# deep-learning-from-scratch-4
**Repository Path**: sunmo/deep-learning-from-scratch-4
## Basic Information
- **Project Name**: deep-learning-from-scratch-4
- **Description**: No description available
- **Primary Language**: Python
- **License**: MIT
- **Default Branch**: master
- **Homepage**: None
- **GVP Project**: No
## Statistics
- **Stars**: 0
- **Forks**: 0
- **Created**: 2025-04-01
- **Last Updated**: 2025-04-01
## Categories & Tags
**Categories**: Uncategorized
**Tags**: None
## README
[ ](https://www.amazon.co.jp/dp/4873119758)
書籍『[ゼロから作るDeep Learning ❹ 強化学習編](https://www.amazon.co.jp/dp/4873119758)』(オライリー・ジャパン)のサポートサイトです。本書籍で使用するソースコードがまとめられています。
## ニュース
](https://www.amazon.co.jp/dp/4873119758)
書籍『[ゼロから作るDeep Learning ❹ 強化学習編](https://www.amazon.co.jp/dp/4873119758)』(オライリー・ジャパン)のサポートサイトです。本書籍で使用するソースコードがまとめられています。
## ニュース
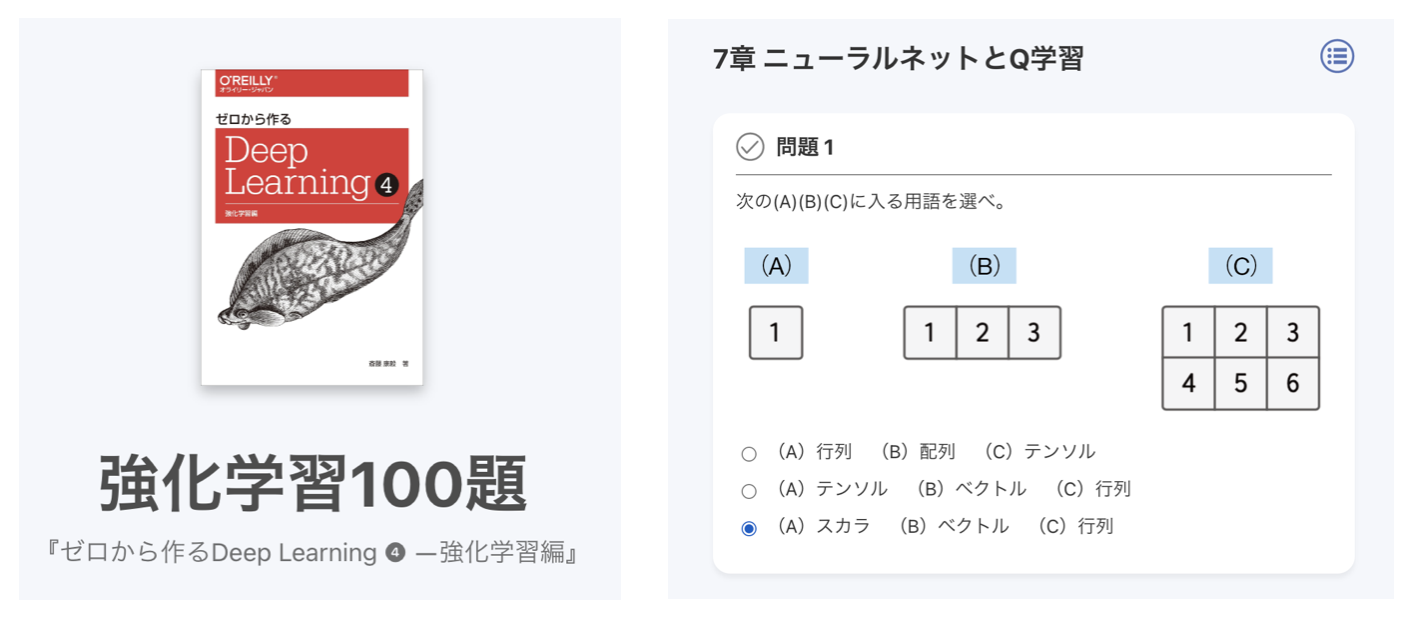 本書の内容を確認するための「強化学習100題」を用意しています。
https://koki0702.github.io/dezero-p100/
## ファイル構成
|フォルダ名 |説明 |
|:-- |:-- |
|ch01 |1章で使用するソースコード |
|... |... |
|ch09 |9章で使用するソースコード |
|common |共通で使用するソースコード |
|notebooks |Jupyter Notebook形式のソースコード |
|pytorch |PyTorchに移植したソースコード |
## Jupyter Notebook
本書のコードはJupyter Notebookでも用意しています。次の表にあるボタンをクリックすることで、Google ColabやKaggle Notebookなどのクラウドサービス上でNotebookを実行することができます。
| 章 | Colab | Kaggle | Studio Lab |
| :--- | :--- | :--- | :--- |
| 1章 バンディット問題 | [](https://colab.research.google.com/github/oreilly-japan/deep-learning-from-scratch-4/blob/master/notebooks/01_bandit.ipynb) | [](https://kaggle.com/kernels/welcome?src=https://github.com/oreilly-japan/deep-learning-from-scratch-4/blob/master/notebooks/01_bandit.ipynb) | [](https://studiolab.sagemaker.aws/import/github/oreilly-japan/deep-learning-from-scratch-4/blob/master/notebooks/01_bandit.ipynb) |
| 4章 動的計画法 | [](https://colab.research.google.com/github/oreilly-japan/deep-learning-from-scratch-4/blob/master/notebooks/04_dynamic_programming.ipynb) | [](https://kaggle.com/kernels/welcome?src=https://github.com/oreilly-japan/deep-learning-from-scratch-4/blob/master/notebooks/04_dynamic_programming.ipynb) | [](https://studiolab.sagemaker.aws/import/github/oreilly-japan/deep-learning-from-scratch-4/blob/master/notebooks/04_dynamic_programming.ipynb) |
| 5章 モンテカルロ法 | [](https://colab.research.google.com/github/oreilly-japan/deep-learning-from-scratch-4/blob/master/notebooks/05_montecarlo.ipynb) | [](https://kaggle.com/kernels/welcome?src=https://github.com/oreilly-japan/deep-learning-from-scratch-4/blob/master/notebooks/05_montecarlo.ipynb) | [](https://studiolab.sagemaker.aws/import/github/oreilly-japan/deep-learning-from-scratch-4/blob/master/notebooks/05_montecarlo.ipynb) |
