This method is always invoked by the thread performing + * acquire. If this method reports failure, the acquire method + * may queue the thread, if it is not already queued, until it is + * signalled by a release from some other thread. This can be used + * to implement method {@link Lock#tryLock()}. + * + *
The default + * implementation throws {@link UnsupportedOperationException}. + * + * @param arg the acquire argument. This value is always the one + * passed to an acquire method, or is the value saved on entry + * to a condition wait. The value is otherwise uninterpreted + * and can represent anything you like. + * @return {@code true} if successful. Upon success, this object has + * been acquired. + * @throws IllegalMonitorStateException if acquiring would place this + * synchronizer in an illegal state. This exception must be + * thrown in a consistent fashion for synchronization to work + * correctly. + * @throws UnsupportedOperationException if exclusive mode is not supported + */ + protected boolean tryAcquire(int arg) { + throw new UnsupportedOperationException(); + } +``` + +##### 1.2 addWaiter(Node) + + 该方法用于将当前线程根据不同的模式(`Node.EXCLUSIVE`互斥模式、`Node.SHARED`共享模式)加入到等待队列的队尾,并返回当前线程所在的结点。如果队列不为空,则以通过`compareAndSetTail`方法以CAS的方式将当前线程节点加入到等待队列的末尾。否则,通过enq(node)方法初始化一个等待队列,并返回当前节点。源码如下: + + + +```java +/** + * Creates and enqueues node for current thread and given mode. + * + * @param mode Node.EXCLUSIVE for exclusive, Node.SHARED for shared + * @return the new node + */ + private Node addWaiter(Node mode) { + Node node = new Node(Thread.currentThread(), mode); + // Try the fast path of enq; backup to full enq on failure + Node pred = tail; + if (pred != null) { + node.prev = pred; + if (compareAndSetTail(pred, node)) { + pred.next = node; + return node; + } + } + enq(node); + return node; + } +``` + +##### 1.2.1 enq(node) + + `enq(node)`用于将当前节点插入等待队列,如果队列为空,则初始化当前队列。整个过程以CAS自旋的方式进行,直到成功加入队尾为止。源码如下: + + + +```java +/** + * Inserts node into queue, initializing if necessary. See picture above. + * @param node the node to insert + * @return node's predecessor + */ + private Node enq(final Node node) { + for (;;) { + Node t = tail; + if (t == null) { // Must initialize + if (compareAndSetHead(new Node())) + tail = head; + } else { + node.prev = t; + if (compareAndSetTail(t, node)) { + t.next = node; + return t; + } + } + } + } +``` + +##### 1.3 acquireQueued(Node, int) + + `acquireQueued()`用于队列中的线程自旋地以独占且不可中断的方式获取同步状态(acquire),直到拿到锁之后再返回。该方法的实现分成两部分:如果当前节点已经成为头结点,尝试获取锁(tryAcquire)成功,然后返回;否则检查当前节点是否应该被park,然后将该线程park并且检查当前线程是否被可以被中断。 + + + +```java +/** + * Acquires in exclusive uninterruptible mode for thread already in + * queue. Used by condition wait methods as well as acquire. + * + * @param node the node + * @param arg the acquire argument + * @return {@code true} if interrupted while waiting + */ + final boolean acquireQueued(final Node node, int arg) { + //标记是否成功拿到资源,默认false + boolean failed = true; + try { + boolean interrupted = false;//标记等待过程中是否被中断过 + for (;;) { + final Node p = node.predecessor(); + if (p == head && tryAcquire(arg)) { + setHead(node); + p.next = null; // help GC + failed = false; + return interrupted; + } + if (shouldParkAfterFailedAcquire(p, node) && + parkAndCheckInterrupt()) + interrupted = true; + } + } finally { + if (failed) + cancelAcquire(node); + } + } +``` + +##### 1.3.1 shouldParkAfterFailedAcquire(Node, Node) + + shouldParkAfterFailedAcquire方法通过对当前节点的前一个节点的状态进行判断,对当前节点做出不同的操作,至于每个Node的状态表示,可以参考接口文档。 + + + +```java +/** + * Checks and updates status for a node that failed to acquire. + * Returns true if thread should block. This is the main signal + * control in all acquire loops. Requires that pred == node.prev. + * + * @param pred node's predecessor holding status + * @param node the node + * @return {@code true} if thread should block + */ + private static boolean shouldParkAfterFailedAcquire(Node pred, Node node) { + int ws = pred.waitStatus; + if (ws == Node.SIGNAL) + /* + * This node has already set status asking a release + * to signal it, so it can safely park. + */ + return true; + if (ws > 0) { + /* + * Predecessor was cancelled. Skip over predecessors and + * indicate retry. + */ + do { + node.prev = pred = pred.prev; + } while (pred.waitStatus > 0); + pred.next = node; + } else { + /* + * waitStatus must be 0 or PROPAGATE. Indicate that we + * need a signal, but don't park yet. Caller will need to + * retry to make sure it cannot acquire before parking. + */ + compareAndSetWaitStatus(pred, ws, Node.SIGNAL); + } + return false; + } +``` + +##### 1.3.2 parkAndCheckInterrupt() + + 该方法让线程去休息,真正进入等待状态。park()会让当前线程进入waiting状态。在此状态下,有两种途径可以唤醒该线程:1)被unpark();2)被interrupt()。需要注意的是,Thread.interrupted()会清除当前线程的中断标记位。 + + + +```java +/** + * Convenience method to park and then check if interrupted + * + * @return {@code true} if interrupted + */ + private final boolean parkAndCheckInterrupt() { + LockSupport.park(this); + return Thread.interrupted(); + } +``` + + 我们再回到acquireQueued(),总结下该函数的具体流程: + +> 1. 结点进入队尾后,检查状态,找到安全休息点; +> 2. 调用park()进入waiting状态,等待unpark()或interrupt()唤醒自己; +> 3. 被唤醒后,看自己是不是有资格能拿到号。如果拿到,head指向当前结点,并返回从入队到拿到号的整个过程中是否被中断过;如果没拿到,继续流程1。 + +最后,总结一下acquire()的流程: + +> 1. 调用自定义同步器的tryAcquire()尝试直接去获取资源,如果成功则直接返回; +> 2. 没成功,则addWaiter()将该线程加入等待队列的尾部,并标记为独占模式; +> 3. acquireQueued()使线程在等待队列中休息,有机会时(轮到自己,会被unpark())会去尝试获取资源。获取到资源后才返回。如果在整个等待过程中被中断过,则返回true,否则返回false。 +> 4. 如果线程在等待过程中被中断过,它是不响应的。只是获取资源后才再进行自我中断selfInterrupt(),将中断补上。 + +#### 2. release(int) + + `release(int)`方法是独占模式下线程释放共享资源的顶层入口。它会释放指定量的资源,如果彻底释放了(即state=0),它会唤醒等待队列里的其他线程来获取资源。这也正是unlock()的语义,当然不仅仅只限于unlock()。下面是release()的源码: + + + +```dart +/** + * Releases in exclusive mode. Implemented by unblocking one or + * more threads if {@link #tryRelease} returns true. + * This method can be used to implement method {@link Lock#unlock}. + * + * @param arg the release argument. This value is conveyed to + * {@link #tryRelease} but is otherwise uninterpreted and + * can represent anything you like. + * @return the value returned from {@link #tryRelease} + */ + public final boolean release(int arg) { + if (tryRelease(arg)) { + Node h = head; + if (h != null && h.waitStatus != 0) + unparkSuccessor(h); + return true; + } + return false; + } + +/** + * Attempts to set the state to reflect a release in exclusive + * mode. + * + *
This method is always invoked by the thread performing release. + * + *
The default implementation throws
+ * {@link UnsupportedOperationException}.
+ *
+ * @param arg the release argument. This value is always the one
+ * passed to a release method, or the current state value upon
+ * entry to a condition wait. The value is otherwise
+ * uninterpreted and can represent anything you like.
+ * @return {@code true} if this object is now in a fully released
+ * state, so that any waiting threads may attempt to acquire;
+ * and {@code false} otherwise.
+ * @throws IllegalMonitorStateException if releasing would place this
+ * synchronizer in an illegal state. This exception must be
+ * thrown in a consistent fashion for synchronization to work
+ * correctly.
+ * @throws UnsupportedOperationException if exclusive mode is not supported
+ */
+ protected boolean tryRelease(int arg) {
+ throw new UnsupportedOperationException();
+ }
+
+/**
+ * Wakes up node's successor, if one exists.
+ *
+ * @param node the node
+ */
+ private void unparkSuccessor(Node node) {
+ /*
+ * If status is negative (i.e., possibly needing signal) try
+ * to clear in anticipation of signalling. It is OK if this
+ * fails or if status is changed by waiting thread.
+ */
+ int ws = node.waitStatus;
+ if (ws < 0)
+ compareAndSetWaitStatus(node, ws, 0);
+
+ /*
+ * Thread to unpark is held in successor, which is normally
+ * just the next node. But if cancelled or apparently null,
+ * traverse backwards from tail to find the actual
+ * non-cancelled successor.
+ */
+ Node s = node.next;
+ if (s == null || s.waitStatus > 0) {
+ s = null;
+ for (Node t = tail; t != null && t != node; t = t.prev)
+ if (t.waitStatus <= 0)
+ s = t;
+ }
+ if (s != null)
+ LockSupport.unpark(s.thread);
+ }
+```
+
+ 与acquire()方法中的tryAcquire()类似,tryRelease()方法也是需要独占模式的自定义同步器去实现的。正常来说,tryRelease()都会成功的,因为这是独占模式,该线程来释放资源,那么它肯定已经拿到独占资源了,直接减掉相应量的资源即可(state-=arg),也不需要考虑线程安全的问题。但要注意它的返回值,上面已经提到了,release()是根据tryRelease()的返回值来判断该线程是否已经完成释放掉资源了!所以自义定同步器在实现时,如果已经彻底释放资源(state=0),要返回true,否则返回false。
+ `unparkSuccessor(Node)`方法用于唤醒等待队列中下一个线程。这里要注意的是,下一个线程并不一定是当前节点的next节点,而是下一个可以用来唤醒的线程,如果这个节点存在,调用`unpark()`方法唤醒。
+ 总之,release()是独占模式下线程释放共享资源的顶层入口。它会释放指定量的资源,如果彻底释放了(即state=0),它会唤醒等待队列里的其他线程来获取资源。
+
+#### 3. acquireShared(int)
+
+ `acquireShared(int)`方法是共享模式下线程获取共享资源的顶层入口。它会获取指定量的资源,获取成功则直接返回,获取失败则进入等待队列,直到获取到资源为止,整个过程忽略中断。下面是acquireShared()的源码:
+
+
+
+```dart
+/**
+ * Acquires in shared mode, ignoring interrupts. Implemented by
+ * first invoking at least once {@link #tryAcquireShared},
+ * returning on success. Otherwise the thread is queued, possibly
+ * repeatedly blocking and unblocking, invoking {@link
+ * #tryAcquireShared} until success.
+ *
+ * @param arg the acquire argument. This value is conveyed to
+ * {@link #tryAcquireShared} but is otherwise uninterpreted
+ * and can represent anything you like.
+ */
+ public final void acquireShared(int arg) {
+ if (tryAcquireShared(arg) < 0)
+ doAcquireShared(arg);
+ }
+```
+
+##### 3.1 doAcquireShared(int)
+
+ 将当前线程加入等待队列尾部休息,直到其他线程释放资源唤醒自己,自己成功拿到相应量的资源后才返回。源码如下:
+
+
+
+```java
+ /**
+ * Acquires in shared uninterruptible mode.
