# bridge
**Repository Path**: skylxl/bridge
## Basic Information
- **Project Name**: bridge
- **Description**: 彩虹桥(rainbow bridge)是基于Canal Server的客户端转换管理平台,即订阅Canal Server监听到的mysql的binlog日志,同步到mysql、redis、es等其他目标源
- **Primary Language**: Unknown
- **License**: MIT
- **Default Branch**: master
- **Homepage**: None
- **GVP Project**: No
## Statistics
- **Stars**: 0
- **Forks**: 14
- **Created**: 2024-11-28
- **Last Updated**: 2024-11-28
## Categories & Tags
**Categories**: Uncategorized
**Tags**: None
## README
# 彩虹桥
## 前言
现在很多公司都用到微服务架构,在微服务架构中会延伸出几个问题
### 冗余问题
如下图
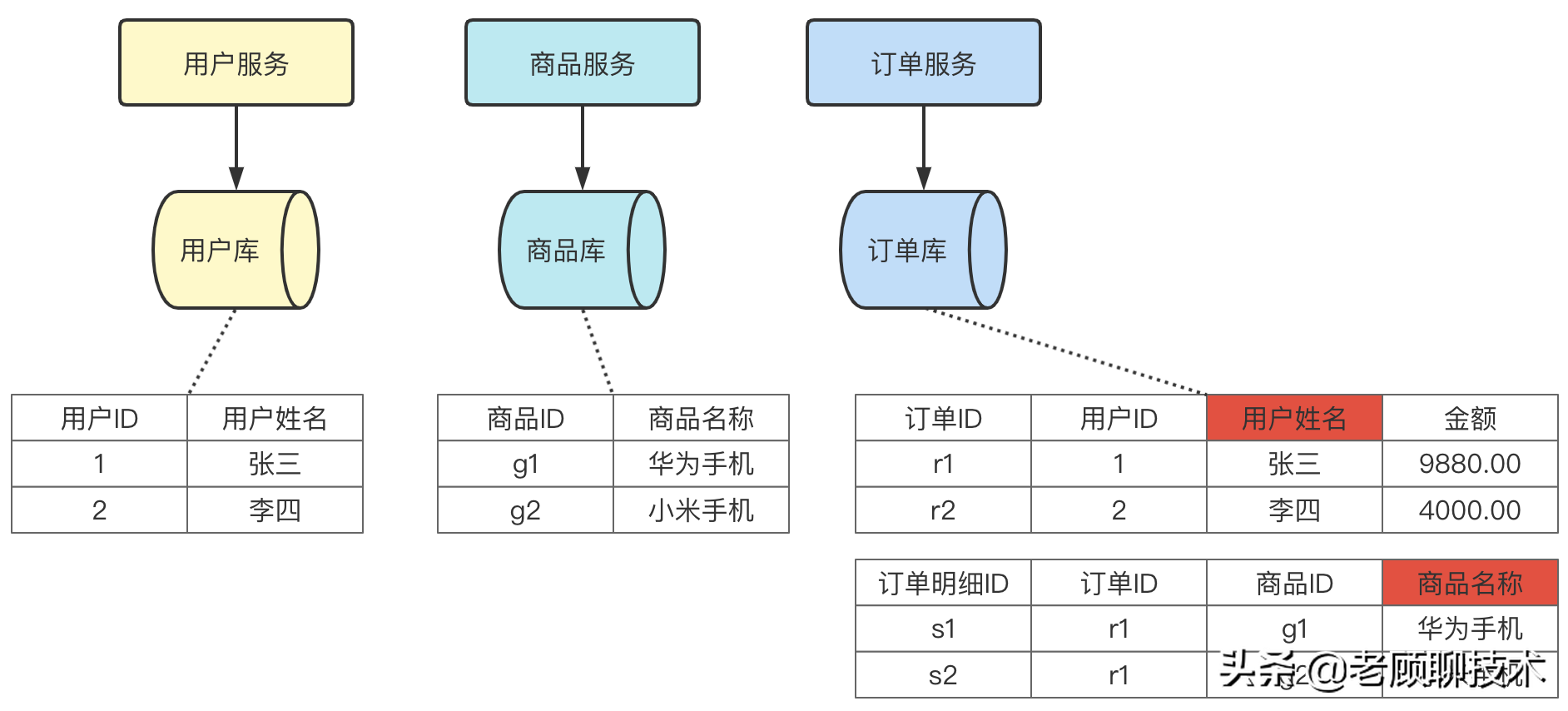
上图中订单库中的表,冗余了用户的姓名以及商品名称。这个主要目的就是为了订单业务中,快速的查询出用户名、商品名;防止跨库查询。但是有时候业务是需要 冗余的数据,要和源数据保持一致,即更新了用户姓名,订单中的用户姓名也要更新。这个就是冗余导致数据不一致的问题
### 缓存问题
如下图
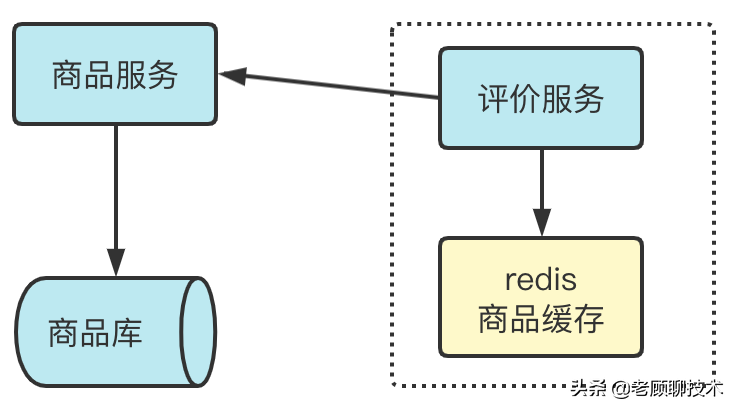
上图中评价服务需要拿到商品信息,为了减少和商品服务的调用频次,有时候需要把商品信息缓存到redis中;这个时候也会出现商品信息更新了,那redis中的缓存 没法即时更新
### ES同步
在有些复杂查询场景中,我们会用到elasticsearch做搜索引擎,es中的数据绝大多数是从mysql来的,那么我们就需要把mysql中的数据同步到es中,那我们如何方便有效的进行同步呢?能否不需要写代码,也能实现业务的自定义同步呢?
