![]()



Various style translations by varying the latent code.
### Boundary-Seeking GAN _Boundary-Seeking Generative Adversarial Networks_ #### Authors R Devon Hjelm, Athul Paul Jacob, Tong Che, Adam Trischler, Kyunghyun Cho, Yoshua Bengio #### Abstract Generative adversarial networks (GANs) are a learning framework that rely on training a discriminator to estimate a measure of difference between a target and generated distributions. GANs, as normally formulated, rely on the generated samples being completely differentiable w.r.t. the generative parameters, and thus do not work for discrete data. We introduce a method for training GANs with discrete data that uses the estimated difference measure from the discriminator to compute importance weights for generated samples, thus providing a policy gradient for training the generator. The importance weights have a strong connection to the decision boundary of the discriminator, and we call our method boundary-seeking GANs (BGANs). We demonstrate the effectiveness of the proposed algorithm with discrete image and character-based natural language generation. In addition, the boundary-seeking objective extends to continuous data, which can be used to improve stability of training, and we demonstrate this on Celeba, Large-scale Scene Understanding (LSUN) bedrooms, and Imagenet without conditioning. [[Paper]](https://arxiv.org/abs/1702.08431) [[Code]](implementations/bgan/bgan.py) #### Run Example ``` $ cd implementations/bgan/ $ python3 bgan.py ``` ### Cluster GAN _ClusterGAN: Latent Space Clustering in Generative Adversarial Networks_ #### Authors Sudipto Mukherjee, Himanshu Asnani, Eugene Lin, Sreeram Kannan #### Abstract Generative Adversarial networks (GANs) have obtained remarkable success in many unsupervised learning tasks and unarguably, clustering is an important unsupervised learning problem. While one can potentially exploit the latent-space back-projection in GANs to cluster, we demonstrate that the cluster structure is not retained in the GAN latent space. In this paper, we propose ClusterGAN as a new mechanism for clustering using GANs. By sampling latent variables from a mixture of one-hot encoded variables and continuous latent variables, coupled with an inverse network (which projects the data to the latent space) trained jointly with a clustering specific loss, we are able to achieve clustering in the latent space. Our results show a remarkable phenomenon that GANs can preserve latent space interpolation across categories, even though the discriminator is never exposed to such vectors. We compare our results with various clustering baselines and demonstrate superior performance on both synthetic and real datasets. [[Paper]](https://arxiv.org/abs/1809.03627) [[Code]](implementations/cluster_gan/clustergan.py) Code based on a full PyTorch [[implementation]](https://github.com/zhampel/clusterGAN). #### Run Example ``` $ cd implementations/cluster_gan/ $ python3 clustergan.py ```



Rows: Masked | Inpainted | Original | Masked | Inpainted | Original
### Coupled GAN _Coupled Generative Adversarial Networks_ #### Authors Ming-Yu Liu, Oncel Tuzel #### Abstract We propose coupled generative adversarial network (CoGAN) for learning a joint distribution of multi-domain images. In contrast to the existing approaches, which require tuples of corresponding images in different domains in the training set, CoGAN can learn a joint distribution without any tuple of corresponding images. It can learn a joint distribution with just samples drawn from the marginal distributions. This is achieved by enforcing a weight-sharing constraint that limits the network capacity and favors a joint distribution solution over a product of marginal distributions one. We apply CoGAN to several joint distribution learning tasks, including learning a joint distribution of color and depth images, and learning a joint distribution of face images with different attributes. For each task it successfully learns the joint distribution without any tuple of corresponding images. We also demonstrate its applications to domain adaptation and image transformation. [[Paper]](https://arxiv.org/abs/1606.07536) [[Code]](implementations/cogan/cogan.py) #### Run Example ``` $ cd implementations/cogan/ $ python3 cogan.py ```

