diff --git a/chap-36-program-profiling/.keep b/chap-36-program-profiling/.keep
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/chap-36-program-profiling/Chapter-36-Program-Profiling.md b/chap-36-program-profiling/Chapter-36-Program-Profiling.md
new file mode 100644
index 0000000000000000000000000000000000000000..b47773c7b30de655a4a59f75dcbcb18669ac890d
--- /dev/null
+++ b/chap-36-program-profiling/Chapter-36-Program-Profiling.md
@@ -0,0 +1,1941 @@
+==前面还是没啥问题的,主要是刚刚收尾的时候有点坐不住了-_-,不过应该还好,有些不好翻的原话去掉了或者自己换了个好理解的说法。搞得不好尽管骂(´・ω・`)==
+
+# 第 36 章:Program Profiling
+
+
+
+## 1、通过本章你能学到什么?
+
+- 什么是 `profiling`
+- 怎样给你的程序创建一个 `CPU profile`
+- 怎样给你的程序创建一个 `Heap profile`
+- 怎样使用 `pprof` 工具分析一个 profile
+- 一些常见的 CPU 使用率优化技术
+
+## 2、涉及到的概念
+
+- Profile
+- pprof
+- Protocol Buffers
+- protoc
+- CPU
+- Heap profile
+
+## 3、什么是 profiling?
+
+Profiling (分析)是一种程序优化技术。『 分析程序 』表示收集程序运行时的详细统计信息。这些统计数据可以是 CPU 使用率、内存分配情况、程序执行花费的时间、函数调用的信息等等。
+
+但这和基准测试( `Benchmark` )有什么区别?基准测试收集指定函数的运行时信息。分析( Profiling )是对整个程序的统计数据的收集。
+
+## 4、为什么需要 profiling?
+
+Profiling 经常用在我们观察到程序的性能下降时。该工具用来了解程序性能不佳的原因。
+
+代码库的静态分析可能不足以检测出程序表现变糟的原因。基准测试针对的是单独的一个函数的性能表现;这不足以让我们了解整个程序的运行情况。
+
+Profiling 也可以成为改进程序设计的工具。Go 是一种性能相对较高的语言,但设计不当的程序也会遇到性能问题。在 profiling 的帮助下,这些问题可以很容易地理解和纠正。
+
+## 5、开始了解 profiling
+
+为了分析程序,我们可以使用 `runtime/pprof` 包,它公开了必要的 API 来启动和停止 profiling。
+
+在本节中,我们将分析一个对整数求和的程序。该程序仅包含一个 main 包,其中包含一个名为 doSum 的函数。此函数将对从 0 到 787766776 的整数求和:
+
+```go
+package main
+
+import (
+ "fmt"
+)
+
+func main() {
+ result := doSum()
+ fmt.Println(result)
+}
+
+func doSum()int{
+ sum := 0
+ for i := 0; i < 787766777; i++ {
+ sum += i
+ }
+ return sum
+}
+```
+
+下一步是在我们的 main 函数中添加对 pprof API 的调用:
+
+```go
+// profiling/getting-started/main.go
+
+f, err := os.Create("profile.pb.gz")
+if err != nil {
+ log.Fatal(err)
+}
+defer f.Close()
+
+err = pprof.StartCPUProfile(f)
+if err != nil {
+ log.Fatal(err)
+}
+defer pprof.StopCPUProfile()
+```
+
+这段代码必须放在 main 函数中。它将创建一个名为『 profile.pb.gz 』的文件。之后它将开始 CPU profiling 并将分析结果写入刚刚打开的文件中。在 main 函数的末尾,我们将调用 `pprof.StopCPUProfile()`。为了可读性,我们使用了 defer 延迟执行。
+
+然后我们必须构建程序(后面我们会用到二进制文件 `gettingstarted`):
+
+```shell
+$ go build -o gettingstarted main.go
+```
+
+这将会在当前目录下创建一个二进制文件。为了产生数据,我们需要运行程序:
+
+```shell
+$ ./gettingstarted
+```
+
+执行后,你可以看到 `profile.pb.gz` 已经创建在当前目录下了。你可以试着直接打开文件来查看结果,但这是一个不明智的做法。这个文件是二进制格式而且是压缩过的。我们需要一个工具来帮助我们查看分析结果。
+
+这个工具就是 `pprof`,由 Google 开发,用来 『 查看和分析 profiling 后的数据 』。`pprof` 可以读取 profile 文件并生成易读的报告。我们只需要使用 `pprof` 的命令行接口就可以查看我们 profiling 后的统计信息了(在本章的后续部分,你也会了解到其他的可视化技术):
+
+```shell
+$ go tool pprof gettingstarted cpu.profile
+```
+
+此命令将启动交互模式。你必须键入命令才能显示统计信息:
+
+```shell
+$ go tool pprof gettingstarted profile.pb.gz
+File: gettingstarted
+Type: cpu
+Time: Jan 1, 2021 at 9:27pm (CET)
+Duration: 413.54ms, Total samples = 220ms (53.20%)
+Entering interactive mode (type "help" for commands, "o" for options)
+(pprof)
+```
+
+在标准输出中,你可以看到 pprof 显示:
+
+- 二进制文件的名称( 这里是 `gettingstarted` )
+- profile 文件的类型( 这里是 `cpu` )
+- profile 文件的生成日期
+- 程序执行的总持续时间( 413ms )
+- 总『 样本( sample ) 』(我们稍后会谈到样本是什么,因为它可能会造成困惑)
+
+## 6、读取 profile 文件
+
+为了能够读取 profile 文件,我们需要安装 Google 提供的 `protoc` 工具。为啥呢?因为 profile 文件有特定的格式,它是 `protobuf` 格式的文件。
+
+### 6.1、简述 Protocol Buffers( protobuf )
+
+`Protocol Buffers` 由 Google 内部开发并开源。它可以将结构化数据转换为 **轻量级** 的可以用来 **存储** 和进行 **网络传输** 的格式。将结构化数据转换为特定格式的过程称为 **序列化**。使用这种方法序列化(或编码)的数据非常轻量。返回的格式称为 『 **binary wire**(二进制线) 』。
+
+与 XML 或 JSON 不同,字段的名称不会转换为数据的序列化版本。因此,消息可以更轻量。你需要某种 **规范** 来读取序列化消息。序列化规范是一个『 proto file(原型文件) 』。Proto 文件具有 .proto 扩展名。
+
+Google 团队开发了多种语言(C++、C#、Dart、Go、Java、Python、Ruby、Objective-C 等等)的工具来轻松序列化和反序列化数据。
+
+在下一节中,我们将使用其中一个工具来反序列化 profile 文件。
+
+### 6.2、安装 protocol buffer 编译器( protoc )
+
+#### 6.2.1、下载最新版本
+
+首先,你必须下载最新版本的编译器。在撰写本文时,最新版本为 3.15.2。我将在以下几行中为你提供下载此特定版本的命令。请始终下载最新版本!要获取最新版本号,请查看 GitHub 页面:https://github.com/protocolbuffers/protobuf/releases。
+
+我们将下载已编译的软件版本。当然,如果你的计算机上安装了 C++ 编译器,你可以自己构建它,但有点多此一举了。
+
+你可以通过链接下载压缩文件:https://github.com/protocolbuffers/protobuf/releases
+
+你也可以使用下面的终端命令:
+
+- Linux (64 位)用户
+
+```shell
+$ curl -OL https://github.com/protocolbuffers/protobuf/releases/download/v3.15.2/protoc-3.15.2-linux-x86_64.zip
+```
+
+- Mac 用户
+
+```shell
+$ curl -OL https://github.com/protocolbuffers/protobuf/releases/download/v3.15.2/protoc-3.15.2-osx-x86_64.zip
+```
+
+对于 Mac 和 Linux,我们使用 `curl`,一种 CLI(命令行) 工具来发送 HTTP 请求。我们传递两个标志(-OL)给命令:
+
+-O:将下载的内容写入文件(与服务器上的文件命名方式相同)
+
+-L:跟随重定向(继续访问返回的重定向链接),因为 GitHub 将发布存储在 Amazon AWS S3 存储桶(一种云存储服务)上
+
+对于 Windows 用户,下载地址是:
+
+```shell
+https://github.com/protocolbuffers/protobuf/releases/download/v3.6.1/protoc-3.6.1-win32.zip
+```
+
+#### 6.2.2、解压文件
+
+Linux 和 Mac 用户可以直接使用 unzip 进行解压:
+
+```shell
+$ cd where/you/downloaded/the/zip/file
+$ unzip protoc-3.15.2-osx-x86_64.zip -d protoc-3.15.2
+```
+
+`-d` 标志将解压后的文件放到指定的目录下(目录不存在会被创建)
+
+对于 Windows 用户,建议直接使用图形接口来解压文件
+
+#### 6.2.3、添加到环境变量
+
+对于 Linux 和 Mac 用户,有一个方便的路径可以放置二进制文件:`/usr/local/bin`。`/usr/local` 用于在本地安装软件。此目录下的 `bin` 文件夹用于保存本地二进制文件。如果你对 UNIX 文件系统层次结构感到好奇,可以查看规范:http://refspecs.linuxfoundation.org/FHS_2.3/fhs-2.3.html
+
+```shell
+$ sudo mv protoc-3.15.2/bin/protoc /usr/local/bin
+```
+
+你可能需要 `sudo` 才能将可执行文件移动到目标文件夹中。
+
+对于 Windows 用户,你需要将二进制文件移动到环境变量 PATH 中的某一路径下或添加一个路径到 PATH。
+
+### 6.3、profile 文件的解码
+
+要解码 profile 文件,第一步是获取 `.proto 文件`。编码的 protocol buffer **不包含字段名称** 以减少大小。
+
+我们可以在 pprof 的 GitHub 存储库中找到 `.proto 文件`:https://github.com/google/pprof/blob/master/proto/profile.proto。Go 附带了 pprof 的 vender 版本,你可以在 go 源文件夹( src/cmd/vendor/GitHub.com/google/pprof/ )内的 vender 目录中找到该版本。然而,在撰写本文时,profile.proto 似乎并未包含在 vender 中。
+
+一种解决方案是在 src 文件夹中克隆 pprof
+
+```shell
+$ cd /path/to/your/dev/directory
+$ git clone https://github.com/google/pprof.git
+```
+
+然后我们就可以使用下载的 proto 文件了。返回的 profile 文件是 gzip 压缩的。我们必须先解压缩它。为此,我们将使用 gunzip 命令(适用于 Linux 和 Mac 用户):
+
+```shell
+$ gunzip profile.pb.gz
+```
+
+这将删除 profile.pb.gz 文件并创建一个名为 profile.pb 的新文件(这是 profile.pb.gz 的解压缩版本)。对于 Windows 用户,你可以使用 GUI 工具来实现此目的。
+
+然后就可以解码 protocol buffer 文件了
+
+```shell
+$ protoc --decode perftools.profiles.Profile /path/to/your/dev/directory/pprof/proto/profile.proto --proto_path /path/to/your/dev/directory/pprof/proto < profile.pb
+```
+
+在我的电脑上:
+
+```shell
+$ protoc --decode perftools.profiles.Profile /Users/maximilienandile/Documents/DEV/pprof/proto/profile.proto --proto_path /Users/maximilienandile/Documents/DEV/pprof/proto < profile.pb
+```
+
+#### 6.3.1、protoc 命令的详细信息
+
+下面我们对上述命令的各个参数进行说明:
+
+- `--decode`:要解码的消息类型。Profile 文件是 protocol buffer 术语中的一条消息。每条消息都有特定的类型。在我们的例子中,我们的 profile 消息的类型是 `perftools.profiles.Profile`。这个类型不是内置的。如果查看 profile.proto 的第一行,你可能就会明白:
+
+```protobuf
+// github.com/google/pprof/blob/master/proto/profile.proto
+//...