## 目标
彩虹桥(rainbow bridge)是基于Canal Server的一个***客户端转换平台***,即订阅Canal Server监听到的mysql的binlog日志,产生Topic消息(支持rocketmq、kafka),rainbow bridge是Canal Server的topic 和 其他目标源的**桥梁**,可以让业务自行定义如何同步到目标源中。
**实现目标:**
```
1、支持多种目标源,已支持mysql、redis、即将支持(es、rocketmq)等
2、任务执行的高可用、负载均衡
3、任务在线实时更新,无须重启任务实例
4、实例执行任务自动伸缩,自动抢购任务
5、任务执行方式支持同步、异步
6、灵活配置任务规则,目标零代码实现业务功能
7、有研发能力的团队可在起基础上,方便的扩展
```
## 架构
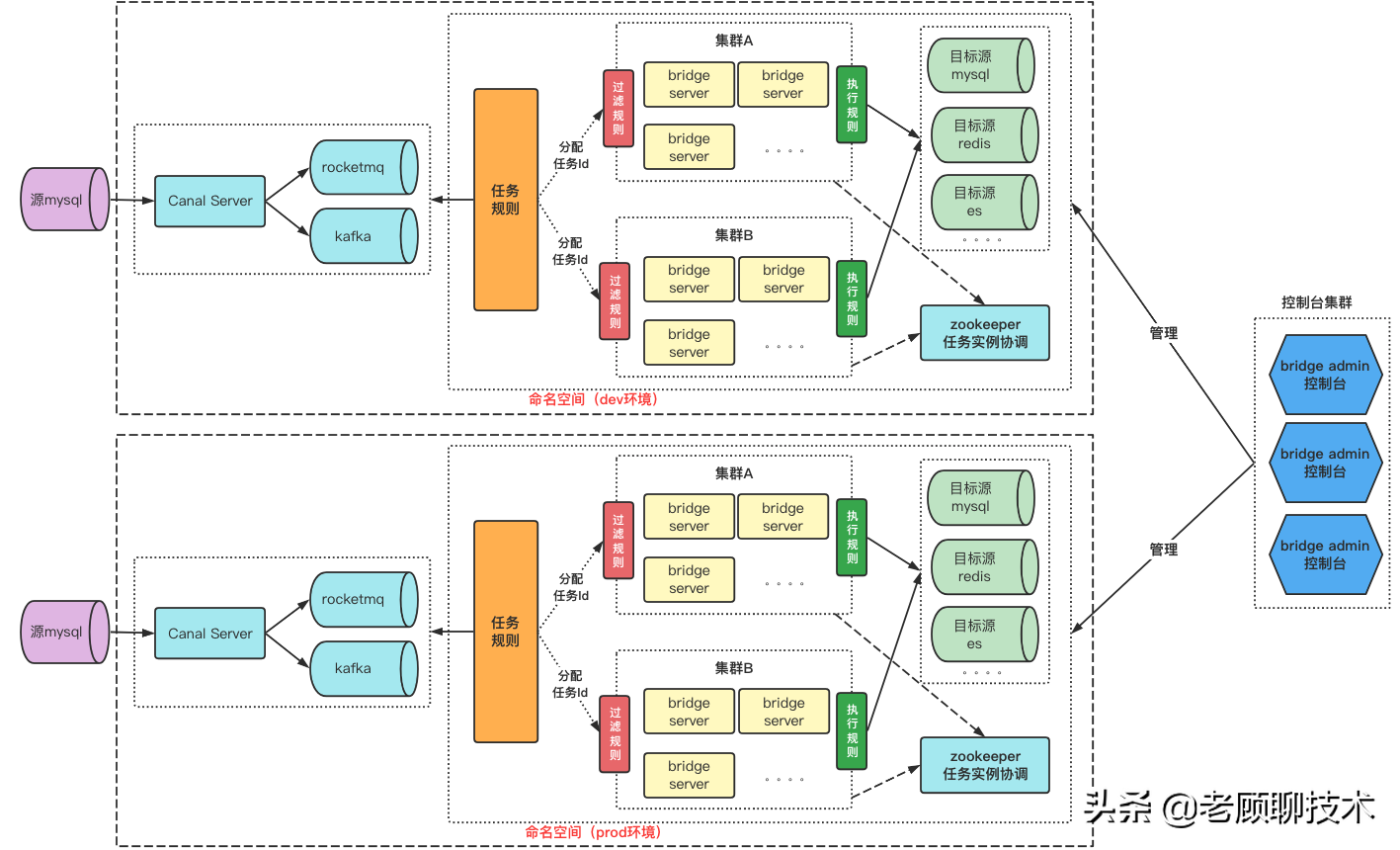
彩虹桥(rainbow bridge)可以理解为canal的**客户端平台**,以任务的方式执行业务需求,***为了保证高可用、负载均衡,引入了集群设计以及zookeeper做实例协调***。
## 部署
彩虹桥部署需要准备
| 序号 | 组件 | 描述 | 依赖关系 |
| :--: | -------------------- | ------------------------------------------------------------ | ------------- |
| 1 | mysql 5.x | 用来存储整个系统的数据,任务、目标源等信息 | |
| 2 | zookeeper 3.6.2 | 用来协调bridge-server实例,以及每个实例要处理的任务数量;通过zk达到高可用,负载均衡 | |
| 3 | bridge-admin.tar.gz | 彩虹桥的管理后台,维护目标源,以及任务等数据;测试环境可以部署一个实例;生产环境可部署多个实例,再用nginx做反向代理 | 依赖zk、mysql |
| 4 | bridge-server.tar.gz | 此为核心服务,用来处理任务,同步数据到目标源;可以部署很多实例,达到高可用和负载均衡;启动时需要启动参数: 集群名以及命名空间 | 依赖zk、mysql |
mysql以及zookeeper的安装,这里就不介绍了
到码云中下载release版本 https://gitee.com/gujiachun/bridge/releases
### 安装admin
解压bridge-admin.tar.gz,可以看到目录结构
```
-bin
restart.sh //重启
startup.bat //启动
startup.sh //启动
stop.sh //停止
-conf
-public //静态资源
application.yml //配置文件
bridge-admin.sql //sql创建文件
logback.xml //日志记录配置
-lib
*.jar
-logs
```
**1、把bridge-admin.sql执行**
**2、修改application.yml中的数据库配置**
```yaml
spring:
datasource:
#定义数据库配置
host: 127.0.0.1:3306
database: rainbow_bridge
password: root
username: root
```
**3、配置启动端口**
```java
server:
port: 8072
```
**4、准备zookeeper**
因为在初始化数据库中,表basic_zk里面维护了zk的信息
```sql
1 zk 127.0.0.1:2181 /bridge dev 2021-11-06 16:00:14 2021-11-06 16:00:17
```
表字段servers中是zk的地址,为 127.0.0.1:2181;你可以配置成自己的zookeeper地址
然后启动zookeeper就行了
**5、执行startup.sh**
这样admin服务就启动了
### 安装server
解压bridge-server.tar.gz,可以看到目录结构
