diff --git a/docs/mindspore/source_en/note/api_mapping/pytorch_api_mapping.md b/docs/mindspore/source_en/note/api_mapping/pytorch_api_mapping.md
index d1933e039b0eac8f9ec47ab79c1bb89f7ab09a78..6f6a0976affadca3f7555c1c38cd38b9eb2887ac 100644
--- a/docs/mindspore/source_en/note/api_mapping/pytorch_api_mapping.md
+++ b/docs/mindspore/source_en/note/api_mapping/pytorch_api_mapping.md
@@ -308,7 +308,7 @@ More MindSpore developers are also welcome to participate in improving the mappi
| [torch.optim.Adagrad](https://pytorch.org/docs/1.5.0/optim.html#torch.optim.Adagrad) | [mindspore.nn.Adagrad](https://mindspore.cn/docs/en/master/api_python/nn/mindspore.nn.Adagrad.html#mindspore.nn.Adagrad) | [diff](https://www.mindspore.cn/docs/en/master/note/api_mapping/pytorch_diff/Adagrad.html) |
| [torch.optim.Adam](https://pytorch.org/docs/1.5.0/optim.html#torch.optim.Adam) | [mindspore.nn.Adam](https://mindspore.cn/docs/en/master/api_python/nn/mindspore.nn.Adam.html#mindspore.nn.Adam) | |
| [torch.optim.Adamax](https://pytorch.org/docs/1.5.0/optim.html#torch.optim.Adamax) | [mindspore.ops.ApplyAdaMax](https://mindspore.cn/docs/en/master/api_python/ops/mindspore.ops.ApplyAdaMax.html#mindspore.ops.ApplyAdaMax) | |
-| [torch.optim.AdamW](https://pytorch.org/docs/1.5.0/optim.html#torch.optim.AdamW) | [mindspore.nn.AdamWeightDecay](https://mindspore.cn/docs/zh-CN/master/api_python/nn/mindspore.nn.AdamWeightDecay.html#mindspore.nn.AdamWeightDecay) | [diff](https://www.mindspore.cn/docs/zh-CN/master/note/api_mapping/pytorch_diff/AdamWeightDecay.html) |
+| [torch.optim.AdamW](https://pytorch.org/docs/1.5.0/optim.html#torch.optim.AdamW) | [mindspore.nn.AdamWeightDecay](https://mindspore.cn/docs/en/master/api_python/nn/mindspore.nn.AdamWeightDecay.html#mindspore.nn.AdamWeightDecay) | [diff](https://www.mindspore.cn/docs/en/master/note/api_mapping/pytorch_diff/AdamWeightDecay.html) |
| [torch.optim.lr_scheduler.CosineAnnealingWarmRestarts](https://pytorch.org/docs/1.5.0/optim.html#torch.optim.lr_scheduler.CosineAnnealingWarmRestarts) | [mindspore.nn.cosine_decay_lr](https://mindspore.cn/docs/en/master/api_python/nn/mindspore.nn.cosine_decay_lr.html#mindspore.nn.cosine_decay_lr) | |
| [torch.optim.lr_scheduler.ExponentialLR](https://pytorch.org/docs/1.5.0/optim.html#torch.optim.lr_scheduler.ExponentialLR) | [mindspore.nn.exponential_decay_lr](https://mindspore.cn/docs/en/master/api_python/nn/mindspore.nn.exponential_decay_lr.html#mindspore.nn.exponential_decay_lr) | [diff](https://www.mindspore.cn/docs/en/master/note/api_mapping/pytorch_diff/ExponentialDecayLR.html) |
| [torch.optim.lr_scheduler.MultiStepLR](https://pytorch.org/docs/1.5.0/optim.html#torch.optim.lr_scheduler.MultiStepLR) | [mindspore.nn.piecewise_constant_lr](https://mindspore.cn/docs/en/master/api_python/nn/mindspore.nn.piecewise_constant_lr.html#mindspore.nn.piecewise_constant_lr) | [diff](https://www.mindspore.cn/docs/en/master/note/api_mapping/pytorch_diff/PiecewiseConstantLR.html) |
diff --git a/docs/mindspore/source_en/note/api_mapping/pytorch_diff/AdamWeightDecay.md b/docs/mindspore/source_en/note/api_mapping/pytorch_diff/AdamWeightDecay.md
index 602707191f3e39848700285bc03a91acfd60dd04..7ddd3c1053be15cfcbf70bdb8cf9bd258b5620b8 100644
--- a/docs/mindspore/source_en/note/api_mapping/pytorch_diff/AdamWeightDecay.md
+++ b/docs/mindspore/source_en/note/api_mapping/pytorch_diff/AdamWeightDecay.md
@@ -1,6 +1,6 @@
-# # Function Differences with torch.optim.AdamW
+# # Function Differences between torch.optim.AdamW and mindspore.nn.AdamWeightDecay
- +
+ ## torch.optim.AdamW
@@ -18,7 +18,7 @@ class torch.optim.AdamW(
)
```
-For more information, see[torch.optim.AdamW](https://pytorch.org/docs/1.5.0/optim.html#torch.optim.AdamW)。
+For more information, see [torch.optim.AdamW](https://pytorch.org/docs/1.5.0/optim.html#torch.optim.AdamW).
## mindspore.nn.AdamWeightDecay
@@ -33,11 +33,11 @@ class mindspore.nn.AdamWeightDecay(
)
```
-For more information, see[mindspore.nn.AdamWeightDecay](https://mindspore.cn/docs/zh-CN/master/api_python/nn/mindspore.nn.AdamWeightDecay.html#mindspore.nn.AdamWeightDecay)。
+For more information, see [mindspore.nn.AdamWeightDecay](https://mindspore.cn/docs/en/master/api_python/nn/mindspore.nn.AdamWeightDecay.html#mindspore.nn.AdamWeightDecay).
## Differences
-The code implementation and parameter update logic of `mindspore.nn.AdamWeightDecay` optimizer is different from `torch.optim.AdamW`,for more information, please refer to the docs of official website。
+The code implementation and parameter update logic of `mindspore.nn.AdamWeightDecay` optimizer is different from `torch.optim.AdamW`. For more information, please refer to the docs of official website.