| 6章 TD法 | [](https://colab.research.google.com/github/oreilly-japan/deep-learning-from-scratch-4/blob/master/notebooks/06_temporal_difference.ipynb) | [](https://kaggle.com/kernels/welcome?src=https://github.com/oreilly-japan/deep-learning-from-scratch-4/blob/master/notebooks/06_temporal_difference.ipynb) | [](https://studiolab.sagemaker.aws/import/github/oreilly-japan/deep-learning-from-scratch-4/blob/master/notebooks/06_temporal_difference.ipynb) |
| 7章 ニューラルネットワークとQ学習 | [](https://colab.research.google.com/github/oreilly-japan/deep-learning-from-scratch-4/blob/master/notebooks/07_neural_networks.ipynb) | [](https://kaggle.com/kernels/welcome?src=https://github.com/oreilly-japan/deep-learning-from-scratch-4/blob/master/notebooks/07_neural_networks.ipynb) | [](https://studiolab.sagemaker.aws/import/github/oreilly-japan/deep-learning-from-scratch-4/blob/master/notebooks/06_temporal_difference.ipynb) | [](https://studiolab.sagemaker.aws/import/github/oreilly-japan/deep-learning-from-scratch-4/blob/master/notebooks/07_neural_networks.ipynb) |
| 8章 DQN | [](https://colab.research.google.com/github/oreilly-japan/deep-learning-from-scratch-4/blob/master/notebooks/08_dqn.ipynb) | [](https://kaggle.com/kernels/welcome?src=https://github.com/oreilly-japan/deep-learning-from-scratch-4/blob/master/notebooks/08_dqn.ipynb) | [](https://studiolab.sagemaker.aws/import/github/oreilly-japan/deep-learning-from-scratch-4/blob/master/notebooks/08_dqn.ipynb) |
| 9章 方策勾配法 | [](https://colab.research.google.com/github/oreilly-japan/deep-learning-from-scratch-4/blob/master/notebooks/09_policy_gradient.ipynb) | [](https://kaggle.com/kernels/welcome?src=https://github.com/oreilly-japan/deep-learning-from-scratch-4/blob/master/notebooks/09_policy_gradient.ipynb) | [](https://studiolab.sagemaker.aws/import/github/oreilly-japan/deep-learning-from-scratch-4/blob/master/notebooks/09_policy_gradient.ipynb) |
## Pythonと外部ライブラリ
ソースコードを実行するには、下記のソフトウェアが必要です。
* Python 3.x(バージョン3系)
* NumPy
* Matplotlib
* OpenAI Gym
* DeZero (または PyTorch)
本書では、ディープラーニングのフレームワークとしてDeZeroを使います。DeZeroは「ゼロから作るDeep Learning」シリーズの3作目で作ったフレームワークです( `pip install dezero` からインストールできます)。
PyTorchを使った実装は[pytorchフォルダ](https://github.com/oreilly-japan/deep-learning-from-scratch-4/tree/master/pytorch)にて提供しています。