Generated MNIST and MNIST-M images
### CycleGAN _Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks_ #### Authors Jun-Yan Zhu, Taesung Park, Phillip Isola, Alexei A. Efros #### Abstract Image-to-image translation is a class of vision and graphics problems where the goal is to learn the mapping between an input image and an output image using a training set of aligned image pairs. However, for many tasks, paired training data will not be available. We present an approach for learning to translate an image from a source domain X to a target domain Y in the absence of paired examples. Our goal is to learn a mapping G:X→Y such that the distribution of images from G(X) is indistinguishable from the distribution Y using an adversarial loss. Because this mapping is highly under-constrained, we couple it with an inverse mapping F:Y→X and introduce a cycle consistency loss to push F(G(X))≈X (and vice versa). Qualitative results are presented on several tasks where paired training data does not exist, including collection style transfer, object transfiguration, season transfer, photo enhancement, etc. Quantitative comparisons against several prior methods demonstrate the superiority of our approach. [[Paper]](https://arxiv.org/abs/1703.10593) [[Code]](implementations/cyclegan/cyclegan.py)
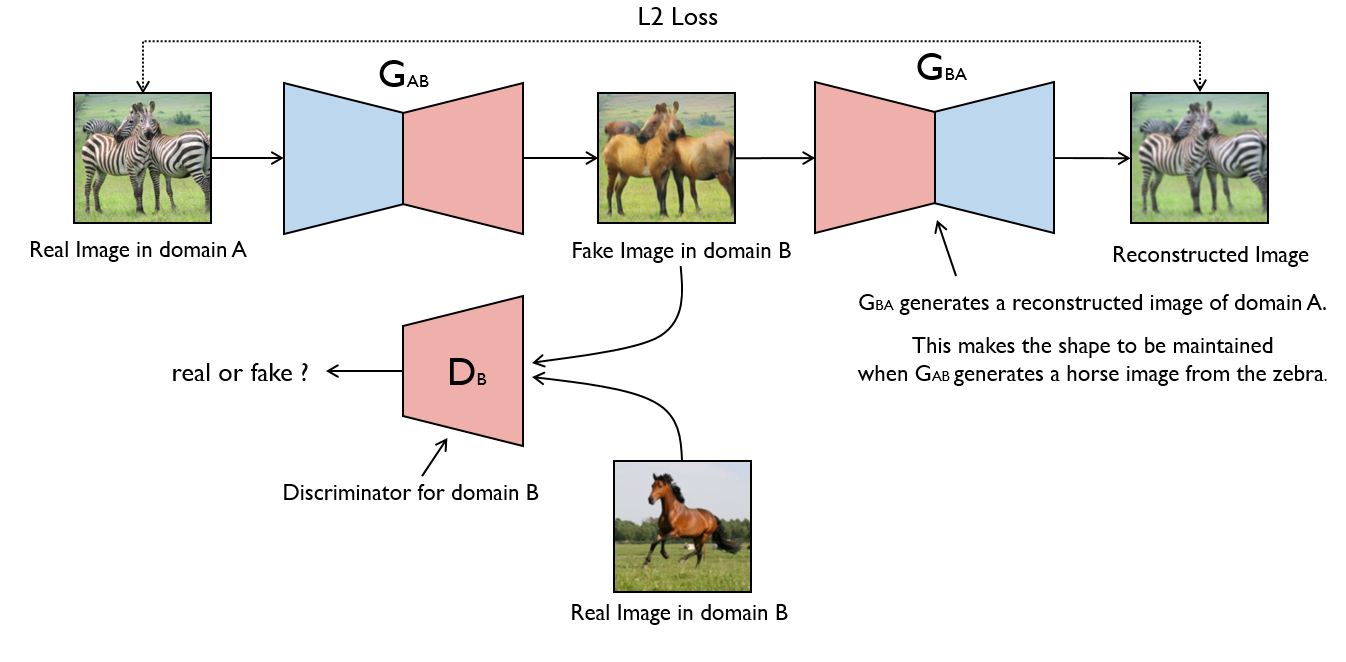

