 获取新的位置元素
+ e = tab[i];
+ }
+ return null;
+}
+```
+
+#### 3.3.2 expungeStaleEntry
+
+核心逻辑就是:
+
+1. 清理无效的 entity
+2. 往后继续搜索和清理,直到 tab[i] == null 退出
+
+```java
+private int expungeStaleEntry(int staleSlot) {
+ Entry[] tab = table;
+ int len = tab.length;
+
+ // 删除无效元素
+ tab[staleSlot].value = null;
+ tab[staleSlot] = null;
+ size--;
+
+ // Rehash until we encounter null
+ Entry e;
+ int i;
+ // 循环,直到 tab[i] == null 退出
+ for (i = nextIndex(staleSlot, len);
+ (e = tab[i]) != null;
+ i = nextIndex(i, len)) {
+ ThreadLocal k = e.get();
+ // 如果再次发现 key 为 null 的都删掉
+ if (k == null) {
+ e.value = null;
+ tab[i] = null;
+ size--;
+ } else {
+ // 处理 rehash 情况
+ int h = k.threadLocalHashCode & (len - 1);
+ if (h != i) {
+ tab[i] = null;
+
+ // Unlike Knuth 6.4 Algorithm R, we must scan until
+ // null because multiple entries could have been stale.
+ while (tab[h] != null)
+ h = nextIndex(h, len);
+ tab[h] = e;
+ }
+ }
+ }
+ return i;
+}
+```
+
+#### 3.3.3 cleanSomeSlots
+
+```java
+private boolean cleanSomeSlots(int i, int n) {
+ boolean removed = false;
+ Entry[] tab = table;
+ int len = tab.length;
+ do {
+ // 获取下一个索引值
+ i = nextIndex(i, len);
+ Entry e = tab[i];
+ // 如果这个索引对应的 value 不为空 并且 key 是空的
+ if (e != null && e.get() == null) {
+ // 重置n为哈希表大小
+ n = len;
+ removed = true;
+ // 清理无效的 entity
+ // expungeStaleEntry我们前面也分析了,会往后找到所有无效的 entity
+ i = expungeStaleEntry(i);
+ }
+ // 每次搜索范围减少一半
+ } while ( (n >>>= 1) != 0);
+ return removed;
+}
+```
+
+## 4. 总结
+
+可以看到,ThreadLocal 在完成基本功能之外,做了很多辅助操作来避免内存泄漏,这种严谨的做法也值得我们在工作中来做。
\ No newline at end of file
diff --git a/week_05/05/20-ThreadPoolExecutor.md b/week_05/05/20-ThreadPoolExecutor.md
new file mode 100644
index 0000000000000000000000000000000000000000..e1d2a018542149bc0f503bf71716404beef4beea
--- /dev/null
+++ b/week_05/05/20-ThreadPoolExecutor.md
@@ -0,0 +1,371 @@
+# ThreadPoolExecutor 源码分析
+
+## 1. 基本介绍
+
+前面文章的 Thread 我们也分析了,因为 Java 中的Thread 和 内核线程是 1 : 1 的,所以线程是一个重量级的对象,应该避免频繁创建和销毁,我们可以使用线程池来避免。
+
+ThreadPoolExecutor 是 Java 实现的线程池,它并没有采取常见的池化资源的设计方法,而是采用的 **生产者-消费者** 模式。
+
+
+
+上图的左边是线程池的核心体系,右边是 JDK 提供创建线程池的工具类。
+
+*Executor 接口*
+
+提供最基础的执行方法 execute(Runnable command)
+
+*ExecutorService 接口*
+
+基于 Executor 接口,新增了线程池的一些操作能力
+
+*AbstractExecutorService 抽象类*
+
+使用模板模式,丰富了一部分操作的细节流程
+
+*ForkJoinPool 实现类*
+
+jdk1.7 中新增的线程池类,适用于分治的场景
+
+## 2. 成员变量 & 核心类分析
+
+```java
+// 控制变量 前 3 位标示运行状态,后 29 位标识工作线程的数量
+// 初始化为 RUNNING 状态
+private final AtomicInteger ctl = new AtomicInteger(ctlOf(RUNNING, 0));
+// 移位的段
+private static final int COUNT_BITS = Integer.SIZE - 3;
+// 后29位,标识容量
+// 0001 1111 1111 1111 1111 1111 1111 1111
+private static final int CAPACITY = (1 << COUNT_BITS) - 1;
+// 下面是线程池状态
+// 表示可以接受新任务,且可执行队列的任务
+// 111 0 0000 ... 0000
+private static final int RUNNING = -1 << COUNT_BITS;
+// 不接收新任务,但可以执行队列的任务
+// 000 0 0000 ... 0000
+private static final int SHUTDOWN = 0 << COUNT_BITS;
+// 中断正在执行的,不再接收和执行队列的任务
+// 001 0 0000 ... 0000
+private static final int STOP = 1 << COUNT_BITS;
+// 半中止状态,所有任务都已中止且无工作线程,修改为这个状态,然后执行 terminated() 方法
+// 010 0 0000 ... 0000
+private static final int TIDYING = 2 << COUNT_BITS;
+// 中止状态,已经执行过 terminated() 方法
+// 011 0 0000 ... 0000