## 実行方法
各章のフォルダに該当するコードがあります。
実行するためには、下記のとおりPythonコマンドを実行します(どのディレクトリからでも実行できます)。
```
$ python ch01/avg.py
$ python ch08/dqn.py
$ cd ch09
$ python actor_critic.py
```
## ライセンス
本リポジトリのソースコードは[MITライセンス](http://www.opensource.org/licenses/MIT)です。
商用・非商用問わず、自由にご利用ください。
## 正誤表
本書の正誤情報は以下のページで公開しています。
https://github.com/oreilly-japan/deep-learning-from-scratch-4/wiki/errata
本ページに掲載されていない誤植など間違いを見つけた方は、[japan@oreilly.co.jp]()までお知らせください。
本書の内容を確認するための「強化学習100題」を用意しています。
https://koki0702.github.io/dezero-p100/
## ファイル構成
|フォルダ名 |説明 |
|:-- |:-- |
|ch01 |1章で使用するソースコード |
|... |... |
|ch09 |9章で使用するソースコード |
|common |共通で使用するソースコード |
|notebooks |Jupyter Notebook形式のソースコード |
|pytorch |PyTorchに移植したソースコード |
## Jupyter Notebook
本書のコードはJupyter Notebookでも用意しています。次の表にあるボタンをクリックすることで、Google ColabやKaggle Notebookなどのクラウドサービス上でNotebookを実行することができます。
| 章 | Colab | Kaggle | Studio Lab |
| :--- | :--- | :--- | :--- |
| 1章 バンディット問題 | [](https://colab.research.google.com/github/oreilly-japan/deep-learning-from-scratch-4/blob/master/notebooks/01_bandit.ipynb) | [](https://kaggle.com/kernels/welcome?src=https://github.com/oreilly-japan/deep-learning-from-scratch-4/blob/master/notebooks/01_bandit.ipynb) | [](https://studiolab.sagemaker.aws/import/github/oreilly-japan/deep-learning-from-scratch-4/blob/master/notebooks/01_bandit.ipynb) |
| 4章 動的計画法 | [](https://colab.research.google.com/github/oreilly-japan/deep-learning-from-scratch-4/blob/master/notebooks/04_dynamic_programming.ipynb) | [](https://kaggle.com/kernels/welcome?src=https://github.com/oreilly-japan/deep-learning-from-scratch-4/blob/master/notebooks/04_dynamic_programming.ipynb) | [](https://studiolab.sagemaker.aws/import/github/oreilly-japan/deep-learning-from-scratch-4/blob/master/notebooks/04_dynamic_programming.ipynb) |
| 5章 モンテカルロ法 | [](https://colab.research.google.com/github/oreilly-japan/deep-learning-from-scratch-4/blob/master/notebooks/05_montecarlo.ipynb) | [](https://kaggle.com/kernels/welcome?src=https://github.com/oreilly-japan/deep-learning-from-scratch-4/blob/master/notebooks/05_montecarlo.ipynb) | [](https://studiolab.sagemaker.aws/import/github/oreilly-japan/deep-learning-from-scratch-4/blob/master/notebooks/05_montecarlo.ipynb) |
| 6章 TD法 | [](https://colab.research.google.com/github/oreilly-japan/deep-learning-from-scratch-4/blob/master/notebooks/06_temporal_difference.ipynb) | [](https://kaggle.com/kernels/welcome?src=https://github.com/oreilly-japan/deep-learning-from-scratch-4/blob/master/notebooks/06_temporal_difference.ipynb) | [](https://studiolab.sagemaker.aws/import/github/oreilly-japan/deep-learning-from-scratch-4/blob/master/notebooks/06_temporal_difference.ipynb) |