+ * @param arg the acquire argument
+ */
+ private void doAcquireShared(int arg) {
+ final Node node = addWaiter(Node.SHARED);
+ boolean failed = true;
+ try {
+ boolean interrupted = false;
+ for (;;) {
+ final Node p = node.predecessor();
+ if (p == head) {
+ int r = tryAcquireShared(arg);
+ if (r >= 0) {
+ setHeadAndPropagate(node, r);
+ p.next = null; // help GC
+ if (interrupted)
+ selfInterrupt();
+ failed = false;
+ return;
+ }
+ }
+ if (shouldParkAfterFailedAcquire(p, node) &&
+ parkAndCheckInterrupt())
+ interrupted = true;
+ }
+ } finally {
+ if (failed)
+ cancelAcquire(node);
+ }
+ }
+```
+
+ 跟独占模式比,还有一点需要注意的是,这里只有线程是head.next时(“老二”),才会去尝试获取资源,有剩余的话还会唤醒之后的队友。那么问题就来了,假如老大用完后释放了5个资源,而老二需要6个,老三需要1个,老四需要2个。老大先唤醒老二,老二一看资源不够,他是把资源让给老三呢,还是不让?答案是否定的!老二会继续park()等待其他线程释放资源,也更不会去唤醒老三和老四了。独占模式,同一时刻只有一个线程去执行,这样做未尝不可;但共享模式下,多个线程是可以同时执行的,现在因为老二的资源需求量大,而把后面量小的老三和老四也都卡住了。当然,这并不是问题,只是AQS保证严格按照入队顺序唤醒罢了(保证公平,但降低了并发)。实现如下:
+
+
+
+```dart
+/**
+ * Sets head of queue, and checks if successor may be waiting
+ * in shared mode, if so propagating if either propagate > 0 or
+ * PROPAGATE status was set.
+ *
+ * @param node the node
+ * @param propagate the return value from a tryAcquireShared
+ */
+ private void setHeadAndPropagate(Node node, int propagate) {
+ Node h = head; // Record old head for check below
+ setHead(node);
+ /*
+ * Try to signal next queued node if:
+ * Propagation was indicated by caller,
+ * or was recorded (as h.waitStatus either before
+ * or after setHead) by a previous operation
+ * (note: this uses sign-check of waitStatus because
+ * PROPAGATE status may transition to SIGNAL.)
+ * and
+ * The next node is waiting in shared mode,
+ * or we don't know, because it appears null
+ *
+ * The conservatism in both of these checks may cause
+ * unnecessary wake-ups, but only when there are multiple
+ * racing acquires/releases, so most need signals now or soon
+ * anyway.
+ */
+ if (propagate > 0 || h == null || h.waitStatus < 0 ||
+ (h = head) == null || h.waitStatus < 0) {
+ Node s = node.next;
+ if (s == null || s.isShared())
+ doReleaseShared();
+ }
+ }
+```
+
+ 此方法在setHead()的基础上多了一步,就是自己苏醒的同时,如果条件符合(比如还有剩余资源),还会去唤醒后继结点,毕竟是共享模式!至此,acquireShared()也要告一段落了。让我们再梳理一下它的流程:
+
+> 1. tryAcquireShared()尝试获取资源,成功则直接返回;
+> 2. 失败则通过doAcquireShared()进入等待队列park(),直到被unpark()/interrupt()并成功获取到资源才返回。整个等待过程也是忽略中断的。
+
+#### 4. releaseShared(int)
+
+ `releaseShared(int)`方法是共享模式下线程释放共享资源的顶层入口。它会释放指定量的资源,如果成功释放且允许唤醒等待线程,它会唤醒等待队列里的其他线程来获取资源。下面是releaseShared()的源码:
+
+
+
+```java
+/**
+ * Releases in shared mode. Implemented by unblocking one or more
+ * threads if {@link #tryReleaseShared} returns true.
+ *
+ * @param arg the release argument. This value is conveyed to
+ * {@link #tryReleaseShared} but is otherwise uninterpreted
+ * and can represent anything you like.
+ * @return the value returned from {@link #tryReleaseShared}
+ */
+ public final boolean releaseShared(int arg) {
+ if (tryReleaseShared(arg)) {
+ doReleaseShared();
+ return true;
+ }
+ return false;
+ }
+```
+
+ 此方法的流程也比较简单,一句话:释放掉资源后,唤醒后继。跟独占模式下的release()相似,但有一点稍微需要注意:独占模式下的tryRelease()在完全释放掉资源(state=0)后,才会返回true去唤醒其他线程,这主要是基于独占下可重入的考量;而共享模式下的releaseShared()则没有这种要求,共享模式实质就是控制一定量的线程并发执行,那么拥有资源的线程在释放掉部分资源时就可以唤醒后继等待结点。
+
+
+
+```csharp
+/**
+ * Release action for shared mode -- signals successor and ensures
+ * propagation. (Note: For exclusive mode, release just amounts
+ * to calling unparkSuccessor of head if it needs signal.)
+ */
+ private void doReleaseShared() {
+ /*
+ * Ensure that a release propagates, even if there are other
+ * in-progress acquires/releases. This proceeds in the usual
+ * way of trying to unparkSuccessor of head if it needs
+ * signal. But if it does not, status is set to PROPAGATE to
+ * ensure that upon release, propagation continues.
+ * Additionally, we must loop in case a new node is added
+ * while we are doing this. Also, unlike other uses of
+ * unparkSuccessor, we need to know if CAS to reset status
+ * fails, if so rechecking.
+ */
+ for (;;) {
+ Node h = head;
+ if (h != null && h != tail) {
+ int ws = h.waitStatus;
+ if (ws == Node.SIGNAL) {
+ if (!compareAndSetWaitStatus(h, Node.SIGNAL, 0))
+ continue; // loop to recheck cases
+ unparkSuccessor(h);
+ }
+ else if (ws == 0 &&
+ !compareAndSetWaitStatus(h, 0, Node.PROPAGATE))
+ continue; // loop on failed CAS
+ }
+ if (h == head) // loop if head changed
+ break;
+ }
+ }
+```
\ No newline at end of file
diff --git "a/week_03/51/Java\345\206\205\345\255\230\346\250\241\345\236\213.md" "b/week_03/51/Java\345\206\205\345\255\230\346\250\241\345\236\213.md"
new file mode 100644
index 0000000..7409dc7
--- /dev/null
+++ "b/week_03/51/Java\345\206\205\345\255\230\346\250\241\345\236\213.md"
@@ -0,0 +1,235 @@
+## 简介
+
+Java内存模型是在硬件内存模型上的更高层的抽象,它屏蔽了各种硬件和操作系统访问的差异性,保证了Java程序在各种平台下对内存的访问都能达到一致的效果。
+
+## 硬件内存模型
+
+在正式讲解Java的内存模型之前,我们有必要先了解一下硬件层面的一些东西。
+
+在现代计算机的硬件体系中,CPU的运算速度是非常快的,远远高于它从存储介质读取数据的速度,这里的存储介质有很多,比如磁盘、光盘、网卡、内存等,这些存储介质有一个很明显的特点——距离CPU越近的存储介质往往越小越贵越快,距离CPU越远的存储介质往往越大越便宜越慢。
+
+所以,在程序运行的过程中,CPU大部分时间都浪费在了磁盘IO、网络通讯、数据库访问上,如果不想让CPU在那里白白等待,我们就必须想办法去把CPU的运算能力压榨出来,否则就会造成很大的浪费,而让CPU同时去处理多项任务则是最容易想到的,也是被证明非常有效的压榨手段,这也就是我们常说的“并发执行”。
+
+但是,让CPU并发地执行多项任务并不是那么容易实现的事,因为所有的运算都不可能只依靠CPU的计算就能完成,往往还需要跟内存进行交互,如读取运算数据、存储运算结果等。
+
+前面我们也说过了,CPU与内存的交互往往是很慢的,所以这就要求我们要想办法在CPU和内存之间建立一种连接,使它们达到一种平衡,让运算能快速地进行,而这种连接就是我们常说的“高速缓存”。
+
+高速缓存的速度是非常接近CPU的,但是它的引入又带来了新的问题,现代的CPU往往是有多个核心的,每个核心都有自己的缓存,而多个核心之间是不存在时间片的竞争的,它们可以并行地执行,那么,怎么保证这些缓存与主内存中的数据的一致性就成为了一个难题。
+
+为了解决缓存一致性的问题,多个核心在访问缓存时要遵循一些协议,在读写操作时根据协议来操作,这些协议有MSI、MESI、MOSI等,它们定义了何时应该访问缓存中的数据、何时应该让缓存失效、何时应该访问主内存中的数据等基本原则。