+syntax = "proto3";
+
+package perftools.profiles;
+
+option java_package = "com.google.perftools.profiles";
+option java_outer_classname = "ProfileProto";
+
+message Profile {
+//...
+```
+
+这是包的名称,然后是消息的名称: `perftools.profiles.Profile`
+
+- protoc 命令的下一个参数是 **proto 文件的路径**
+- `--proto_path` :向 protoc 指明 `.proto 文件` 的路径。这个路径必须包含我们的 .proto 文件。否则,protoc 将无法完成工作。
+
+然后我们将编码的消息通过 `< profile.pb` 传递给 protoc。profile.pb 文件中的数据将作为标准输入传递给 protoc 程序。
+
+这是此命令的输出:
+
+```protobuf
+sample_type {
+ type: 1
+ unit: 2
+}
+sample_type {
+ type: 3
+ unit: 4
+}
+sample {
+ location_id: 1
+ location_id: 2
+ location_id: 3
+ value: 14
+ value: 140000000
+}
+sample {
+ location_id: 4
+ location_id: 2
+ location_id: 3
+ value: 7
+ value: 70000000
+}
+sample {
+ location_id: 5
+ location_id: 2
+ location_id: 3
+ value: 1
+ value: 10000000
+}
+mapping {
+ id: 1
+ has_functions: true
+}
+location {
+ id: 1
+ mapping_id: 1
+ address: 17482189
+ line {
+ function_id: 1
+ line: 24
+ }
+}
+location {
+ id: 2
+ mapping_id: 1
+ address: 17482037
+ line {
+ function_id: 2
+ line: 18
+ }
+}
+location {
+ id: 3
+ mapping_id: 1
+ address: 16946166
+ line {
+ function_id: 3
+ line: 201
+ }
+}
+location {
+ id: 4
+ mapping_id: 1
+ address: 17482182
+ line {
+ function_id: 1
+ line: 24
+ }
+}
+location {
+ id: 5
+ mapping_id: 1
+ address: 17482186
+ line {
+ function_id: 1
+ line: 25
+ }
+}
+function {
+ id: 1
+ name: 5
+ system_name: 5
+ filename: 6
+}
+function {
+ id: 2
+ name: 7
+ system_name: 7
+ filename: 6
+}
+function {
+ id: 3
+ name: 8
+ system_name: 8
+ filename: 9
+}
+string_table: ""
+string_table: "samples"
+string_table: "count"
+string_table: "cpu"
+string_table: "nanoseconds"
+string_table: "main.doSum"
+string_table: "/Users/maximilienandile/go/src/go_book/profiling/gettingstarted/main.go"
+string_table: "main.main"
+string_table: "runtime.main"
+string_table: "/usr/local/go/src/runtime/proc.go"
+time_nanos: 1546864261276935000
+duration_nanos: 417027943
+period_type {
+ type: 3
+ unit: 4
+}
+period: 10000000
+```
+
+我们可以看到这个文件的定义:
+
+- Sample types(样本类型)
+- Samples(样本)
+- Mappings(映射)
+- Locations(地点)
+- Functions(职能)
+- A 『 string table(字符串表)』
+- 属性:time_nanos、period_type 和 period
+
+在接下来的部分中,你将了解这些属性的用法。
+
+## 7、什么是调用堆栈?
+
+### 7.1、什么是调用堆栈
+
+堆栈 就是一堆对象。在现实生活中,你可以用木头、香槟酒或任何可以叠放的东西来模拟一个堆栈。
+
+在计算机科学中,我们叠放的是函数调用。当程序执行时,它从一个函数开始。main 函数是第一个执行的。然后我们将调用其他的函数,在其内部又会调用其他的函数。。。
+
+当你的程序运行时,调用堆栈是会增长的。你可以使用 `debug` 包来获取调用堆栈。
+
+程序的调用堆栈是当前正在运行的函数的有序列表。
+
+### 7.2、调用堆栈示例:如何打印堆栈
+
+举个例子:下面,你可以看到一个示例应用程序,它定义了一个 main 函数,两个其他函数 `firstFunctionToBeCalled` 和 `secondFunctionToBeCalled`。main 函数调用 `firstFunctionToBeCalled` ,这个函数又调用 `secondFunctionToBeCalled`。在最后一个函数中,我们将打印堆栈。
+
+```go
+// profiling/stack/main.go
+package main
+
+import "runtime/debug"
+
+func main() {
+ firstFunctionToBeCalled()
+}
+
+func firstFunctionToBeCalled(){
+ secondFunctionToBeCalled()
+}
+
+func secondFunctionToBeCalled(){
+ debug.PrintStack()
+}
+```
+
+程序输出:
+
+```shell
+$ go run main.go
+goroutine 1 [running]:
+runtime/debug.Stack(0xc00000e1b0, 0x1, 0x1)
+ /usr/local/go/src/runtime/debug/stack.go:24 +0xa7
+runtime/debug.PrintStack()
+ /usr/local/go/src/runtime/debug/stack.go:16 +0x22
+main.secondFunctionToBeCalled()
+ /Users/maximilienandile/go/src/go_book/profiling/stack/main.go:14 +0x20
+main.firstFunctionToBeCalled()
+ /Users/maximilienandile/go/src/go_book/profiling/stack/main.go:10 +0x20
+main.main()
+ /Users/maximilienandile/go/src/go_book/profiling/stack/main.go:6 +0x20
+```
+
+我们可以自下而上(从 `main.main` 到 `runtime/debug.Stack` )的读取堆栈。一切从 main 函数开始。然后堆栈开始增长。
+
+我们通过调用堆栈的解析来理解 profiler 所做的工作。
+
+## 8、CPU时间
+
+在本节中,我将尝试向你解释什么是 CPU 时间。如果没有清楚地理解这个概念,接下来的部分将很难理解。
+
+CPU 时间表示中央处理单元(CPU)执行程序中定义的指令集的时间。由微处理器处理这些指令。你的程序越复杂且计算量越大,你需要的 CPU 时间就越多。
+
+我们可以将 CPU 时间分为两个子类别:
+
+- CPU 用户时间
+- CPU 系统时间
+
+让我们举个例子来更好地理解这些概念。
+
+```go
+// profiling/understanding-CPU-profile/main.go
+package main
+
+import (
+ "fmt"
+ "log"
+ "os"
+ "runtime/pprof"
+)
+
+func main() {
+ // set CPU profiling (1)
+ f, err := os.Create("profile.pb.gz")
+ if err != nil {
+ log.Fatal(err)
+ }
+ defer f.Close()
+
+ err = pprof.StartCPUProfile(f)
+ if err != nil {
+ log.Fatal(err)
+ }
+
+ defer pprof.StopCPUProfile()
+
+ // CPU intensive operation (2)
+ test := 0
+ for i := 0; i < 1000000000; i++ {
+ test = i
+ }
+ fmt.Println(test)
+}
+```
+
+上面的例子中,我们使用标准的做法对我们的程序进行 CPU profiling。之后是一个 for 循环,从 0 迭代到 1000000000。在 for 循环中,我们将变量 test 的值更改为 i 的值(即计数器变量)。
+
+编译我们的程序,然后运行:
+
+```shell
+$ go build main.go
+$ ./main
+999999999
+```
+
+这段程序运行需要多长时间?我们可以使用 time 工具重新运行它(适用于 Mac 和 Linux 用户)。该命令将执行程序并显示统计的时间信息:
+
+```shell
+$ time ./main
+real 0m0.629s
+user 0m0.518s
+sys 0m0.005s
+```
+
+这些输出是什么意思?
+
+- real 0m0.629s:总时间,即程序调入和终止之间经过的时间
+- user 0m0.518s:用户的 CPU 时间。该时间表示 CPU 忙于执行用户态指令的时间。
+- sys 0m0.005s:系统的 CPU 时间。这个时间表示 CPU 在内核空间中执行指令所花费的时间,例如系统调用(打开文件等等的操作)
+
+下图中,你可以看到用户和系统 CPU 时间的配额情况。
+
+
+
+CPU 时间的分配
+
+你可以看到系统调用仅占用 1% 的 CPU 时间。99% 的 CPU 时间发生在用户空间。
+
+为了理解这两个百分比的概念,我们可以让这次程序执行大量的系统调用,观察百分比的变化。在这里,我们可以使用 **syscall** 包:
+
+```go
+// profiling/system-call/main.go
+package main
+
+import (
+ "fmt"
+ "io/ioutil"
+ "log"
+ "syscall"
+ "time"
+)
+
+func main() {
+ for i := 0; i < 100; i++ {
+ fileName := fmt.Sprintf("/tmp/file%d", time.Now().UnixNano())
+
+ err := ioutil.WriteFile(fileName, []byte("test"), 0644)
+ if err != nil {
+ log.Fatal(err)
+ }
+
+ err = syscall.Chmod(fileName, 0444)
+ if err != nil {
+ log.Fatal(err)
+ }
+ }
+}
+```
+
+这里有一个 for 循环,它将创建 100 个文件。使用 `fmt.Sprintf` 来生成文件的路径。生成的路径是 `/tmp/fileXXX` 的格式,其中 XXX 表示自 UNIX 纪元时间(『 1970 年 1 月 1 日 00:00:00 星期四 』)以来的纳秒数。
+
+然后我们用 `ioutil.Writefile` 创建并写入文件。 这个函数将执行两个系统调用( open 和 write )。当文件被创建后,我们将利用系统调用 `chmod` 将其模式更改为 `0444`。
+
+这会造成很多的系统调用!让我们看看统计信息会发生什么变化:
+
+```shell
+$ go build main.go
+$ time ./main
+
+real 0m0.031s
+user 0m0.004s
+sys 0m0.023s
+```
+
+用户空间只对应 0.004 秒,而系统空间对应 0.023 秒。通过下图你可以直观地看到配额的变化。系统调用的 CPU 时间现在占总 CPU 时间的 85.2%!
