# WarblerHomepage
**Repository Path**: onresize/WarblerHomepage
## Basic Information
- **Project Name**: WarblerHomepage
- **Description**: 流莺书签
- **Primary Language**: Unknown
- **License**: Apache-2.0
- **Default Branch**: main
- **Homepage**: None
- **GVP Project**: No
## Statistics
- **Stars**: 0
- **Forks**: 12
- **Created**: 2023-10-26
- **Last Updated**: 2023-10-26
## Categories & Tags
**Categories**: Uncategorized
**Tags**: None
## README
# 写在前面
#### 什么是流莺书签
“流莺”是我非常喜欢的一个词,本指四处飞翔鸣唱的莺鸟,就像我本身也是一个很随性的人。“流莺书签”是一个用来统一存放、管理收藏网址的网站,虽然浏览器本身自带收藏夹功能,并且还能创建多个文件夹,但我个人觉得查找起来依然很费劲,并且它长的很丑。所以我就想做一个好用又好看的收藏夹,取名“流莺书签”。
#### 为什么会有流莺书签
在开始这个项目之前,公司一直使用的是`VUE2`系列+`JS`,以及我👉👉[自己的博客](https://www.duwanyu.com)也是基于`VUE2`的,在`VUE3`正式版发布以后,一方面是公司有升级`VUE3`的打算,另外也是想学习更多的技术,提升自己的能力和竞争力,再加上`TS`看过有一段时间了也没有练过,正好一起练练手。
#### 项目地址
👉👉[项目预览地址](https://alanhzw.github.io),可以直接设置为浏览器主页或者桌面快捷方式进行使用
#### 源码地址
完全开源,大家可以随意研究,二次开发。当然还是十分欢迎大家点个Star⭐⭐⭐
👉👉[源码链接(gitee)](https://gitee.com/hzw_0174/WarblerHomepage) 👉👉[源码链接(github)](https://github.com/alanhzw/WarblerHomepage)
#### 项目展示
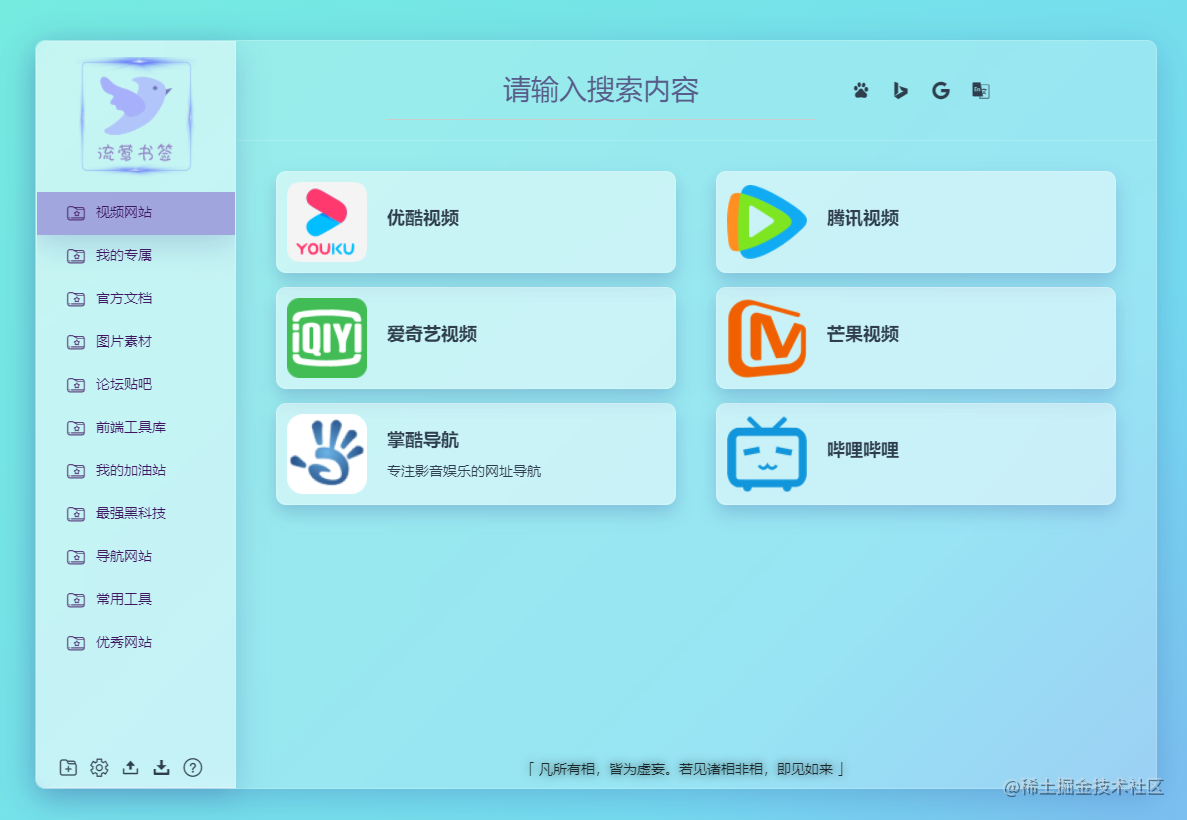
# 项目目录
基本是一个标准的**脚手架工程目录**,基础组件和业务组件分开存放,每一个组件都是一个文件夹,文件夹下一个`VUE文件`,一个`TS文件`,`TS文件`主要存放一些数据和类型声明。
```js
├── src
├── assets // 存放静态资源
├── baseComponents // 基础组件
│ └──Form // 表单组件
│ │ ├──Form.vue
│ │ └──index.ts
│ ├── Input // 输入框组件
│ │ ├──Input.vue
│ │ └──index.ts
│ ....