```
-bin
restart.sh //重启
startup.bat //启动
startup.sh //启动
stop.sh //停止
-conf
application.yml //配置文件
logback.xml //日志记录配置
-lib
*.jar
-logs
```
**1、修改application.yml中的数据库配置**
```yaml
spring:
datasource:
#定义数据库配置
host: 127.0.0.1:3306
database: rainbow_bridge
password: root
username: root
```
**2、配置启动端口**
```java
server:
port: 8064
```
**3、启动集群以及命名空间**
```yaml
bridge:
#启动时 需指定命名空间/环境,以及所属集群
env: dev
#可以指定集群代码,如果不配置,就根据各个集群server实例数情况,自动分配到某个集群
clusterCode: c1
#启动时 可以指定 此实例 可以处理多少任务;默认值为1
maxTaskCount: 3
#异步处理任务的线程池 配置
#核心线程数
threadCorePoolSize: 10
#最大线程数
threadMaxPoolSize: 20
#等待队列大小
threadQueueSize: 100
```
**env环境代码**
env的值必须存在于表basic_namespace中字段env中的值【对应控制台的命名空间】
**clusterCode集群代码**
clusterCode的值必须存在于表basic_cluster中字段code中的值【对应控制台的集群管理】
> 如果不配置,就根据各个集群server实例数情况,自动分配到某个集群
**maxTaskCount最大处理任务数**
如果此集群中的任务很少,有可能此实例没有抢得过其他实例,很有可能此实例就没有任务执行。
即时集群中的任务很多,但此实例处理的任务数 不会超过 最大处理任务数
默认值为1
**处理任务线程池**
任务的处理可以同步,也可以异步;可自行配置线程池大小
**4、执行startup.sh**
这样server服务就启动了。
> 可以启动多个实例哦,体验高可用、负载均衡;自动去抢任务哦
## 控制台
控制台访问,根据admin部署的情况,请求ip+port
控制台是不依赖server实例的,也就是不安装server,照样可以运行控制台哦
```url
http://127.0.0.1:8072/
```
### 登录页面
V1.0版本时没有权限控制的,所以直接登录进入 就行了
### 主菜单
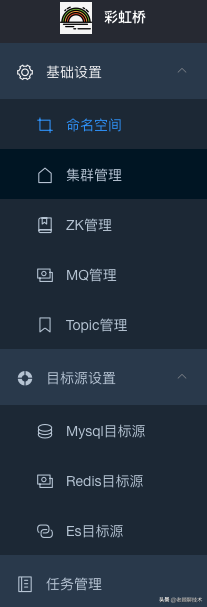
#### 基础设置
配置整个系统的基础信息
1、命名空间:配置不同环境
2、集群管理:配置不同环境中存在哪些集群
3、ZK管理:配置不同环境中zookeeper的地址
4、MQ管理:配置不同环境需要订阅哪些源数据库binlog的MQ消息中间件
5、Topic管理:配置源数据库binlog产生了哪些topic
#### 目标源设置
配置我们需要把数据同步到哪些目标源
1、mysql目标源:mysql目标源相关的配置
2、redis目标源:redis目标源相关的配置
3、es目标源:es目标源相关的配置
#### 任务管理
创建同步数据任务
## 命名空间

配置不同的环境,整个系统时支持多个环境,环境代码要唯一哦
## 集群管理

维护不同环境中有哪些集群
还可以查看集群现在状态;
在线任务数:执行了多少个任务序列数;(一个任务可以产生多个序列,代表多个server实例在处理同一个任务)
在线实例数:集群中有多少个在线server实例
## ZK管理

维护不同环境对应的zk服务;**一个环境只能有一个zk服务器,(不同环境可以配置一样的zk服务,但根节点路径要不一样)**
生产环境zk服务需要高可用哦
> 根节点路径:多个环境可以共用一个zk服务,需要根节点不一样哦
注意:默认支持zookeeper的版本为3.6.X;如你的zookeeper版本为3.4.x,下载的包是不一样的