+
+
+CPU 时间配额变化
+
+### 8.1、内核
+
+在本节中,我们使用了术语『 内核 』。内核是指操作系统的核心组件。内核管理系统资源。它还管理计算机的不同硬件组件。当我们进行系统调用时,我们使用内核设施。例如,在 Go 中打开文件将触发系统调用,之后程序会由内核接管。
+
+## 9、什么是 sample
+
+你已经看到解码后的 profile 文件中有大量的 sample。Sample 的概念可能会造成困惑,所以下面将进行一些解释。
+
+Sample 表示一次测量。该测量是在 profiling 过程中的某个时间点进行的。当我们 profiling 一个程序时,我们会收集信息,这些信息在 profile 文件中以 sample 表示。在下图中,你可以看到 profile 文件由包含以下内容的 sample 组成:
+
+- a measure(一种方法)
+- a location(一个位置)
+- optional additional information(可选的附加信息)
+
+
+
+剖面示意图
+
+如果你有 CPU profile 文件或 内存 profile 文件,则 measure 是不同的。
+
+当你激活 CPU profiling 时,你的程序将每 100 毫秒停止一次并进行信息收集。
+
+
+
+CPU profiling 时的收集频率
+
+每次 profiler 停止程序时:
+
+1. 收集数据
+2. 解析数据,提取 measure
+3. 创建一个 sample
+
+收集的数据包含在『 调用堆栈 』中。正如你在上一节中看到的,堆栈的追踪路径( trace )将提供有关调用函数的信息。还会测量每个 sample 的 CPU 时间。
+
+pprof 工具允许我们可视化出现在 profile 文件中的 sample。要获取这些数据,只需在终端中输入以下命令(将进入 pprof 交互模式)
+
+```shell
+$ go tool pprof main profile.pb.gz
+File: main
+Type: cpu
+Time: Jan 13, 2019 at 7:07pm (CET)
+Duration: 720.43ms, Total samples = 470ms (65.24%)
+Entering interactive mode (type "help" for commands, "o" for options)
+(pprof)
+```
+
+然后只需输入『 `traces` 』:
+
+```shell
+(pprof) traces
+File: main
+Type: cpu
+Time: Jan 13, 2019 at 7:07pm (CET)
+Duration: 720.43ms, Total samples = 470ms (65.24%)
+-----------+-------------------------------------------------------
+ 240ms main.main
+ runtime.main
+-----------+-------------------------------------------------------
+ 190ms main.main
+ runtime.main
+-----------+-------------------------------------------------------
+ 30ms runtime.nanotime
+ runtime.sysmon
+ runtime.mstart1
+ runtime.mstart
+-----------+-------------------------------------------------------
+ 10ms main.main
+ runtime.main
+-----------+-------------------------------------------------------
+```
+
+profile sample 将以文本模式展示。可以看到,在我们的案例中,我们有四个 sample。第一列代表 sample 的值,即 CPU 时间。第二列是堆栈追踪路径( trace )。
+
+可以看到我们的 profiling 花了 720.43 毫秒来构建,所有样本一共占 470 毫秒,占用了总时间的 65.24%。术语『 持续时间 』可能会造成困惑。这不是程序的持续时间,而是 profile 文件的持续时间。在上面的例子中,这两个数字很接近但不相等。
+
+程序的总执行时间小于 profile 文件的持续时间。因为 profiling 是先于程序启动,晚于程序结束的。
+
+第一个 sample 的表格展示了 CPU 时间为 240 毫秒,收集数据时的调用堆栈深度为 2,调用的第一个函数是 runtime.main,调用的第二个函数是 main.main。在此视图中不累积这些值。
+
+## 10、pprof 命令行工具
+
+在本节中,我们将重点介绍 pprof 命令行工具。正如你在下图中看到的,pprof 工具有 4 个参数:
+
+- 可视化结果的 **输出格式**(例如:pdf、SVG、web ...)
+- 可以优化可视化的 **选项**(例如,-show 标志仅表示与正则表达式匹配的节点)
+- 二进制可执行文件的路径
+- profile 文件源的路径(即 protocol buffer 文件)
+
+
+
+pprof 命令行
+
+在撰写本文时,有 24 种输出格式可用。我们不会涵盖每一种格式。更常见的是 **`-web`**,它将生成一个 SVG 图形并将其输出到 Web 浏览器上,**`-svg`** 和 **`-pdf`** 将允许你轻松地与同事共享你的个人资料。在下一节中,我们将看到一些常见的用例。
+
+## 11、在网络浏览器中显示 profile 文件
+
+### 11.1、先决条件:Graphviz 的安装
+
+你需要在你的机器上安装 [Graphviz](https://gitlab.com/graphviz/graphviz) 才能运行以下命令。
+
+- MacOS 用户: `brew install graphviz`
+- Linux(Ubuntu) 用户: `apt-get install graphviz`
+- Windows 用户,安装说明在官网
+
+**Mac 用户注意事项**
+
+对于 Mac 用户,你可能必须先定义默认应用程序才能打开 SVG。例如,在我的计算机上,默认应用程序是 Latex。如果你遇到这种情况,你可以更改默认应用程序以将 SVG 打开到你喜欢的浏览器。右键单击一个 SVG 文件,然后单击『 获取信息 』。打开的视图允许你选择用于打开的默认应用程序。选择你想要的一个,然后使修改生效。
+
+### 11.2、执行命令
+
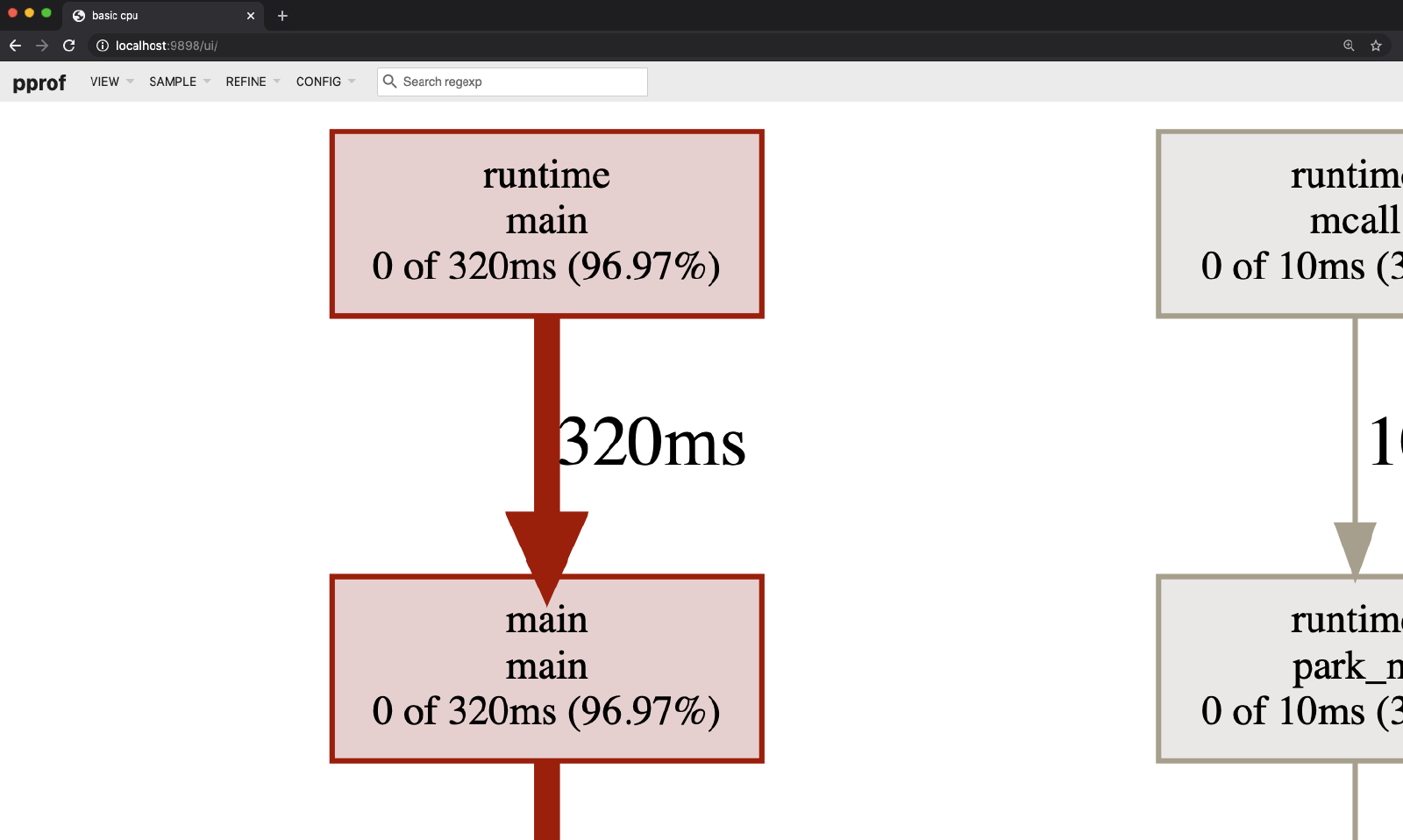
+要从你的 profile 文件生成 SVG 文件并在你的网络浏览器中打开它,你可以使用 web 标志:
+
+```shell
+$ go tool pprof -web gettingstarted profile.pb
+```
+
+这将创建一个 SVG 文件并打开你的浏览器以显示它。将出现下图的图形。
+
+
+
+pprof SVG CPU profile 文件
+
+让我们详细说明一下这张图上有什么
+
+
+
+pprof SVG 解释
+
+你可以在图中看到生成的 SVG 由两个主要部分组成。
+
+第一部分(矩形框)包含有关 profile 文件的详细信息:
+
+- 被 profiling 的二进制文件的名称
+- profile 文件类型
+- 生成 profile 文件的时间
+- profile 文件的持续时间
+- 总 sample 的缩略信息,这里返回的是持续时间
+- 当前视图的节点耗时信息
+
+然后在此图像上,你可以看到称为 『 节点 』 和 『 箭头 』 的块。如果我们使用了正确的术语,我们就有了一个有向图(它是无环的)。该图中的每个节点代表一个函数调用。在下图中,我们详细说明了节点的每个元素的含义:
+
+
+
+pprof SVG 节点含义
+
+你获得了包的信息、调用的函数、sample 的值以及每个节点上 profile 文件的所有样本。最后一个统计数据非常重要。通过此统计数据,你可以比较每个节点的权重并查看发生性能下降的位置。
+
+## 12、交互式 web 界面
+
+生成的 profile 文件信息可以展示为一个漂亮的 Web 界面。要启动它,请键入:
+
+```shell
+$ go tool pprof -http localhost:9898 yourBinaryName profile.pb
+```
+
+它将在 http://localhost:9898 上启动一个 Web 服务器,你可以在其中查看统计信息
+
+
+
+pprof 交互式 web 界面主页
+
+
+
+pprof 查看源代码
+
+
+
+反汇编视图
+
+网络列表是一个有趣的视图。它允许你使用 profile 统计信息查看应用程序的源代码。除此之外,你还可以获得已 profiling 的源代码的反汇编版本!