+
+
+
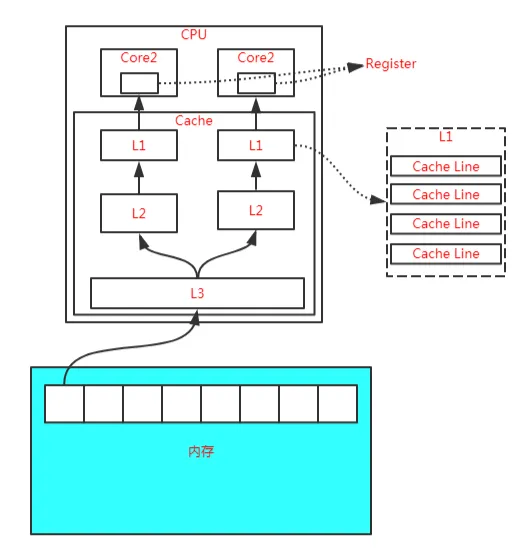
+而随着CPU能力的不断提升,一层缓存就无法满足要求了,就逐渐衍生出了多级缓存。
+
+按照数据读取顺序和CPU的紧密程度,CPU的缓存可以分为一级缓存(L1)、二级缓存(L2)、三级缓存(L3),每一级缓存存储的数据都是下一级的一部分。
+
+这三种缓存的技术难度和制作成本是相对递减的,容量也是相对递增的。
+
+所以,在有了多级缓存后,程序的运行就变成了:
+
+当CPU要读取一个数据的时候,先从一级缓存中查找,如果没找到再从二级缓存中查找,如果没找到再从三级缓存中查找,如果没找到再从主内存中查找,然后再把找到的数据依次加载到多级缓存中,下次再使用相关的数据直接从缓存中查找即可。
+
+而加载到缓存中的数据也不是说用到哪个就加载哪个,而是加载内存中连续的数据,一般来说是加载连续的64个字节,因此,如果访问一个 long 类型的数组时,当数组中的一个值被加载到缓存中时,另外 7 个元素也会被加载到缓存中,这就是“缓存行”的概念。
+
+
+
+缓存行虽然能极大地提高程序运行的效率,但是在多线程对共享变量的访问过程中又带来了新的问题,也就是非常著名的“伪共享”。
+
+关于伪共享的问题,我们这里就不展开讲了,有兴趣的可以看彤哥之前发布的【[杂谈 什么是伪共享(false sharing)?](https://mp.weixin.qq.com/s?__biz=Mzg2ODA0ODM0Nw==&mid=2247483887&idx=1&sn=eac830409917a8c31840c687b4a4154b&scene=21#wechat_redirect)】章节的相关内容。
+
+除此之外,为了使CPU中的运算单元能够充分地被利用,CPU可能会对输入的代码进行乱序执行优化,然后在计算之后再将乱序执行的结果进行重组,保证该结果与顺序执行的结果一致,但并不保证程序中各个语句计算的先后顺序与代码的输入顺序一致,因此,如果一个计算任务依赖于另一个计算任务的结果,那么其顺序性并不能靠代码的先后顺序来保证。
+
+与CPU的乱序执行优化类似,java虚拟机的即时编译器也有类似的指令重排序优化。
+
+为了解决上面提到的多个缓存读写一致性以及乱序排序优化的问题,这就有了内存模型,它定义了共享内存系统中多线程读写操作行为的规范。
+
+## Java内存模型
+
+Java内存模型(Java Memory Model,JMM)是在硬件内存模型基础上更高层的抽象,它屏蔽了各种硬件和操作系统对内存访问的差异性,从而实现让Java程序在各种平台下都能达到一致的并发效果。
+
+Java内存模型定义了程序中各个变量的访问规则,即在虚拟机中将变量存储到内存和从内存中取出这样的底层细节。这里所说的变量包括实例字段、静态字段,但不包括局部变量和方法参数,因为它们是线程私有的,它们不会被共享,自然不存在竞争问题。
+
+为了获得更好的执行效能,Java内存模型并没有限制执行引擎使用处理器的特定寄存器或缓存来和主内存进行交互,也没有限制即时编译器调整代码的执行顺序等这类权利。
+
+Java内存模型规定了所有的变量都存储在主内存中,这里的主内存跟介绍硬件时所用的名字一样,两者可以类比,但此处仅指虚拟机中内存的一部分。
+
+除了主内存,每条线程还有自己的工作内存,此处可与CPU的高速缓存进行类比。工作内存中保存着该线程使用到的变量的主内存副本的拷贝,线程对变量的操作都必须在工作内存中进行,包括读取和赋值等,而不能直接读写主内存中的变量,不同的线程之间也无法直接访问对方工作内存中的变量,线程间变量值的传递必须通过主内存来完成。
+
+线程、工作内存、主内存三者的关系如下图所示:
+
+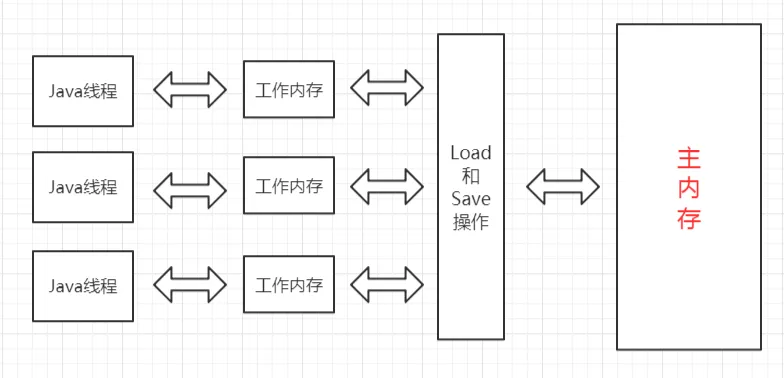u
+
+注意,这里所说的主内存、工作内存跟Java虚拟机内存区域划分中的堆、栈是不同层次的内存划分,如果两者一定要勉强对应起来,主内存主要对应于堆中对象的实例部分,而工作内存主要对应与虚拟机栈中的部分区域。
+
+从更低层次来说,主内存主要对应于硬件内存部分,工作内存主要对应于CPU的高速缓存和寄存器部分,但也不是绝对的,主内存也可能存在于高速缓存和寄存器中,工作内存也可能存在于硬件内存中。
+
+
+
+## 内存间的交互操作
+
+关于主内存与工作内存之间具体的交互协议,Java内存模型定义了以下8种具体的操作来完成:
+
+(1)lock,锁定,作用于主内存的变量,它把主内存中的变量标识为一条线程独占状态;
+
+(2)unlock,解锁,作用于主内存的变量,它把锁定的变量释放出来,释放出来的变量才可以被其它线程锁定;
+
+(3)read,读取,作用于主内存的变量,它把一个变量从主内存传输到工作内存中,以便后续的load操作使用;
+
+(4)load,载入,作用于工作内存的变量,它把read操作从主内存得到的变量放入工作内存的变量副本中;
+
+(5)use,使用,作用于工作内存的变量,它把工作内存中的一个变量传递给执行引擎,每当虚拟机遇到一个需要使用到变量的值的字节码指令时将会执行这个操作;
+
+(6)assign,赋值,作用于工作内存的变量,它把一个从执行引擎接收到的变量赋值给工作内存的变量,每当虚拟机遇到一个给变量赋值的字节码指令时使用这个操作;
+
+(7)store,存储,作用于工作内存的变量,它把工作内存中一个变量的值传递到主内存中,以便后续的write操作使用;
+
+(8)write,写入,作用于主内存的变量,它把store操作从工作内存得到的变量的值放入到主内存的变量中;
+
+如果要把一个变量从主内存复制到工作内存,那就要按顺序地执行read和load操作,同样地,如果要把一个变量从工作内存同步回主内存,就要按顺序地执行store和write操作。注意,这里只说明了要按顺序,并没有说一定要连续,也就是说可以在read与load之间、store与write之间插入其它操作。比如,对主内存中的变量a和b的访问,可以按照以下顺序执行:
+
+read a -> read b -> load b -> load a。
+
+另外,Java内存模型还定义了执行上述8种操作的基本规则:
+
+(1)不允许read和load、store和write操作之一单独出现,即不允许出现从主内存读取了而工作内存不接受,或者从工作内存回写了但主内存不接受的情况出现;
+
+(2)不允许一个线程丢弃它最近的assign操作,即变量在工作内存变化了必须把该变化同步回主内存;
+
+(3)不允许一个线程无原因地(即未发生过assign操作)把一个变量从工作内存同步回主内存;
+
+(4)一个新的变量必须在主内存中诞生,不允许工作内存中直接使用一个未被初始化(load或assign)过的变量,换句话说就是对一个变量的use和store操作之前必须执行过load和assign操作;
+
+(5)一个变量同一时刻只允许一条线程对其进行lock操作,但lock操作可以被同一个线程执行多次,多次执行lock后,只有执行相同次数的unlock操作,变量才能被解锁。
+
+(6)如果对一个变量执行lock操作,将会清空工作内存中此变量的值,在执行引擎使用这个变量前,需要重新执行load或assign操作初始化变量的值;
+
+(7)如果一个变量没有被lock操作锁定,则不允许对其执行unlock操作,也不允许unlock一个其它线程锁定的变量;
+
+(8)对一个变量执行unlock操作之前,必须先把此变量同步回主内存中,即执行store和write操作;
+
+注意,这里的lock和unlock是实现synchronized的基础,Java并没有把lock和unlock操作直接开放给用户使用,但是却提供了两个更高层次的指令来隐式地使用这两个操作,即moniterenter和moniterexit。
+
+## 原子性、可见性、有序性
+
+Java内存模型就是为了解决多线程环境下共享变量的一致性问题,那么一致性包含哪些内容呢?
+
+一致性主要包含三大特性:原子性、可见性、有序性,下面我们就来看看Java内存模型是怎么实现这三大特性的。
+
+(1)原子性
+
+原子性是指一段操作一旦开始就会一直运行到底,中间不会被其它线程打断,这段操作可以是一个操作,也可以是多个操作。
+
+由Java内存模型来直接保证的原子性操作包括read、load、user、assign、store、write这两个操作,我们可以大致认为基本类型变量的读写是具备原子性的。
+
+如果应用需要一个更大范围的原子性,Java内存模型还提供了lock和unlock这两个操作来满足这种需求,尽管不能直接使用这两个操作,但我们可以使用它们更具体的实现synchronized来实现。
+
+因此,synchronized块之间的操作也是原子性的。
+
+(2)可见性
+
+可见性是指当一个线程修改了共享变量的值,其它线程能立即感知到这种变化。
+
+Java内存模型是通过在变更修改后同步回主内存,在变量读取前从主内存刷新变量值来实现的,它是依赖主内存的,无论是普通变量还是volatile变量都是如此。
+
+普通变量与volatile变量的主要区别是是否会在修改之后立即同步回主内存,以及是否在每次读取前立即从主内存刷新。因此我们可以说volatile变量保证了多线程环境下变量的可见性,但普通变量不能保证这一点。
+
+除了volatile之外,还有两个关键字也可以保证可见性,它们是synchronized和final。
+
+synchronized的可见性是由“对一个变量执行unlock操作之前,必须先把此变量同步回主内存中,即执行store和write操作”这条规则获取的。
+
+final的可见性是指被final修饰的字段在构造器中一旦被初始化完成,那么其它线程中就能看见这个final字段了。
+
+(3)有序性
+
+Java程序中天然的有序性可以总结为一句话:如果在本线程中观察,所有的操作都是有序的;如果在另一个线程中观察,所有的操作都是无序的。
+
+前半句是指线程内表现为串行的语义,后半句是指“指令重排序”现象和“工作内存和主内存同步延迟”现象。
+
+Java中提供了volatile和synchronized两个关键字来保证有序性。
+
+volatile天然就具有有序性,因为其禁止重排序。
+
+synchronized的有序性是由“一个变量同一时刻只允许一条线程对其进行lock操作”这条规则获取的。
+
+## 先行发生原则(Happens-Before)
+
+如果Java内存模型的有序性都只依靠volatile和synchronized来完成,那么有一些操作就会变得很啰嗦,但是我们在编写Java并发代码时并没有感受到,这是因为Java语言天然定义了一个“先行发生”原则,这个原则非常重要,依靠这个原则我们可以很容易地判断在并发环境下两个操作是否可能存在竞争冲突问题。
+
+先行发生,是指操作A先行发生于操作B,那么操作A产生的影响能够被操作B感知到,这种影响包括修改了共享内存中变量的值、发送了消息、调用了方法等。
+
+下面我们看看Java内存模型定义的先行发生原则有哪些:
+
+(1)程序次序原则
+
+在一个线程内,按照程序书写的顺序执行,书写在前面的操作先行发生于书写在后面的操作,准确地讲是控制流顺序而不是代码顺序,因为要考虑分支、循环等情况。
+
+(2)监视器锁定原则
+
+一个unlock操作先行发生于后面对同一个锁的lock操作。
+
+(3)volatile原则
+
+对一个volatile变量的写操作先行发生于后面对该变量的读操作。
+
+(4)线程启动原则
+
+对线程的start()操作先行发生于线程内的任何操作。
+
+(5)线程终止原则
+
+线程中的所有操作先行发生于检测到线程终止,可以通过Thread.join()、Thread.isAlive()的返回值检测线程是否已经终止。
+
+(6)线程中断原则
+
+对线程的interrupt()的调用先行发生于线程的代码中检测到中断事件的发生,可以通过Thread.interrupted()方法检测是否发生中断。
+
+(7)对象终结原则
+
+一个对象的初始化完成(构造方法执行结束)先行发生于它的finalize()方法的开始。
+
+(8)传递性原则
+
+如果操作A先行发生于操作B,操作B先行发生于操作C,那么操作A先行发生于操作C。
+
+这里说的“先行发生”与“时间上的先发生”没有必然的关系。
+
+比如,下面的代码:
+
+```
+int a = 0;
+// 操作A:线程1对进行赋值操作a = 1;
+// 操作B:线程2获取a的值
+int b = a;
+```
+
+如果线程1在时间顺序上先对a进行赋值,然后线程2再获取a的值,这能说明操作A先行发生于操作B吗?