如需要自己改源码,可参考分支zk-3.4.x;改动pom文件 里面的版本,即可支持3.4.x
```
org.apache.zookeeper
zookeeper
3.4.14
org.slf4j
slf4j-log4j12
log4j
log4j
org.apache.curator
curator-framework
2.11.1
org.apache.zookeeper
zookeeper
org.apache.curator
curator-recipes
2.11.1
org.apache.zookeeper
zookeeper
org.apache.curator
curator-framework
com.google.guava
guava
16.0.1
```
## MQ管理
维护不同环境的mq,此mq是对应canal server端配置的MQ;Canal Server虽然支持直连,但生产环境不推荐,推荐配合MQ同步binlog日志

mq类型支持rocketmq和kafka
## Topic管理

topic主要也是对应canal server端配置的mq中的topic,哪些源数据库中的表同步到此topic
## Mysql目标源

维护需要把数据同步到哪些目标mysql源中
**数据库配置**
```
数据源配置格式(k1=v1;k2=v2)如下:
driverClassName=com.mysql.cj.jdbc.Driver;maxActive=20;maxPoolPreparedStatementPerConnectionSize=20;minIdle=8;initialSize=8;maxWait=60000;testOnBorrow=false;testOnReturn=false;timeBetweenEvictionRunsMillis=60000;minEvictableIdleTimeMillis=30000;testWhileIdle=true;password=root;url=jdbc:mysql://127.0.0.1:3306/test1?useUnicode=true&characterEncoding=UTF-8&serverTimezone=Asia/Shanghai;username=root;validationQuery=SELECT 1
```
**其中的key是不能改的,value可以改;key如下**
```
driverClassName
maxActive
maxPoolPreparedStatementPerConnectionSize
minIdle
initialSize
maxWait
testOnBorrow
testOnReturn
timeBetweenEvictionRunsMillis
minEvictableIdleTimeMillis
testWhileIdle
password
url
username
validationQuery
```
以上的key其实就是 druid数据链接池的配置
## Redis目标源

维护不同环境的redis,可以把数据同步到redis中;支持多种部署方式,单机、哨兵、集群版redis
**连接配置**
配置格式(k1=v1;k2=v2)如
```
redis.single.host=localhost;redis.single.max-active=8;redis.single.max-idle=8;redis.single.min-idle=1;redis.single.database=0;redis.single.max-wait=5000;redis.single.so-timeout=1000;redis.single.port=6379
```
### 单机配置
```yaml
#单节点redis的连接配置信息
redis.single.host=localhost
#*资源池中的最大连接数*
redis.single.max-active= 8
#*资源池允许的最大空闲连接数*
redis.single.max-idle= 8
#*资源池确保的最少空闲连接数*
redis.single.min-idle=1
redis.single.password= test123