## Code Example
diff --git a/tutorials/experts/source_zh_cn/others/mixed_precision.ipynb b/tutorials/experts/source_zh_cn/others/mixed_precision.ipynb
index 27acfe2f84e54e0b3dd292ef608971ffb8336d48..71ef06ead2ec351453768ec4fb7f01061e60ceb1 100644
--- a/tutorials/experts/source_zh_cn/others/mixed_precision.ipynb
+++ b/tutorials/experts/source_zh_cn/others/mixed_precision.ipynb
@@ -9,7 +9,7 @@
"source": [
"# 混合精度\n",
"\n",
- "[](https://obs.dualstack.cn-north-4.myhuaweicloud.com/mindspore-website/notebook/master/tutorials/experts/zh_cn/others/mindspore_mixed_precision.ipynb) [](https://obs.dualstack.cn-north-4.myhuaweicloud.com/mindspore-website/notebook/master/tutorials/experts/zh_cn/others/mindspore_mixed_precision.py) [](https://gitee.com/mindspore/docs/blob/master/tutorials/experts/source_zh_cn/others/mixed_precision.ipynb)\n",
+ "[](https://obs.dualstack.cn-north-4.myhuaweicloud.com/mindspore-website/notebook/master/tutorials/experts/zh_cn/others/mindspore_mixed_precision.ipynb) [](https://obs.dualstack.cn-north-4.myhuaweicloud.com/mindspore-website/notebook/master/tutorials/experts/zh_cn/others/mindspore_mixed_precision.py) [](https://gitee.com/mindspore/docs/blob/master/tutorials/experts/source_zh_cn/others/mixed_precision.ipynb)\n",
"\n",
"## 概述\n",
"\n",
@@ -21,7 +21,7 @@
"\n",
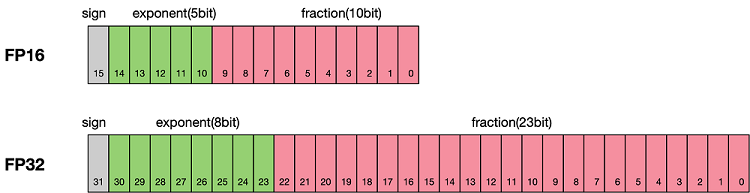
"根据IEEE二进制浮点数算术标准([IEEE 754](https://en.wikipedia.org/wiki/IEEE_754))的定义,浮点数据类型分为双精度(FP64)、单精度(FP32)、半精度(FP16)三种,其中每一种都有三个不同的位来表示。FP64表示采用8个字节共64位,来进行的编码存储的一种数据类型;同理,FP32表示采用4个字节共32位来表示;FP16则是采用2字节共16位来表示。如图所示:\n",
"\n",
- "\n",
+ "\n",
"\n",
"从图中可以看出,与FP32相比,FP16的存储空间是FP32的一半,FP32则是FP64的一半。主要分为三种类型:\n",
"\n",
@@ -70,7 +70,7 @@
"\n",
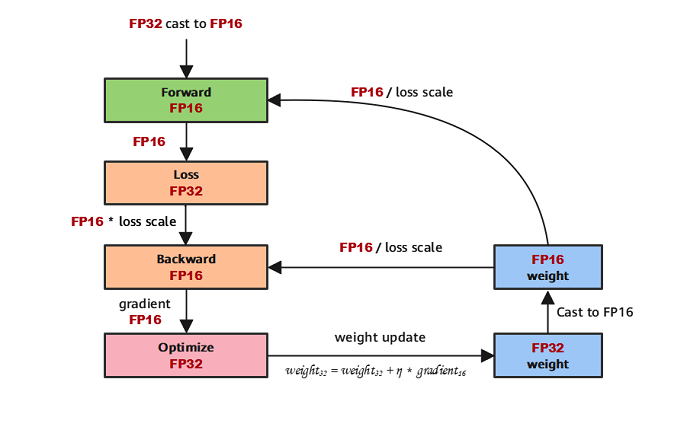
"MindSpore混合精度典型的计算流程如下图所示:\n",
"\n",
- "\n",
+ "\n",
"\n",
"1. 参数以FP32存储;\n",
"2. 正向计算过程中,遇到FP16算子,需要把算子输入和参数从FP32 cast成FP16进行计算;\n",
@@ -102,15 +102,15 @@
"\n",
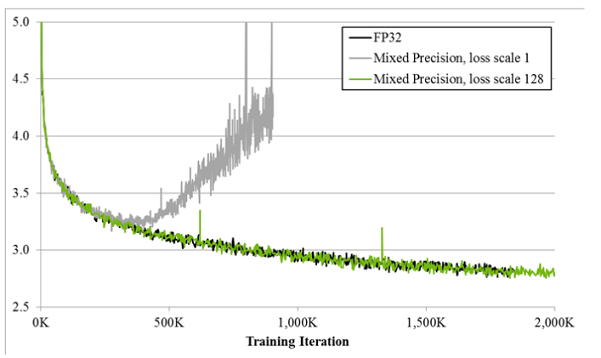
"如图所示,如果仅仅使用FP32训练,模型收敛得比较好,但是如果用了混合精度训练,会存在网络模型无法收敛的情况。原因是梯度的值太小,使用FP16表示会造成了数据下溢出(Underflow)的问题,导致模型不收敛,如图中灰色的部分。于是需要引入损失缩放(Loss Scale)技术。\n",
"\n",
- "\n",
+ "\n",
"\n",
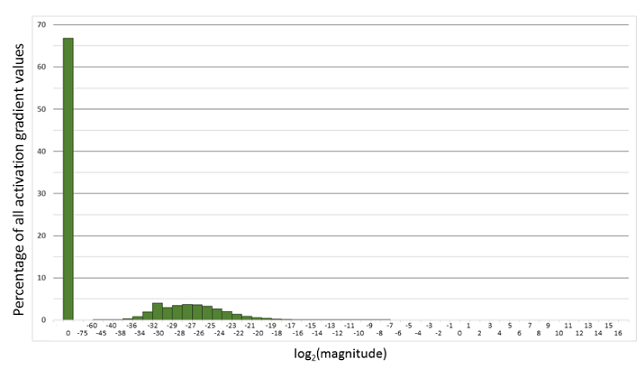
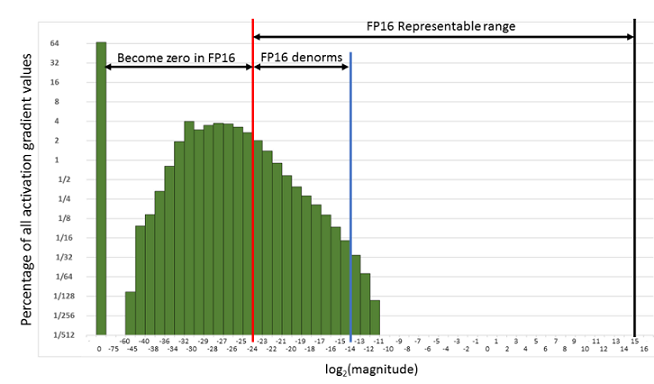
"下面是在网络模型训练阶段, 某一层的激活函数梯度分布式中,其中有68%的网络模型激活参数位0,另外有4%的精度在$2^{-32},2^{-20}$这个区间内,直接使用FP16对这里面的数据进行表示,会截断下溢的数据,所有的梯度值都会变为0。\n",
"\n",
- "\n",
+ "\n",
"\n",
"为了解决梯度过小数据下溢的问题,对前向计算出来的Loss值进行放大操作,也就是把FP32的参数乘以某一个因子系数后,把可能溢出的小数位数据往前移,平移到FP16能表示的数据范围内。根据链式求导法则,放大Loss后会作用在反向传播的每一层梯度,这样比在每一层梯度上进行放大更加高效。\n",
"\n",
- "\n",
+ "\n",
"\n",
"损失放大是需要结合混合精度实现的,其主要的主要思路是:\n",
"\n",
@@ -145,7 +145,8 @@
},
{
"cell_type": "code",
- "execution_count": null,
+ "execution_count": 1,
+ "metadata": {},
"outputs": [],
"source": [
"import numpy as np\n",
@@ -187,16 +188,11 @@
" x = self.relu(self.fc2(x))\n",
" x = self.fc3(x)\n",
" return x"
- ],
- "metadata": {
- "collapsed": false,
- "pycharm": {
- "name": "#%%\n"
- }
- }
+ ]
},
{
"cell_type": "markdown",
+ "metadata": {},
"source": [
"对网络做自动混合精度处理。\n",
"\n",
@@ -207,18 +203,13 @@
"- 'O2':按黑名单保留FP32,其余cast为FP16;\n",
"- 'O3':完全cast为FP16;\n",
"\n",
- "> 注:当前黑白名单为Cell粒度。"
- ],
- "metadata": {
- "collapsed": false,
- "pycharm": {
- "name": "#%% md\n"
- }
- }
+ "> 当前黑白名单为Cell粒度。"
+ ]
},
{
"cell_type": "code",
"execution_count": null,
+ "metadata": {},
"outputs": [],
"source": [
"from mindspore import amp\n",
@@ -226,26 +217,19 @@
"\n",
"net = LeNet5(10)\n",
"amp.auto_mixed_precision(net, 'O1')"
- ],
- "metadata": {
- "collapsed": false,
- "pycharm": {
- "name": "#%%\n"
- }
- }
+ ]
},
{
"cell_type": "markdown",
+ "metadata": {},
"source": [
"实例化LossScaler,并在定义前向网络时,手动放大loss值。"
- ],
- "metadata": {
- "collapsed": false
- }
+ ]
},
{
"cell_type": "code",
"execution_count": null,
+ "metadata": {},
"outputs": [],
"source": [
"loss_fn = nn.BCELoss(reduction='mean')\n",
@@ -260,49 +244,35 @@
" # scale up the loss value\n",
" scaled_loss = loss_scaler.scale(loss_value)\n",
" return scaled_loss, out"
- ],
- "metadata": {
- "collapsed": false,
- "pycharm": {
- "name": "#%%\n"
- }
- }
+ ]
},
{
"cell_type": "markdown",
+ "metadata": {},
"source": [
"反向获取梯度。"
- ],
- "metadata": {
- "collapsed": false
- }
+ ]
},
{
"cell_type": "code",
"execution_count": null,
+ "metadata": {},
"outputs": [],
"source": [