+private static final int TERMINATED = 3 << COUNT_BITS;
+// 获取状态
+private static int runStateOf(int c) { return c & ~CAPACITY; }
+// 获取工作线程的数量
+private static int workerCountOf(int c) { return c & CAPACITY; }
+// ctl 的值
+private static int ctlOf(int rs, int wc) { return rs | wc; }
+```
+
+## 3. 核心方法分析
+
+### 3.1 普通任务提交
+
+#### 3.1.1 execute(Runnable command)
+
+主要过程就是:
+
+1. 如果当前工作线程没有达到核心线程数量阈值,就直接添加一个核心工作线程
+2. 如果达到了核心线程数量阈值,就入任务队列,如果状态不正常,执行拒绝策略
+3. 如果队列满了,就创建非核心线程
+4. 如果创建非核心线程失败(达到了最大数量阈值、线程池状态不正常),执行拒绝策略
+
+```java
+public void execute(Runnable command) {
+ // 校验是否为空
+ if (command == null)
+ throw new NullPointerException();
+ int c = ctl.get();
+ // 如果工作线程数小于核心数
+ if (workerCountOf(c) < corePoolSize) {
+ // 添加一个核心工作线程
+ if (addWorker(command, true))
+ return;
+ c = ctl.get();
+ }
+ // 如果线程池状态正常,并且达到了核心数量,就入队列
+ if (isRunning(c) && workQueue.offer(command)) {
+ int recheck = ctl.get();
+ // 再次检查状态,如果不是运行状态就移除任务并执行拒绝策略
+ if (! isRunning(recheck) && remove(command))
+ reject(command);
+ // 再次检查,如果工作线程数量是0,就创建一个
+ else if (workerCountOf(recheck) == 0)
+ addWorker(null, false);
+ }
+ // 如果入队列失败,就尝试创建非核心工作线程
+ else if (!addWorker(command, false))
+ // 创建非核心线程失败,执行拒绝策略
+ reject(command);
+}
+```
+
+#### 3.1.2 addWorker(Runnable firstTask, boolean core)
+
+`addWorker` 方法主要作用就是创建一个工作线程,并加入到工作线程的集合中,然后启动。在此期间会进行状态和数量的校验。
+
+```java
+private boolean addWorker(Runnable firstTask, boolean core) {
+ retry:
+ for (;;) {
+ int c = ctl.get();
+ int rs = runStateOf(c);
+
+ // 校验状态
+ if (rs >= SHUTDOWN &&
+ ! (rs == SHUTDOWN &&
+ firstTask == null &&
+ ! workQueue.isEmpty()))
+ return false;
+
+ for (;;) {
+ int wc = workerCountOf(c);
+ // 校验工作线程数量
+ if (wc >= CAPACITY ||
+ wc >= (core ? corePoolSize : maximumPoolSize))
+ return false;
+ // 数量+1 跳出循环
+ if (compareAndIncrementWorkerCount(c))
+ break retry;
+ c = ctl.get(); // Re-read ctl
+ if (runStateOf(c) != rs)
+ continue retry;
+ // else CAS failed due to workerCount change; retry inner loop
+ }
+ }
+
+ boolean workerStarted = false;
+ boolean workerAdded = false;
+ Worker w = null;
+ try {
+ // 创建工作线程,把 firstTask 封装到 Worker 对象,然后把 Worker 对象传给 thread
+ w = new Worker(firstTask);
+ final Thread t = w.thread;
+ if (t != null) {
+ final ReentrantLock mainLock = this.mainLock;
+ mainLock.lock();
+ try {
+ int rs = runStateOf(ctl.get());
+ // 再次检查状态
+ if (rs < SHUTDOWN ||
+ (rs == SHUTDOWN && firstTask == null)) {
+ if (t.isAlive()) // precheck that t is startable
+ throw new IllegalThreadStateException();
+ // 加入到工作线程集合
+ workers.add(w);
+ // 目前集合的数量
+ int s = workers.size();
+ if (s > largestPoolSize)
+ largestPoolSize = s;
+ // 标记添加成功
+ workerAdded = true;
+ }
+ } finally {
+ mainLock.unlock();
+ }
+ if (workerAdded) {
+ // 添加成功就启动线程
+ // 通过上面 new Worker 的分析,我们知道这里会调用 Worker对象的 run方法
+ // run 方法里接着调用 runWorker(this)
+ t.start();
+ workerStarted = true;
+ }
+ }
+ } finally {
+ // 没有启动成功,执行降级方法(从集合中清除掉、数量减少、)
+ if (! workerStarted)
+ addWorkerFailed(w);
+ }
+ return workerStarted;
+}
+```
+
+#### 3.1.3 runWorker(Worker w)
+
+如果有第一个任务就先执行,之后从任务队列取任务执行。
+
+```java
+final void runWorker(Worker w) {
+ // 获取当前工作线程
+ Thread wt = Thread.currentThread();
+ Runnable task = w.firstTask;
+ w.firstTask = null;
+ // ???