+
+显然不能,因为线程2可能读取的还是其工作内存中的值,或者说线程1并没有把a的值刷新回主内存呢,这时候线程2读取到的值可能还是0。
+
+所以,“时间上的先发生”不一定“先行发生”。
+
+再看一个例子:
+
+```
+// 同一个线程中int i = 1;
+int j = 2;
+```
+
+根据第一条程序次序原则, `inti=1;`先行发生于 `intj=2;`,但是由于处理器优化,可能导致 `intj=2;`先执行,但是这并不影响先行发生原则的正确性,因为我们在这个线程中并不会感知到这点。
+
+所以,“先行发生”不一定“时间上先发生”。
+
+## 总结
+
+(1)硬件内存架构使得我们必须建立内存模型来保证多线程环境下对共享内存访问的正确性;
+
+(2)Java内存模型定义了保证多线程环境下共享变量一致性的规则;
+
+(3)Java内存模型提供了工作内存与主内存交互的8大操作:lock、unlock、read、load、use、assign、store、write;
+
+(4)Java内存模型对原子性、可见性、有序性提供了一些实现;
+
+(5)先行发生的8大原则:程序次序原则、监视器锁定原则、volatile原则、线程启动原则、线程终止原则、线程中断原则、对象终结原则、传递性原则;
+
+(6)先行发生不等于时间上的先发生;
\ No newline at end of file
diff --git a/week_03/51/ReentrantLock_51.md b/week_03/51/ReentrantLock_51.md
new file mode 100644
index 0000000..a0022ed
--- /dev/null
+++ b/week_03/51/ReentrantLock_51.md
@@ -0,0 +1,679 @@
+目录
+
+- [1.前言](https://www.cnblogs.com/takumicx/p/9402021.html#前言)
+- 2.AbstractQueuedSynchronizer介绍
+ - [2.1 AQS是构建同步组件的基础](https://www.cnblogs.com/takumicx/p/9402021.html#aqs是构建同步组件的基础)
+ - [2.2 AQS的内部结构(ReentrantLock的语境下)](https://www.cnblogs.com/takumicx/p/9402021.html#aqs的内部结构reentrantlock的语境下)
+- 3 非公平模式加锁流程
+ - [3.1加锁流程真正意义上的入口](https://www.cnblogs.com/takumicx/p/9402021.html#加锁流程真正意义上的入口)
+ - [3.2 尝试获取锁的通用方法:tryAcquire()](https://www.cnblogs.com/takumicx/p/9402021.html#尝试获取锁的通用方法tryacquire)
+ - [3.3 获取锁失败的线程如何安全的加入同步队列:addWaiter()](https://www.cnblogs.com/takumicx/p/9402021.html#获取锁失败的线程如何安全的加入同步队列addwaiter)
+ - [3.4 线程加入同步队列后会做什么:acquireQueued()](https://www.cnblogs.com/takumicx/p/9402021.html#线程加入同步队列后会做什么acquirequeued)
+ - [3.5 加锁流程源码总结](https://www.cnblogs.com/takumicx/p/9402021.html#加锁流程源码总结)
+- 4.非公平模式解锁流程
+ - [4.1 解锁流程源码解读](https://www.cnblogs.com/takumicx/p/9402021.html#解锁流程源码解读)
+ - [4.2 解锁流程源码总结](https://www.cnblogs.com/takumicx/p/9402021.html#解锁流程源码总结)
+- [5. 公平锁相比非公平锁的不同](https://www.cnblogs.com/takumicx/p/9402021.html#公平锁相比非公平锁的不同)
+- \6. 一些疑问的解答
+ - [6.1 为什么基于FIFO的同步队列可以实现非公平锁?](https://www.cnblogs.com/takumicx/p/9402021.html#为什么基于fifo的同步队列可以实现非公平锁)
+ - [6.2 为什么非公平锁性能好](https://www.cnblogs.com/takumicx/p/9402021.html#为什么非公平锁性能好)
+- [7. 阅读源码的收获](https://www.cnblogs.com/takumicx/p/9402021.html#阅读源码的收获)
+
+## 1.前言
+
+在[ReentrantLock(重入锁)功能详解和应用演示](https://www.cnblogs.com/takumicx/p/9338983.html)这篇文章里我们讲解并演示了ReentrantLock(重入锁)的各种功能,其中就谈到ReentrantLock可以有公平锁和非公平锁的不同实现,只要在构造它的时候传入不同的布尔值,继续跟进下源码我们就能发现,关键在于实例化内部变量`sync`的方式不同,如下所示
+
+```
+/**
+ * Creates an instance of {@code ReentrantLock} with the
+ * given fairness policy.
+ *
+ * @param fair {@code true} if this lock should use a fair ordering policy
+ */
+public ReentrantLock(boolean fair) {
+ sync = fair ? new FairSync() : new NonfairSync();
+}
+```
+
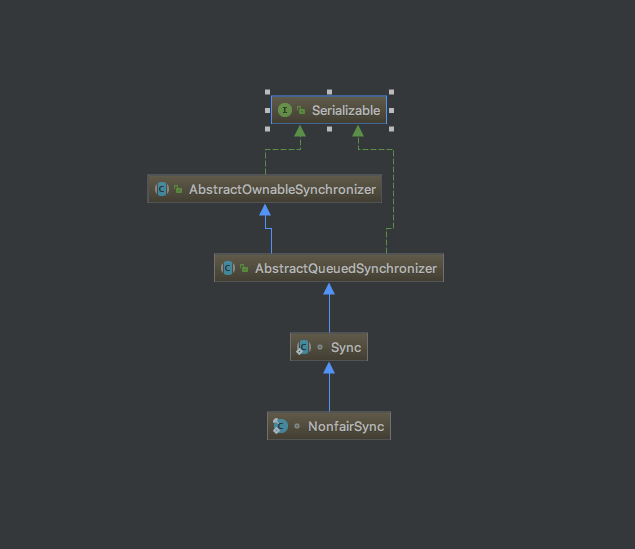
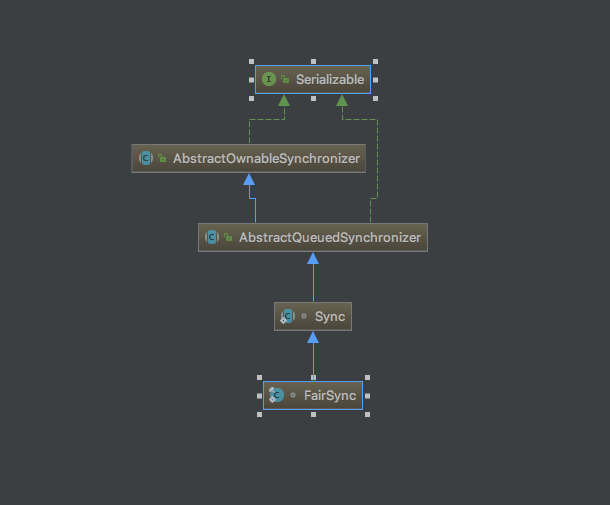
+公平锁内部是FairSync,非公平锁内部是NonfairSync。而不管是FairSync还是NonfariSync,都间接继承自AbstractQueuedSynchronizer这个抽象类,如下图所示
+
+- NonfairSync的类继承关系
+ 
+- FairSync的类继承关系
+ 
+
+该抽象类为我们的加锁和解锁过程提供了统一的模板方法,只是一些细节的处理由该抽象类的实现类自己决定。所以在解读ReentrantLock(重入锁)的源码之前,有必要了解下AbstractQueuedSynchronizer。
+
+## 2.AbstractQueuedSynchronizer介绍
+
+### 2.1 AQS是构建同步组件的基础
+
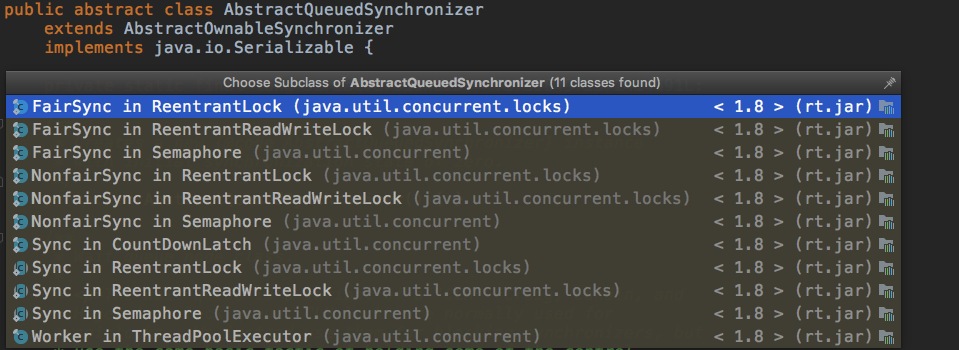
+AbstractQueuedSynchronizer,简称AQS,为构建不同的同步组件(重入锁,读写锁,CountDownLatch等)提供了可扩展的基础框架,如下图所示。
+
+
+AQS以模板方法模式在内部定义了获取和释放同步状态的模板方法,并留下钩子函数供子类继承时进行扩展,由子类决定在获取和释放同步状态时的细节,从而实现满足自身功能特性的需求。除此之外,AQS通过内部的同步队列管理获取同步状态失败的线程,向实现者屏蔽了线程阻塞和唤醒的细节。
+
+### 2.2 AQS的内部结构(ReentrantLock的语境下)
+
+AQS的内部结构主要由同步等待队列构成
+
+#### 2.2.1 同步等待队列
+
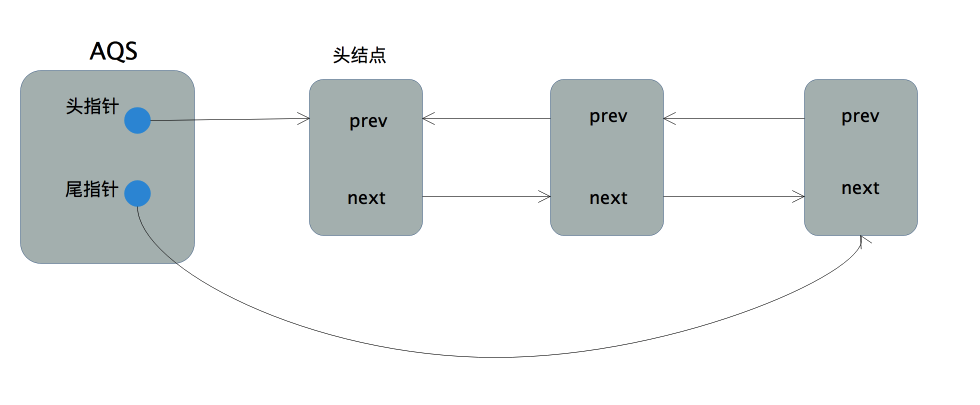
+AQS中同步等待队列的实现是一个带头尾指针(这里用指针表示引用是为了后面讲解源码时可以更直观形象,况且引用本身是一种受限的指针)且不带哨兵结点(后文中的头结点表示队列首元素结点,不是指哨兵结点)的双向链表。
+
+```
+/**
+ * Head of the wait queue, lazily initialized. Except for
+ * initialization, it is modified only via method setHead. Note:
+ * If head exists, its waitStatus is guaranteed not to be
+ * CANCELLED.
+ */
+private transient volatile Node head;//指向队列首元素的头指针
+
+/**
+ * Tail of the wait queue, lazily initialized. Modified only via
+ * method enq to add new wait node.
+ */
+private transient volatile Node tail;//指向队列尾元素的尾指针
+```
+
+head是头指针,指向队列的首元素;tail是尾指针,指向队列的尾元素。而队列的元素结点Node定义在AQS内部,主要有如下几个成员变量
+
+```
+volatile Node prev; //指向前一个结点的指针
+
+volatile Node next; //指向后一个结点的指针
+volatile Thread thread; //当前结点代表的线程
+volatile int waitStatus; //等待状态
+```
+
+- prev:指向前一个结点的指针
+- next:指向后一个结点的指针
+- thread:当前结点表示的线程,因为同步队列中的结点内部封装了之前竞争锁失败的线程,故而结点内部必然有一个对应线程实例的引用
+- waitStatus:对于重入锁而言,主要有3个值。0:初始化状态;-1(SIGNAL):当前结点表示的线程在释放锁后需要唤醒后续节点的线程;1(CANCELLED):在同步队列中等待的线程等待超时或者被中断,取消继续等待。
+
+------
+
+同步队列的结构如下图所示
+
+
+为了接下来能够更好的理解加锁和解锁过程的源码,对该同步队列的特性进行简单的讲解:
+
+- 1.同步队列是个先进先出(FIFO)队列,获取锁失败的线程将构造结点并加入队列的尾部,并阻塞自己。如何才能线程安全的实现入队是后面讲解的重点,毕竟我们在讲锁的实现,这部分代码肯定是不能用锁的。
+- 2.队列首结点可以用来表示当前正获取锁的线程。
+- 3.当前线程释放锁后将尝试唤醒后续处结点中处于阻塞状态的线程。
+
+为了加深理解,还可以在阅读源码的过程中思考下这个问题:
+
+这个同步队列是FIFO队列,也就是说先在队列中等待的线程将比后面的线程更早的得到锁,那ReentrantLock是如何基于这个FIFO队列实现非公平锁的?
+
+#### 2.2.2 AQS中的其他数据结构(ReentrantLock的语境下)
+
+- 同步状态变量
+
+```
+/**
+ * The synchronization state.