+
+### 12.1、反汇编?是什么东西?
+
+当你编译你的 Go 程序时,你会得到所谓的『 可执行文件 』。你可以用你的计算机执行一个可执行文件。可执行文件是用机器语言编写的。机器语言并不是没办法读懂,但它真的太难了。反汇编程序是一种可以将机器语言转换为汇编语言的程序。汇编语言不是 Go 代码。它是一组非常接近计算机( CPU )架构,也非常接近操作系统的指令。
+
+通过可视化生成的汇编代码,你可以更好地了解幕后发生的事情。汇编语言在开发者社区中并不是很流行。如果我们拿 2018 年的 Stackoverflow 开发者调查来看,只有 7.8% 的同事说他们在使用它,如果只统计『 专业 』的汇编语言开发者的话,这个数字会更低:6.8%
+
+## 13、什么是代码优化?
+
+指的是『 修改软件系统以使其在某些方面更有效地工作或使用更少的资源 』的过程
+
+代码优化的主要目标是减少程序的执行时间。Profiling 是一个有趣的工具,我们可以用它来减少程序的执行时间和内存消耗。
+
+要优化代码,你需要对其进行修改,有时你需要进行重要的修改以获得性能。Chang、Mahlke 和 Hwu 在 1991 年发表的一篇论文中对两种类型的代码优化进行了有趣的区分:
+
+1. 第一个是修改部分代码,减少该特定部分的执行时间,而不修改程序中其他任何指令的执行时间。例如,删除一些旧代码,这会减少被优化部分的执行时间;此修改不会影响其他指令
+2. 第二个是优化部分代码,这将增加其他部分代码的执行时间。举个例子,假设你有一个 for 循环,在这个循环中,你正在做一个没有必要的计算。你可以提取这部分计算到循环外。如果这样做,将减少循环的执行时间,但会增加循环外的执行时间。
+
+## 14、常见的优化技术
+
+做代码优化最好要有一定的经验积累。下面给出一些常见的优化技术,你应该牢记在心!
+
+### 14.1、移除僵尸代码
+
+在 golang 中很难引入僵尸代码。如果你声明一个变量但没有使用它,go 编译器在编译时会报错。这显然是个非常好的设计,但这并不意味着你不能引入一些僵尸代码片段。
+
+下面就是一个例子:
+
+```go
+// profiling/classic-opti/deadCode/main.go
+package main
+
+import "fmt"
+
+func main() {
+ fmt.Println(multiply(1, 9))
+}
+
+func multiply(x, y int) int {
+ a := x + 1
+ b := a + 2*y
+ b = b * b
+ return x * y
+}
+```
+
+函数参数是两个整数(x 和 y)。此函数将两个整数相乘并返回结果。
+
+在这个函数的内部中,我们定义了 `a` 和 `b`。这两个变量是无用的,实际情况中可能是之前旧项目的遗产( 或者是 cv 操作的后遗症)。删除这些无用的代码时不要多愁善感(反正也跑不出来 -\_-):
+
+```go
+// profiling/classic-opti/deadCodeV2/main.go
+//...
+func multiply(x,y int) int {
+ return x * y
+}
+```
+
+### 14.2 循环出口优化
+
+这种优化技术很容易付诸实践。如果你遇到新代码,请仔细检查循环及其退出条件。
+
+当你不知道元素的索引时,通常通过遍历数组或切片来查找。这种情况下,当找到你要找的东西时,就不需要继续循环了!
+
+让我们举个例子。想象一下,你要在切片中查找元素并返回其索引。你可能会编写下面这个程序
+
+```go
+// profiling/classic-opti/loopExit/main.go
+//...
+
+// s is a slice of uint32
+var search uint32 = 4285020338
+var foundIndex int
+var found bool
+
+for j := 0; j < len(s); j++ {
+ if s[j] == search {
+ found = true
+ foundIndex = j
+ }
+}
+
+if found {
+ fmt.Printf("found index is %d", foundIndex)
+} else {
+ fmt.Println("index not found")
+}
+```
+
+在这段代码中,我们从定义 3 个变量开始:( `search` 保存我们试图在切片 `s` 中定位的数字),`foundIndex` 保存目标元素的索引,一个标志位用于表示数字是否被存在于切片中。
+
+请仔细查看上面代码中的 for 循环。我们会迭代切片的所有元素。在每次迭代中,我们检查位于当前索引处的元素是否等于我们要查找的数字。如果相等,我们将把 `found` 和 `foundIndex` 变量设置为对应的值。
+
+我们找到元素后为什么要继续循环下去?这样会造成一些额外的步骤,必然会花费一些时间。改进方法 :找到元素后,直接退出循环:
+
+```go
+// profiling/classic-opti/loopExitV2/main.go
+//...
+
+for j := 0; j < len(s); j++ {
+ if s[j] == search {
+ found = true
+ foundIndex = j
+ break
+ }
+}
+```
+
+使用 `break` 结束 for 循环。
+
+### 14.3、移除循环中的不变代码
+
+这种优化技术将不变的指令移出循环。这些指令拥有在循环内不会更改的源操作数。
+
+下面我们举一个例子来说明。这个程序需要计算连锁商店的总营业额。商店将营业额数据发送给持有人。对于每个商店,必须从传输的营业额数字中扣除成本:
+
+```go
+// profiling/classic-opti/loopInvariant/main.go
+// ...
+var turnover uint32
+
+for i := 0; i < len(s); i++ {
+ var costs = 950722 + 12*uint32(len(s))
+ turnover = turnover + s[i] - costs
+}
+
+fmt.Println(turnover)
+```
+
+可以注意到,在 for 循环中,我们在每次迭代时都定义了 `costs` 变量。此变量需要一定的计算得出:
+
+```go
+var costs = 950722 + 12*uint32(len(s))
+```
+
+在这里,每个商店的成本是相同的。它不取决于商店的营业额。源操作数 `costs` 不变。因此可以提取这个指令到 for 循环之外。这段指令只会执行一次,因此我们会节省一些 CPU 时间:
+
+```go
+// profiling/classic-opti/loopInvariantV2/main.go
+//...
+
+var turnover uint32
+var costs = 950722 + 12*uint32(len(s))
+
+for i := 0; i < len(s); i++ {
+ turnover = turnover + s[i] - costs
+}
+
+fmt.Println(turnover)
+```
+
+### 14.4、循环融合
+
+如果你的程序由两个(或更多)循环组成:
+
+- 在相同的条件下执行
+- 是独立的(一个循环的执行不依赖于另一个循环)
+- 执行次数相同
+
+我们可以将这些循环合并为一个循环。下面是一个小例子:
+
+```go
+// profiling/classic-opti/loopFusion/main.go
+//...
+
+var costs float64
+for i := 0; i < len(s); i++ {
+ costs += 0.2*float64(s[i])
+}
+
+var turnover uint32
+for i := 0; i < len(s); i++ {
+ turnover += s[i]
+}
+```
+
+这两个循环具有相同的迭代次数,它们是独立的,并且都需要执行。我们可以合并它们:
+
+```go
+// profiling/classic-opti/loopFusionV2/main.go
+//...
+
+var costs float64
+var turnover uint32
+for i := 0; i < len(s); i++ {
+ costs += 0.2*float64(s[i])
+ turnover += s[i]
+}
+```
+
+这将节省一部分 CPU 时间(我们只循环了一次 ,而不是之前的两次。在实际使用中,可以结合可读性来权衡合不合并)。
+
+### 14.5、常量折叠
+
+常量折叠是一种编译器优化技术,它是指常量的值在程序编译期间确定而不是在程序运行期间。
+
+编译器已经为我们做了这件事。但记住这是很有用的!如果你的程序定义了一个变量来保存操作的结果,请考虑是否可以创建一个常量。该操作将在编译期间执行,因此你将节省宝贵的 CPU 时间。
+
+以将文件从一台服务器传输到另一台服务器的上传函数为例:
+
+```go
+// profiling/classic-opti/constantFolding/main.go
+// ...
+
+func upload(files []File)(error){
+ uploadLimit := 10*2048/2
+ for _,file := range files{
+ if file.Size > uploadLimit {
+ return errors.New("the upload limit has been reached")
+ }
+ // upload the file
+ }
+ return nil
+}
+```
+
+变量 `uploadLimit` 设置为: `10*2048/2`
+
+这里的问题是每次我们要将文件上传到服务器时,我们都会再次计算 `uploadLimit`,它是一个常数。我们可以用一个常量代替它,让 Go 在编译程序时计算它。
+
+```go
+// profiling/classic-opti/constantFoldingV2/main.go
+// ....
+
+const uploadLimit =10*2048/2
+
+func upload(files []File)(error){
+ for _,file := range files{
+ if file.Size > uploadLimit {
+ return errors.New("the upload limit has been reached")
+ }
+ // upload the file
+ }
+ return nil
+}
+```
+
+## 15、实际项目中的优化
+
+我们在前面的章节中讨论了很多关于 profiling 的内容;是时候将我们学到的知识应用于实际项目的优化了。
+
+### 15.1、程序的优化 - 概述
+
+假设你是一家大型全球酒店集团的开发商。贵公司在全球拥有 30000 家酒店。你被要求建立一个程序来计算全球集团营业额。每个酒店都会在每个月底向中央办公室发送一份报告。报告是一个 JSON 文件。这是一个例子:
+
+```json
+{
+ "name": "The Ultra Big Luxury Hotel",
+ "reservations": [
+ {
+ "id": 0,
+ "duration": 1,
+ "rateId": 0
+ },
+ {
+ "id": 1,
+ "duration": 5,
+ "rateId": 1
+ }
+ ],
+ "rates": [
+ {
+ "id": 0,
+ "price": 300
+ },
+ {
+ "id": 1,
+ "price": 244
+ }
+ ]
+}
+```
+
+这是『 The Ultra Big Luxury Hotel 』的报道。酒店有两个 『 reservation 』。每个『 reservation 』都有一个内部 ID;『 duration 』表示预订几个晚上,『 rateId 』表示费率 Id。每家酒店都有自己的价格表。第一个『 reservation 』的 rateId 为 0,这意味着每晚 300 美元。第二个『 reservation 』的费用为 244 美元/晚。
+
+报告汇总到一个大的 JSON 文件中。我们必须开发一个程序来读取 JSON 文件,然后计算整个组的总营业额。
+
+```go
+// profiling/program-optimization/cmd/main.go
+// ...