redis.single.database=0
#*当资源池连接用尽后,调用者的最大等待时间(单位为毫秒)*
redis.single.max-wait=5000
## 请求响应时间毫秒
redis.single.so-timeout=1000
redis.single.port=6379
```
需要用分号;拼接哦,不要忘了哦
### 哨兵配置
```yaml
redis.sentinel.master-name=mymaster
#redis配置示例:
redis.sentinel.nodes=ip1:port1,ip2:port2,ip3:port3
## 连接超时时间
redis.sentinel.connect-timeout=1000
## 最大连接数
redis.sentinel.max-active=8
## 最大空闲连接数
redis.sentinel.max-idle=8
## 连接密码
redis.sentinel.password=passwd1
## 请求响应时间毫秒
redis.sentinel.so-timeout=1000
## 等待连接超时时间毫秒
redis.sentinel.max-wait= 1000
## 最新空闲连接数
redis.sentinel.min-idle= 1
```
需要用分号;拼接哦,不要忘了哦
### 集群配置
```
#redis集群配置示例:
redis.cluster.nodes=ip1:port1,ip2:port2,ip3:port3
## 连接超时时间
redis.cluster.connect-timeout=1000
## 最大连接数
redis.cluster.max-active=8
## 最大空闲连接数
redis.cluster.max-idle=8
## 连接密码
redis.cluster.password=passwd1
## 请求响应时间毫秒
redis.cluster.so-timeout=1000
## 等待连接超时时间毫秒
redis.cluster.max-wait= 1000
## 最新空闲连接数
redis.cluster.min-idle= 1
```
需要用分号;拼接哦,不要忘了哦
## ES目标源
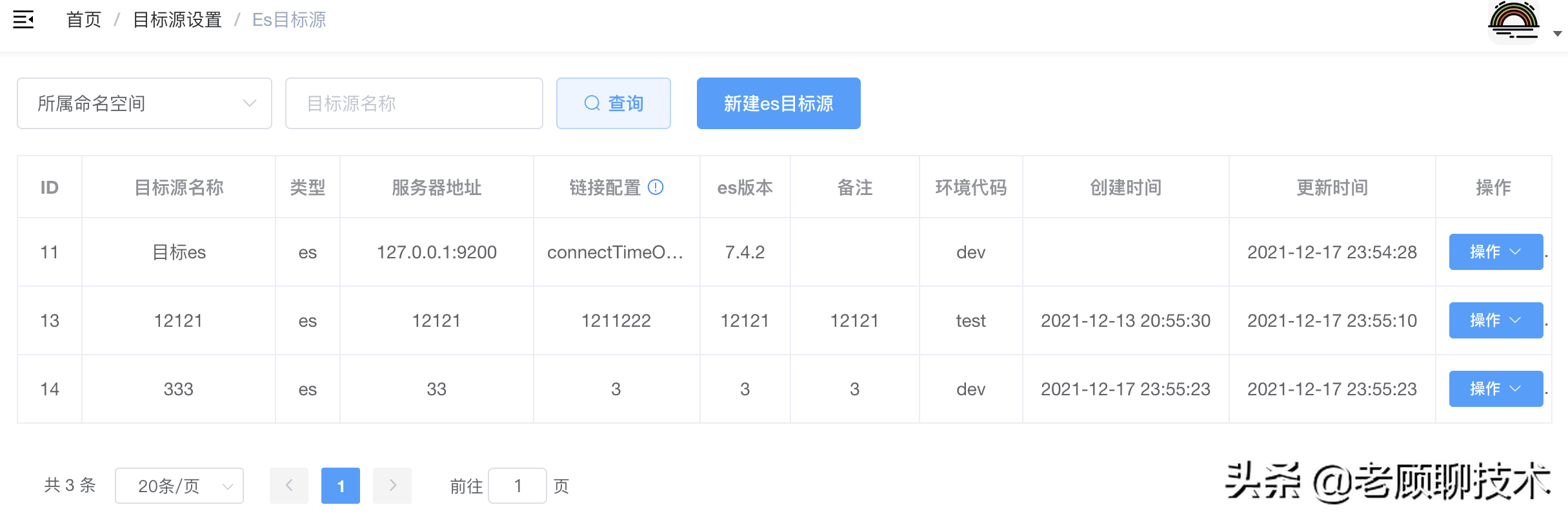
**类型**:指定为es
**服务器地址**:链接es服务器的地址
**链接配置**:代表链接es的配置,配置格式(k1=v1;k2=v2);没有用户名和密码时,可不需要配置username=elastic;password=elastic;案例如下:
```
connectTimeOut=3000;socketTimeOut=3000;connectionRequestTimeOut=3000;maxConnectCount=100;maxConnectPerRoute=10;keepAliveMinutes=10
```
**es版本**:链接es服务器的es版本,目的只是说明而已,可以不填写
## 任务管理

### 创建任务
指定订阅哪个topic,同步哪种类型目标源
指定任务在哪个集群中处理;并且指定期望有多少个server实例执行
指定执行方式是异步 还是 同步
### 执行任务的集群
任务在哪个集群中执行
### 任务状态
未发布、已发布、已停用
### 执行期望实例数
任务会在集群中执行,为了高可用、负载均衡
此任务可设置最大期望多个实例执行此任务
### 在线实例数
可以实时查看有几个server实例在处理此任务
### 执行方式
执行任务时采用异步或同步;(异步方式能够提升处理性能,但是出现异常时,消息不会重发);(同步方式 出现异常时,消息会重发)
## 规则
任务列表中,针对不同的目标源类型,会有不同的规则配置
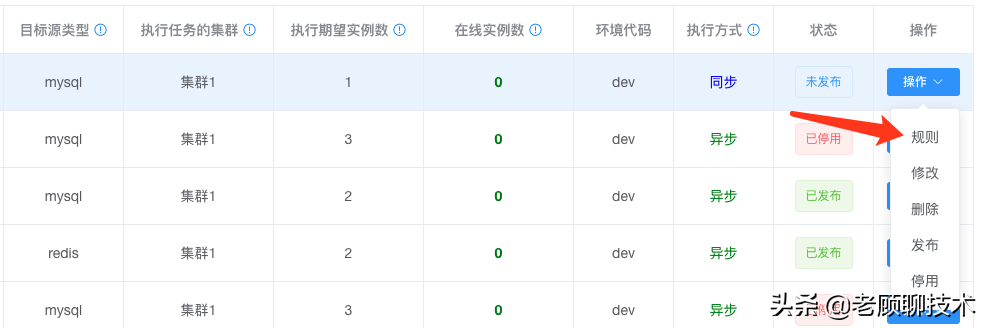
规则的作用,就是让业务自行配置,如何同步数据
### Mysql目标源任务规则
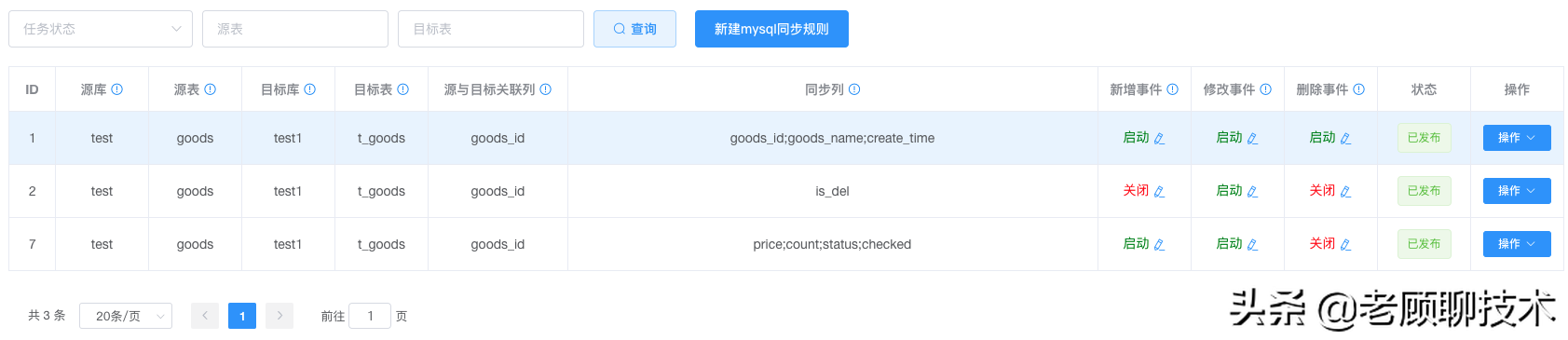
本质就是需要配置哪个源数据 同步到 哪个目标
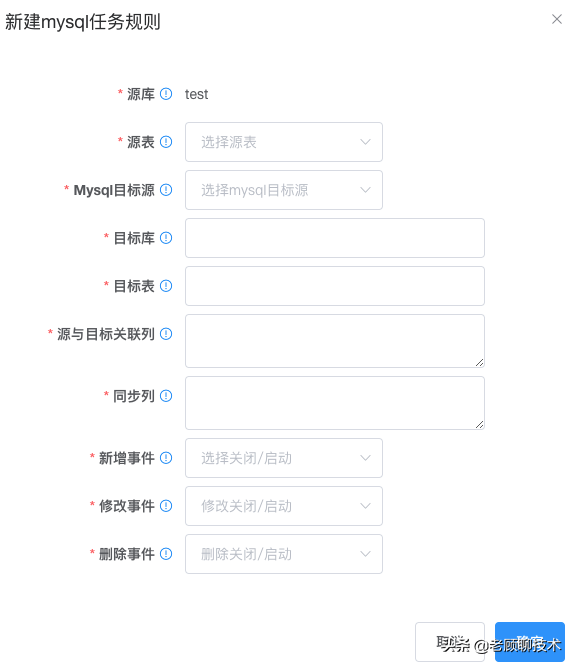