Monet to photo translations.
### Deep Convolutional GAN _Deep Convolutional Generative Adversarial Network_ #### Authors Alec Radford, Luke Metz, Soumith Chintala #### Abstract In recent years, supervised learning with convolutional networks (CNNs) has seen huge adoption in computer vision applications. Comparatively, unsupervised learning with CNNs has received less attention. In this work we hope to help bridge the gap between the success of CNNs for supervised learning and unsupervised learning. We introduce a class of CNNs called deep convolutional generative adversarial networks (DCGANs), that have certain architectural constraints, and demonstrate that they are a strong candidate for unsupervised learning. Training on various image datasets, we show convincing evidence that our deep convolutional adversarial pair learns a hierarchy of representations from object parts to scenes in both the generator and discriminator. Additionally, we use the learned features for novel tasks - demonstrating their applicability as general image representations. [[Paper]](https://arxiv.org/abs/1511.06434) [[Code]](implementations/dcgan/dcgan.py) #### Run Example ``` $ cd implementations/dcgan/ $ python3 dcgan.py ```

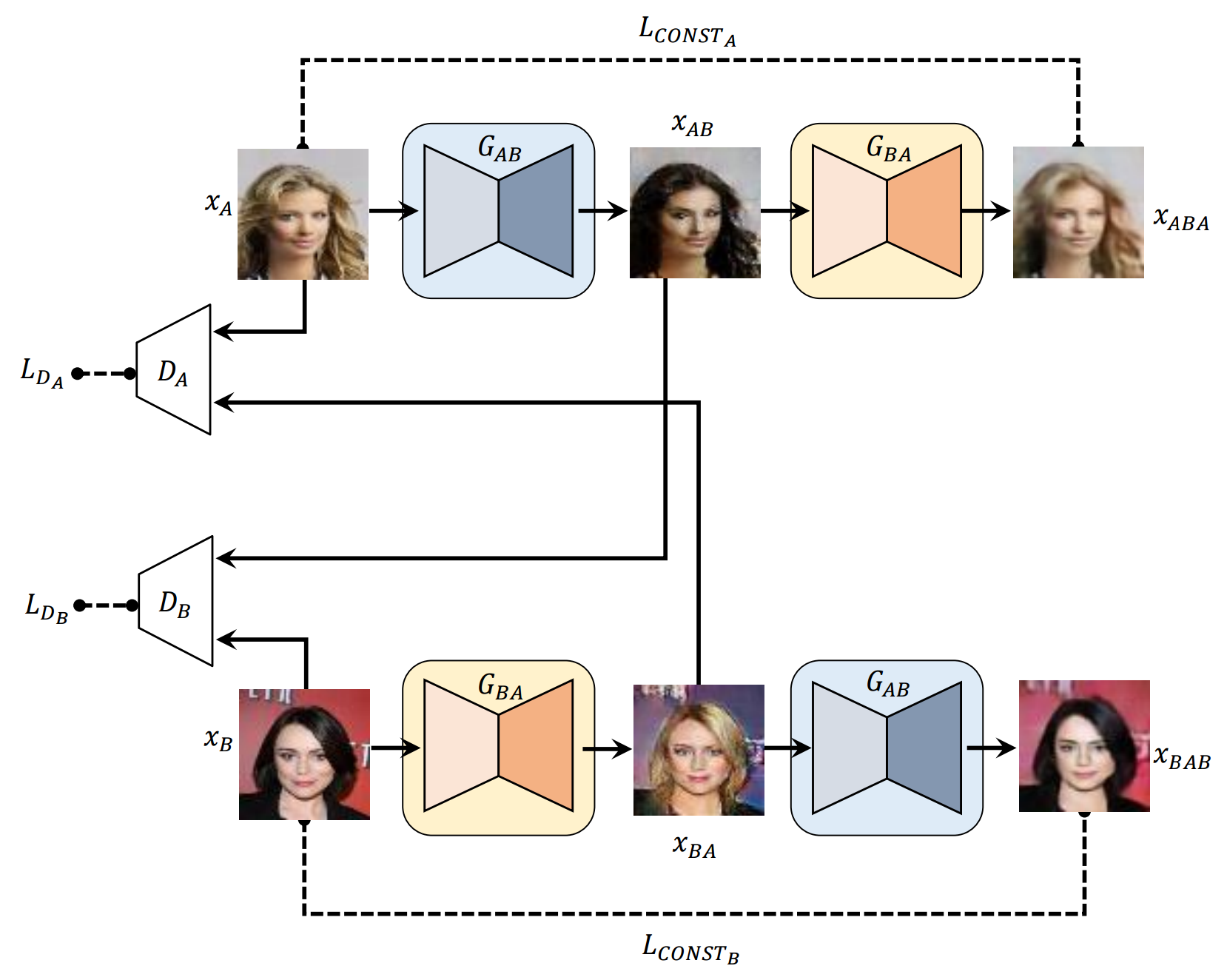

Rows from top to bottom: (1) Real image from domain A (2) Translated image from
domain A (3) Reconstructed image from domain A (4) Real image from domain B (5)
Translated image from domain B (6) Reconstructed image from domain B