+ */
+private volatile int state;
+```
+
+这是一个带volatile前缀的int值,是一个类似计数器的东西。在不同的同步组件中有不同的含义。以ReentrantLock为例,state可以用来表示该锁被线程重入的次数。当state为0表示该锁不被任何线程持有;当state为1表示线程恰好持有该锁1次(未重入);当state大于1则表示锁被线程重入state次。因为这是一个会被并发访问的量,为了防止出现可见性问题要用volatile进行修饰。
+
+- 持有同步状态的线程标志
+
+```
+/**
+ * The current owner of exclusive mode synchronization.
+ */
+private transient Thread exclusiveOwnerThread;
+```
+
+如注释所言,这是在独占同步模式下标记持有同步状态线程的。ReentrantLock就是典型的独占同步模式,该变量用来标识锁被哪个线程持有。
+
+------
+
+了解AQS的主要结构后,就可以开始进行ReentrantLock的源码解读了。由于非公平锁在实际开发中用的比较多,故以讲解非公平锁的源码为主。以下面这段对非公平锁使用的代码为例:
+
+```
+/**
+ * @author: takumiCX
+ * @create: 2018-08-01
+ **/
+public class NoFairLockTest {
+
+
+ public static void main(String[] args) {
+
+ //创建非公平锁
+ ReentrantLock lock = new ReentrantLock(false);
+
+ try {
+
+ //加锁
+ lock.lock();
+
+ //模拟业务处理用时
+ TimeUnit.SECONDS.sleep(1);
+
+ } catch (InterruptedException e) {
+ e.printStackTrace();
+
+ } finally {
+ //释放锁
+ lock.unlock();
+ }
+
+ }
+}
+```
+
+## 3 非公平模式加锁流程
+
+加锁流程从`lock.lock()`开始
+
+```
+public void lock() {
+ sync.lock();
+}
+```
+
+进入该源码,正确找到sycn的实现类后可以看到真正有内容的入口方法
+
+### 3.1加锁流程真正意义上的入口
+
+```
+/**
+ * Performs lock. Try immediate barge, backing up to normal
+ * acquire on failure.
+ */
+//加锁流程真正意义上的入口
+final void lock() {
+ //以cas方式尝试将AQS中的state从0更新为1
+ if (compareAndSetState(0, 1))
+ setExclusiveOwnerThread(Thread.currentThread());//获取锁成功则将当前线程标记为持有锁的线程,然后直接返回
+ else
+ acquire(1);//获取锁失败则执行该方法
+}
+```
+
+首先尝试快速获取锁,以cas的方式将state的值更新为1,只有当state的原值为0时更新才能成功,因为state在ReentrantLock的语境下等同于锁被线程重入的次数,这意味着只有当前锁未被任何线程持有时该动作才会返回成功。若获取锁成功,则将当前线程标记为持有锁的线程,然后整个加锁流程就结束了。若获取锁失败,则执行acquire方法
+
+```
+/**
+ * Acquires in exclusive mode, ignoring interrupts. Implemented
+ * by invoking at least once {@link #tryAcquire},
+ * returning on success. Otherwise the thread is queued, possibly
+ * repeatedly blocking and unblocking, invoking {@link
+ * #tryAcquire} until success. This method can be used
+ * to implement method {@link Lock#lock}.
+ *
+ * @param arg the acquire argument. This value is conveyed to
+ * {@link #tryAcquire} but is otherwise uninterpreted and
+ * can represent anything you like.
+ */
+public final void acquire(int arg) {
+ if (!tryAcquire(arg) &&
+ acquireQueued(addWaiter(Node.EXCLUSIVE), arg))
+ selfInterrupt();
+}
+```
+
+该方法主要的逻辑都在if判断条件中,这里面有3个重要的方法tryAcquire(),addWaiter()和acquireQueued(),这三个方法中分别封装了加锁流程中的主要处理逻辑,理解了这三个方法到底做了哪些事情,整个加锁流程就清晰了。
+
+### 3.2 尝试获取锁的通用方法:tryAcquire()
+
+tryAcquire是AQS中定义的钩子方法,如下所示
+
+```
+protected boolean tryAcquire(int arg) {
+ throw new UnsupportedOperationException();
+}
+```
+
+该方法默认会抛出异常,强制同步组件通过扩展AQS来实现同步功能的时候必须重写该方法,ReentrantLock在公平和非公平模式下对此有不同实现,非公平模式的实现如下:
+
+```
+protected final boolean tryAcquire(int acquires) {
+ return nonfairTryAcquire(acquires);
+}
+```
+
+底层调用了nonfairTryAcquire()
+从方法名上我们就可以知道这是非公平模式下尝试获取锁的方法,具体方法实现如下
+
+```
+/**
+ * Performs non-fair tryLock. tryAcquire is implemented in
+ * subclasses, but both need nonfair try for trylock method.
+ */
+final boolean nonfairTryAcquire(int acquires) {
+ final Thread current = Thread.currentThread();//获取当前线程实例
+ int c = getState();//获取state变量的值,即当前锁被重入的次数
+ if (c == 0) { //state为0,说明当前锁未被任何线程持有
+ if (compareAndSetState(0, acquires)) { //以cas方式获取锁
+ setExclusiveOwnerThread(current); //将当前线程标记为持有锁的线程
+ return true;//获取锁成功,非重入
+ }
+ }
+ else if (current == getExclusiveOwnerThread()) { //当前线程就是持有锁的线程,说明该锁被重入了
+ int nextc = c + acquires;//计算state变量要更新的值
+ if (nextc < 0) // overflow
+ throw new Error("Maximum lock count exceeded");
+ setState(nextc);//非同步方式更新state值
+ return true; //获取锁成功,重入
+ }
+ return false; //走到这里说明尝试获取锁失败
+}
+```
+
+这是非公平模式下获取锁的通用方法。它囊括了当前线程在尝试获取锁时的所有可能情况:
+
+- 1.当前锁未被任何线程持有(state=0),则以cas方式获取锁,若获取成功则设置exclusiveOwnerThread为当前线程,然后返回成功的结果;若cas失败,说明在得到state=0和cas获取锁之间有其他线程已经获取了锁,返回失败结果。
+- 2.若锁已经被当前线程获取(state>0,exclusiveOwnerThread为当前线程),则将锁的重入次数加1(state+1),然后返回成功结果。因为该线程之前已经获得了锁,所以这个累加操作不用同步。
+- 3.若当前锁已经被其他线程持有(state>0,exclusiveOwnerThread不为当前线程),则直接返回失败结果
+
+因为我们用state来统计锁被线程重入的次数,所以当前线程尝试获取锁的操作是否成功可以简化为:state值是否成功累加1,是则尝试获取锁成功,否则尝试获取锁失败。
+
+其实这里还可以思考一个问题:nonfairTryAcquire已经实现了一个囊括所有可能情况的尝试获取锁的方式,为何在刚进入lock方法时还要通过compareAndSetState(0, 1)去获取锁,毕竟后者只有在锁未被任何线程持有时才能执行成功,我们完全可以把compareAndSetState(0, 1)去掉,对最后的结果不会有任何影响。这种在进行通用逻辑处理之前针对某些特殊情况提前进行处理的方式在后面还会看到,一个直观的想法就是它能提升性能,而代价是牺牲一定的代码简洁性。
+
+退回到上层的acquire方法,
+
+```
+public final void acquire(int arg) {
+ if (!tryAcquire(arg) && //当前线程尝试获取锁,若获取成功返回true,否则false
+ acquireQueued(addWaiter(Node.EXCLUSIVE), arg)) //只有当前线程获取锁失败才会执行者这部分代码
+ selfInterrupt();
+}
+```
+
+tryAcquire(arg)返回成功,则说明当前线程成功获取了锁(第一次获取或者重入),由取反和&&可知,整个流程到这结束,只有当前线程获取锁失败才会执行后面的判断。先来看addWaiter(Node.EXCLUSIVE)
+部分,这部分代码描述了当线程获取锁失败时如何安全的加入同步等待队列。这部分代码可以说是整个加锁流程源码的精华,充分体现了并发编程的艺术性。
+
+### 3.3 获取锁失败的线程如何安全的加入同步队列:addWaiter()
+
+这部分逻辑在addWaiter()方法中
+
+```
+/**
+ * Creates and enqueues node for current thread and given mode.
+ *
+ * @param mode Node.EXCLUSIVE for exclusive, Node.SHARED for shared
+ * @return the new node
+ */
+private Node addWaiter(Node mode) {
+ Node node = new Node(Thread.currentThread(), mode);//首先创建一个新节点,并将当前线程实例封装在内部,mode这里为null
+ // Try the fast path of enq; backup to full enq on failure
+ Node pred = tail;
+ if (pred != null) {
+ node.prev = pred;
+ if (compareAndSetTail(pred, node)) {
+ pred.next = node;
+ return node;
+ }
+ }
+ enq(node);//入队的逻辑这里都有
+ return node;
+}
+```
+
+首先创建了一个新节点,并将当前线程实例封装在其内部,之后我们直接看enq(node)方法就可以了,中间这部分逻辑在enq(node)中都有,之所以加上这部分“重复代码”和尝试获取锁时的“重复代码”一样,对某些特殊情况
+进行提前处理,牺牲一定的代码可读性换取性能提升。
+
+```
+/**
+ * Inserts node into queue, initializing if necessary. See picture above.
+ * @param node the node to insert
+ * @return node's predecessor
+ */
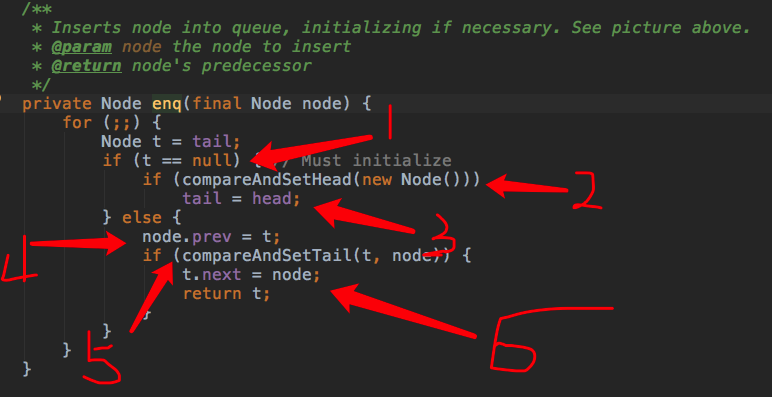
+private Node enq(final Node node) {
+ for (;;) {
+ Node t = tail;//t指向当前队列的最后一个节点,队列为空则为null
+ if (t == null) { // Must initialize //队列为空
+ if (compareAndSetHead(new Node())) //构造新结点,CAS方式设置为队列首元素,当head==null时更新成功
+ tail = head;//尾指针指向首结点
+ } else { //队列不为空
+ node.prev = t;
+ if (compareAndSetTail(t, node)) { //CAS将尾指针指向当前结点,当t(原来的尾指针)==tail(当前真实的尾指针)时执行成功
+ t.next = node; //原尾结点的next指针指向当前结点
+ return t;
+ }
+ }
+ }
+}
+```
+
+这里有两个CAS操作:
+
+- compareAndSetHead(new Node()),CAS方式更新head指针,仅当原值为null时更新成功
+
+```
+/**
+ * CAS head field. Used only by enq.
+ */
+private final boolean compareAndSetHead(Node update) {
+ return unsafe.compareAndSwapObject(this, headOffset, null, update);
+}
+```
+
+- compareAndSetTail(t, node),CAS方式更新tial指针,仅当原值为t时更新成功
+
+```
+/**
+ * CAS tail field. Used only by enq.