**源库**
topic配置的源库
**源表**
topic配置的源表,有可能有多个表
**mysql目标源**
需要同步到哪个目标源
**目标库**
同步到目标库,必须和选择的目标源配置的数据库名保持一致
**目标表**
同步到目标表,这里只能写一张表【如果需要把一个源数据同步到多张表,可以新建多个规则】
**源与目标关联列**
源表 和 目标表之间通过 哪些列进行关联的,作为过滤条件用,类似 where id=xx and name=yy
【格式(源列1=目标列1;源列2=目标列2);如果列名一样可简写(列名1;列名2)】
【新增时:无效】;【修改和删除时:作为目标表更新哪些数据的过滤条件】
**同步列**
源表 和 目标表 同步数据的列名映射关系;这个才是把源表的哪些列数据,同步到 目标表的哪些列
前提条件是 【**源与目标关联列**】过滤后
【格式(源列1=目标列1;源列2=目标列2);如果列名一样可简写(列名1;列名2)】
**新增事件**
是否开启 源表发生【新增数据事件】的处理同步;即源表insert操作后,要不要同步。
**修改事件**
是否开启 源表发生【修改数据事件】的处理同步;即源表update操作后,要不要同步。
**删除事件**
是否开启 源表发生【删除数据事件】的处理同步;即源表delete操作后,要不要同步。
### mysql执行规则
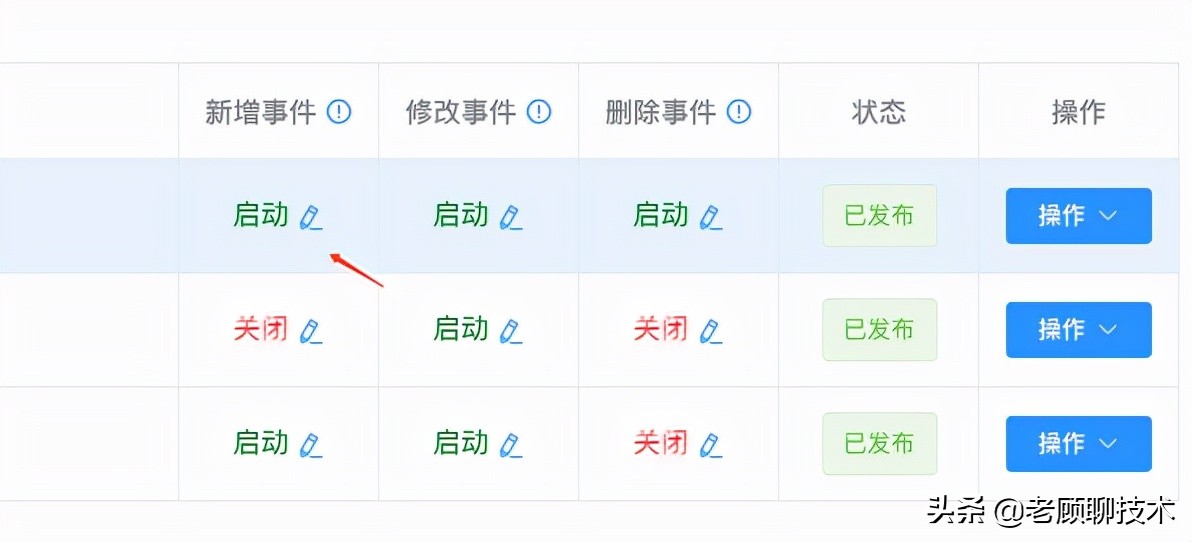
在进行同步时,可以自定义同步规则
#### 新增事件执行规则
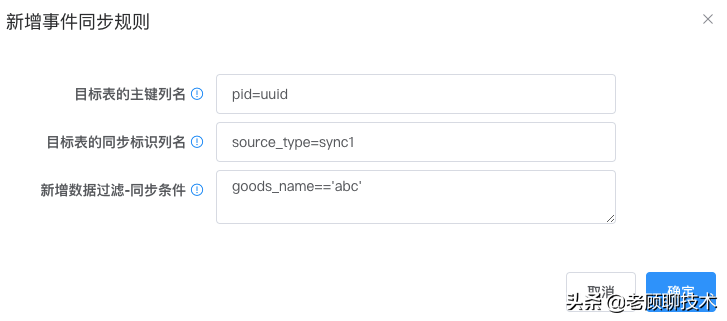
**目标表的主键列名**
新增同步时,如果目标表有自己的主键,那么我们可以在插入数据时,自动生产主键;
此处配置Id列名,以及生成规则,暂只支持uuid(列名=uuid); 如果此值为空 表示新增时忽略
**目标表的同步标识列名**
新增同步时,有些业务需要区分数据来源,那么就有必要有个列标识一下数据来源
【格式(目标列=指定来源值),如: sourceType=sync;来源值随业务定】,这样就可以区分哪些数据是同步过来的;可以为空,表示不需要区分来源
**新增数据过滤-同步条件**
新增过滤条件,源数据是什么值才同步,不满足条件 就不同步此数据
针对源数据的过滤条件,表达式成立才会同步此数据,【属性用:源表的列名】
【goods_name=='abc' 或 price < 30 && is_del==0】
```
利用了com.googlecode.aviator表达式引擎,可自行网补
```
简单的关系表达式
```
支持的关系运算符包括"<" "<=" ">" ">=" 以及"=="和"!="
```
逻辑表达式
```
一元否定运算符"!",以及逻辑与的"&&",逻辑或的"||"
```
#### 修改事件执行规则

**源表的旧数据过滤-同步条件**
修改事件的过滤条件,针对修改前的源数据过滤条件,表达式成立才同步;如【goods_name=='abc' 或 price < 30 && is_del==0】
**源表的新数据过滤-同步条件**
修改事件的过滤条件,针对修改后的源数据过滤条件,表达式成立才同步;如【goods_name=='abc' 或 price < 30 && is_del==0】
#### 删除事件执行规则
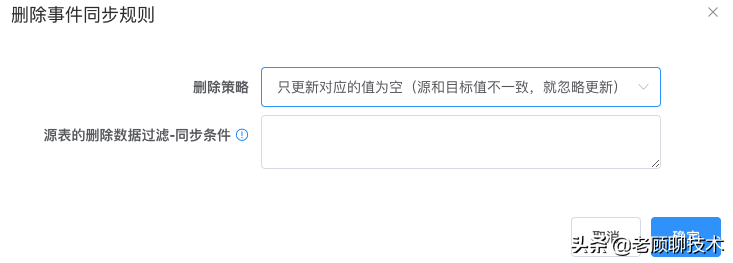
**源表的删除数据过滤-同步条件**
删除事件的过滤条件,针对删除的源数据过滤条件,表达式成立才同步;如【goods_name=='abc' 或 price < 30 && is_del==0】
**删除策略**
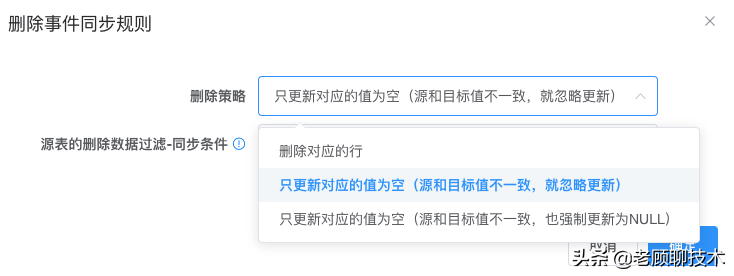
**删除对应的行**,即根据源与目标关联列过滤进行删除
**只更新对应的值为空**,即根据源与目标关联列过滤,更新相关同步列
------
### Redis目标源任务规则

redis的动态执行规则,是利用了freemarker执行引擎,也就是java开发比较熟悉的,${xxx}里面的是针对表的列名