| 7章 ニューラルネットワークとQ学習 | [](https://colab.research.google.com/github/oreilly-japan/deep-learning-from-scratch-4/blob/master/notebooks/07_neural_networks.ipynb) | [](https://kaggle.com/kernels/welcome?src=https://github.com/oreilly-japan/deep-learning-from-scratch-4/blob/master/notebooks/07_neural_networks.ipynb) | [](https://studiolab.sagemaker.aws/import/github/oreilly-japan/deep-learning-from-scratch-4/blob/master/notebooks/06_temporal_difference.ipynb) | [](https://studiolab.sagemaker.aws/import/github/oreilly-japan/deep-learning-from-scratch-4/blob/master/notebooks/07_neural_networks.ipynb) |
| 8章 DQN | [](https://colab.research.google.com/github/oreilly-japan/deep-learning-from-scratch-4/blob/master/notebooks/08_dqn.ipynb) | [](https://kaggle.com/kernels/welcome?src=https://github.com/oreilly-japan/deep-learning-from-scratch-4/blob/master/notebooks/08_dqn.ipynb) | [](https://studiolab.sagemaker.aws/import/github/oreilly-japan/deep-learning-from-scratch-4/blob/master/notebooks/08_dqn.ipynb) |
| 9章 方策勾配法 | [](https://colab.research.google.com/github/oreilly-japan/deep-learning-from-scratch-4/blob/master/notebooks/09_policy_gradient.ipynb) | [](https://kaggle.com/kernels/welcome?src=https://github.com/oreilly-japan/deep-learning-from-scratch-4/blob/master/notebooks/09_policy_gradient.ipynb) | [](https://studiolab.sagemaker.aws/import/github/oreilly-japan/deep-learning-from-scratch-4/blob/master/notebooks/09_policy_gradient.ipynb) |
## Pythonと外部ライブラリ
ソースコードを実行するには、下記のソフトウェアが必要です。
* Python 3.x(バージョン3系)
* NumPy
* Matplotlib
* OpenAI Gym
* DeZero (または PyTorch)
本書では、ディープラーニングのフレームワークとしてDeZeroを使います。DeZeroは「ゼロから作るDeep Learning」シリーズの3作目で作ったフレームワークです( `pip install dezero` からインストールできます)。
PyTorchを使った実装は[pytorchフォルダ](https://github.com/oreilly-japan/deep-learning-from-scratch-4/tree/master/pytorch)にて提供しています。
## 実行方法
各章のフォルダに該当するコードがあります。
実行するためには、下記のとおりPythonコマンドを実行します(どのディレクトリからでも実行できます)。
```
$ python ch01/avg.py
$ python ch08/dqn.py
$ cd ch09
$ python actor_critic.py
```
## ライセンス
本リポジトリのソースコードは[MITライセンス](http://www.opensource.org/licenses/MIT)です。
商用・非商用問わず、自由にご利用ください。
## 正誤表
本書の正誤情報は以下のページで公開しています。
https://github.com/oreilly-japan/deep-learning-from-scratch-4/wiki/errata
本ページに掲載されていない誤植など間違いを見つけた方は、[japan@oreilly.co.jp]()までお知らせください。