"grad_fn = ops.value_and_grad(net_forward, None, net.trainable_params())"
- ],
- "metadata": {
- "collapsed": false,
- "pycharm": {
- "name": "#%%\n"
- }
- }
+ ]
},
{
"cell_type": "markdown",
+ "metadata": {},
"source": [
"定义训练step:计算当前梯度值并恢复损失。使用 `all_finite` 判断是否出现梯度下溢问题,如果无溢出,恢复梯度并更新网络权重;如果溢出,跳过此step。"
- ],
- "metadata": {
- "collapsed": false
- }
+ ]
},
{
"cell_type": "code",
"execution_count": null,
+ "metadata": {},
"outputs": [],
"source": [
"@ms_function\n",
@@ -316,42 +286,30 @@
" loss_value = ops.depend(loss_value, opt(grads))\n",
" loss_scaler.adjust(is_finite)\n",
" return loss_value"
- ],
- "metadata": {
- "collapsed": false,
- "pycharm": {
- "name": "#%%\n"
- }
- }
+ ]
},
{
"cell_type": "markdown",
+ "metadata": {},
"source": [
"执行训练。"
- ],
- "metadata": {
- "collapsed": false
- }
+ ]
},
{
"cell_type": "code",
"execution_count": null,
+ "metadata": {},
"outputs": [],
"source": [
"epochs = 5\n",
"for epoch in range(epochs):\n",
" for data, label in datasets:\n",
" loss = train_step(data, label)"
- ],
- "metadata": {
- "collapsed": false,
- "pycharm": {
- "name": "#%%\n"
- }
- }
+ ]
},
{
- "cell_type": "markdown",
+ "cell_type": "markdown",,
+ "metadata": {},
"source": [
"### 使用训练接口 `Model` 实现混合精度与损失缩放\n",
"\n",
@@ -371,19 +329,17 @@
"\n",
"2. 定义网络:该步骤和正常的网络定义相同(无需新增任何配置);\n",
"\n",
- "3. 创建数据集:该步骤可参考[数据处理](https://www.mindspore.cn/tutorials/zh-CN/r1.8/advanced/dataset.html);\n",
+ "3. 创建数据集:该步骤可参考[数据处理](https://www.mindspore.cn/tutorials/zh-CN/master/advanced/dataset.html);\n",
"\n",
- "4. 使用`Model`接口封装网络模型、优化器和损失函数,设置`amp_level`参数,详情参考[MindSpore API](https://www.mindspore.cn/docs/zh-CN/r1.8/api_python/mindspore/mindspore.Model.html#mindspore.Model)。该步骤MindSpore会自动选择合适的算子自动进行FP32到FP16的类型转换。\n",
+ "4. 使用`Model`接口封装网络模型、优化器和损失函数,设置`amp_level`参数,详情参考[MindSpore API](https://www.mindspore.cn/docs/zh-CN/master/api_python/mindspore/mindspore.Model.html#mindspore.Model)。该步骤MindSpore会自动选择合适的算子自动进行FP32到FP16的类型转换。\n",
"\n",
"下面是基础的代码样例,首先导入必须的库和声明。"
- ],
- "metadata": {
- "collapsed": false
- }
+ ]
},
{
"cell_type": "code",
"execution_count": null,
+ "metadata": {},
"outputs": [],
"source": [
"import numpy as np\n",
@@ -395,26 +351,19 @@
"\n",
"ms.set_context(mode=ms.GRAPH_MODE)\n",
"ms.set_context(device_target=\"GPU\")"
- ],
- "metadata": {
- "collapsed": false,
- "pycharm": {
- "name": "#%%\n"
- }
- }
+ ]
},
{
"cell_type": "markdown",
+ "metadata": {},
"source": [
"接着创建一个虚拟的随机数据集,用于样例模型的数据输入。"
- ],
- "metadata": {
- "collapsed": false
- }
+ ]
},
{
"cell_type": "code",
"execution_count": null,
+ "metadata": {},
"outputs": [],
"source": [
"# create dataset\n",
@@ -434,26 +383,19 @@
" input_data = input_data.batch(batch_size, drop_remainder=True)\n",
" input_data = input_data.repeat(repeat_size)\n",
" return input_data"
- ],
- "metadata": {
- "collapsed": false,
- "pycharm": {
- "name": "#%%\n"
- }
- }
+ ]
},
{
"cell_type": "markdown",
+ "metadata": {},
"source": [
"以LeNet5网络为例,设置`amp_level`参数,使用`Model`接口封装网络模型、优化器和损失函数。"
- ],
- "metadata": {
- "collapsed": false
- }
+ ]
},
{
"cell_type": "code",
"execution_count": null,
+ "metadata": {},
"outputs": [],
"source": [
"ds_train = create_dataset()\n",
@@ -469,16 +411,11 @@
"\n",
"# Run training\n",
"model.train(epoch=10, train_dataset=ds_train)"
- ],
- "metadata": {
- "collapsed": false,
- "pycharm": {
- "name": "#%%\n"
- }
- }
+ ]
},
{
"cell_type": "markdown",
+ "metadata": {},
"source": [
"##### 手动混合精度\n",
"\n",
@@ -497,14 +434,12 @@
"3. 使用`TrainOneStepCell`封装网络模型和优化器。\n",
"\n",
"下面是基础的代码样例,首先导入必须的库和声明。"
- ],
- "metadata": {
- "collapsed": false
- }
+ ]
},
{
"cell_type": "code",
"execution_count": null,
+ "metadata": {},
"outputs": [],
"source": [
"import numpy as np\n",
@@ -517,26 +452,19 @@
"import mindspore.ops as ops\n",
"\n",
"ms.set_context(mode=ms.GRAPH_MODE, device_target=\"GPU\")"
- ],
- "metadata": {
- "collapsed": false,
- "pycharm": {
- "name": "#%%\n"
- }
- }
+ ]
},
{
"cell_type": "markdown",
+ "metadata": {},
"source": [
"在初始化网络模型后,声明LeNet5中的Conv1层使用FP16进行计算,即`network.conv1.to_float(mstype.float16)`。"
- ],
- "metadata": {
- "collapsed": false
- }
+ ]
},
{
"cell_type": "code",
"execution_count": null,
+ "metadata": {},
"outputs": [],
"source": [
"ds_train = create_dataset()\n",
@@ -546,22 +474,17 @@
"network.conv1.to_float(ms.float16)\n",