+
+type Reporting struct {
+ HotelReportings []HotelReporting
+ ExchangeRates []ExchangeRate
+}
+
+type HotelReporting struct {
+ HotelId int
+ HotelName string
+ Reservations []Reservation
+ Rates []Rate
+}
+
+type ExchangeRate struct {
+ RateUSD float64
+ HotelId int
+}
+
+type Reservation struct {
+ Id uint
+ Duration uint
+ RateId uint
+}
+
+type Rate struct {
+ Id uint
+ Price uint
+}
+```
+
+我们首先创建一些结构体来解码 JSON 文件:
+
+```go
+data, err := ioutil.ReadFile("/Users/maximilienandile/go/src/go_book/profiling/programOptimization/cmd/output.json")
+if err != nil {
+ panic(err)
+}
+
+reportings := make([]Reporting, 0)
+err = json.Unmarshal(data, &reportings)
+if err != nil {
+ panic(err)
+}
+```
+
+然后我们加载文件并将 JSON 解析到『 Reporting 』切片中。然后我们将实现主要逻辑:
+
+```go
+var groupTurnover float64
+for _, hotelReport := range r.HotelReportings {
+ turnover, err := getTurnover(hotelReport,r.ExchangeRates)
+ if err != nil {
+ panic(err)
+ }
+
+ groupTurnover += turnover
+}
+
+fmt.Printf("Group Turnover %f\n", groupTurnover)
+```
+
+我们迭代『 Reporting 』切片,然后对于每个『 Reporting 』,我们将调用函数 getTurnover 来计算特定酒店报告的营业额。
+
+```go
+func getTurnover(reporting HotelReporting, exchangeRates []ExchangeRate) (float64, error) {
+ turnoverPerReservation := []float64{}
+
+ for _, reservation := range reporting.Reservations {
+ ratePerNight, err := getRatePerNight(reporting.Rates, reservation.RateId)
+ if err != nil {
+ panic(err)
+ }
+
+ xr,err := getExchangeRate(reporting.HotelId,exchangeRates)
+ if err != nil {
+ panic(err)
+ }
+
+ turnoverResaUSD := float64(ratePerNight*reservation.Duration)*xr
+ turnoverPerReservation = append(turnoverPerReservation, turnoverResaUSD)
+ }
+
+ return computeTotalTurnover(turnoverPerReservation), nil
+}
+
+func computeTotalTurnover(turnoverPerReservation []float64) float64 {
+ var totalTurnover float64
+
+ for _, t := range turnoverPerReservation {
+ totalTurnover += t
+ }
+
+ return totalTurnover
+}
+
+func getRatePerNight(rates []Rate, rateId uint) (uint, error) {
+ var found bool
+ var price uint
+
+ for _, rate := range rates {
+ if rate.Id == rateId {
+ found = true
+ price = rate.Price
+ }
+ }
+
+ if found {
+ return price, nil
+ } else {
+ return 0, errors.New("Impossible to retrieve rate per night")
+ }
+}
+
+func getExchangeRate(hotelId int, exchangeRates []ExchangeRate) (float64, error) {
+ var found bool
+ var rate float64
+
+ for _, xr := range exchangeRates {
+ if xr.HotelId == hotelId {
+ found = true
+ rate = xr.RateUSD
+ }
+ }
+
+ if found {
+ return rate, nil
+ } else {
+ return 0, errors.New("Impossible to retrieve exchange rate")
+ }
+}
+```
+
+在上面的代码中,我们有三个主要的函数来计算营业额:
+
+- `getTurnover` 函数将为每个酒店预订创建一个保存营业额的切片。要获得此营业额,该函数需要检索酒店的价格表(它将调用 `getRatePerNight` ),并且将当地的价格转换为美元 ( `getExchangeRate` )
+- 然后它将 持续时间 乘以 费率 以获得订单产生的金额。此金额为当地货币;该程序会将其乘以美元汇率
+- 下一步是求和,数值在 `turnoverPerReservation` 切片中。为此,我们调用 `computeTotalTurnover`
+
+### 15.2、首次运行
+
+为了测试我们的程序,我们生成了假数据:
+
+- 5000 家酒店
+- 每家酒店 70 档价格
+- 每家酒店 1000 次预订。
+
+让我们构建它:
+
+```go
+$ go build main.go
+```
+
+然后我们可以运行它(使用 `time` 工具)
+
+```shell
+$ time ./main --rates 70 --hotels 5000 --resas 1000
+real 0m27.659s
+user 0m27.423s
+sys 0m0.124s
+```
+
+程序工具 27.659s 执行(包含数据样本生成时间)
+
+### 15.3、pprof 分析
+
+程序运行后,profile 文件已写入名为 profile.pb.gz 的通过 gzip 压缩过的文件。我们可以启动 pprof 来查看分析数据:
+
+```shell
+$ go tool pprof main profile.pb.gz
+File: main
+Type: cpu
+Time: Jan 15, 2019 at 1:42pm (CET)
+Duration: 27.18s, Total samples = 25.72s (94.63%)
+Entering interactive mode (type "help" for commands, "o" for options)
+(pprof)
+```
+
+最后一个命令将打开交互模式。你可以看到收集的样本覆盖了 profile 文件持续时间的 90.81%。我们将首先显示有关 CPU 时间的前 10 个函数。
+
+### 15.4、top命令
+
+```shell
+(pprof) top
+Showing nodes accounting for 25.58s, 99.46% of 25.72s total
+Dropped 25 nodes (cum <= 0.13s)
+Showing top 10 nodes out of 23
+ flat flat% sum% cum cum%
+ 16.87s 65.59% 65.59% 16.87s 65.59% main.getExchangeRate
+ 6.15s 23.91% 89.50% 6.15s 23.91% runtime.memclrNoHeapPointers
+ 2.03s 7.89% 97.40% 2.03s 7.89% runtime.nanotime
+ 0.24s 0.93% 98.33% 0.24s 0.93% main.getRatePerNight
+ 0.21s 0.82% 99.14% 0.21s 0.82% runtime.(*mspan).init (inline)
+ 0.07s 0.27% 99.42% 23.62s 91.84% main.getTurnover
+ 0.01s 0.039% 99.46% 6.44s 25.04% runtime.growslice
+ 0 0% 99.46% 23.63s 91.87% main.main
+ 0 0% 99.46% 6.42s 24.96% runtime.(*mcache).nextFree
+ 0 0% 99.46% 6.42s 24.96% runtime.(*mcache).nextFree.func1
+```
+
+
+
+pprof top命令解释
+
+在下图中你可以看到有关命令输出的说明。请记住 cum 和 flat 的含义。
+
+- flat(平坦)
+
+ 函数的 flat 时间 对应于程序 profiling 期间,函数执行花费的 CPU 时间总和。
+
+- cum
+
+ 代表 **累积**。这是函数的执行的 CPU 时间的总和,等待另一个函数返回的时间也会记录在内。
+
+举个例子。我们可以使用以下命令显示包含函数 `main.getTurnover` 的所有追踪(使用 pprof 交互模式)
+
+```shell
+(pprof) traces focus main.getTurnover
+```
+
+在下一节中,你可以看到显示的 3 条轨迹的摘录。
+
+```shell
+-----------+-------------------------------------------------------
+ 1.58s runtime.memmove
+ runtime.growslice
+ main.getTurnover
+ main.main
+ runtime.main
+-----------+-------------------------------------------------------
+ 70ms runtime.memclrNoHeapPointers
+ runtime.growslice
+ main.getTurnover
+ main.main
+ runtime.main
+-----------+-------------------------------------------------------
+ 20ms main.getTurnover
+ main.main
+ runtime.main
+```
+
+第一个 trace 占 1.58 秒。
+
+该函数 `main.getTurnover` 位于第三个位置(从调用堆栈的开头开始)。此跟踪表明 main ( `main.main`) 函数调用了 `main.getTurnover` ,该函数继续调用了 `runtime.growslice`。。。在此示例中,函数 `getTurnover` 正在等待函数 `runtime.grow` 返回(又等待 `runtime.memove` 返回)。我们可以将其添加到 **累积持续时间。**
+
+对于**第二个调用堆栈,**该函数 `getTurnover` 也是 **调用堆栈** 的一部分,也在第三个位置。我们必须将持续时间添加到累积持续时间。
+
+对于**第三个调用栈,**我们的函数位于栈顶。我们可以将其添加到平坦持续时间。让我们做一些数学运算:
+
+如果我们只添加那些调用堆栈来生成我们的 profile 文件
+
+- `main.getTurnover` 的 **平坦** 时间将等于 20ms
+
+- 而 `main.getTurnover` 的 **累计** 时间将等于:
+
+1.58s + 70ms = 1.58s + 0.07s = 1.65s
+
+如果我们分析所有的 trace,我们可以进行相同的观察。
+
+### 15.5、第一轮优化:循环退出
+
+我们将在第一轮中关注 `main.getExchangeRate`,profile 信息它总计占用了 16.87 秒的 CPU 时间。它占累计 CPU 时间的 65.59%。我们必须改进这个函数:
+
+```go
+func getExchangeRate(hotelId int, exchangeRates []ExchangeRate) (float64, error) {
+ var found bool
+ var rate float64
+
+ for _, xr := range exchangeRates {
+ if xr.HotelId == hotelId {
+ found = true
+ rate = xr.RateUSD
+ }
+ }
+
+ if found {
+ return rate, nil
+ } else {
+ return 0, errors.New("Impossible to retrieve exchange rate")
+ }
+}
+```
+
+- 此函数将迭代一个名为 `exchangeRates` 的切片,其中包含每个酒店的所有费率。
+- 每个酒店都有各自的费率。在我们的样本中,有 5000 家酒店。每次调用此函数时,for 循环都会迭代 5000 个费率以找到正确的费率。
+- 想象一下,我们正在寻找 id 为 42 的酒店的费率,如果切片元素是按 hotelId 排序的,在第 42 次迭代时,我们就完成了,费率已经找到了。
+- 但是我们的函数将不断迭代切片。那将是 5000 - 42 = 4958 次无用的迭代。
+
+当我们找到我们的费率时,我们可以停止迭代:
+
+```go
+if xr.HotelId == hotelId {
+ found = true
+ rate = xr.RateUSD
+ break
+}
+```
+
+这里关键字 break 将退出 for 循环。
+
+让我们再次运行 profile 文件,看看它是否提高了我们的性能。
+
+#### 15.5.1、时间统计
+
+```shell
+real 0m7.690s
+user 0m7.498s
+sys 0m0.085s
+```
+
+牛逼 !通过这个简单的 break 语句,我们获得了 27 - 7 = 2027 − 7 =20 秒的性能提升!
