diff --git "a/content/zh/post/wzr/opengauss-\350\241\214\345\255\230\350\241\250\344\270\216\345\210\227\345\255\230\350\241\250.md" "b/content/zh/post/wzr/opengauss-\350\241\214\345\255\230\350\241\250\344\270\216\345\210\227\345\255\230\350\241\250.md"
new file mode 100644
index 0000000000000000000000000000000000000000..c0f72760355eb54b22acb209b5f94cdf53390423
--- /dev/null
+++ "b/content/zh/post/wzr/opengauss-\350\241\214\345\255\230\350\241\250\344\270\216\345\210\227\345\255\230\350\241\250.md"
@@ -0,0 +1,236 @@
+**+++**
+**title="openGauss社区入门(opengauss-行存表与列存表)"**
+**date="2022-08-26"**
+**tags=["openGauss社区开发入门"]**
+**archives=“2022-08”**
+**author=“wangrururu”**
+**summary="openGauss社区开发入门"**
+**img="/zh/post/wzr/title/title.jpg"**
+**times="21:15"**
+**+++**
+1.行式存储和列式存储的区别:
+(1)行式存储倾向于结构固定,列式存储倾向于结构弱化。
+(2)行式存储一行数据仅需要一个主键,列式存储一行数据需要多份主键。
+(3)行式存储的是业务数据,而列式存储除了业务数据之外,还需要存储列名。
+(4)行式存储更像是一个Java Bean,所有的字段都提前定义好,且不能改变;列式存储更像是一个Map,不提前定义,随意往里面添加key/value。
+2.列存表
+(1)列存表支持的数据类型:
+
+| 类别 | 类型 | 长度 |
+| --- | --- | --- |
+| Numeric Types | smallint | 2 |
+| | integer | 4 |
+| | bigint | 8 |
+| | decimal | -1 |
+| | numeric | -1 |
+| | real | 4 |
+| | double precision | 8 |
+| | smallserial | 2 |
+| | serial | 4 |
+| | bigserial | 8 |
+| | largeserial | -1 |
+| Monetary Types | money | 8 |
+| Character Types | character varying(n), varchar(n) | -1 |
+| | character(n), char(n) | n |
+| | character、char | 1 |
+| | text | -1 |
+| | nvarchar | -1 |
+| | nvarchar2 | -1 |
+| Date/Time Types | timestamp with time zone | 8 |
+| | timestamp without time zone | 8 |
+| | date | 4 |
+| | time without time zone | 8 |
+| | time with time zone | 12 |
+| | interval | 16 |
+| big object | clob | -1 |
+
+(2)列存表的特性
+•列存表不支持数组。
+•列存表不支持生成列。
+•列存表不支持创建全局临时表。
+•创建列存表的数量建议不超过1000个。
+•列存表的表级约束只支持PARTIAL CLUSTER KEY、UNIQUE、PRIAMRY KEY,不支持外键等表级约束。
+•列存表的字段约束只支持NULL、NOT NULL和DEFAULT常量值、UNIQUE和PRIMARY KEY。
+•列存表支持delta表,受参数enable_delta_store控制是否开启,受参数deltarow_threshold控制进入delta表的阀值。
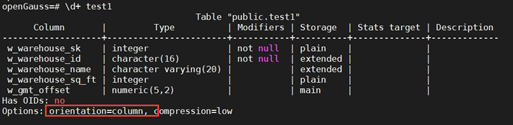
+(3)创建一个列存表