"model = ms.Model(network, net_loss, net_opt, metrics={\"Accuracy\": Accuracy()}, amp_level=\"O2\")\n",
"model.train(epoch=2, train_dataset=ds_train)"
- ],
- "metadata": {
- "collapsed": false,
- "pycharm": {
- "name": "#%%\n"
- }
- }
+ ]
},
{
"cell_type": "markdown",
+ "metadata": {},
"source": [
- "> 约束:使用混合精度时,只能由自动微分功能生成反向网络,不能由用户自定义生成反向网络,否则可能会导致MindSpore产生数据格式不匹配的异常信息。\n",
+ "> 使用混合精度时,只能由自动微分功能生成反向网络,不能由用户自定义生成反向网络,否则可能会导致MindSpore产生数据格式不匹配的异常信息。\n",
"\n",
"#### 损失缩放\n",
"\n",
- "下面将会分别介绍MindSpore中,配合 `Model` 接口使用损失缩放算法的主要两个API [FixedLossScaleManager](https://www.mindspore.cn/docs/zh-CN/r1.8/api_python/amp/mindspore.amp.FixedLossScaleManager.html)和[DynamicLossScaleManager](https://www.mindspore.cn/docs/zh-CN/r1.8/api_python/amp/mindspore.amp.DynamicLossScaleManager.html)。\n",
+ "下面将会分别介绍MindSpore中,配合 `Model` 接口使用损失缩放算法的主要两个API [FixedLossScaleManager](https://www.mindspore.cn/docs/zh-CN/master/api_python/amp/mindspore.amp.FixedLossScaleManager.html)和[DynamicLossScaleManager](https://www.mindspore.cn/docs/zh-CN/master/api_python/amp/mindspore.amp.DynamicLossScaleManager.html)。\n",
"\n",
"##### FixedLossScaleManager\n",
"\n",
@@ -574,16 +497,15 @@
"`FixedLossScaleManager`具体用法如下:\n",
"\n",
"import必要的库,并声明使用图模式下执行。"
- ],
- "metadata": {
- "collapsed": false
- }
+ ]
},
{
"cell_type": "code",
"execution_count": null,
+ "metadata": {},
"outputs": [],
"source": [
+ "from mindspore import amp\n",
"import numpy as np\n",
"import mindspore as ms\n",
"import mindspore.nn as nn\n",
@@ -591,28 +513,20 @@
"from mindspore.common.initializer import Normal\n",
"from mindspore import dataset as ds\n",
"\n",
- "#ms.set_seed(0)\n",
"ms.set_context(mode=ms.GRAPH_MODE, device_target=\"GPU\")"
- ],
- "metadata": {
- "collapsed": false,
- "pycharm": {
- "name": "#%%\n"
- }
- }
+ ]
},
{
"cell_type": "markdown",
+ "metadata": {},
"source": [
"以LeNet5为例定义网络模型;定义数据集和训练流程中常用的接口。"
- ],
- "metadata": {
- "collapsed": false
- }
+ ]
},
{
"cell_type": "code",
"execution_count": null,
+ "metadata": {},
"outputs": [],
"source": [
"ds_train = create_dataset()\n",
@@ -620,52 +534,40 @@
"network = LeNet5(10)\n",
"# Define Loss and Optimizer\n",
"net_loss = nn.SoftmaxCrossEntropyWithLogits(reduction=\"mean\")"
- ],
- "metadata": {
- "collapsed": false,
- "pycharm": {
- "name": "#%%\n"
- }
- }
+ ]
},
{
"cell_type": "markdown",
+ "metadata": {},
"source": [
"使用Loss Scale的API接口,作用于优化器和模型中。"
- ],
- "metadata": {
- "collapsed": false
- }
+ ]
},
{
"cell_type": "code",
"execution_count": null,
+ "metadata": {},
"outputs": [],
"source": [
"# Define Loss Scale, optimizer and model\n",
"#1) Drop the parameter update if there is an overflow\n",
- "loss_scale_manager = ms.FixedLossScaleManager()\n",
+ "loss_scale_manager = amp.FixedLossScaleManager()\n",
"net_opt = nn.Momentum(network.trainable_params(), learning_rate=0.01, momentum=0.9)\n",
"model = ms.Model(network, net_loss, net_opt, metrics={\"Accuracy\": Accuracy()}, amp_level=\"O0\", loss_scale_manager=loss_scale_manager)\n",
"\n",
"#2) Execute parameter update even if overflow occurs\n",
"loss_scale = 1024.0\n",
- "loss_scale_manager = ms.FixedLossScaleManager(loss_scale, False)\n",
+ "loss_scale_manager = amp.FixedLossScaleManager(loss_scale, False)\n",
"net_opt = nn.Momentum(network.trainable_params(), learning_rate=0.01, momentum=0.9, loss_scale=loss_scale)\n",
"model = ms.Model(network, net_loss, net_opt, metrics={\"Accuracy\": Accuracy()}, amp_level=\"O0\", loss_scale_manager=loss_scale_manager)\n",
"\n",
"# Run training\n",
"model.train(epoch=10, train_dataset=ds_train, callbacks=[ms.LossMonitor()])"
- ],
- "metadata": {
- "collapsed": false,
- "pycharm": {
- "name": "#%%\n"
- }
- }
+ ]
},
{
"cell_type": "markdown",
+ "metadata": {},
"source": [
"##### LossScale与优化器\n",
"\n",
@@ -676,14 +578,12 @@
"> 后续MindSpore会优化不同场景下溢出检测功能的用法,并逐步移除优化器中的`loss_scale`参数,到时便无需配置优化器的`loss_scale`参数。\n",
"\n",
"需要注意的是,当前MindSpore提供的部分优化器如`AdamWeightDecay`,未提供`loss_scale`参数。如果使用`FixedLossScaleManager`,且`drop_overflow_update`配置为False,优化器中未能进行梯度与`loss_scale`之间的除法运算,此时需要自定义`TrainOneStepCell`,并在其中对梯度除`loss_scale`,以使最终的计算结果正确,定义方式如下:"
- ],
- "metadata": {
- "collapsed": false
- }
+ ]
},
{
"cell_type": "code",
"execution_count": null,
+ "metadata": {},
