




 |
|  |
| **第1章:理解大型语言模型** | 无代码 | - | | |
| **第2章:处理文本数据** | - [ch02.ipynb](ch02/01_main-chapter-code/ch02.ipynb) | |
| **第3章:编码注意力机制** | - [ch03.ipynb](ch03/01_main-chapter-code/ch03.ipynb) | |
| **第4章:从零开始实现 GPT 模型** | - [ch04.ipynb](ch04/01_main-chapter-code/ch04.ipynb) | |
| **第5章:在无标注数据上进行预训练** | - [ch05.ipynb](ch05/01_main-chapter-code/ch05.ipynb) |
|
| **第1章:理解大型语言模型** | 无代码 | - | | |
| **第2章:处理文本数据** | - [ch02.ipynb](ch02/01_main-chapter-code/ch02.ipynb) | |
| **第3章:编码注意力机制** | - [ch03.ipynb](ch03/01_main-chapter-code/ch03.ipynb) | |
| **第4章:从零开始实现 GPT 模型** | - [ch04.ipynb](ch04/01_main-chapter-code/ch04.ipynb) | |
| **第5章:在无标注数据上进行预训练** | - [ch05.ipynb](ch05/01_main-chapter-code/ch05.ipynb) |  |
| **第6章:进行文本分类的微调** | - [ch06.ipynb](ch06/01_main-chapter-code/ch06.ipynb) |
|
| **第6章:进行文本分类的微调** | - [ch06.ipynb](ch06/01_main-chapter-code/ch06.ipynb) |  |
| **第7章:进行遵循指令的微调** | - [ch07.ipynb](ch07/01_main-chapter-code/ch07.ipynb) | |
| **附录 A:PyTorch 简介** | - [code-part1.ipynb](appendix-A/01_main-chapter-code/code-part1.ipynb) | |
| **附录 B:参考文献与进一步阅读** | 无代码 | - | | |
| **附录 C:习题解答** | 无代码 | - | | |
| **附录 D:在训练循环中加入附加功能** | - [appendix-D.ipynb](appendix-D/01_main-chapter-code/appendix-D.ipynb) | [appendix-D](./appendix-D) | | |
| **附录 E:使用 LoRA 进行参数高效微调** | - [appendix-E.ipynb](appendix-E/01_main-chapter-code/appendix-E.ipynb) | [appendix-E](./appendix-E) | | |
|
| **第7章:进行遵循指令的微调** | - [ch07.ipynb](ch07/01_main-chapter-code/ch07.ipynb) | |
| **附录 A:PyTorch 简介** | - [code-part1.ipynb](appendix-A/01_main-chapter-code/code-part1.ipynb) | |
| **附录 B:参考文献与进一步阅读** | 无代码 | - | | |