+CREATE TABLE test1
+(
+W_WAREHOUSE_SK INTEGER NOT NULL,
+W_WAREHOUSE_ID CHAR(16) NOT NULL,
+W_WAREHOUSE_NAME VARCHAR(20) ,
+W_WAREHOUSE_SQ_FT INTEGER ,
+W_GMT_OFFSET DECIMAL(5,2)
+) WITH (ORIENTATION = COLUMN);
+
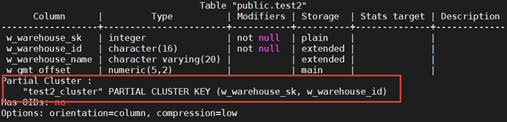
+(4)创建局部聚簇存储的列存表。
+CREATE TABLE test2
+(
+ W_WAREHOUSE_SK INTEGER NOT NULL,
+ W_WAREHOUSE_ID CHAR(16) NOT NULL,
+ W_WAREHOUSE_NAME VARCHAR(20) ,
+ W_GMT_OFFSET DECIMAL(5,2),
+ PARTIAL CLUSTER KEY(W_WAREHOUSE_SK, W_WAREHOUSE_ID)
+) WITH (ORIENTATION = COLUMN);
+
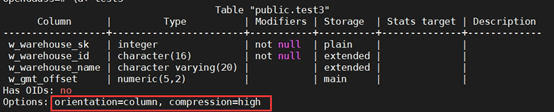
+(5) 创建一个带压缩的列存表。
+CREATE TABLE test3
+(
+ W_WAREHOUSE_SK INTEGER NOT NULL,
+ W_WAREHOUSE_ID CHAR(16) NOT NULL,
+ W_WAREHOUSE_NAME VARCHAR(20) ,
+ W_GMT_OFFSET DECIMAL(5,2)
+) WITH (ORIENTATION = COLUMN, COMPRESSION=HIGH);
+
+3.行存表
+(1)创建一个行存表
+CREATE TABLE test4
+(
+ W_WAREHOUSE_SK INTEGER NOT NULL,
+ W_WAREHOUSE_ID CHAR(16) NOT NULL,
+ W_WAREHOUSE_NAME VARCHAR(20) ,
+ W_GMT_OFFSET DECIMAL(5,2)
+);
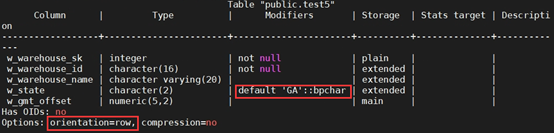
+(2)创建表,并指定W_STATE字段的缺省值为GA。
+CREATE TABLE test5
+(
+ W_WAREHOUSE_SK INTEGER NOT NULL,
+ W_WAREHOUSE_ID CHAR(16) NOT NULL,
+ W_WAREHOUSE_NAME VARCHAR(20) ,
+ W_STATE CHAR(2) DEFAULT 'GA',
+ W_GMT_OFFSET DECIMAL(5,2)
+);
+
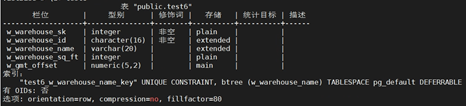
+(3)创建表,并在事务结束时检查W_WAREHOUSE_NAME字段是否有重复。
+CREATE TABLE test6
+(
+ W_WAREHOUSE_SK INTEGER NOT NULL,
+ W_WAREHOUSE_ID CHAR(16) NOT NULL,
+ W_WAREHOUSE_NAME VARCHAR(20) UNIQUE DEFERRABLE,
+ W_WAREHOUSE_SQ_FT INTEGER ,
+ W_GMT_OFFSET DECIMAL(5,2)
+);
+
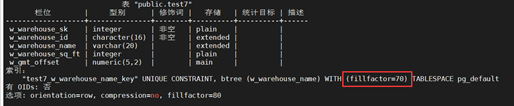
+(4)创建一个带有70%填充因子的表
+CREATE TABLE test7
+(
+ W_WAREHOUSE_SK INTEGER NOT NULL,
+ W_WAREHOUSE_ID CHAR(16) NOT NULL,
+ W_WAREHOUSE_NAME VARCHAR(20) ,
+ W_WAREHOUSE_SQ_FT INTEGER ,
+ W_GMT_OFFSET DECIMAL(5,2),
+ UNIQUE(W_WAREHOUSE_NAME) WITH(fillfactor=70)
+);
+
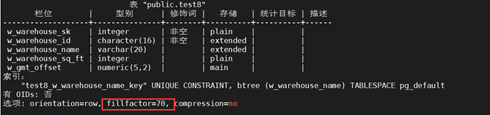
+CREATE TABLE test8
+(
+ W_WAREHOUSE_SK INTEGER NOT NULL,
+ W_WAREHOUSE_ID CHAR(16) NOT NULL,
+ W_WAREHOUSE_NAME VARCHAR(20) UNIQUE,
+ W_WAREHOUSE_SQ_FT INTEGER ,
+ W_GMT_OFFSET DECIMAL(5,2)