+ w.unlock(); // allow interrupts
+ boolean completedAbruptly = true;
+ try {
+ // task如果为空就取任务,如果任务也取不到就结束循环
+ // getTask() 方法主要就是从任务队列中取任务
+ while (task != null || (task = getTask()) != null) {
+ w.lock();
+ // 检查状态
+ if ((runStateAtLeast(ctl.get(), STOP) ||
+ (Thread.interrupted() &&
+ runStateAtLeast(ctl.get(), STOP))) &&
+ !wt.isInterrupted())
+ wt.interrupt();
+ try {
+ // 任务执行前扩展方法,例如:可以在执行前等待实现暂停的效果
+ beforeExecute(wt, task);
+ Throwable thrown = null;
+ try {
+ // 执行任务
+ task.run();
+ } catch (RuntimeException x) {
+ thrown = x; throw x;
+ } catch (Error x) {
+ thrown = x; throw x;
+ } catch (Throwable x) {
+ thrown = x; throw new Error(x);
+ } finally {
+ // 任务执行后扩展方法,例如:可以在执行后释放一些资源
+ afterExecute(task, thrown);
+ }
+ } finally {
+ // 置 null,重新从队列取
+ task = null;
+ // 增加完成数
+ w.completedTasks++;
+ w.unlock();
+ }
+ }
+ completedAbruptly = false;
+ } finally {
+ processWorkerExit(w, completedAbruptly);
+ }
+}
+```
+
+### 3.2 异步任务提交
+
+#### 3.2.1 submit(Callable task)
+
+`submit` 方法定义在模板类 `AbstractExecutorService` 中,然后把 task 封装为 `FutureTask` , 最后调用 `execute` 方法来提交任务
+
+*AbstractExecutorService#submit*
+
+```java
+public Future submit(Callable task) {
+ if (task == null) throw new NullPointerException();
+ RunnableFuture ftask = newTaskFor(task);
+ execute(ftask);
+ return ftask;
+}
+
+protected RunnableFuture newTaskFor(Runnable runnable, T value) {
+ return new FutureTask(runnable, value);
+}
+```
+
+我们上面分析 `execute` 方法知道其最终执行的地方还是调用的 task 的 run 方法,所以我们来分析 FutureTask 的 run 方法。
+
+#### 3.2.2 run()
+
+主要是多了一个执行结果的记录
+
+```java
+public void run() {
+ // 线程状态不为 NEW 或者 修改当前线程来运行当前任务失败,直接返回
+ if (state != NEW ||
+ !UNSAFE.compareAndSwapObject(this, runnerOffset,
+ null, Thread.currentThread()))
+ return;
+ try {
+ Callable c = callable;
+ // 再次校验线程状态
+ if (c != null && state == NEW) {
+ // 注意盯着这个运行结果变量
+ V result;
+ boolean ran;
+ try {
+ // 任务执行
+ result = c.call();
+ ran = true;
+ } catch (Throwable ex) {
+ result = null;
+ ran = false;
+ // 执行异常就修改线程状态为 EXCEPTIONAL
+ setException(ex);
+ }
+ if (ran)
+ // 执行正常就修改线程的状态为 NORMAL
+ set(result);
+ }
+ } finally {
+ runner = null;
+ // state must be re-read after nulling runner to prevent
+ // leaked interrupts
+ int s = state;
+ if (s >= INTERRUPTING)
+ handlePossibleCancellationInterrupt(s);
+ }
+}
+```
+
+#### 3.2.3 get()
+
+主要思路就是自旋等待线程执行完
+
+```java
+public V get() throws InterruptedException, ExecutionException {
+ int s = state;
+ // 如果线程状态没完成,就进入等待队列
+ if (s <= COMPLETING)