"outputs": [],
"source": [
"import mindspore as ms\n",
@@ -716,16 +616,11 @@
" grads = self.grad_reducer(grads)\n",
" loss = ops.depend(loss, self.optimizer(grads))\n",
" return loss"
- ],
- "metadata": {
- "collapsed": false,
- "pycharm": {
- "name": "#%%\n"
- }
- }
+ ]
},
{
"cell_type": "markdown",
+ "metadata": {},
"source": [
"- network:参与训练的网络,该网络包含前向网络和损失函数的计算逻辑,输入数据和标签,输出损失函数值。\n",
"- optimizer:所使用的优化器。\n",
@@ -734,17 +629,16 @@
"- construct函数:参照`nn.TrainOneStepCell`定义`construct`的计算逻辑,并在获取梯度后调用`scale_grad`。\n",
"\n",
"自定义`TrainOneStepCell`后,需要手动构建训练网络,如下:"
- ],
- "metadata": {
- "collapsed": false
- }
+ ]
},
{
"cell_type": "code",
"execution_count": null,
+ "metadata": {},
"outputs": [],
"source": [
"from mindspore import nn\n",
+ "from mindspore import amp\n",
"\n",
"network = LeNet5(10)\n",
"\n",
@@ -754,31 +648,24 @@
"\n",
"# Define LossScaleManager\n",
"loss_scale = 1024.0\n",
- "loss_scale_manager = ms.FixedLossScaleManager(loss_scale, False)\n",
+ "loss_scale_manager = amp.FixedLossScaleManager(loss_scale, False)\n",
"\n",
"# Build train network\n",
"net_with_loss = nn.WithLossCell(network, net_loss)\n",
"net_with_train = CustomTrainOneStepCell(net_with_loss, net_opt, loss_scale)"
- ],
- "metadata": {
- "collapsed": false,
- "pycharm": {
- "name": "#%%\n"
- }
- }
+ ]
},
{
"cell_type": "markdown",
+ "metadata": {},
"source": [
"构建训练网络后可以直接运行或通过Model运行:"
- ],
- "metadata": {
- "collapsed": false
- }
+ ]
},
{
"cell_type": "code",
"execution_count": null,
+ "metadata": {},
"outputs": [],
"source": [
"epochs = 2\n",
@@ -796,16 +683,11 @@
"ds_train = create_dataset()\n",
"\n",
"model.train(epoch=epochs, train_dataset=ds_train)"
- ],
- "metadata": {
- "collapsed": false,
- "pycharm": {
- "name": "#%%\n"
- }
- }
+ ]
},
{
"cell_type": "markdown",
+ "metadata": {},
"source": [
"在此场景下使用`Model`进行训练时,`loss_scale_manager`和`amp_level`无需配置,因为`CustomTrainOneStepCell`中已经包含了混合精度的计算逻辑。\n",
"\n",
@@ -818,38 +700,28 @@
"在训练过程中,如果不发生溢出,在更新scale_window次参数后,会尝试扩大scale的值,如果发生了溢出,则跳过参数更新,并缩小scale的值,入参scale_factor是控制扩大或缩小的步数,scale_window控制没有发生溢出时,最大的连续更新步数。\n",
"\n",
"具体用法如下,仅需将`FixedLossScaleManager`样例中定义LossScale,优化器和模型部分的代码改成如下代码:"
- ],
- "metadata": {
- "collapsed": false
- }
+ ]
},
{
"cell_type": "code",
"execution_count": null,
+ "metadata": {},
"outputs": [],
"source": [
"# Define Loss Scale, optimizer and model\n",
"scale_factor = 4\n",
"scale_window = 3000\n",
- "loss_scale_manager = ms.DynamicLossScaleManager(scale_factor, scale_window)\n",
+ "loss_scale_manager = amp.DynamicLossScaleManager(scale_factor, scale_window)\n",
"net_opt = nn.Momentum(network.trainable_params(), learning_rate=0.01, momentum=0.9)\n",
"model = ms.Model(network, net_loss, net_opt, metrics={\"Accuracy\": Accuracy()}, amp_level=\"O0\", loss_scale_manager=loss_scale_manager)"
- ],
- "metadata": {
- "collapsed": false,
- "pycharm": {
- "name": "#%%\n"
- }
- }
+ ]
},
{
"cell_type": "markdown",
+ "metadata": {},
"source": [
"> 图片引用自[automatic-mixed-precision](https://developer.nvidia.com/automatic-mixed-precision)"
- ],
- "metadata": {
- "collapsed": false
- }
+ ]
}
],
"metadata": {
## torch.optim.AdamW
@@ -18,7 +18,7 @@ class torch.optim.AdamW(
)
```
-For more information, see[torch.optim.AdamW](https://pytorch.org/docs/1.5.0/optim.html#torch.optim.AdamW)。
+For more information, see [torch.optim.AdamW](https://pytorch.org/docs/1.5.0/optim.html#torch.optim.AdamW).
## mindspore.nn.AdamWeightDecay
@@ -33,11 +33,11 @@ class mindspore.nn.AdamWeightDecay(
)
```
-For more information, see[mindspore.nn.AdamWeightDecay](https://mindspore.cn/docs/zh-CN/master/api_python/nn/mindspore.nn.AdamWeightDecay.html#mindspore.nn.AdamWeightDecay)。
+For more information, see [mindspore.nn.AdamWeightDecay](https://mindspore.cn/docs/en/master/api_python/nn/mindspore.nn.AdamWeightDecay.html#mindspore.nn.AdamWeightDecay).
## Differences
-The code implementation and parameter update logic of `mindspore.nn.AdamWeightDecay` optimizer is different from `torch.optim.AdamW`,for more information, please refer to the docs of official website。
+The code implementation and parameter update logic of `mindspore.nn.AdamWeightDecay` optimizer is different from `torch.optim.AdamW`. For more information, please refer to the docs of official website.