+) WITH(fillfactor=70);
+
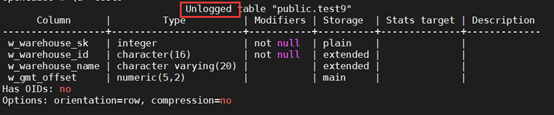
+(5)创建表,并指定该表数据不写入预写日志
+CREATE UNLOGGED TABLE test9
+(
+ W_WAREHOUSE_SK INTEGER NOT NULL,
+ W_WAREHOUSE_ID CHAR(16) NOT NULL,
+ W_WAREHOUSE_NAME VARCHAR(20) ,
+ W_GMT_OFFSET DECIMAL(5,2)
+);
+
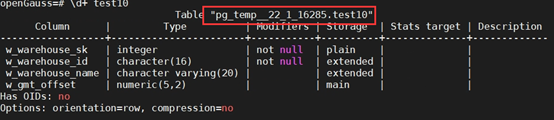
+(6)创建临时表
+CREATE TEMPORARY TABLE test10
+(
+ W_WAREHOUSE_SK INTEGER NOT NULL,
+ W_WAREHOUSE_ID CHAR(16) NOT NULL,
+ W_WAREHOUSE_NAME VARCHAR(20) ,
+ W_GMT_OFFSET DECIMAL(5,2)
+);
+
+(7)创建本地临时表,并指定提交事务时删除该临时表数据
+CREATE TEMPORARY TABLE test11
+(
+ W_WAREHOUSE_SK INTEGER NOT NULL,
+ W_WAREHOUSE_ID CHAR(16) NOT NULL,
+ W_WAREHOUSE_NAME VARCHAR(20) ,
+ W_GMT_OFFSET DECIMAL(5,2)
+) ON COMMIT DELETE ROWS;
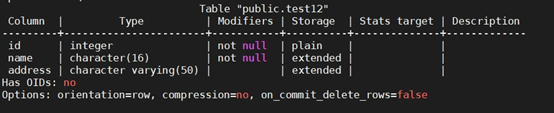
+(8)创建全局临时表,并指定会话结束时删除该临时表数据
+CREATE GLOBAL TEMPORARY TABLE test12
+(
+ ID INTEGER NOT NULL,
+ NAME CHAR(16) NOT NULL,
+ ADDRESS VARCHAR(50)
+) ON COMMIT PRESERVE ROWS;
+
+(9)创建表时,不希望因为表已存在而报错
+CREATE TABLE IF NOT EXISTS test13
+(
+ W_WAREHOUSE_SK INTEGER NOT NULL,
+ W_WAREHOUSE_ID CHAR(16) NOT NULL,
+ W_WAREHOUSE_NAME VARCHAR(20) ,
+ W_GMT_OFFSET DECIMAL(5,2)
+);
+(10)创建普通表空间
+CREATE TABLESPACE DS_TABLESPACE1 RELATIVE LOCATION 'tablespace/tablespace_1';
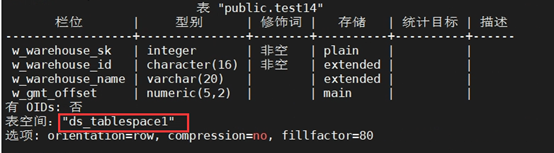
+(11)创建表时,指定表空间
+CREATE TABLE test14
+(
+ W_WAREHOUSE_SK INTEGER NOT NULL,
+ W_WAREHOUSE_ID CHAR(16) NOT NULL,
+ W_WAREHOUSE_NAME VARCHAR(20) ,
+ W_GMT_OFFSET DECIMAL(5,2)
+) TABLESPACE DS_TABLESPACE1;
+
+(12)创建表时,单独指定W_WAREHOUSE_NAME的索引表空间
+CREATE TABLE test15
+(
+ W_WAREHOUSE_SK INTEGER NOT NULL,
+ W_WAREHOUSE_ID CHAR(16) NOT NULL,
+ W_WAREHOUSE_NAME VARCHAR(20) UNIQUE USING INDEX TABLESPACE DS_TABLESPACE1,
+ W_GMT_OFFSET DECIMAL(5,2)
+);
+
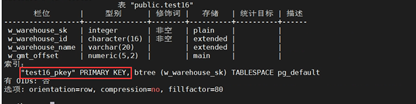
+(13)创建一个有主键约束的表
+CREATE TABLE test16
+(
+ W_WAREHOUSE_SK INTEGER PRIMARY KEY,
+ W_WAREHOUSE_ID CHAR(16) NOT NULL,
+ W_WAREHOUSE_NAME VARCHAR(20) ,
+ W_GMT_OFFSET DECIMAL(5,2)
+);
+
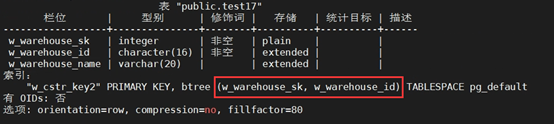
+(14) 创建一个有复合主键约束的表
+CREATE TABLE test17
+(
+ W_WAREHOUSE_SK INTEGER NOT NULL,