+
+#### 15.5.2、CPU profile
+
+让我们看看对 profile 文件统计的影响:
+
+```shell
+Showing nodes accounting for 6.70s, 99.41% of 6.74s total
+Dropped 5 nodes (cum <= 0.03s)
+Showing top 10 nodes out of 25
+ flat flat% sum% cum cum%
+ 4.29s 63.65% 63.65% 4.29s 63.65% main.getExchangeRate
+ 1.48s 21.96% 85.61% 1.48s 21.96% runtime.memmove
+ 0.57s 8.46% 94.07% 0.57s 8.46% runtime.nanotime
+ 0.18s 2.67% 96.74% 0.18s 2.67% main.getRatePerNight
+ 0.10s 1.48% 98.22% 0.10s 1.48% runtime.(*mspan).init (inline)
+ 0.06s 0.89% 99.11% 0.06s 0.89% runtime.memclrNoHeapPointers
+ 0.02s 0.3% 99.41% 6.15s 91.25% main.getTurnover
+ 0 0% 99.41% 6.15s 91.25% main.main
+ 0 0% 99.41% 0.18s 2.67% runtime.(*mcache).nextFree
+ 0 0% 99.41% 0.18s 2.67% runtime.(*mcache).nextFree.func1
+```
+
+该函数 `main.getExchangeRate` 仍位于 CPU profile 文件的顶部。它的 flat 执行时间现在仅为 4.29 秒,而不是之前版本为 16.87 秒;这是一个进步!
+
+### 15.6、第二轮优化:循环不变量(V2)
+
+之前的 CPU profile 文件显示该函数 `main.getExchangeRate` 仍然是最消耗 CPU 时间的函数之一。让我们看看它在哪个上下文中使用:
+
+```go
+func getTurnover(reporting HotelReporting, exchangeRates []ExchangeRate) (float64, error) {
+ turnoverPerReservation := []float64{}
+ for _, reservation := range reporting.Reservations {
+ //..
+ xr,err := getExchangeRate(reporting.HotelId,exchangeRates)
+ //...
+ }
+ //...
+}
+```
+
+- 你可以看到该函数 `getTurnover` 将检索特定酒店的营业额。
+- 它将遍历所有的酒店预订。
+- 对于每个酒店预订,该函数将检索酒店费率。这不是最佳选择,因为费率没有变化。它对每个预订都是稳定的,因为它是在每个酒店定义的。
+
+在这个代码片段中,我们有一个完美的循环不变量示例。该变量 `xr` 将始终相同,但我们会在每次循环迭代中不断检索它。
+
+我们可以简单地从 for 循环中提取对 `getExchangeRate` 的调用。我们将把它放在循环开始之前:
+
+```go
+func getTurnover(reporting HotelReporting, exchangeRates []ExchangeRate) (float64, error) {
+ turnoverPerReservation := []float64{}
+
+ xr,err := getExchangeRate(reporting.HotelId,exchangeRates)
+ for _, reservation := range reporting.Reservations {
+ //..
+ //...
+ }
+ //...
+}
+```
+
+让我们看看这个简单的修改对我们程序性能的影响。
+
+```shell
+$ go build main
+$ time ./main --rates 70 --hotels 20000 --resas 1000
+```
+
+结果依然令人激动:
+
+```
+real 0m1.090s
+user 0m0.847s
+sys 0m0.072s
+```
+
+该程序仅需 1.090 秒即可执行完成!让我们看看分析的结果:
+
+```shell
+$ go tool pprof main profile_1547640425.pb.gz
+File: main
+Type: cpu
+Time: Jan 16, 2019 at 1:07pm (CET)
+Duration: 614.36ms, Total samples = 400ms (65.11%)
+Entering interactive mode (type "help" for commands, "o" for options)
+(pprof)
+```
+
+首先,我们注意到样本仅占 400 毫秒(大约四个样本)。这是完全正常的,因为我们的程序只有一秒的执行时间。Profiler 仅提取了 4 个样本,占 Profile 持续时间的 65.11%。
+
+我们想改进这一点。解决办法是生成更多的样本数据。我们将酒店数量乘以 4(现在为 20000)以增加样本数量。我有一个生成假数据的简单脚本;我特意把它隐藏起来以让你专注于代码优化。
+
+我们再次构建程序,然后启动它以获取 profile 文件。
+
+```shell
+$ go tool pprof main profile_1547641211.pb.gz
+File: main
+Type: cpu
+Time: Jan 16, 2019 at 1:20pm (CET)
+Duration: 2.06s, Total samples = 1.86s (90.28%)
+Entering interactive mode (type "help" for commands, "o" for options)
+(pprof)
+```
+
+样本现在占 profile 文件持续时间的 90.28%!采样时间的总和现在是 1.86 秒。样本数量现在是 24!profile 的数据更准确。让我们看看 top 视图:
+
+```shell
+(pprof) top
+Showing nodes accounting for 1.83s, 98.39% of 1.86s total
+Showing top 10 nodes out of 45
+ flat flat% sum% cum cum%
+ 1.48s 79.57% 79.57% 1.48s 79.57% runtime.memmove
+ 0.12s 6.45% 86.02% 0.12s 6.45% main.getRatePerNight
+ 0.06s 3.23% 89.25% 0.06s 3.23% runtime.(*mspan).refillAllocCache
+ 0.05s 2.69% 91.94% 0.05s 2.69% runtime.memclrNoHeapPointers
+ 0.04s 2.15% 94.09% 0.04s 2.15% runtime.(*mspan).init (inline)
+ 0.02s 1.08% 95.16% 0.02s 1.08% main.getExchangeRate
+ 0.02s 1.08% 96.24% 1.81s 97.31% main.getTurnover
+ 0.02s 1.08% 97.31% 0.02s 1.08% runtime.mmap
+ 0.01s 0.54% 97.85% 0.01s 0.54% main.computeTotalTurnover
+ 0.01s 0.54% 98.39% 0.01s 0.54% runtime.findrunnable
+```
+
+### 15.7、第三轮优化:map(V3)
+
+在前面的 top 视图中,我们可以注意到该函数 `main.getRatePerNight` 是 CPU 时间的第二大消费者。
+
+我们来分析一下这个函数:
+
+```go
+func getRatePerNight(rates []Rate, rateId uint) (uint, error) {
+ var found bool
+ var price uint
+
+ for _, rate := range rates {
+ if rate.Id == rateId {
+ found = true
+ price = rate.Price
+ }
+ }
+
+ if found {
+ return price, nil
+ } else {
+ return 0, errors.New("Impossible to retrieve rate per night")
+ }
+}
+```
+
+- 在这里,我们正在搜索对应的费率。
+- 对于每家酒店,费率都在报告中传输。
+- 每个费率都有一个 `id`,每个预订都有一个 `rateId`,通过它来检索订单的费率。
+- 该函数包含一个 for 循环,该循环将遍历酒店的价格表以找到对应的价格。
+- 我们在这里可以进行第一个优化;当我们找到对应的费率时,我们必须停止循环。
+- 我们只需添加一个 break 语句:
+
+```go
+if rate.Id == rateId {
+ found = true
+ price = rate.Price
+ break
+}
+```
+
+有了这个改进,程序现在需要 3.088 秒来执行(与之前的 3.097 秒相比):
+
+我们也可以改进搜索。
+
+让 n 表示酒店的价格数量。在最坏的情况下,我们必须执行 n 次迭代才能找到对应的价格。
+
+我们可以使用 map 来改善查找时间。这将需要对代码进行重要修改。首先,我们需要创建一个函数来生成费率的 map。
+
+map 会将 `rateId` 与 价格 关联:
+
+```go
+func RateMap(reporting HotelReporting)map[uint]uint{
+ m := make(map[uint]uint)
+ for _,rate := range reporting.Rates{
+ m[rate.Id] = rate.Price
+ }
+ return m
+}
+```
+
+这个函数将 `HotelReporting` 作为参数并返回一个 `map`(键和值是无符号整数)。我们将迭代酒店报告并逐步填充 map。
+
+接下来我们要修改函数 `getRatePerNight`。现在它将查看 map 以检索对应的价格:
+
+```go
+func getRatePerNight(rateMap map[uint]uint, rateId uint) (uint, error) {
+ price, found := rateMap[rateId]
+ if found {
+ return price, nil
+ } else {
+ return 0, errors.New("Impossible to retrieve rate per night")
+ }
+}
+```
+
+下一个修改包括在我们的 main 函数中调用这个 map 生成器。对于每个酒店报告,我们将构建我们的 map,然后将其传递给 `getTurnover` 函数:
+
+```go
+func main(){
+ //...
+ for _, hotelReport := range r.HotelReportings {
+ rateMap := RateMap(hotelReport)
+ turnover, err := getTurnover(hotelReport,r.ExchangeRates,rateMap)
+ if err != nil {
+ panic(err)
+ }
+ groupTurnover += turnover
+ }
+ fmt.Printf("Group Turnover %f\n", groupTurnover)
+}
+```
+
+顺便说一下,函数 `getTurnover` 也需要修改。它必须接受第三个参数:rateMap:
+
+```go
+func getTurnover(reporting HotelReporting, exchangeRates []ExchangeRate, rateMap map[uint]uint) (float64, error) {
+ //...
+ for _, reservation := range reporting.Reservations {
+ ratePerNight, err := getRatePerNight(rateMap, reservation.RateId)
+ //...
+ }
+ //...