+ */
+private final boolean compareAndSetTail(Node expect, Node update) {
+ return unsafe.compareAndSwapObject(this, tailOffset, expect, update);
+}
+```
+
+外层的for循环保证了所有获取锁失败的线程经过失败重试后最后都能加入同步队列。因为AQS的同步队列是不带哨兵结点的,故当队列为空时要进行特殊处理,这部分在if分句中。注意当前线程所在的结点不能直接插入
+空队列,因为阻塞的线程是由前驱结点进行唤醒的。故先要插入一个结点作为队列首元素,当锁释放时由它来唤醒后面被阻塞的线程,从逻辑上这个队列首元素也可以表示当前正获取锁的线程,虽然并不一定真实持有其线程实例。
+
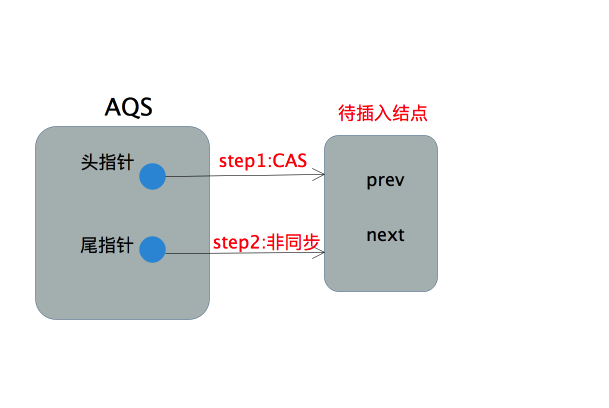
+首先通过new Node()创建一个空结点,然后以CAS方式让头指针指向该结点(该结点并非当前线程所在的结点),若该操作成功,则将尾指针也指向该结点。这部分的操作流程可以用下图表示
+
+
+当队列不为空,则执行通用的入队逻辑,这部分在else分句中
+
+```
+else {
+ node.prev = t;//step1:待插入结点pre指针指向原尾结点
+ if (compareAndSetTail(t, node)) { step2:CAS方式更改尾指针
+ t.next = node; //原尾结点next指针指向新的结点
+ return t;
+ }
+ }
+```
+
+首先当前线程所在的结点的前向指针pre指向当前线程认为的尾结点,源码中用t表示。然后以CAS的方式将尾指针指向当前结点,该操作仅当tail=t,即尾指针在进行CAS前未改变时成功。若CAS执行成功,则将原尾结点的后向指针next指向新的尾结点。整个过程如下图所示
+
+
+
+整个入队的过程并不复杂,是典型的CAS加失败重试的乐观锁策略。其中只有更新头指针和更新尾指针这两步进行了CAS同步,可以预见高并发场景下性能是非常好的。但是本着质疑精神我们不禁会思考下这么做真的线程安全吗?
+
+
+- 1.队列为空的情况:
+ 因为队列为空,故head=tail=null,假设线程执行2成功,则在其执行3之前,因为tail=null,其他进入该方法的线程因为head不为null将在2处不停的失败,所以3即使没有同步也不会有线程安全问题。
+- 2.队列不为空的情况:
+ 假设线程执行5成功,则此时4的操作必然也是正确的(当前结点的prev指针确实指向了队列尾结点,换句话说tail指针没有改变,如若不然5必然执行失败),又因为4执行成功,当前节点在队列中的次序已经确定了,所以6何时执行对线程安全不会有任何影响,比如下面这种情况
+
+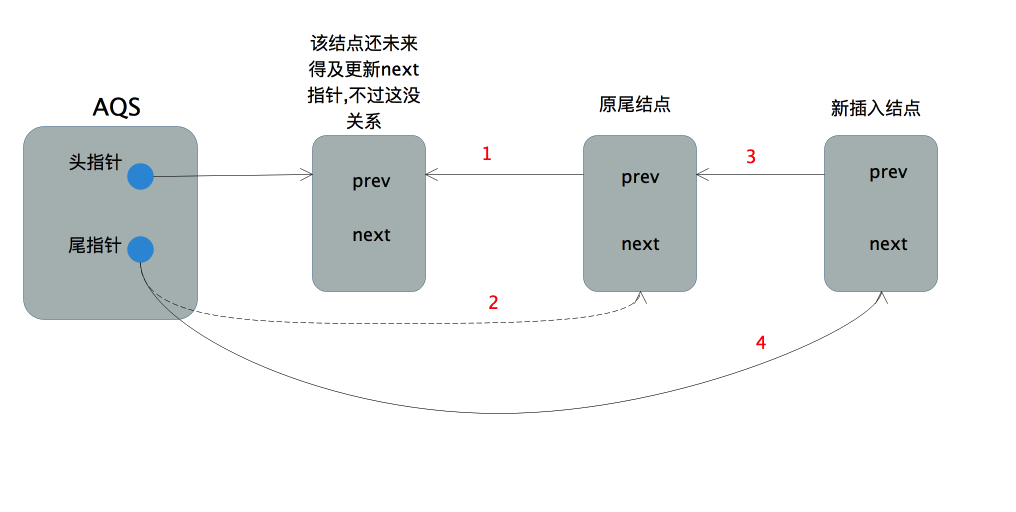
+
+为了确保真的理解了它,可以思考这个问题:把enq方法图中的4放到5之后,整个入队的过程还线程安全吗?
+
+到这为止,获取锁失败的线程加入同步队列的逻辑就结束了。但是线程加入同步队列后会做什么我们并不清楚,这部分在acquireQueued方法中
+
+### 3.4 线程加入同步队列后会做什么:acquireQueued()
+
+先看acquireQueued方法的源码
+
+```
+/**
+ * Acquires in exclusive uninterruptible mode for thread already in
+ * queue. Used by condition wait methods as well as acquire.
+ *
+ * @param node the node
+ * @param arg the acquire argument
+ * @return {@code true} if interrupted while waiting
+ */
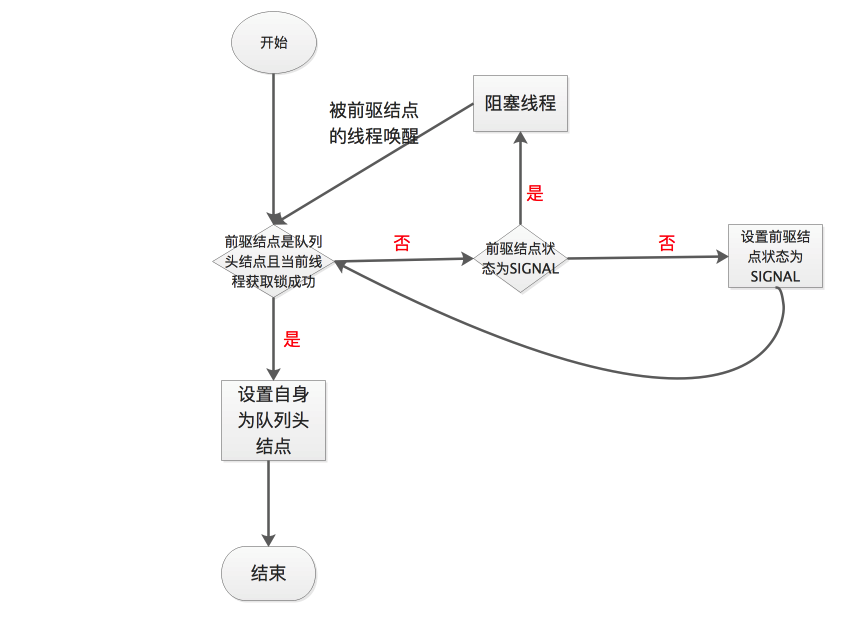
+final boolean acquireQueued(final Node node, int arg) {
+ boolean failed = true;
+ try {
+ boolean interrupted = false;
+ //死循环,正常情况下线程只有获得锁才能跳出循环
+ for (;;) {
+ final Node p = node.predecessor();//获得当前线程所在结点的前驱结点
+ //第一个if分句
+ if (p == head && tryAcquire(arg)) {
+ setHead(node); //将当前结点设置为队列头结点
+ p.next = null; // help GC
+ failed = false;
+ return interrupted;//正常情况下死循环唯一的出口
+ }
+ //第二个if分句
+ if (shouldParkAfterFailedAcquire(p, node) && //判断是否要阻塞当前线程
+ parkAndCheckInterrupt()) //阻塞当前线程
+ interrupted = true;
+ }
+ } finally {
+ if (failed)
+ cancelAcquire(node);
+ }
+}
+```
+
+这段代码主要的内容都在for循环中,这是一个死循环,主要有两个if分句构成。第一个if分句中,当前线程首先会判断前驱结点是否是头结点,如果是则尝试获取锁,获取锁成功则会设置当前结点为头结点(更新头指针)。为什么必须前驱结点为头结点才尝试去获取锁?因为头结点表示当前正占有锁的线程,正常情况下该线程释放锁后会通知后面结点中阻塞的线程,阻塞线程被唤醒后去获取锁,这是我们希望看到的。然而还有一种情况,就是前驱结点取消了等待,此时当前线程也会被唤醒,这时候就不应该去获取锁,而是往前回溯一直找到一个没有取消等待的结点,然后将自身连接在它后面。一旦我们成功获取了锁并成功将自身设置为头结点,就会跳出for循环。否则就会执行第二个if分句:确保前驱结点的状态为SIGNAL,然后阻塞当前线程。
+
+先来看shouldParkAfterFailedAcquire(p, node),从方法名上我们可以大概猜出这是判断是否要阻塞当前线程的,方法内容如下
+
+```
+/**
+ * Checks and updates status for a node that failed to acquire.
+ * Returns true if thread should block. This is the main signal
+ * control in all acquire loops. Requires that pred == node.prev.
+ *
+ * @param pred node's predecessor holding status
+ * @param node the node
+ * @return {@code true} if thread should block
+ */
+private static boolean shouldParkAfterFailedAcquire(Node pred, Node node) {
+ int ws = pred.waitStatus;
+ if (ws == Node.SIGNAL) //状态为SIGNAL
+
+ /*
+ * This node has already set status asking a release
+ * to signal it, so it can safely park.
+ */
+ return true;
+ if (ws > 0) { //状态为CANCELLED,
+ /*
+ * Predecessor was cancelled. Skip over predecessors and
+ * indicate retry.
+ */
+ do {
+ node.prev = pred = pred.prev;
+ } while (pred.waitStatus > 0);
+ pred.next = node;
+ } else { //状态为初始化状态(ReentrentLock语境下)
+ /*
+ * waitStatus must be 0 or PROPAGATE. Indicate that we
+ * need a signal, but don't park yet. Caller will need to
+ * retry to make sure it cannot acquire before parking.
+ */
+ compareAndSetWaitStatus(pred, ws, Node.SIGNAL);
+ }
+ return false;
+}
+```
+
+可以看到针对前驱结点pred的状态会进行不同的处理
+
+- 1.pred状态为SIGNAL,则返回true,表示要阻塞当前线程。
+- 2.pred状态为CANCELLED,则一直往队列头部回溯直到找到一个状态不为CANCELLED的结点,将当前节点node挂在这个结点的后面。
+- 3.pred的状态为初始化状态,此时通过compareAndSetWaitStatus(pred, ws, Node.SIGNAL)方法将pred的状态改为SIGNAL。
+
+其实这个方法的含义很简单,就是确保当前结点的前驱结点的状态为SIGNAL,SIGNAL意味着线程释放锁后会唤醒后面阻塞的线程。毕竟,只有确保能够被唤醒,当前线程才能放心的阻塞。
+
+但是要注意只有在前驱结点已经是SIGNAL状态后才会执行后面的方法立即阻塞,对应上面的第一种情况。其他两种情况则因为返回false而重新执行一遍
+for循环。这种延迟阻塞其实也是一种高并发场景下的优化,试想我如果在重新执行循环的时候成功获取了锁,是不是线程阻塞唤醒的开销就省了呢?