+ s = awaitDone(false, 0L);
+ return report(s);
+}
+
+private int awaitDone(boolean timed, long nanos)
+ throws InterruptedException {
+ final long deadline = timed ? System.nanoTime() + nanos : 0L;
+ WaitNode q = null;
+ boolean queued = false;
+ // 自旋
+ for (;;) {
+ if (Thread.interrupted()) {
+ removeWaiter(q);
+ throw new InterruptedException();
+ }
+
+ int s = state;
+ // 已完成就返回
+ if (s > COMPLETING) {
+ if (q != null)
+ q.thread = null;
+ return s;
+ }
+ // 快完成(异常),就等一会
+ else if (s == COMPLETING) // cannot time out yet
+ Thread.yield();
+ // 第一次进来一般会走到这里,把当前线程构建一个等待节点
+ else if (q == null)
+ q = new WaitNode();
+ // 第二次循环尝试把节点入队
+ else if (!queued)
+ queued = UNSAFE.compareAndSwapObject(this, waitersOffset,
+ q.next = waiters, q);
+ // 如果有超时时间
+ else if (timed) {
+ nanos = deadline - System.nanoTime();
+ if (nanos <= 0L) {
+ removeWaiter(q);
+ return state;
+ }
+ LockSupport.parkNanos(this, nanos);
+ }
+ // 如果发现入队失败(已经入队过了),就挂起当前线程
+ else
+ LockSupport.park(this);
+ }
+}
+```
+
+## 4. 总结
+
+可以看到,线程池实际上是一个生产-消费模型的实现,其支持普通任务提交和异步任务提交(ps.. 其实叫异步并不是很合适,对于用户来说线程池本来就是异步的)。
+
+知道了核心数量以及等待队列还有最大数量这些功能的实现,相信对如何更好的使用线程池会更有帮助。
\ No newline at end of file
diff --git a/week_05/05/21-Executors.md b/week_05/05/21-Executors.md
new file mode 100644
index 0000000000000000000000000000000000000000..e2142fcd64aabfe3bcc117b5c2736209e40f63d4
--- /dev/null
+++ b/week_05/05/21-Executors.md
@@ -0,0 +1,72 @@
+# Executors 源码分析
+
+## TOP 带着问题看源码
+
+1. 为什么阿里巴巴的开发规范不提倡使用 Executors 呢
+
+## 1. 基本介绍
+
+Executors 是辅助线程池创建的工具类,我们可以使用它来很方便的创建出来一个想要的线程池,而不用关心线程池很多复杂的构造参数。
+
+以下是它的 API:
+
+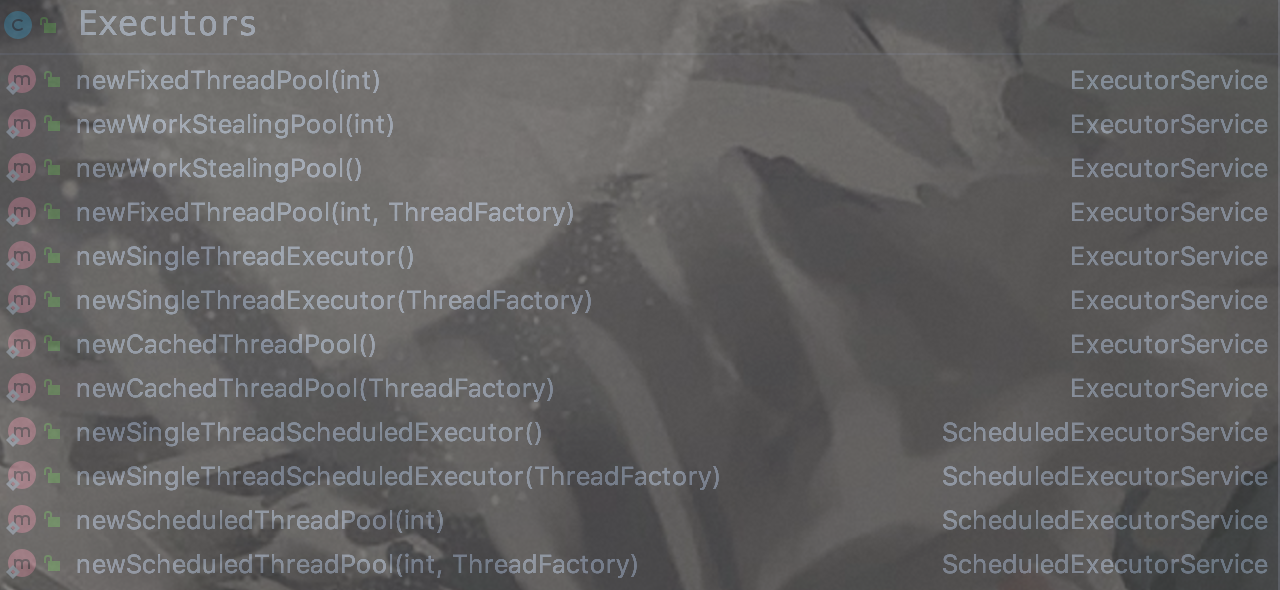 +
+## 2. 核心方法分析
+
+### 2.1 newFixedThreadPool(int nThreads, ThreadFactory threadFactory)
+
+创建一个 **固定数量线程、无界队列** 的线程池
+
+```java
+public static ExecutorService newFixedThreadPool(int nThreads, ThreadFactory threadFactory) {
+ return new ThreadPoolExecutor(nThreads, nThreads,
+ 0L, TimeUnit.MILLISECONDS,
+ new LinkedBlockingQueue(),
+ threadFactory);
+}
+```
+
+### 2.2 newSingleThreadExecutor(ThreadFactory threadFactory)
+
+创建一个 **线程数固定为1、无界队列** 的线程池
+
+```java
+public static ExecutorService newSingleThreadExecutor(ThreadFactory threadFactory) {
+ return new FinalizableDelegatedExecutorService
+ (new ThreadPoolExecutor(1, 1,
+ 0L, TimeUnit.MILLISECONDS,
+ new LinkedBlockingQueue(),
+ threadFactory));
+}
+```
+
+### 2.3 newCachedThreadPool(ThreadFactory threadFactory)
+
+创建一个 **线程数基本无界、保活60秒、无容量的阻塞队列** 的线程池
+
+```java