Nearest Neighbor Upsampling | ESRGAN
### GAN _Generative Adversarial Network_ #### Authors Ian J. Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, Yoshua Bengio #### Abstract We propose a new framework for estimating generative models via an adversarial process, in which we simultaneously train two models: a generative model G that captures the data distribution, and a discriminative model D that estimates the probability that a sample came from the training data rather than G. The training procedure for G is to maximize the probability of D making a mistake. This framework corresponds to a minimax two-player game. In the space of arbitrary functions G and D, a unique solution exists, with G recovering the training data distribution and D equal to 1/2 everywhere. In the case where G and D are defined by multilayer perceptrons, the entire system can be trained with backpropagation. There is no need for any Markov chains or unrolled approximate inference networks during either training or generation of samples. Experiments demonstrate the potential of the framework through qualitative and quantitative evaluation of the generated samples. [[Paper]](https://arxiv.org/abs/1406.2661) [[Code]](implementations/gan/gan.py) #### Run Example ``` $ cd implementations/gan/ $ python3 gan.py ```


Result of varying categorical latent variable by column.

Result of varying continuous latent variable by row.
### Least Squares GAN _Least Squares Generative Adversarial Networks_ #### Authors Xudong Mao, Qing Li, Haoran Xie, Raymond Y.K. Lau, Zhen Wang, Stephen Paul Smolley #### Abstract Unsupervised learning with generative adversarial networks (GANs) has proven hugely successful. Regular GANs hypothesize the discriminator as a classifier with the sigmoid cross entropy loss function. However, we found that this loss function may lead to the vanishing gradients problem during the learning process. To overcome such a problem, we propose in this paper the Least Squares Generative Adversarial Networks (LSGANs) which adopt the least squares loss function for the discriminator. We show that minimizing the objective function of LSGAN yields minimizing the Pearson χ2 divergence. There are two benefits of LSGANs over regular GANs. First, LSGANs are able to generate higher quality images than regular GANs. Second, LSGANs perform more stable during the learning process. We evaluate LSGANs on five scene datasets and the experimental results show that the images generated by LSGANs are of better quality than the ones generated by regular GANs. We also conduct two comparison experiments between LSGANs and regular GANs to illustrate the stability of LSGANs. [[Paper]](https://arxiv.org/abs/1611.04076) [[Code]](implementations/lsgan/lsgan.py) #### Run Example ``` $ cd implementations/lsgan/ $ python3 lsgan.py ``` ### MUNIT _Multimodal Unsupervised Image-to-Image Translation_ #### Authors Xun Huang, Ming-Yu Liu, Serge Belongie, Jan Kautz #### Abstract Unsupervised image-to-image translation is an important and challenging problem in computer vision. Given an image in the source domain, the goal is to learn the conditional distribution of corresponding images in the target domain, without seeing any pairs of corresponding images. While this conditional distribution is inherently multimodal, existing approaches make an overly simplified assumption, modeling it as a deterministic one-to-one mapping. As a result, they fail to generate diverse outputs from a given source domain image. To address this limitation, we propose a Multimodal Unsupervised Image-to-image Translation (MUNIT) framework. We assume that the image representation can be decomposed into a content code that is domain-invariant, and a style code that captures domain-specific properties. To translate an image to another domain, we recombine its content code with a random style code sampled from the style space of the target domain. We analyze the proposed framework and establish several theoretical results. Extensive experiments with comparisons to the state-of-the-art approaches further demonstrates the advantage of the proposed framework. Moreover, our framework allows users to control the style of translation outputs by providing an example style image. Code and pretrained models are available at [this https URL](https://github.com/nvlabs/MUNIT) [[Paper]](https://arxiv.org/abs/1804.04732) [[Code]](implementations/munit/munit.py) #### Run Example ``` $ cd data/ $ bash download_pix2pix_dataset.sh edges2shoes $ cd ../implementations/munit/ $ python3 munit.py --dataset_name edges2shoes ```