+ W_WAREHOUSE_ID CHAR(16) NOT NULL,
+ W_WAREHOUSE_NAME VARCHAR(20) ,
+ CONSTRAINT W_CSTR_KEY2 PRIMARY KEY(W_WAREHOUSE_SK,W_WAREHOUSE_ID)
+);
+
+(15) 定义一个检查列约束
+CREATE TABLE test18
+(
+ W_WAREHOUSE_SK INTEGER PRIMARY KEY CHECK (W_WAREHOUSE_SK > 0),
+ W_WAREHOUSE_ID CHAR(16) NOT NULL,
+ W_WAREHOUSE_NAME VARCHAR(20) CHECK (W_WAREHOUSE_NAME IS NOT NULL),
+ W_GMT_OFFSET DECIMAL(5,2)
+);
+
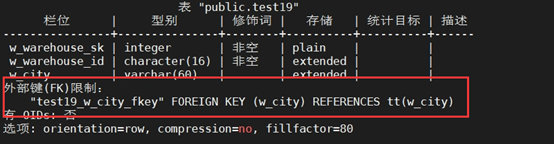
+(16) 创建一个有外键约束的表
+CREATE TABLE tt
+(
+ W_CITY VARCHAR(60) PRIMARY KEY,
+ W_ADDRESS TEXT
+);
+CREATE TABLE test19
+(
+ W_WAREHOUSE_SK INTEGER NOT NULL,
+ W_WAREHOUSE_ID CHAR(16) NOT NULL,
+ W_CITY VARCHAR(60) ,
+ FOREIGN KEY(W_CITY) REFERENCES tt (W_CITY)
+);
+
+
diff --git a/content/zh/post/wzr/wzr.md b/content/zh/post/wzr/wzr.md
deleted file mode 100644
index 64fd36ceca1fe2aaebb545bc195b54515c38347f..0000000000000000000000000000000000000000
--- a/content/zh/post/wzr/wzr.md
+++ /dev/null
@@ -1,3 +0,0 @@
-**+++**
**title="openGauss社区入门(opengauss-事务管理小结)"**
**date="2022-08-11"**
**tags=["openGauss社区开发入门"]**
**archives=“2022-08”**
**author=“wangrururu”**
**summary="openGauss社区开发入门"**
**img="/zh/post/wzr/title/title.jpg"**
**times="10:06"**
**+++**
-
-**1.事务概念:**
在日常操作中,对于一组相关操作通常需要其全部成功或全部失败,在关系型数据库中,这组相关操作称为事务。
**2.事务特性:**
**原子性**(atomicity,A):事务必须以一个整体单元的形式工作,对于其数据的修改,要么全部执行,幺要么全都不执行。如果只执行事务中多个操作的前半部分就会出现错误,那么必须回滚所有操作,让数据在逻辑上回滚到先前的状态。
**一致性**(consistency,C):事务在完成时,必须使所有的数据都保持一致状态。
**隔离性**(isolation,I):事务查看数据时数据所处的状态,要么是零一并发事务修改它之前的状态,要么是另一事务修改它之后的状态,事务是不会查看中间状态的数据的。
**持久性**(durability,D):事务完成之后,对于系统的影响是永久性的。即使今后出现致命的系统故障,数据也将一直保持。
**3. 事务的隔离级别**
openGauss支持的事务隔离级别有两个:
**Read Committed**(读提交):只有在事务提交后,其更新结果才会被其他事务看见。可以解决脏读问题。
**Repeateble Read**(重复读):在一个事务中,对于同一份数据的读取结果总是相同的,无论是否有其他事务对这份数据进行操作,以及这个事务是否提交。可以解决脏读、不可重复读。
**4.事务语法参数:**
(1)**transaction_isolation**:设置当前事务的隔离级别。
取值范围:字符串,只识别以下字符串,大小写空格敏感:
serializable:等价于REPEATABLE READ。
read committed:只能读取已提交的事务的数据(缺省),不能读取到未提交的数据。
repeatable read:仅能读取事务开始之前提交的数据,不能读取未提交的数据以及在事务执行期间由 其它并发事务提交的修改。
default:设置为default_transaction_isolation所设隔离级别。