+public static ExecutorService newCachedThreadPool(ThreadFactory threadFactory) {
+ return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
+ 60L, TimeUnit.SECONDS,
+ new SynchronousQueue(),
+ threadFactory);
+}
+```
+
+### 2.4 newScheduledThreadPool(int corePoolSize, ThreadFactory threadFactory)
+
+创建一个 **固定线程数的可调度** 的线程池
+
+```java
+public static ScheduledExecutorService newScheduledThreadPool(
+ int corePoolSize, ThreadFactory threadFactory) {
+ return new ScheduledThreadPoolExecutor(corePoolSize, threadFactory);
+}
+```
+
+## 3. 总结
+
+由几个常用的核心方法分析,我们可以看到可以满足不同场景的线程池创建。
+
+回到问题 **TOP 1** 阿里的开发规范为什么不提倡,我猜测是因为担心滥用,虽然有些场景还是可以用的,但是通过自己构建的线程池会对参数更加敏感。
\ No newline at end of file
diff --git a/week_05/05/Problem1115.java b/week_05/05/Problem1115.java
new file mode 100644
index 0000000000000000000000000000000000000000..45f1d6c0e7f2629c340d8b9924b529cb05c943df
--- /dev/null
+++ b/week_05/05/Problem1115.java
@@ -0,0 +1,153 @@
+package com.itliusir.concurrent;
+
+import java.util.concurrent.Semaphore;
+import java.util.concurrent.locks.Condition;
+import java.util.concurrent.locks.Lock;
+import java.util.concurrent.locks.ReentrantLock;
+
+/**
+ * @author liugang
+ * @date 2020-01-12
+ */
+public class Problem1115 {
+
+ public static volatile int flag = 0;
+
+ private static Lock lock = new ReentrantLock();
+ private static Condition fooCondition = lock.newCondition();
+ private static Condition barCondition = lock.newCondition();
+ private static boolean fooRun = true;
+
+ private static Object lockObj = new Object();
+
+ private static Semaphore foo = new Semaphore(0);
+ private static Semaphore bar = new Semaphore(1);
+
+ public static void main(String[] args) {
+ FooBar fooBar = new FooBar(2);
+ new Thread(() -> {
+ try {
+ fooBar.bar(() -> {
+ System.out.print("bar");
+ });
+ } catch (InterruptedException e) {
+ e.printStackTrace();
+ }
+ }).start();
+
+ new Thread(() -> {
+ try {
+ fooBar.foo(() -> {
+ System.out.print("foo");
+ });
+ } catch (InterruptedException e) {
+ e.printStackTrace();
+ }
+ }).start();
+ }
+
+ static class FooBar {
+ private int n;
+
+ public FooBar(int n) {
+ this.n = n;
+ }
+
+ public void foo(Runnable printFoo) throws InterruptedException {
+ // method 1
+ /*for (int i = 0; i < n; i++) {
+ while (flag != 0) {
+ Thread.yield();
+ }
+ printFoo.run();
+ flag = 1;
+ }*/
+
+ // method2
+ /*try {
+ lock.lock();
+ for (int i = 0; i < n; i++) {
+ if (!fooRun) {
+ fooCondition.await();
+ barCondition.signal();
+ }
+ printFoo.run();