Results by varying the style code.
### Pix2Pix _Unpaired Image-to-Image Translation with Conditional Adversarial Networks_ #### Authors Phillip Isola, Jun-Yan Zhu, Tinghui Zhou, Alexei A. Efros #### Abstract We investigate conditional adversarial networks as a general-purpose solution to image-to-image translation problems. These networks not only learn the mapping from input image to output image, but also learn a loss function to train this mapping. This makes it possible to apply the same generic approach to problems that traditionally would require very different loss formulations. We demonstrate that this approach is effective at synthesizing photos from label maps, reconstructing objects from edge maps, and colorizing images, among other tasks. Indeed, since the release of the pix2pix software associated with this paper, a large number of internet users (many of them artists) have posted their own experiments with our system, further demonstrating its wide applicability and ease of adoption without the need for parameter tweaking. As a community, we no longer hand-engineer our mapping functions, and this work suggests we can achieve reasonable results without hand-engineering our loss functions either. [[Paper]](https://arxiv.org/abs/1611.07004) [[Code]](implementations/pix2pix/pix2pix.py)


Rows from top to bottom: (1) The condition for the generator (2) Generated image
based of condition (3) The true corresponding image to the condition
![]()
Rows from top to bottom: (1) Real images from MNIST (2) Translated images from
MNIST to MNIST-M (3) Examples of images from MNIST-M

Original | Black Hair | Blonde Hair | Brown Hair | Gender Flip | Aged
### Super-Resolution GAN _Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network_ #### Authors Christian Ledig, Lucas Theis, Ferenc Huszar, Jose Caballero, Andrew Cunningham, Alejandro Acosta, Andrew Aitken, Alykhan Tejani, Johannes Totz, Zehan Wang, Wenzhe Shi #### Abstract Despite the breakthroughs in accuracy and speed of single image super-resolution using faster and deeper convolutional neural networks, one central problem remains largely unsolved: how do we recover the finer texture details when we super-resolve at large upscaling factors? The behavior of optimization-based super-resolution methods is principally driven by the choice of the objective function. Recent work has largely focused on minimizing the mean squared reconstruction error. The resulting estimates have high peak signal-to-noise ratios, but they are often lacking high-frequency details and are perceptually unsatisfying in the sense that they fail to match the fidelity expected at the higher resolution. In this paper, we present SRGAN, a generative adversarial network (GAN) for image super-resolution (SR). To our knowledge, it is the first framework capable of inferring photo-realistic natural images for 4x upscaling factors. To achieve this, we propose a perceptual loss function which consists of an adversarial loss and a content loss. The adversarial loss pushes our solution to the natural image manifold using a discriminator network that is trained to differentiate between the super-resolved images and original photo-realistic images. In addition, we use a content loss motivated by perceptual similarity instead of similarity in pixel space. Our deep residual network is able to recover photo-realistic textures from heavily downsampled images on public benchmarks. An extensive mean-opinion-score (MOS) test shows hugely significant gains in perceptual quality using SRGAN. The MOS scores obtained with SRGAN are closer to those of the original high-resolution images than to those obtained with any state-of-the-art method. [[Paper]](https://arxiv.org/abs/1609.04802) [[Code]](implementations/srgan/srgan.py)
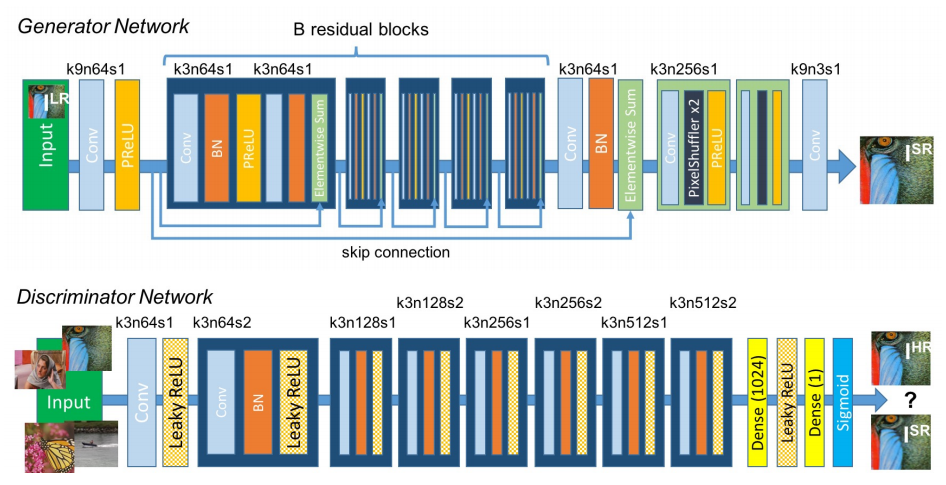