+
+最后我们来看看阻塞线程的方法parkAndCheckInterrupt
+
+shouldParkAfterFailedAcquire返回true表示应该阻塞当前线程,则会执行parkAndCheckInterrupt方法,这个方法比较简单,底层调用了LockSupport来阻塞当前线程,源码如下:
+
+```
+/**
+ * Convenience method to park and then check if interrupted
+ *
+ * @return {@code true} if interrupted
+ */
+private final boolean parkAndCheckInterrupt() {
+ LockSupport.park(this);
+ return Thread.interrupted();
+}
+```
+
+该方法内部通过调用LockSupport的park方法来阻塞当前线程,不清楚LockSupport的可以看看这里。[LockSupport功能简介及原理浅析](https://www.cnblogs.com/takumicx/p/9328459.html)
+
+下面通过一张流程图来说明线程从加入同步队列到成功获取锁的过程
+
+
+概括的说,线程在同步队列中会尝试获取锁,失败则被阻塞,被唤醒后会不停的重复这个过程,直到线程真正持有了锁,并将自身结点置于队列头部。
+
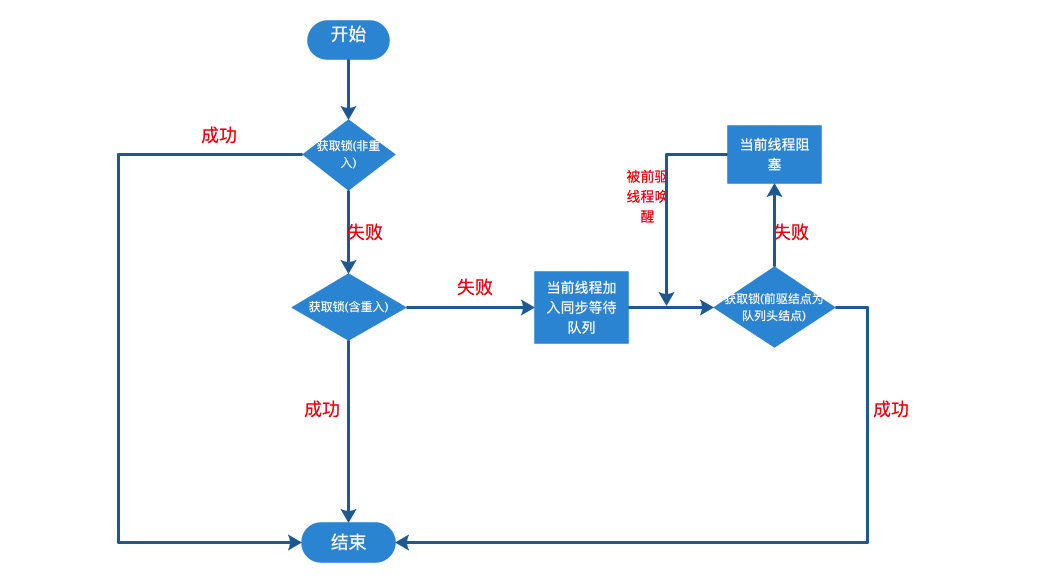
+### 3.5 加锁流程源码总结
+
+ReentrantLock非公平模式下的加锁流程如下
+
+
+## 4.非公平模式解锁流程
+
+### 4.1 解锁流程源码解读
+
+解锁的源码相对简单,源码如下:
+
+```
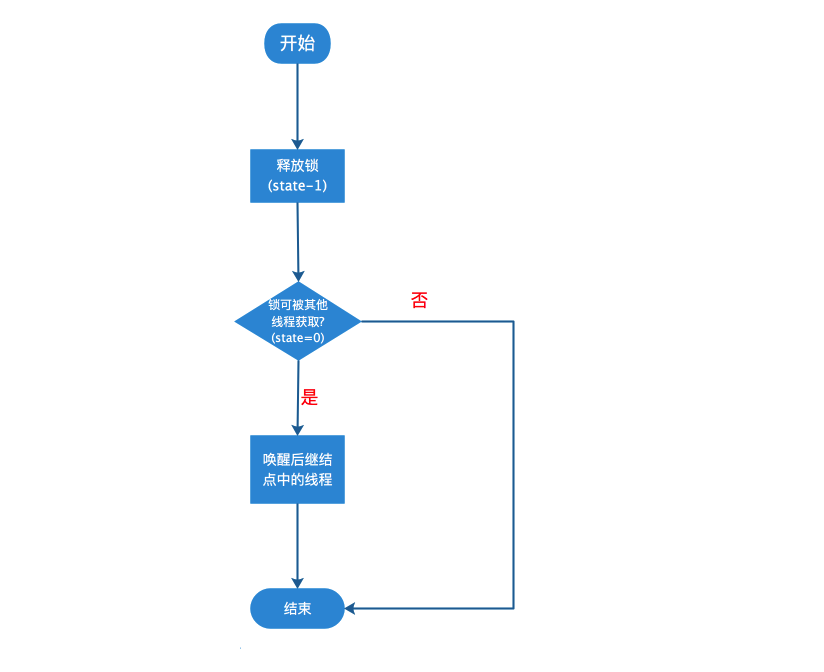
+public void unlock() {
+ sync.release(1);
+}
+public final boolean release(int arg) {
+ if (tryRelease(arg)) { //释放锁(state-1),若释放后锁可被其他线程获取(state=0),返回true
+ Node h = head;
+ //当前队列不为空且头结点状态不为初始化状态(0)
+ if (h != null && h.waitStatus != 0)
+ unparkSuccessor(h); //唤醒同步队列中被阻塞的线程
+ return true;
+ }
+ return false;
+}
+```
+
+正确找到sync的实现类,找到真正的入口方法,主要内容都在一个if语句中,先看下判断条件tryRelease方法
+
+```
+protected final boolean tryRelease(int releases) {
+ int c = getState() - releases; //计算待更新的state值
+ if (Thread.currentThread() != getExclusiveOwnerThread())
+ throw new IllegalMonitorStateException();
+ boolean free = false;
+ if (c == 0) { //待更新的state值为0,说明持有锁的线程未重入,一旦释放锁其他线程将能获取
+ free = true;
+ setExclusiveOwnerThread(null);//清除锁的持有线程标记
+ }
+ setState(c);//更新state值
+ return free;
+}
+```
+
+tryRelease其实只是将线程持有锁的次数减1,即将state值减1,若减少后线程将完全释放锁(state值为0),则该方法将返回true,否则返回false。由于执行该方法的线程必然持有锁,故该方法不需要任何同步操作。
+若当前线程已经完全释放锁,即锁可被其他线程使用,则还应该唤醒后续等待线程。不过在此之前需要进行两个条件的判断:
+
+- h!=null是为了防止队列为空,即没有任何线程处于等待队列中,那么也就不需要进行唤醒的操作
+- h.waitStatus != 0是为了防止队列中虽有线程,但该线程还未阻塞,由前面的分析知,线程在阻塞自己前必须设置前驱结点的状态为SIGNAL,否则它不会阻塞自己。
+
+接下来就是唤醒线程的操作,unparkSuccessor(h)源码如下
+
+```
+private void unparkSuccessor(Node node) {
+ /*
+ * If status is negative (i.e., possibly needing signal) try
+ * to clear in anticipation of signalling. It is OK if this
+ * fails or if status is changed by waiting thread.
+ */
+ int ws = node.waitStatus;
+ if (ws < 0)
+ compareAndSetWaitStatus(node, ws, 0);
+
+ /*
+ * Thread to unpark is held in successor, which is normally
+ * just the next node. But if cancelled or apparently null,
+ * traverse backwards from tail to find the actual
+ * non-cancelled successor.
+ */
+ Node s = node.next;
+ if (s == null || s.waitStatus > 0) {
+ s = null;
+ for (Node t = tail; t != null && t != node; t = t.prev)
+ if (t.waitStatus <= 0)
+ s = t;
+ }
+ if (s != null)
+ LockSupport.unpark(s.thread);
+}
+```
+
+一般情况下只要唤醒后继结点的线程就行了,但是后继结点可能已经取消等待,所以从队列尾部往前回溯,找到离头结点最近的正常结点,并唤醒其线程。
+
+### 4.2 解锁流程源码总结
+
+
+
+## 5. 公平锁相比非公平锁的不同
+
+公平锁模式下,对锁的获取有严格的条件限制。在同步队列有线程等待的情况下,所有线程在获取锁前必须先加入同步队列。队列中的线程按加入队列的先后次序获得锁。
+从公平锁加锁的入口开始,
+
+
+对比非公平锁,少了非重入式获取锁的方法,这是第一个不同点
+
+接着看获取锁的通用方法tryAcquire(),该方法在线程未进入队列,加入队列阻塞前和阻塞后被唤醒时都会执行。
+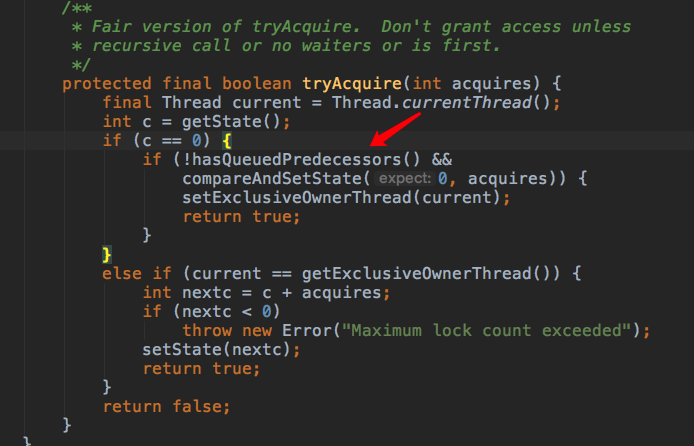
+
+在真正CAS获取锁之前加了判断,内容如下
+
+```
+public final boolean hasQueuedPredecessors() {
+ // The correctness of this depends on head being initialized
+ // before tail and on head.next being accurate if the current
+ // thread is first in queue.
+ Node t = tail; // Read fields in reverse initialization order
+ Node h = head;
+ Node s;
+ return h != t &&
+ ((s = h.next) == null || s.thread != Thread.currentThread());
+}
+```
+
+从方法名我们就可知道这是判断队列中是否有优先级更高的等待线程,队列中哪个线程优先级最高?由于头结点是当前获取锁的线程,队列中的第二个结点代表的线程优先级最高。
+那么我们只要判断队列中第二个结点是否存在以及这个结点是否代表当前线程就行了。这里分了两种情况进行探讨:
+
+1. 第二个结点已经完全插入,但是这个结点是否就是当前线程所在结点还未知,所以通过s.thread != Thread.currentThread()进行判断,如果为true,说明第二个结点代表其他线程。
+2. 第二个结点并未完全插入,我们知道结点入队一共分三步:
+
+- 1.待插入结点的pre指针指向原尾结点
+- 2.CAS更新尾指针
+- 3.原尾结点的next指针指向新插入结点
+
+所以(s = h.next) == null 就是用来判断2刚执行成功但还未执行3这种情况的。这种情况第二个结点必然属于其他线程。
+以上两种情况都会使该方法返回true,即当前有优先级更高的线程在队列中等待,那么当前线程将不会执行CAS操作去获取锁,保证了线程获取锁的顺序与加入同步队列的顺序一致,很好的保证了公平性,但也增加了获取锁的成本。
+
+## 6. 一些疑问的解答
+
+### 6.1 为什么基于FIFO的同步队列可以实现非公平锁?