+ fooRun = false;
+ barCondition.signal();
+ }
+ } finally {
+ lock.unlock();
+ }*/
+
+ // method 3
+ /*for (int i = 0; i < n; i++) {
+ synchronized (lockObj) {
+ if (!fooRun) {
+ lockObj.wait();
+ }
+ printFoo.run();
+ fooRun = false;
+ lockObj.notify();
+ }
+
+ }*/
+
+ // method 4
+ for (int i = 0; i < n; i++) {
+ bar.acquire();
+ printFoo.run();
+ foo.release();
+ }
+
+
+ }
+
+ public void bar(Runnable printBar) throws InterruptedException {
+ // method 1
+ /*for (int i = 0; i < n; i++) {
+ while (flag != 1) {
+ Thread.yield();
+ }
+ printBar.run();
+ flag = 0;
+ }*/
+
+ // method 2
+ /*try {
+ lock.lock();
+ for (int i = 0; i < n; i++) {
+ if (fooRun) {
+ barCondition.await();
+ fooCondition.signal();
+ }
+ printBar.run();
+ fooRun = true;
+ fooCondition.signal();
+ }
+ } finally {
+ lock.unlock();
+ }*/
+
+ // method 3
+ /*for (int i = 0; i < n; i++) {
+ synchronized (lockObj) {
+ if (fooRun) {
+ lockObj.wait();
+ }
+ printBar.run();
+ fooRun = true;
+ lockObj.notify();
+ }
+
+ }*/
+
+ // method 4
+ for (int i = 0; i < n; i++) {
+ foo.acquire();
+ printBar.run();
+ bar.release();
+ }
+
+ }
+ }
+}
diff --git a/week_05/05/Problem1116.java b/week_05/05/Problem1116.java
new file mode 100644
index 0000000000000000000000000000000000000000..79566ad27e00b3bd58eb7f953fe7cd188e1b9004
--- /dev/null
+++ b/week_05/05/Problem1116.java
@@ -0,0 +1,90 @@
+package com.itliusir.concurrent;
+
+import java.util.concurrent.Semaphore;
+import java.util.function.IntConsumer;
+
+/**
+ * @author liugang
+ * @date 2020-01-12
+ */
+public class Problem1116 {
+
+ public static void main(String[] args) {
+ ZeroEvenOdd zeroEvenOdd = new ZeroEvenOdd(5);
+ new Thread(() -> {
+ try {
+ zeroEvenOdd.zero((num) -> System.out.print(num));
+ } catch (InterruptedException e) {
+ e.printStackTrace();
+ }
+ }).start();
+
+ new Thread(() -> {
+ try {
+ zeroEvenOdd.even((num) -> System.out.print(num));
+ } catch (InterruptedException e) {
+ e.printStackTrace();
+ }
+ }).start();
+
+ new Thread(() -> {
+ try {
+ zeroEvenOdd.odd((num) -> System.out.print(num));
+ } catch (InterruptedException e) {
+ e.printStackTrace();
+ }
+ }).start();
+ }
+
+
+ static class ZeroEvenOdd {
+
+ private Semaphore zeroSemaphore = new Semaphore(1);
+ private Semaphore evenSemaphore = new Semaphore(0);
+ private Semaphore oddSemaphore = new Semaphore(0);
+
+ private int n;
+
+ public ZeroEvenOdd(int n) {
+ this.n = n;
+ }
+
+ // printNumber.accept(x) outputs "x", where x is an integer.