+}
+```
+
+我们已经完成了。我们现在可以编译、分析和计时:
+
+```shell
+$ go build main.go
+$ time ./main --rates 70 --hotels 20000 --resas 1000
+real 0m3.242s
+user 0m2.774s
+sys 0m0.321s
+```
+
+这不是很及预期。总执行时间比以前的版本还要大!是原来的三倍。哪里出问题了?性能下降的原因是创建 map 会产生开销(运行时必须计算 hash 值并存储它们)。
+
+| 费率数 | **70 rates** | | **600 rates** | | **10000 rates** |
+| :--------------: | :----------: | ------------- | :-----------: | ------------- | :-------------: |
+| 程序版本 | **v2** | **v3(map)** | **v2** | **v3(map)** | **v3(map)** |
+| **总执行时间** | 1.090s | 3,242s | **7.698s** | **4.209s** | 26.628s |
+| **CPU 用户时间** | 0.847s | 2.774s | 7.493s | 3.705s | 23.218s |
+
+添加 map 对运行时间的影响
+
+我们的数据样本中只有 70 个 rate。让我们用 600 个 rate 再次测试我们的程序。可以在上表中看到,当速率数量增加时,v3 的相对性能也在增加。
+
+让我们用 pprof 来看看 CPU 时间的主要消耗者(对于 10000 rates ):
+
+```shell
+Showing nodes accounting for 12.02s, 94.50% of 12.72s total
+Dropped 51 nodes (cum <= 0.06s)
+Showing top 10 nodes out of 36
+ flat flat% sum% cum cum%
+ 4.51s 35.46% 35.46% 9.71s 76.34% runtime.mapassign_fast64
+ 4.19s 32.94% 68.40% 4.24s 33.33% runtime.(*hmap).newoverflow
+ 1.53s 12.03% 80.42% 1.53s 12.03% runtime.memclrNoHeapPointers
+ 0.57s 4.48% 84.91% 0.57s 4.48% runtime.aeshash64
+ 0.54s 4.25% 89.15% 11.86s 93.24% main.RateMap
+ 0.21s 1.65% 90.80% 0.26s 2.04% runtime.mapaccess2_fast64
+ 0.13s 1.02% 91.82% 0.62s 4.87% main.getTurnover
+ 0.13s 1.02% 92.85% 0.13s 1.02% runtime.nanotime
+ 0.11s 0.86% 93.71% 0.14s 1.10% runtime.overLoadFactor (inline)
+ 0.10s 0.79% 94.50% 0.10s 0.79% main.getExchangeRate
+```
+
+你可以在 pprof top 视图中看到该函数 `runtime.mapassign_fast64` 占用了大部分 CPU 时间(总时间的 76.34%)。这意味着用键值对填充 map 是 CPU 密集型的,但我们仍然节省了大量 CPU 时间。
+
+### 15.8、第四轮优化:代码简化
+
+如果你仔细看看我们程序的代码,你会发现我们有一个没必要进行调用的函数:`computeTotalTurnover`。此函数获取 `float64` 的切片并返回该切片中元素的总和:
+
+```go
+func getTurnover(reporting HotelReporting, exchangeRates []ExchangeRate, rateMap map[uint]uint) (float64, error) {
+
+ turnoverPerReservation := []float64{}
+ // is this slice necessary
+ //... for loop
+ return computeTotalTurnover(turnoverPerReservation), nil
+ // this function call is useless
+}
+```
+
+我们不需要再打包一个函数来做这件事!`computeTotalTurnover` 可以更新到以下版本:
+
+```go
+func getTurnover(reporting HotelReporting, exchangeRates []ExchangeRate, rateMap map[uint]uint) (float64, error) {
+ var totalTurnover float64
+ xr,err := getExchangeRate(reporting.HotelId,exchangeRates)
+ if err != nil {
+ panic(err)
+ }
+ for _, reservation := range reporting.Reservations {
+ ratePerNight, err := getRatePerNight(rateMap, reservation.RateId)
+ if err != nil {
+ panic(err)
+ }
+ totalTurnover += float64(ratePerNight*reservation.Duration)*xr
+ }
+ return totalTurnover, nil
+}
+```
+
+在这里,我们首先定义将保存整个酒店报告的营业额的变量 `totalTurnover`(类型为 `float64`)。而不是将预订的部分营业额放入切片,而是在最后对切片求和,我们只需将营业额添加到 `totalTurnover`
+
+让我们运行这个版本:
+
+```go
+$ go build main.go
+$ time ./main --rates 600 --hotels 20000 --resas 1000 --profileName 600rates
+real 4.14s
+user 3.58s
+sys 0.44s
+```
+
+这个小小的改进对性能的影响很小(但不是可以忽略不计的。程序的第 3 版需要 3.705 秒(CPU 用户时间),新版本现在只需要 3.58 秒。
+
+> 译者注:这里说的东西应该是内联,本来是一个函数调用,内联会在编译时把他展开。本质上是通过减少函数调用(函数调用会发生参数和返回值的拷贝,还可能造成变量的逃逸)来节省操作
+
+### 15.9、总结
+
+| | 0 | v1 | v2 | v3 | v4 |
+| ---------------- | :-----: | :-----: | :----: | :---: | :---: |
+| **总执行时间** | 463.21s | 136.60s | 16.51s | 4.79s | 4.57s |
+| **CPU 用户时间** | 460.93s | 135.12s | 15.83s | 4.13s | 3.91s |
+| **CPU 系统时间** | 1.92s | 1.02s | 0.57s | 0.51s | 0.55s |
+
+性能提升 (600 rates, 20000 hotels, 1000 reservations)
+
+在表中可以看到我已经详细说明了执行时间和程序每个版本的 CPU 时间。
+
+我们的努力得到了回报,因为每一轮优化都改善了执行时间。从初始版本到最终版本(我们仍然可以改进),CPU User 时间缩短了大约 115 倍。
+
+## 16、heap profiling
+
+我们可以在『 top 』表中看到大部分时间都花在了函数 `runtime.memmove` 上**。**如果我们查看 Go 运行时的源代码,该函数用于将内存字节从一个位置移动到另一个位置。你还可以注意到,在 CPU 使用率最高的运行时中,其他处理内存的函数被称为 `runtime.(*mspan).refillAllocCache` 和 `runtime.memclrNoHeapPointers`
+
+我们可以推断我们在程序中的某个地方弄乱了内存。。。我们还没有进行内存分析,但我们可以检测到内存消耗问题。
+
+让我们看看我们的三个函数头:
+
+```go
+func getTurnover(reporting HotelReporting) (uint, error)
+
+func computeTotalTurnover(turnoverPerReservation []uint) uint
+
+func getRatePerNight(rates []Rate, rateId uint) (uint, error)
+```
+
+这里我们通过 **值** 而不是 **通过引用** 传递变量。我们在程序执行期间复制数据。一个简单的优化是通过引用传递变量。
+
+### 16.1、什么是 heap profile
+
+heap profile 允许开发人员准确了解程序的内存使用情况。因此,heap profile 将收集程序中分配和释放的数据。分析器将以特定速率收集正在运行的程序的堆栈跟踪和精确的内存统计信息。
+
+顺便说一下,你还可以通过添加下面的代码在程序的任何部分输出当前的内存统计信息:
+
+```go
+memStats = new(runtime.MemStats)
+runtime.ReadMemStats(memStats)
+fmt.Println("cumulative count of heap objects allocated: %d",memStats.Mallocs)
+//...
+```
+
+### 16.2、先决条件:保存内存 profile 文件
+
+我们将不得不更改应用程序的代码以记录内存消耗。我们将添加以下代码来要求 pprof 包保存我们应用程序的内存 profile 文件:
+
+```go
+f, err := os.Create("mem_profile.pb.gz")
+if err != nil {
+ log.Fatal(err)
+}
+defer f.Close()
+
+runtime.GC() // get up-to-date statistics
+if err := pprof.WriteHeapProfile(f); err != nil {
+ log.Fatal("memory profile cannot be gathered", err)
+}
+```
+
+首先要做的是创建一个文件来保存我们的 profile 数据。我们将使用简单的方法 `os.Create`。
+
+然后我们将手动进行一次 GC 调用(这将阻塞执行直到 GC 完成)。为什么?因为我们希望我们的内存统计更精确。垃圾收集器将清除之前分配的而目前未使用的内存。因此,未使用的内存不会出现在我们的统计中。
+
+然后我们启动 `WriteHeapProfile` 将配置文件写入提供的文件的函数。
+
+### 16.3、垃圾收集器及其对内存分析的影响
+
+pprof 包生成的内存 profile 文件将记录『 自最近完成的一次 GC 开始 』的实时内存分配。
+
+如果运行时在程序中运行了三次 GC,则记录到 profile 文件中的数据将涉及第二次和第三次 GC 之间的内存分配。
+
+如果程序运行期间没有进行 GC,则 profile 文件将包含所有分配的信息。
+
+要禁用 GC,你可以在 go 程序中添加以下代码:
+
+```go
+debug.SetGCPercent(-1)
+```
+
+### 16.4、剖析率
+
+与 CPU profiling 一样,内存 profiling 以一定的速率发生。
+
+### 16.5、我们的第一个内存 profile 文件
+
+让我们构建我们修改过的程序并启动它:
+
+```shell
+$ go build main.go
+$ ./main --rates 600 --hotels 20000 --resas 1000
+```
+
+我们的内存 profile 文件已写入磁盘。我们现在可以使用 pprof 命令行分析我们的 profile 文件:
+
+```shell
+$ go tool pprof main mem_profile.pb.gz
+File: main
+Type: inuse_space
+Time: Jan 21, 2019 at 8:49pm (CET)
+Entering interactive mode (type "help" for commands, "o" for options)
+(pprof) top
+Showing nodes accounting for 791.52MB, 100% of 791.52MB total
+ flat flat% sum% cum cum%
+ 791.52MB 100% 100% 791.52MB 100% main.data
+ 0 0% 100% 791.52MB 100% main.main
+ 0 0% 100% 791.52MB 100% runtime.main
+```
+
+首先,我们可以注意到 791.52MB 的分配被 profile 记录。
+
+通过输入 top 命令,我们可以看到 profile 文件中大小最大的前 10 个节点。这里我们只有三个节点!这是我们的 profile 的唯一节点(这也解释了为什么是 100%)。
+
+然后我们可以注意到 profile 文件的类型是 `inuse_space`
+
+### 16.6、不同类型的内存统计
+
+默认情况下 `inuse_space ` 会显示统计信息的类型,但这不是唯一可用的内存指标类型:
+
+已分配但未释放的内存空间。这是采样时使用的内存
+
+要在该模式下获取 profile 文件,你可以键入以下命令:
+
+```shell
+$ go tool pprof -sample_index=inuse_space main profile.pb.gz
+```
+
+- `alloc_space` 现在分配的内存空间 + 已释放的内存。
+
+```shell
+$ go tool pprof -sample_index=alloc_space main profile.pb.gz
+```
+
+- `inuse_objects` 将显示已分配但未释放的对象数。
+
+```shell
+$ go tool pprof -sample_index=inuse_objects main profile.pb.gz
+```
+
+- `alloc_objects` 这是已分配对象的计数器 + 已释放的所有对象。
+
+```shell
+$ go tool pprof -sample_index=alloc_space main profile.pb.gz
+```
+
+你必须知道,这些统计信息都存储在同一个 profile 文件中。没有四种类型的内存 profile 文件,只有一种,称为 『 **heap profile** 』。
+
+### 16.7、不同类型统计数据的使用
+
+每种类型的统计数据都会收集不同类型的信息:
+
+- **inuse** 统计提供一个程序执行过程中某个时间点内存占用的视图
+- **alloc** 统计用来查看哪些部分占用了大量内存(它也考虑到了 GC 释放的内存)
+
+### 16.8、内存分配的主要特点
+
+我们在生成的第一个 profile 文件中可以看到,函数 `main.data` 中的内存使用率为 100% 。此函数旨在生成我们在程序中使用的数据。
+
+这并不奇怪。让我们看看 alloc_space 统计信息。
+
+```shell
+$ go tool pprof -sample_index=alloc_space main profile.pb.gz
+File: main
+Type: alloc_space
+Time: Jan 21, 2019 at 9:10pm (CET)
+Entering interactive mode (type "help" for commands, "o" for options)
+(pprof) top
+Showing nodes accounting for 1.53GB, 100% of 1.53GB total
+ flat flat% sum% cum cum%
+ 1.53GB 100% 100% 1.53GB 100% main.data
+ 0 0% 100% 1.53GB 100% main.main
+ 0 0% 100% 1.53GB 100% runtime.main
+```
+
+此 profile 文件提供有关内存分配的信息(内存分配是程序能运行的重要组成)。
+
+### 16.9、使用交互式视图探索内存使用情况
+
+要探索你的内存 profile 文件,请使用以下命令:
+
+```shell
+$ go tool pprof -http localhost:9898 profile.pb.gz
+```
+
+它将打开一个交互式 Web UI:
+
+pprof 内存消耗统计
+
+## 17、最后
+
+- pprof 是一个很好的工具,可以了解你的程序是如何工作的以及它们是如何执行的
+- 通过 profiling,你可以检测性能问题。
+- 然而,一个清晰易懂的程序总是比一个晦涩的超高性能程序更容易维护。
+
+## 18、测试
+
+### 18.1、问题
+
+1. go 程序生成 profile 文件需要引入的包的名称是什么?