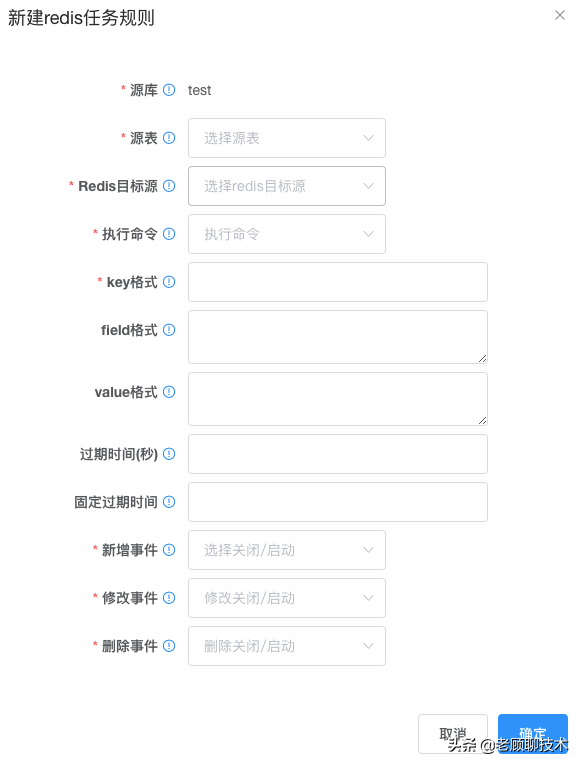
**源库**
topic配置的源库
**源表**
topic配置的源表,有可能有多个表
**redis目标源**
需要同步到哪个目标源
**执行命令**
redis的命令,先支持set、hset、hmset、incr、delete、delhKeys
**key格式**
支持写固定的key,也可以支持动态的key;如 key1-${good_id}-p;其中的good_id是源表的列名
支持freemarker解析引擎,利用源表中的数据,对模板进行解析;最终生成值。【如:user_${name}_act】
**field格式**
field的模板【field是用来支持 hset、delhKeys指令的】;支持freemarker解析引擎,利用源表中的数据,对模板进行解析;最终生成值。【如:user_${name}_act】,如果多个field用(逗号,)隔开
**value格式**
value的模板,支持freemarker解析引擎,利用源表中的数据,对模板进行解析;最终生成值。【如:user_${name}_act】,如果hmset命令需要,map对象;可对此value设置json格式字符串,系统会自动转为map
**过期时间**
设置key的过期时间,即过多少秒后 过期;可以为空,代表不过期
**固定时间过期**
设置key的过期时间,即在固定的时间点过期,即每天的哪个时间点过期,一旦有更新 即代表第二天固定时间点;可以为空,代表不过期
**新增事件**
是否开启 源表发生【新增数据事件】的处理同步;即源表insert操作后,要不要同步。
**修改事件**
是否开启 源表发生【修改数据事件】的处理同步;即源表update操作后,要不要同步。
**删除事件**
是否开启 源表发生【删除数据事件】的处理同步;即源表delete操作后,要不要同步。
------
### Es目标源任务规则(elasticsearch)
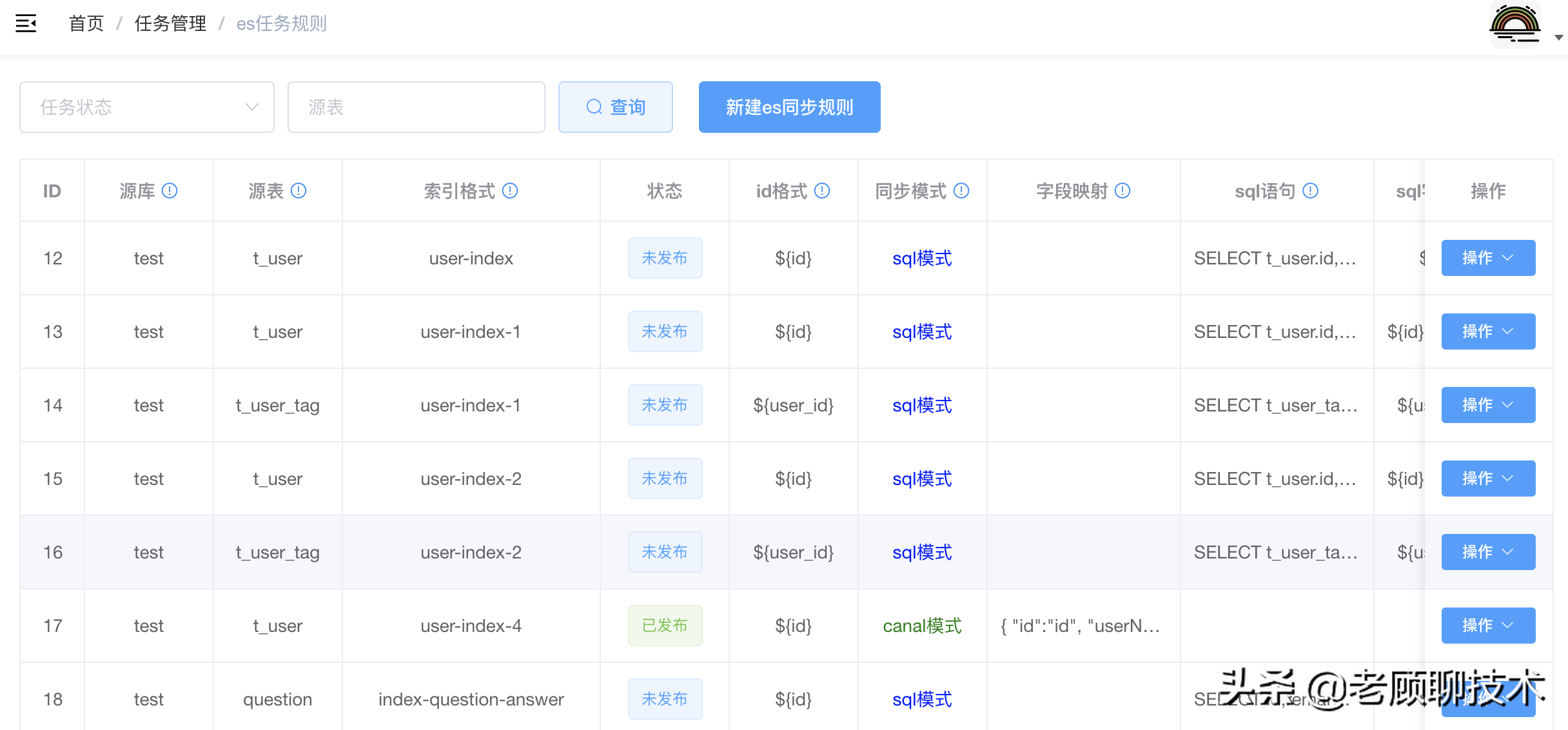
配置同步到ES的规则
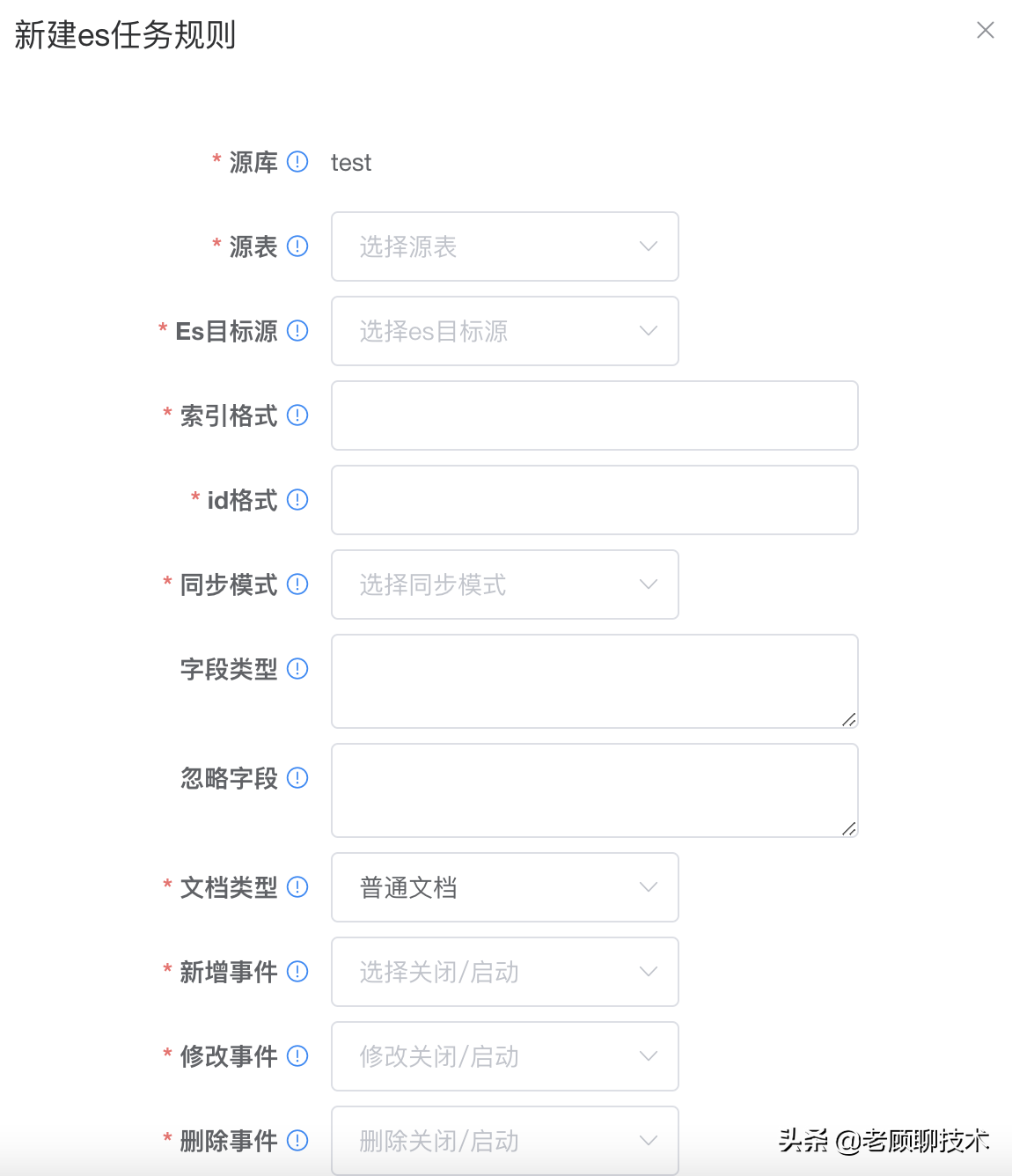
父子文档如下
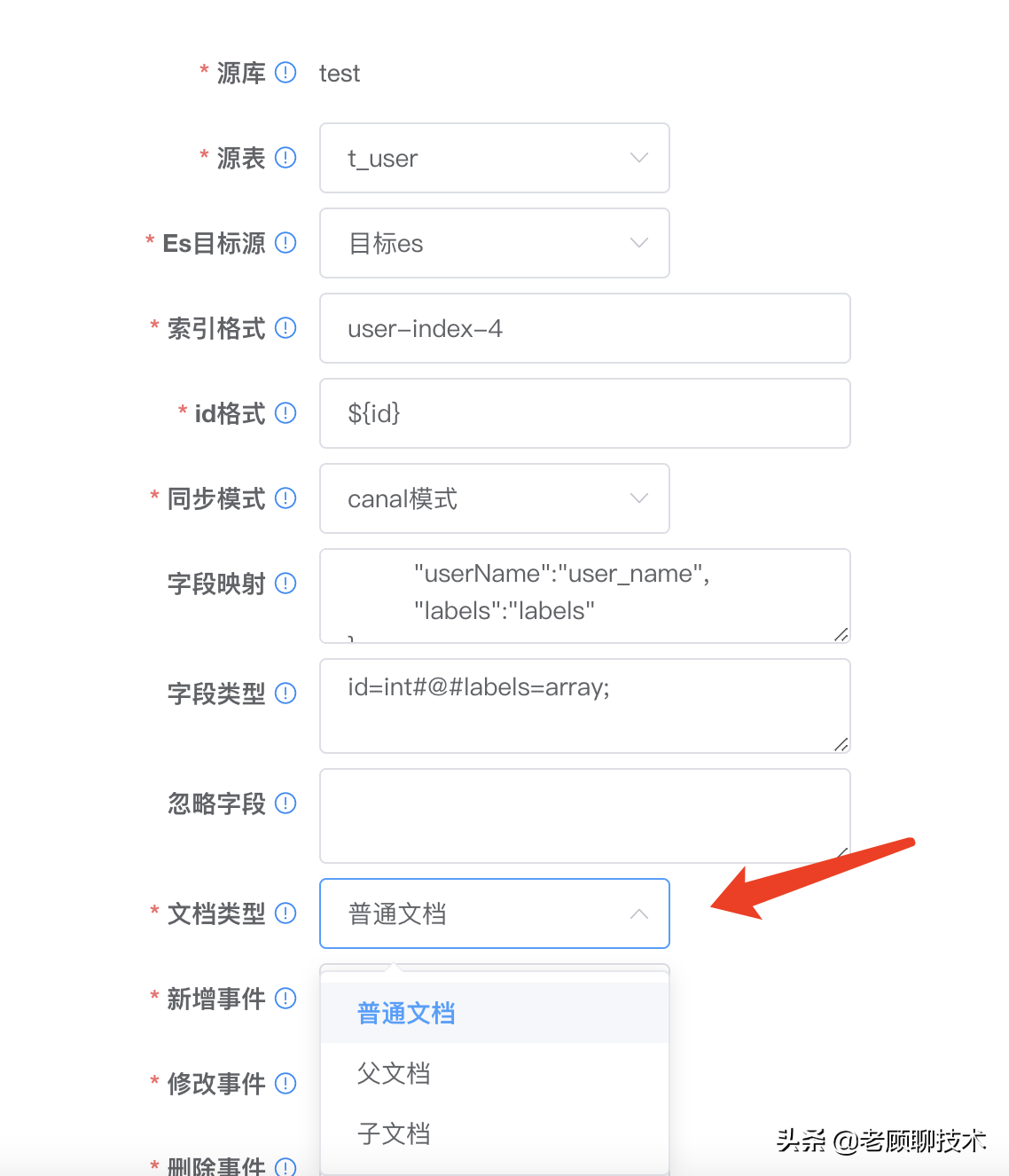
**索引格式:**数据同步哪一个index索引中,支持freemarker
**id格式:**index文档的唯一id,支持freemarker
**同步模式:** 0:索引更新sql模式(执行sql语句,获得es属性)),1:索引更新canal模式(直接从binlog属性中获取)
sql模式针对负责需求,需要关联其他表时用到
**字段映射:**canal模式时有效,json格式,映射es和db的属性字段,格式{k1:v1, k2:v2} k1=v1(es属性=db列)
**sql语句:**sql模式时有效,sql格式,有事件时执行sql,变量用?代替
**sql字段:**sql模式时有效,sql格式中?对应的值,(以#@#隔开)
**sqlNull字段:**sql模式时有效,如果sql执行结果为空是,需要清理的esFiled(逗号隔开)
**字段类型:**字段的类型(k1=v1 以#@#隔开)(表示:es字段名=字段类型)\n类型有 int、date、string、array、json、decimal\n如:\nF1=array; 数组格式 array+值分隔符(1个字符)+值类型(int,decimal,string;默认不写为string), 配合 group_concat 字符; 代表值以;隔开\nF1=json json对象
**忽略字段:**跳过忽略此字段(es属性),不需要把此es属性更新进去(F1,F2以逗号隔开)
**文档类型:**0:普通文档,1:父文档,2:子文档
**父子关联名:**父子文档时有效,父子关联健名(父子文档有效),如:join_field
**文档关联名:**父子文档时有效,文档关联名(父子文档有效),如:父:question,子:answer
**子文档路由:**子文档的route格式(父子文档有效)支持freemarker
**子文档的父Id:**子文档的parent格式(父子文档有效)支持freemarker
**删除策略:**0:根据index和id模板删除索引,1:sql模式有效,执行sql模板,更新索引
------