默认值:read committed
(2)**transaction_read_only**:设置当前事务是只读事务。该参数在数据库恢复过程中/在备机里固定为on;否则为default_transaction_read_only的值。
取值范围:布尔型
on表示设置当前事务为只读事务。
off表示该事务可以是非只读事务。
默认值:off
(3)**xc_maintenance_mode**:设置系统进入维护模式。(谨慎打开这个开关,避免引起openGauss数据不一致)
取值范围:布尔型
on表示该功能启用。
off表示该功能被禁用。
默认值:off
(4)**allow_concurrent_tuple_update**:设置是否允许并发更新。
取值范围:布尔型
on表示该功能启用。
off表示该功能被禁用。
默认值:on
(5)**transaction_deferrable**:指定是否允许一个只读串行事务延迟执行,使其不会执行失败。
取值范围:布尔型
on表示允许执行。
off表示不允许执行。
默认值:off
(6)**enable_show_any_tuples**:该参数只有在只读事务中可用,用于分析。
取值范围:布尔型
on/true表示表中元组的所有版本都会可见。
off/false表示表中元组的所有版本都不可见。
默认值:off
(7)**replication_type**:标记当前HA模式是单主机模式、主备从模式还是一主多备模式。该参数用户不能自己去设置参数值。
取值范围:0~2
2 表示单主机模式,此模式无法扩展备机。
1 表示使用一主多备模式,全场景覆盖,推荐使用。
0 表示主备从模式,目前此模式暂不支持。
默认值:1
(8)**pgxc_node_name**:指定节点名称。在备机请求主机进行日志复制时,如果application_name参数没有被设置,那么pgxc_node_name参数会被用来作为备机在主机上的流复制槽名字。该流复制槽的命名方式为 "该参数值_备机ip_备机port"。其中,备机ip和备机port取自replconninfo参数中指定的备机ip和端口号。该流复制槽最大长度为61个字符,如果拼接后的字符串超过该长度,则会使用截断后的pgxc_node_name进行拼接,以保证流复制槽名字长度小于等于61个字符。此参数修改后会导致连接数据库实例失败,不建议进行修改。
取值范围:字符串
默认值:当前节点名称
(9)**enable_defer_calculate_snapshot**:延迟计算快照的xmin和oldestxmin,执行1000个事务或者间隔1s才触发计算,设置为on时可以在高负载场景下减少计算快照的开销,但是会导致oldestxmin推进较慢,影响垃圾元组回收,设置为off时xmin和oldestxmin可以实时推进,但是会增加计算快照时的开销。
取值范围:布尔型。
on表示延迟计算快照xmin和oldestxmin。
off表示实时计算快照xmin和oldestxmin。
默认值:on。
**5.自治事务**
在主事务执行过程中新启的独立的事务。自治事务的提交和回滚不会影响主事务已提交的数据,同时自治事务也不受主事务影响。自治事务在存储过程、函数和匿名块中定义,用PRAGMA AUTONOMOUS_TRANSACTION关键字来声明。
例如存储过程中含自治事务:
--建表
create table t2(a int, b int);
insert into t2 values(1,2);
select * from t2;
--创建包含自治事务的存储过程
CREATE OR REPLACE PROCEDURE autonomous_4(a int, b int) AS
DECLARE
num3 int := a;
num4 int := b;
PRAGMA AUTONOMOUS_TRANSACTION;
BEGIN
insert into t2 values(num3, num4);
END;
/
--创建调用自治事务存储过程的普通存储过程
CREATE OR REPLACE PROCEDURE autonomous_5(a int, b int) AS
DECLARE
BEGIN
insert into t2 values(666, 666);
autonomous_4(a,b);
rollback;
END;
/
--调用普通存储过程
select autonomous_5(11,22);
--查看表结果
select * from t2 order by a;
结果为:**主事务的回滚,不会影响自治事务已经提交的内容**。

diff --git a/content/zh/post/wzr/wzr1.md b/content/zh/post/wzr/wzr1.md