+2. 什么是 protocol buffer?
+3. 使用什么工具来解码 protobuf 格式的消息?
+4. 什么是『 调用栈 』?
+5. 在 UNIX 下 `time` 命令的输出中,『 user 』和『 sys 』时间有什么区别?
+6. 给出一种优化技术来降低 CPU 使用率。
+
+### 18.2、答案
+
+1. go 程序生成 profile 文件需要引入的包的名称是什么?
+ 1. `runtime/pprof`
+2. 什么是 protocol buffer?
+ 1. 这是一种用于序列化结构化数据的方法。
+ 2. 序列化数据较小。
+3. 使用什么工具来解码 protobuf 格式的消息?
+ 1. protoc
+ 2. 你可以在这里下载 https://github.com/protocolbuffers/protobuf/releases
+4. 什么是『 调用栈 』?
+ 1. 程序的调用栈是当前正在运行的函数的列表。
+ 2. 在栈的开头,你会从 `main` 包中找到 `main` 函数(程序入口点)
+5. 在 UNIX 下 `time` 命令的输出中,『 user 』和『 sys 』时间有什么区别?
+ 1. user:这个时间表示 CPU 忙于执行用户空间中的指令的时间。
+ 2. sys:该时间表示 CPU 在内核空间中执行命令(例如系统调用)所花费的时间。
+6. 给出一种优化技术来降低 CPU 使用率。
+ 1. 例如,删除僵尸代码
+
+## 19、关键点概述
+
+- profiling = 收集有关程序运行的详细统计信息
+- profiling (分析)不同于 benchmark (基准测试)。基准测试衡量个别函数的性能。
+- 要创建 CPU profile 文件,请将这些代码添加到你的 main 函数中:
+
+```go
+f, err := os.Create("profile.pb.gz")
+if err != nil {
+ log.Fatal(err)
+}
+
+pprof.StartCPUProfile(f)
+defer pprof.StopCPUProfile()
+```
+
+- 『 protocol buffer 』是一种用于序列化结构化数据的方法。
+- 它可以将结构化数据转换为可以存储或通过网络传输的轻量级格式。
+- go 生成的 profile 文件使用 Protocol Buffer 进行序列化。
+- 调用堆栈是程序中活动函数的有序列表。调用堆栈可能会根据程序增长或缩小。
+- CPU 时间表示 CPU 执行程序中定义的指令集合所用的时间。
+- 程序的执行时间可以通过 UNIX 系统上的 `time` 命令来测量
+- 要在 Web 浏览器中显示 profile 文件,你可以使用以下命令
+
+```shell
+$ go tool pprof -web yourBinary profile.pb
+```
+
+- sample(样本)是一次测量。该措施是在 profiling 过程中的某个时间进行的。
+- 一些常见的 CPU 使用率优化技术是:
+ - 僵尸代码移除
+ - 循环退出优化:尽快退出循环
+ - 循环不变代码移除:移除任何不依赖于循环局部变量的指令。
+ - 循环融合:如果你有两个循环遍历同一个集合,你可能想要合并它们。
+ - 当操作的结果没有变化时,你可能需要创建一个常量
+- 要创建内存 profile 文件,请使用以下代码:
+
+```go
+f, err := os.Create("mem_profile.pb.gz")
+if err != nil {
+ log.Fatal(err)
+}
+defer f.Close()
+
+if err := pprof.WriteHeapProfile(f); err != nil {
+ log.Fatal("memory profiling is cannot be gathered", err)
+}
+```
+
+- 要启动 pprof 交互式 Web 界面,请使用以下命令:
+
+```shell
+$ go tool pprof -http localhost:9898 profile.pb.gz
+```
+
diff --git a/chap-36-program-profiling/imgs/cpu_syscall_impact.64ac15d0.png b/chap-36-program-profiling/imgs/cpu_syscall_impact.64ac15d0.png
new file mode 100644
index 0000000000000000000000000000000000000000..540e5e7e46973b9b7d74df4cc42b1a95342b1dd3
Binary files /dev/null and b/chap-36-program-profiling/imgs/cpu_syscall_impact.64ac15d0.png differ
diff --git a/chap-36-program-profiling/imgs/cpu_time_graph.dfb0de60.png b/chap-36-program-profiling/imgs/cpu_time_graph.dfb0de60.png
new file mode 100644
index 0000000000000000000000000000000000000000..de79dc924ec33abf67f0a00e61bdc51123bd2eb7
Binary files /dev/null and b/chap-36-program-profiling/imgs/cpu_time_graph.dfb0de60.png differ
diff --git a/chap-36-program-profiling/imgs/pprof_command_line.d74d9a2f.png b/chap-36-program-profiling/imgs/pprof_command_line.d74d9a2f.png
new file mode 100644
index 0000000000000000000000000000000000000000..9de91aa93a0bdf2d246503dd05e139404b3e23a9
Binary files /dev/null and b/chap-36-program-profiling/imgs/pprof_command_line.d74d9a2f.png differ
diff --git a/chap-36-program-profiling/imgs/pprof_svg_explanation.0e848ada.png b/chap-36-program-profiling/imgs/pprof_svg_explanation.0e848ada.png
new file mode 100644
index 0000000000000000000000000000000000000000..b7edae180ff713dd67c9904adca3cf8829af0634
Binary files /dev/null and b/chap-36-program-profiling/imgs/pprof_svg_explanation.0e848ada.png differ
diff --git a/chap-36-program-profiling/imgs/pprof_svg_getting_started.69b0e2e8.png b/chap-36-program-profiling/imgs/pprof_svg_getting_started.69b0e2e8.png
new file mode 100644
index 0000000000000000000000000000000000000000..532eff0b0fb220b335389976a2aec6157e125a48
Binary files /dev/null and b/chap-36-program-profiling/imgs/pprof_svg_getting_started.69b0e2e8.png differ
diff --git a/chap-36-program-profiling/imgs/pprof_web_memory.a9267bb8.png b/chap-36-program-profiling/imgs/pprof_web_memory.a9267bb8.png
new file mode 100644
index 0000000000000000000000000000000000000000..4a70557c59b188dc14d778ff62ac2ded553fa383
Binary files /dev/null and b/chap-36-program-profiling/imgs/pprof_web_memory.a9267bb8.png differ
diff --git a/chap-36-program-profiling/imgs/profile_web_1.61127a06.png b/chap-36-program-profiling/imgs/profile_web_1.61127a06.png
new file mode 100644
index 0000000000000000000000000000000000000000..ae37f9e43f8b3b69679d2d1448efcad2b1e33207
Binary files /dev/null and b/chap-36-program-profiling/imgs/profile_web_1.61127a06.png differ
diff --git a/chap-36-program-profiling/imgs/profile_web_2.7d689401.png b/chap-36-program-profiling/imgs/profile_web_2.7d689401.png
new file mode 100644
index 0000000000000000000000000000000000000000..9d5850d98d8c06b39be31e6e01862e0abe2ede8a
Binary files /dev/null and b/chap-36-program-profiling/imgs/profile_web_2.7d689401.png differ
diff --git a/chap-36-program-profiling/imgs/profile_web_2_disasembling.db7ae075.png b/chap-36-program-profiling/imgs/profile_web_2_disasembling.db7ae075.png
new file mode 100644
index 0000000000000000000000000000000000000000..01c71d2843820aa9033d8d3363aae44d7240c2be
Binary files /dev/null and b/chap-36-program-profiling/imgs/profile_web_2_disasembling.db7ae075.png differ
diff --git a/chap-36-program-profiling/imgs/profiling.d0e9aaa8.jpg b/chap-36-program-profiling/imgs/profiling.d0e9aaa8.jpg
new file mode 100644
index 0000000000000000000000000000000000000000..507ee04c26992ce3aacda12eaf541ed728799b07
Binary files /dev/null and b/chap-36-program-profiling/imgs/profiling.d0e9aaa8.jpg differ
diff --git a/chap-36-program-profiling/imgs/stop_and_collect_profiling.e8d28a4f.png b/chap-36-program-profiling/imgs/stop_and_collect_profiling.e8d28a4f.png
new file mode 100644
index 0000000000000000000000000000000000000000..20dbcca6094aa279e3dfadc20ca36632993973c0
Binary files /dev/null and b/chap-36-program-profiling/imgs/stop_and_collect_profiling.e8d28a4f.png differ
diff --git a/chap-36-program-profiling/imgs/top_explanation.e3addfe1.png b/chap-36-program-profiling/imgs/top_explanation.e3addfe1.png
new file mode 100644
index 0000000000000000000000000000000000000000..40b613f9da005a0e963847bb515360613ffe8495
Binary files /dev/null and b/chap-36-program-profiling/imgs/top_explanation.e3addfe1.png differ
diff --git a/chap-36-program-profiling/imgs/what_is_a_profile.f3235947.png b/chap-36-program-profiling/imgs/what_is_a_profile.f3235947.png
new file mode 100644
index 0000000000000000000000000000000000000000..82c00256325467269d42aaae99ed3f5597dae632
Binary files /dev/null and b/chap-36-program-profiling/imgs/what_is_a_profile.f3235947.png differ
diff --git a/chap-36-program-profiling/imgs/zoom_node_explanation.045c7eb8.png b/chap-36-program-profiling/imgs/zoom_node_explanation.045c7eb8.png
new file mode 100644
index 0000000000000000000000000000000000000000..58fabb3e36ef0aa1b1fbda920805ad381a77c364
Binary files /dev/null and b/chap-36-program-profiling/imgs/zoom_node_explanation.045c7eb8.png differ