├── components // 业务组件
│ ├── BookMark // 页面主要内容相关组件
│ │ ├──BookMark.vue
│ │ ├──useLabels.ts
│ │ └──index.ts
│ .....
├── hooks // 封装的一些复用逻辑
├── styles // 样式
├── utils // 存放自己封装的工具
├── APP.vue
└── main.ts
```
# 项目功能/特色
## 功能
#### ✅标签操作
也就是分类,支持增加、删除,修改的操作
#### ✅书签操作
也就是保存下来的网址,支持增加、删除,修改的操作
#### ✅搜索
可以在输入框中输入内容后点击对应的图标进行搜索,目前支持百度、谷歌、必应,回车默认使用百度搜索
#### ✅翻译
点击翻译图标可以快捷进行翻译,目前支持百度
#### ✅导出,导入配置
由于没有账号功能,所以为了让辛辛苦苦积累的数据不会丢失,或者向小伙伴们分享自己的收藏,支持配置的导出备份和导入恢复
## 特色
#### 💎localStorage
项目使用`localStorage`存储数据,所以不要随意清除缓存,除非你已经做好备份,不然所有的收藏都会付之一炬了
#### 💎自动获取
输入目标网址后可以自动获取图标和标题,但是接口能力有限,并不能适用于所有网站,所以支持手动输入,也可使用默认的图标
#### 💎基础组件
项目没有使用任何的组件库,自己封装了一些基础组件,比如`Dialog`,`Message`,`Input`,`Form`等
## 项目没有使用的
#### ❎vue-router4,vuex4
`vue3`生态出了配套的`vue-router4`,`vuex4`,但由于项目本身并不复杂,所以没有用到,可能随着功能的扩充,以后会添加。
#### ❎<script setup>
这个语法糖倒是了解过,但是毕竟是初学`vue3`,所以还是决定先搞好基础,再搞**骚操作**,以后也许会找几个页面试一试这个语法糖。
# 重点介绍
由于篇幅过长,对于组件的介绍独立成文章,直接点击链接进行跳转查看。
## 项目搭建
👉👉[从零搭建一个Vite2+VUE3+TS工程](https://juejin.cn/post/6951302450892521480)
## 封装的基础组件
👉👉[基础组件(一):Button、Overlay、Dialog、Message](https://juejin.cn/post/6963941445451382792)
👉👉[基础组件(二):Form、Input](https://juejin.cn/post/6963931012191485982)
## 业务组件
👉👉业务组件,整体布局(暂无)
## 导入,导出配置
首先我是封装了上传文件,下载文件,两个工具函数,注释写的非常详细
```js
//file.ts
import createMessage from 'base/Message/index';
// 文件下载
export const downloadFile = (jsonStr: any) => {
// 将数据转换为字符串
jsonStr = JSON.stringify(jsonStr);
// 创建 blob 对象
const blob = new Blob([jsonStr]);
// 创建一个a标签
const el = document.createElement('a');
// 创建一个 URL 对象并传给 a 的 href
el.href = URL.createObjectURL(blob);
// 设置下载的默认文件名
el.download = '流莺书签数据备份.json';
// 模拟点击链接进行下载
el.click();
};
// 文件上传
export const uploadFile = (e: any) => {
return new Promise((reject) => {
// 如果没有选择文件就什么也不做
if (e.target.value === '' || e.target.files.length < 1) {
return;
}
// 如果不是json格式的文件,给出提示
if (e.target.files[0].type !== 'application/json') {
createMessage('请上传由本站导出的json格式的文件 !');
return;
}
// 创建 FileReader对象
const reader = new FileReader();
// 把文件读取为字符串
reader.readAsText(e.target.files[0]);
// 文件读取完成
reader.onload = function (ev: any) {
reject(ev);
};
});
};
```
在组件中使用,我是隐藏了上传文件的`input`,用一个图标来模拟点击上传按钮,文件读取成功后,进入`promise`的`reject`状态,然后要验证一下上传的文件是否符合格式。如果不符合给出错误提示,符合的话就替换一下数据。
```js
//这里是简略过的伪代码,详情请查阅源码
//此处省略css,详情请查看源码
```
## 自动获取图标
本身没有写爬虫的经历,经过查阅资料,照猫画虎的简单写了一个爬取网站图标和标题的接口。所以有些网站就爬不下来,如果有更好的爬取方式,请大家不吝赐教。
我的博客是基于`express`的,而且是部署在我自己服务器上的,所以直接坐了个顺风车,在我的博客项目里写了这个接口。
```js
/*
* @Description:获取网站标题和图标的爬虫
* 1.某些网站有大佬设计了反爬,我就是写了最基本的爬虫,根本进不去网站
* 2.某些网站虽然能进去,但是图标经过了各种骚操作,我找不到
* 所以前端支持自动获取失败的时候,手动选择图标
* 3.错误码 300 没有填写网址 301请求失败
* 4.请求失败 也会在error返回text字段 里面包含网站图标 只不过取不到网站内容
* 我们不需要内容 只需要title和icon 所以我们在错误处理中也进行一次爬取
*/
// 用来发送请求的模块
const superagent = require('superagent');