deleted file mode 100644
index eb2968e0d3df94c6f0d72a18ecdd5d74ceb7cbb0..0000000000000000000000000000000000000000
--- a/content/zh/post/wzr/wzr1.md
+++ /dev/null
@@ -1 +0,0 @@
-**+++**
**title="openGauss社区入门(opengauss-逻辑备份命令)"**
**date="2022-08-19"**
**tags=["openGauss社区开发入门"]**
**archives=“2022-08”**
**author=“wangrururu”**
**summary="openGauss社区开发入门"**
**img="/zh/post/wzr/title/title.jpg"**
**times="19:15"**
**+++**
openGauss支持使用gs_dump工具导出表级的内容,包含表定义和表数据。视图、序列和外表属于特殊的表。用户可通过灵活的自定义方式导出表内容,不仅支持选定一个表或多个表的导出,还支持排除一个表或者多个表的导出。可根据需要自定义导出如下信息:
•导出表全量信息,包含表数据和表定义。
•仅导出数据,不包含表定义。
•仅导出表定义。
1.常用参数
(1)-U 连接数据库的用户名。
(2)-W 指定用户连接的密码。
(3)-f 将导出文件发送至指定目录文件夹。如果这里省略,则使用标准输出。
(4)-p 指定服务器所侦听的TCP端口或本地Unix域套接字后缀,以确保连接。
(5)dbname 需要导出的数据库名称。
(6)-t 指定导出的表(或视图、序列、外表),可以使用多个-t选项来选择多个表,也可以使用通配符指定多个表对象。
(7)-F 选择导出文件格式。-F参数值如下:
•p:纯文本格式
•c:自定义归档
•d:目录归档格式
•t:tar归档格式
(8)-T 不转储的表(或视图、或序列、或外表)对象列表,可以使用多个-t选项来选择多个表,也可以使用通配符指定多个表对象。
2.示例
(1)导出表的定义和数据,导出文件格式为文本格式。
gs_dump -f /home/opengauss300_0708/backup/m.sql -p 3436 postgres -t dd1 -F p

(2)只导出表的数据,导出文件格式为tar归档格式。
gs_dump -f /home/opengauss300_0708/backup/m.tar -p 3436 postgres -t dd1 -a -F t

(3)导出表的定义,导出文件格式为目录归档格式。
gs_dump -f /home/opengauss300_0708/backup/m -p 3436 postgres -t dd1 -s -F d

(4)不导出表,导出文件格式为自定义归档格式。
gs_dump -f /home/opengauss300_0708/backup/m.dmp -p 3436 postgres -T dd1 -F c

(5)同时导出两个表,导出文件格式为文本格式。
gs_dump -f /home/opengauss300_0708/backup/m1.sql -p 3436 postgres -t dd1 -t dd2 -F p

(6)导出时,排除两个表,导出文件格式为文本格式。
gs_dump -f /home/opengauss300_0708/backup/m2.sql -p 3436 postgres -T dd1 -T dd2 -F p

(7)导出表1的定义和数据,只导出表2的定义,导出文件格式为tar归档格式。
gs_dump -f /home/opengauss300_0708/backup/m3.tar -p 3436 postgres -t dd1 -t dd2 --exclude-table-data dd2 -F t

(8)导出表的定义和数据,并对导出文件进行加密,导出文件格式为文本格式。
gs_dump -f /home/opengauss300_0708/backup/m4.sql -p 3436 postgres -t dd1 --with-encryption AES128 --with-key abcdefg_?1234567 -F p

(9)导出public模式下所有表(包括视图、序列和外表)和自定义模式中的表,包含数据和表定义,导出文件格式为自定义归档格式。
gs_dump -f /home/opengauss300_0708/backup/m5.dmp -p 3436 postgres -t public.* -t myschema.dd1 -F c