Nearest Neighbor Upsampling | SRGAN
### UNIT _Unsupervised Image-to-Image Translation Networks_ #### Authors Ming-Yu Liu, Thomas Breuel, Jan Kautz #### Abstract Unsupervised image-to-image translation aims at learning a joint distribution of images in different domains by using images from the marginal distributions in individual domains. Since there exists an infinite set of joint distributions that can arrive the given marginal distributions, one could infer nothing about the joint distribution from the marginal distributions without additional assumptions. To address the problem, we make a shared-latent space assumption and propose an unsupervised image-to-image translation framework based on Coupled GANs. We compare the proposed framework with competing approaches and present high quality image translation results on various challenging unsupervised image translation tasks, including street scene image translation, animal image translation, and face image translation. We also apply the proposed framework to domain adaptation and achieve state-of-the-art performance on benchmark datasets. Code and additional results are available in this [https URL](https://github.com/mingyuliutw/unit). [[Paper]](https://arxiv.org/abs/1703.00848) [[Code]](implementations/unit/unit.py) #### Run Example ``` $ cd data/ $ bash download_cyclegan_dataset.sh apple2orange $ cd implementations/unit/ $ python3 unit.py --dataset_name apple2orange ``` ### Wasserstein GAN _Wasserstein GAN_ #### Authors Martin Arjovsky, Soumith Chintala, Léon Bottou #### Abstract We introduce a new algorithm named WGAN, an alternative to traditional GAN training. In this new model, we show that we can improve the stability of learning, get rid of problems like mode collapse, and provide meaningful learning curves useful for debugging and hyperparameter searches. Furthermore, we show that the corresponding optimization problem is sound, and provide extensive theoretical work highlighting the deep connections to other distances between distributions. [[Paper]](https://arxiv.org/abs/1701.07875) [[Code]](implementations/wgan/wgan.py) #### Run Example ``` $ cd implementations/wgan/ $ python3 wgan.py ``` ### Wasserstein GAN GP _Improved Training of Wasserstein GANs_ #### Authors Ishaan Gulrajani, Faruk Ahmed, Martin Arjovsky, Vincent Dumoulin, Aaron Courville #### Abstract Generative Adversarial Networks (GANs) are powerful generative models, but suffer from training instability. The recently proposed Wasserstein GAN (WGAN) makes progress toward stable training of GANs, but sometimes can still generate only low-quality samples or fail to converge. We find that these problems are often due to the use of weight clipping in WGAN to enforce a Lipschitz constraint on the critic, which can lead to undesired behavior. We propose an alternative to clipping weights: penalize the norm of gradient of the critic with respect to its input. Our proposed method performs better than standard WGAN and enables stable training of a wide variety of GAN architectures with almost no hyperparameter tuning, including 101-layer ResNets and language models over discrete data. We also achieve high quality generations on CIFAR-10 and LSUN bedrooms. [[Paper]](https://arxiv.org/abs/1704.00028) [[Code]](implementations/wgan_gp/wgan_gp.py) #### Run Example ``` $ cd implementations/wgan_gp/ $ python3 wgan_gp.py ```