| **附录 C:习题解答** | 无代码 | - | | |
| **附录 D:在训练循环中加入附加功能** | - [appendix-D.ipynb](appendix-D/01_main-chapter-code/appendix-D.ipynb) | [appendix-D](./appendix-D) | | |
| **附录 E:使用 LoRA 进行参数高效微调** | - [appendix-E.ipynb](appendix-E/01_main-chapter-code/appendix-E.ipynb) | [appendix-E](./appendix-E) | | |
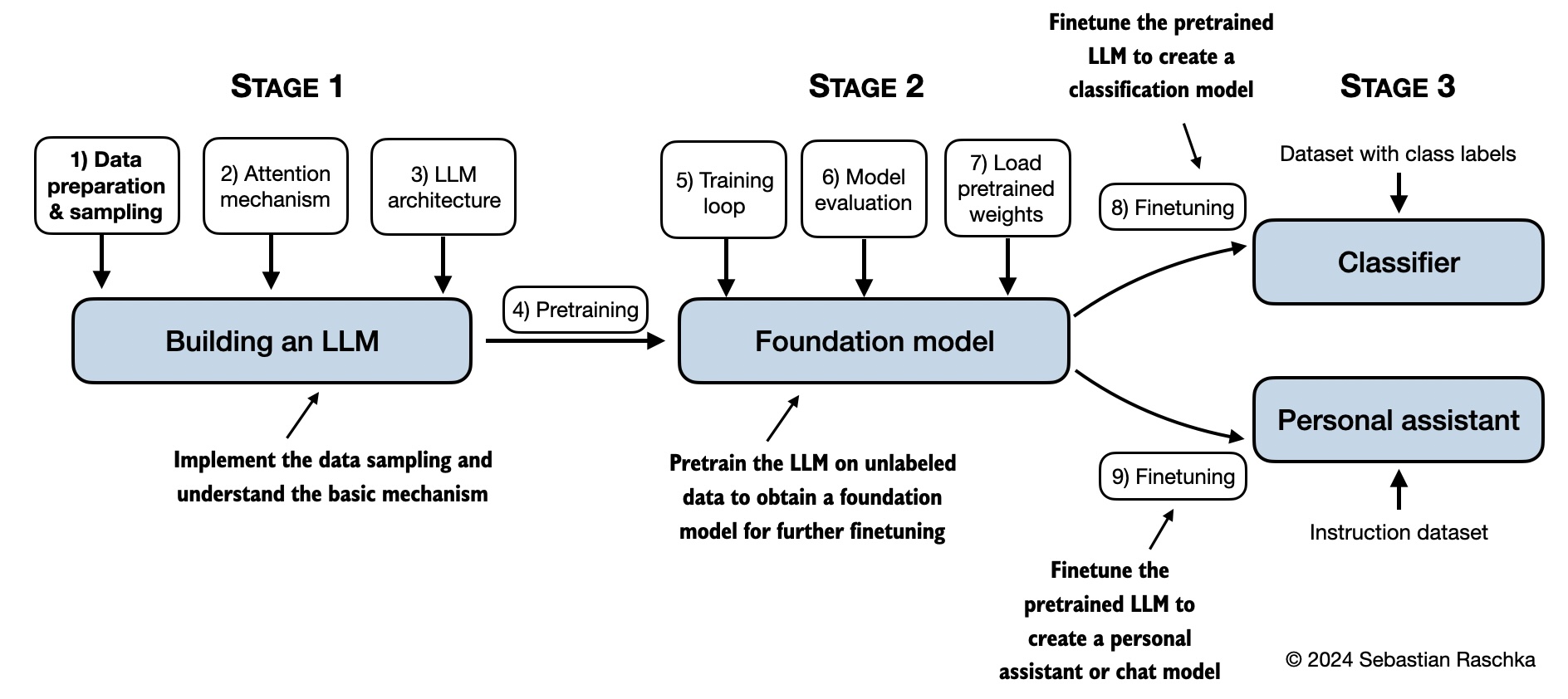 | |
| **第二章:处理文本数据** | - [从零开始实现字节对编码(BPE)分词器](ch02/05_bpe-from-scratch/bpe-from-scratch.ipynb) | |
| **第三章:编码注意力机制** | - [比较高效的多头注意力实现](ch03/02_bonus_efficient-multihead-attention/mha-implementations.ipynb) | |
| **第四章:从零开始实现 GPT 模型** | - [FLOPS 性能分析](ch04/02_performance-analysis/flops-analysis.ipynb) | | |
| **第五章:在未标注数据上进行预训练** | - [使用 Transformers 从 Hugging Face 模型库加载替代权重](ch05/02_alternative_weight_loading/weight-loading-hf-transformers.ipynb) | |
| **第六章:用于分类的微调** | - [微调不同层并使用更大模型的额外实验](ch06/02_bonus_additional-experiments) | |
| **第七章:微调以跟随指令** | - [查找近重复项和创建被动语态条目的数据集工具](ch07/02_dataset-utilities) | |
| |
| **第二章:处理文本数据** | - [从零开始实现字节对编码(BPE)分词器](ch02/05_bpe-from-scratch/bpe-from-scratch.ipynb) | |
| **第三章:编码注意力机制** | - [比较高效的多头注意力实现](ch03/02_bonus_efficient-multihead-attention/mha-implementations.ipynb) | |
| **第四章:从零开始实现 GPT 模型** | - [FLOPS 性能分析](ch04/02_performance-analysis/flops-analysis.ipynb) | | |
| **第五章:在未标注数据上进行预训练** | - [使用 Transformers 从 Hugging Face 模型库加载替代权重](ch05/02_alternative_weight_loading/weight-loading-hf-transformers.ipynb) | |
| **第六章:用于分类的微调** | - [微调不同层并使用更大模型的额外实验](ch06/02_bonus_additional-experiments) | |
| **第七章:微调以跟随指令** | - [查找近重复项和创建被动语态条目的数据集工具](ch07/02_dataset-utilities) | |