## Code Example
diff --git a/tutorials/experts/source_zh_cn/others/mixed_precision.ipynb b/tutorials/experts/source_zh_cn/others/mixed_precision.ipynb
index 27acfe2f84e54e0b3dd292ef608971ffb8336d48..71ef06ead2ec351453768ec4fb7f01061e60ceb1 100644
--- a/tutorials/experts/source_zh_cn/others/mixed_precision.ipynb
+++ b/tutorials/experts/source_zh_cn/others/mixed_precision.ipynb
@@ -9,7 +9,7 @@
"source": [
"# 混合精度\n",
"\n",
- "[](https://obs.dualstack.cn-north-4.myhuaweicloud.com/mindspore-website/notebook/master/tutorials/experts/zh_cn/others/mindspore_mixed_precision.ipynb) [](https://obs.dualstack.cn-north-4.myhuaweicloud.com/mindspore-website/notebook/master/tutorials/experts/zh_cn/others/mindspore_mixed_precision.py) [](https://gitee.com/mindspore/docs/blob/master/tutorials/experts/source_zh_cn/others/mixed_precision.ipynb)\n",
+ "[](https://obs.dualstack.cn-north-4.myhuaweicloud.com/mindspore-website/notebook/master/tutorials/experts/zh_cn/others/mindspore_mixed_precision.ipynb) [](https://obs.dualstack.cn-north-4.myhuaweicloud.com/mindspore-website/notebook/master/tutorials/experts/zh_cn/others/mindspore_mixed_precision.py) [](https://gitee.com/mindspore/docs/blob/master/tutorials/experts/source_zh_cn/others/mixed_precision.ipynb)\n",
"\n",
"## 概述\n",
"\n",
@@ -21,7 +21,7 @@
"\n",
"根据IEEE二进制浮点数算术标准([IEEE 754](https://en.wikipedia.org/wiki/IEEE_754))的定义,浮点数据类型分为双精度(FP64)、单精度(FP32)、半精度(FP16)三种,其中每一种都有三个不同的位来表示。FP64表示采用8个字节共64位,来进行的编码存储的一种数据类型;同理,FP32表示采用4个字节共32位来表示;FP16则是采用2字节共16位来表示。如图所示:\n",
"\n",
- "\n",
+ "\n",
"\n",
"从图中可以看出,与FP32相比,FP16的存储空间是FP32的一半,FP32则是FP64的一半。主要分为三种类型:\n",
"\n",
@@ -70,7 +70,7 @@
"\n",
"MindSpore混合精度典型的计算流程如下图所示:\n",
"\n",
- "\n",
+ "\n",
"\n",
"1. 参数以FP32存储;\n",
"2. 正向计算过程中,遇到FP16算子,需要把算子输入和参数从FP32 cast成FP16进行计算;\n",
@@ -102,15 +102,15 @@
"\n",
"如图所示,如果仅仅使用FP32训练,模型收敛得比较好,但是如果用了混合精度训练,会存在网络模型无法收敛的情况。原因是梯度的值太小,使用FP16表示会造成了数据下溢出(Underflow)的问题,导致模型不收敛,如图中灰色的部分。于是需要引入损失缩放(Loss Scale)技术。\n",
"\n",
- "\n",
+ "\n",
"\n",
"下面是在网络模型训练阶段, 某一层的激活函数梯度分布式中,其中有68%的网络模型激活参数位0,另外有4%的精度在$2^{-32},2^{-20}$这个区间内,直接使用FP16对这里面的数据进行表示,会截断下溢的数据,所有的梯度值都会变为0。\n",
"\n",
- "\n",
+ "\n",
"\n",
"为了解决梯度过小数据下溢的问题,对前向计算出来的Loss值进行放大操作,也就是把FP32的参数乘以某一个因子系数后,把可能溢出的小数位数据往前移,平移到FP16能表示的数据范围内。根据链式求导法则,放大Loss后会作用在反向传播的每一层梯度,这样比在每一层梯度上进行放大更加高效。\n",
"\n",
- "\n",
+ "\n",
"\n",
"损失放大是需要结合混合精度实现的,其主要的主要思路是:\n",
"\n",
@@ -145,7 +145,8 @@
},
{
"cell_type": "code",
- "execution_count": null,
+ "execution_count": 1,
+ "metadata": {},
"outputs": [],
"source": [
"import numpy as np\n",
@@ -187,16 +188,11 @@
" x = self.relu(self.fc2(x))\n",
" x = self.fc3(x)\n",
" return x"
- ],
- "metadata": {
- "collapsed": false,
- "pycharm": {
- "name": "#%%\n"
- }
- }
+ ]
},
{
"cell_type": "markdown",
+ "metadata": {},
"source": [
"对网络做自动混合精度处理。\n",
"\n",
@@ -207,18 +203,13 @@
"- 'O2':按黑名单保留FP32,其余cast为FP16;\n",
"- 'O3':完全cast为FP16;\n",
"\n",
- "> 注:当前黑白名单为Cell粒度。"
- ],
- "metadata": {
- "collapsed": false,
- "pycharm": {
- "name": "#%% md\n"
- }
- }
+ "> 当前黑白名单为Cell粒度。"
+ ]
},
{
"cell_type": "code",
"execution_count": null,
+ "metadata": {},
"outputs": [],
"source": [
"from mindspore import amp\n",
@@ -226,26 +217,19 @@
"\n",
"net = LeNet5(10)\n",
"amp.auto_mixed_precision(net, 'O1')"
- ],
- "metadata": {
- "collapsed": false,
- "pycharm": {
- "name": "#%%\n"
- }
- }
+ ]
},
{
"cell_type": "markdown",
+ "metadata": {},
"source": [
"实例化LossScaler,并在定义前向网络时,手动放大loss值。"
- ],
- "metadata": {
- "collapsed": false
- }
+ ]
},
{
"cell_type": "code",
"execution_count": null,
+ "metadata": {},
"outputs": [],
"source": [
"loss_fn = nn.BCELoss(reduction='mean')\n",
@@ -260,49 +244,35 @@
" # scale up the loss value\n",
" scaled_loss = loss_scaler.scale(loss_value)\n",
" return scaled_loss, out"
- ],
- "metadata": {
- "collapsed": false,
- "pycharm": {
- "name": "#%%\n"
- }
- }
+ ]
},
{
"cell_type": "markdown",
+ "metadata": {},
"source": [
"反向获取梯度。"
- ],
- "metadata": {
- "collapsed": false
- }
+ ]
},
{
"cell_type": "code",
"execution_count": null,
+ "metadata": {},
"outputs": [],
"source": [
"grad_fn = ops.value_and_grad(net_forward, None, net.trainable_params())"
- ],
- "metadata": {
- "collapsed": false,
- "pycharm": {
- "name": "#%%\n"
- }
- }
+ ]
},
{
"cell_type": "markdown",
+ "metadata": {},
"source": [
"定义训练step:计算当前梯度值并恢复损失。使用 `all_finite` 判断是否出现梯度下溢问题,如果无溢出,恢复梯度并更新网络权重;如果溢出,跳过此step。"
- ],
- "metadata": {
- "collapsed": false
- }
+ ]
},
{
"cell_type": "code",
"execution_count": null,
+ "metadata": {},
"outputs": [],
"source": [
"@ms_function\n",
@@ -316,42 +286,30 @@
" loss_value = ops.depend(loss_value, opt(grads))\n",
" loss_scaler.adjust(is_finite)\n",
" return loss_value"
- ],
- "metadata": {
- "collapsed": false,
- "pycharm": {
- "name": "#%%\n"
- }
- }
+ ]
},
{
"cell_type": "markdown",
+ "metadata": {},
"source": [
"执行训练。"
- ],
- "metadata": {
- "collapsed": false
- }
+ ]
},
{
"cell_type": "code",
"execution_count": null,
+ "metadata": {},
"outputs": [],
"source": [
"epochs = 5\n",
"for epoch in range(epochs):\n",
" for data, label in datasets:\n",
" loss = train_step(data, label)"
- ],
- "metadata": {
- "collapsed": false,
- "pycharm": {
- "name": "#%%\n"
- }
- }
+ ]
},
{
- "cell_type": "markdown",
+ "cell_type": "markdown",,
+ "metadata": {},