+ public void zero(IntConsumer printNumber) throws InterruptedException {
+ boolean printOdd = true;
+ int currentNum = this.n;
+ for (int i = 0; i < currentNum; i++) {
+ zeroSemaphore.acquire();
+ printNumber.accept(0);
+ if (printOdd) {
+ oddSemaphore.release();
+ } else {
+ evenSemaphore.release();
+ }
+ printOdd = !printOdd;
+ }
+ }
+
+ public void even(IntConsumer printNumber) throws InterruptedException {
+ int currentNum = this.n / 2;
+ int nextEvenNum = 2;
+ for (int i = 0; i < currentNum; i++) {
+ evenSemaphore.acquire();
+ printNumber.accept(nextEvenNum);
+ nextEvenNum += 2;
+ zeroSemaphore.release();
+ }
+ }
+
+ public void odd(IntConsumer printNumber) throws InterruptedException {
+ int currentNum = (int) Math.ceil((double) this.n / 2);
+ int nextOddNum = 1;
+ for (int i = 0; i < currentNum; i++) {
+ oddSemaphore.acquire();
+ printNumber.accept(nextOddNum);
+ nextOddNum += 2;
+ zeroSemaphore.release();
+ }
+ }
+ }
+}
+
+## 2. 核心方法分析
+
+### 2.1 newFixedThreadPool(int nThreads, ThreadFactory threadFactory)
+
+创建一个 **固定数量线程、无界队列** 的线程池
+
+```java
+public static ExecutorService newFixedThreadPool(int nThreads, ThreadFactory threadFactory) {
+ return new ThreadPoolExecutor(nThreads, nThreads,
+ 0L, TimeUnit.MILLISECONDS,
+ new LinkedBlockingQueue(),
+ threadFactory);
+}
+```
+
+### 2.2 newSingleThreadExecutor(ThreadFactory threadFactory)
+
+创建一个 **线程数固定为1、无界队列** 的线程池
+
+```java
+public static ExecutorService newSingleThreadExecutor(ThreadFactory threadFactory) {
+ return new FinalizableDelegatedExecutorService
+ (new ThreadPoolExecutor(1, 1,
+ 0L, TimeUnit.MILLISECONDS,
+ new LinkedBlockingQueue(),
+ threadFactory));
+}
+```
+
+### 2.3 newCachedThreadPool(ThreadFactory threadFactory)
+
+创建一个 **线程数基本无界、保活60秒、无容量的阻塞队列** 的线程池
+
+```java
+public static ExecutorService newCachedThreadPool(ThreadFactory threadFactory) {
+ return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
+ 60L, TimeUnit.SECONDS,
+ new SynchronousQueue(),
+ threadFactory);
+}
+```
+
+### 2.4 newScheduledThreadPool(int corePoolSize, ThreadFactory threadFactory)
+
+创建一个 **固定线程数的可调度** 的线程池
+
+```java
+public static ScheduledExecutorService newScheduledThreadPool(
+ int corePoolSize, ThreadFactory threadFactory) {
+ return new ScheduledThreadPoolExecutor(corePoolSize, threadFactory);
+}
+```
+
+## 3. 总结
+
+由几个常用的核心方法分析,我们可以看到可以满足不同场景的线程池创建。
+
+回到问题 **TOP 1** 阿里的开发规范为什么不提倡,我猜测是因为担心滥用,虽然有些场景还是可以用的,但是通过自己构建的线程池会对参数更加敏感。
\ No newline at end of file
diff --git a/week_05/05/Problem1115.java b/week_05/05/Problem1115.java
new file mode 100644
index 0000000000000000000000000000000000000000..45f1d6c0e7f2629c340d8b9924b529cb05c943df
--- /dev/null
+++ b/week_05/05/Problem1115.java
@@ -0,0 +1,153 @@
+package com.itliusir.concurrent;
+
+import java.util.concurrent.Semaphore;
+import java.util.concurrent.locks.Condition;
+import java.util.concurrent.locks.Lock;
+import java.util.concurrent.locks.ReentrantLock;
+
+/**
+ * @author liugang
+ * @date 2020-01-12
+ */
+public class Problem1115 {
+
+ public static volatile int flag = 0;
+
+ private static Lock lock = new ReentrantLock();
+ private static Condition fooCondition = lock.newCondition();
+ private static Condition barCondition = lock.newCondition();
+ private static boolean fooRun = true;
+
+ private static Object lockObj = new Object();
+
+ private static Semaphore foo = new Semaphore(0);
+ private static Semaphore bar = new Semaphore(1);
+
+ public static void main(String[] args) {
+ FooBar fooBar = new FooBar(2);
+ new Thread(() -> {
+ try {
+ fooBar.bar(() -> {
+ System.out.print("bar");
+ });
+ } catch (InterruptedException e) {
+ e.printStackTrace();
+ }
+ }).start();
+
+ new Thread(() -> {
+ try {
+ fooBar.foo(() -> {
+ System.out.print("foo");
+ });
+ } catch (InterruptedException e) {
+ e.printStackTrace();
+ }
+ }).start();
+ }
+
+ static class FooBar {