// 用来托管html的模块
const cheerio = require('cheerio');
//获取网站主域名
const getFinallyUrl = (targetUrl) => {
// 将目标域名以“//”进行分割
const urlArray = targetUrl.split('//');
//定义最终的域名
let finallyUrl = '';
//这个判断的意思是 如果数组存在第[1]项 那么证明这个网址是以http/https开头的 否则就是不带有http/https的
if (urlArray[1]) {
//如果带有http/https 咱们就把http/https给拼上返回
finallyUrl = urlArray[0] + '//' + urlArray[1];
} else {
//如果不带有http/https 咱也不知道是http还是https 就返回原来的值
finallyUrl = urlArray[0] + '/';
}
return finallyUrl;
};
//获取最终的图标地址
const getFinallyIcon = (finallyUrl, icon) => {
let finallyIcon = '';
if (icon) {
//这个判断的意思是 如果存在://或者www. 则证明路径中是绝对路径 否则是相对路径
if (icon.indexOf('//') > -1 || icon.indexOf('www.') > -1) {
//如果是绝对路径直接使用
finallyIcon = icon;
} else {
//如果是相对路径的话,就给拼接上当前网站的主域名
finallyIcon = finallyUrl + icon;
}
}
return finallyIcon;
};
//获取标题和图标地址
const getTitleAndIcon = (finallyUrl, text) => {
//获取到的网页是本文格式,node自身无法解析,所以交给cheerio进行托管
const $ = cheerio.load(text);
//获取网站标题
const title = $('title').text();
//由于不同网站的icon格式不同,这里预设了几种
//但是由于某些网站的大佬进行了各种包装,导致基本的爬取方式获取不到
const icon1 = $("[rel='icon']").attr('href');
const icon2 = $("[href$='.ico']").attr('href');
const icon3 = $("[rel='shortcut icon']").attr('href');
let icon = icon1 || icon2 || icon3;
//获取最终图标的地址
const finallyIcon = getFinallyIcon(finallyUrl, icon);
return {
title,
finallyIcon,
};
};
module.exports = async (req, res) => {
//从请求体里获取将要爬取网站的url
const targetUrl = req.body.targetUrl;
//判断一下url是否为空,虽然前端也会校验
if (!targetUrl) {
return res.json({
errorStatus: 300,
errorMsg: '目标网址路径不可为空',
});
}
const finallyUrl = getFinallyUrl(targetUrl);
//模拟打开对应url的网页
superagent
.get(targetUrl)
.then((superagentRes) => {
//成功的话直接取text
const { title, finallyIcon } = getTitleAndIcon(finallyUrl, superagentRes.text);
//接口返回标题和图标地址
res.json({
title: title,
icon: finallyIcon,
});
})
.catch((error) => {
console.log('🚀🚀~ error:', error);
//错误处理
//部分网站失败了也会有text字段 只不过取不到网站内容 我们不需要内容 只需要title和icon
const { title, finallyIcon } = getTitleAndIcon(finallyUrl, error.response.text);
res.json({
errorStatus: 301,
errorMsg: error.message,
title: title,
icon: finallyIcon,
});
});
};
```
# 接下来的开发计划
💡支持标签,书签的拖拽排序,以及可以把书签拖到其他的标签中
💡移动端适配,现在只支持电脑浏览器
💡更换主题,网站自身提供暗、亮两套主题,并支持自定义
# 链接整合
🔊项目预览地址(GitHub Pages):👉👉https://alanhzw.github.io
🔊项目预览备用地址(自己的服务器):👉👉http://warbler.duwanyu.com
🔊源码地址(gitee):👉👉https://gitee.com/hzw_0174/warbler-homepage
🔊源码地址(github):👉👉https://github.com/alanhzw/WarblerHomepage
🔊流莺书签-从零搭建一个Vite+Vue3+Ts项目:👉👉https://juejin.cn/post/6951302450892521480
🔊流莺书签-基础组件介绍(Form,Input):👉👉https://juejin.cn/post/6963931012191485982
🔊流莺书签-基础组件(Button,Overlay,Dialog,Message):👉👉https://juejin.cn/post/6963941445451382792
🔊流莺书签-业务组件介绍:👉👉暂无
🔊我的博客:👉👉https://www.duwanyu.com