"source": [
"### 使用训练接口 `Model` 实现混合精度与损失缩放\n",
"\n",
@@ -371,19 +329,17 @@
"\n",
"2. 定义网络:该步骤和正常的网络定义相同(无需新增任何配置);\n",
"\n",
- "3. 创建数据集:该步骤可参考[数据处理](https://www.mindspore.cn/tutorials/zh-CN/r1.8/advanced/dataset.html);\n",
+ "3. 创建数据集:该步骤可参考[数据处理](https://www.mindspore.cn/tutorials/zh-CN/master/advanced/dataset.html);\n",
"\n",
- "4. 使用`Model`接口封装网络模型、优化器和损失函数,设置`amp_level`参数,详情参考[MindSpore API](https://www.mindspore.cn/docs/zh-CN/r1.8/api_python/mindspore/mindspore.Model.html#mindspore.Model)。该步骤MindSpore会自动选择合适的算子自动进行FP32到FP16的类型转换。\n",
+ "4. 使用`Model`接口封装网络模型、优化器和损失函数,设置`amp_level`参数,详情参考[MindSpore API](https://www.mindspore.cn/docs/zh-CN/master/api_python/mindspore/mindspore.Model.html#mindspore.Model)。该步骤MindSpore会自动选择合适的算子自动进行FP32到FP16的类型转换。\n",
"\n",
"下面是基础的代码样例,首先导入必须的库和声明。"
- ],
- "metadata": {
- "collapsed": false
- }
+ ]
},
{
"cell_type": "code",
"execution_count": null,
+ "metadata": {},
"outputs": [],
"source": [
"import numpy as np\n",
@@ -395,26 +351,19 @@
"\n",
"ms.set_context(mode=ms.GRAPH_MODE)\n",
"ms.set_context(device_target=\"GPU\")"
- ],
- "metadata": {
- "collapsed": false,
- "pycharm": {
- "name": "#%%\n"
- }
- }
+ ]
},
{
"cell_type": "markdown",
+ "metadata": {},
"source": [
"接着创建一个虚拟的随机数据集,用于样例模型的数据输入。"
- ],
- "metadata": {
- "collapsed": false
- }
+ ]
},
{
"cell_type": "code",
"execution_count": null,
+ "metadata": {},
"outputs": [],
"source": [
"# create dataset\n",
@@ -434,26 +383,19 @@
" input_data = input_data.batch(batch_size, drop_remainder=True)\n",
" input_data = input_data.repeat(repeat_size)\n",
" return input_data"
- ],
- "metadata": {
- "collapsed": false,
- "pycharm": {
- "name": "#%%\n"
- }
- }
+ ]
},
{
"cell_type": "markdown",
+ "metadata": {},
"source": [
"以LeNet5网络为例,设置`amp_level`参数,使用`Model`接口封装网络模型、优化器和损失函数。"
- ],
- "metadata": {
- "collapsed": false
- }
+ ]
},
{
"cell_type": "code",
"execution_count": null,
+ "metadata": {},
"outputs": [],
"source": [
"ds_train = create_dataset()\n",
@@ -469,16 +411,11 @@
"\n",
"# Run training\n",
"model.train(epoch=10, train_dataset=ds_train)"
- ],
- "metadata": {
- "collapsed": false,
- "pycharm": {
- "name": "#%%\n"
- }
- }
+ ]
},
{
"cell_type": "markdown",
+ "metadata": {},
"source": [
"##### 手动混合精度\n",
"\n",
@@ -497,14 +434,12 @@
"3. 使用`TrainOneStepCell`封装网络模型和优化器。\n",
"\n",
"下面是基础的代码样例,首先导入必须的库和声明。"
- ],
- "metadata": {
- "collapsed": false
- }
+ ]
},
{
"cell_type": "code",
"execution_count": null,
+ "metadata": {},
"outputs": [],
"source": [
"import numpy as np\n",
@@ -517,26 +452,19 @@
"import mindspore.ops as ops\n",
"\n",
"ms.set_context(mode=ms.GRAPH_MODE, device_target=\"GPU\")"
- ],
- "metadata": {
- "collapsed": false,
- "pycharm": {
- "name": "#%%\n"
- }
- }
+ ]
},
{
"cell_type": "markdown",
+ "metadata": {},
"source": [
"在初始化网络模型后,声明LeNet5中的Conv1层使用FP16进行计算,即`network.conv1.to_float(mstype.float16)`。"
- ],
- "metadata": {
- "collapsed": false
- }
+ ]
},
{
"cell_type": "code",
"execution_count": null,
+ "metadata": {},
"outputs": [],
"source": [
"ds_train = create_dataset()\n",
@@ -546,22 +474,17 @@
"network.conv1.to_float(ms.float16)\n",
"model = ms.Model(network, net_loss, net_opt, metrics={\"Accuracy\": Accuracy()}, amp_level=\"O2\")\n",
"model.train(epoch=2, train_dataset=ds_train)"
- ],
- "metadata": {
- "collapsed": false,
- "pycharm": {
- "name": "#%%\n"
- }
- }
+ ]
},
{
"cell_type": "markdown",
+ "metadata": {},
"source": [
- "> 约束:使用混合精度时,只能由自动微分功能生成反向网络,不能由用户自定义生成反向网络,否则可能会导致MindSpore产生数据格式不匹配的异常信息。\n",
+ "> 使用混合精度时,只能由自动微分功能生成反向网络,不能由用户自定义生成反向网络,否则可能会导致MindSpore产生数据格式不匹配的异常信息。\n",
"\n",
"#### 损失缩放\n",
"\n",
- "下面将会分别介绍MindSpore中,配合 `Model` 接口使用损失缩放算法的主要两个API [FixedLossScaleManager](https://www.mindspore.cn/docs/zh-CN/r1.8/api_python/amp/mindspore.amp.FixedLossScaleManager.html)和[DynamicLossScaleManager](https://www.mindspore.cn/docs/zh-CN/r1.8/api_python/amp/mindspore.amp.DynamicLossScaleManager.html)。\n",
+ "下面将会分别介绍MindSpore中,配合 `Model` 接口使用损失缩放算法的主要两个API [FixedLossScaleManager](https://www.mindspore.cn/docs/zh-CN/master/api_python/amp/mindspore.amp.FixedLossScaleManager.html)和[DynamicLossScaleManager](https://www.mindspore.cn/docs/zh-CN/master/api_python/amp/mindspore.amp.DynamicLossScaleManager.html)。\n",
"\n",
"##### FixedLossScaleManager\n",
"\n",
@@ -574,16 +497,15 @@
"`FixedLossScaleManager`具体用法如下:\n",
"\n",
"import必要的库,并声明使用图模式下执行。"
- ],
- "metadata": {
- "collapsed": false
- }
+ ]
},
{
"cell_type": "code",
"execution_count": null,
+ "metadata": {},
"outputs": [],
"source": [
+ "from mindspore import amp\n",
"import numpy as np\n",
"import mindspore as ms\n",
"import mindspore.nn as nn\n",
@@ -591,28 +513,20 @@
"from mindspore.common.initializer import Normal\n",
"from mindspore import dataset as ds\n",
"\n",
- "#ms.set_seed(0)\n",
"ms.set_context(mode=ms.GRAPH_MODE, device_target=\"GPU\")"
- ],
- "metadata": {
- "collapsed": false,
- "pycharm": {
- "name": "#%%\n"
- }
- }
+ ]
},
{
"cell_type": "markdown",
+ "metadata": {},
"source": [
"以LeNet5为例定义网络模型;定义数据集和训练流程中常用的接口。"
- ],
- "metadata": {
- "collapsed": false
- }
+ ]
},
{
"cell_type": "code",
"execution_count": null,
+ "metadata": {},
"outputs": [],
"source": [
"ds_train = create_dataset()\n",
@@ -620,52 +534,40 @@
"network = LeNet5(10)\n",