+ private int n;
+
+ public FooBar(int n) {
+ this.n = n;
+ }
+
+ public void foo(Runnable printFoo) throws InterruptedException {
+ // method 1
+ /*for (int i = 0; i < n; i++) {
+ while (flag != 0) {
+ Thread.yield();
+ }
+ printFoo.run();
+ flag = 1;
+ }*/
+
+ // method2
+ /*try {
+ lock.lock();
+ for (int i = 0; i < n; i++) {
+ if (!fooRun) {
+ fooCondition.await();
+ barCondition.signal();
+ }
+ printFoo.run();
+ fooRun = false;
+ barCondition.signal();
+ }
+ } finally {
+ lock.unlock();
+ }*/
+
+ // method 3
+ /*for (int i = 0; i < n; i++) {
+ synchronized (lockObj) {
+ if (!fooRun) {
+ lockObj.wait();
+ }
+ printFoo.run();
+ fooRun = false;
+ lockObj.notify();
+ }
+
+ }*/
+
+ // method 4
+ for (int i = 0; i < n; i++) {
+ bar.acquire();
+ printFoo.run();
+ foo.release();
+ }
+
+
+ }
+
+ public void bar(Runnable printBar) throws InterruptedException {
+ // method 1
+ /*for (int i = 0; i < n; i++) {
+ while (flag != 1) {
+ Thread.yield();
+ }
+ printBar.run();
+ flag = 0;
+ }*/
+
+ // method 2
+ /*try {
+ lock.lock();
+ for (int i = 0; i < n; i++) {
+ if (fooRun) {
+ barCondition.await();
+ fooCondition.signal();
+ }
+ printBar.run();
+ fooRun = true;
+ fooCondition.signal();
+ }
+ } finally {
+ lock.unlock();
+ }*/
+
+ // method 3
+ /*for (int i = 0; i < n; i++) {
+ synchronized (lockObj) {
+ if (fooRun) {
+ lockObj.wait();
+ }
+ printBar.run();
+ fooRun = true;
+ lockObj.notify();
+ }
+
+ }*/
+
+ // method 4
+ for (int i = 0; i < n; i++) {
+ foo.acquire();
+ printBar.run();
+ bar.release();
+ }
+
+ }
+ }
+}
diff --git a/week_05/05/Problem1116.java b/week_05/05/Problem1116.java
new file mode 100644
index 0000000000000000000000000000000000000000..79566ad27e00b3bd58eb7f953fe7cd188e1b9004
--- /dev/null
+++ b/week_05/05/Problem1116.java
@@ -0,0 +1,90 @@
+package com.itliusir.concurrent;
+
+import java.util.concurrent.Semaphore;
+import java.util.function.IntConsumer;
+
+/**
+ * @author liugang
+ * @date 2020-01-12
+ */
+public class Problem1116 {
+
+ public static void main(String[] args) {
+ ZeroEvenOdd zeroEvenOdd = new ZeroEvenOdd(5);
+ new Thread(() -> {
+ try {
+ zeroEvenOdd.zero((num) -> System.out.print(num));
+ } catch (InterruptedException e) {
+ e.printStackTrace();
+ }
+ }).start();
+
+ new Thread(() -> {
+ try {
+ zeroEvenOdd.even((num) -> System.out.print(num));
+ } catch (InterruptedException e) {
+ e.printStackTrace();
+ }
+ }).start();
+
+ new Thread(() -> {
+ try {
+ zeroEvenOdd.odd((num) -> System.out.print(num));
+ } catch (InterruptedException e) {
+ e.printStackTrace();
+ }
+ }).start();
+ }
+
+
+ static class ZeroEvenOdd {
+
+ private Semaphore zeroSemaphore = new Semaphore(1);
+ private Semaphore evenSemaphore = new Semaphore(0);
+ private Semaphore oddSemaphore = new Semaphore(0);
+
+ private int n;
+
+ public ZeroEvenOdd(int n) {
+ this.n = n;
+ }
+
+ // printNumber.accept(x) outputs "x", where x is an integer.
+ public void zero(IntConsumer printNumber) throws InterruptedException {
+ boolean printOdd = true;
+ int currentNum = this.n;
+ for (int i = 0; i < currentNum; i++) {
+ zeroSemaphore.acquire();
+ printNumber.accept(0);
+ if (printOdd) {
+ oddSemaphore.release();
+ } else {
+ evenSemaphore.release();
+ }
+ printOdd = !printOdd;
+ }
+ }
+
+ public void even(IntConsumer printNumber) throws InterruptedException {
+ int currentNum = this.n / 2;
+ int nextEvenNum = 2;
+ for (int i = 0; i < currentNum; i++) {
+ evenSemaphore.acquire();
+ printNumber.accept(nextEvenNum);
+ nextEvenNum += 2;
+ zeroSemaphore.release();
+ }
+ }
+
+ public void odd(IntConsumer printNumber) throws InterruptedException {
+ int currentNum = (int) Math.ceil((double) this.n / 2);
+ int nextOddNum = 1;
+ for (int i = 0; i < currentNum; i++) {
+ oddSemaphore.acquire();
+ printNumber.accept(nextOddNum);
+ nextOddNum += 2;
+ zeroSemaphore.release();
+ }
+ }
+ }
+}