## 任务刷新
如何让任务以及规则配置好后,立即生效?
1、需要把任务以及规则状态,设置为发布
2、需要在任务管理中,点击任务刷新按钮
3、任务刷新按钮 可以 指定刷新 什么环境,以及什么集群
4、一旦操作了任务刷新,对应的环境集群的任务 就会自动分配。
------
# Docker容器化部署
## bridge-admin部署
1、dockerfile文件,如下
```
#需要指定一个安装了java jdk1.8以上的centos7 64位
FROM java_jdk1.8
ARG arg_env=dev
ARG arg_opts=default
ENV TZ=Asia/Shanghai
ENV ENV_CODE=$arg_env
ENV START_OPTS=$arg_opts
COPY bridge-admin/ /opt/bridge-admin
RUN chmod 755 /opt/bridge-admin/bin/*.sh
CMD /opt/bridge-admin/bin/startup.sh ${ENV_CODE} ${START_OPTS}
```
把dockerfile放到与bridge-admin同级目录下
2、startup.sh脚本支持传2个参数
第一个参数代表命名空间(环境),默认值为dev
第二个参数是java_opts启动参数,默认值在脚本文件中
可以不传,有对应的默认值
3、执行docker build、push等命令,推送到harbor私有仓库中
## bridge-server部署
1、dockerfile文件,如下
```
#需要指定一个安装了java jdk1.8以上的centos7 64位
FROM java_jdk1.8
ARG arg_env=dev
ARG arg_opts=default
ENV TZ=Asia/Shanghai
ENV ENV_CODE=$arg_env
ENV START_OPTS=$arg_opts
COPY bridge-server/ /opt/bridge-server
RUN chmod 755 /opt/bridge-server/bin/*.sh
CMD /opt/bridge-server/bin/startup.sh ${ENV_CODE} ${START_OPTS}
```
把dockerfile放到与bridge-server同级目录下
2、startup.sh脚本支持传2个参数
第一个参数代表命名空间(环境),默认值为dev
第二个参数是java_opts启动参数,默认值在脚本文件中
可以不传,有对应的默认值
3、执行docker build、push等命令,推送到harbor私有仓库中
------
# Bridge打包
## 如何生成admin-ui访问文件?
在admin-ui目录下执行如下命令,就可以生成dist目录
```
npm run build:prod
```
## 如何把dist目录 迁移到admin服务下?
在bridge-admin目录下
```
mvn package -Pnpm
```
这个就可以把 dist目录中的文件 打到 admin目录resources的public下
## 如何生成release执行包?
**在bridge-admin目录下**
```
mvn package -Prelease
```
就可以在整个bridge目录的上级目录中,找到target目录
```
bridge-admin-1.1.0.tar.gz
```
**在bridge-server目录下**
```
mvn package -Prelease
```
就可以在整个bridge目录的上级目录中,找到target目录
```
bridge-server-1.1.0.tar.gz
```
------
# 相关文献
Canal项目地址:https://github.com/alibaba/canal
Canal文档:https://github.com/alibaba/canal/wiki/Introduction