"# Define Loss and Optimizer\n",
"net_loss = nn.SoftmaxCrossEntropyWithLogits(reduction=\"mean\")"
- ],
- "metadata": {
- "collapsed": false,
- "pycharm": {
- "name": "#%%\n"
- }
- }
+ ]
},
{
"cell_type": "markdown",
+ "metadata": {},
"source": [
"使用Loss Scale的API接口,作用于优化器和模型中。"
- ],
- "metadata": {
- "collapsed": false
- }
+ ]
},
{
"cell_type": "code",
"execution_count": null,
+ "metadata": {},
"outputs": [],
"source": [
"# Define Loss Scale, optimizer and model\n",
"#1) Drop the parameter update if there is an overflow\n",
- "loss_scale_manager = ms.FixedLossScaleManager()\n",
+ "loss_scale_manager = amp.FixedLossScaleManager()\n",
"net_opt = nn.Momentum(network.trainable_params(), learning_rate=0.01, momentum=0.9)\n",
"model = ms.Model(network, net_loss, net_opt, metrics={\"Accuracy\": Accuracy()}, amp_level=\"O0\", loss_scale_manager=loss_scale_manager)\n",
"\n",
"#2) Execute parameter update even if overflow occurs\n",
"loss_scale = 1024.0\n",
- "loss_scale_manager = ms.FixedLossScaleManager(loss_scale, False)\n",
+ "loss_scale_manager = amp.FixedLossScaleManager(loss_scale, False)\n",
"net_opt = nn.Momentum(network.trainable_params(), learning_rate=0.01, momentum=0.9, loss_scale=loss_scale)\n",
"model = ms.Model(network, net_loss, net_opt, metrics={\"Accuracy\": Accuracy()}, amp_level=\"O0\", loss_scale_manager=loss_scale_manager)\n",
"\n",
"# Run training\n",
"model.train(epoch=10, train_dataset=ds_train, callbacks=[ms.LossMonitor()])"
- ],
- "metadata": {
- "collapsed": false,
- "pycharm": {
- "name": "#%%\n"
- }
- }
+ ]
},
{
"cell_type": "markdown",
+ "metadata": {},
"source": [
"##### LossScale与优化器\n",
"\n",
@@ -676,14 +578,12 @@
"> 后续MindSpore会优化不同场景下溢出检测功能的用法,并逐步移除优化器中的`loss_scale`参数,到时便无需配置优化器的`loss_scale`参数。\n",
"\n",
"需要注意的是,当前MindSpore提供的部分优化器如`AdamWeightDecay`,未提供`loss_scale`参数。如果使用`FixedLossScaleManager`,且`drop_overflow_update`配置为False,优化器中未能进行梯度与`loss_scale`之间的除法运算,此时需要自定义`TrainOneStepCell`,并在其中对梯度除`loss_scale`,以使最终的计算结果正确,定义方式如下:"
- ],
- "metadata": {
- "collapsed": false
- }
+ ]
},
{
"cell_type": "code",
"execution_count": null,
+ "metadata": {},
"outputs": [],
"source": [
"import mindspore as ms\n",
@@ -716,16 +616,11 @@
" grads = self.grad_reducer(grads)\n",
" loss = ops.depend(loss, self.optimizer(grads))\n",
" return loss"
- ],
- "metadata": {
- "collapsed": false,
- "pycharm": {
- "name": "#%%\n"
- }
- }
+ ]
},
{
"cell_type": "markdown",
+ "metadata": {},
"source": [
"- network:参与训练的网络,该网络包含前向网络和损失函数的计算逻辑,输入数据和标签,输出损失函数值。\n",
"- optimizer:所使用的优化器。\n",
@@ -734,17 +629,16 @@
"- construct函数:参照`nn.TrainOneStepCell`定义`construct`的计算逻辑,并在获取梯度后调用`scale_grad`。\n",
"\n",
"自定义`TrainOneStepCell`后,需要手动构建训练网络,如下:"
- ],
- "metadata": {
- "collapsed": false
- }
+ ]
},
{
"cell_type": "code",
"execution_count": null,
+ "metadata": {},
"outputs": [],
"source": [
"from mindspore import nn\n",
+ "from mindspore import amp\n",
"\n",
"network = LeNet5(10)\n",
"\n",
@@ -754,31 +648,24 @@
"\n",
"# Define LossScaleManager\n",
"loss_scale = 1024.0\n",
- "loss_scale_manager = ms.FixedLossScaleManager(loss_scale, False)\n",
+ "loss_scale_manager = amp.FixedLossScaleManager(loss_scale, False)\n",
"\n",
"# Build train network\n",
"net_with_loss = nn.WithLossCell(network, net_loss)\n",
"net_with_train = CustomTrainOneStepCell(net_with_loss, net_opt, loss_scale)"
- ],
- "metadata": {
- "collapsed": false,
- "pycharm": {
- "name": "#%%\n"
- }
- }
+ ]
},
{
"cell_type": "markdown",
+ "metadata": {},
"source": [
"构建训练网络后可以直接运行或通过Model运行:"
- ],
- "metadata": {
- "collapsed": false
- }
+ ]
},
{
"cell_type": "code",
"execution_count": null,
+ "metadata": {},
"outputs": [],
"source": [
"epochs = 2\n",
@@ -796,16 +683,11 @@
"ds_train = create_dataset()\n",
"\n",
"model.train(epoch=epochs, train_dataset=ds_train)"
- ],
- "metadata": {
- "collapsed": false,
- "pycharm": {
- "name": "#%%\n"
- }
- }
+ ]
},
{
"cell_type": "markdown",
+ "metadata": {},
"source": [
"在此场景下使用`Model`进行训练时,`loss_scale_manager`和`amp_level`无需配置,因为`CustomTrainOneStepCell`中已经包含了混合精度的计算逻辑。\n",
"\n",
@@ -818,38 +700,28 @@
"在训练过程中,如果不发生溢出,在更新scale_window次参数后,会尝试扩大scale的值,如果发生了溢出,则跳过参数更新,并缩小scale的值,入参scale_factor是控制扩大或缩小的步数,scale_window控制没有发生溢出时,最大的连续更新步数。\n",
"\n",
"具体用法如下,仅需将`FixedLossScaleManager`样例中定义LossScale,优化器和模型部分的代码改成如下代码:"
- ],
- "metadata": {
- "collapsed": false
- }
+ ]
},
{
"cell_type": "code",
"execution_count": null,
+ "metadata": {},
"outputs": [],
"source": [
"# Define Loss Scale, optimizer and model\n",
"scale_factor = 4\n",
"scale_window = 3000\n",
- "loss_scale_manager = ms.DynamicLossScaleManager(scale_factor, scale_window)\n",
+ "loss_scale_manager = amp.DynamicLossScaleManager(scale_factor, scale_window)\n",
"net_opt = nn.Momentum(network.trainable_params(), learning_rate=0.01, momentum=0.9)\n",
"model = ms.Model(network, net_loss, net_opt, metrics={\"Accuracy\": Accuracy()}, amp_level=\"O0\", loss_scale_manager=loss_scale_manager)"
- ],
- "metadata": {
- "collapsed": false,
- "pycharm": {
- "name": "#%%\n"
- }
- }
+ ]
},
{
"cell_type": "markdown",
+ "metadata": {},
"source": [
"> 图片引用自[automatic-mixed-precision](https://developer.nvidia.com/automatic-mixed-precision)"
- ],
- "metadata": {
- "collapsed": false
- }
+ ]
}
],
"metadata": {