+
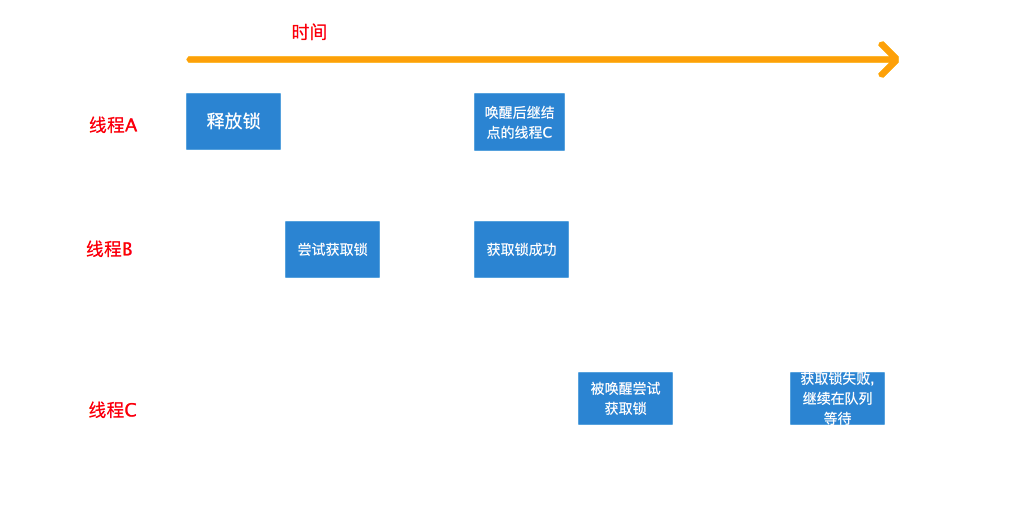
+由FIFO队列的特性知,先加入同步队列等待的线程会比后加入的线程更靠近队列的头部,那么它将比后者更早的被唤醒,它也就能更早的得到锁。从这个意义上,对于在同步队列中等待的线程而言,它们获得锁的顺序和加入同步队列的顺序一致,这显然是一种公平模式。然而,线程并非只有在加入队列后才有机会获得锁,哪怕同步队列中已有线程在等待,非公平锁的不公平之处就在于此。回看下非公平锁的加锁流程,线程在进入同步队列等待之前有两次抢占锁的机会:
+
+- 第一次是非重入式的获取锁,只有在当前锁未被任何线程占有(包括自身)时才能成功;
+- 第二次是在进入同步队列前,包含所有情况的获取锁的方式。
+
+只有这两次获取锁都失败后,线程才会构造结点并加入同步队列等待。而线程释放锁时是先释放锁(修改state值),然后才唤醒后继结点的线程的。试想下这种情况,线程A已经释放锁,但还没来得及唤醒后继线程C,而这时另一个线程B刚好尝试获取锁,此时锁恰好不被任何线程持有,它将成功获取锁而不用加入队列等待。线程C被唤醒尝试获取锁,而此时锁已经被线程B抢占,故而其获取失败并继续在队列中等待。整个过程如下图所示
+
+
+如果以线程第一次尝试获取锁到最后成功获取锁的次序来看,非公平锁确实很不公平。因为在队列中等待很久的线程相比还未进入队列等待的线程并没有优先权,甚至竞争也处于劣势:在队列中的线程要等待其他线程唤醒,在获取锁之前还要检查前驱结点是否为头结点。在锁竞争激烈的情况下,在队列中等待的线程可能迟迟竞争不到锁。这也就非公平在高并发情况下会出现的饥饿问题。那我们再开发中为什么大多使用会导致饥饿的非公平锁?很简单,因为它性能好啊。
+
+### 6.2 为什么非公平锁性能好
+
+非公平锁对锁的竞争是抢占式的(队列中线程除外),线程在进入等待队列前可以进行两次尝试,这大大增加了获取锁的机会。这种好处体现在两个方面:
+
+- 1.线程不必加入等待队列就可以获得锁,不仅免去了构造结点并加入队列的繁琐操作,同时也节省了线程阻塞唤醒的开销,线程阻塞和唤醒涉及到线程上下文的切换和操作系统的系统调用,是非常耗时的。在高并发情况下,如果线程持有锁的时间非常短,短到线程入队阻塞的过程超过线程持有并释放锁的时间开销,那么这种抢占式特性对并发性能的提升会更加明显。
+- 2.减少CAS竞争。如果线程必须要加入阻塞队列才能获取锁,那入队时CAS竞争将变得异常激烈,CAS操作虽然不会导致失败线程挂起,但不断失败重试导致的对CPU的浪费也不能忽视。除此之外,加锁流程中至少有两处通过将某些特殊情况提前来减少CAS操作的竞争,增加并发情况下的性能。一处就是获取锁时将非重入的情况提前,如下图所示
+ 
+
+另一处就是入队的操作,将同步队列非空的情况提前处理
+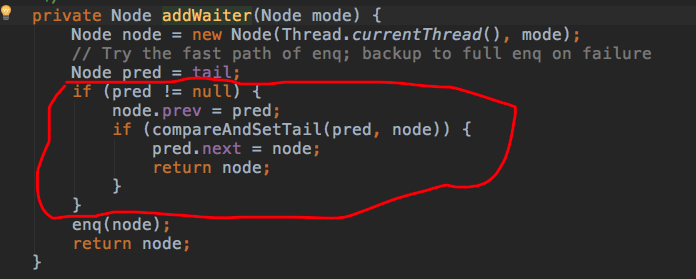
+
+这两部分的代码在之后的通用逻辑处理中都有,很显然属于重复代码,但因为避免了执行无意义的流程代码,比如for循环,获取同步状态等,高并发场景下也能减少CAS竞争失败的可能。
+
+## 7. 阅读源码的收获
+
+- 1.熟悉了ReentrantLock的内部构造以及加锁和解锁的流程,理解了非公平锁和公平锁实现的本质区别以及为何前者相比后者有更好的性能。以此为基础,我们可以更好的使用ReentrantLock。
+- 2.通过对部分实现细节的学习,了解了如何以CAS算法构建无锁的同步队列,我们可以借鉴并以此来构建自己的无锁的并发容器。
\ No newline at end of file
diff --git a/week_03/51/Semaphore_51.md b/week_03/51/Semaphore_51.md
new file mode 100644
index 0000000..90babfe
--- /dev/null
+++ b/week_03/51/Semaphore_51.md
@@ -0,0 +1,250 @@
+## 类介绍
+
+Semaphore(信号量)是用来控制同时访问特定资源的线程数量,它通过协调各个线程,以保证合理的使用公共资源。比如控制用户的访问量,同一时刻只允许1000个用户同时使用系统,如果超过1000个并发,则需要等待。
+
+## 使用场景
+
+比如模拟一个停车场停车信号,假设停车场只有两个车位,一开始两个车位都是空的。这时如果同时来了两辆车,看门人允许它们进入停车场,然后放下车拦。以后来的车必须在入口等待,直到停车场中有车辆离开。这时,如果有一辆车离开停车场,看门人得知后,打开车拦,放入一辆,如果又离开一辆,则又可以放入一辆,如此往复。
+
+
+
+```java
+public class SemaphoreDemo {
+ private static Semaphore s = new Semaphore(2);
+ public static void main(String[] args) {
+ ExecutorService pool = Executors.newCachedThreadPool();
+ pool.submit(new ParkTask("1"));
+ pool.submit(new ParkTask("2"));
+ pool.submit(new ParkTask("3"));
+ pool.submit(new ParkTask("4"));
+ pool.submit(new ParkTask("5"));
+ pool.submit(new ParkTask("6"));
+ pool.shutdown();
+ }
+
+ static class ParkTask implements Runnable {
+ private String name;
+ public ParkTask(String name) {
+ this.name = name;
+ }
+ @Override
+ public void run() {
+ try {
+ s.acquire();
+ System.out.println("Thread "+this.name+" start...");
+ TimeUnit.SECONDS.sleep(new Random().nextInt(10));
+ } catch (InterruptedException e) {
+ e.printStackTrace();
+ } finally {
+ s.release();
+ }
+ }
+ }
+}
+```
+
+## Semaphore 源码分析
+
+Semaphore 通过使用内部类Sync继承AQS来实现。
+ 支持公平锁和非公平锁。内部使用的AQS的共享锁。
+ 具体实现可参考 [AbstractQueuedSynchronizer 源码分析](https://www.jianshu.com/p/dbe18cea28e7)
+
+Semaphore 的结构如下:
+
+
+
+
+
+Semaphore 类结构
+
+#### Semaphore构造
+
+
+
+```java
+public Semaphore(int permits) {
+ sync = new NonfairSync(permits);
+}
+
+public Semaphore(int permits, boolean fair) {
+ sync = fair ? new FairSync(permits) : new NonfairSync(permits);
+}
+```
+
+构造方法指定信号量的许可数量,默认采用的是非公平锁,也只可以指定为公平锁。
+ permits赋值给AQS中的state变量。
+
+#### acquire:可响应中断的获得信号量
+
+
+
+```java
+public void acquire() throws InterruptedException {
+ sync.acquireSharedInterruptibly(1);
+}
+
+public void acquire(int permits) throws InterruptedException {
+ if (permits < 0) throw new IllegalArgumentException();
+ sync.acquireSharedInterruptibly(permits);
+}
+```
+
+获得信号量方法,这两个方法支持 Interrupt中断机制,可使用acquire() 方法每次获取一个信号量,也可以使用acquire(int permits) 方法获取指定数量的信号量 。
+
+#### acquire:不可响应中断的获取信号量
+
+
+
+```java
+public void acquireUninterruptibly() {
+ sync.acquireShared(1);
+}
+
+public void acquireUninterruptibly(int permits) {
+ if (permits < 0) throw new IllegalArgumentException();
+ sync.acquireShared(permits);
+}
+```
+
+这两个方法不响应Interrupt中断机制,其它功能同acquire方法机制。
+
+#### tryAcquire 方法,尝试获得信号量
+
+
+
+```java
+public boolean tryAcquire() {
+ return sync.nonfairTryAcquireShared(1) >= 0;
+}
+
+public boolean tryAcquire(long timeout, TimeUnit unit)
+ throws InterruptedException {
+ return sync.tryAcquireSharedNanos(1, unit.toNanos(timeout));
+}
+
+public boolean tryAcquire(int permits, long timeout, TimeUnit unit)
+ throws InterruptedException {
+ if (permits < 0) throw new IllegalArgumentException();
+ return sync.tryAcquireSharedNanos(permits, unit.toNanos(timeout));
+}
+```
+
+尝试获得信号量有三个方法。
+
+1. 尝试获取信号量,如果获取成功则返回true,否则马上返回false,不会阻塞当前线程。
+2. 尝试获取信号量,如果在指定的时间内获得信号量,则返回true,否则返回false
+3. 尝试获取指定数量的信号量,如果在指定的时间内获得信号量,则返回true,否则返回false。
+
+#### release 释放信号量
+
+
+
+```java
+public void release() {
+ sync.releaseShared(1);
+}
+```
+
+调用AQS中的releaseShared方法,使得state每次减一来控制信号量。
+
+#### availablePermits方法,获取当前剩余的信号量数量
+
+
+
+```java
+public int availablePermits() {
+ return sync.getPermits();
+}
+
+//=========Sync类========
+final int getPermits() {
+ return getState();
+ }
+```
+
+该方法返回AQS中state变量的值,当前剩余的信号量个数
+
+#### drainPermits方法
+
+
+
+```java
+public int drainPermits() {
+ return sync.drainPermits();
+}
+
+//=========Sync类========
+final int drainPermits() {
+ for (;;) {
+ int current = getState();
+ if (current == 0 || compareAndSetState(current, 0))
+ return current;
+ }
+}
+```
+
+获取并返回立即可用的所有许可。Sync类的drainPermits方法,获取1个信号量后将可用的信号量个数置为0。例如总共有10个信号量,已经使用了5个,再调用drainPermits方法后,可以获得一个信号量,剩余4个信号量就消失了,总共可用的信号量就变成6个了。
+
+#### reducePermits 方法
+
+
+
+```java
+protected void reducePermits(int reduction) {
+ if (reduction < 0) throw new IllegalArgumentException();
+ sync.reducePermits(reduction);
+}
+
+//=========Sync类========
+final void reducePermits(int reductions) {
+ for (;;) {
+ int current = getState();
+ int next = current - reductions;
+ if (next > current) // underflow
+ throw new Error("Permit count underflow");
+ if (compareAndSetState(current, next))
+ return;
+ }
+}
+```
+
+该方法是protected 方法,减少信号量个数
+
+#### 判断AQS等待队列中是否还有Node
+
+
+
+```java
+public final boolean hasQueuedThreads() {
+ return sync.hasQueuedThreads();
+}
+
+//=========AbstractQueuedSynchronizer类========
+public final boolean hasQueuedThreads() {
+ //头结点不等于尾节点就说明链表中还有元素
+ return head != tail;
+}
+```
+
+#### getQueuedThreads方法
+
+
+
+```java
+protected Collection